- 论文 - 《VERA: Explainable Video Anomaly Detection via Verbalized Learning of Vision-Language Models》
- 代码 - Github
- 关键词 - Prompt工程、无需训练微调、视频异常检测VAD、视觉-语言大模型、可学习Prompt、语言学习
1 引言
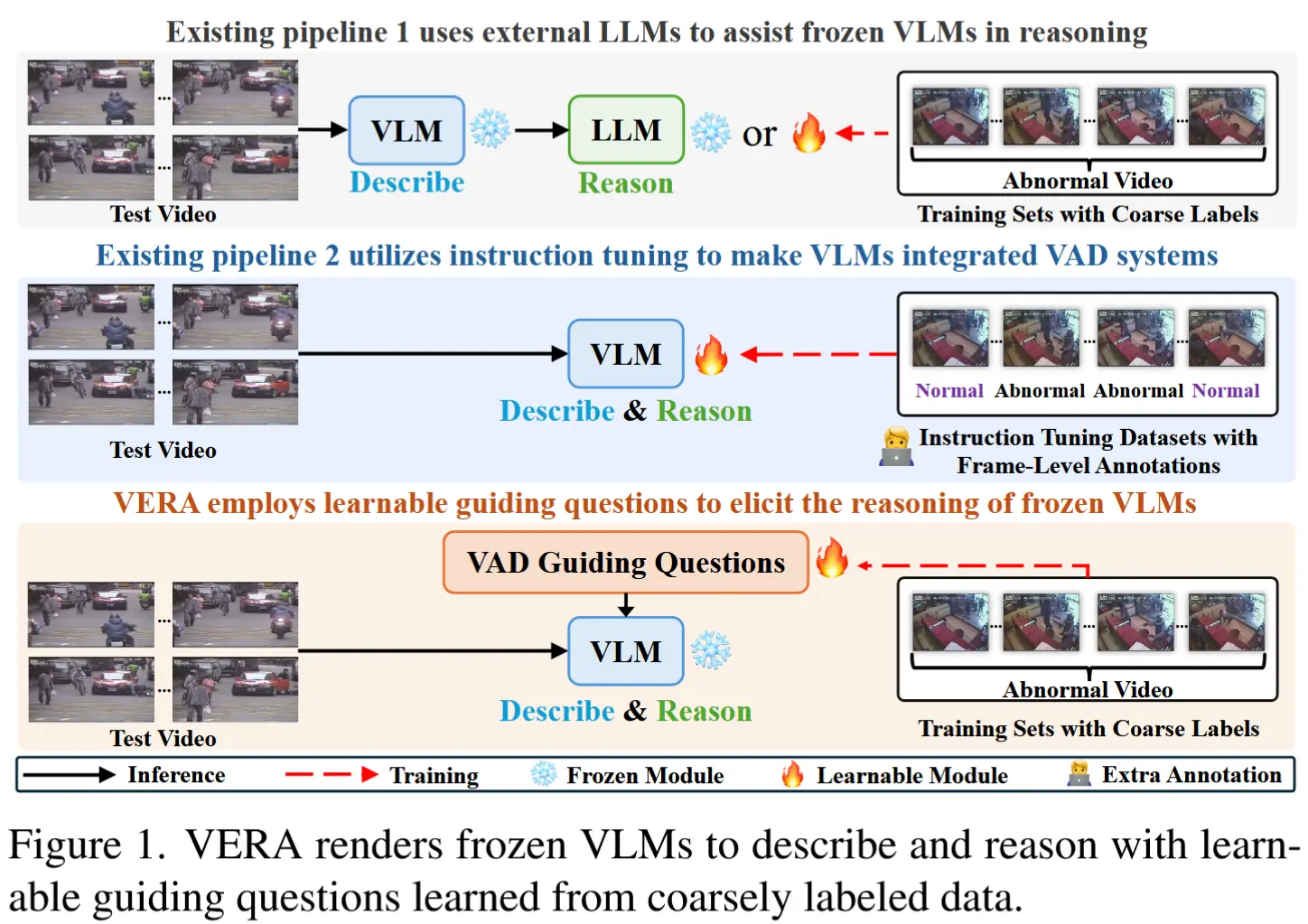
- 如图1,VLM for VAD 现有研究分类:
- 1)引入 LLM 来辅助冻结状态下的 VLM 进行 VAD 推理。首先使用VLM对给定视频内容生成描述,然后将这些描述传递给外部LLM,由其判断是否存在异常。
- 2)构建带有帧级标注的额外VAD数据集,并通过指令微调扩展VLM的能力,使其生成可解释的预测结果。
-
动机/现有工作局限
- 将 VAD 系统拆分为冻结的 VLM 和额外的 LLM,会导致推理过程中的额外负担,因为描述生成和推理过程被分离。
- 尽管指令微调使 VLM 能够有效地将描述与推理结合起来用于VAD任务,但它们需要人工标注并微调精细粒度的指令数据集,这不仅耗时,而且难以扩展到大规模数据集上。
-
提出问题:是否可以在不进行指令微调的前提下,让一个冻结的VLM实现对VAD任务中描述与推理的融合?
-
挑战:冻结状态下的VLM在视觉任务中的推理能力是有限的。
-
启发:逐步将异常描述从抽象细化为具体、细致的特征刻画,即用具体、明确的问题来引导VLM识别异常模式
-
解决办法 - VERA
- 引入了一个基于粗标注数据集的数据驱动学习任务,自动识别出适合当前冻结VLM的、包含具体异常特征的问题,从而避免了指令微调的需求。
- 具体而言
- 在训练阶段,VERA 将引导VLM进行推理的“问题”视为可学习参数,并根据优化者VLM对学习者VLM在中间VAD子任务(即每个训练视频的二分类判断)上的语言反馈来不断改进这些问题。
- 在推理阶段,考虑到视频帧数量庞大,VERA采用由粗到细的方式为每一帧分配精细的异常评分:
- 段级异常评分生成:使用已学习的引导性问题向VLM查询,生成每个视频片段的异常评分。
- 场景上下文融合:通过集成方法将场景上下文信息融入各个片段评分中,提升初始评分。
- 帧级评分输出:通过高斯平滑与帧位置加权融合时间上下文信息,最终输出每帧的异常评分。
2 相关工作
BERA 的设计受到“语言化机器学习”(Verbalized Machine Learning, VML)技术的影响。
VML 的核心思想:利用 LLMs 近似函数、学习执行特定任务的语言规则和描述方式,将传统的机器学习任务转化为基于语言的学习任务。
VML 的范式:将定义分类规则和其他任务相关标准的语言表达视为可学习参数,并通过由LLM或VLM建模的“学习者”和“优化者”之间的交互,以数据驱动的方式对其进行优化。
3 VERA 框架
3.1 VERA 中的训练
- 训练目标
目标:学习一组引导性问题,将一个复杂且模糊的概念分解为一组可识别的异常模式,从而在冻结状态的VLM中解锁其在 VAD 任务中的推理能力。
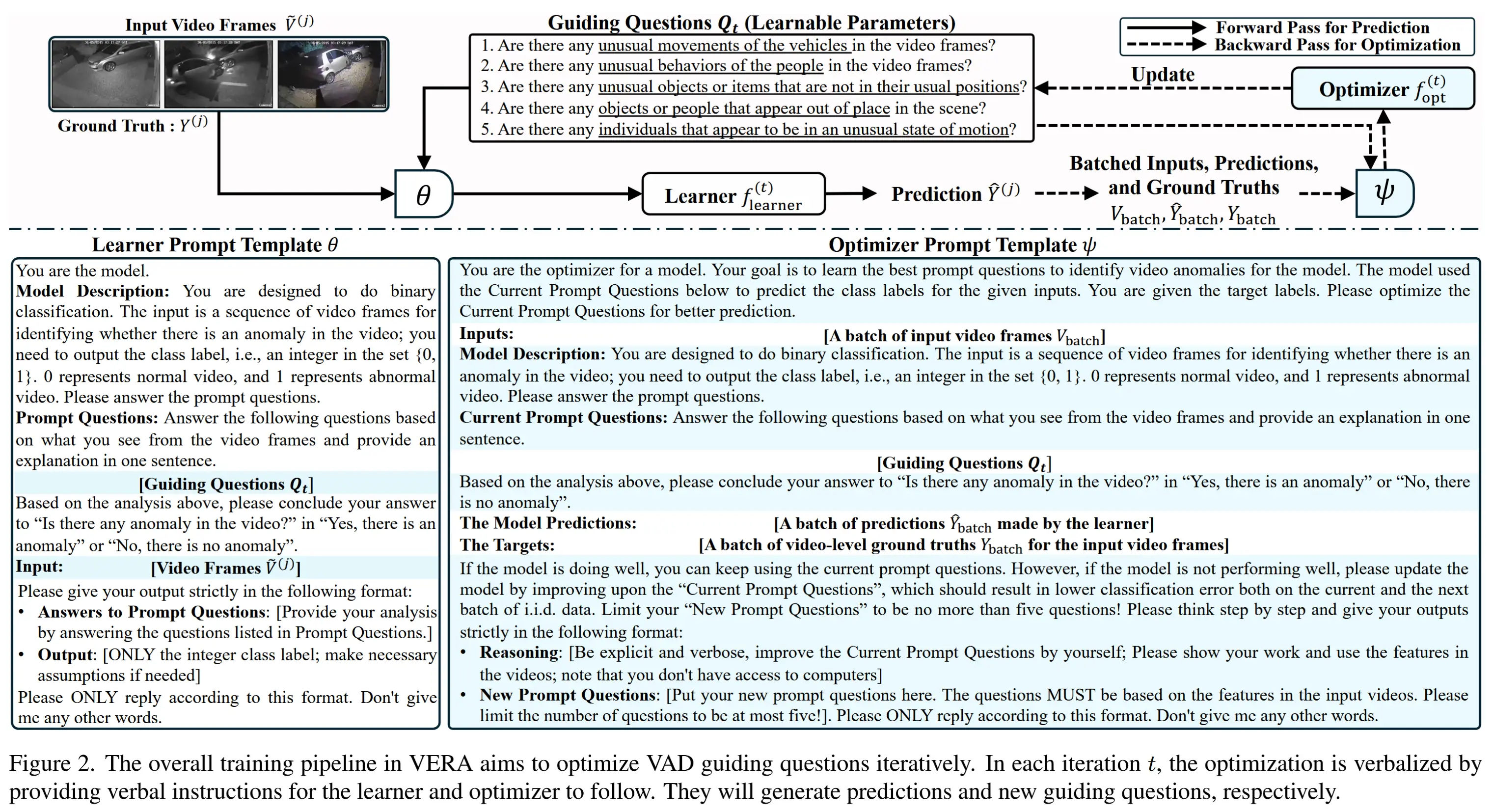
方法:提出了一种通用的语言化学习框架,如图2所示,用于生成所需的引导性问题。
将引导性问题集合表示为 \mathbf{Q} = \{q_1, \dots, q_m\} ,其中 q_i 表示第 i 个问题( 1 \leq i \leq m ), m 是问题的数量。训练框架将 \mathbf{Q} 视为可学习参数,并通过学习者和优化器之间的语言交互对其进行优化。
- 训练数据
学习 \mathbf{Q} 的训练数据由成对采样的视频帧和视频级标签组成。由于视频帧的数量庞大,使用均匀采样。具体而言,对于任何视频 V^{(j)} \in \mathcal{D} ,首先计算采样帧之间的间隔 l = \text{floor}(F_j / S) ,其中 S 表示采样帧的数量,\text{floor} 表示向下取整。均匀采样的帧表示为 \widetilde{V}^{(j)} = [I_1^{(j)}, I_{l+1}^{(j)}, \dots, I_{(S-1)\cdot l + 1}^{(j)}] 。训练时使用的标签仅为 Y^{(j)} ,从而得到VERA的训练数据对 \{(\widetilde{V}^{(j)}, Y^{(j)})\}_{j=1}^N 。
- 通过学习者和优化器更新 \mathbf{Q}
语言化机器学习(Verbalized Machine Learning, VML)的思想:通过学习者代理 f_{\text{learner}} 和优化器代理 f_{\text{opt}} 之间的语言交互来优化基于语言的参数,而不是使用数值优化算法(如Adam)。
以完整算法的一个任意迭代 t 为例进行阐述:
如图2所示,在每次迭代 t 中,学习者代理 f_{\text{learner}}^{(t)} 由冻结状态的VLM f_{\text{VLM}}(\cdot) 建模,并使用提示模板 \theta 和当前的引导性问题 \mathbf{Q}_t 引导其执行学习任务。优化器代理 f_{\text{opt}}^{(t)} 同样基于冻结状态的VLM f_{\text{VLM}} ,但使用不同的提示模板 \psi 来评估学习者的预测质量并优化 \mathbf{Q}_t 。
具体而言:
- 学习者代理表示为 f_{\text{learner}}^{(t)}(x) = f_{\text{VLM}}(x; (\theta, \mathbf{Q}_t)) ,其中 x 是输入, \mathbf{Q}_t 是可学习的引导性问题。
- 优化器代理表示为 f_{\text{opt}}^{(t)}(z) = f_{\text{VLM}}(z; (\psi, \mathbf{Q}_t)) ,其中 z 是输入, \psi 是用于改进 \mathbf{Q}_t 的指令。
需要注意的是,尽管两者都基于相同的VLM,但学习者和优化器遵循不同的提示模板( \theta 和 \psi ),因此它们的功能不同:学习者负责执行学习任务,而优化器负责优化引导性问题 \mathbf{Q}_t 。
- f_{\text{learner}} 的学习任务
f_{\text{learner}} 执行“前向传播”并输出预测结果。需要注意的是,在训练时仅使用原始的粗粒度标注信息。因此, f_{\text{learner}} 执行一个二分类任务。在这个任务中, f_{\text{learner}} 的工作是基于采样帧 \widetilde{V}^{(j)} ,生成一个二分类预测 \hat{Y}^{(j)} ,以判断视频中是否存在异常。如图2所示,在提示模板 \theta 的“模型描述”部分用自然语言解释了任务,并将引导性问题 \mathbf{Q}_t 插入到 \theta 的“Prompt Questions”部分。给定 \theta 和采样帧集合 \widetilde{V}^{(j)} ,f_{\text{learner}} 将输出预测结果:
- f_{\text{opt}} 的优化步骤
优化器执行“反向传播”并通过小批量更新问题 \mathbf{Q}_t 。假设 Batch 中的视觉输入为 V_{\text{batch}} ,对应的 GT 标签为 Y_{\text{batch}} 。学习者根据当前的 \mathbf{Q}_t 生成预测结果 \hat{Y}_{\text{batch}},如公式 (1) 所示。优化器将通过阅读提示 \psi 并结合批量数据,输出一组新的问题 \mathbf{Q}_{t+1} 。我们将优化步骤表示为:
其中, \mathbf{Q}_{t+1} 是从 f_{\text{opt}}^{(t)} 构造的一组新引导性问题,这是由于 f_{\text{opt}}^{(t)} 在读取 \psi 后具备文本生成和遵循指令的能力。
3.2 VERA 中的推理
在训练过程中,得到了验证准确率最高的参数集表示为 \mathbf{Q}^* 。在推理阶段,给定 \mathbf{Q}^* ,VERA 通过图3所示的“由粗到细”过程为测试视频 V 输出细粒度异常评分 \hat{Y} 。
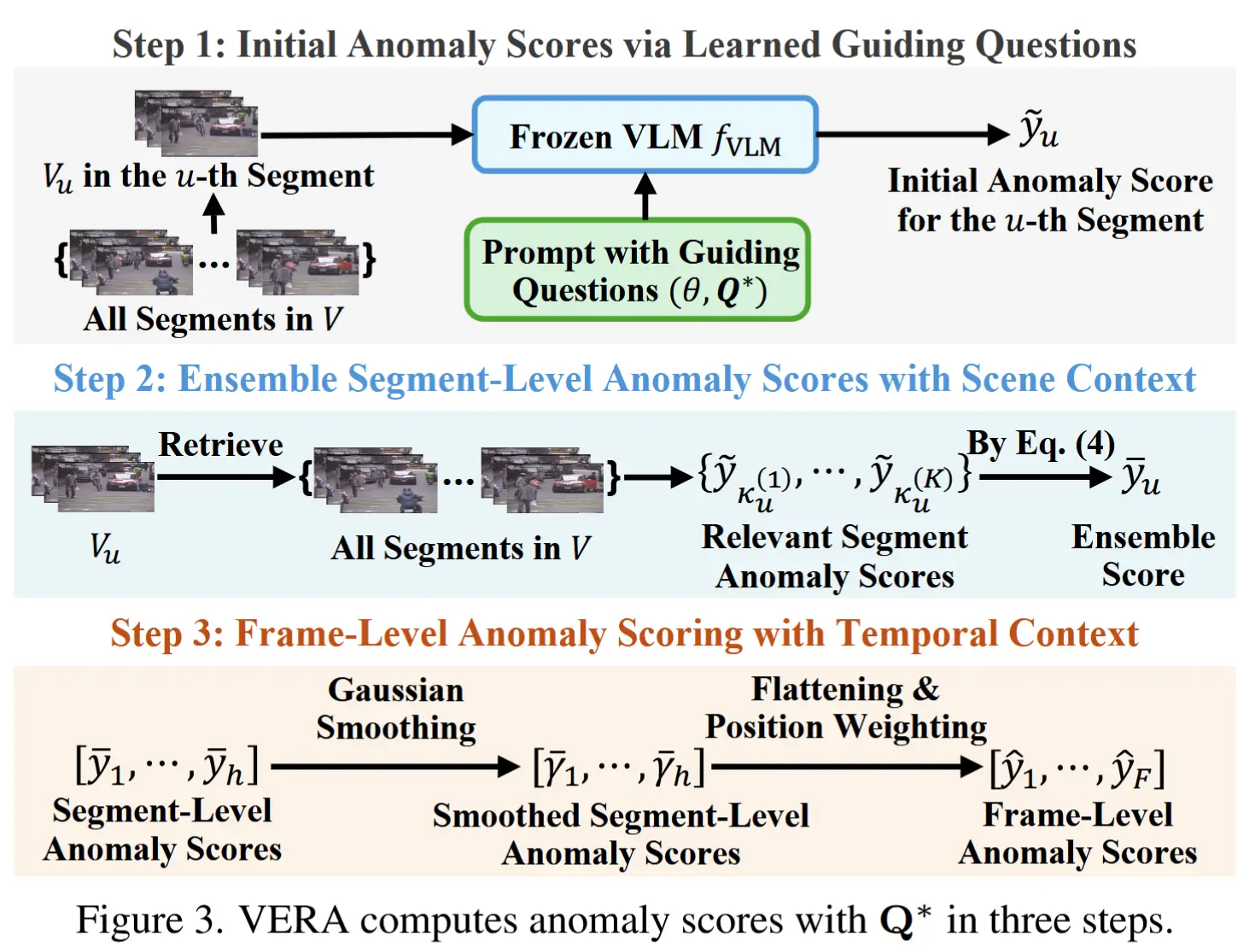
步骤1:通过学习到的引导性问题生成初始异常评分
首先,将视频划分为多个片段,并独立分析每个片段。对于单个片段,进行等距帧采样,得到片段中心集合 \mathcal{C} = \{I_1, I_{d+1}, \dots, I_{(h-1)\cdot d + 1}\} ,其中 d 是中心间隔。对于每个中心帧 I_{(u-1)\cdot d + 1} ( 1 \leq u \leq h ),我们定义其周围的一个10秒窗口为第 u 个片段,并在该窗口内均匀采样8帧,记为 V_u 。然后输入冻结的 VLM获取初始评分:
其中,若推理后认为片段包含异常,则 \tilde{y}_u = 1 ;否则 \tilde{y}_u = 0 。重复公式 (3) 对所有片段计算,得到片段级初始异常评分集合 \widetilde{Y} = [\tilde{y}_1, \dots, \tilde{y}_h] 。
步骤2:融合片段级异常评分与场景上下文
需要注意的是,步骤1的评分仅检查了长视频中的短暂时刻,而未考虑任何上下文信息。因此,步骤2引入场景上下文来细化初始片段级评分,场景上下文被定义为包含与当前片段相似元素(如演员和背景)的前序和后续片段。
具体步骤如下:
-
使用预训练的视觉特征提取器 g (例如ImageBind [10])提取视频片段的特征表示,并通过余弦相似度计算片段之间的相关性:
\text{sim}(u, w) = \cos\left(\frac{e_u \cdot e_w}{\|e_u\| \cdot \|e_w\|}\right)其中 e_u = g(V_u) 和 e_w = g(V_w) 分别为片段的特征表示。
-
令 \kappa_u = [\kappa_u^{(1)}, \dots, \kappa_u^{(K)}] 表示与 V_u 最相似的前 K 个片段的索引。
-
使用加权集成的方式细化异常评分:
\bar{y}_u = \sum_{i=1}^K \tilde{y}_{\kappa_u^{(i)}} \cdot \frac{\exp(\text{sim}(u, \kappa_u^{(i)}) / \tau)}{\sum_{j=1}^K \exp(\text{sim}(u, \kappa_u^{(j)}) / \tau)}, \tag{4}其中, \bar{y}_u 是与 V_u 相关的前 K 个片段的初始评分的加权集成。
-
通过公式 (4) 对所有片段进行计算,最终得到 \bar{Y} = [\bar{y}_1, \dots, \bar{y}_h] 。
步骤3:融合时间上下文的帧级异常评分
给定 \bar{Y} ,为了在计算帧级异常评分时融入时间上下文,首先通过高斯平滑对片段级评分进行处理,然后通过位置加权整合全局时间上下文。具体步骤如下:
-
高斯平滑:
- 使用高斯核 G(p) = \exp\left(-\frac{p^2}{2\sigma_1^2}\right) 对 \bar{Y} 进行卷积,得到更新后的片段级评分 \overline{\Gamma} = \overline{Y}*G = [\overline{\gamma}_1, \dots, \overline{\gamma}_h] 。
-
位置加权与全局时间上下文整合:
-
将 \overline{\Gamma} 展平为帧级评分序列 [\rho_1, \dots, \rho_F] 。
-
使用高斯函数编码位置权重:
w(i) = \exp\left(\frac{-(i - c)^2}{2\sigma_2^2}\right),其中 i 是帧索引, c = \text{floor}(F/2) 是中心帧索引, \sigma_2 是方差。
-
计算最终帧级异常评分:
\hat{y}_i = w(i) \cdot \rho_i. \tag{5}
-
-
效果:
- 该方法通过位置权重缩放评分,降低事件开始和结束附近帧的异常评分,从而更好地捕捉异常的时间进程。
- 最终的帧级异常评分表示为 \hat{Y} = [\hat{y}_1, \dots, \hat{y}_F] 。
VERA 的可解释 VAD
当使用嵌入了 \mathbf{Q}^* 的模板 \theta 来计算 \hat{Y} 时,要求VLM在推理过程中“用一句话提供解释”。VLM 将基于 \mathbf{Q}^* 解释其分配的异常评分。
4 实验
4.1 实验设定
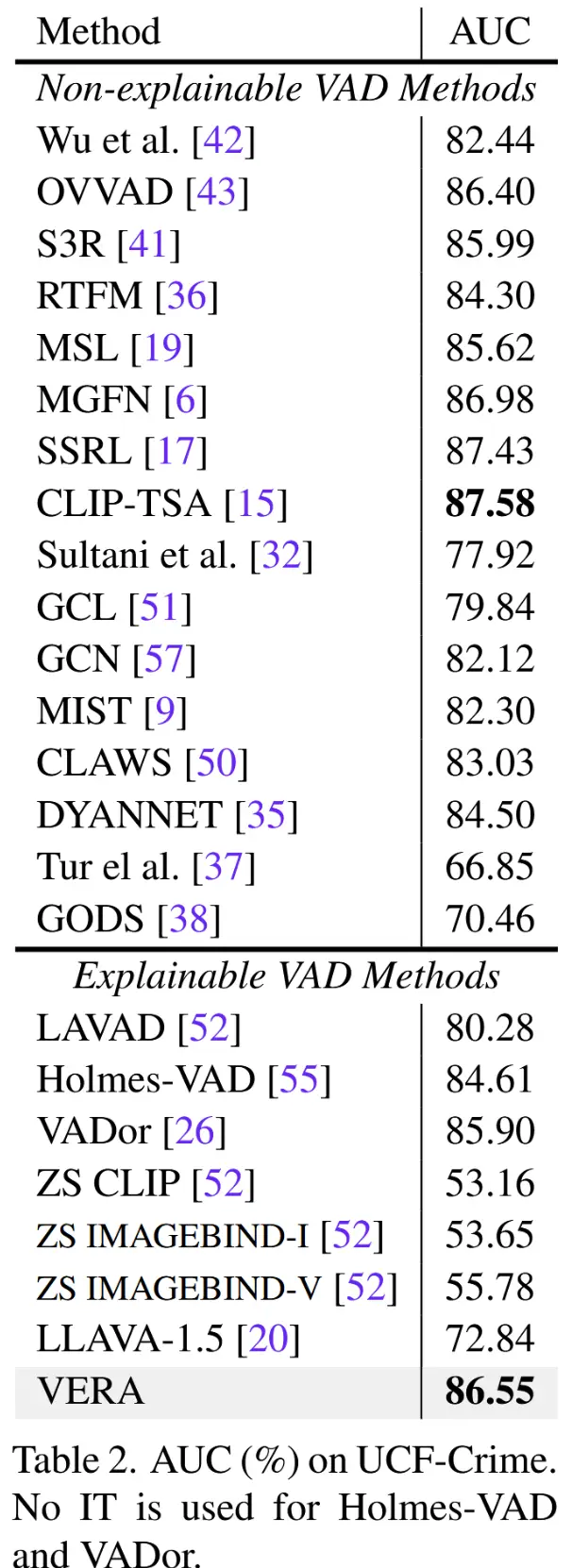
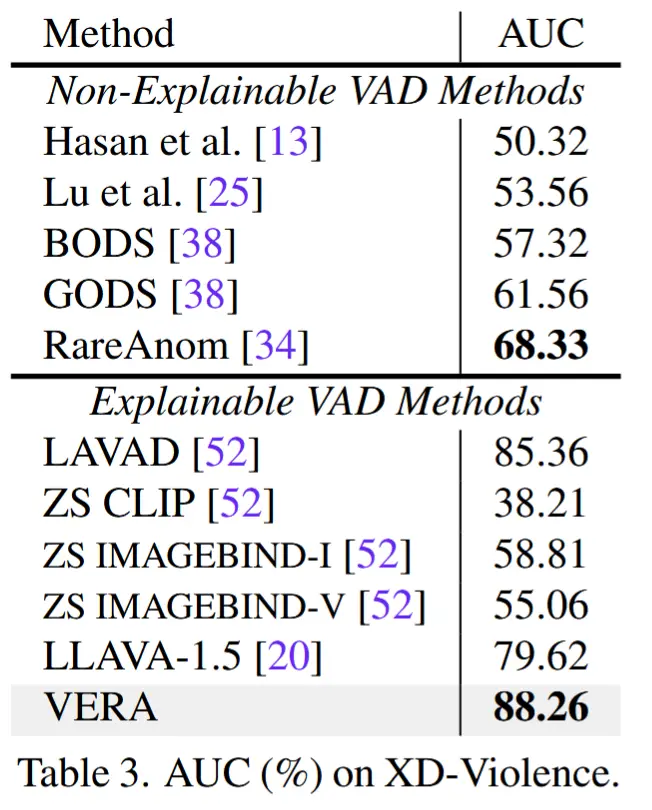
- 数据集:UCF-Crime 和 XD-Violence
- 评估指标:ROC AUC
- 基线方法:选择了非常多不可解释和可解释方法。
- 实现细节
- VLM:InternVL2-8B
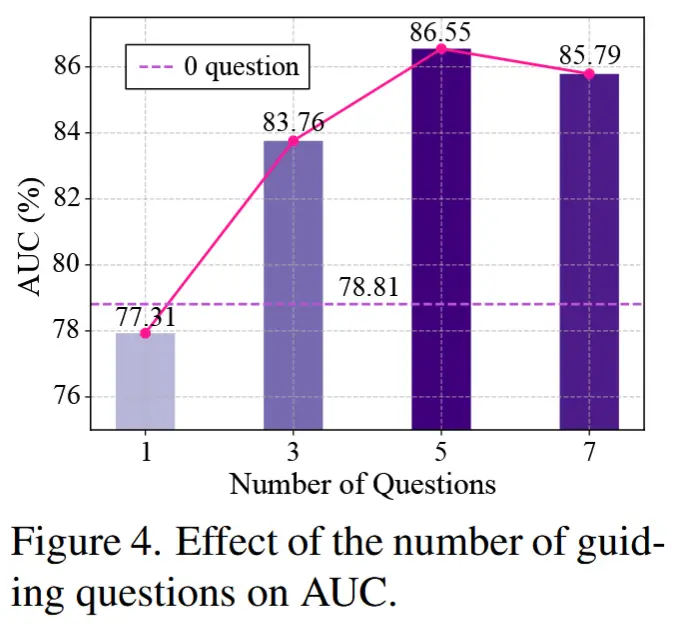
- 训练引导性问题 \mathbf{Q} 最多不超过10轮。
- 初始问题 \mathbf{Q}_0 为:“1. Is there any suspicious person or object that looks unusual in this scene?2. Is there any behavior that looks unusual in this scene?”[13, 43]
4.2 实验结果
- 与SOTA对比
- 两个数据集上的结果分别对应表2和表3。
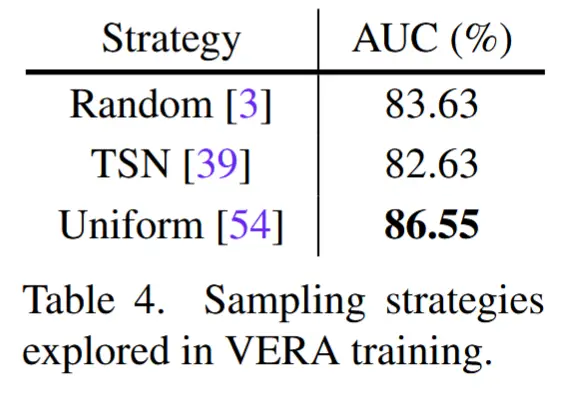
- 训练中的帧采样策略
- 三种获取每个 \widetilde{V}^{(j)} 的帧采样策略:均匀采样、随机采样 和 TSN采样(从等分的片段中随机采样)。
- 如何获得 VLM 的指导性问题 \mathbf{Q}
- 考虑几种变体:
- 不将引导性问题嵌入到VLM提示中
- 仅使用手动编写的问题(即初始问题 \mathbf{Q}_0 )
- 在优化器中仅输入预测结果和真实标签,而不输入视频帧 V_{\text{batch}}
- 本体 VERA
- 考虑几种变体:

- 问题数量 m 的影响