- 论文 - 《VAU-R1: Advancing Video Anomaly Understanding via Reinforcement Fine-Tuning》
- 代码 - Github
- 关键词 - 强化微调、Qwen、视频异常理解VAU、新数据集、视频异常问答、视频异常检测VAD、新基准
1 引言
-
研究问题
- 早期方法仅关注异常检测,二分类任务,定位异常事件的时间边界,但是缺乏可解释性。
- 随着多模态大语言模型 MLLMs 的发展,生成异常描述成为可能,但是仍面临三个关键局限:
- 缺乏生成连贯的多步推理链的能力。
- 尚无全面的基准提供丰富标注以支持详细的因果推理。
- 针对推理质量的评估协议仍不完善。
-
为了超越浅层分类,实现更深层次的理解,作者将VAU分解为四个递进阶段:
- 感知:通过自由文本描述或引导式选择题识别场景和相关对象。
- 定位:精确确定异常发生的时间片段。
- 推理:通过分析因果因素、时间动态和上下文线索来解释事件。
- 结论:总结事件并做出最终判断,例如将其归类为特定类型。
-
本文方法 - VAU-R1
- 一种强化微调(RFT)框架,旨在提升MLLMs在VAU任务中的推理能力。
- 该方法基于组相对策略优化(GRPO),引入了基于答案格式正确性、问答准确性和时间定位对齐的任务特定奖励信号。该框架数据效率高,适用于低资源场景,具有现实部署的实用性。
-
本文新基准 - VAUBench
- 这是一个涵盖多样化场景的新基准,为四个推理阶段提供了丰富的标注,包括多项选择题问答对、详细事件描述、时间定位标注以及逐步推理过程。
-
本文新评估指标
- 问答准确率、时间交并比(IoU)、基于GPT的推理评分和分类准确率——以定量评估模型在感知、定位、推理和结论各阶段的表现。
2 方法论
2.1 预备知识:基于 GRPO 的强化学习
组相对策略优化(GRPO)是一种强化学习框架,它通过基于偏好的反馈和多方面奖励信号来优化策略 \pi_\theta。给定一个问题 x,GRPO 从旧策略 \pi_{\theta_{\text{old}}} 生成 M 个候选输出 O = \{o_1, o_2, \ldots, o_M\},每个输出 o_j 被赋予一个奖励 R_j,该奖励计算为 K 个任务特定组件的加权和:
其中 R_j^{(k)} 是第 k 个任务特定奖励(例如,准确率、IoU、格式合规性),\lambda_k 是其对应的权重。为了衡量第 j 个输出的相对质量,计算每个输出 o_j 的归一化奖励 \tilde{R}_j,使用在 M 个候选输出上的均值 \mu_R 和标准差 \sigma_R:
GRPO 通过 KL 惩罚项 D_{\text{KL}}(\cdot \parallel \cdot) 实现保持更新过程接近原始 MLLM 参数 \pi_{\text{ref}} ,并最大化以下目标函数:
其中 \beta 是正则化系数。该公式使 GRPO 能够融合多样化的奖励信号,同时通过 KL 正则化保持训练稳定性。
2.2 VAU-R1
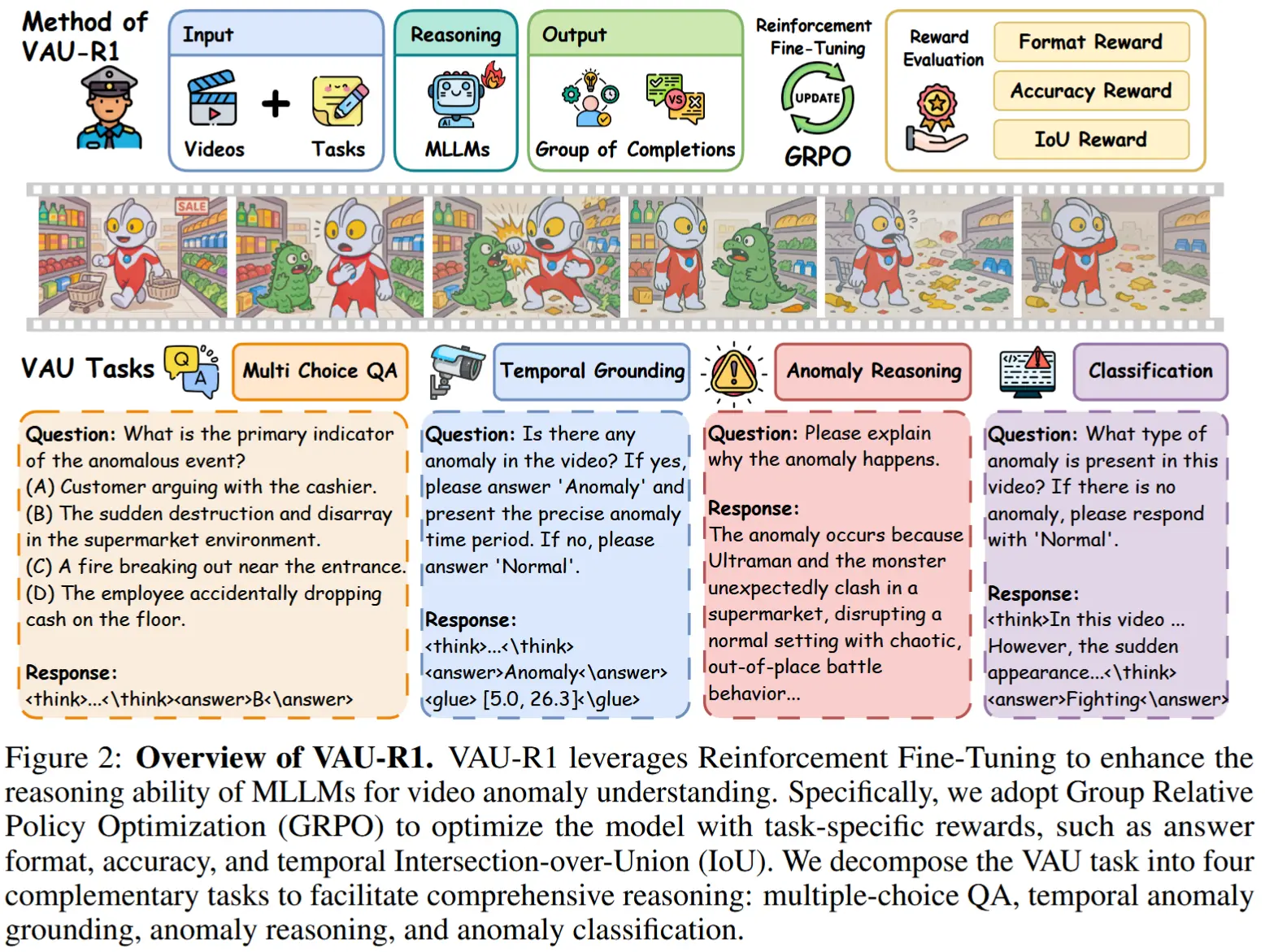
如图2所示,VAU-R1 是一种面向四项视频异常理解任务的数据高效强化微调框架,包括多项选择问答、时间异常定位、异常推理和异常分类。
2.3 奖励规则
采用基于GRPO的强化微调的一般思想,通过为不同的VAU组件设计任务特定的奖励函数来优化VAU模型。下文将详细说明每种奖励的定义。
格式奖励(Format)。对于多项选择问答和异常分类任务,指导模型将其推理过程置于 <think>...</think> 标签内,答案置于 <answer>...</answer> 标签内。对于时间异常定位任务,额外要求使用 <glue>...</glue> 标签来表示预测的时间段(以秒为单位)。定义如下:
准确率奖励(Accuracy)。作者还定义了一个准确率奖励 R_{\text{acc}},用于衡量模型答案的正确性。定义为:
时间IoU奖励(Temporal IoU)。为了鼓励更精确的时间定位,作者引入一个时间交并比(IoU)奖励 R_{\text{tIoU}},用于衡量预测异常时间段与真实异常时间段之间的对齐程度。该奖励定义如下:
其中,[s_1, s_2] 表示模型预测的异常时间段,而 [s_1^*, s_2^*] 为真实标注的时间区间。时间IoU量化了这两个区间之间的重叠程度。
任务特定奖励组合(Task-specific)。根据上述奖励组件,为不同任务设计特定的奖励组合:
- 对于多项选择问答任务:R_{\text{QA}} = R_{\text{format}} + R_{\text{acc}}。
- 对于时间异常定位任务:R_{\text{TAG}} = R_{\text{format}} + R_{\text{acc}} + R_{\text{tIoU}}。
- 对于异常分类任务:R_{\text{CLS}} = R_{\text{format}} + R_{\text{acc}}。
2.4 VAU-Bench
任务定义。视频异常理解(VAU)任务分解为四个阶段:感知、定位、推理和结论。与这些阶段相对应,作者定义了四项VAU任务:
- 多项选择问答:通过回答关于视频的问题来实现事件感知。
- 时间定位:在视频时间轴上定位异常片段。
- 异常推理:探索因果关系以解释异常产生的原因。
- 异常分类:将异常归类到相应的类别中。
数据集构建与标注: VAU-Bench 是一个统一基准,整合 MSAD、UCF-Crime 和 ECVA 数据集,并补充了思维链(CoT)标注,包括视频描述、时间边界、多项选择问答对和推理依据。通过清洗流程移除损坏或过长视频并合并重叠异常类型。UCF-Crime 和 ECVA 使用 DeepSeek-V3 生成摘要、QA 和推理链;MSAD 采用两阶段流程:先由 InternVL-8B-MPO 生成初稿,再由 DeepSeek-V3 优化,提升准确性和连贯性。(详见附录)
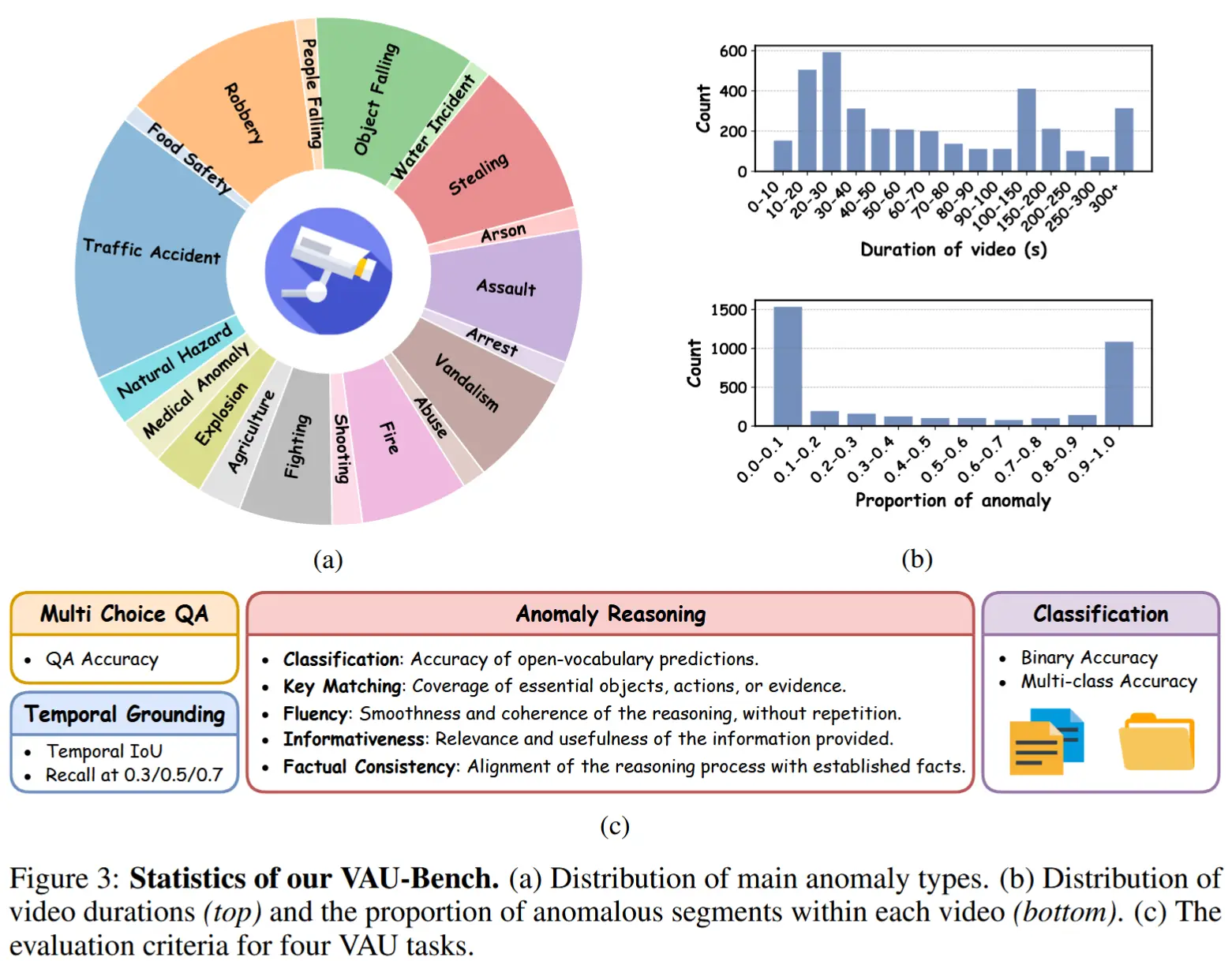
数据集统计: VAU-Bench 包含 4,602 个视频,覆盖 19 类异常,总时长 169.1 小时,标注文本超 150 万词(平均每视频 337 词),分为 2,939/734/929 训练/验证/测试集,并提供 3,700 条时间标注支持定位任务。图3展示类别分布、时长多样性及评估协议。
推理评估指标:传统指标(如 BLEU/ROUGE)难以衡量推理质量。作者提出 VAU-Eval,基于 GPT 的评估框架,使用 DeepSeek-V3 从五个维度评分:分类准确率、关键概念对齐、流畅性、信息丰富度、事实一致性,每项满分 10 分,实现对推理质量的细粒度评估。
3 实验
3.1 实验设定
- 数据集:MSAD、ECVA、UCF-Crime,以及本文的 VAU-bench。
- 模型:Qwen2-VL-2B-Instruct 和 Qwen2.5-VL-3B-Instruct。
- 使用2块NVIDIA H20进行全参数微调。
- 评估指标:如图3,不同任务不同指标。
3.2 实验结果
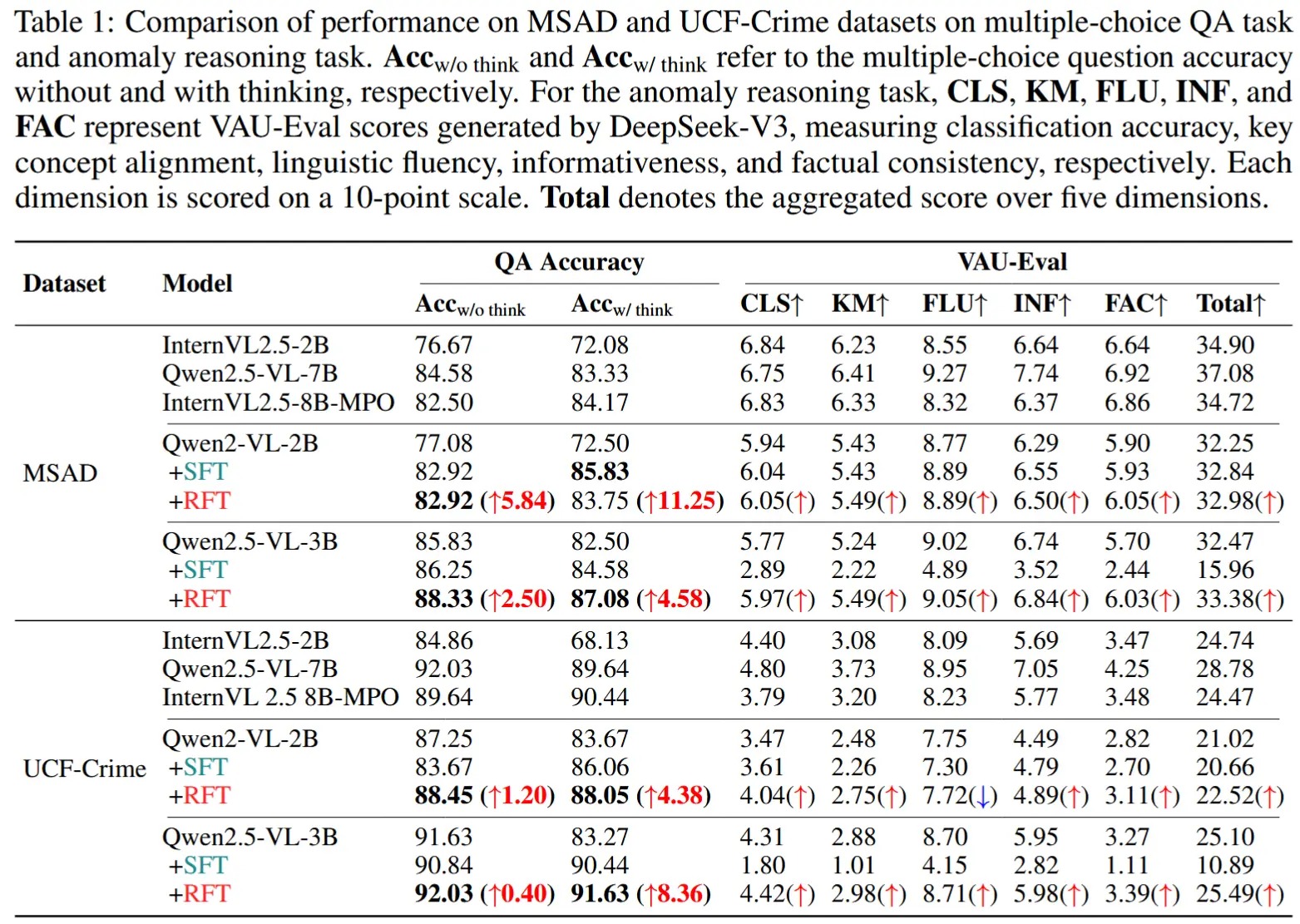
- 多选问答性能
- 使用准确性和VAU-Eval进行测评,其中CLS、KM等代表DeepSeek-V3对五个维度的评分。
- 结论:
- Acc_{w/think} 的表现往往不如 Acc_{w/o think} 的情况,表明朴素的思维链生成可能引入幻觉。
- 强化微调(RFT)显著提升了包含推理的问答准确率以及整体推理质量.
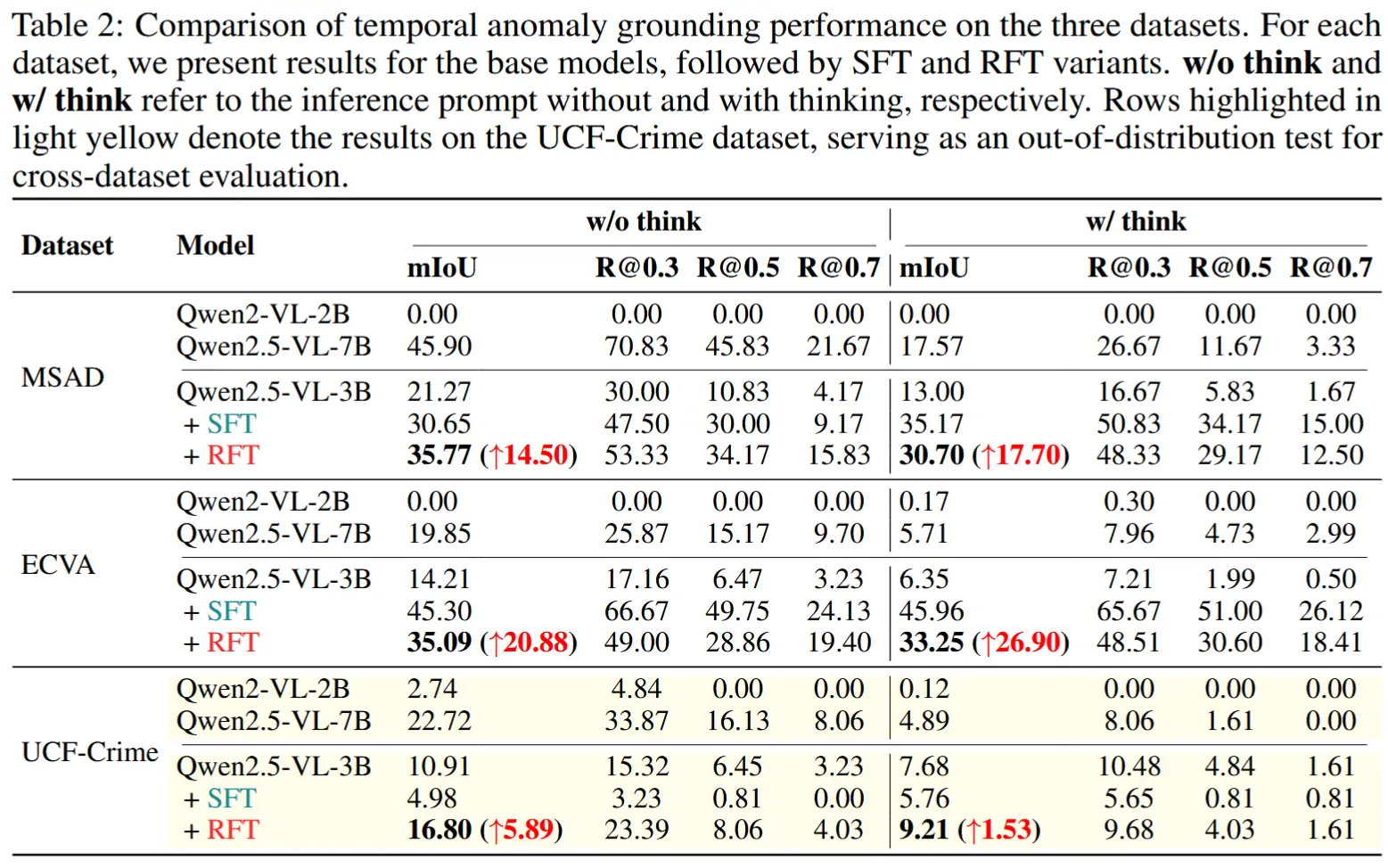
- 时间异常定位评估
- 所有模型仅在MSAD和ECVA上进行训练,而UCF-Crime作为分布外测试集。
- 结论:
- 在两种推理设置(含/不含推理)下,RFT始终优于对应的基础模型,表明其在提升时间定位方面的有效性。
- CoT 并不一定提升定位性能;在某些情况下,加入推理反而导致定位准确率下降。
- RFT相比SFT展现出显著更强的泛化能力。
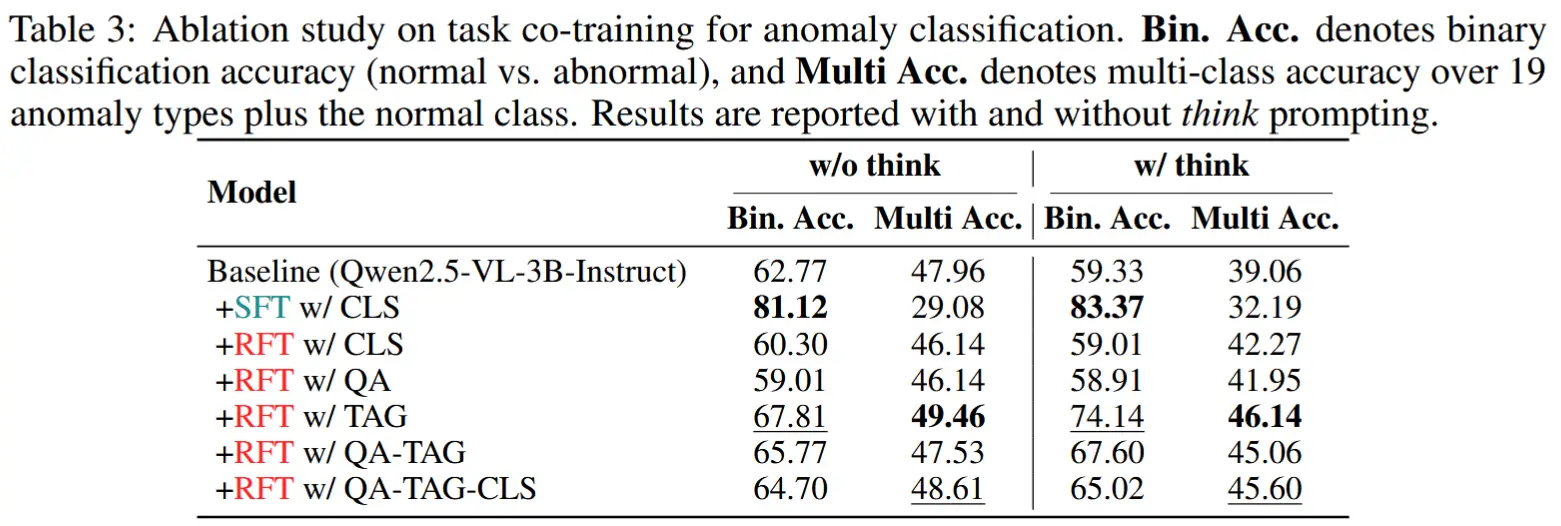
- 消融实验
- 使用不同组合的VAU任务——多项选择问答(QA)、时间异常定位(TAG)和多分类(CLS)——训练模型,以评估其对推理能力的影响。
- 结论:总体而言,基于定位的任务更有利于异常分类,而通过强化学习联合优化多个任务可在准确率和推理能力上实现互补性提升。