- 论文 - 《Holmes-VAU: Towards Long-term Video Anomaly Understanding at Any Granularity》
- 代码 - Github
- 关键词 - 指令微调数据集、InterVL2、视频大模型、视觉-语言大模型VLM、视频异常检测VAD、时序采样器
1 引言
- 研究问题:如何让模型理解在不同时间尺度和情境下发生的视频异常?
- 现有工作不足之处
- 现有的 VAU 数据集通常只提供单一粒度的标注信息,缺乏包含层次化标注的数据集(即同时涵盖短期和长期异常),这限制了模型理解那些需要扩展上下文推理的异常。
- 在面向长期视频异常理解的任务中,效率仍然是一个关键挑战。以往方法通常依赖于均匀帧采样,这容易遗漏关键异常帧,或带来巨大的计算开销 [25, 47, 67]。
- 本文工作
- HIVAU-70k 数据集
- 作者开发了一个半自动化标注引擎 ,通过将人工视频分段与基于 LLMs 的递归自由文本标注相结合,高效地扩展高质量的标注。该过程包括三个关键阶段:
- 层次化视频解耦: 手动识别异常事件,并将其分割为较短的片段。
- 层次化自由文本标注: 每个片段的描述由人工撰写或通过视频描述模型生成,然后利用 LLM 对其在事件级和视频级进行摘要总结。
- 层次化指令构建: 通过将描述和摘要与设计好的提示词结合,将文本数据转化为问答形式的指令提示,从而构建出一个具备丰富标注的训练与评估数据集。
- 利用该标注引擎,得到了 HIVAU-70k ,这是一个具有层次化指令的大规模视频异常理解基准数据集。包含超过 70,000 条多粒度的指令数据,按照 clip-level、event-level 和 video-level 进行组织。
- 作者开发了一个半自动化标注引擎 ,通过将人工视频分段与基于 LLMs 的递归自由文本标注相结合,高效地扩展高质量的标注。该过程包括三个关键阶段:
- Holmes-VAU 方法
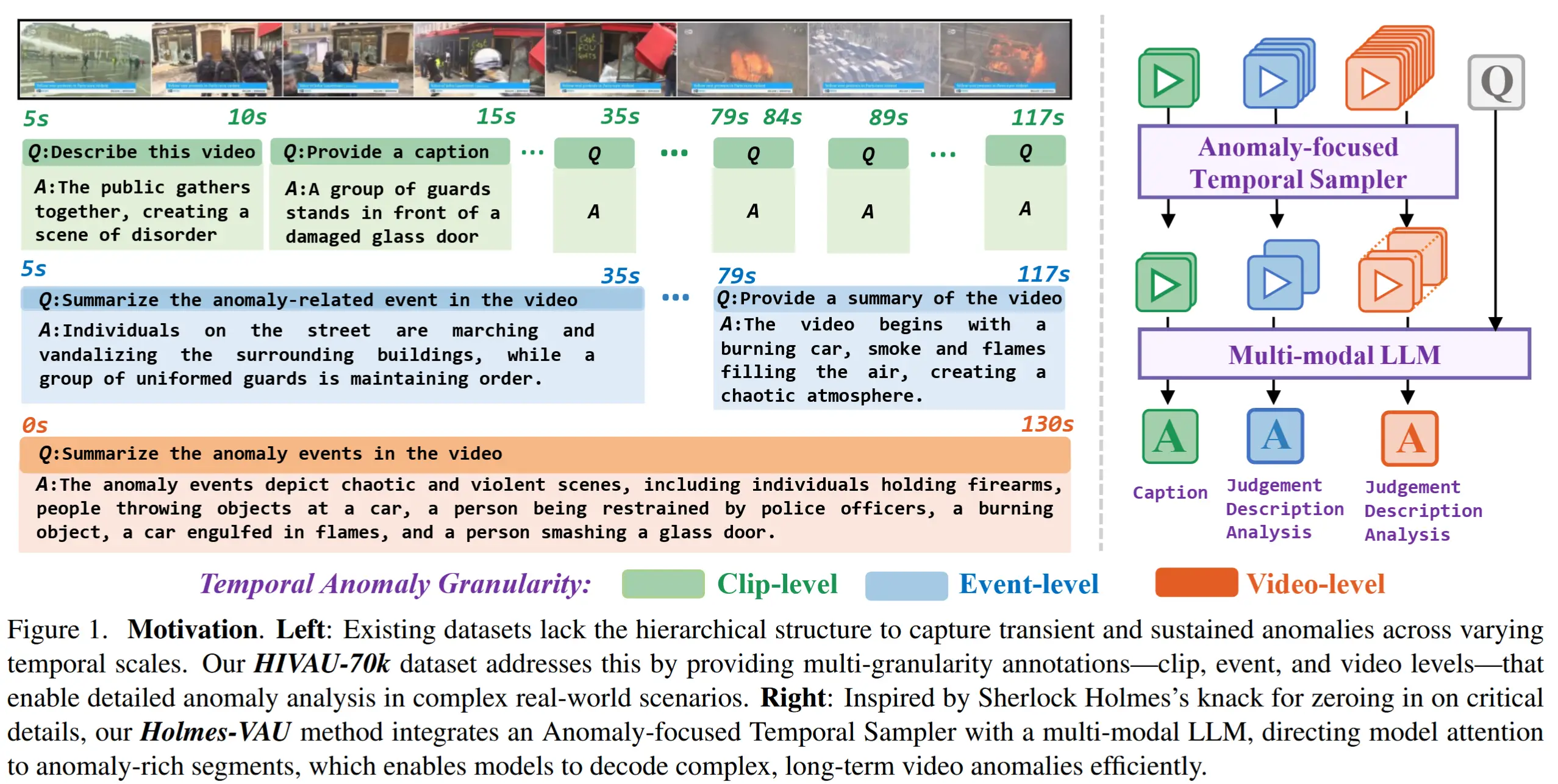
- Holmes-VAU 将所提出的 异常聚焦时序采样器(Anomaly-focused Temporal Sampler, ATS) 与多模态视觉-语言模型相结合,实现高效的长期视频异常理解。
- ATS 将异常评分模块与密度感知采样模块相结合,根据帧的异常得分自适应地选择关键帧。这种设计确保视觉-语言模型专注于异常密集区域,从而显著提升了处理效率与准确性。
- HIVAU-70k 数据集
2 相关工作
视频异常检测和多模态视频异常理解的相关工作略过。
- 层次化视频理解
- 为了更好地理解视频内容,许多先前的研究从数据集和模型两个方面出发,探索了层次化视频理解。
- [3, 24, 32, 35, 45, 54] 提出了细粒度动作识别与定位的数据集。
- [16] 为长达一小时的视频在多个时间尺度上提供了自由形式的层次化描述。
- [8, 18, 38, 43, 60, 69] 在不同层次上训练模型以获得更好的视频特征表示。
- 与这些研究不同,本文将研究重点放在视频异常理解 领域,从而填补了该领域在多尺度标注方面的空白。
3 HIVAU-70k 数据集
3.1 任务描述
HIVAU-70k 聚焦于视频异常理解 VAU 任务,该任务包含两个核心方面:
- 事件异常检测:旨在为视频中的每一帧预测一个异常得分。
- 异常可解释性:给定一个视频和一个文本查询,生成一个与异常相关的回答 。
3.2 基于 LLM 的数据引擎
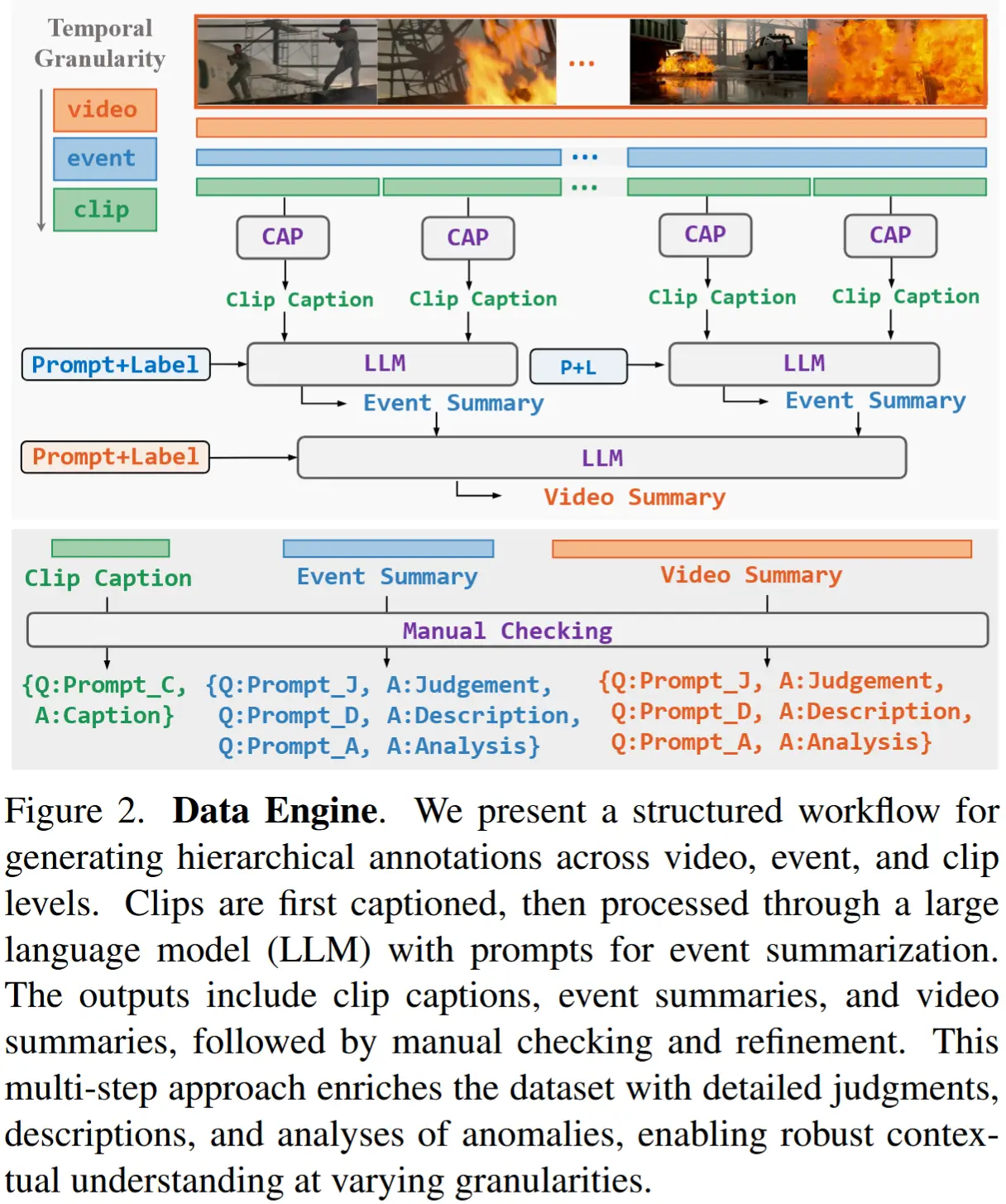
本文开发的半自动化标注引擎如图 2 所示,包含三个步骤,接下来依次介绍。
层次化视频解耦
视频来源于 UCF-Crime 和 XD-Violence 数据集的训练集,进行以下处理:
-
对于异常视频
- 首先手动标注视频中每个异常事件的时间边界,非连续的异常状态被视为不同的事件。
- 然后,将每个事件分割为随机长度的片段。
-
对于正常视频
- 采用随机采样的方式获取不同粒度的片段。
最终,获得了5443个视频、11076个事件和55806个片段。
层次化自由文本标注
目的:提取片段级视频中的语义信息。
具体步骤:
- 首先,使用了现成视频理解模型 LLaVANext-Video 来为每个片段生成详细的描述性文本。
- 随后,使用 Llama 3 对同一事件下的所有片段描述进行整合,生成事件级摘要。具体而言,作者将事件的类别标签注入 prompt 中,并设计 prompt 来引导 LLM 为每个异常事件摘要生成三部分内容:
- Judgment:判断是否存在异常,并指出其具体类别。
- Description:对异常或正常事件进行详细描述。
- Analysis:对异常判断的推理过程,包括因果分析等。
- 最后,将所有事件级摘要进一步整合,生成视频级摘要。
层次化指令数据构建
概述:为了构建适用于 VLM 的指令调优数据集,作者将前面生成的自由文本标注与预设的异常相关用户指令进行匹配。
具体来说:
- 对于片段级 内容,仅构造与“Description”相关的指令,因为短片段难以支持深入的异常分析。
- 对于事件级和视频级 内容,从 "Judgment"、"Description"、"Analysis" 三个维度构建指令数据。
3.3 HIVAU-70k 数据统计
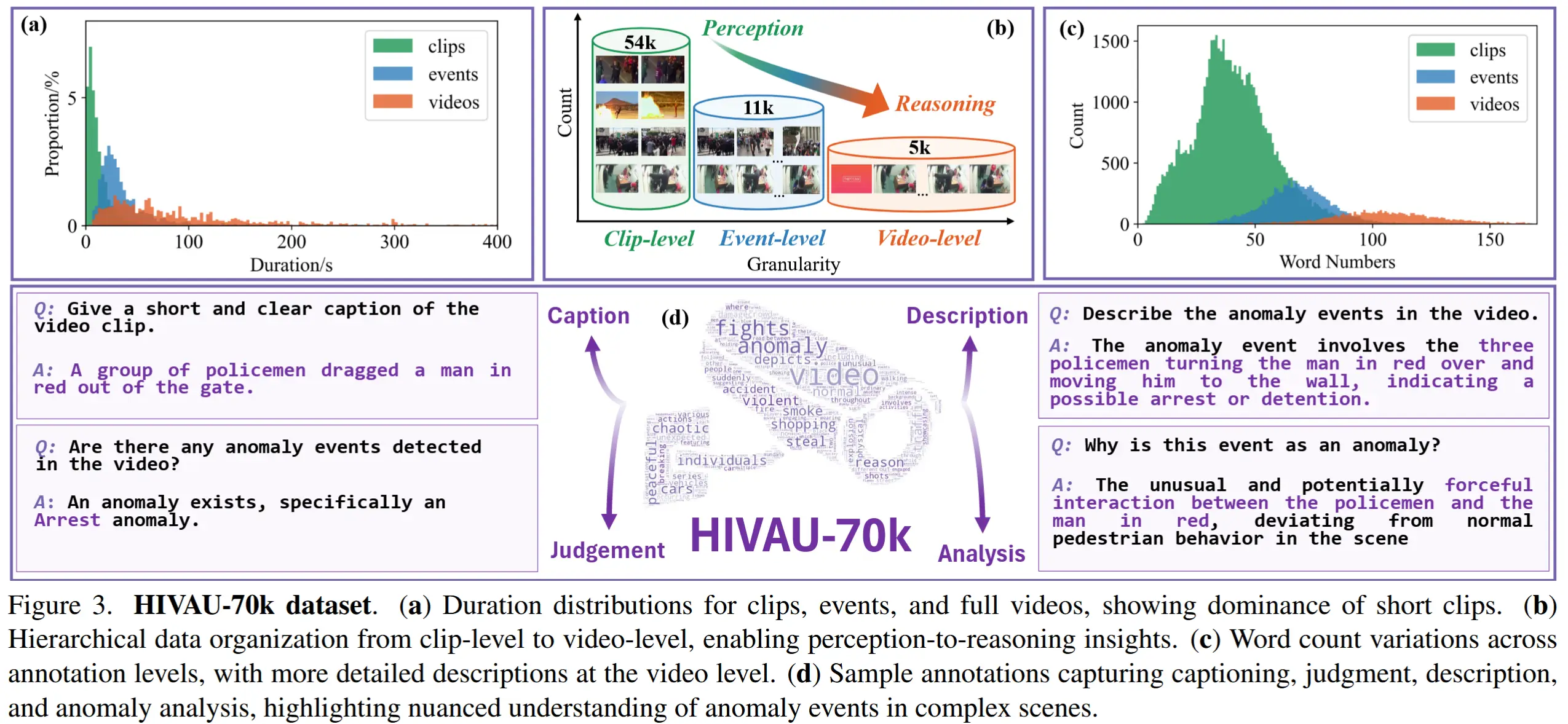
利用第 3.2 节所提出的标注引擎,引入了数据集 HIVAU-70k,如图 3 所示。
- 如图3(b)所示,HIVAU-70k包含超过70,000个多粒度标注,分别组织在片段级、事件级和视频级,实现了从感知到推理的层次递进。
- 如图3(a)和(c)所示,不同粒度下的片段时长和文本标注词数呈现出显著的分布差异。
- 如图3(d)所示,HIVAU-70k的指令数据涵盖了针对现实世界异常的 Caption、Judgment、Description 和 Analysis,引导模型发展短期与长期的视频异常理解能力。
4 Holmes-VAU
主要动机:以往的VAU方法在注意力分配上存在不足:例如密集窗口采样引入冗余信息,而均匀帧采样常常遗漏关键异常帧,限制了其在短视频上的应用。
解决办法:异常聚焦时序采样器(ATS)。
4.1 整体流程
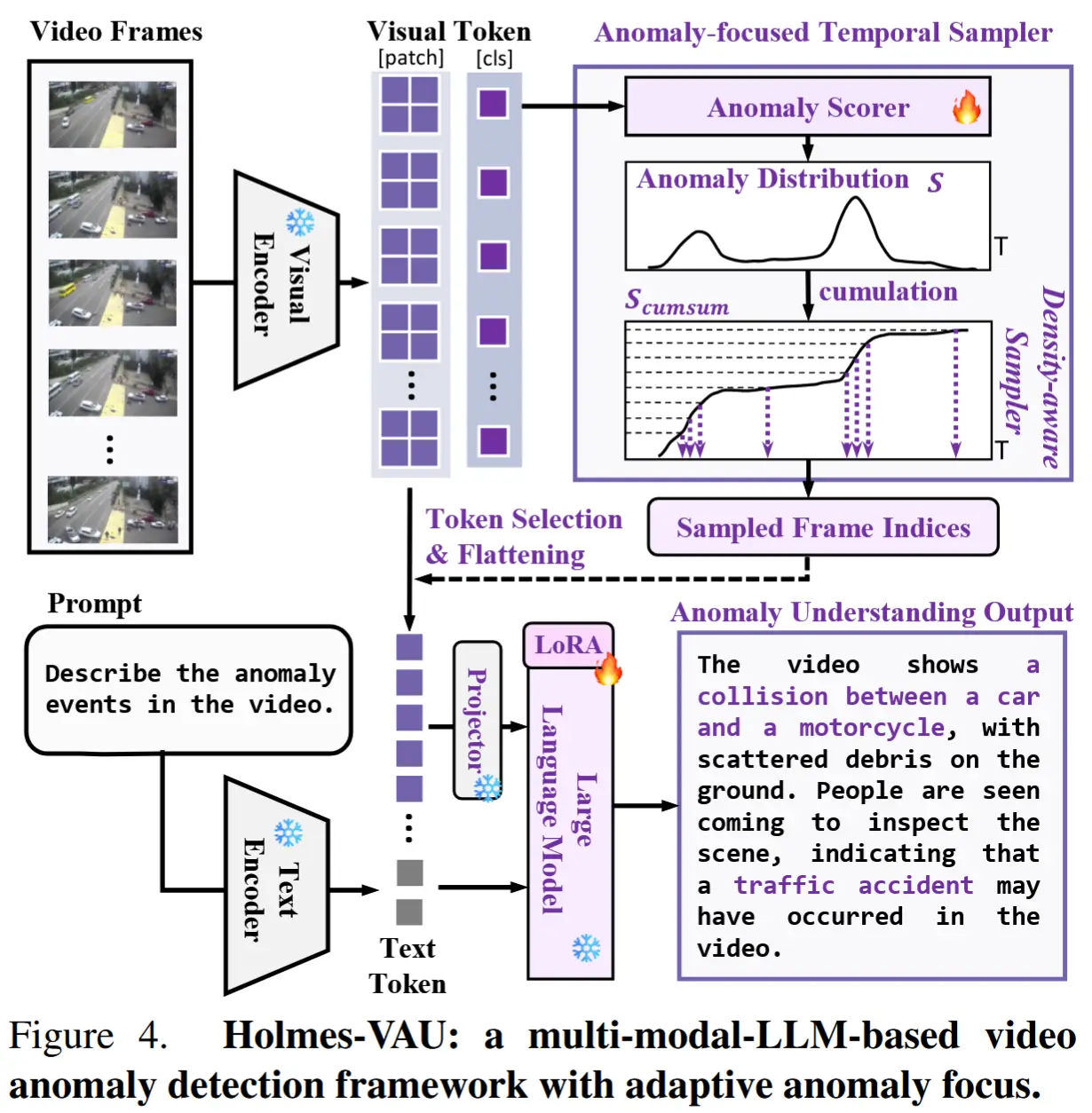
Holmes-VAU 模型的整体流程如图4所示。
- 视频帧首先由视觉编码器处理,生成视觉token。
- 视觉 token 被送入 ATS,该模块结合异常评分器和累积和(S_{cumsum})机制来选择关键帧。
- 同时,文本编码器处理输入提示语。
- 最后,将视觉与文本表示输入一个经过LoRA微调的预训练语言模型中,生成对检测到的异常的描述。
4.2 模型架构
视觉和文本嵌入
冻结的视觉编码器来自 InternVL2 , CLIP-ViT 结构,将此编码器表示为 \phi_v。以每16帧的间隔从输入视频中采样密集的视频帧。每个视频帧通过视觉编码器进行处理,以获得对应的视觉token。给定输入视频帧序列 \mathcal{V} \in \mathbb{R}^{T \times H \times W \times C},第 i 帧的输出特征可以表示为:
其中,v_i^{cls} 表示类别 token,N_p 表示patch的数量。
文本编码器 \phi_t 也初始化自 InternVL2,包括一个 tokenizer 和一个嵌入层。提示文本 Q 通过文本编码器转换为文本token:X_q = \phi_t(Q)。
异常聚焦时序采样器 ATS
ATS 包含两个主要组件:异常评分器 和 密度感知采样器。
异常评分器 \phi_s 是一个基于特征的 VAD 网络,用于估计每一帧的异常得分。作者采用了 [74] 中的网络结构(简单且性能良好)。给定视频帧的类别token集合 \{v_1^{cls}, v_2^{cls}, \dots, v_T^{cls}\},可以计算出每一帧的异常得分:s_i = \phi_s(v_i^{cls}) 。
密度感知采样器的动机:异常帧通常比正常帧包含更多信息,并表现出更大的变化性。这一观察结果表明应在高异常得分区域采样更多帧,同时减少低异常得分区域的采样。
密度感知采样器 从总共 T 个输入帧中选择 N 个帧。具体而言,将异常得分 S \in \mathbb{R}^T 视为概率质量函数,并首先沿着时间维度对它们进行累积求和,得到累积分布函数,记为 S_{cumsum}:
然后,在累积轴上均匀采样 N 个点,并将这些点映射到累积分布 S_{cumsum} 上。对应的时间轴上的 N 个时间戳被映射到最近的帧索引,最终形成采样的帧索引集合,记为 \mathcal{G}。参数 \tau 用于控制采样的均匀性。
投影器和 LLM
选择与采样帧对应的 token,即 \mathcal{G},作为视觉嵌入。然后,使用投影器 \phi_p 将视觉嵌入映射到语言特征空间。最后,将这些嵌入与文本嵌入拼接起来,输入 LLM,并计算目标答案 X_a 的概率。上述过程可以表示如下:
其中:
- \text{cat}[\cdot] 表示拼接操作;
- \theta 是可训练的参数;
- X_{ins, <i}, X_{a, <i} 分别是当前预测token x_i 之前的所有指令token和答案token;
- L 是序列的长度。
4.3 训练与测试
- 训练 按照以下两步:
-
(1)使用来自 HIVAU-70k 的视频数据和标注的帧级标签(\hat{y} \in \mathbb{R}^T),来训练异常评分器。
\mathcal{L}_{AS} = -\sum_{i=1}^{T} (s_i \log(\hat{y}_i) + (1-s_i) \log(1-\hat{y}_i)) \tag{5} -
(2)固定异常评分器,并使用 HIVAU-70k 中的所有指令数据来训练模型。采用 LoRA 进行微调,优化预测token与真实token之间的交叉熵损失。
-
- 测试
- 在测试阶段,用户输入一个视频和文本提示,模型将根据用户的指令生成相应的文本响应。
5 实验
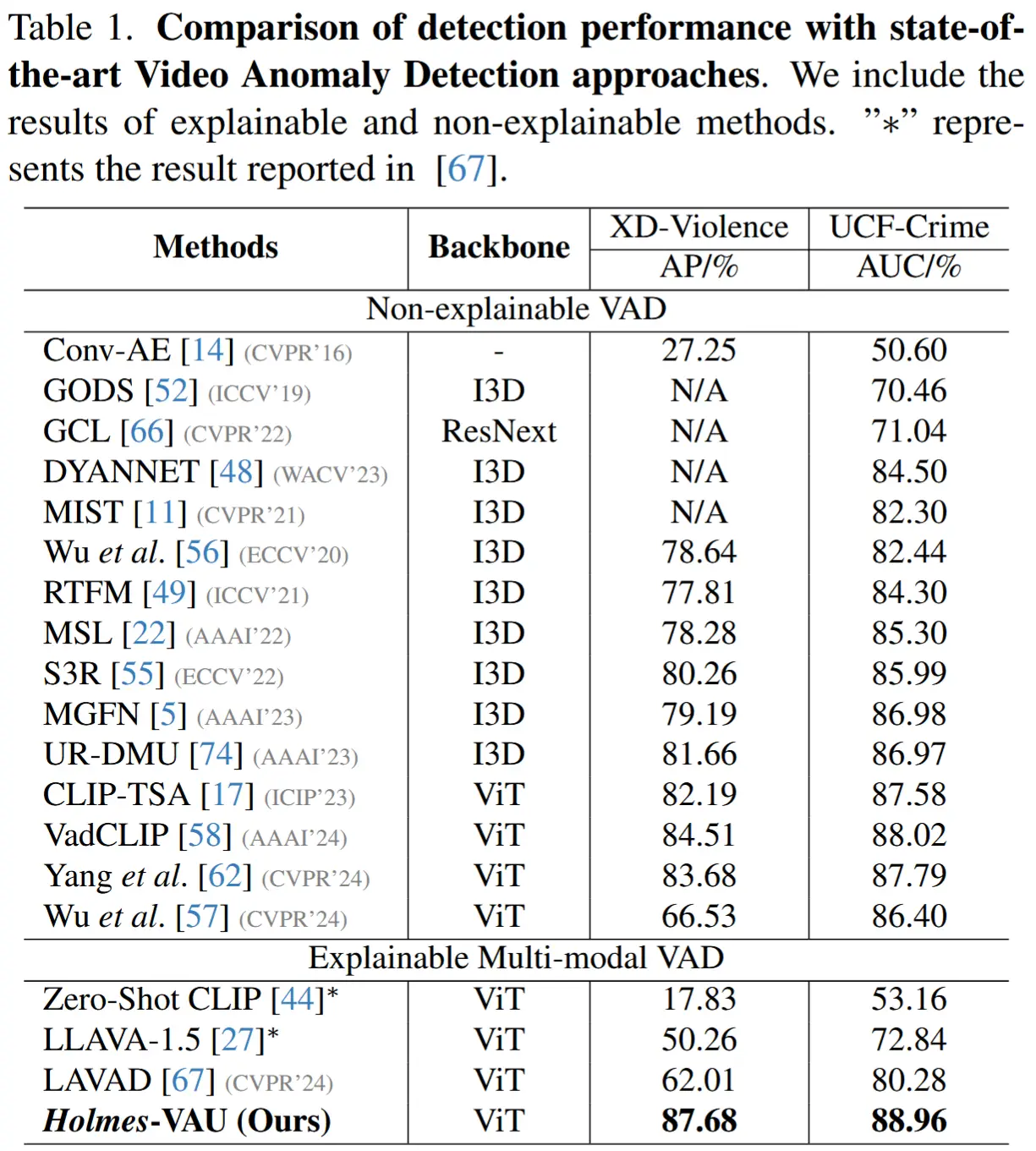
- 表1 与 SOTA 视频异常检测方法比较
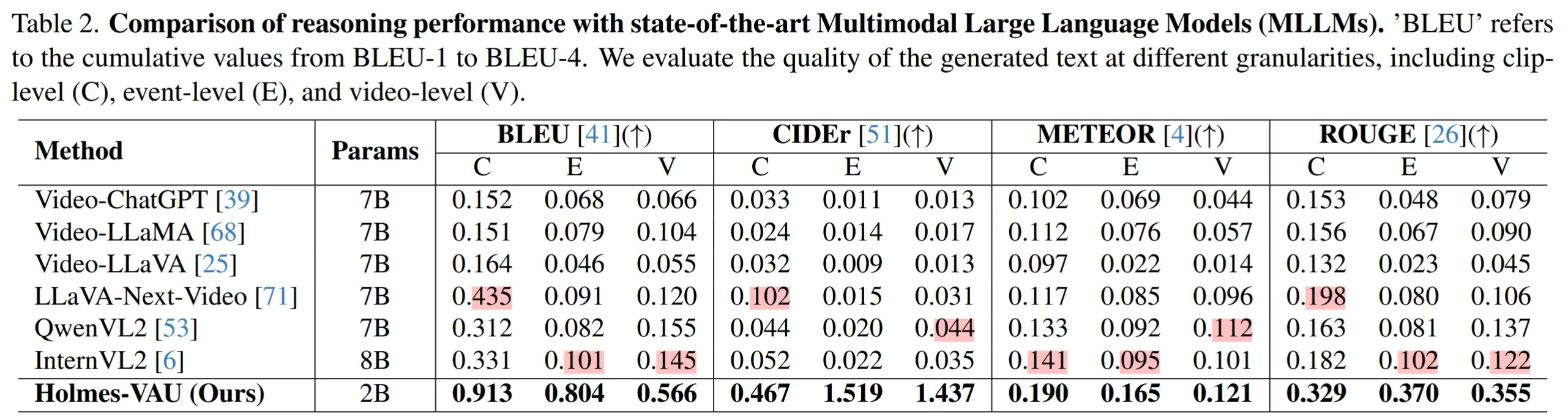
- 表2 与 SOTA 通用 MLLMs进行比较
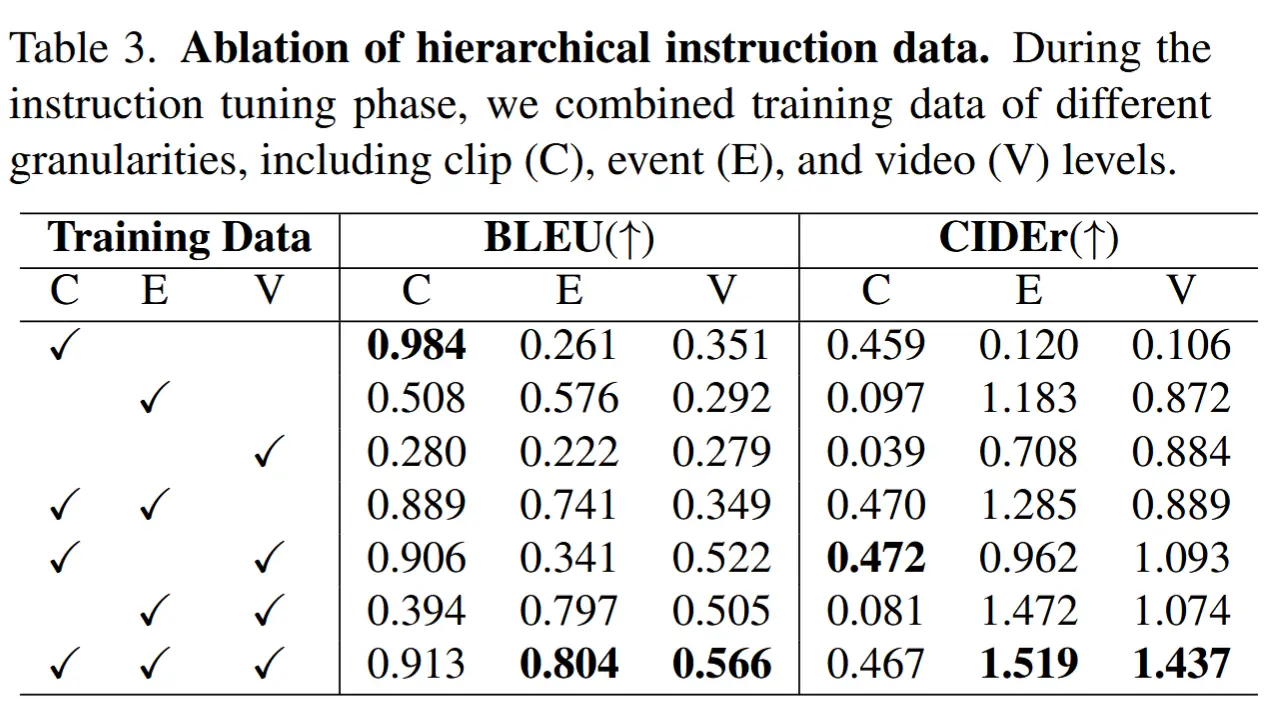
- 表3 消融不同层次化指令的组合
- 使用不同的指令微调数据:C片段级、E事件级、V视频级。
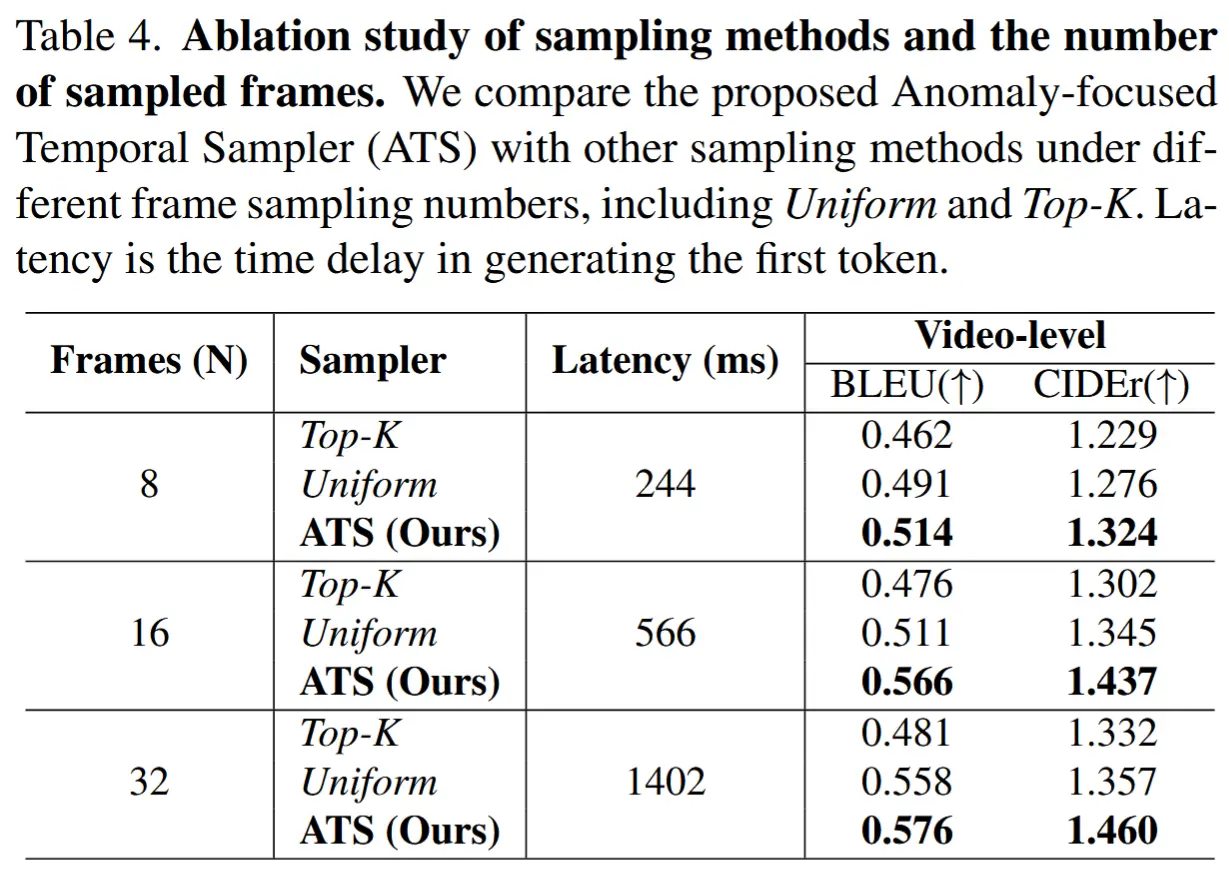
- 表4 消融不同的采样方法和采样帧数的影响
- 在均匀采样中,从所有帧中均匀抽取 N 帧;而在 Top-K 采样中,选择异常得分最高的前 N 帧。