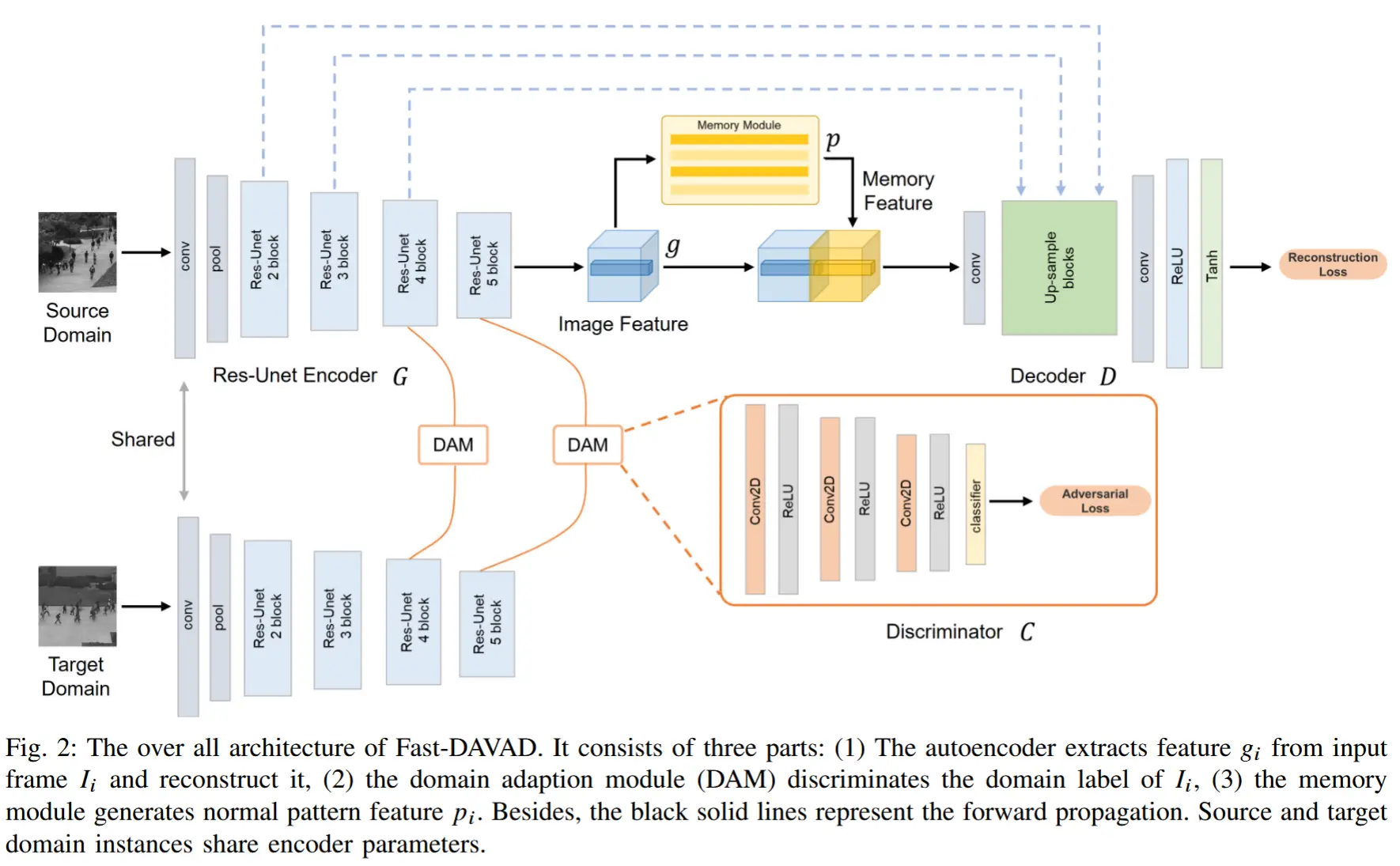
论文 - 《Fast-DAVAD : Domain Adaptation for Fast Video Anomaly Detection on Resource-Constrained Edge Devices》 关键词 - 边缘智能、域适应、视频异常检测、资源限制、对抗学习、记忆模块 1 引言
论文 - 《VideoLLM-online: Online Video Large Language Model for Streaming Video》 代码 - Github 关键词 - 流式视频、在线视频问答、视频大模型 1 引言 研究动机 现有大模型训练时通常将视频视为预定义的视频片段,导致
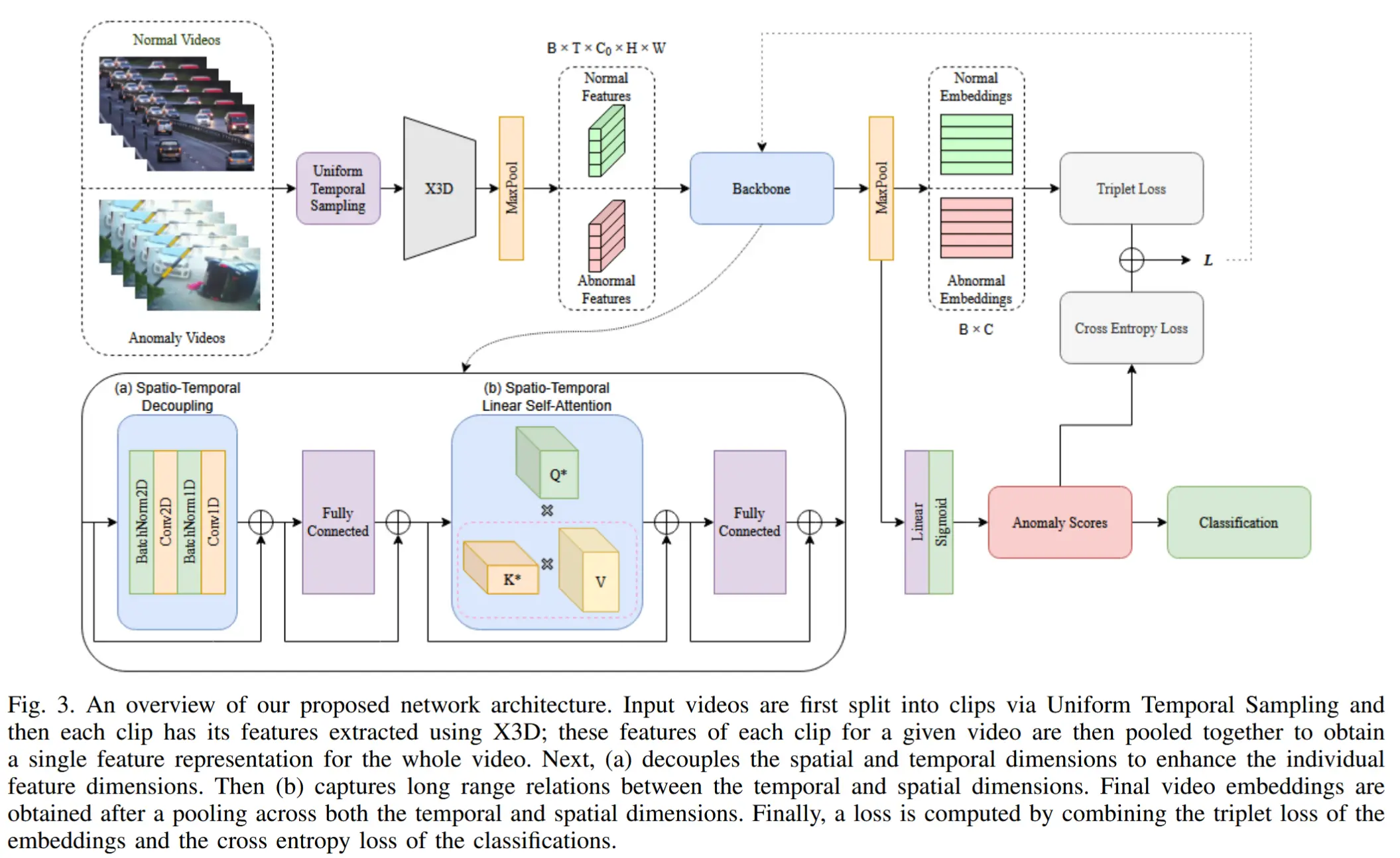
论文 - 《STEAD: Spatio-Temporal Efficient Anomaly Detection for Time and Compute Sensitive Applications》 代码 - Github 关键词 - 实时推理、轻量化、时空建模、视频异常检测VAD、I3D、X3
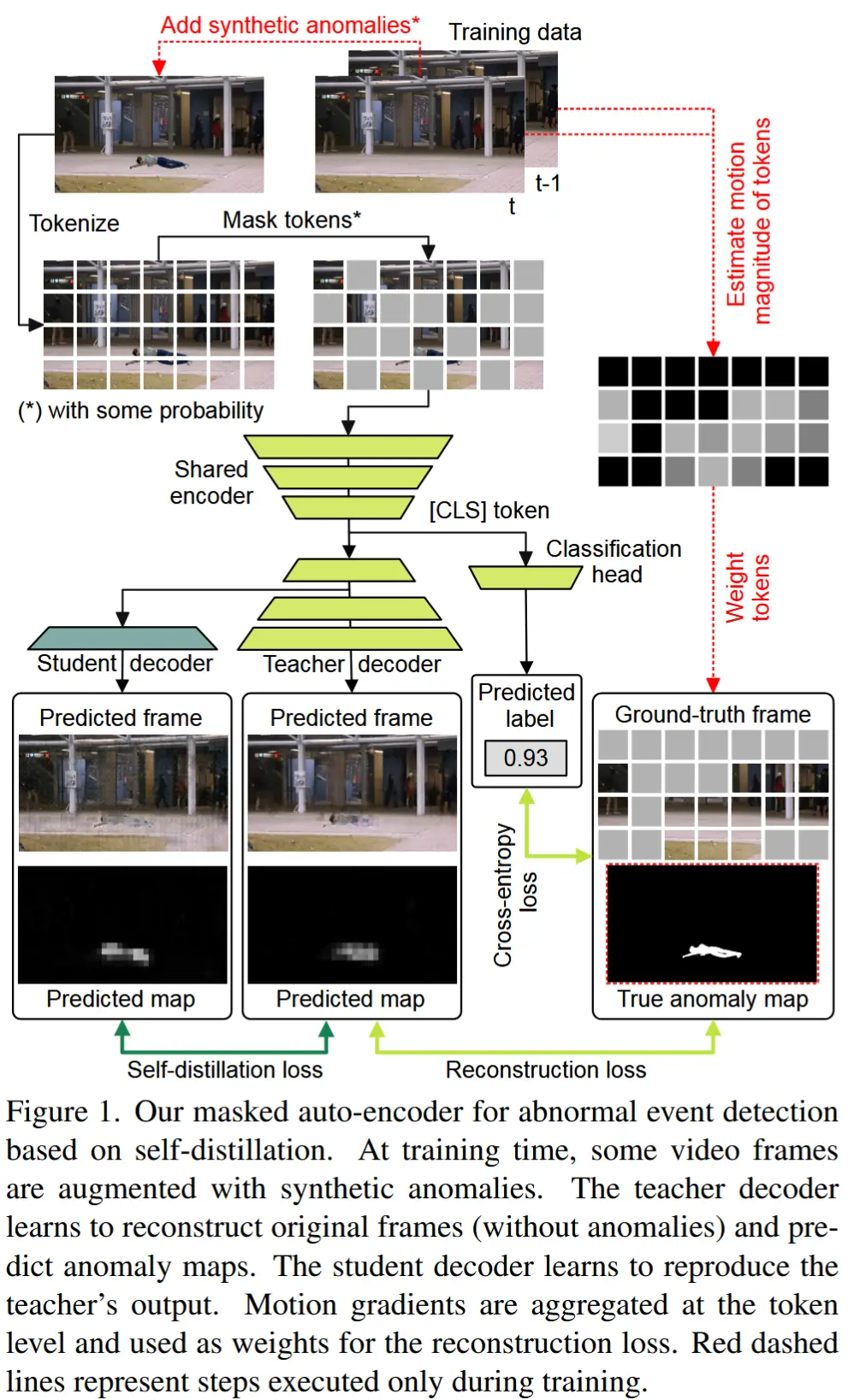
论文 - 《Self-Distilled Masked Auto-Encoders are Efficient Video Anomaly Detectors》 代码 - Github 关键词 - 视频异常检测VAD、高效方法、掩码自编码器、重建、自蒸馏、教师-学生、合成数据 1 引言 动机:当前最
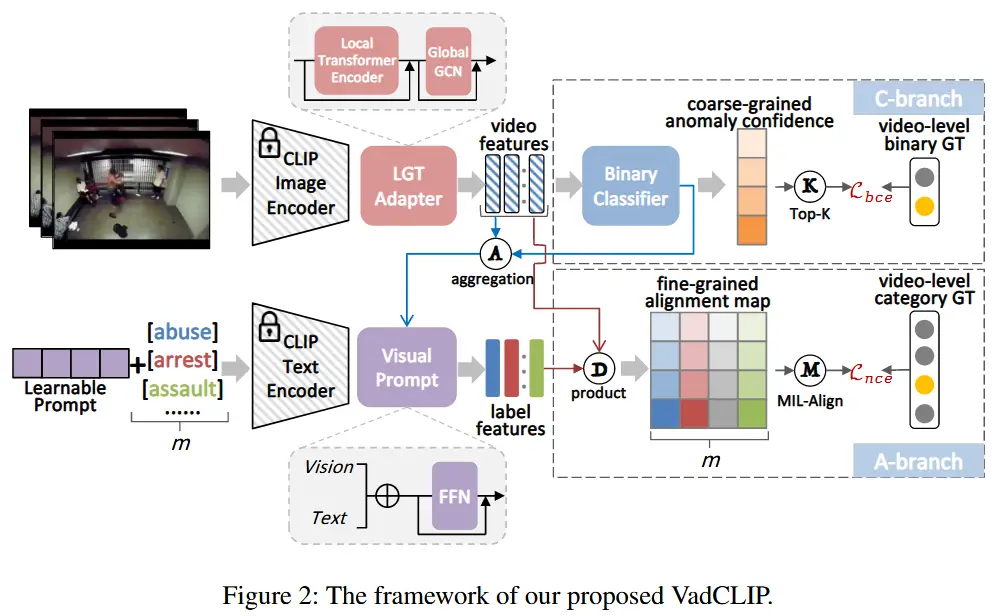
论文 - 《VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection》 代码 -Github 关键词 - 视频异常检测、CLIP、对比学习、局部全局、时序建模、弱监督学习 摘要 研究问
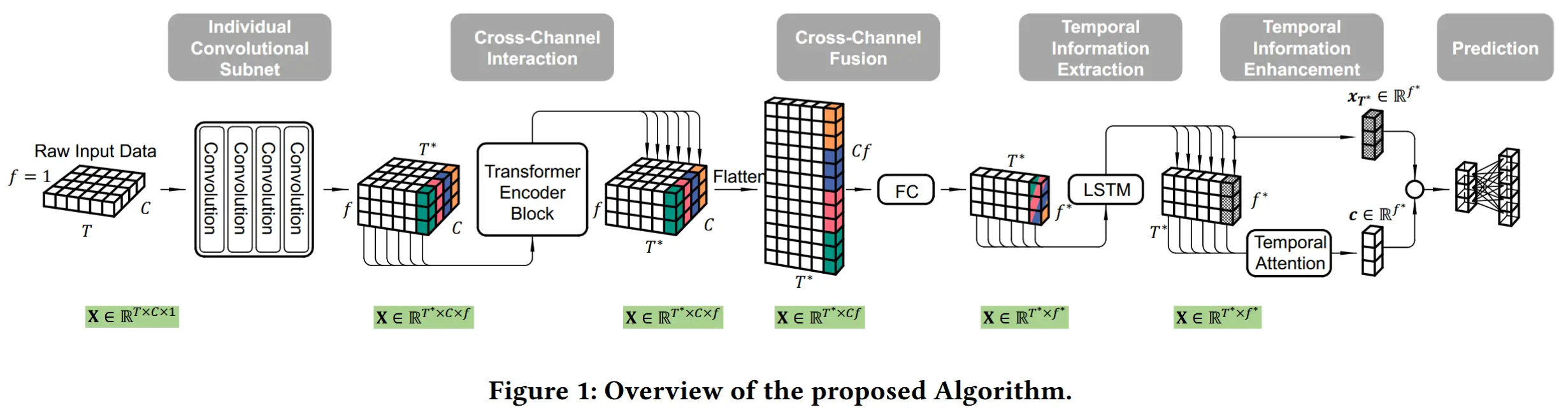
论文 - 《TinyHAR: A Lightweight Deep Learning Model Designed for Human Activity Recognition》 代码 -Github 关键词 - 高效、边缘智能、人类活动识别HAR、惯性传感单元IMU、卷积+Transformer
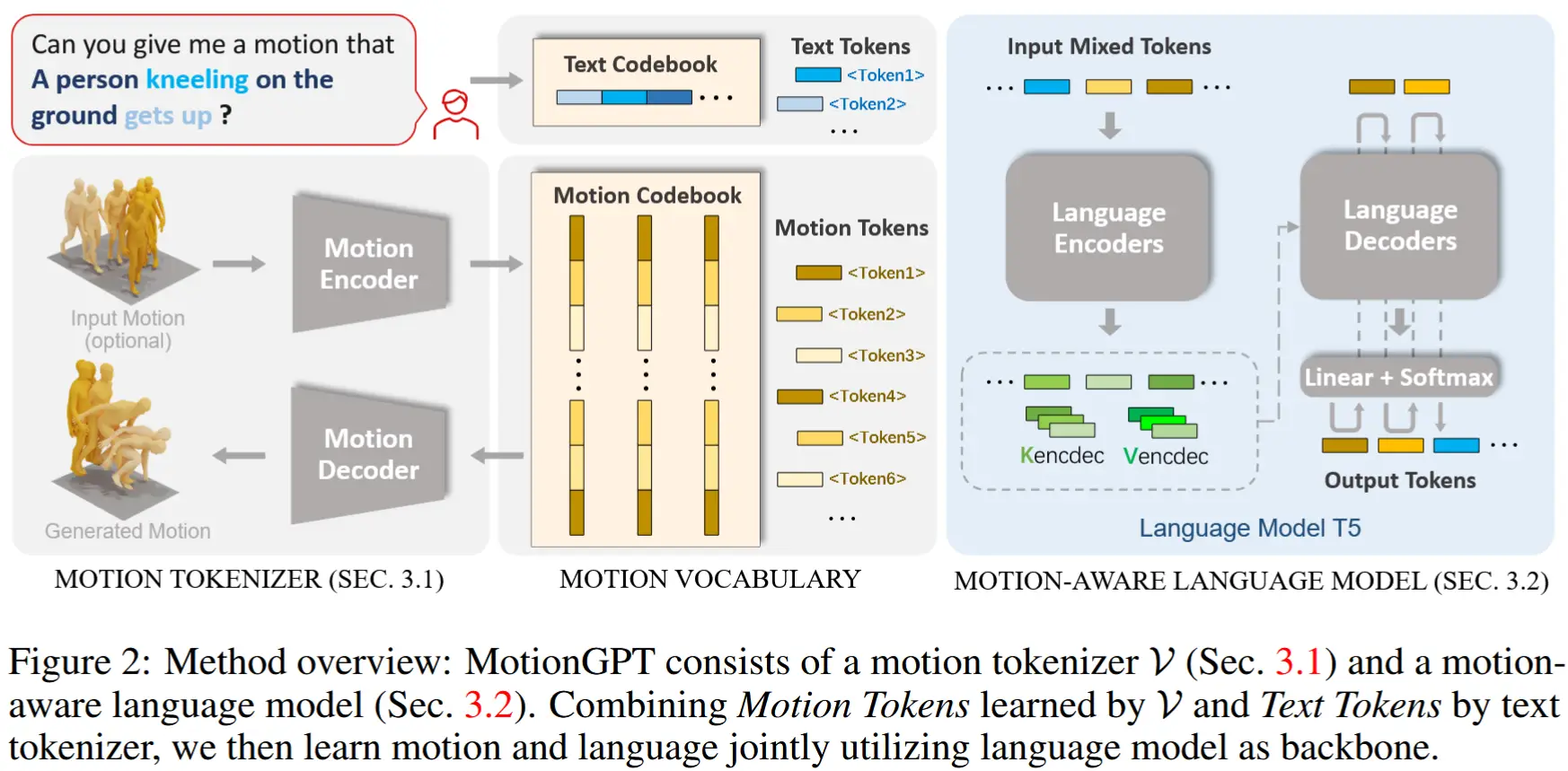
论文 - 《MotionGPT: Human Motion as a Foreign Language》 代码 - Github 关键词 - Neurips、运动-语言大模型、多任务、预训练+微调 1 摘要 研究问题 人类运动展现出与语言类似的语义结构,通常被视为一种“身体语言”。 通过将语言数据与
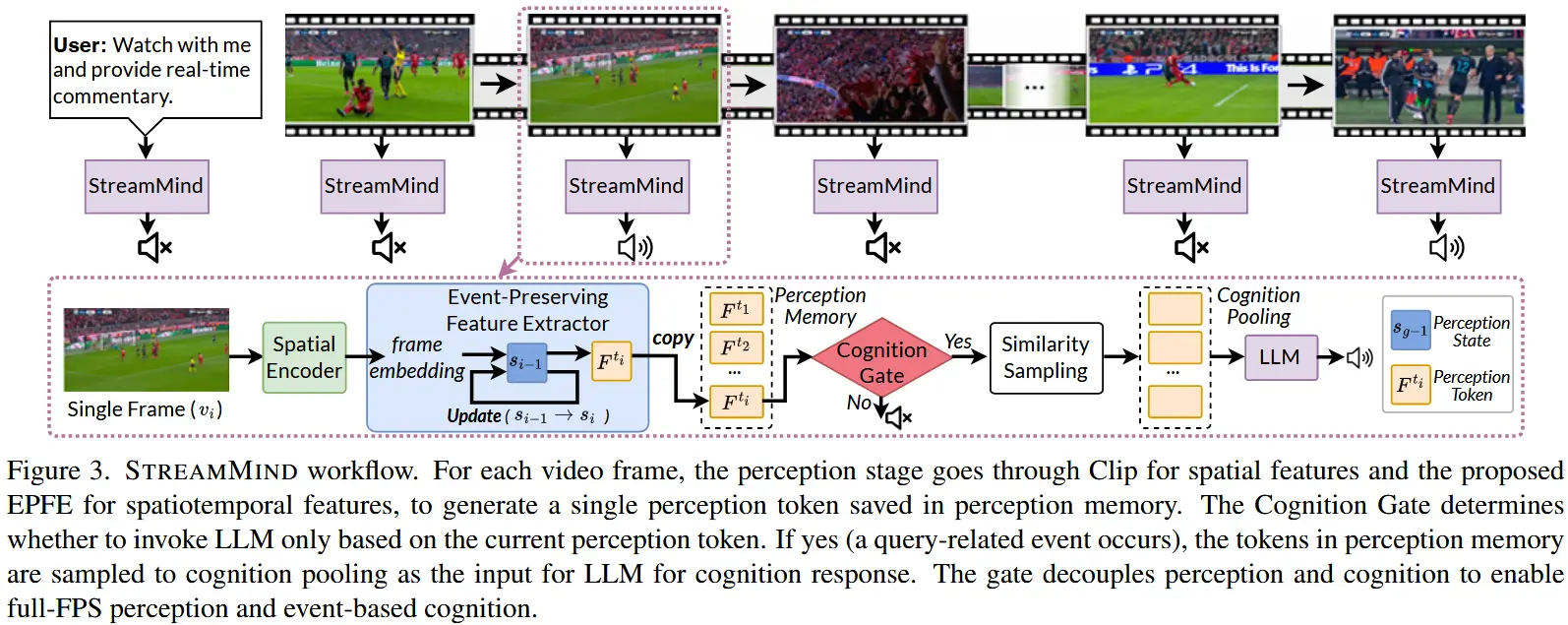
论文 - 《STREAMMIND: Unlocking Full Frame Rate Streaming Video Dialogue through Event-Gated Cognition》 代码 - Github 关键词 - 流式视频对话、实时处理、视频大模型、高效处理、开源 摘要 研究问
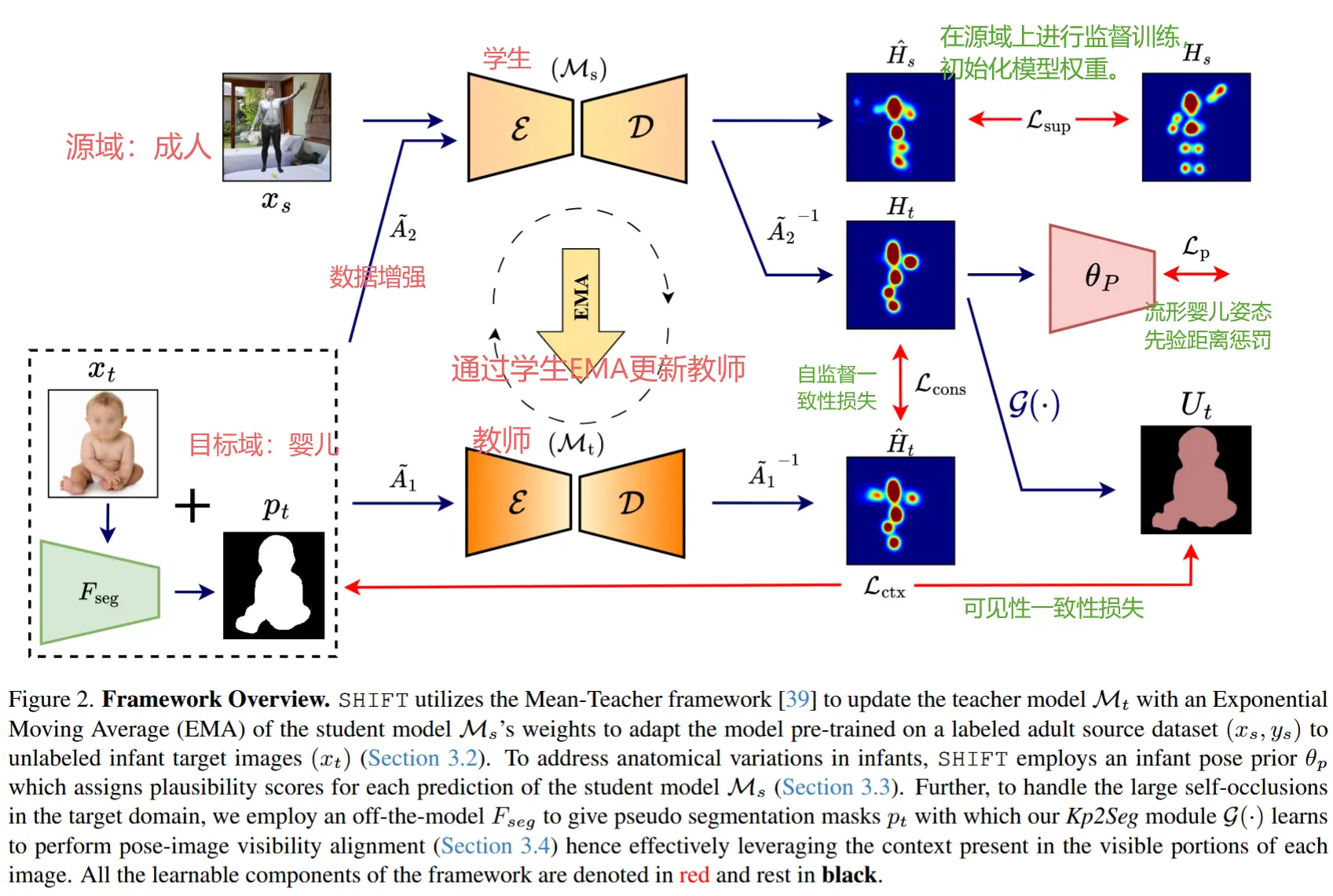
论文 - 《Leveraging Synthetic Adult Datasets for Unsupervised Infant Pose Estimation》 代码 - 给的链接失效了 关键词 - 婴儿动作识别、无监督域适应、均值教师模型、流形先验 摘要 研究问题 针对婴儿的姿态估计发展仍较为
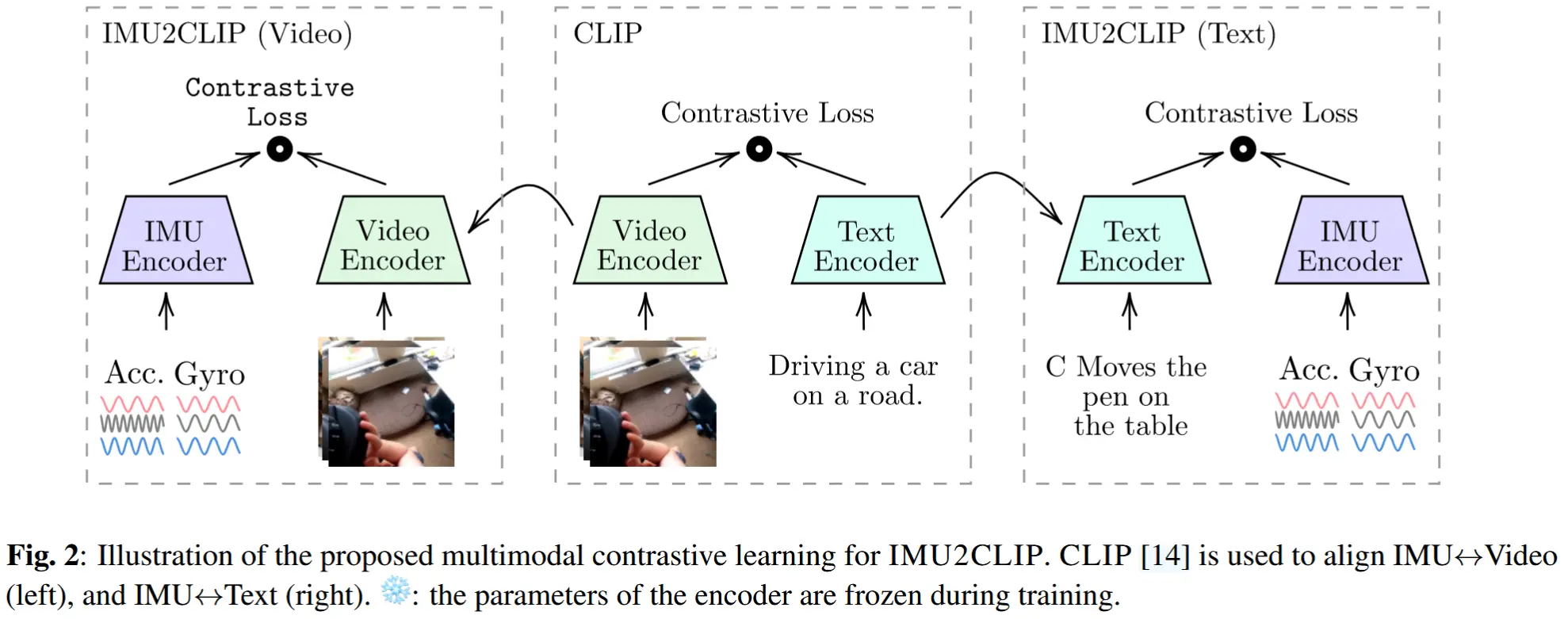
论文 - 《IMU2CLIP: Multimodal Contrastive Learning for IMU Motion Sensors from Egocentric Videos and Text》 代码 - Github 关键词 - Meta工作、多模态学习、IMU建模、对比学习、CLIP
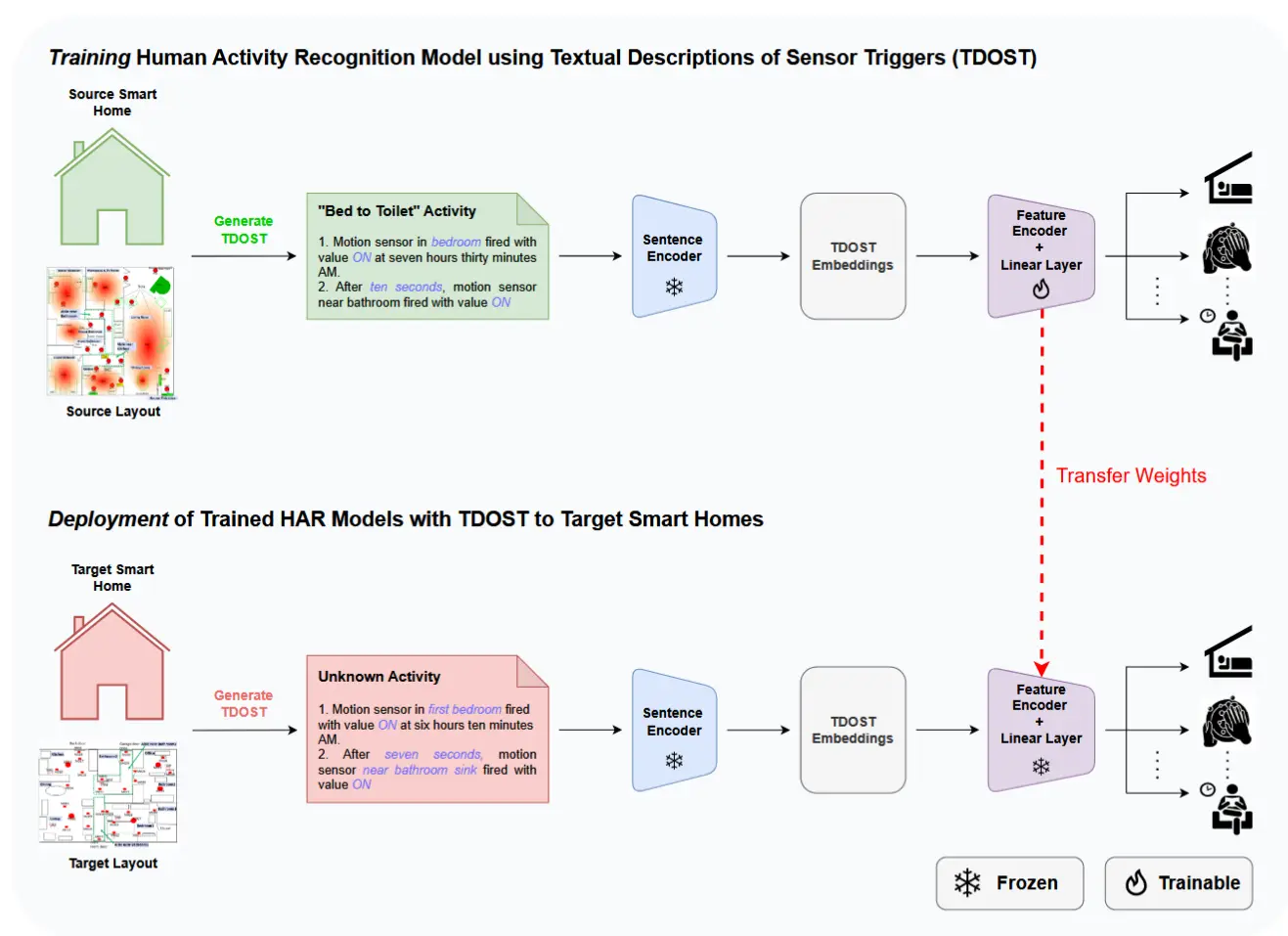
论文 - 《Layout-Agnostic Human Activity Recognition in Smart Homes through Textual Descriptions Of Sensor Triggers (TDOST)》 关键词 - Ubicomp2025、prompt工程、提示
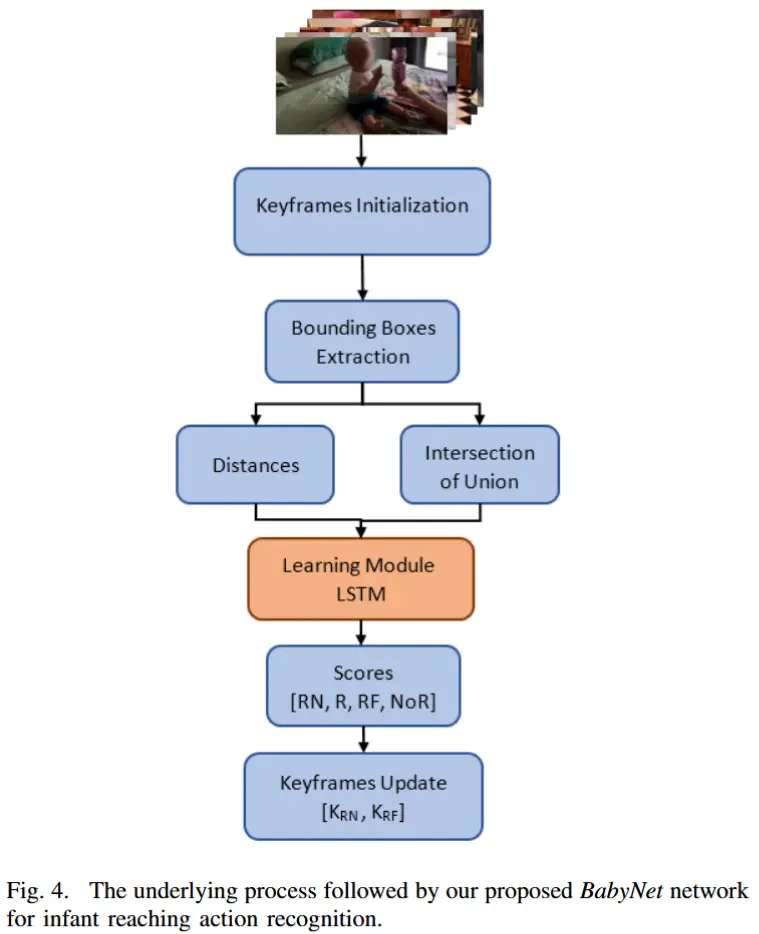
论文 - 《BabyNet: A Lightweight Network for Infant Reaching Action Recognition in Unconstrained Environments to Support Future Pediatric Rehabilitation A
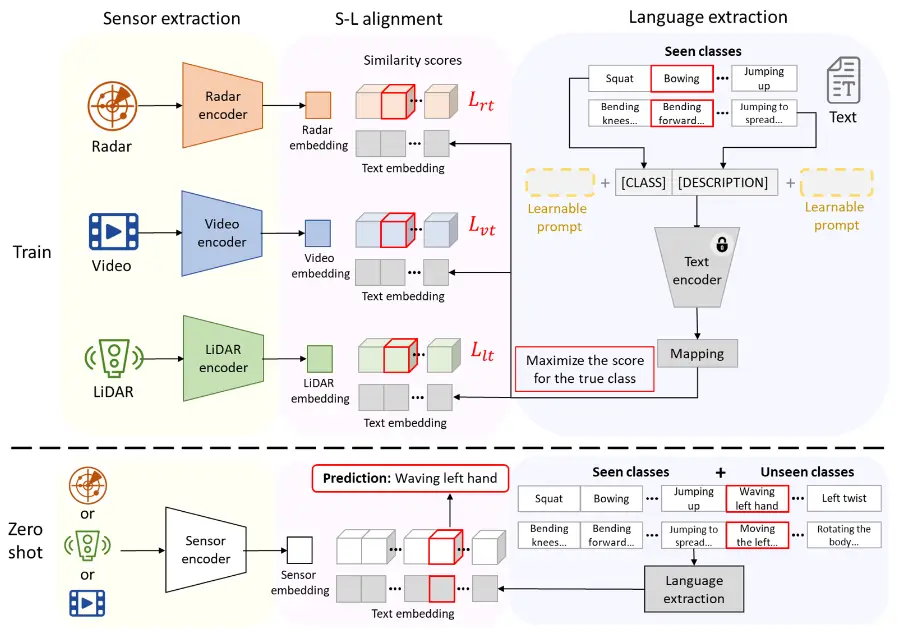
论文 - 《TENT: Connect Language Models with IoT Sensors for Zero-Shot Activity Recognition》 关键词 - 对比学习、人类活动识别HAR、多模态对齐、毫米波mmWave、LiDAR、图像 摘要 研究问题 语言模型是否能
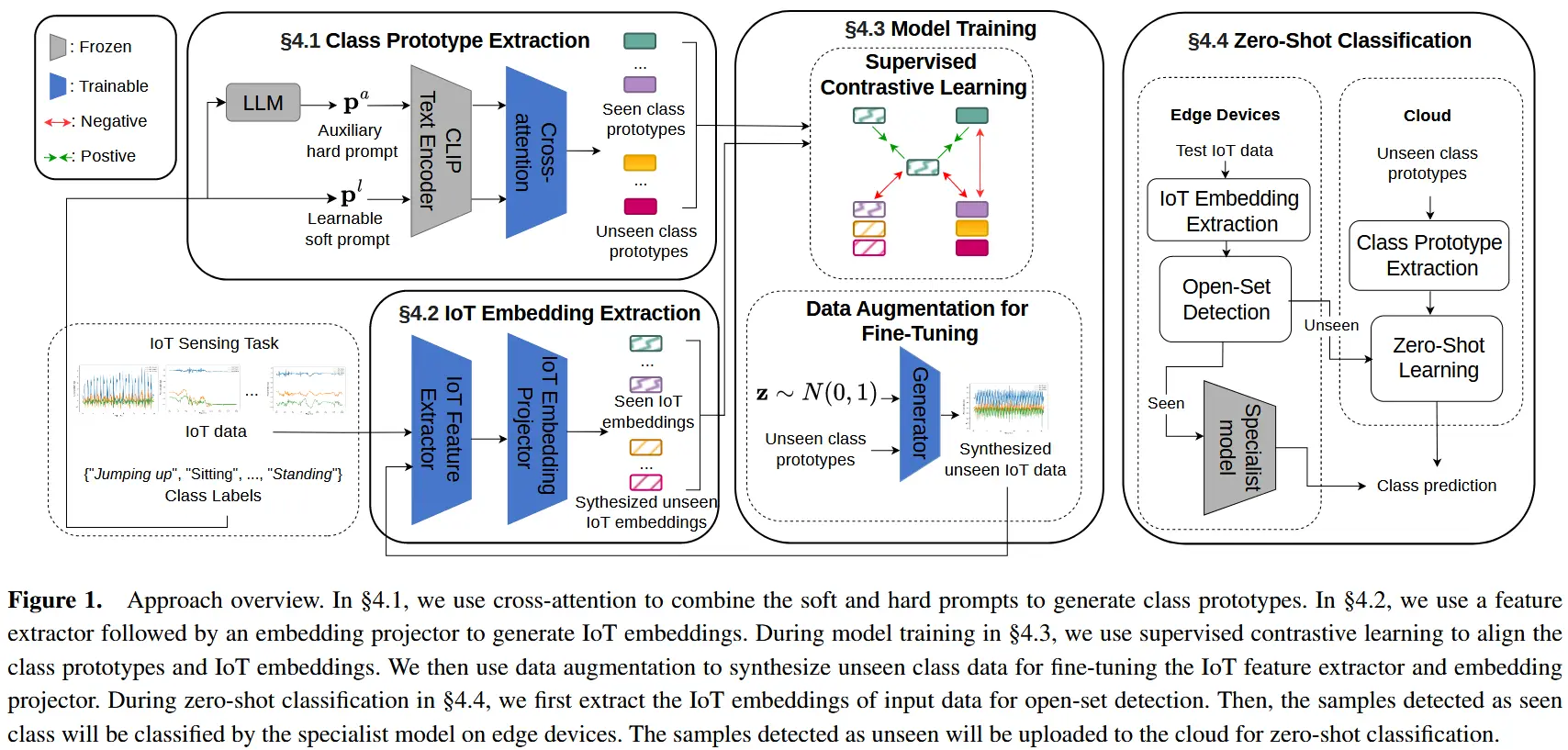
论文 - 《Leveraging Foundation Models for Zero-Shot IoT Sensing》 代码 - Github 关键词 - 零样本学习、IMU、人类活动识别HAR、大模型、WiFi、毫米波mmWave、对比学习 摘要 研究问题 边缘物联网IoT上的深度学习模型通常
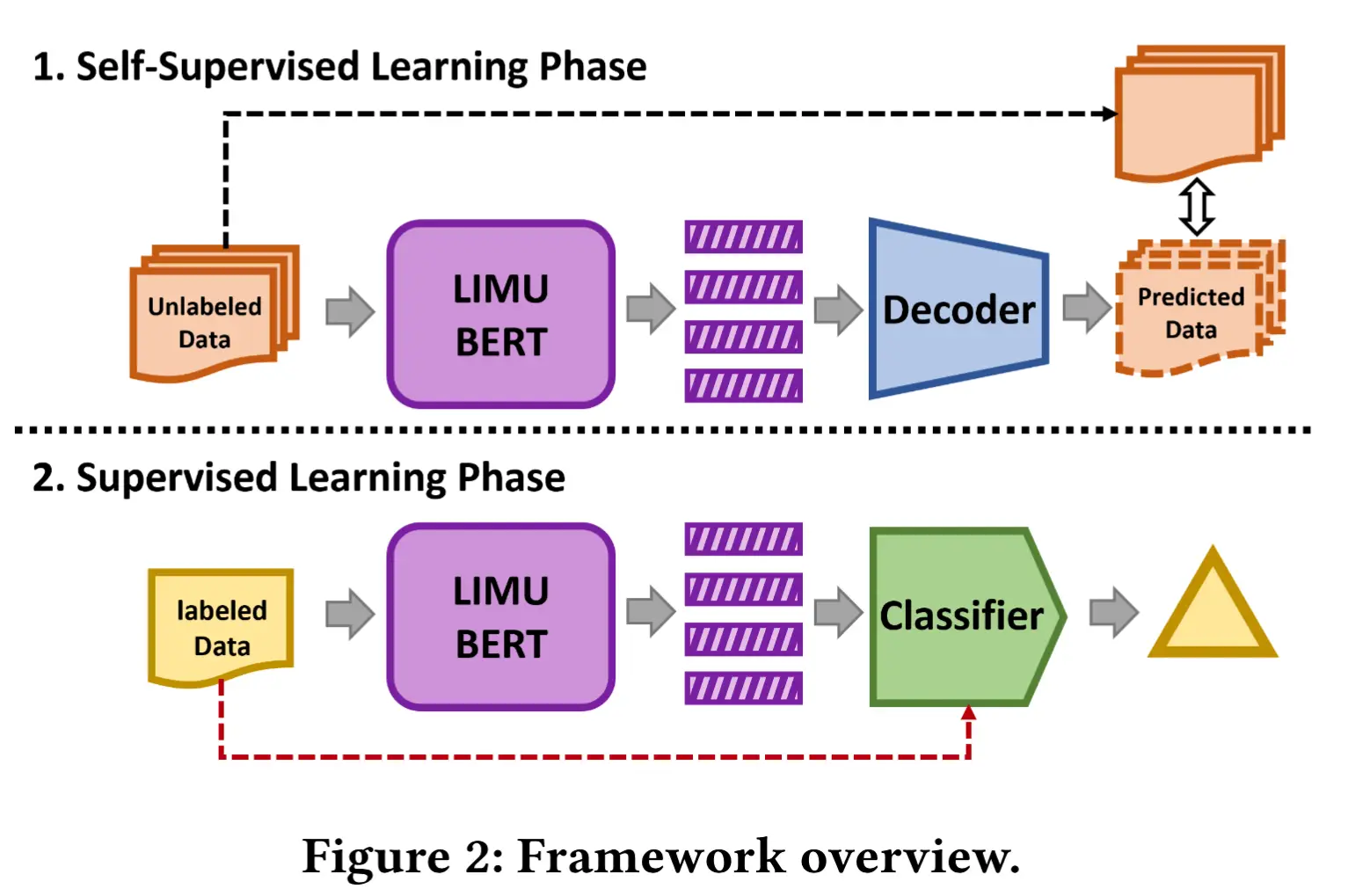
论文 - 《LIMU-BERT: Unleashing the Potential of Unlabeled Data for IMU Sensing Applications》 代码 - Github 关键词 - Sensys2021、IMU、HAR、自监督学习、训练、掩码、BERT、 摘要 研究
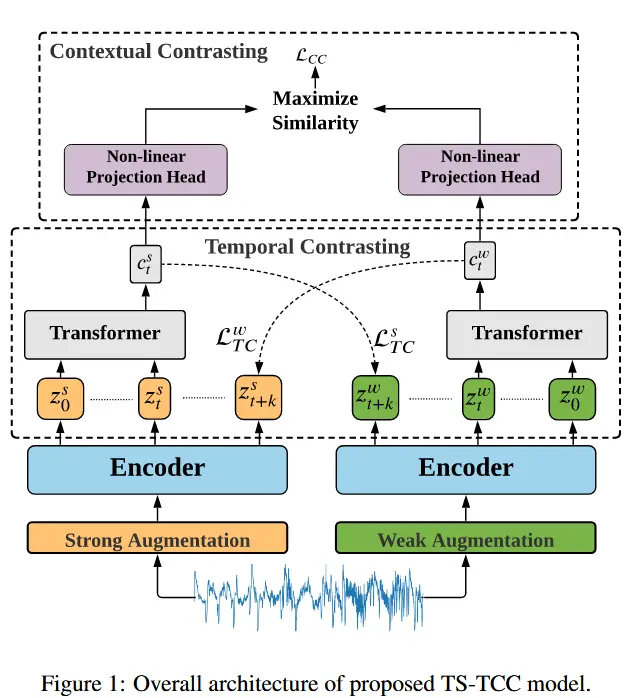
论文 - 《Time-Series Representation Learning via Temporal and Contextual Contrasting》 代码 - Github 关键词 - IJCAI-21、时序表征学习、对比学习、人体活动识别HAR、睡眠阶段检测、 1 引言 时间序列数
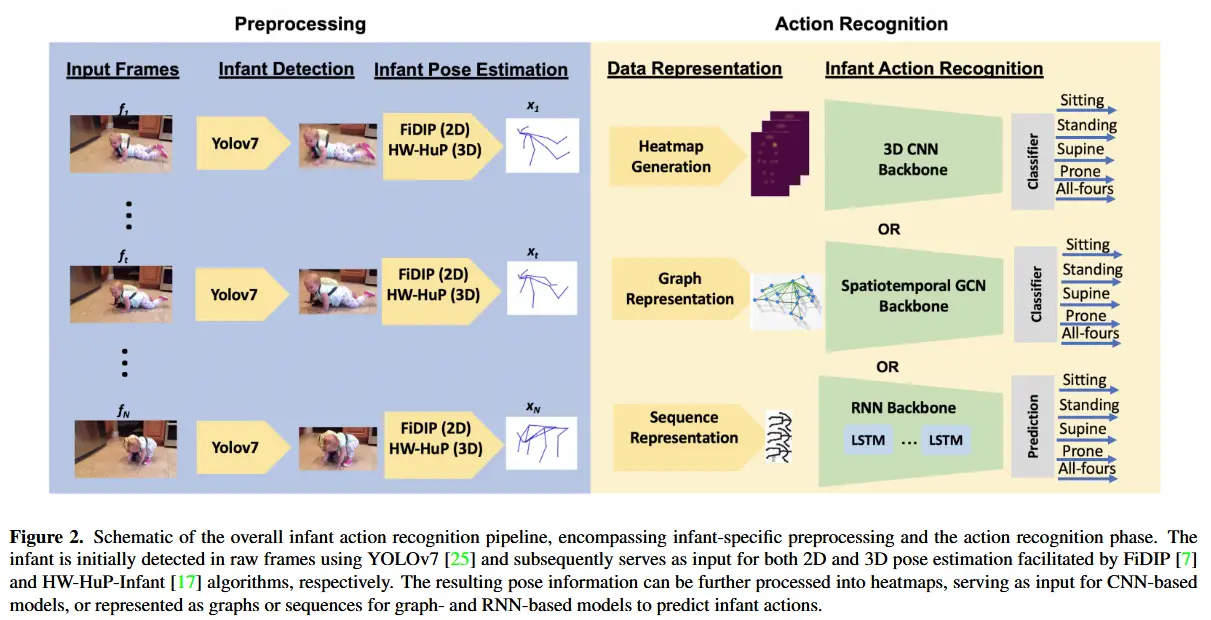
论文 - 《Challenges in Video-Based Infant Action Recognition: A Critical Examination of the State of the Art》 代码 - Github 关键词 - WACV、婴儿动作识别、综述、数据集贡献 摘要 研
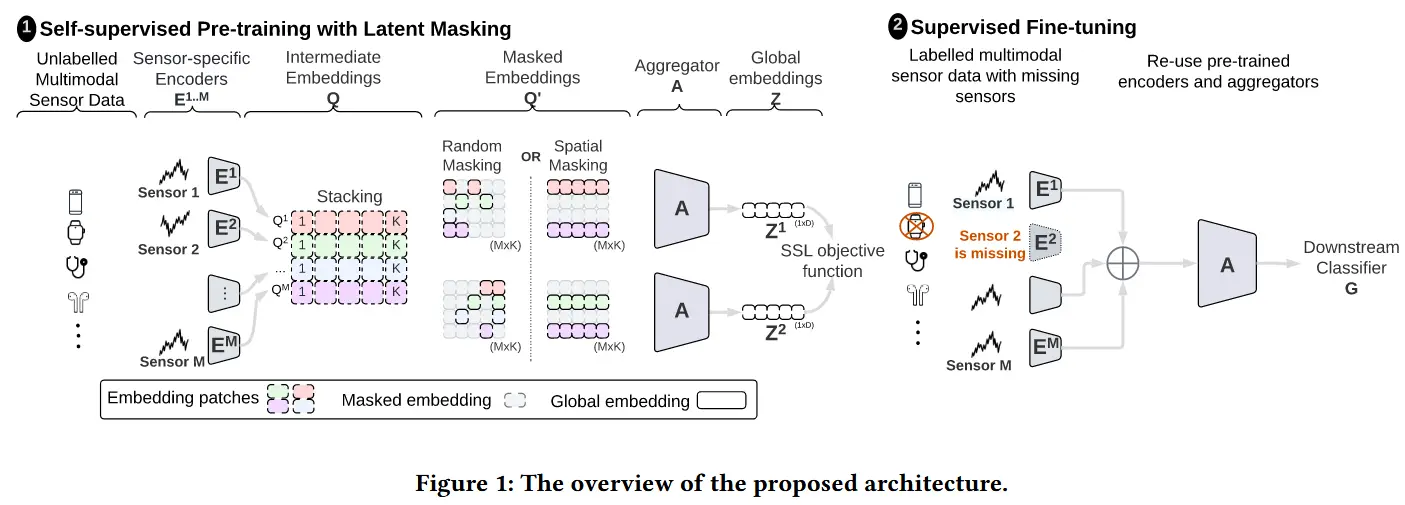
论文 - 《CroSSL: Cross-modal Self-Supervised Learning for Time-series through Latent Masking》 代码 - Github 关键词 - 自监督学习、时序关系、掩码、人类活动感知HAR 摘要 研究问题 多模态时间序列研究
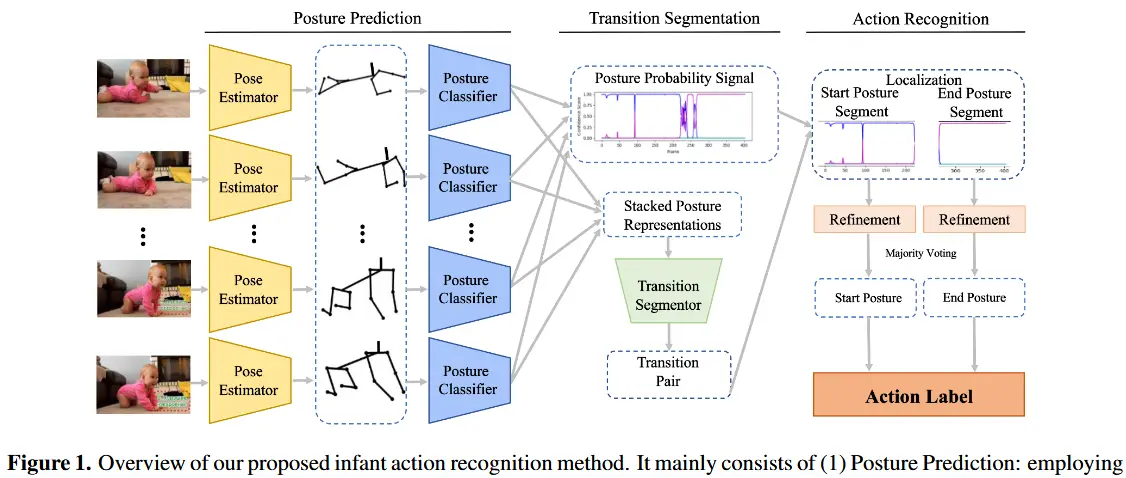
论文 - 《Posture-based Infant Action Recognition in the Wild with Very Limited Data》 代码 - Github 关键词 - 婴儿动作识别、姿态估计、数据集InfAct、视频模态 摘要 研究问题 自动检测婴儿的动作视频有助于在
论文 - 《IMAGEBIND: One Embedding Space To Bind Them All》 代码 - Github 关键词 - CVPR2023、多模态联合学习、无监督学习、模态对齐、大模型 摘要 本文贡献 (1)提出 ImageBind 方法,一种能够在六种不同模态之间学习联合嵌