- 论文 - 《Self-Distilled Masked Auto-Encoders are Efficient Video Anomaly Detectors》
- 代码 - Github
- 关键词 - 视频异常检测VAD、高效方法、掩码自编码器、重建、自蒸馏、教师-学生、合成数据
1 引言
-
动机:当前最先进的深度异常检测模型通常依赖代价高昂的目标检测方法来提高检测精度。
-
本文方法概述
- 提出了一种基于轻量级掩码自编码器(AE)的视频帧级异常事件检测模型。通过以下三个创新点提升检测性能:
- 引入了一种基于运动梯度的令牌加权方法,根据运动梯度的大小为每个 token 分配不同的权重,从而在重建损失中提升具有高运动特征的 token 的重要性。这使得模型更关注对高动态区域的重建,避免对通常静止的背景场景进行重建。。
- 在网络结构中集成了一个教师解码器和一个学生解码器,教师模型与学生模型共享同一个编码器,并利用两者输出之间的差异来提升异常检测的效果。
- 生成合成的异常事件以增强训练视频,并让掩码AE模型同时重建原始帧(无异常)和对应的像素级异常图。
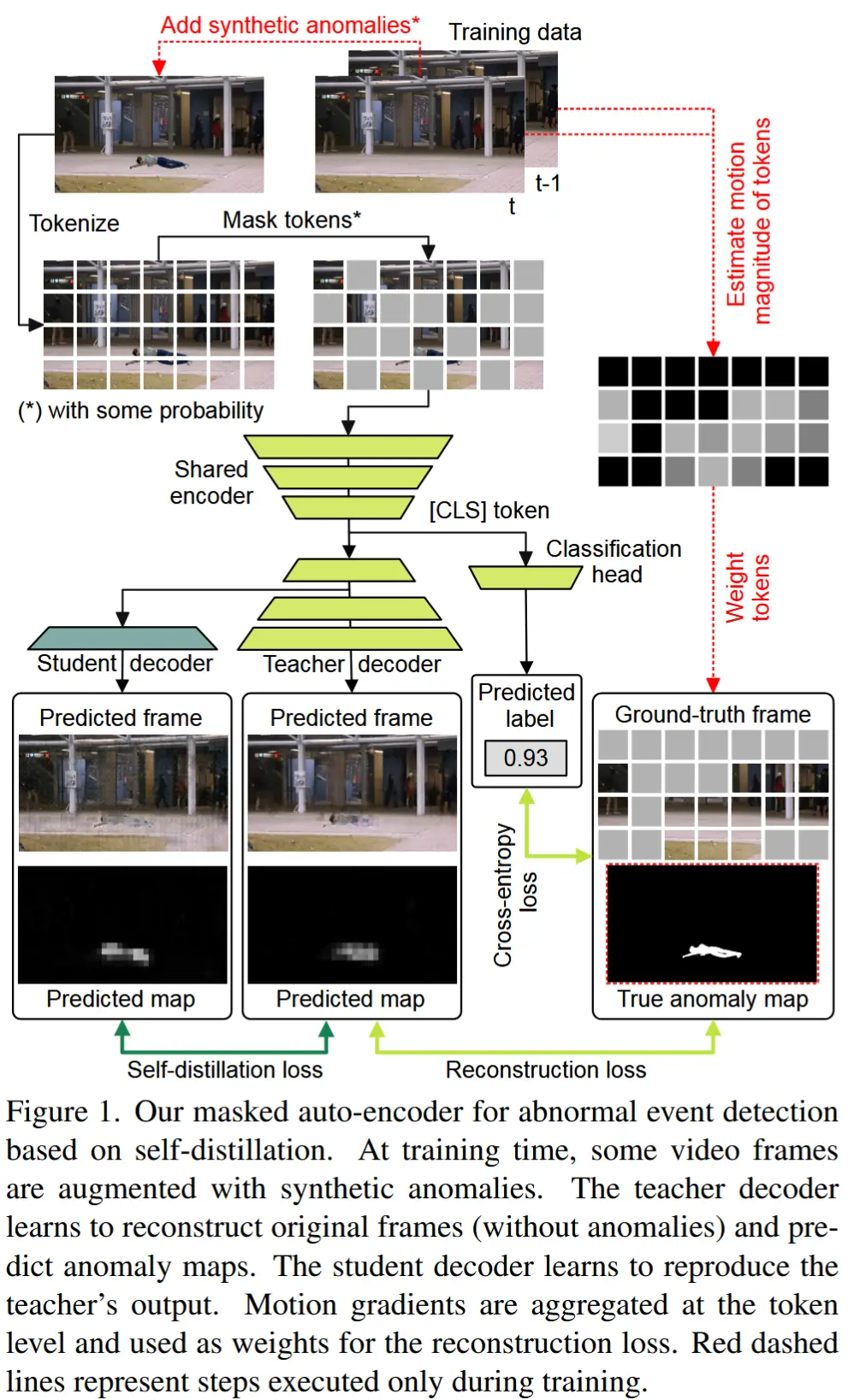
- 结构如图1所示。
- 提出了一种基于轻量级掩码自编码器(AE)的视频帧级异常事件检测模型。通过以下三个创新点提升检测性能:
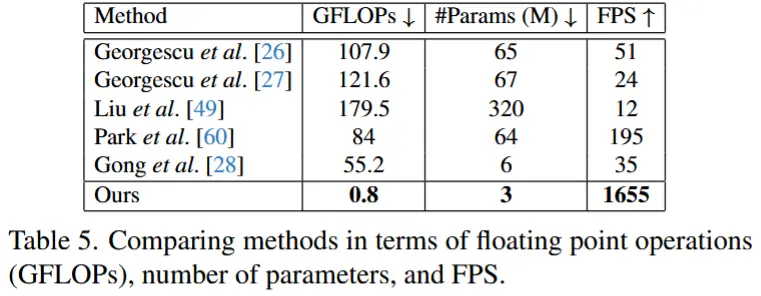
- 实验效果
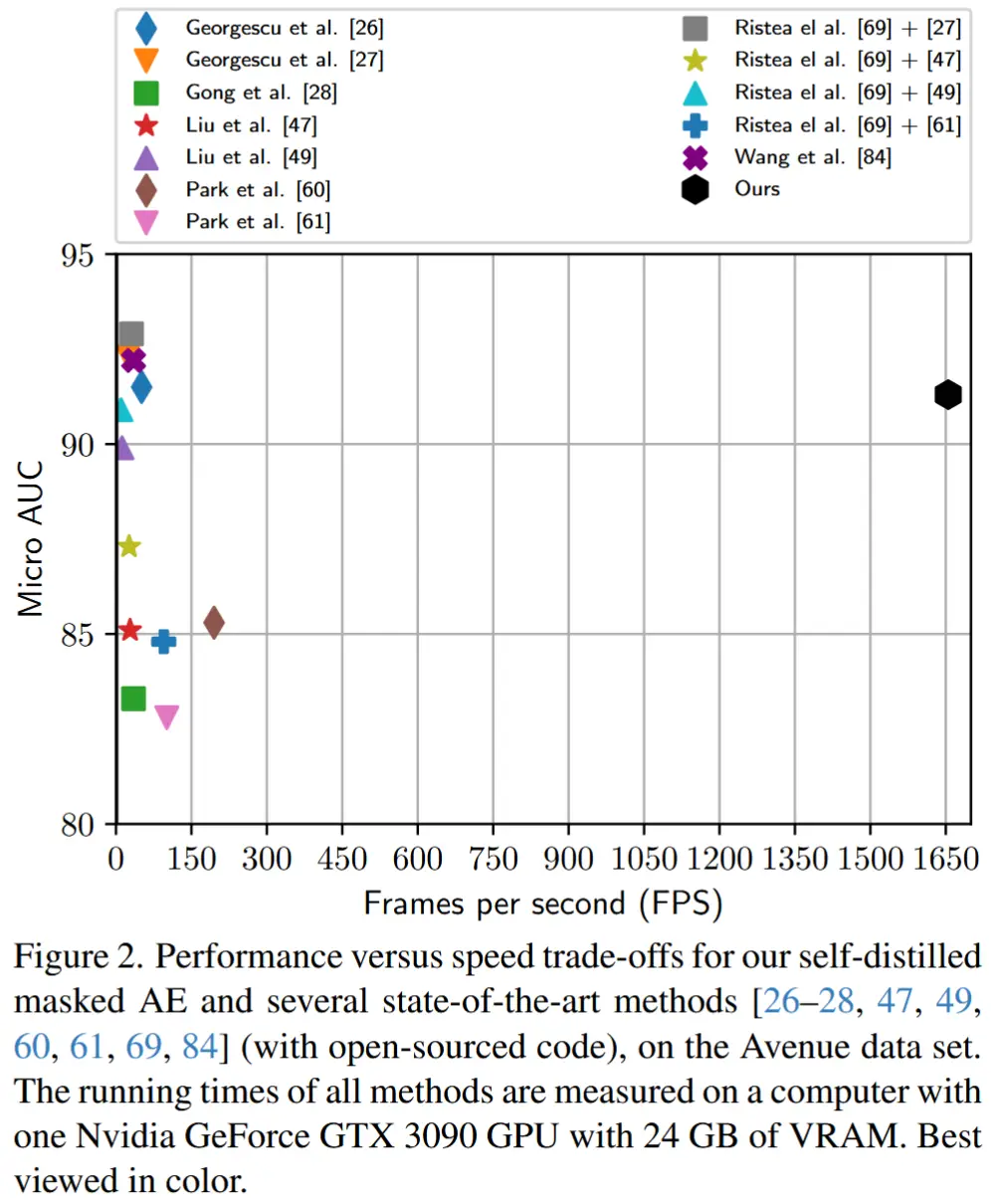
- 在保持竞争力的AUC分数的同时,处理速度达到了1655 FPS,因此比现有方法快了8到70倍。
- 注意,与现有方法在目标级别或时空立方体级别进行异常检测不同,本文提出的模型直接以整个视频帧作为输入,效率更高(参见图2)。
2 相关工作
- 按照异常检测方法所处的粒度,可以分为以下几类:
- spatio-temporal cube-level methods
- frame-level methods
- object-level methods
- Frame-level and cube-level methods
- Frame-level:将整张视频帧作为输入进行处理 [47, 66, 67]。
- spatiotemporal cube-level methods:将短视频序列划分为时空立方体[15, 21, 41, 51, 55, 75, 103]。这些立方体被视为独立的样本,并作为输入传递给机器学习模型。
- 共同特点:预处理步骤相对较快,整体处理速度高于 object-level 方法。
- 不同之处:时间上,frame-level 快于 cube-level;性能上,cube-level 优于 frame-level。
- Object-level Methods
- 这类以目标为中心的方法利用了目标检测器提供的先验信息,使异常检测器只需关注视频中的具体物体。这种框架显著提升了检测的准确性。
- 缺陷:整个系统的推理速度受限于目标检测器的速度,而目标检测器通常比异常检测网络慢得多。
- Masked Auto-Encoders in 异常检测
- 掩码自编码器被广泛应用于多个领域,例如视频处理 [24]、多模态学习 [7],以及医学图像 [34] 和工业图像 [39]的异常检测。
- 本文是首个提出基于掩码 Transformer 的自编码器用于视频异常检测的研究。
- Knowledge Distillation in 异常检测
- 大多数基于知识蒸馏的研究都将其应用于图像异常检测任务 [8, 12, 16, 74]。
- 少数几项工作将知识蒸馏用于视频异常检测 [26, 86]。
- 本文是首个在异常检测中引入自蒸馏(self-distillation)变体的研究。
3. 方法
概述
本文提出了一种基于轻量级教师-学生 Transformer 的掩码自编码器,整体框架如图1所示,并采用两阶段训练流程:
- 第一阶段,通过一种基于运动梯度的新权重机制设计的重建损失函数来优化教师掩码自编码器。
- 第二阶段,优化学生掩码自编码器的最后一个(也是唯一一个)解码器块。
网络架构
掩码自编码器参考 [30] 中的设计原则,不同的是,作者将原始的 ViT 块替换成 Convolutional vision Transformer [88],以追求更高的效率。
处理流程如下:
- 将输入图像划分为非重叠的 token;
- 随机移除一部分 token;
- 编码器通过卷积投影层嵌入剩余的 token;
- 这些 token 经过多个 Transformer 块进行处理;
- 解码器则作用于完整的 token 集合,其中被掩码的部分由“mask token”替代;
具体设计:编码器和解码器中各仅使用三个 Transformer 块(结构对称),每个块包含四个注意力头。为了进一步提高速度,将 CvT 块内的所有全连接层替换为逐点卷积(pointwise)。
教师和学生架构不同:共享编码器,但是教师解码器有三层,学生解码器则从教师解码器的第一个 Transformer 块之后分支出来,并仅含一个额外的 Transformer 块(如图1所示)。
Motion Gradient Weighting
动机:在异常检测中摄像头是固定的,背景往往是静态的。通过掩码自编码器学习重建静态背景既简单又无意义。为此,在计算重建损失时引入了运动梯度的幅度。
具体做法:
令 \boldsymbol{x}_t \in \mathbb{R}^{h \times w \times c} 表示索引为 t 的视频帧,将每帧 \boldsymbol{x}_t 划分为大小为 d \times d \times c 的非重叠视觉 token,其中 d 是一个超参数,直接决定了每帧中的 token 数量 n。令 \left\{\boldsymbol{p}_i^{(t)}\right\}_{i=1}^n \in \mathbb{R}^{d \times d \times c} 表示帧 \boldsymbol{x}_t 中的 token 集合,\left\{\hat{\boldsymbol{p}}_i^{(t)}\right\}_{i=1}^n 表示对应相同大小的重建 token 集合。
第一步:根据 [36],首先通过计算连续帧之间的绝对差值来估计帧 \boldsymbol{x}_t 的运动梯度图 \boldsymbol{g}_t,并在计算前使用 3 \times 3 median filter 去除噪声。
第二步:将 \boldsymbol{g}_t 划分为非重叠的 patch,得到梯度 patch 集合 \left\{\boldsymbol{\tau}_i^{(t)}\right\}_{i=1}^n \in \mathbb{R}^{d \times d \times c}。
第三步:在每个梯度 patch 内,计算每个通道的最大梯度幅度,然后计算所有通道的最大梯度幅度的均值,公式如下:
第四步:计算每个 token 的重建损失权重 w_i^{(t)},公式如下:
第五步:将上述权重 w_i^{(t)} 引入传统的 token 级重建损失中,引导掩码自编码器专注于重建具有高运动幅度的 patch。因此,加权均方误差损失定义为:
其中 \theta_T 是教师掩码自编码器的权重。
自蒸馏
动机:学生和教师模型都是在正常数据上训练的,对于正常样本应该相似,而异常样本不保证相似。因此,它们输出之间的差异度可以作为一种量化样本异常程度的手段。然而,两个模型导致速度减半,作者选择了自蒸馏,教师和学生共享编码器,同时学生仅添加一个额外的 Transformer 块。
两阶段训练过程:
- 第一阶段:通过公式 (3) 的损失函数训练教师模型。
- 第二阶段:冻结共享主干网络,并通过自蒸馏训练学生解码器。自蒸馏损失类似于公式 (3) ,但是学生模型学习重建由教师模型生成的 patch,而不是真实图像。令 \left\{\tilde{\boldsymbol{p}}_i^{(t)}\right\}_{i=1}^n \in \mathbb{R}^{d \times d \times c} 表示学生模型重建的 patch。自蒸馏损失可以表示为:
其中 \hat{\boldsymbol{x}}_t 是教师模型重建的帧,\theta_S 是学生解码器的权重。
合成异常
动机:自编码器(AEs)往往对分布外数据泛化得过于良好,这与异常检测需要的刚好相反。因此,作者提出通过为训练视频添加异常事件来增强训练数据。利用最近引入的 UBnormal 数据集 [1] 及其精确的像素级标注,裁剪出异常事件并将其融合到训练视频中,同时确保添加的事件在时间上保持一致性。
为什么是合成?因为异常训练样本难以在现实中收集。
合成异常的作用:
- 在重建损失中:将无异常的原始训练帧视为真实值,迫使模型忽略异常。即在公式 (3) 中,使用来自帧 \boldsymbol{x}_t 的正常版本中的 patch 集合 \left\{\boldsymbol{p}_i^{(t)}\right\}_{i=1}^n。
- 在目标图像中添加异常图:将异常图作为额外的通道添加到目标图像中。在异常图中正常像素为 0,异常像素为 1。这一变化意味着,在公式 (3) 和公式 (4) 中,所有 patch 都将包含一个额外的通道。
- 增强权重定义:使用真实异常图来增强公式 (2) 中定义的权重。在计算权重之前,将异常图与梯度图结合起来。形式上,在公式 (1) 中,将 \left\{\boldsymbol{\tau}_i^{(t)}\right\}_{i=1}^n 替换为 \left\{\boldsymbol{\tau}_i^{(t)} + \boldsymbol{a}_i^{(t)}\right\}_{i=1}^n,其中 \left\{\boldsymbol{a}_i^{(t)}\right\}_{i=1}^n 是从异常图中提取的 patch 集合。
分类头
进一步利用合成异常来训练一个分类头,该分类头应用于共享编码器的最终 [CLS] token 上。该分类头被训练以区分包含和不包含合成异常的帧。使用二元交叉熵损失训练:
其中 y_t \in \{0, 1\} 表示真实异常值;\hat{y}_t 是预测值;\theta_E 表示共享编码器的权重集合。
推理
在推理阶段,将每一帧 \boldsymbol{x}_t 分别通过教师模型和学生模型,分别得到重建后的帧 \hat{\boldsymbol{x}}_t 和 \tilde{\boldsymbol{x}}_t。然后,计算像素级异常图如下:
其中 \alpha、\beta 和 \gamma 是超参数。
接下来,遵循 [15, 35] 的方法,应用时空 3D 滤波器对异常体积进行平滑处理。为了获得帧级别的异常分数,从每个输出图 \boldsymbol{o}_t 中保留最大值,并随后应用另一个时间高斯滤波器对这些值进行平滑处理。
有点抽象,公式(6)的第一部分是教师模型重建质量,第二部分是学生模型重建质量,第三部分是分类头输出异常得分。如果图像异常,三个部分都应该值较大,得到较大的异常得分。
4 实验
4.1 实验设定
- 数据集:Avenue、ShanghaiTech、UBnormal、UCSD Ped2
- 评估指标
- micro AUC
- macro AUC
- 超参数省略
4.2 实验结果
- 下面展示在各个数据集的结果

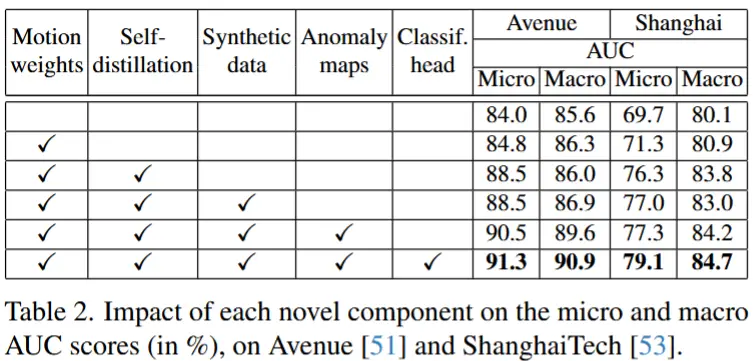
- 消融实验 - 各个组件
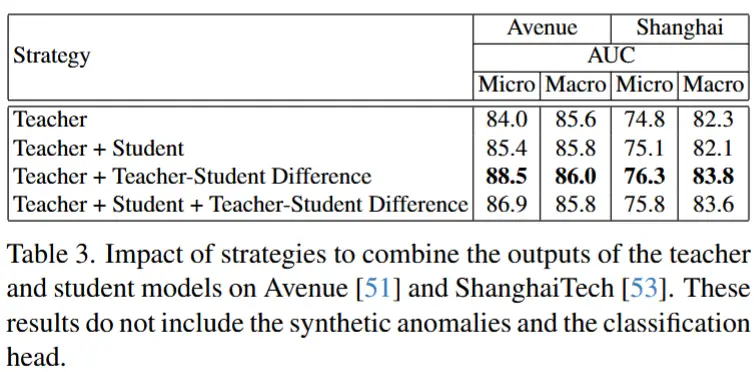
- 消融实验 - 自蒸馏的不同输出策略
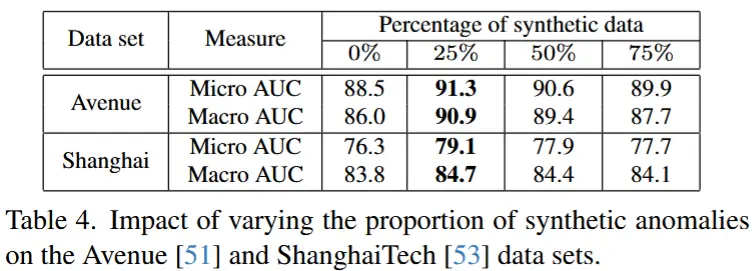
- 消融实验 - 改变合成异常比例
- 性能-速度权衡