- 论文 - 《EventVAD: Training-Free Event-Aware Video Anomaly Detection》
- 代码 - Github
- 关键词 - 无需训练、视频异常处理、图注意力网络、异常边界判定、视频大模型VideoLLaMA
1 引言
- 研究问题
- 视频异常检测(VAD)致力于识别视频中的异常事件。
- 现有方法的不足
- 监督学习方法需要大量特定领域的训练数据,且通常难以泛化到未见过的异常类型。
- 无监督的方法由于缺乏有效的标签信息,难以达到监督方法的水平。
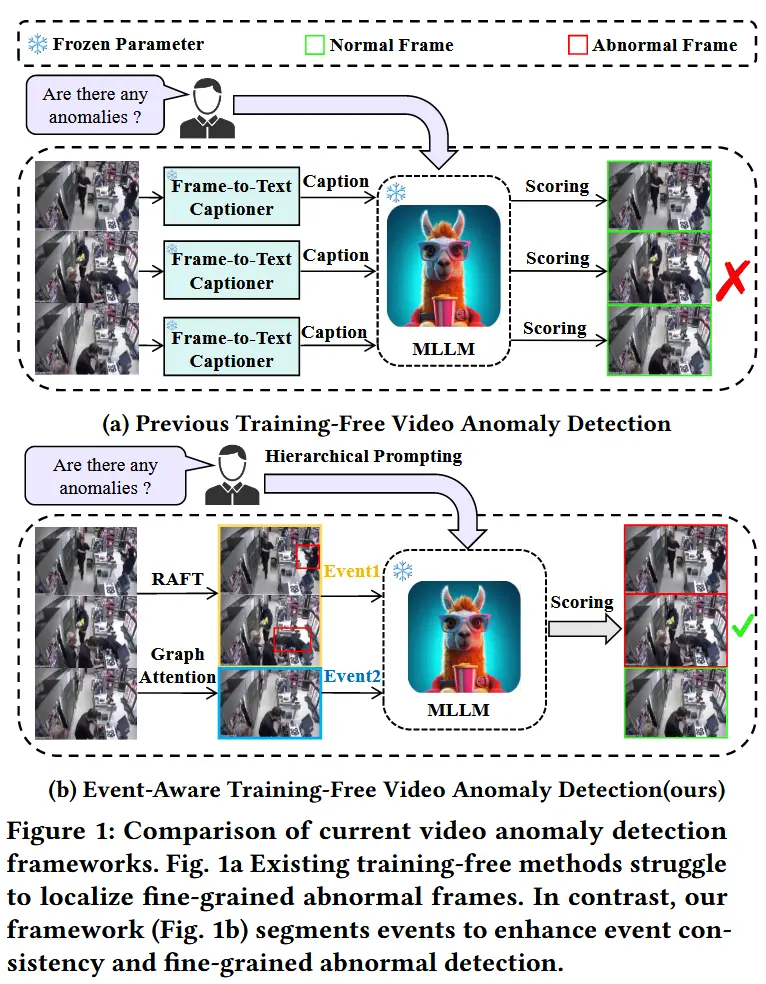
- 无需训练的方法利用 LLMs 内在的世界知识进行异常检测,但在定位细粒度的视觉变化和多样化事件方面仍面临挑战。例如:LLAVA 和 LAVAD(效率低、可能引发长尾问题)。
- 本文工作 - EventVAD
- 一种无需训练、具备事件感知能力的视频异常检测框架,该框架通过将长视频分割为短视频片段,增强MLLM在理解过程中的事件一致性。
2 方法
问题定义:给定一个包含 T 帧的输入视频序列 \mathcal{V} = \{\mathbf{I}_t\}_{t=1}^T,目标是检测异常帧。\{a_t\}_{t=1}^T 是异常指示器,其中 a_t \in \{0, 1\} 表示第 t 帧的二值异常状态。
方法流程(如图2):
- 首先,方法构建了一个具有多模态时间衰减特性的动态图,其中节点表示融合后的帧特征,边编码了时空相关性。
- 然后,图注意力传播机制通过正交约束的消息传递来优化节点特征。
- 接着,增强后的特征被送入统计边界检测模块,通过不连续性分析识别事件转换并获取事件边界。
- 最后,以事件为中心的评分机制利用语义线索评估检测到的事件单元内的异常。
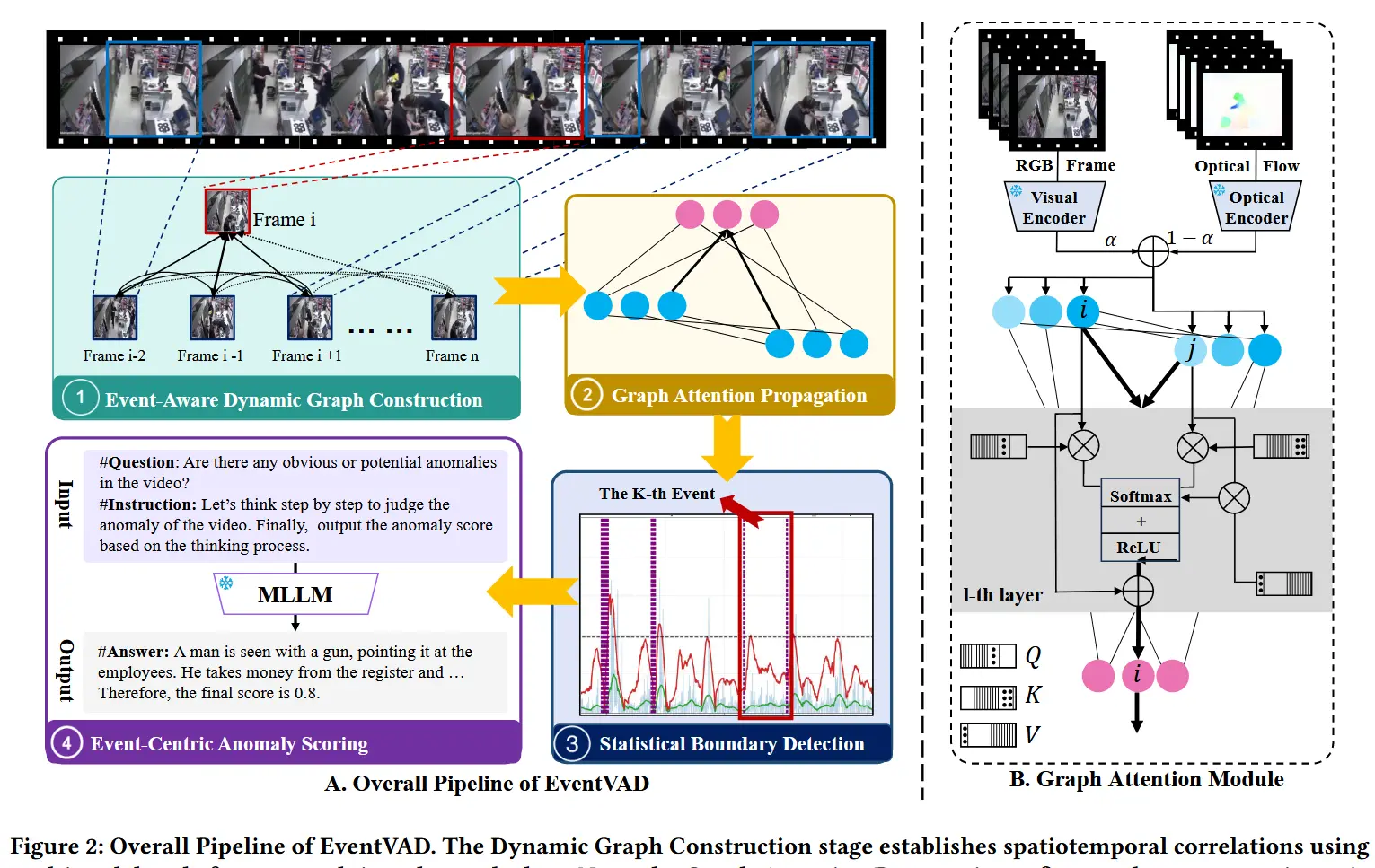
2.1 事件感知动态图构建
2.1.1 节点特征构建
动机:克服静态图在捕捉动态视频事件时的固有限制以及图神经网络训练速度较慢的问题。
解决办法:提出了一种基于视频帧的动态时空图模型 G = (F, E) ,通过跨模态相似性度量动态建立边,其中顶点集 F 对应于具有增强特征编码的视频帧,而边集 E 动态地根据跨模态相似性建立。
节点特征表示采用双流架构,结合语义和运动模式:
第一步:语义分支利用 CLIP 通过 L2 归一化生成判别性嵌入:
其中,\phi_{\text{CLIP}} 生成 512 维的语义嵌入。这种显式的归一化放大了帧之间的特征不连续性,这是检测语义级事件边界的关键组成部分。
第二步:运动分支通过光流处理捕获时间动态:
其中,\mathbf{o}_{i \to i-1} \in \mathbb{R}^{H \times W \times 2} 表示来自 RAFT 的光流场。投影矩阵 \mathbf{P} \in \mathbb{R}^{2 \times 128} 将高维光流统计映射到紧凑的运动码。这种降维提高了运动模式的可区分性,同时保留了时间一致性。
第三步:融合后的节点表示 f_i 计算公式如下:
其中,融合系数 \alpha = 0.75,融合向量 \mathbf{f}_i 集成了语义和运动约束,以精确定义事件转换边界。
2.1.2 时间衰减邻接矩阵
动机:分析视频内容的时间演化,整合跨组件的时空变化。
方法:构建一个具有时间衰减特性的动态图。
时间衰减邻接矩阵 E 定义如下:
其中:
- 融合系数 \alpha = 0.75 。
- 为了强调短期相关性并抑制长期相关性,在分子中结合了帧 i 和 j 之间的多模态相似性。
- 在分母中,引入了一个 \gamma 时间衰减因子来惩罚远程关联。
2.2 图注意力网络传播
为了在保持时间一致性的同时提升帧级表示,作者提出了一种基于正交特征投影的无需训练的注意力机制。该机制通过图引导的消息传递放大片段对比度,从而增强事件边界区分能力。该方法基于具有正交约束的图注意力网络。
第一步:随机生成正态分布矩阵做 QR 分解构建正交的 Q、K、V 投影矩阵,正交是为了防止维度坍缩:
其中,\text{QR}(\cdot) 通过 QR 分解确保列正交,d = 640 是融合后的特征维度, k = 64 是投影维度。这些固定的正交矩阵最大化了特征保留。
第二步:给定从上一节中传播的节点特征 \mathbf{F}^{(0)} = [\mathbf{f}_1, \dots, \mathbf{f}_n]^\top \in \mathbb{R}^{n \times d},对于动态图中的节点 \mathbf{f}_i,其对邻居节点 \mathbf{f}_j 的注意力权重计算如下:
第三步:加入时间连通性约束。指示函数 \mathbb{E}_{(i,j)} 遵循第 2.1 节中的时间连通性,确保注意力尊重事件诱导的拓扑结构。这一约束防止注意力分散到无关帧上。
特征通过以下方式迭代更新:
每次迭代后,特征进行中心化处理:
通过迭代图注意力更新,特征传播保持全局发散性和局部一致性,保留异常检测中至关重要的相对差异。
2.3 统计边界检测
为了增强图注意力网络的特征,作者提出了一种通过时间不连续性分析识别事件转换的统计边界检测机制。
第一步:复合差异度量。对于连续帧 (i, i+1),计算一个复合差异度量:
其中,平方 L2 范数项放大了特征空间中的突然跳跃,而余弦项则检测流形上的方向变化。这种双重策略捕捉了异常引起的幅度和方向不连续性。
第二步:噪声抑制与真实边界的保留。原始差异度量 s_i 包含来自相机抖动或微小运动的高频噪声。为了在抑制噪声的同时保留真实边界,应用了一个 Savitzky-Golay 滤波器,窗口宽度为 w=60,定义如下:
其中,系数 a_k 来自二次多项式拟合,保留真实不连续性。
对于平滑信号 \bar{s}_i,计算移动平均值:
然后,计算信号比 r_i 如下:
其中,等宽窗口权重抑制了瞬时波动,增强了对噪声的鲁棒性。
第三步:自适应阈值调整。为了减轻遮挡或抖动引起的异常值敏感性,使用中位绝对偏差(MAD)进行自适应阈值调整:
调整参数 k = 3 符合 3\sigma 原则,捕获了 99.7\% 的正常变化范围。当 r_i > M 时,识别出边界点。
最后,相邻的边界点被合并以防止过度分割,从而提高事件边界的准确性。
2.4 以事件为中心的异常评分
动机:现有的 VAD 方法通常依赖于离散的帧级分析或对整个视频进行全局处理。这种非自适应分割机制如果时间片段过短会丢失上下文信息,而时间单元过长则会削弱空间特征的表达能力。
解决办法:作者构建了以事件语义单元为时空基本单元的表示方式,针对事件单元的分析,提出了一种语义驱动的分层提示框架。该框架引导多模态大语言模型生成结构化输出:首先生成对视频内容的描述,然后据此推导出异常评分。
3 实验
3.1 实验设定
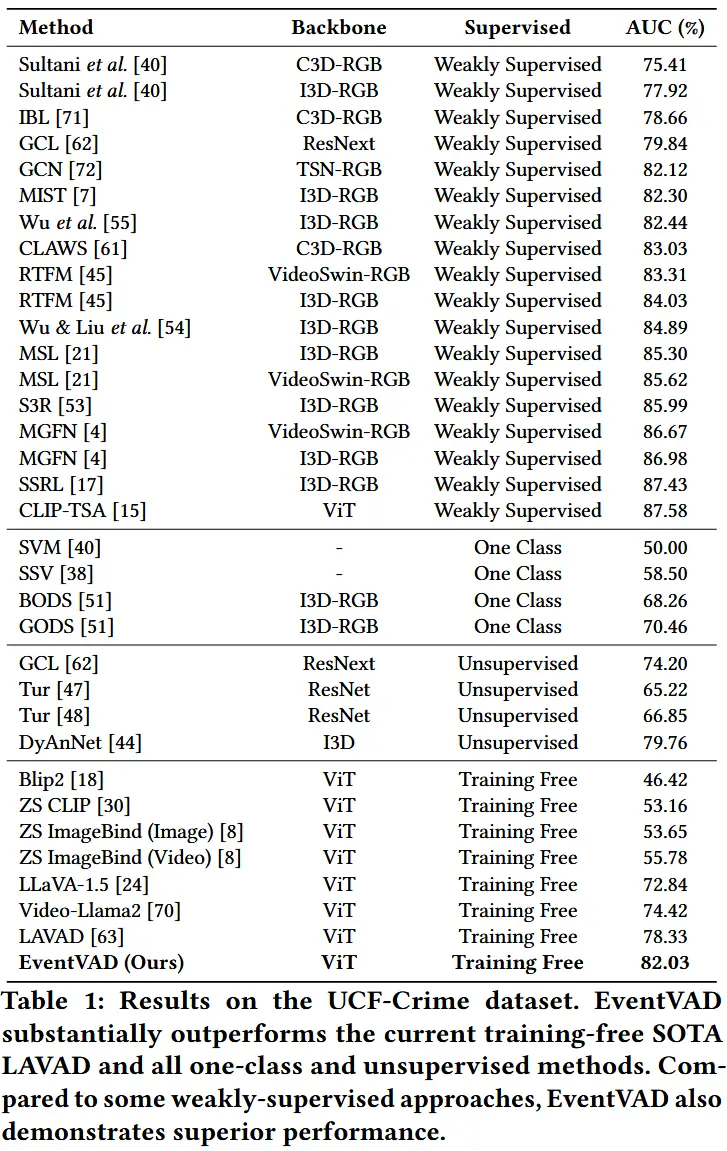
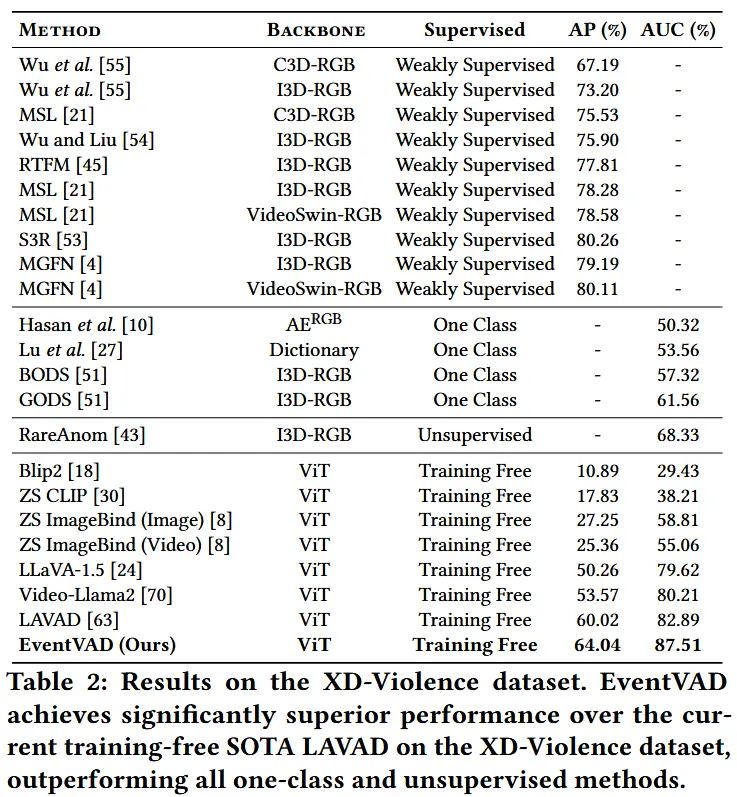
- 数据集:UCF-Crime 和 XD-Violence
- 评估指标:对于UCF-Crime,采用帧级别的AUC-ROC;对于XD-Violence,采用平均精度(Average Precision)。
- 实验细节
- 编码器采用双分支架构,结合视觉语义与运动表征。使用预训练的 CLIP ViT-B/16 提取视觉,RAFT模型提取光流特征。
- 采用VideoLLaMA2.1-7B-16F [5] 作为主干模型。
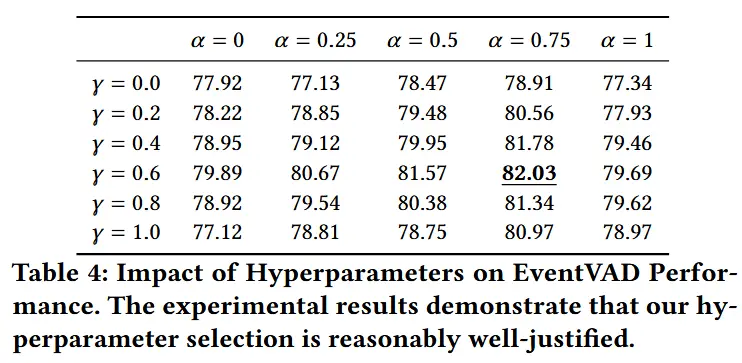
- 时间衰减因子 γ = 0.6,语义-运动融合系数 α = 0.75,图注意力传播仅进行一次迭代。
- 实验设备单张NVIDIA A800(80GB)。
3.2 实验结果
- 性能结果
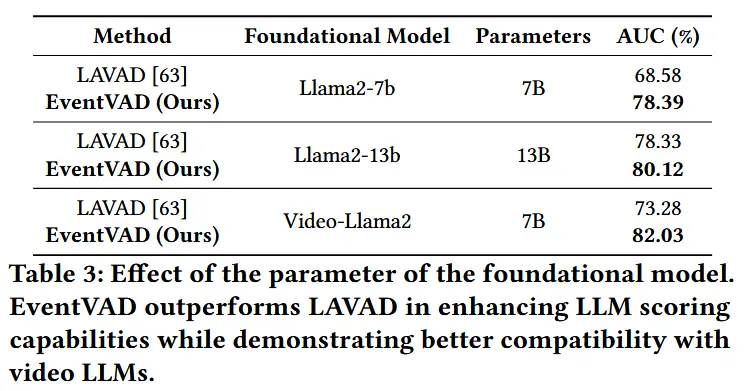
- 如表1和表2所示,展示了在两个数据集上的性能结果。
- 可视化分析
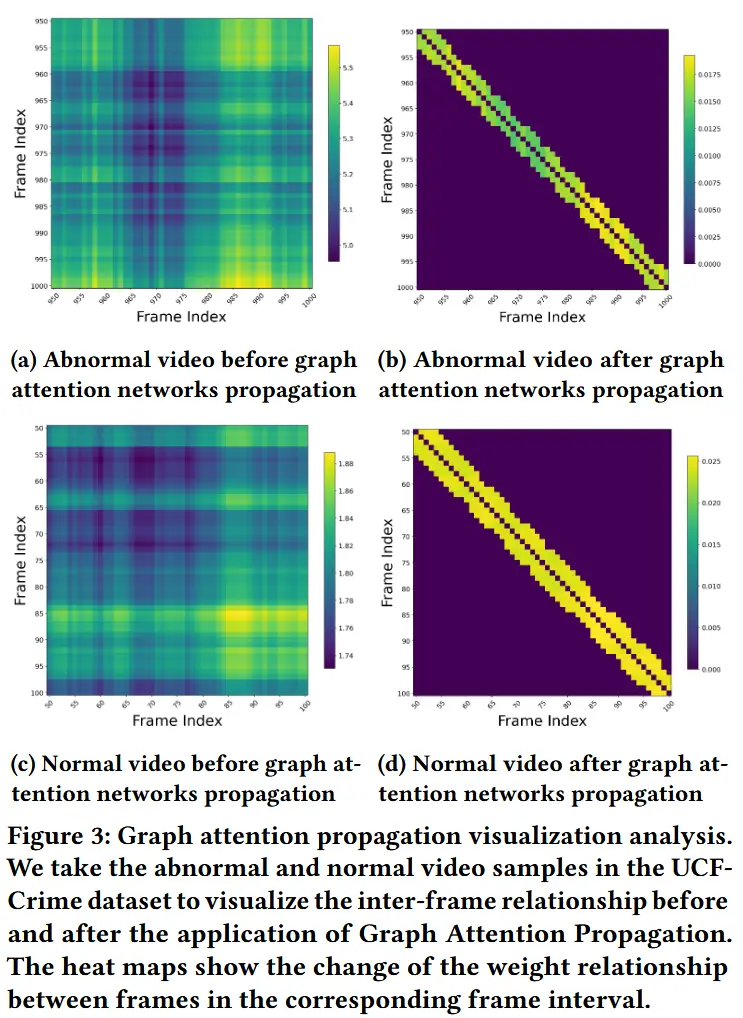
- 如图3所示,以一个视频样本为例,展示了通过图注意力传播过程对异常和正常序列的全面可视化。
- a和c均显示了混乱的帧间连接,区分度较差。经过应用图的注意力传播后,b和d清楚地显示出相邻帧连接得到增强,远距离帧相关性被抑制。且图c在965-975帧附近有一个独特的低权重簇,这对应于实际的边界划分。
- 验证了图注意力传播过程的有效性。
- 边界检测可视化
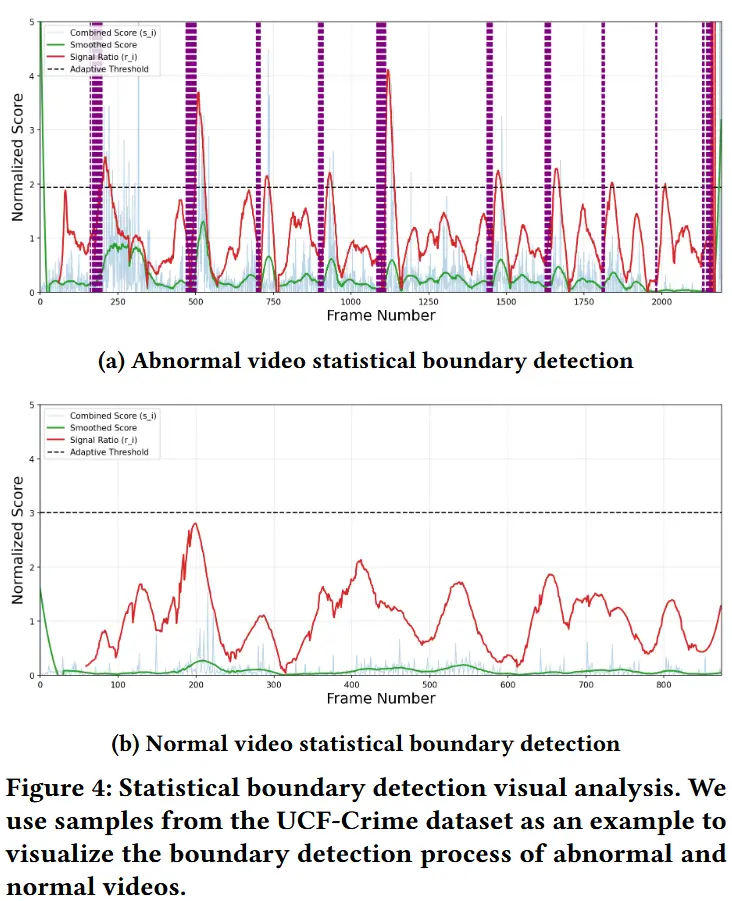
- 如图4所示,对某个视频样本的所有帧进行了边界检测的可视化。浅蓝色曲线表示用于分割的原始信号,绿色曲线表示经过Savitzky-Golay滤波平滑后的信号,红色曲线表示窗口内平滑信号与对应窗口平均线的比值变化,黑色水平线表示自适应阈值,紫色水平线表示检测到的边界。
- 在子图4a中,对于视频的第965-975帧,本文框架通过图注意力传播后能够有效捕捉关键的边界检测模式,这也从定量上验证了子图3b中的后续边界检测过程。
- 消融实验
- 效率-准确性权衡
- 超参数对模型性能的影响
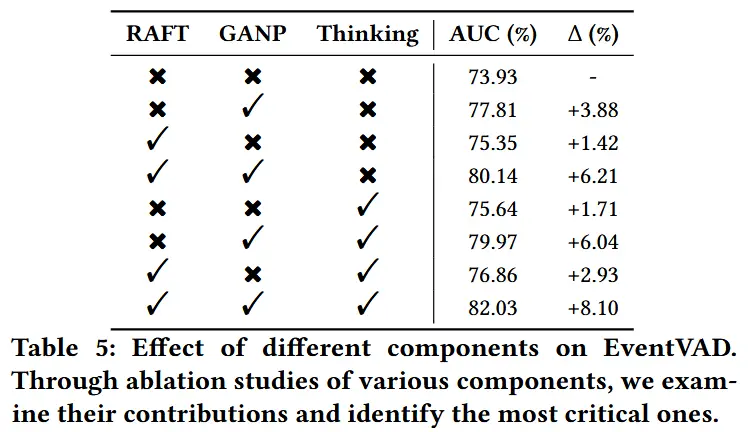
- 关键组件消融