- 论文 - 《VideoLLM-online: Online Video Large Language Model for Streaming Video》
- 代码 - Github
- 关键词 - 流式视频、在线视频问答、视频大模型
1 引言
- 研究动机
- 现有大模型训练时通常将视频视为预定义的视频片段,导致在处理流式视频输入时效率低且效果不佳。
- 本文贡献
- LIVE(Learning-InVideo-Stream)框架
- 能够在连续视频流中实现事件对齐、长上下文且实时的对话交互。
- LIVE包含:
- 一种专为连续流式输入设计的语言建模训练目标。
- 一种将离线时序标注数据转换为流式对话格式的数据生成方案。
- 一种优化的推理流程,LIVE 利用连续的键值缓存技术来支持流式辅助任务,并将快速的视觉编码与较慢的语言解码过程并行化。
- 与逐帧对话的方法不同,LIVE 引入了一种新颖的训练目标——流式 EOS 预测,使模型能够学习在视频流中何时应生成响应、何时保持静默。
- VideoLLM-online 模型
- 基于LIVE框架,采用 CLIP 作为视觉编码器,在Llama2/Llama-3基础上构建。
- 该模型平均可在5分钟的视频片段中以超过10帧每秒的速度支持流式对话。
- 该模型在多个公开的离线视频基准任务(如动作识别、视频描述生成和未来预测)上也达到了当前最先进的性能。
- LIVE(Learning-InVideo-Stream)框架

2 方法
2.1 视频流式对话
问题定义
给定时间 t = t_1 之前的上下文序列,记为 [\text{Ctx}^{t < t_1}] ,该上下文可能包含先前的视觉-语言内容(例如,历史用户查询、视频帧、助手回复),以及从 t_1 到 t_2 的持续视频流,记为 [\text{Frame}^{t_1 \leq t \leq t_2}] ,我们的目标是:
(1) 确定当前时间 t_2 是否适合进行语言建模;
(2) 如果确定了 t_2 ,则执行语言建模:
其中, [{\text{Txt}}_i^t] 表示在时间戳 t 的第 i 个位置的理想语言标记, [\text{F}] 是 [\text{Frame}] 的缩写。
流式EOS预测
为了解决上述问题,首先考虑一种更高效的逐帧聊天方法:简单地将“EOS”标记作为 t_1 \leq t < t_2 期间的聊天内容。然而,这种方法仍然不够理想。对话提示模板(例如,在Llama 中的 [INST]、[/INST] 和空格标记)每帧仍会消耗大量token,这对于流式视频中的大量帧来说并不有利。此外,序列中过多的EOS标记会显著增加语言模型的困惑度(perplexity)。
为此,作者提出了一种新的训练目标,称为“流式EOS预测”,以解决这一问题。仍然假设 t_2 是解码语言所必需的;因此,正常学习语言建模:
然而,对于冗余的时间戳 t_1 \leq t < t_2 (这些时间戳对生成答案没有贡献),直接学习模型预测帧标记上的EOS标记,即:
通过这种方式,“跳过”了不必要的对话回合,并学会了如何确定何时对流式输入进行语言解码。在推理过程中,如果某个帧预测了EOS,则可以直接请求下一帧作为输入。同时,EOS标记不会被添加到上下文中,以防止其影响语言建模。因此,这项任务并不是关于下一个词的预测;然而,它可以与自回归损失结合,用于训练流式视频对话模型。
注意,这里提到的EOS标记并不局限于语言模型中实际使用的EOS标记(例如,Llama中的 </s>)。只要在系统提示中明确指定,可以使用任何标记或引入新标记。在此仅使用“EOS”一词是为了简化表述。
2.2 数据
对于流式收集的数据集(如Ego4D),使用原作者收集时为人类注释者提供的指令给模型,指导模型模拟人类注释者,在5分钟的视频(约600帧,2 FPS)中流式生成叙述。
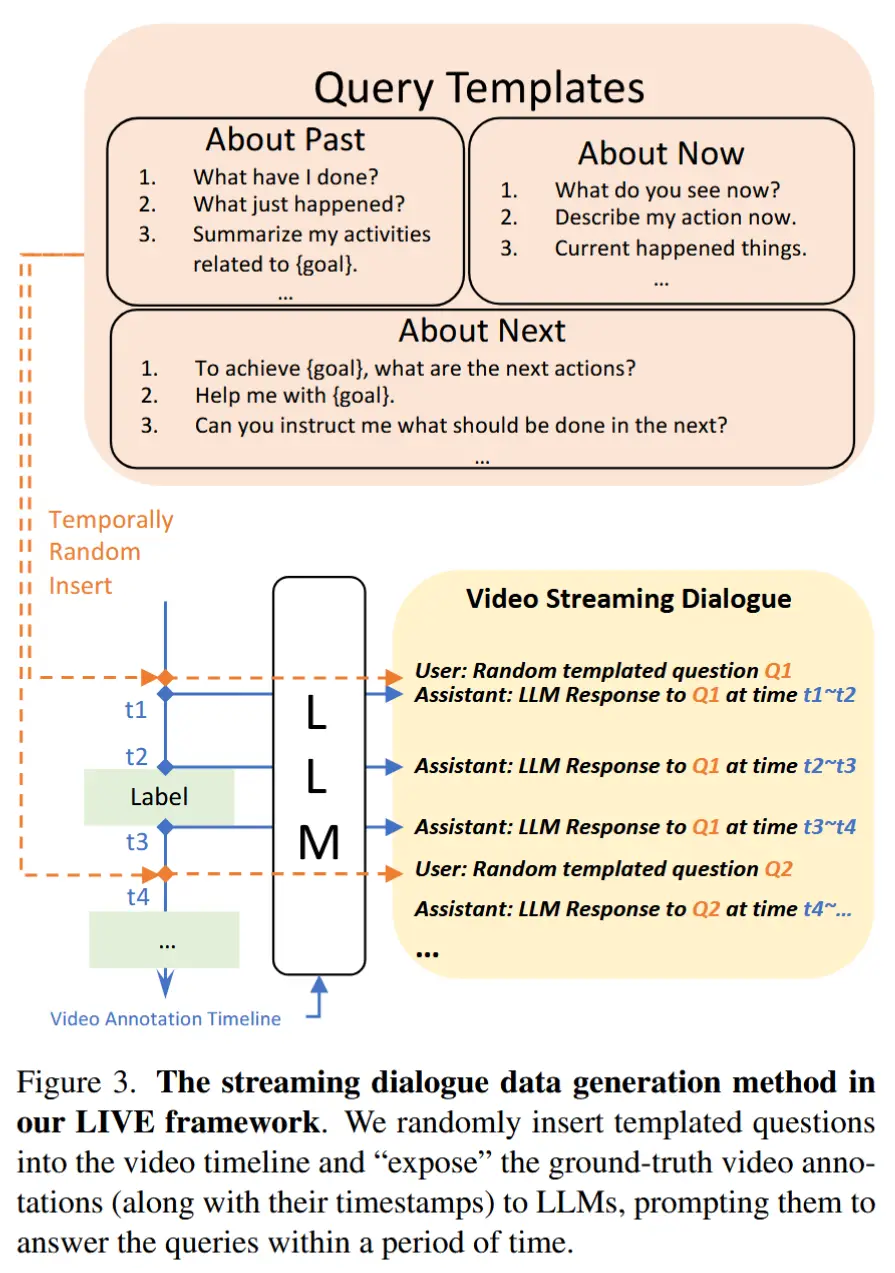
对于其他的主流视频数据集,它们仅包含与基本语言描述配对的时间段标注。为此作者提出了一种利用这类数据集合成对话数据的方法,如图3所示,核心思想是利用 LLM 基于视频标注生成用户-助手对话,具体步骤如下:
- 准备问题模板库,随机抽取一个问题。
- 从离线数据集中获取视频标注时间轴。例如,“时间 t_a∼t_b :烧水“。
- 提示 LLM 在每个关键时间点生成响应。例如,t_a 和 t_b 生成响应。
- 最终,在训练期间:(1)随机采样一个查询并加载其在关键时间点的响应。(2)随机插入一个查询到视频的一个时间戳 t_r。(3)丢弃在 t_r 之前的所有响应,并在 t_r 处添加一个新的响应。不同查询可以插入到同一个视频中,只需在新查询插入时间戳之后丢弃前一个查询的响应即可。
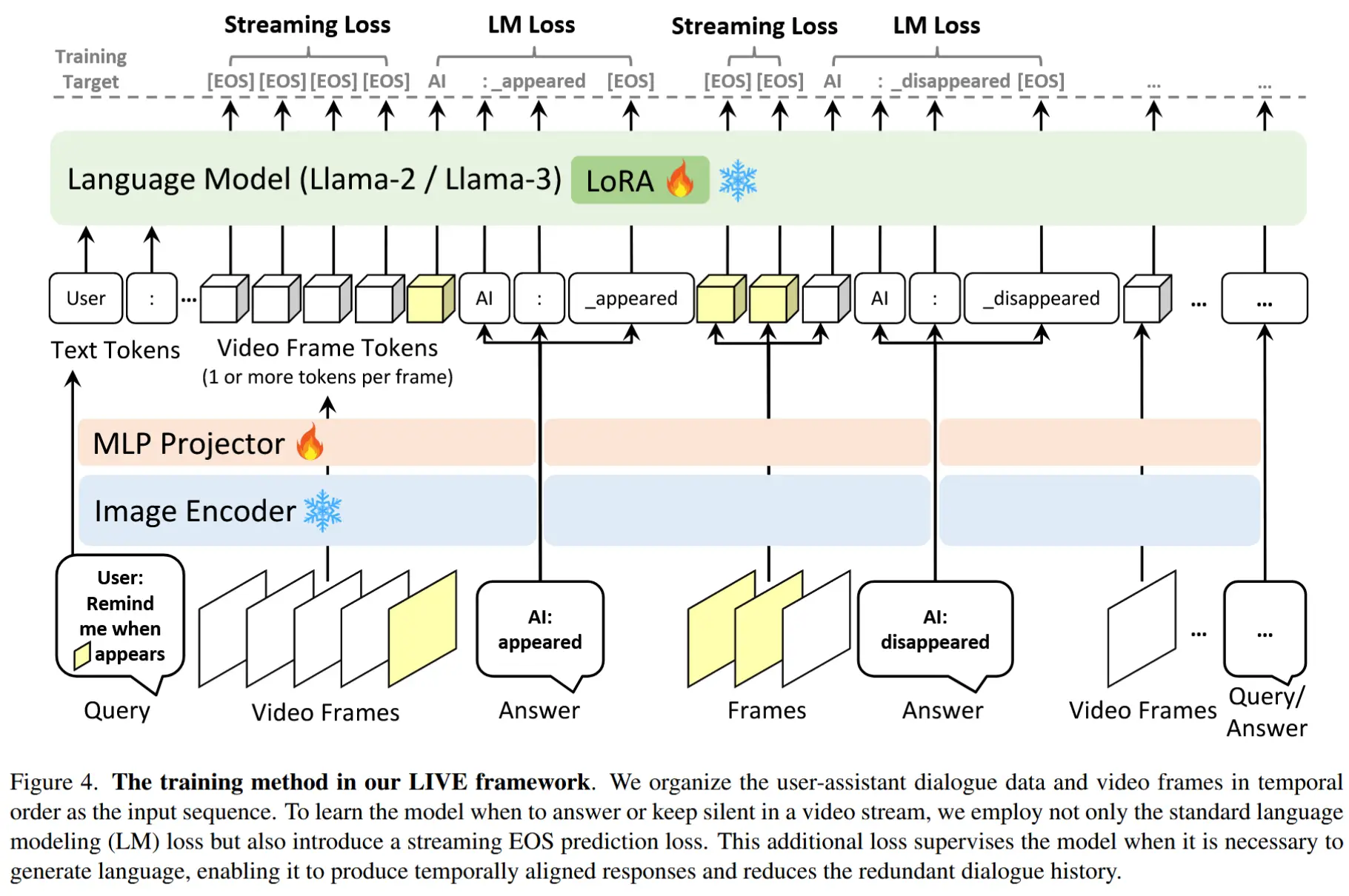
2.3 模型训练
模型架构
图4展示了模型的架构。该模型包含三个关键组件:图像编码器(CLIP ViT-L)、MLP 投影器和语言模型(带 LoRA 的 Llama-2-7B-Chat 或 Llama-3-8B-Instruct)。
训练损失
训练目标由两部分组成:第一部分专注于自回归语言建模,旨在最大化输入文本序列的联合概率。第二部分涉及流式EOS预测,要求模型在不需要输出响应时保持沉默。因此,训练损失为语言建模损失和流式损失需要最小化,两者均采用交叉熵损失:
其中:
- l_j 和 f_j 是条件指示符。如果第 j 个标记是语言响应标记,则 l_j = 1 ,否则 l_j = 0 。 f_j = 1 当且仅当满足以下两个条件:(1) 第 j 个标记是某一帧的最后一个标记;(2) l_{j+1} = 0 。
- P_j^{[\text{Txt}_{j+1}]} 表示第 j+1 个文本标记的概率,由第 j 个标记的语言模型头输出; P_j^{[\text{EOS}]} 表示EOS标记的概率。
- w 是平衡项,默认 w = 1 。
2.4 推理
概率校正: EOS标记的频繁出现会使模型偏向于预测EOS标记。为了解决这一问题,引入了一个阈值 \theta 来校正帧标记上的输出概率:如果 P_j^{[\text{EOS}]} < \theta,则不将EOS视为下一个标记。
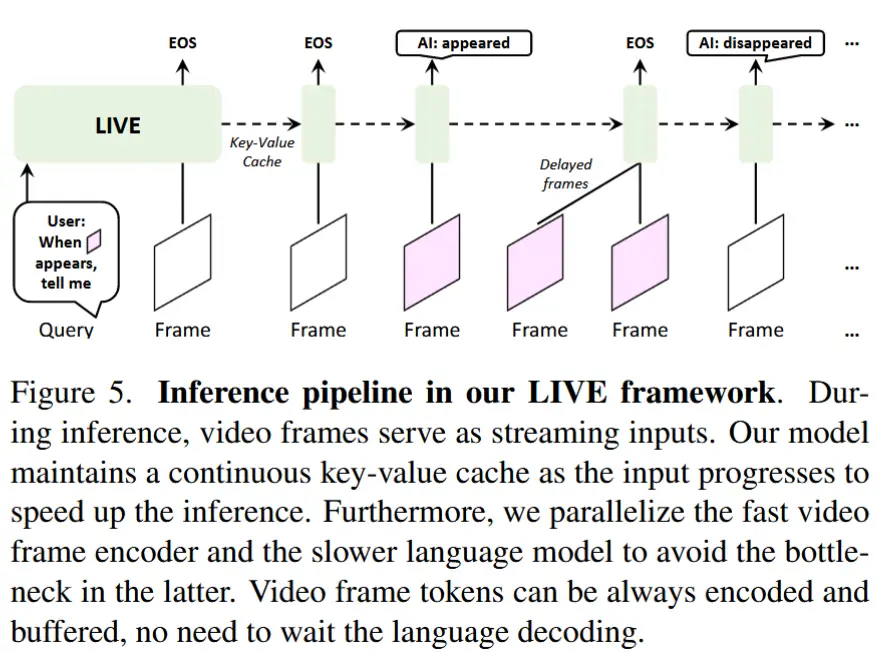
连续键值缓存: 如图5所示,在推理过程中,使用 KV cache来保证效率。
编码和解码的并行化: 由于视频帧编码器比 LLM 参数少速度快,为了避免帧跳过,将编码和解码过程并行化,并为视频帧标记建立一个 FIFO 队列。快速的编码器不需要等待缓慢的LLM,它只需持续对视频帧进行编码并将结果追加到队列中。一旦语言模型完成前一帧的解码,它可以从队列中获取帧标记,但不会延迟视频编码过程。
3 实验指标
实验部分略,展示作者设计的三类指标。
- 语言建模指标
- 语言困惑度 LM-PPL: 衡量模型在某一时间戳的语言建模能力。
- 语言生成匹配率 LG-Match: 第一个错误 token 的位置 / 总 token 数 ,按自回归顺序计算。
- 时间差异 TimeDiff: 计算每个回复的实际响应时间戳 与期望响应时间戳 之间的差异,然后对每轮对话取平均。
- 流畅性 Fluency: 定义为在一次对话轮次中,连续正确预测 token 的比例 。