- 论文 - 《AssistPDA: An Online Video Surveillance Assistant for Video Anomaly Prediction, Detection, and Analysis》
- 代码 - 预计开源
- 关键词 - 实时、视频异常检测VAD、新数据集、Qwen-VL、实时问答
1 引言
- 动机:现有方法都是在离线环境下运行的,这与实际监控场景中对在线VAD的需求存在根本性的差异。
- 目标:开发一个在线视频异常监控助手,具备三项核心能力:
- 视频异常预测 VAP:系统应尽可能提前预测异常。
- 视频异常检测 VAD:系统必须能够稳健地检测突发且不可预测的异常事件。
- 视频预测分析 VAA:监控助手应支持实时问答与事件分析,帮助用户高效处理异常情况。
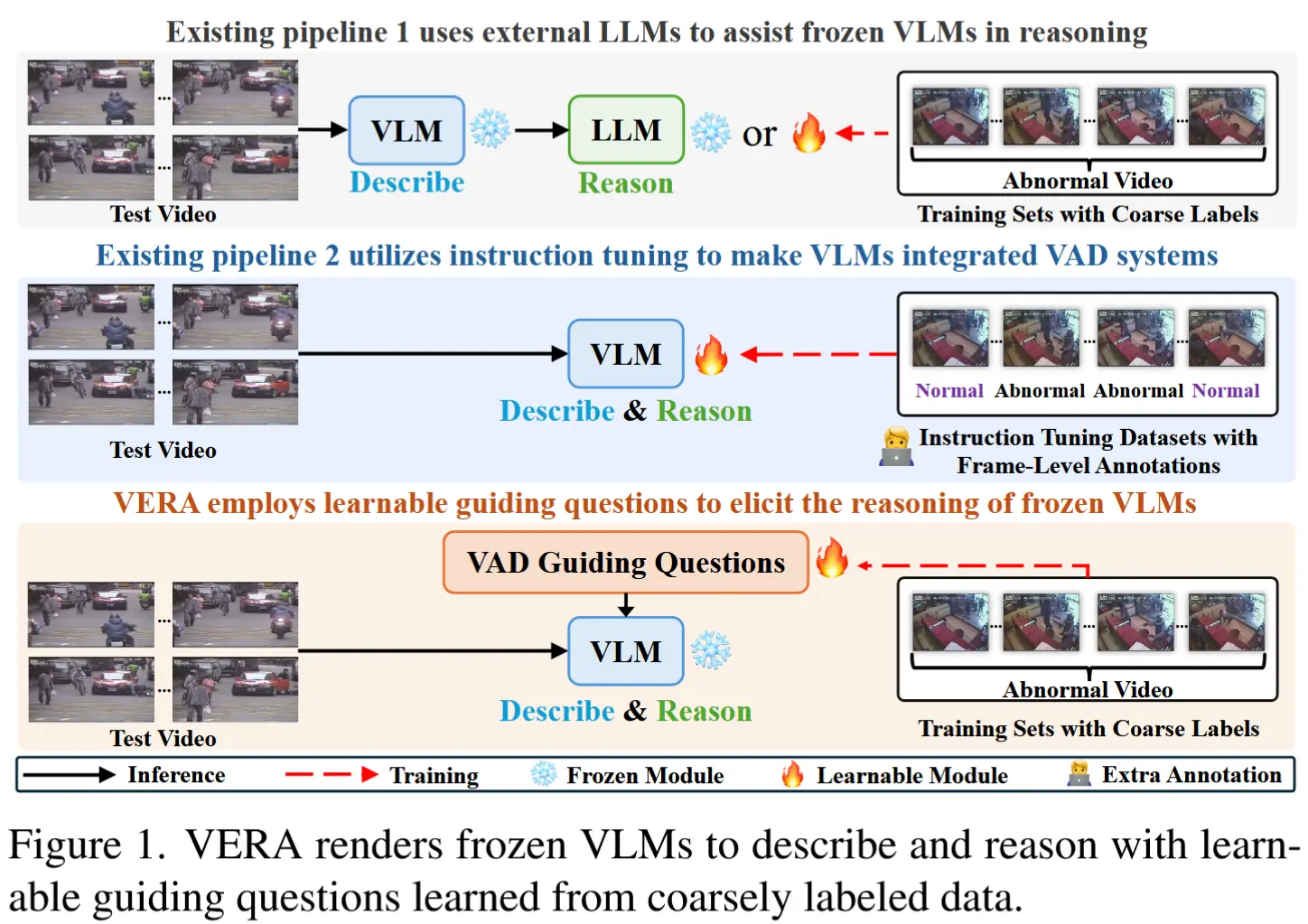
- AssistPDA
- 首个将异常预测、检测与交互式分析统一在一个系统中的框架,支持实时流式推理与用户交互。
- 具备三种主要运行模式:主动异常预测、实时异常检测与交互式分析。
- 开发 AssistPDA 的挑战
- (1)构建适用于在线 VAPDA 的训练数据。现有的视频异常问答数据集局限于片段级别的问答,无法满足基于流式视频的实时模型训练需求。
- (2)在逐帧流式推理中实现时间感知能力。如何在缺乏完整视频上下文的情况下,捕捉长期的时间依赖关系,这对于检测复杂且多样的异常事件至关重要。
- 解决办法
- 对于挑战(1),作者构建了 VAPDA-127K ——首个面向在线VAPDA任务的大规模基准数据集。
- 对于挑战(2),作者提出了一种时空关系蒸馏模块(STRD),旨在将预训练好的离线VLM视觉编码器中的时空推理知识进行蒸馏,压缩并集成到一个轻量级模块中,并嵌入到在线的视觉编码器与LLM的处理流程中。
2 相关工作
2.1 VAD
基于深度学习的方法大致可以分为三类:
- 无监督VAD方法 通常利用聚类技术或通过自训练生成伪标签,直接从正常与异常混合的数据中挖掘异常相关信息。
- 半监督VAD方法 主要基于帧重建或帧预测,通过代理任务从正常视频数据中学习正常模式。在推理阶段,偏离正常模式的行为被视为异常。
- 弱监督VAD方法 使用仅具有视频级标注的数据集,通常采用多实例学习来推断片段级别的异常得分。
2.2 多模态 VAD
基于LLM的多模态视频异常检测工作:
- Lv等人提出了一个结合视觉-语言模型(VLM)的视频异常检测与解释框架 [17];
- Zanella等人提出了一种无需训练的LLM驱动VAD方法 [39];
- Du等人开发了一个利用VLM进行因果推理的VAD框架 [8];
- Tang等人引入了HAWK系统,使用VLM理解开放世界中的视频异常 [23];
- Zhang等人提出了Holmes-VAD,用于实现无偏且可解释的VAD [41]。
局限:局限于单一任务的异常检测或视频异常问答任务,且均在离线环境下运行,缺乏对异常事件的预测能力。
3 方法
3.1 任务定义
3.1.1 视频异常预测 VAP
文字定义:事件级视频异常预测,旨在利用历史视频信息,在潜在异常事件完全展开之前进行预测,并以自然语言形式生成早期预警。预测输出包括异常事件的类别及其描述性解释。
形式化定义:在时间点 t_0,用户发出查询,例如,“请基于接收到的视频流实时预测可能发生的异常事件。” 实际的异常事件发生在 t_n \sim t_m 之间。给定从 t_0 到 t_k (k <= n) 的观察到的视频流,如果模型判断可能发生异常,则应在 t_k 自动生成一个自然语言响应,详细说明预测的事件类型和描述。
与之前的研究 [2,30] 中的基于帧的异常评分预测不同,它们受限于非常短的预测窗口,实用性低。
3.1.2 视频异常检测 VAD
形式化定义:在时间点 t_0,用户发出查询,例如,“请基于接收到的视频流实时检测任何异常事件。” 实际的异常事件发生在 t_n \sim t_m 之间。在此期间,模型会在 t_n \sim t_m 内的关键时刻提供异常检测响应,每个响应包含检测到的异常类型及其描述性解释。
3.1.3 视频异常分析 VAA
形式化定义:假设异常事件从 t_n 开始发生。在稍后的某个时间点 t_n + k,用户发出查询,例如,“当前的异常应该如何处理?” 接收到查询后,模型应立即在 t_n + l (l >= k) 时生成响应,实时解答用户的问题。
3.2 数据集构建
图2展示了整个数据集的构建流程。
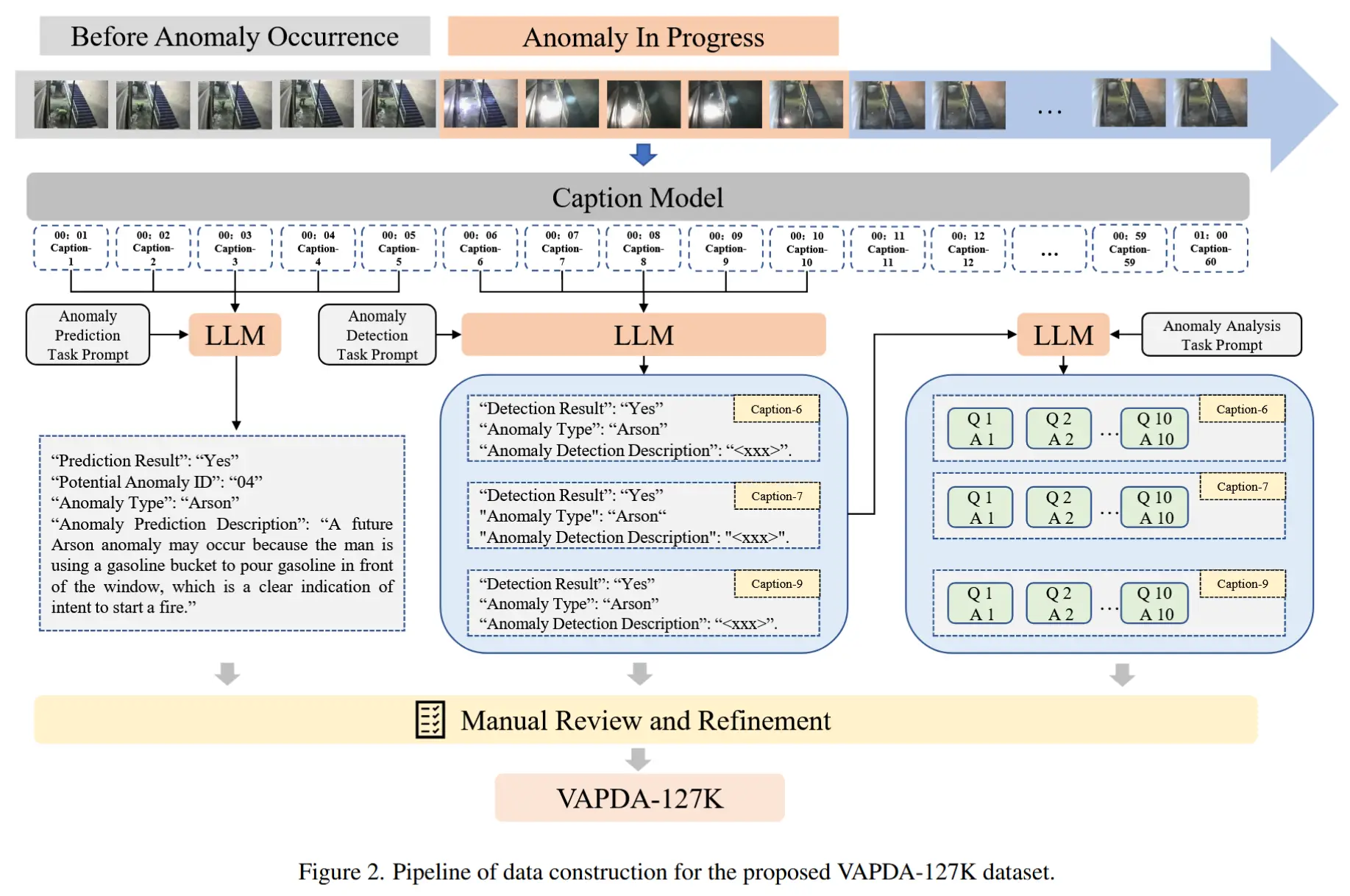
- 数据收集
- 原始视频来自 UCF-Crime 和 XD-Violence。
- 过滤掉低质量视频。
- 使用 HICAU-70K [42] 提供的上述两个数据集精确到时间戳级别的异常标注(即start和end)。
- 异常预测数据标注 for VAP
- 每秒一帧采样,并使用现有的视觉-语言模型为每一帧生成描述性文本。
- 将异常发生前的所有帧描述输入 LLM,通过设计的 prompt,让 LLM 判断最早可以在哪一帧预见即将发生的异常,并生成预测的异常类型及其简要描述。
- 异常检测数据标注 for VAD
- 这一步关注的是异常事件的片段,由于描述可能不包含异常相关信息,因此需要重新标注。
- 将带时间戳的当前描述与历史描述依次输入LLM,让 LLM 判断当前描述是否包含正在进行的异常事件,并基于当前和历史描述,生成简洁的异常描述,包括异常类型。
- 异常分析数据标注 for VAA
- 构建基于正在进行的异常事件的开放式问答对。
- 在异常事件期间的关键时刻提取关键检测描述,并按时间顺序结合历史描述输入LLM。随后,LLM根据 5W2H原则(Who, What, When, Where, Why, How, How much) 生成与当前异常相关的开放问题与答案。
- 人工审核与优化
3.3 模型架构
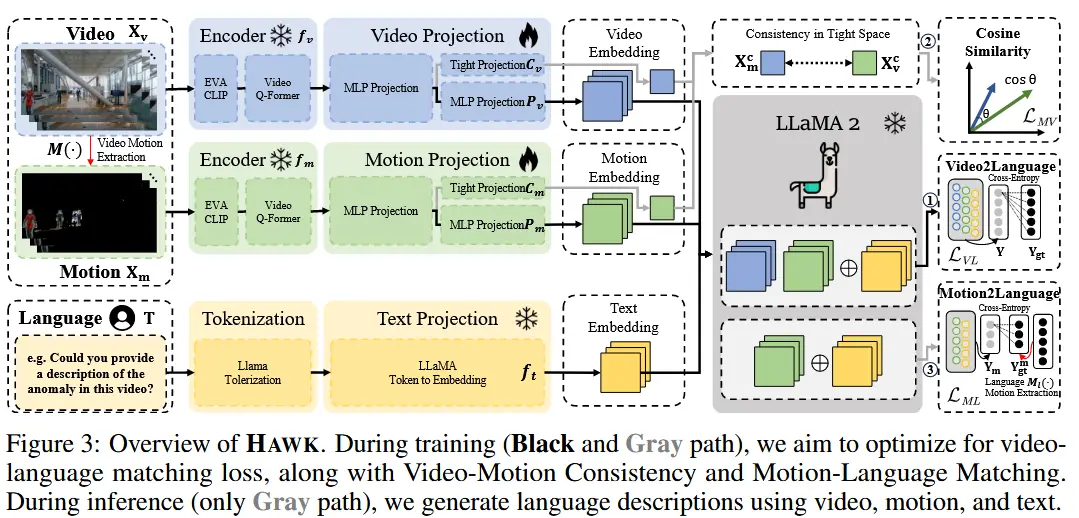
图3展示了 AssistPDA 的整体架构,该架构由三个关键组件组成:视觉编码器、时空关系蒸馏模块(STRD),以及一个带LoRA的LLM。
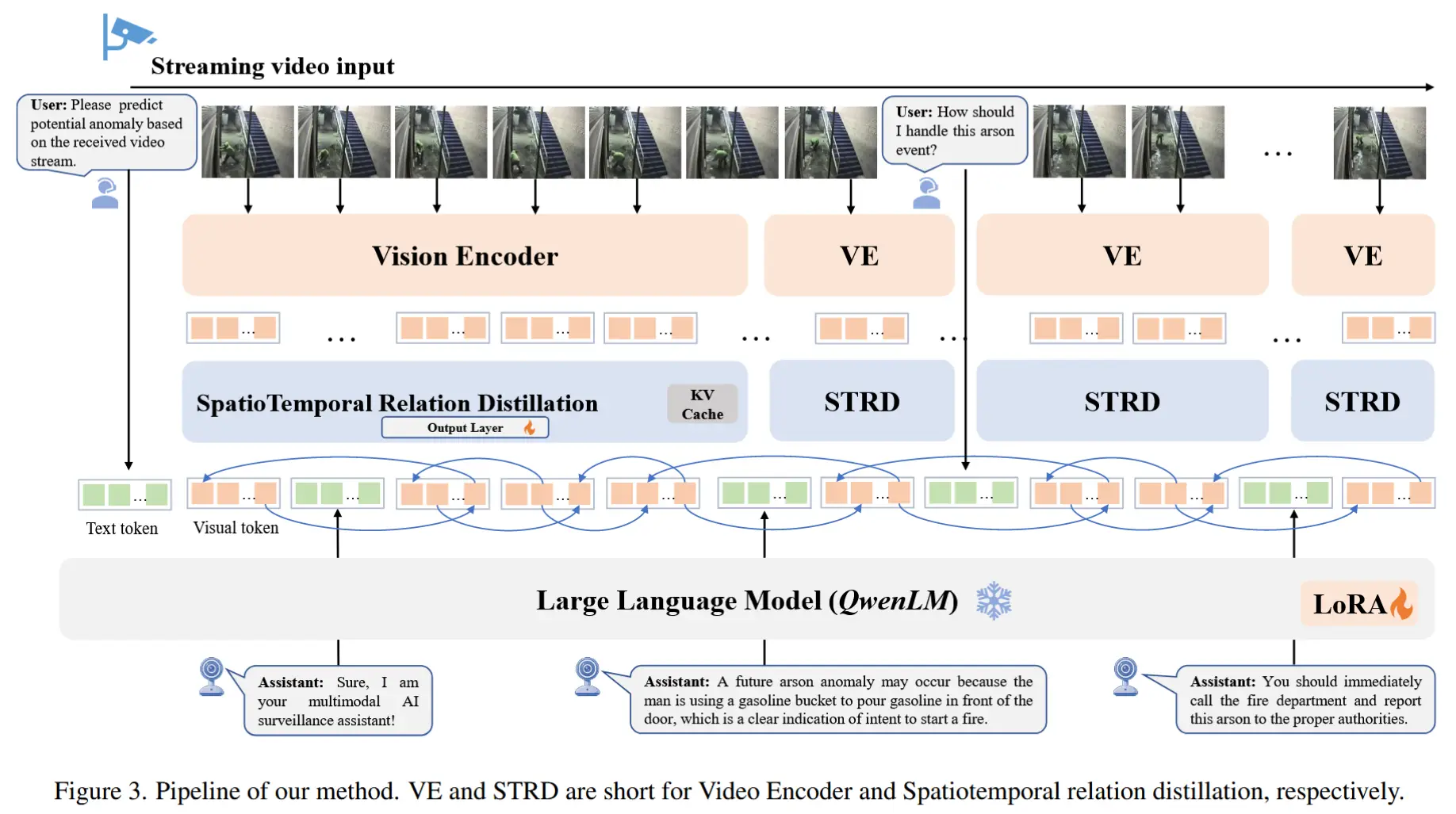
3.3.1 视觉编码器
采用来自 Qwen2-VL 的冻结视觉编码器 \varphi_v。以每秒2帧的频率从原始视频中采样帧,将每两个连续帧作为输入,提取视觉标记(tokens)。给定一个输入视频帧序列 \nu \in \mathbb{R}^{T \times H \times W \times C},从第 (i-1) 帧和第 i 帧中提取的视觉标记表示为:
其中,v^j_{i-1,i} (j \in \{1, 2, ..., N\}) 表示 patch tokens,N 表示从每两帧输入中提取的总 patch 数。为了简洁,后续讨论中“每一帧”视为实际的两帧输入的表示。
3.3.2 时空关系蒸馏(STRD)
动机:在线处理模式下,学习时空关系和长期记忆成为一个重大挑战。现有方法通常引入记忆单元来存储历史帧信息,然后在推理时检索信息。然而,这种方法对推理速度施加了显著的限制。
解决办法:
为了在保持高推理效率的同时具备强大的时空推理能力和长期记忆能力,作者引入了一个 STRD 模块 \phi。采用一种轻量级方法,使用两层多头自注意力(MHSA)网络作为 STRD 模块。该模块将 VLM 离线模式下建模全局时空关系的能力迁移到在线处理流程中。时空关系蒸馏过程如图4所示。
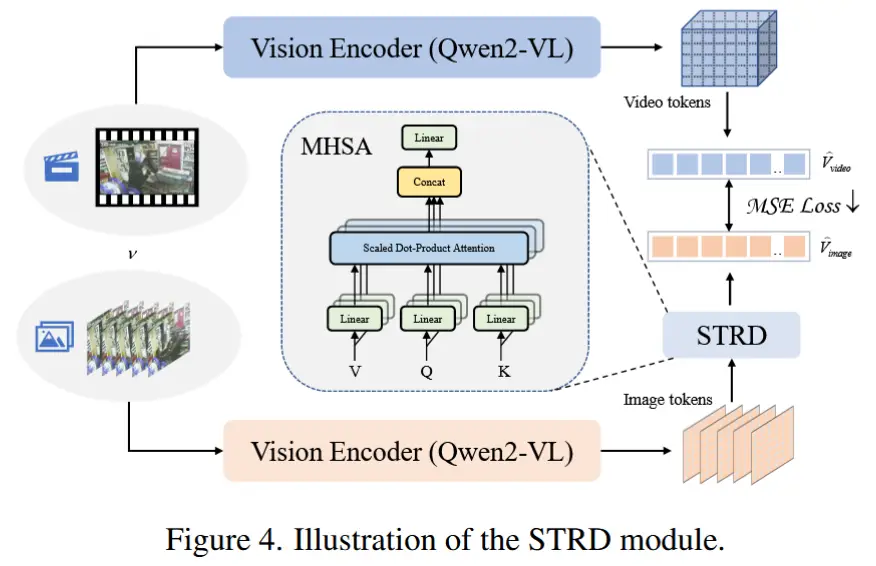
首先,输入的视频帧序列 \nu \in \mathbb{R}^{T \times H \times W \times C} 直接通过视觉编码器进行处理,获得全局视觉标记表示:
其中,\widetilde{v}^j_i (j \in \{1, 2, ..., M\}) 表示 patch tokens,M 是从输入视频中提取的 patch 数量。
由于视觉编码器在 patch 嵌入之前应用了步长为2的三维卷积,每个 v^j_i 仍然表示由两帧融合而成的 patch 标记。然而,与逐帧输入不同的是,这里的视觉标记是通过全局注意力操作获得的,这意味着每个 v^j_i 内在地包含了来自所有其他帧 patch 的信息,从而融入了完整的时空上下文。STRD 模块的作用是确保从逐帧输入中获取的标记,在经过变换后也能封装全局上下文信息。
为了实现这一点,首先沿时间维度将从逐帧输入中获得的标记进行拼接:
然后,将这些标记输入到蒸馏模块中进行转换,其公式如下:
最后,使用均方误差损失函数,在特征空间中强制 \widetilde{V}_{images} 和全局视频标记 \widetilde{V}_{video} 的一致性:
训练完成后,在 LoRA 微调过程中将 STRD 模块插入到视觉编码器和 LLM 之间。在实时推理阶段,STRD 模块中的 MHSA 模块配备了 KV 缓存,保留历史时空上下文。通过调整 KV 缓存的长度,可以控制 STRD 模块考虑的帧的时间跨度(在实验中最大时间感受野可以达到 20 分钟)。
3.3.3 LLM
使用 QwenLM,来源于 Qwen2-VL。负责处理从 STRD 模块中获得的视觉标记,将其与用户查询生成的文本标记按时间顺序拼接,并输入到 LLM 中进行解码,从而生成 VLM 响应。
3.4 训练与推理
训练过程分为两个阶段:
- 对 STRD 模块预训练,按照公式 (5) 进行优化。
- 使用构建的 VAPDA-127K 对模型进行指令微调,其中损失函数包含两部分:
-
自回归语言建模:最大化输入文本序列的联合概率 P_i^{[\text{Txl}_{i+1}]}。
-
视频流输入预测建模:AssistPDA 需要决定何时生成响应以及何时保持静默。根据文献 [3],作者在每个视频帧标记后引入了一个额外的流式结束序列(EOS)标记,EOS 标记的预测概率 P_i^{[\text{EOS}]} 用于决定是否继续接收视频帧输入或生成响应。
-
因此,损失函数公式如下:
L = \frac{1}{N} \sum_{i=1}^N \left( -l_i \log P_i^{[\text{Txl}_{i+1}]} - w f_i \log P_i^{[\text{EOS}]} \right), \tag{6} -
其中:
- l_i 和 f_i 是条件指示器;
- l_i = 1 表示第 i 个标记是语言响应标记,否则为 0;
- f_i = 1 表示满足两个条件:(1) 它是某一帧的最后一个标记,且 (2) l_{i+1} = 0;
- w 是平衡项。
- l_i 和 f_i 是条件指示器;
-
本质上,流式 EOS 损失应用于响应前的帧。P_i^{[\text{Txl}_{i+1}]} 表示在第 i 个标记处的语言头输出的第 (i+1) 个文本标记的概率,而 P_i^{[\text{EOS}]} 表示分配给 EOS 标记的概率。
推理阶段,AssistPDA 根据用户指定的查询执行不同的任务:
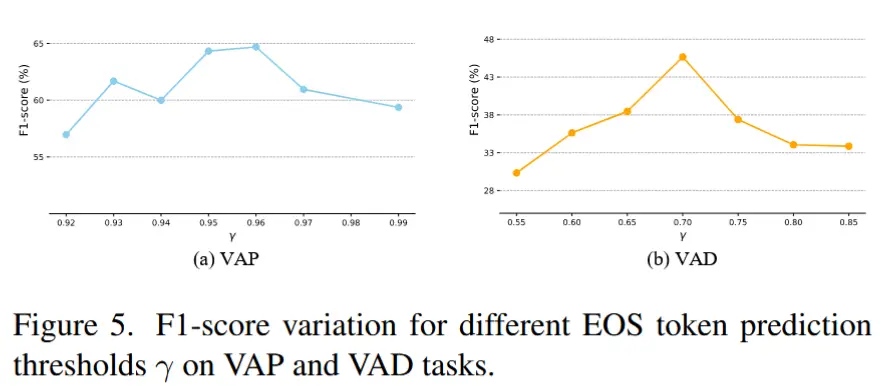
- 对于 VAP(预测) 和 VAD(检测) 任务,引入了一个阈值 \gamma 来控制 EOS 标记的预测。当 EOS 标记的预测概率低于 \gamma 时,模型生成响应,反之静默。
- 对于 VAA(分析) 任务,AssistPDA 在用户完成查询后立即响应,无需设置阈值。
在 A6000 GPU 上,AssistPDA 实现了平均推理速度为 15–20 FPS。
4 实验
4.1 实验设定
- 数据集:VAPDA-127K
- 评估指标
- 训练阶段
- 语言建模困惑度(LM-PPL)
- 时间差(TimeDiff):模型预测响应的时间戳与期望时间戳之间的差异。
- 流畅性(Fluency):衡量在一个对话回合中连续且成功预测的 token 比例。
- 推理阶段
- 对于 VAP\VAD\VAA,参考文献 [8],使用MoverScore (MS)、Bleurt 和 Unieval 来评估生成响应的质量。
- 对于 VAP\VAD,使用加权F1衡量分类准确性。
- 引入了平均提前时间(Average Advance Time, AAT),评估模型在异常发生前进行预测的能力。
- 训练阶段
- 实现细节
- 视觉编码器和 LLM 模块均使用 Qwen2-VL-2B-Instruct 版本进行初始化。
4.2 主要结果
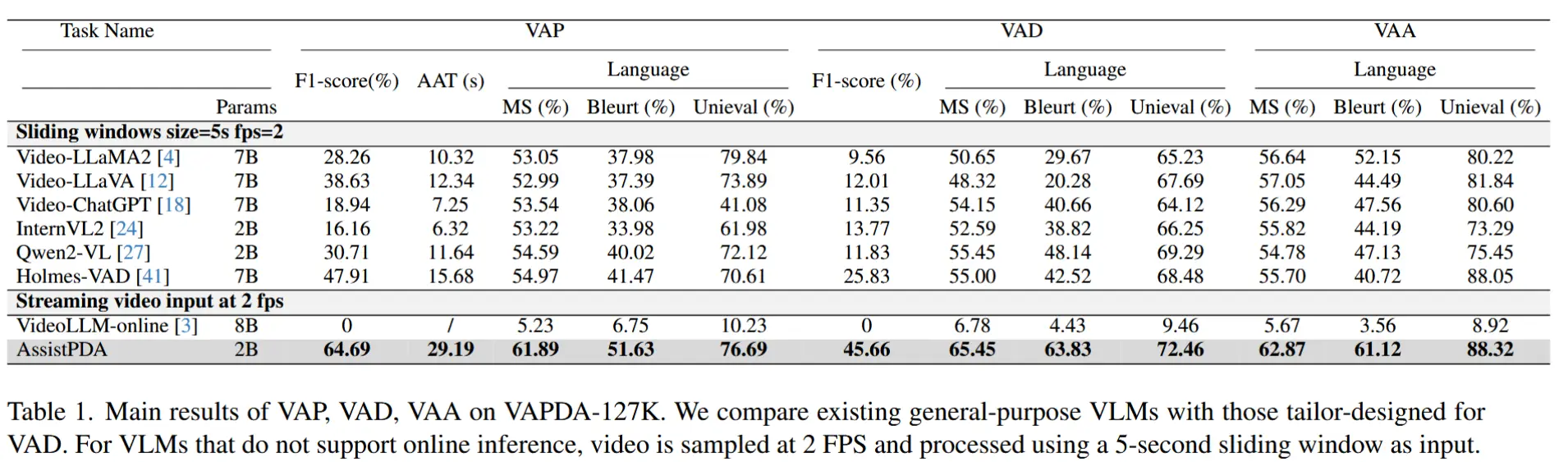
- 基线实现
- 对于离线模式的基线,采用滑动窗口的方式模拟在线环境,窗口大小设为 5 秒。
- 由于不同 VLM 的指令微调数据存在差异,作者为每个模型优化了提示词以最大化响应准确性。
- 结果如表1所示
- AssistPDA 在所有评估指标上均显著优于所有基线方法。
提升效果非常多,期待开源试一试。
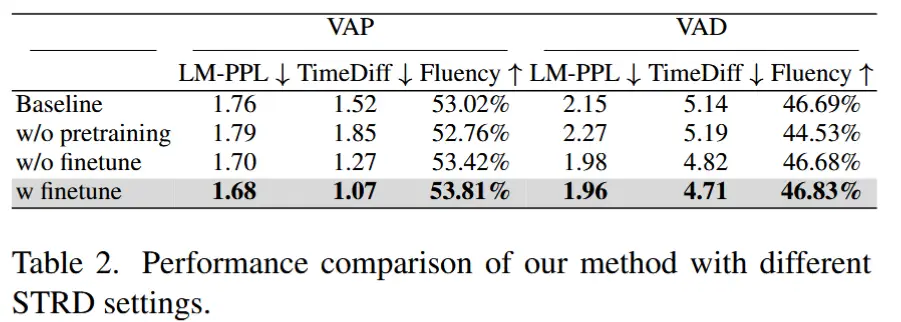
4.3 消融实验
- STRD模块的有效性
- EOS Token 预测阈值 \gamma 的影响