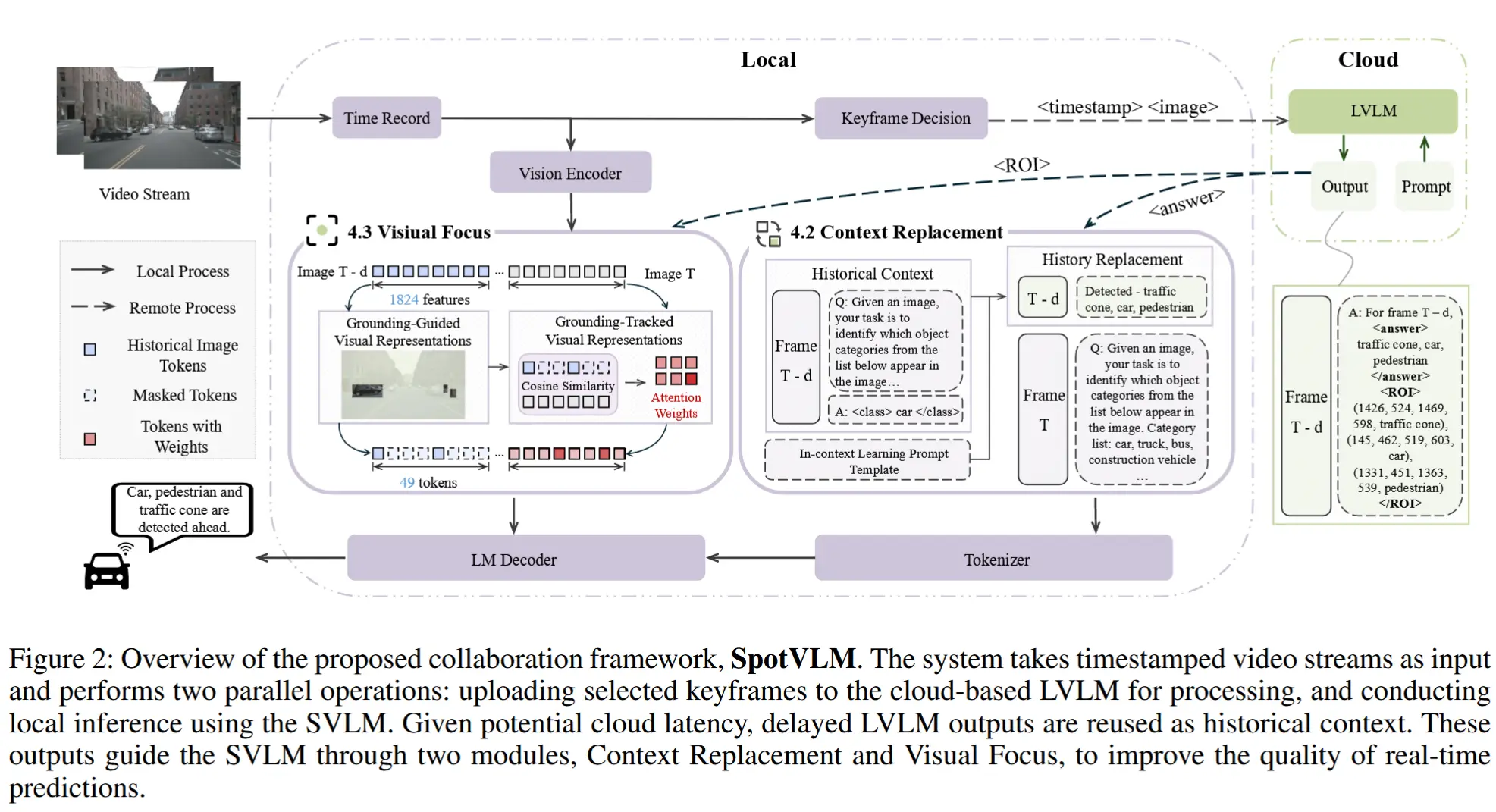
论文 - 《SpotVLM: Cloud-edge Collaborative Real-time VLM based on Context Transfer》 关键词 - 云边协同、视觉-语言大模型VLM、文本上下文、视觉聚焦、大小模型混合、实时视频 这篇介绍了一种新的大小模型协同方式,大模型通过
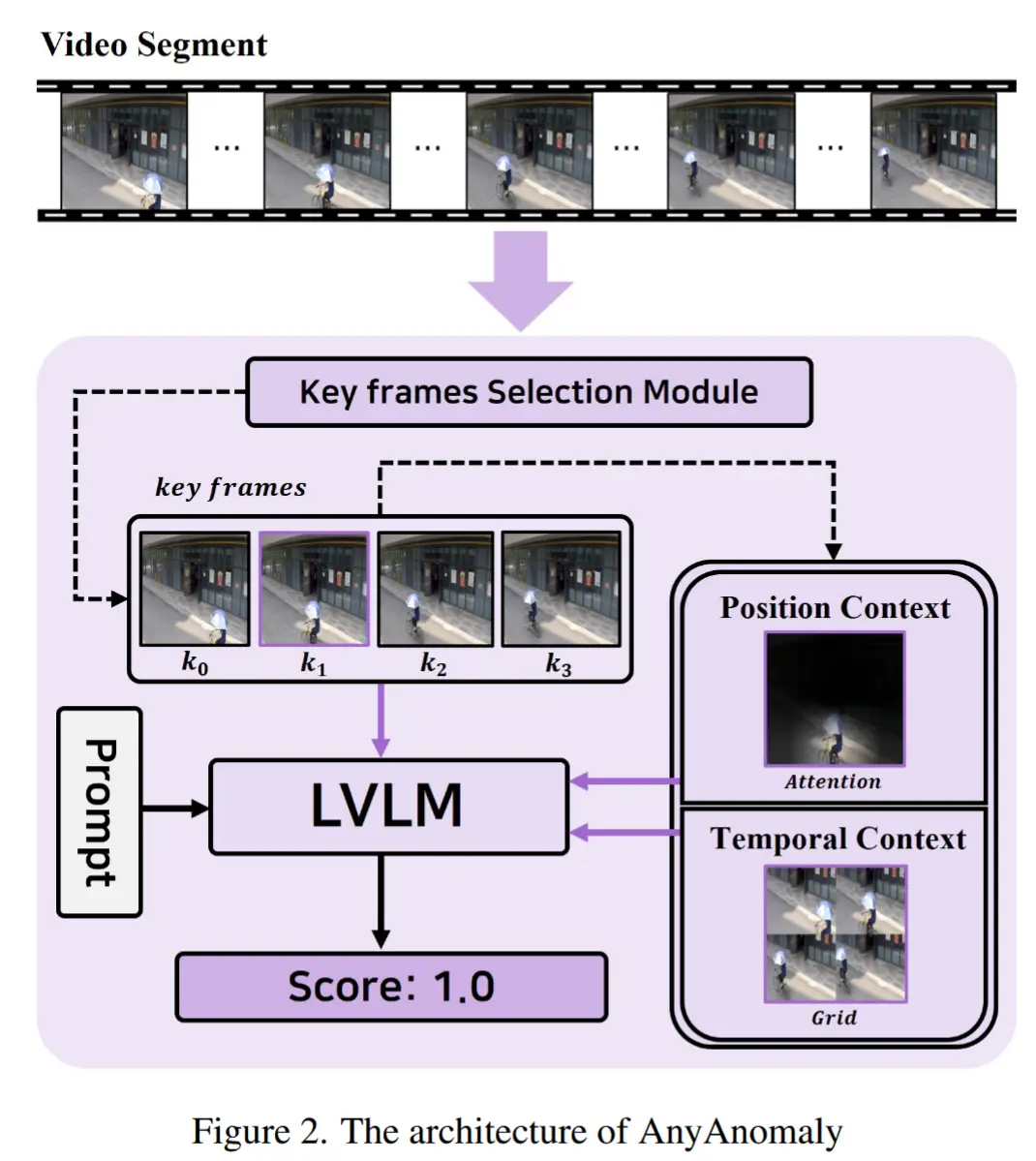
论文 - 《AnyAnomaly: Zero-Shot Customizable Video Anomaly Detection with LVLM》 代码 - Github 关键词 - 关键帧采样、无需微调/训练、零样本、视频异常检测、视觉语言模型VLM 这篇论文主要是利用VLM的通用泛化能力来实
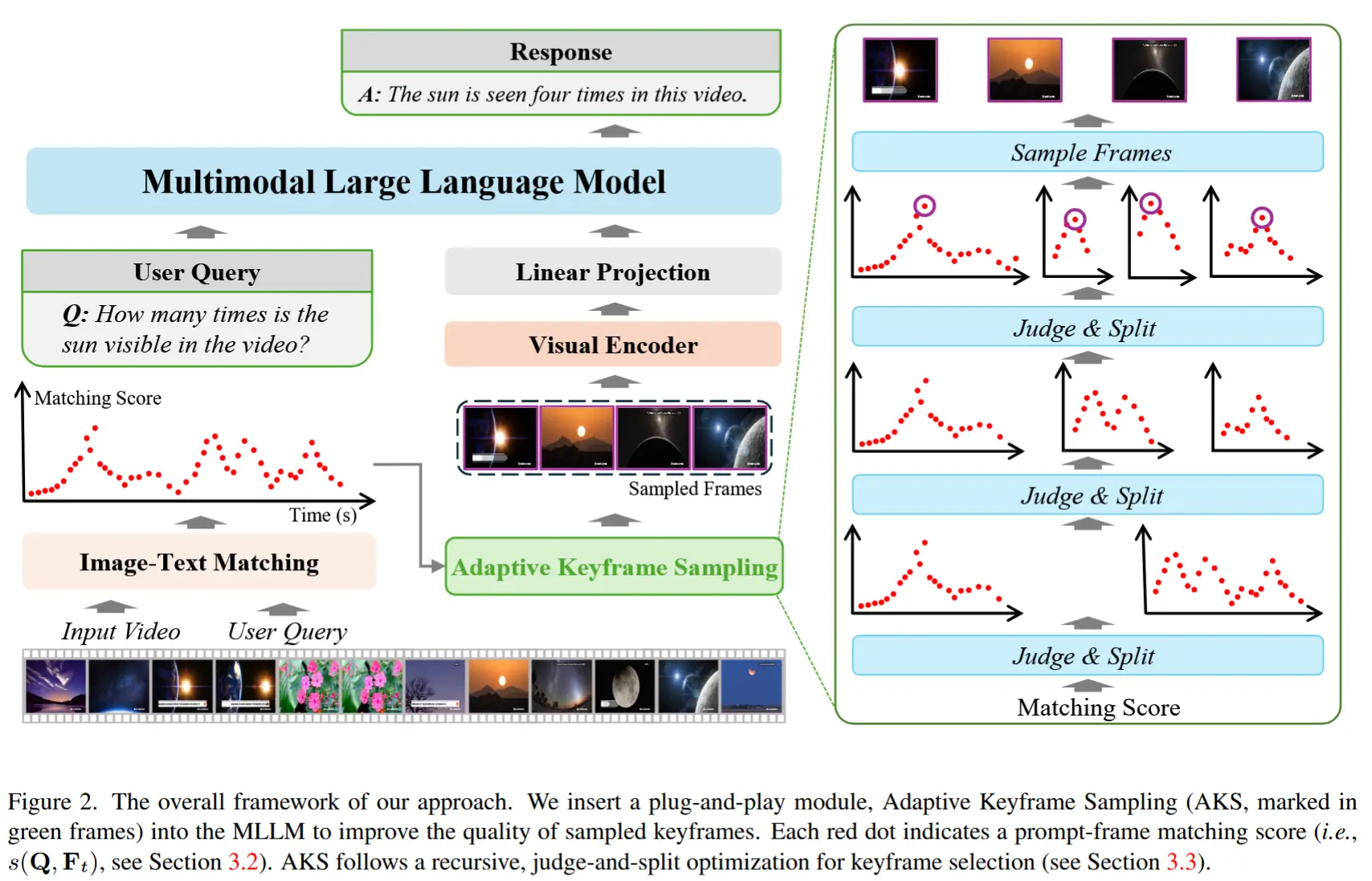
论文 - 《Adaptive Keyframe Sampling for Long Video Understanding》 代码 - Github 关键词 - 自适应抽帧、多模态大模型MLLM、相关性、覆盖度、采样 1 引言 研究问题 MLLMs 通过将视觉输入作为额外的标记注入到 LLMs 中作
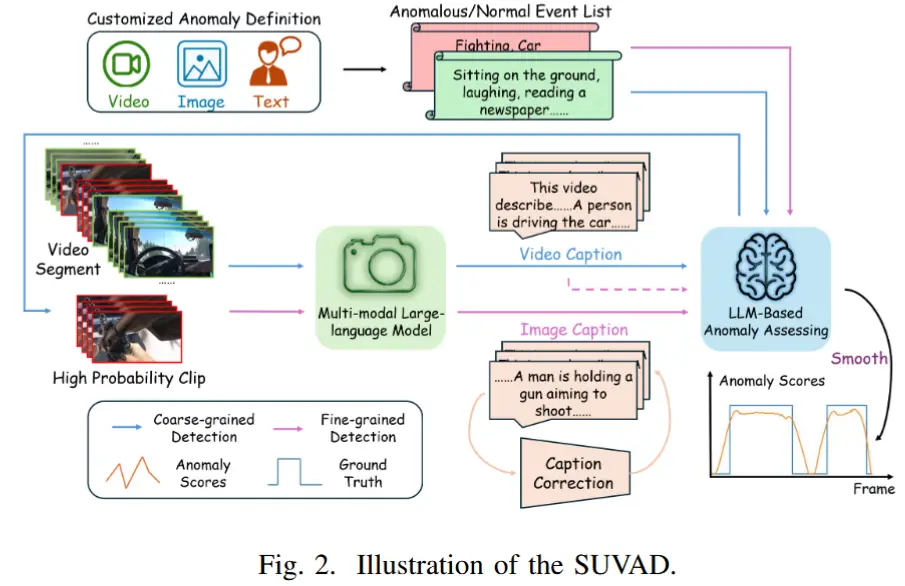
论文 - 《SUVAD: Semantic Understanding Based Video Anomaly Detection Using MLLM》 关键词 - ICASSP2025、无需训练的、多模态大模型、视觉-语言模型、视频异常检测 1 引言 现有工作不足 这些方法大多依赖特定场景,一旦
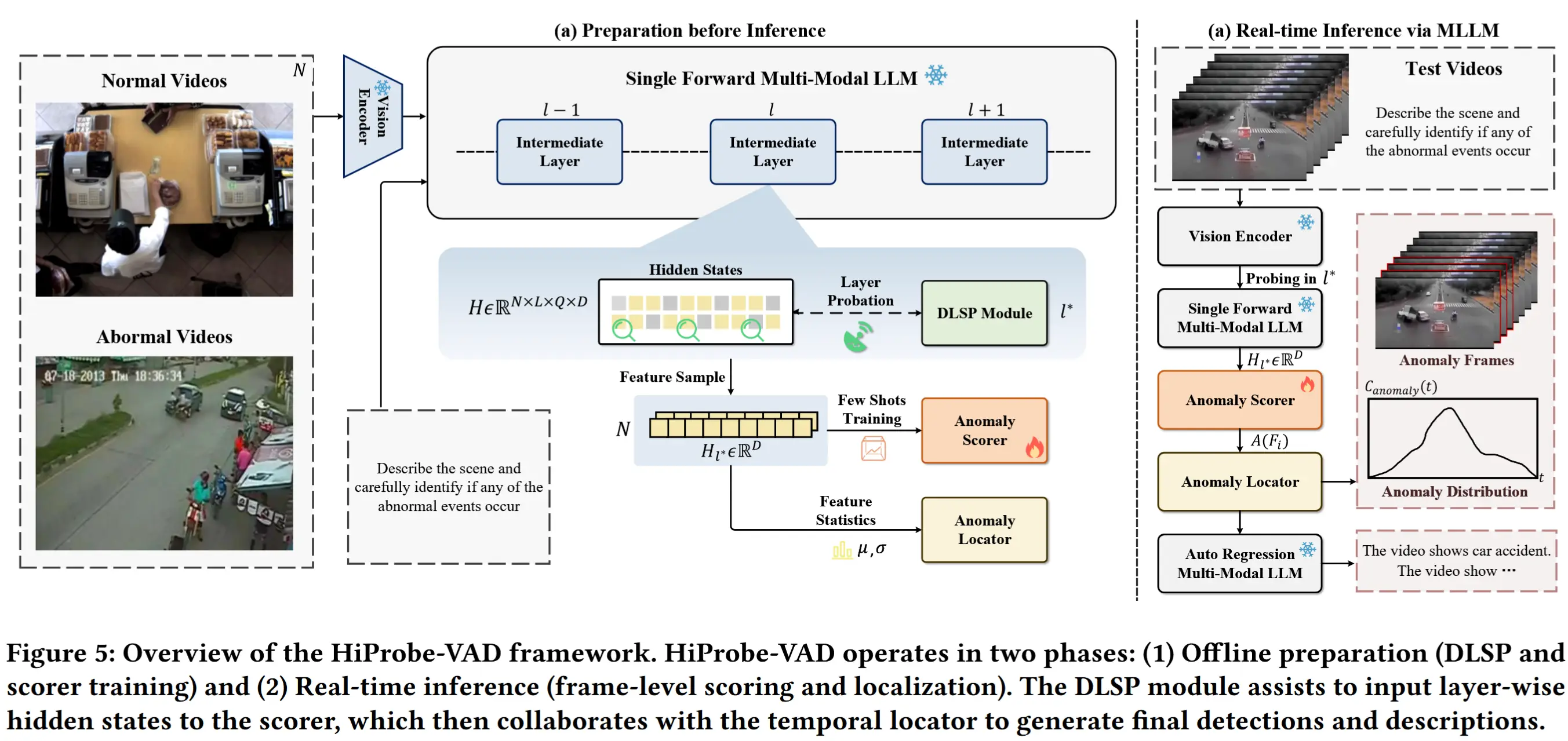
论文 - 《HiProbe-VAD: Video Anomaly Detection via Hidden States Probing in Tuning-Free Multimodal LLMs》 关键词 - ACM MM '25、多模态大模型MLLM、中间隐藏状态、免微调 1 引言 现有工作的
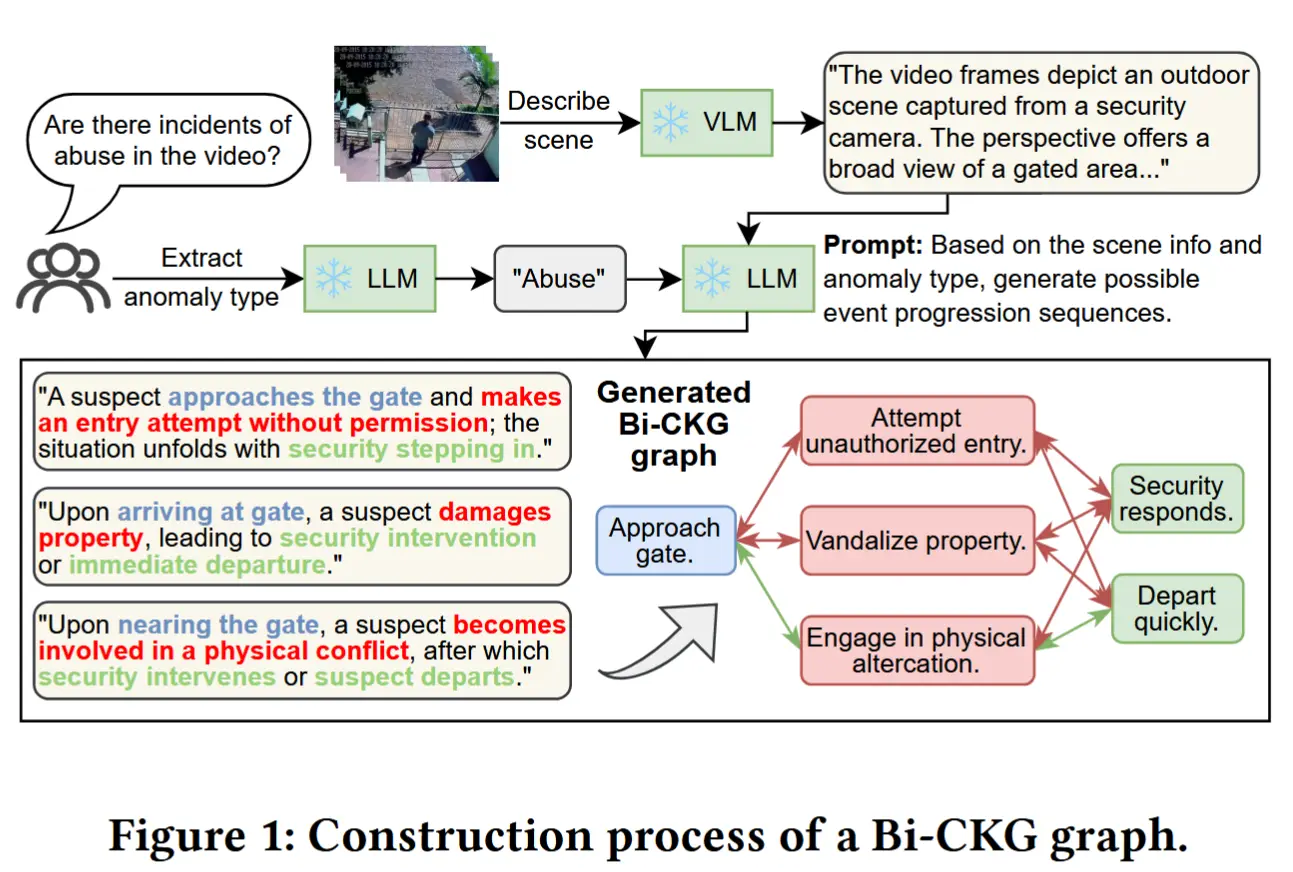
论文 - 《HoloTrace: LLM-based Bidirectional Causal Knowledge Graph for Edge-Cloud Video Anomaly Detection》 代码 - Github 关键词 - ACM MM2025、边缘-云协作、知识图谱、视频异常检
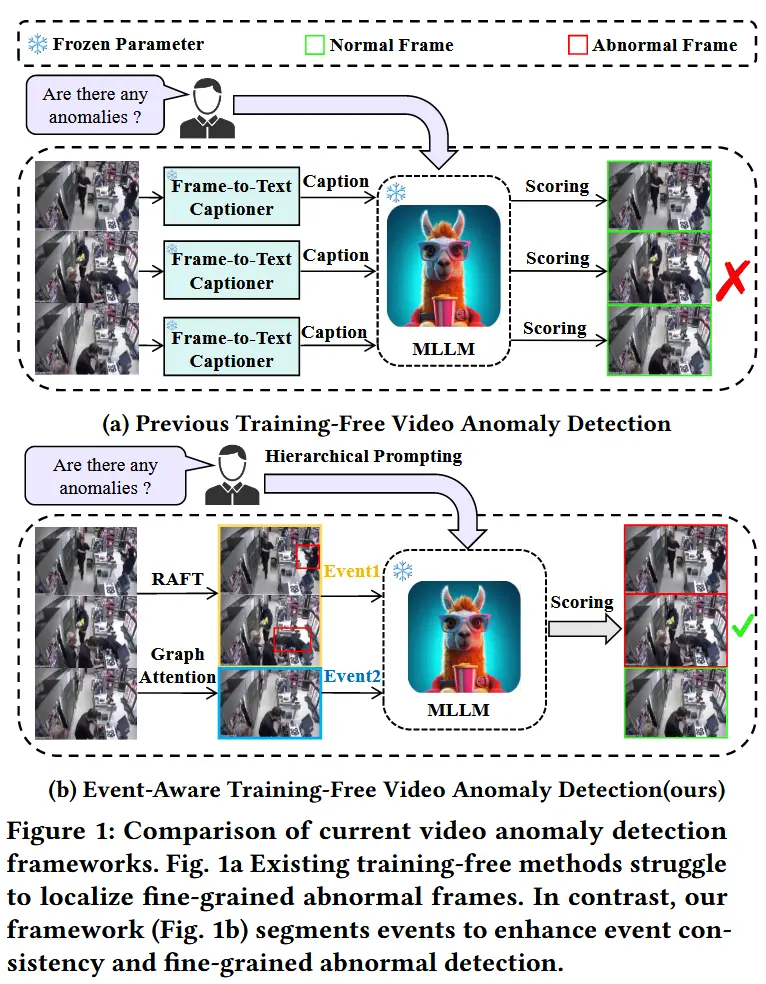
论文 - 《EventVAD: Training-Free Event-Aware Video Anomaly Detection》 代码 - Github 关键词 - 无需训练、视频异常处理、图注意力网络、异常边界判定、视频大模型VideoLLaMA 1 引言 研究问题 视频异常检测(VAD)致力
论文 - 《VideoLLM-online: Online Video Large Language Model for Streaming Video》 代码 - Github 关键词 - 流式视频、在线视频问答、视频大模型 1 引言 研究动机 现有大模型训练时通常将视频视为预定义的视频片段,导致
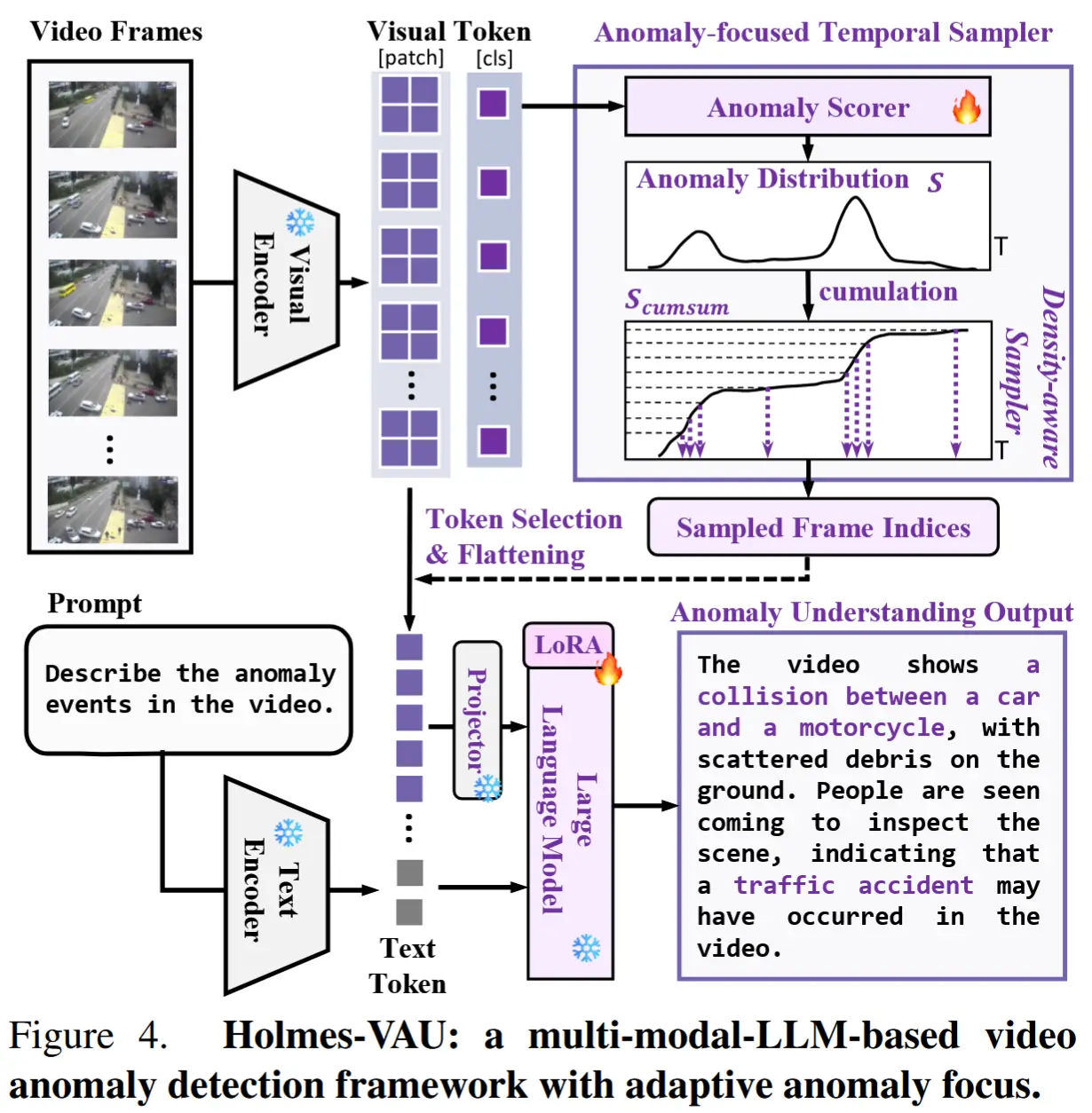
论文 - 《Holmes-VAU: Towards Long-term Video Anomaly Understanding at Any Granularity》 代码 - Github 关键词 - 指令微调数据集、InterVL2、视频大模型、视觉-语言大模型VLM、视频异常检测VAD、时序采
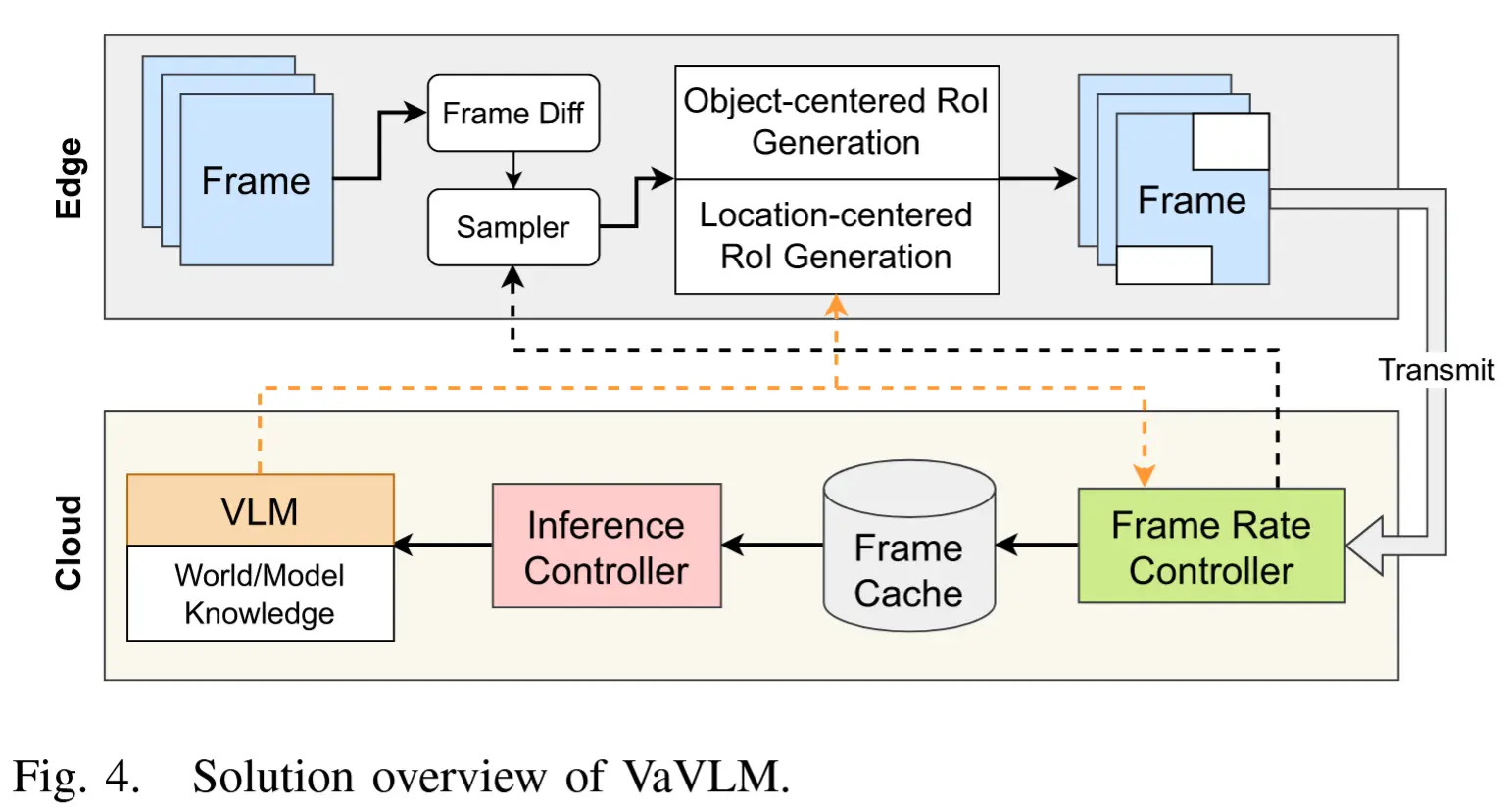
论文 - 《VaVLM: Toward Efficient Edge-Cloud Video Analytics With Vision-Language Models》 关键词 - 边缘智能、端云协作、边缘设备、任务特定推理、视频大模型、自适应抽帧、感兴趣区域 Rol、边缘推理 1 引言 现有工作
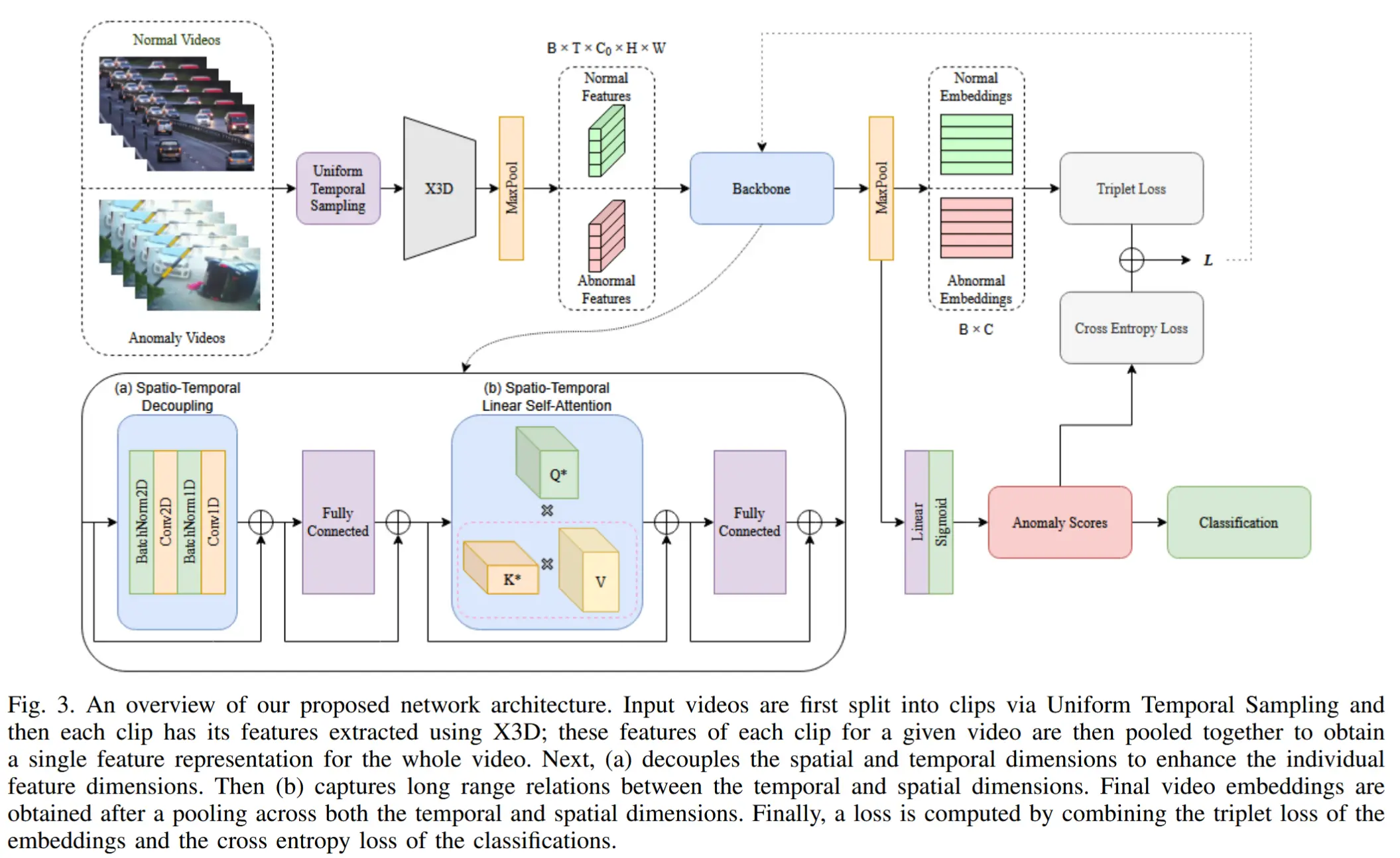
论文 - 《STEAD: Spatio-Temporal Efficient Anomaly Detection for Time and Compute Sensitive Applications》 代码 - Github 关键词 - 实时推理、轻量化、时空建模、视频异常检测VAD、I3D、X3
论文 - 《Follow the Rules: Reasoning for Video Anomaly Detection with Large Language Models》 代码 - Github 关键词 - 无需训练、Prompt 工程、视频异常检测VAD、视觉-语言模型VLM、基于规则推理
论文 - 《Flashback: Memory-Driven Zero-shot, Real-time Video Anomaly Detection》 关键词 - 实时高效视频异常检测、基于记忆库、零样本、可解释性、视觉语言大模型VLM、无需训练 1 引言 VAD 有两个根本性的障碍阻碍了其在现实
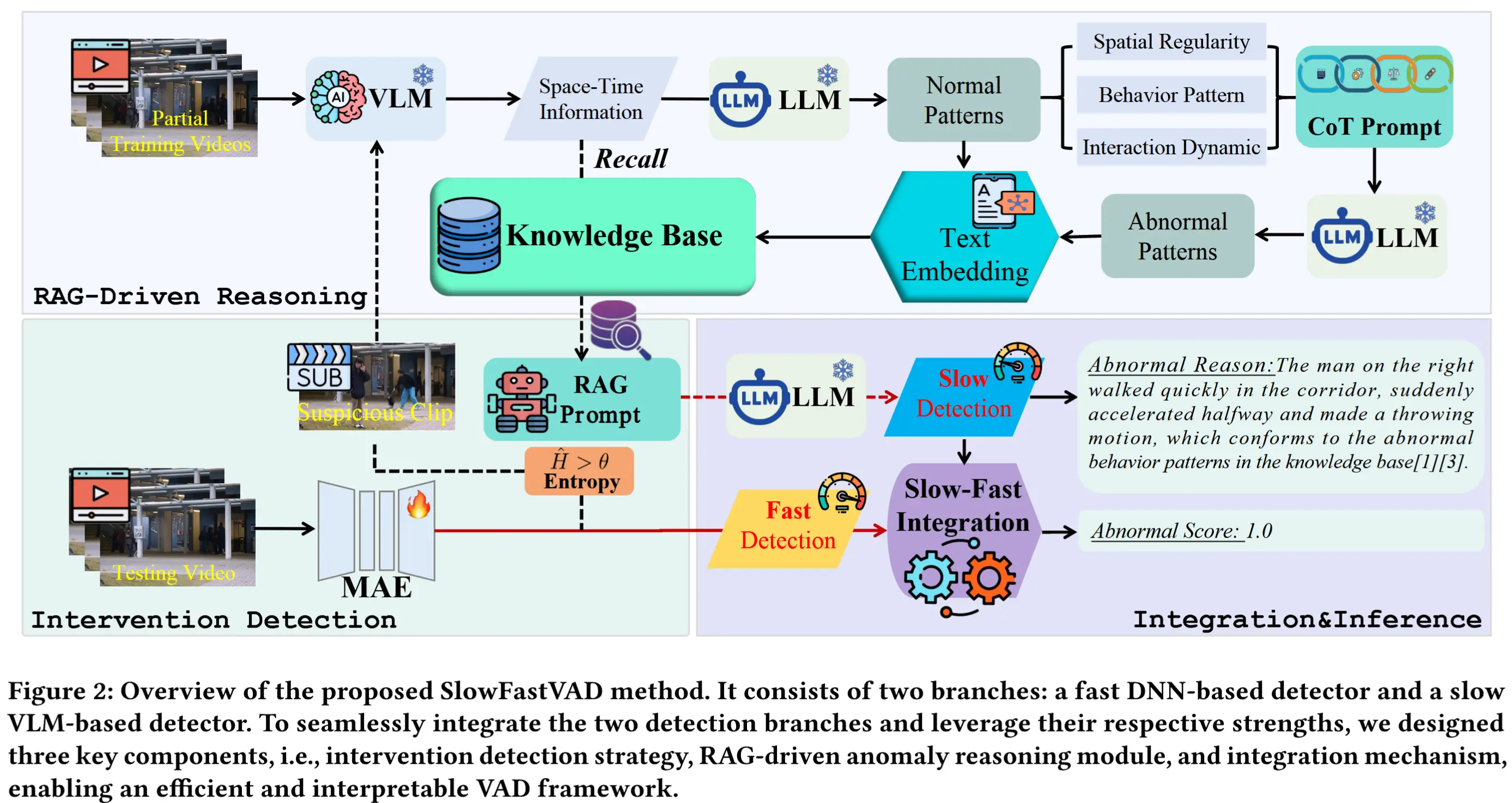
论文 - 《SlowFastVAD: Video Anomaly Detection via Integrating Simple Detector and RAG-Enhanced Vision-Language Model》 代码 - 预计开源 关键词 - 大小模型协作、视频异常检测、高效检测、
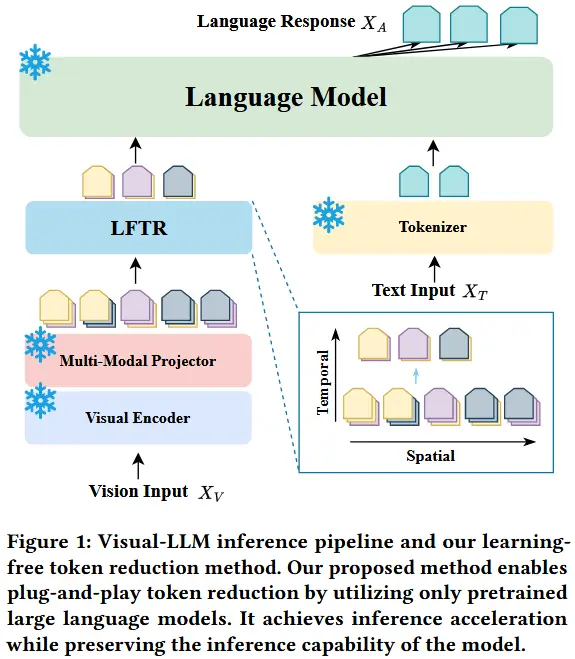
论文 - 《LFTR: Learning-Free Token Reduction for Multimodal Large Language Models》 关键词 - 即插即用、高效压缩、多模态大模型MLLM、视频、Token剪枝、时间空间、相似性、视频问答、无需训练 1 引言 动机:多模态大语
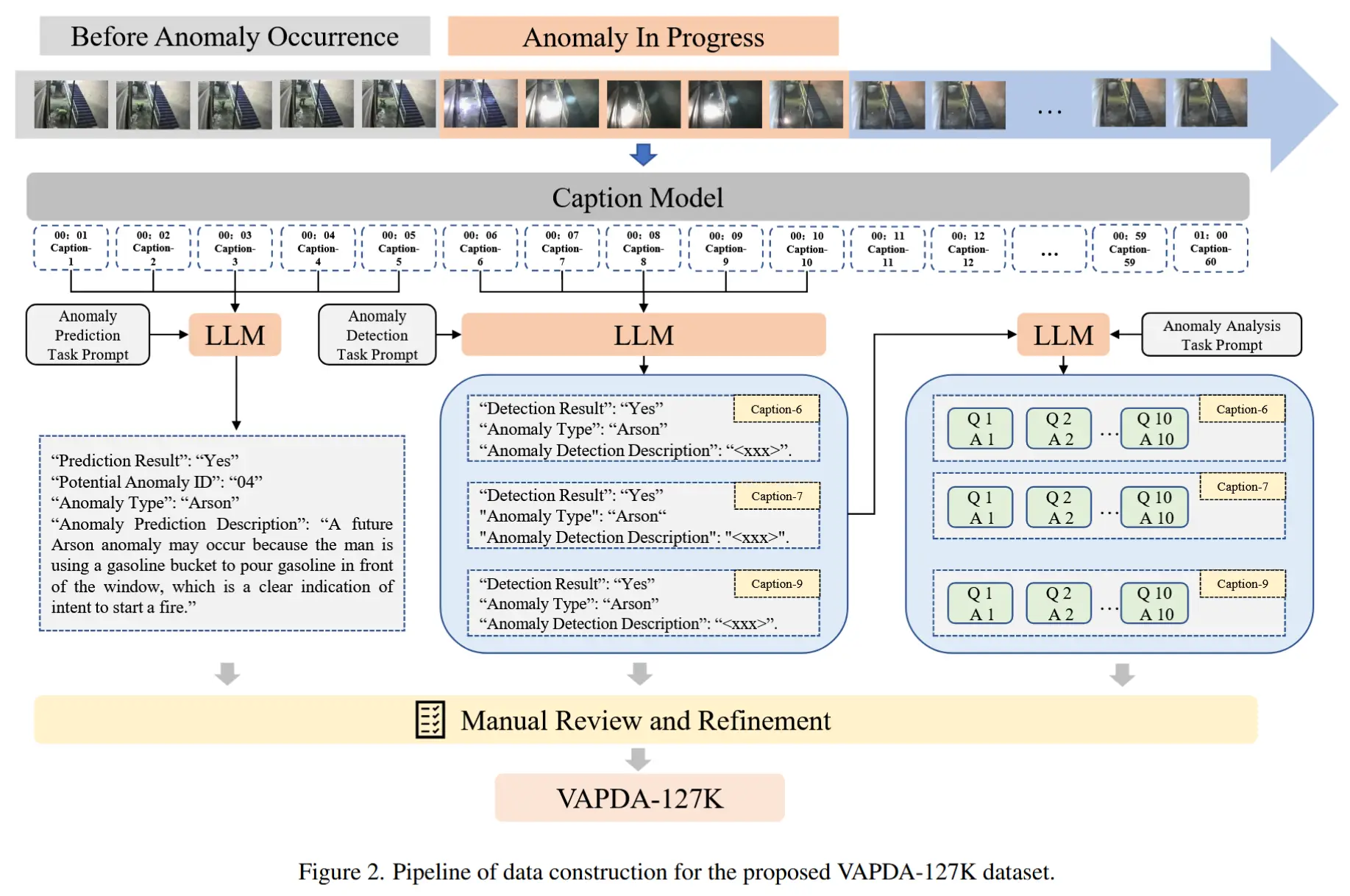
论文 - 《AssistPDA: An Online Video Surveillance Assistant for Video Anomaly Prediction, Detection, and Analysis》 代码 - 预计开源 关键词 - 实时、视频异常检测VAD、新数据集、Qwen-
论文 - 《Harnessing Large Language Models for Training-free Video Anomaly Detection》 代码 - Github 关键词 - 视觉-语言模型VLM、大模型LLM、视频异常检测、无需训练、prompt工程设计 摘要 研究问题 视
论文 - 《HARGPT: Are LLMs Zero-Shot Human Activity Recognizers?》 代码 - Github 关键词 - 评估工作、大模型GPT-4、人类活动识别HAR、零样本 注意这是一篇评估现有工作的文章。 摘要 研究问题:LLMs 是否具备零样本的人类活动
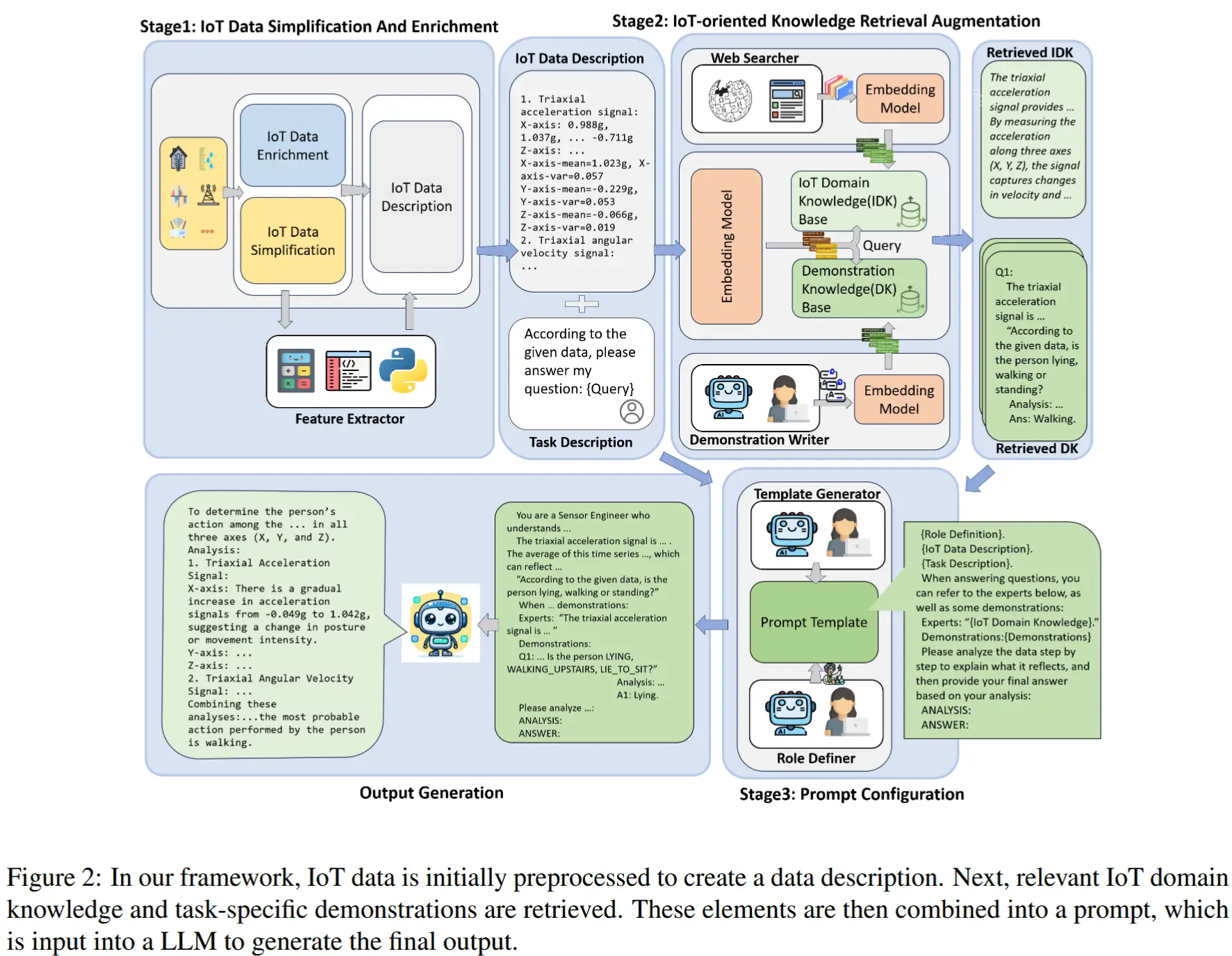
论文 - 《IoT-LLM: Enhancing Real-World IoT Task Reasoning with Large Language Models》 关键词 - 物联网感知、数据增强、检索增强生成RAG、通用性方法、思维链CoT、大模型LLM、人体活动识别HAR、医疗诊断、人类定位、
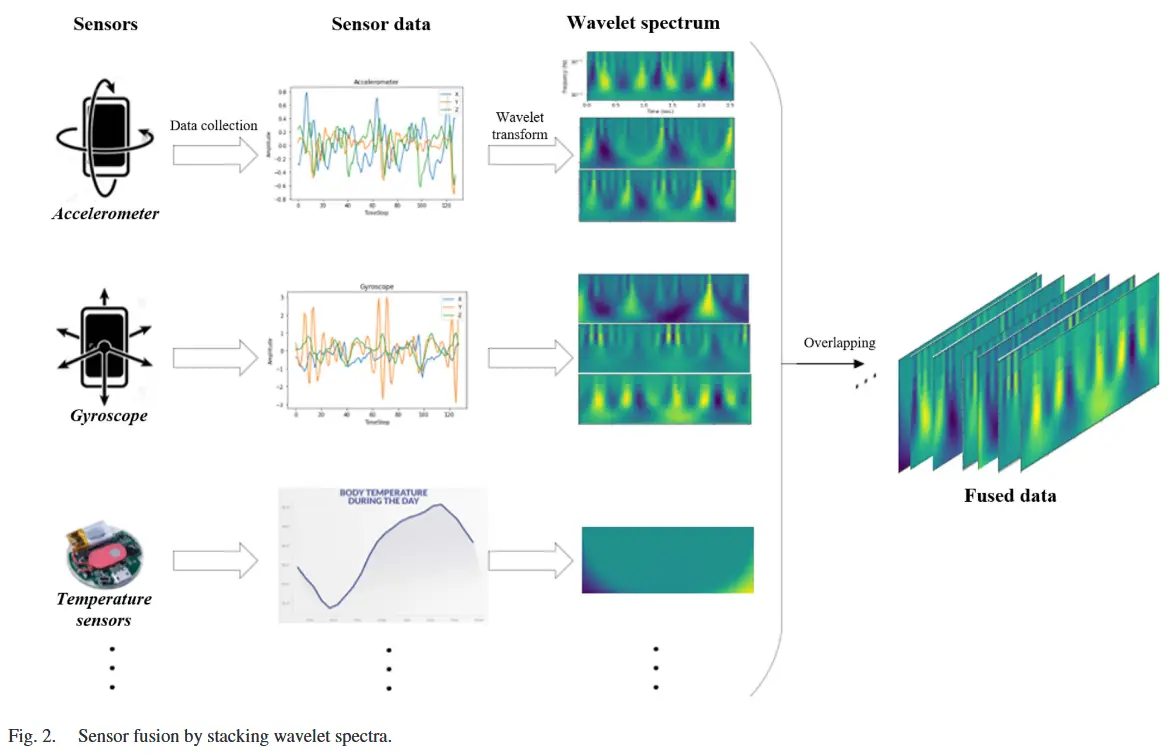
论文 - 《Bi-DeepViT: Binarized Transformer for Efficient Sensor-Based Human Activity Recognition》 关键词 - 高效、二值化、DeepViT、HAR、传感器 1 引言 人体活动识别(HAR)是一种通过传感器采集