- 论文 - 《HAWK: Learning to Understand Open-World Video Anomalies》
- 代码 - Github
- 关键词 - 视频大模型、视频异常检测 VAD、框架设计、新微调数据集、运动模态、视频-文本、视频描述生成、视频问答
摘要
- 研究问题
- 现有的 VAD 系统通常受限于其对场景语义理解的浅层以及用户交互的缺乏。
- 现有数据集中普遍存在的数据稀缺问题也限制了它们在开放世界场景中的适用性。
- 新框架 - HAWK
- 该框架利用交互式的大规模视觉语言模型(VLM)来精确解释视频中的异常现象。
- 考虑到异常视频与正常视频之间在运动信息上的差异,HAWK 显式地整合了运动模态以增强异常识别能力。
- 为了强化对运动的关注,作者在运动空间和视频空间中构建了一个辅助一致性损失函数,引导视频分支专注于运动模态。
- 为了提升从运动到语言的解释能力,作者建立了清晰的监督关系,将运动与其语言表示联系起来。
- 新数据集
- 为进一步推动模型在开放世界场景下的泛化能力,作者标注了超过 8,000 条带有语言描述的异常视频,支持在多样化开放世界场景中的有效训练,并创建了 8,000 组问答对,用于处理用户的开放性问题。
1 研究动机
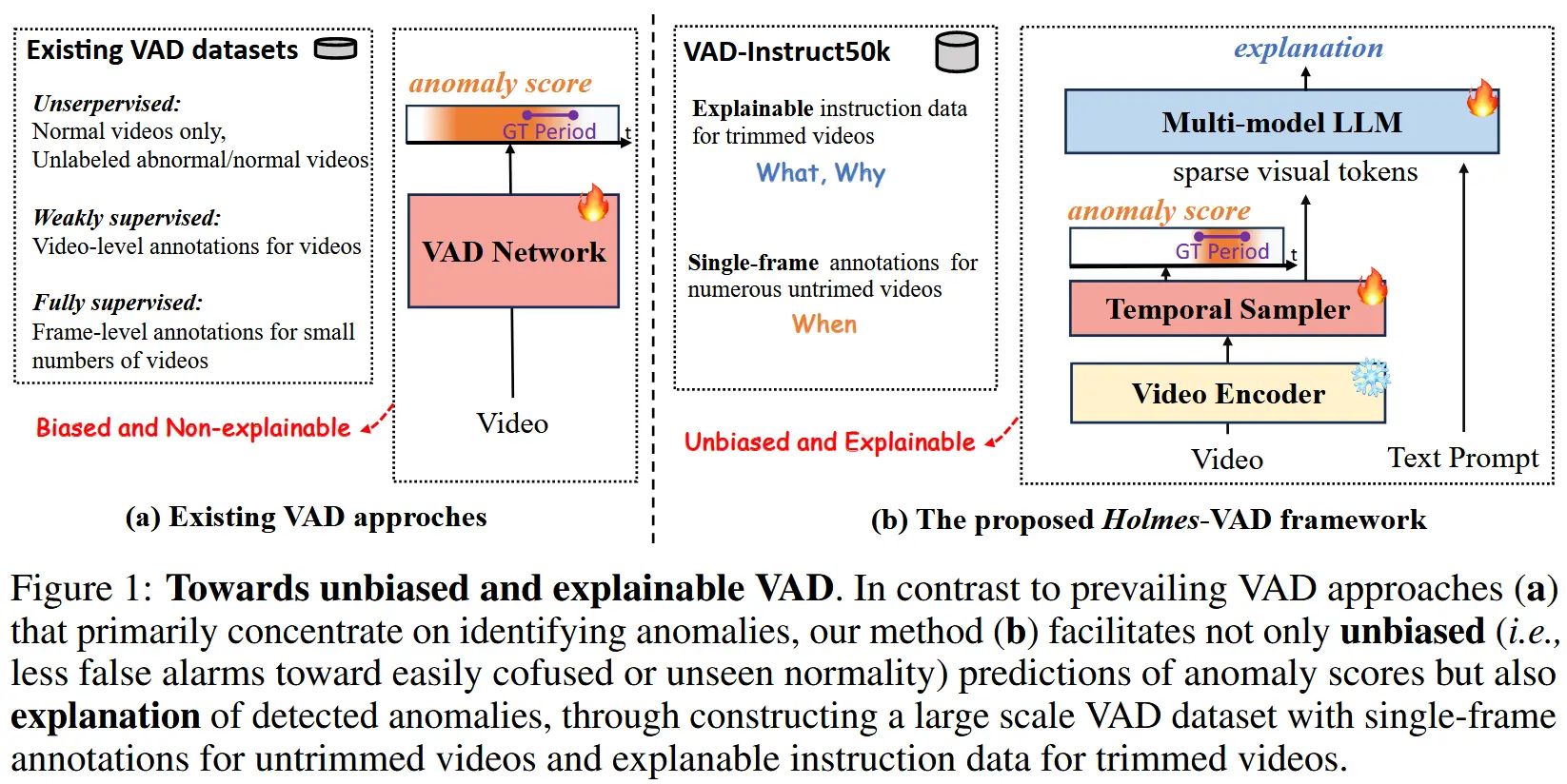
- 现有的 VAD 系统往往缺乏对场景的深层语义理解,并且与用户的交互能力有限。
- 虽然 [28][39] 将语义信息引入到视频异常检测中,但他们的框架仅限于多类分类器,因此,功能局限于异常帧的检测,用户仍需手动分析以全面理解检测到的异常。
- [24] 最早提出了一种用于视频异常解释的大语言模型,但其方法主要依赖伪标签进行训练,缺乏稳健的训练数据,严重限制了其实用性。
- 如图1所示,展示了不同 VAD 框架的差异。
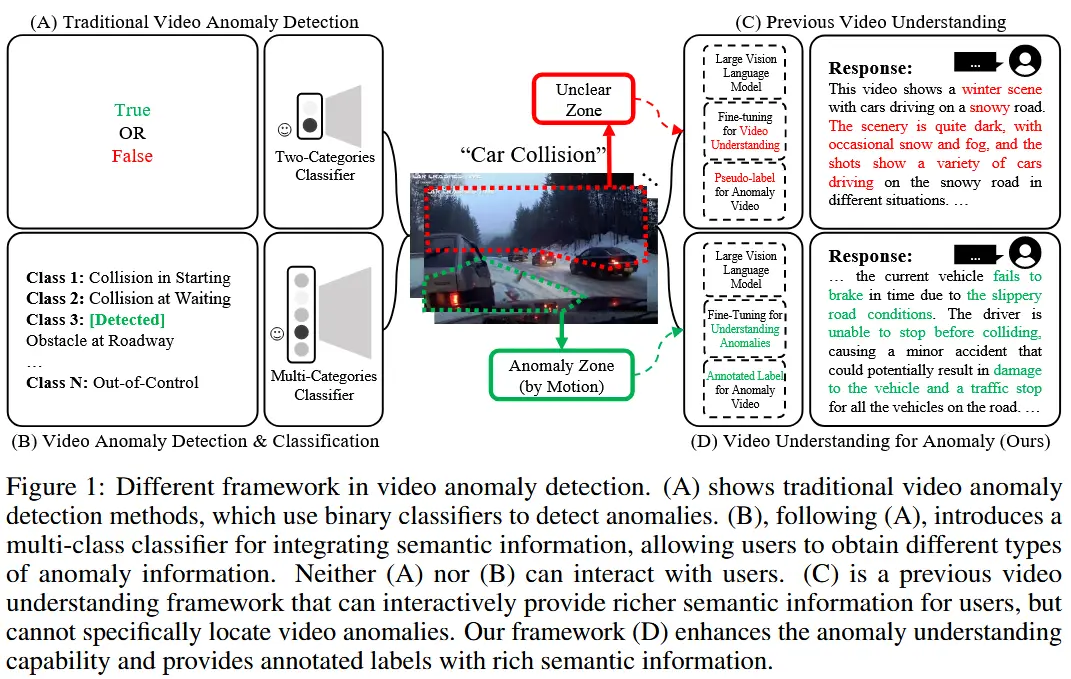
- 本文目标:设计一个模型,集成更全面的语义信息,作为通用视频理解系统的一部分,还为用户提供先进的交互能力。
2 数据集构建
- 动机:现有数据集不足以解决本文的问题。
- [2、42] 仅包含简单的视频类别标签,缺乏详细的语言描述,导致视频理解模型缺乏准确且全面的监督,从而在识别视频中的异常时面临重大障碍。
- [24] 的描述只是标签和固定文本的简单组合,依赖于僵化的格式,提供的信息非常有限。
- [3],虽然包含视频内容的一般性描述,但可能无法引导模型聚焦于异常事件。
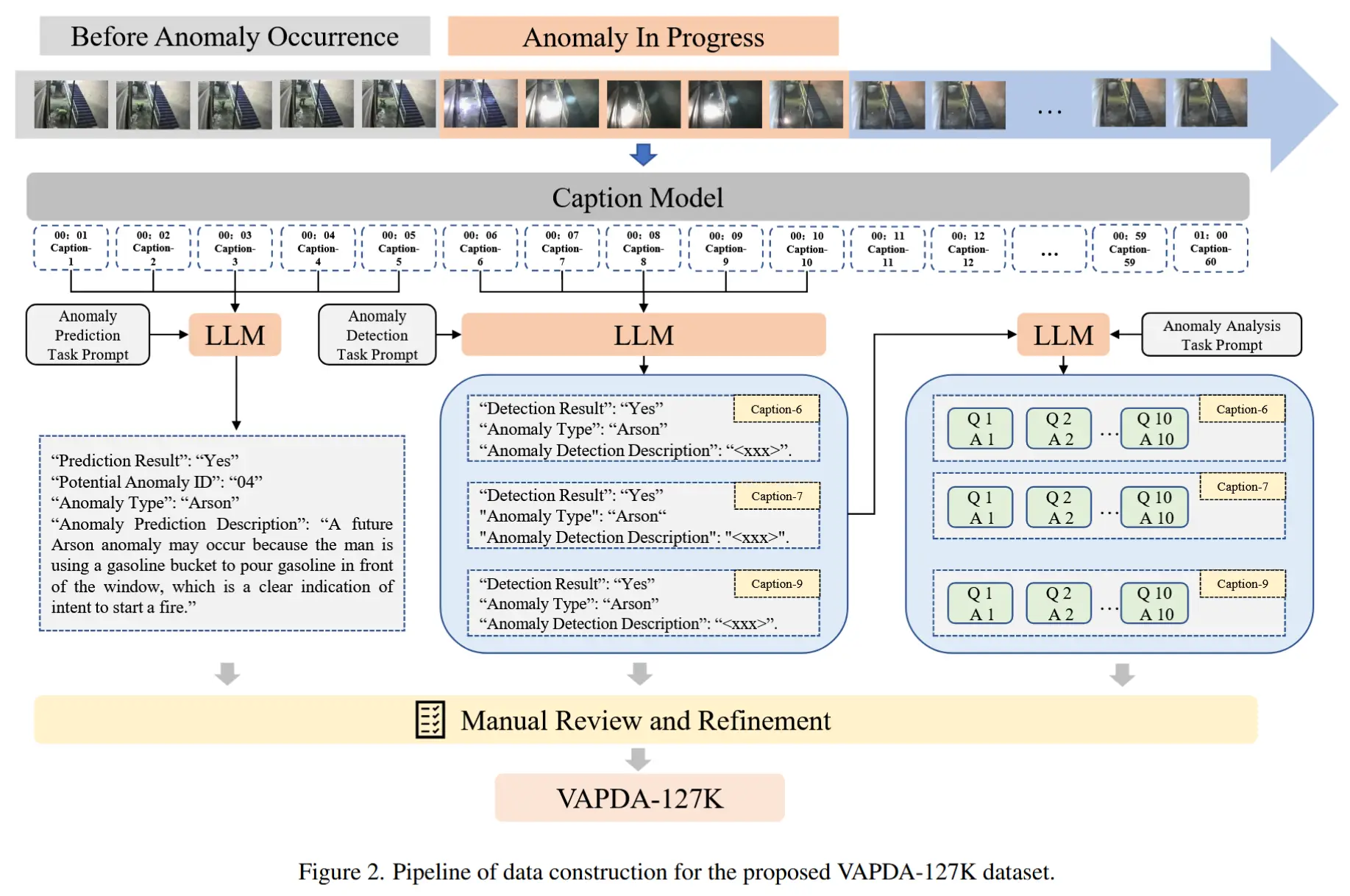
- 数据集构建步骤,如图2所示
- 0)选择基础数据集:UCF-Crime、ShanghaiTech、CUHK Avenue、UCSD Ped1 & Ped2、DoTA、UBnormal。包含多种异常场景。
- 1)生成语言描述:对异常场景进行了详细的语言标注。
- 2)构建开放式问答对:为了模拟现实世界中用户的交互,为每个场景构建了开放式问答对。
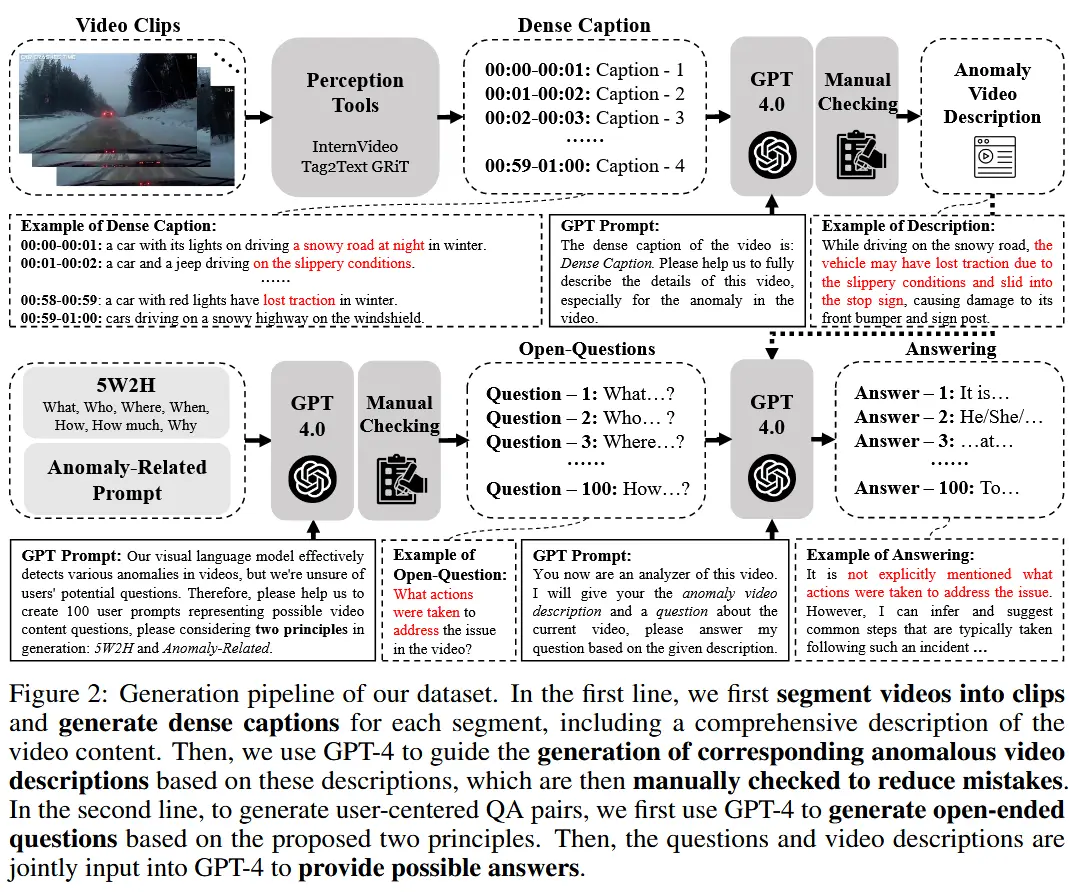
2.1 异常视频描述生成
步骤:
- 首先将视频拆分为密集的片段,以确保捕捉关键信息。
- 使用感知工具(如 InternVideo、Tag2Text 或 GRiT)自动为每个关键片段生成字幕,从而获得视频的密集表示。
- 使用 GPT-4 基于这些字幕为每个视频生成与异常相关的描述。
- 对最终生成的视频异常描述进行了人工复查,以确保标签的准确性。
2.2 以人类为中心的问答对生成
问答生成的原则:
- 与异常相关性:问题应紧密关联视频中的异常事件。
- 5W2H原则:引入了七个不同的疑问词(What、Who、Where、When、How、How much、Why),以模拟用户可能使用的多种提问格式。
步骤:
- 将这两个原则输入到 GPT-4 中,用于生成针对异常视频的开放式问题。
- 对生成的问题进行人工审核,并选出最合适的 100 个问题,随机分配给每个视频。
- GPT-4 [1] 将为这些问题生成相应的
<ANSWER>。
emmm,看了一下数据集,质量。。。很多问题都和对应视频无关的,更像是纯文本的对话,比如:“为什么制定处理视频异常的备份计划很重要?”、“如何针对特定用例自定义视频异常检测系统?"、”我应该分配多少时间来分析视频异常?“。而且在问答的标准答案里,还出现了很多大模型抽风的回答,作者也放进来了作为标准答案,很明显没有人工审核。。。比如:”抱歉,我无法分析和查看视频。“。
3 方法论
解决方案的核心:引导视觉信息处理专注于异常区域。
解决方案概述:
- 显式引入了运动模态:以针对异常相关的特征建模。(3.1节)
- 隐式增强运动注意力:通过在特征空间内保持外观模态与运动模态之间的互信息一致性实现。(3.2节)
- 解释运动 to 语言:为了提高从运动到语言的解释能力,提取了与运动相关的语言描述,并将其直接匹配到对应的运动特征上,以实现更准确的视频异常语义表达。(3.3节)
3.1 显式运动模态集成
HAWK显式地整合了运动模态。HAWK 采用双分支架构,其中 f_v 是原始视频理解网络,而 f_m 则用于运动理解。受 Video-LLaMA 的启发, f_v 和 f_m 具有相同的架构但使用独立的参数。公式 (2) 描述了整体框架:
其中:
- \mathbf{X}_v \in \mathbb{R}^{T \times C \times H \times W} 表示提取外观特征的
<VIDEO>输入。 - \mathbf{X}_m = M(\mathbf{X}_v) ,其中 M(\cdot) 是运动提取器。
整体架构如图 3 所示:
- 组成
- 视频和运动编码器 f_v(\cdot) 和 f_m(\cdot) 是 BLIP-2 中冻结的预训练视频编码器,由一个 EVA-CLIP 和一个预训练的 Video Q-Former 组成。
- 视频和运动投影网络 P_v(\cdot) 和 P_m(\cdot) 。
- 文本分词器和投影 f_t(\cdot) 。
- LLaMA-2。
- 流程
- 1)输入处理:视频到视频编码器,输出视觉嵌入。使用运动提取器 M() 处理视频输入后输入运动编码器,输出运动嵌入。同时文本信息(视频描述和问题)经过Tokenization和投影得到文本嵌入。
- 2)将提示定义为:
Here is the input video embedding: <VIDEO_EMBEDDING> and motion embedding <MOTION_EMBEDDING> in different frames, please help me to <DESCRIBE_VIDEO> | <QUESTION>。 - 3)利用 LLaMA-2,生成最终的语言响应 Y 。
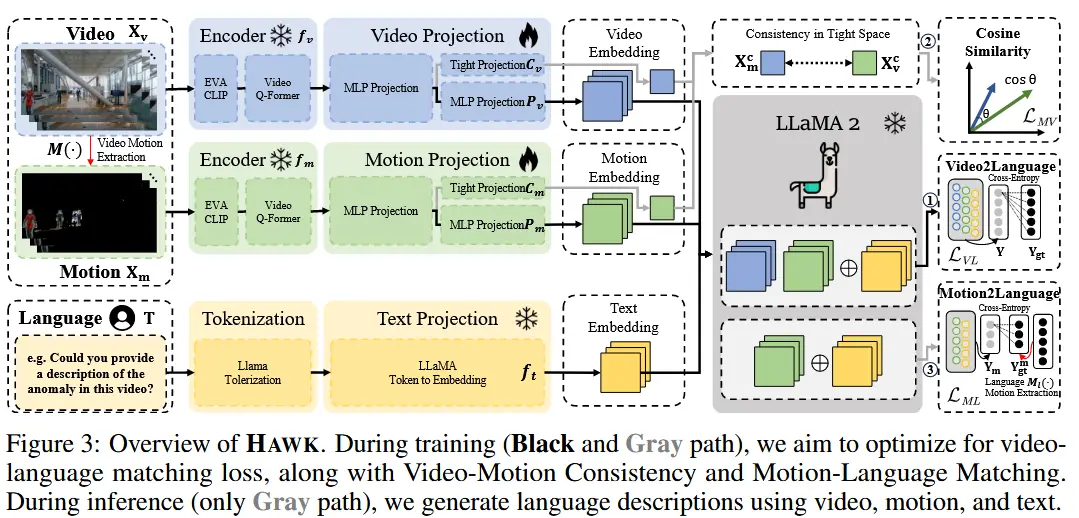
3.2 隐式增强运动注意力
基本思想:为了帮助 HAWK 更加关注异常区域,作者观察到运动与原始视频在互信息中的包含关系。利用这种关系构建了一个辅助一致性损失函数,从而隐式地强化对运动的注意力(见图 4)。
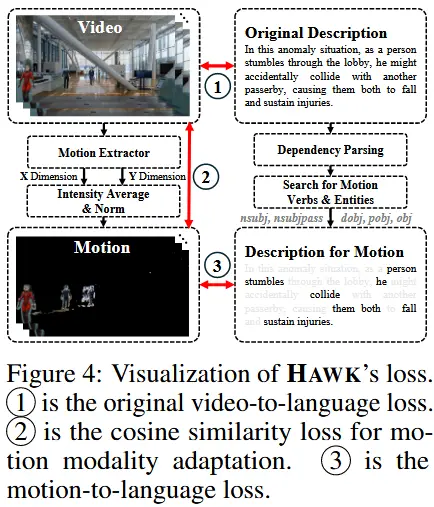
提取运动
具体来说,为了提取运动信息,使用了一个运动描述器 M(\cdot) ,如公式 (3) 所示:
其中:
- M^{(t)}(\cdot) 是在时间步 t 的运动描述器;
- \mathbf{X}_v^{(t)}, \mathbf{X}_v^{(t-1)} \in \mathbb{R}^{1 \times C \times H \times W} 表示时间步 t 和 t-1 的视频帧。
\mathbf{X}_{\text{Motion}}^{(t)} \in \mathbb{R}^{2 \times H \times W} 包含了两个通道的运动向量(水平和垂直)。从这两个通道中提取光流的幅度作为掩码,并将其归一化到 [0, 1] 范围内,然后与原始视频外观相乘,以隐藏其他非运动区域,如公式 (4) 所示:
其中:
- \times 表示逐像素乘法运算;
- \mathbf{X}_v^{(t)}, \mathbf{X}_{\text{m}}^{(t)} \in \mathbb{R}^{1 \times C \times H \times W} 分别表示时间步 t 的原始视频和输入的运动信息;
- 通常提取 T 帧作为运动输入 \mathbf{X}_{\text{m}} \in \mathbb{R}^{T \times C \times H \times W} ,与 \mathbf{X}_v 相同。
构建 \mathcal{L}_{MV} 损失
由于 \mathbf{X}_v 的特征空间更为稀疏,因此,将 \mathbf{X}_{\text{m}} 和 \mathbf{X}_v 的特征压缩到一个紧凑的空间中。在这个空间中,作者希望保持 \mathbf{X}_{\text{m}} 和 \mathbf{X}_v 之间的互信息一致性,从而使外观特征能够聚焦于运动区域。为此,构建了一个辅助损失函数来促进 \mathbf{X}_v 对运动的关注:
其中:
- \mathbf{X}_v^c = C_v(f_v(\mathbf{X}_v)) 和 \mathbf{X}_{\text{m}}^c = C_m(f_m(\mathbf{X}_{\text{m}})) 表示压缩后的嵌入。
- 压缩函数 C_v 和 C_m 共享部分浅层参数与投影网络 P_v 和 P_m (如图 3 所示)。
优势:通过这种辅助损失,可以在外观特征中强化对运动的关注,从而使 HAWK 的特征空间更加聚焦于与异常相关的特征,从而提升整个框架对异常的理解能力。
3.3 解释运动到语言的映射
基本思想:对应的运动在语言中的表示仍然不明确。这一限制阻碍了 HAWK 在运动模态中的解释能力。因此,需要强化运动与其语言表示之间的对应关系。
提取与运动相关的语言
先前的研究证明,运动在语言中的表示主要来源于动词及其相应的实体。因此,为了提取语言表示,第一步是对原始句子进行 dependency parsing:
其中:
- D(\cdot) 是 dependency parsing;
- Y_{\text{gt}} 是 ground truth;
- \mathbf{G}_{\text{gt}} 表示 the graph of the dependency structure,象征着句子中单词之间的语法关系。
基于此图,可以提取谓语(动词) V ,以及与这些谓语密切相关的实体,例如主语 S 、宾语 O 、间接主语 S_1 和间接宾语 O_1 。然后,这些元素被组合成短语来表示运动:
其中:
- M_l(\cdot) 是语言运动提取算子;
- \mathbf{Y}_{\text{gt}}^{\text{m}} 是与运动相关的语言。
构建 \mathcal{L}_{ML} 损失
在获得与运动相关的语言后,可以在视觉和语言表示中的运动之间建立强监督,提升 HAWK 对运动到语言的理解能力。因此,作者设计了一个运动-语言匹配损失作为辅助损失:
其中:
- \mathcal{L}_{ML}(\cdot) 是交叉熵损失,包含 N 个单词;
- Y_{\text{m}} 是通过 LLaMA 模型生成的语言输出。
优化目标
最后,总损失 \mathcal{L} 如下所示:
其中:
- \mathcal{L}_{VL} 是原始视频到语言的损失(如图 4 中的步骤 ①);
- t_i 是超参数。
4 实验
4.1 实验设定
-
训练和测试分为三个阶段
- 1)在WebVid数据集上进行预训练。
- 2)通过第2节的数据集微调模型对视频异常理解的关注,联合训练了两个任务:视频描述生成和视频问答。
- 3)在测试集中对这两个任务进行独立评估。
-
基线
- VideoChatGPT, VideoChat, Video-LLaMA, LLaMA-Adapter, Video-LLaVA。
-
指标
- BLEU-1到BLEU-4
- 利用 GPT-Guided 方法评估生成文本的质量,从可推理性、细节性和一致性三个方面评价。
4.2 实验结果
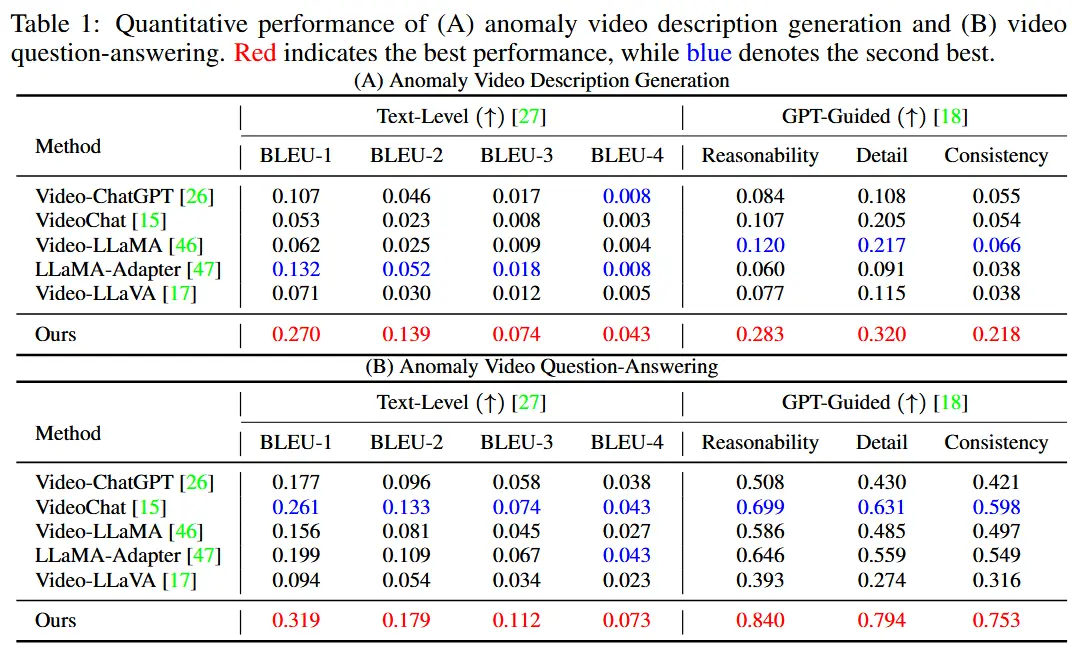
- 定量评估
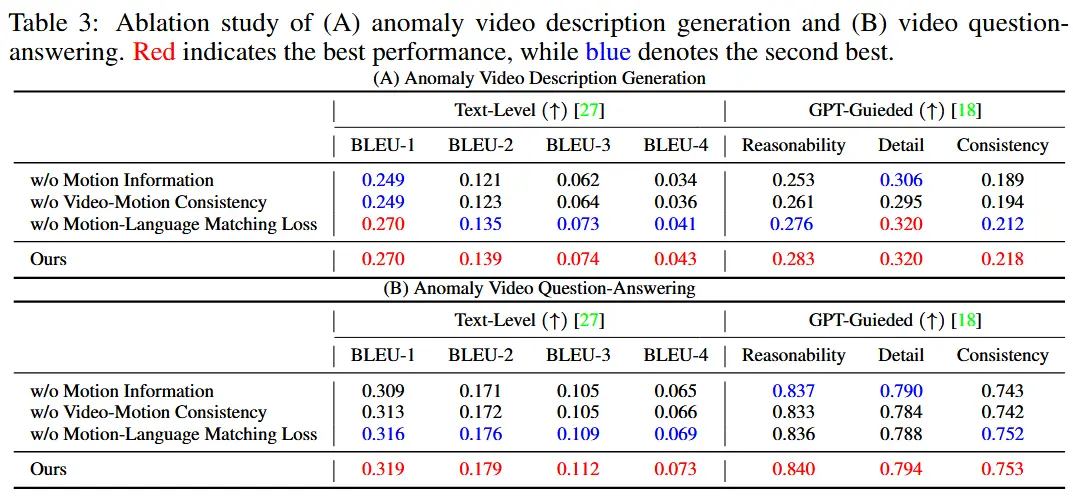
- 消融实验
- 运动信息的有效性
- 消融所有运动成分,包括 f_m,P_m,X_m。
- 视频-动作一致性的有效性
- 消融视频-运动一致性约束 \mathcal{L}_{MV}。
- 运动-语言匹配的有效性
- 消融运动-语言匹配损失 \mathcal{L}_{ML}。
- 运动信息的有效性
- 定性分析不展示了。