- 论文 - 《VaVLM: Toward Efficient Edge-Cloud Video Analytics With Vision-Language Models》
- 关键词 - 边缘智能、端云协作、边缘设备、任务特定推理、视频大模型、自适应抽帧、感兴趣区域 Rol、边缘推理
1 引言
- 现有工作的不足
- 现有的大多数边缘-云计算视频分析系统是为传统的深度学习模型(例如图像分类和目标检测)设计的。
- 针对传统 DNN 模型的边缘推理优化工作
- ParaLoupe [14] 设计了一组面向任务的小型模型,可在边缘硬件上高效执行。
- AdaptiveNet [15] 利用部署后设备端神经网络架构自适应技术,生成适用于多样化边缘环境的模型。
- 为了减少边缘设备与云服务器之间的数据传输,VaBUS [16] 智能地从视频中移除背景内容以实现语义压缩,而 DDS [17] 则根据服务器端深度神经网络(DNN)模型的反馈生成感兴趣区域(RoI)。
- 为了持续满足延迟要求,REMIX [18] 通过选择性地处理分区图像,在边缘设备上实现了可调节延迟的高清目标检测。
- 此外,还有研究专注于在边缘集群和多租户场景下调度和优化视频分析任务 [19]、[20]、[21]、[22]、[23]。
- 本文工作
- 提出了 VaVLM,这是一种专为视觉语言模型(VLMs)设计的新型边缘-云协同视频分析系统,能够通过单一模型支持多种任务。
- VaVLM 旨在从三个方面提升基于VLM的视频分析系统的性能:
- 首先,为了减少视频传输过程中的带宽消耗,提出了一种基于VLM对任务和场景理解的新型感兴趣区域(RoI)生成机制。
- 其次,为了降低推理成本,我们设计了一种任务导向的推理触发机制,使用优化的推理逻辑仅处理部分视频帧。
- 第三,为了提高推理准确性,在推理阶段通过结合来自环境和其他辅助分析模型的信息来增强模型。
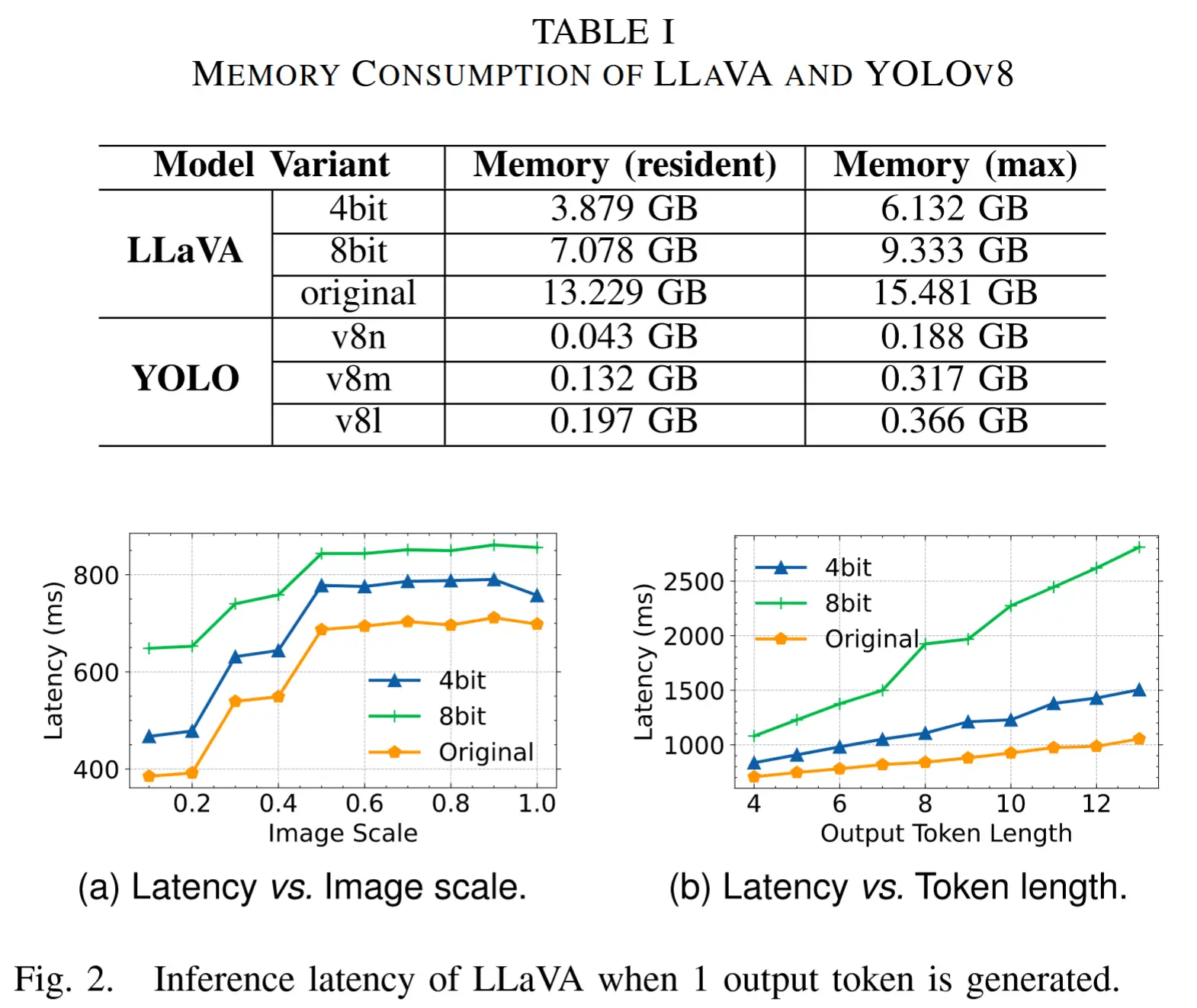
VLM与DNN计算成本对比:
- 表I展示了典型VLM(即LLaVA)在不同量化精度下的驻留内存和最大消耗内存,以及一个目标检测模型(YOLOv8)在不同模型复杂度下的表现。
- 图2展示了在 RTX 3090 上运行时,LLaVA在不同图像尺度(图像尺度1.0对应720×1280分辨率)和输出token长度下的推理延迟情况。
2 相关工作
这里只展示部分。
- 边缘-云协同视频分析
- 基于信息剪枝的方法:这类方法旨在通过使用 自适应编码器 [43]、[44]、[45] 和帧过滤 [25]、[46] 等技术,减少从边缘设备传输到云端的数据量;
- 基于模型优化的方法:这类方法采用 神经网络架构搜索(NAS) 等技术 [14]、[15]、[47]、[48]、[49],设计适合部署在边缘设备上的轻量化模型;
- 基于资源优化的方法:这类方法通过优化带宽和计算资源的使用来提升整体系统性能 [18]、[50]、[51]、[52]。
3 VaVLM:方案设计
3.1 方案概述
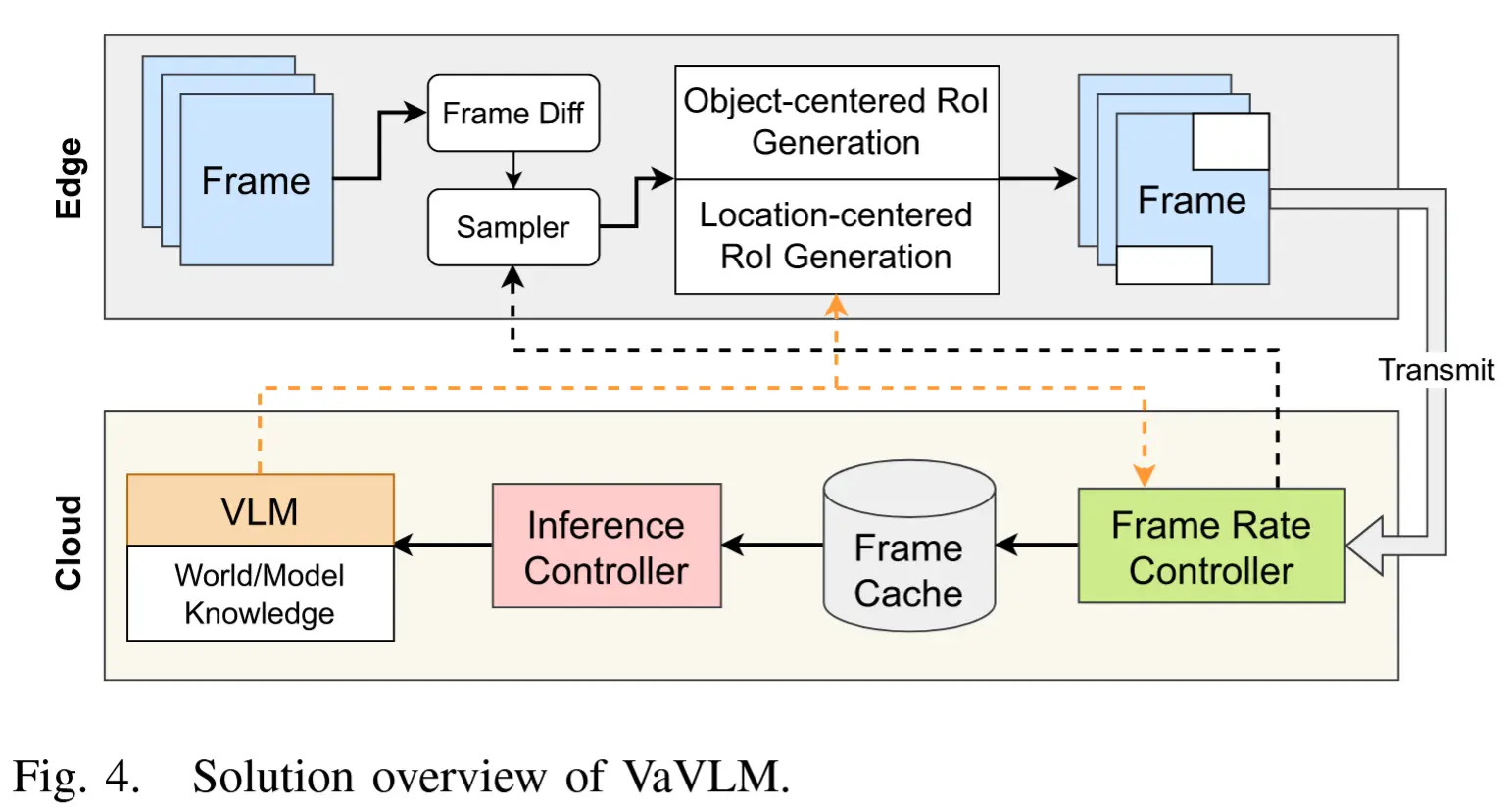
VaVLM 的整体架构如图4所示。总体而言,VaVLM 在 Edge 从采样帧中生成感兴趣区域(RoI),以减少带宽消耗;而在 Cloud 部署 VLM 进行选择性推理,以降低计算成本。(带宽高效和计算高效)
-
边缘端 :
- 当边缘设备捕获视频帧后,首先经过一个“a frame difference(帧差)模块”去除变化极小的重复帧。
- 随后,一个“采样器”根据变量 r = f_{cup}/f_{orin} \in [0, 1] 来决定每一帧是否上传或丢弃。在此过程中,只有比例为 r 的帧被送入下一阶段处理。
- 为了进一步减少带宽消耗,系统采用两个 RoI 生成模块:面向对象的 RoI 生成模块和面向位置的 RoI 生成模块。这两个模块分别对应涉及特定人物或特定图像区域的任务。生成的 RoI 随后被传输至云端进行分析。
-
云端 :
- 接收到的帧首先由“帧率控制器”处理,以判断是否需要调整采样率。
- 随后,这些帧被缓存并输入“推理控制器”,用于决定何时触发一次推理。
- 为了进一步增强 VLM 的推理能力,还融合了外部知识,包括:世界知识和模型知识。
3.2 基于 VLM 的 Rol 生成
视频分析任务中,通常只需关注图像中的部分区域,因此传输和生成感兴趣区域(Rol)已成为边缘-云的常见技术。现有方法,现有方法要么每次都需要云端反馈(导致高延迟),要么依赖基于运动向量或背景减除的方法(带宽节省效果有限)。
本文利用 VLM 进行智能 Rol 生成,根据分析任务的不同,将 Rol分成以下两类:
- 以对象为中心的RoI: 适用于涉及特定人物的任务,例如智能家居应用中检测儿童危险行为或人机交互中的手势识别。在这种情况下,系统会生成并传输包含该特定人物的RoI。
- 以位置为中心的RoI: 适用于聚焦图像特定区域的任务,例如交通拥堵检测或禁区监控。对于这类任务,系统会在相关图像区域生成RoI。
3.2.1 以对象为中心的 Rol 生成
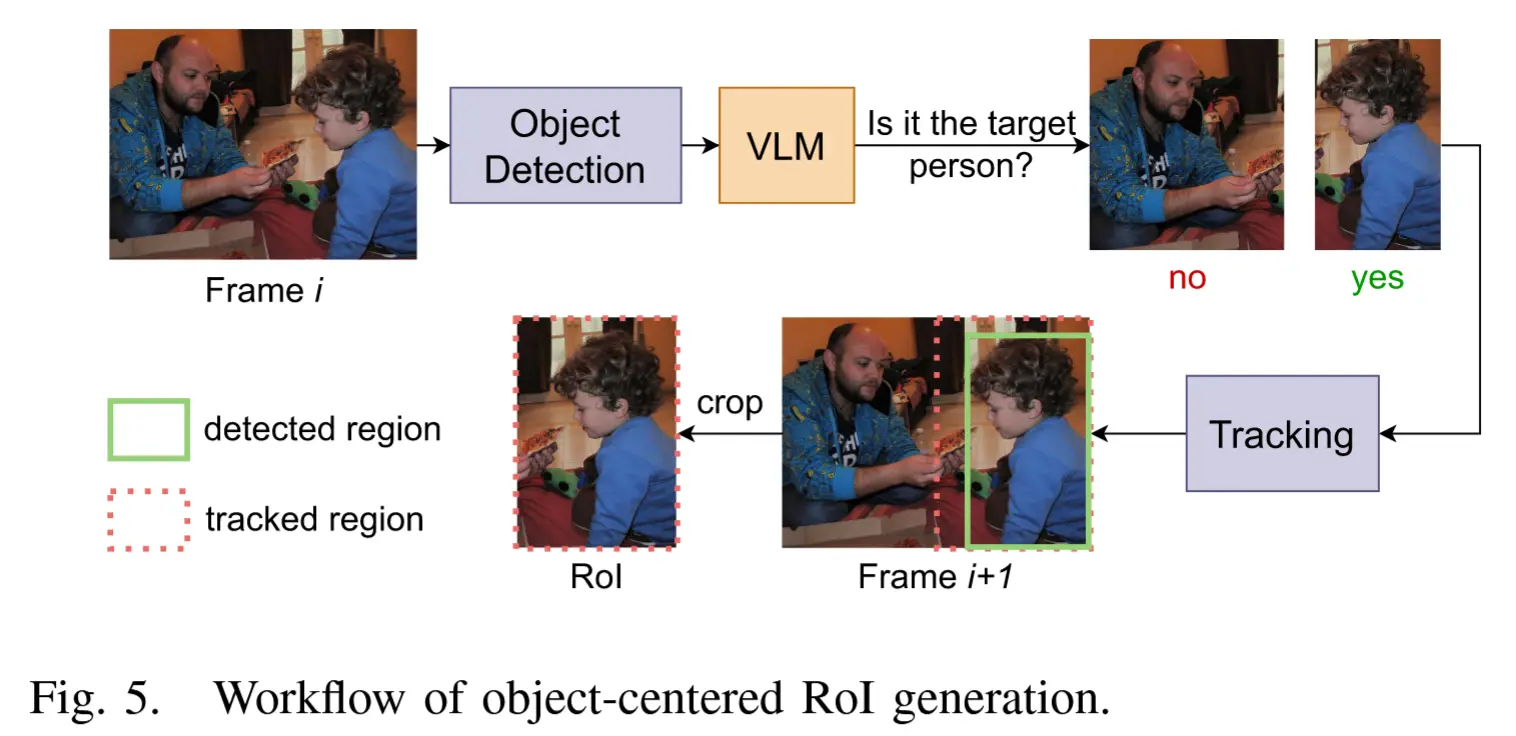
基本思路:以对象为中心的 RoI 用于分析场景中的特定个体。由于 VLM 无法直接定位目标人物的确切位置,通过集成一个目标检测模型来辅助 VLM 完成定位。
图5展示了生成以对象为中心 RoI 的工作流程:
- 给定输入帧 i,第一步是将其输入目标检测模型(如 YOLOv8),以识别帧中的所有物体。检测结果包括每个人物周围的边界框。
- 针对每个检测到的人物,裁剪出对应的子图像,并输入 VLM 进行判断,确认其是否为目标人物。
- 为了确保在以对象为中心的 RoI 生成过程中保持低延迟,作者精心设计 prompt,以在保留必要信息的同时获得尽可能短的响应。(
:Is this the target person? Respond with ‘yes’ or ‘no’ only."使得响应长度仅为一个 token) - 一旦识别出目标人物,系统将在其边界框的基础上,按比例 α 向四周扩展,生成最终的 RoI。这种扩展可以确保人物完全处于 RoI 内部,避免因连续帧之间的小幅移动而导致目标丢失。
- 此外,云端还会执行目标跟踪,持续更新 RoI,确保随着人物在不同帧之间移动,其始终处于感兴趣区域内。如果目标人物移出 RoI,系统会自动将整帧发送至 VLM,重新识别目标人物。
3.2.2 以位置为中心的 RoI 生成
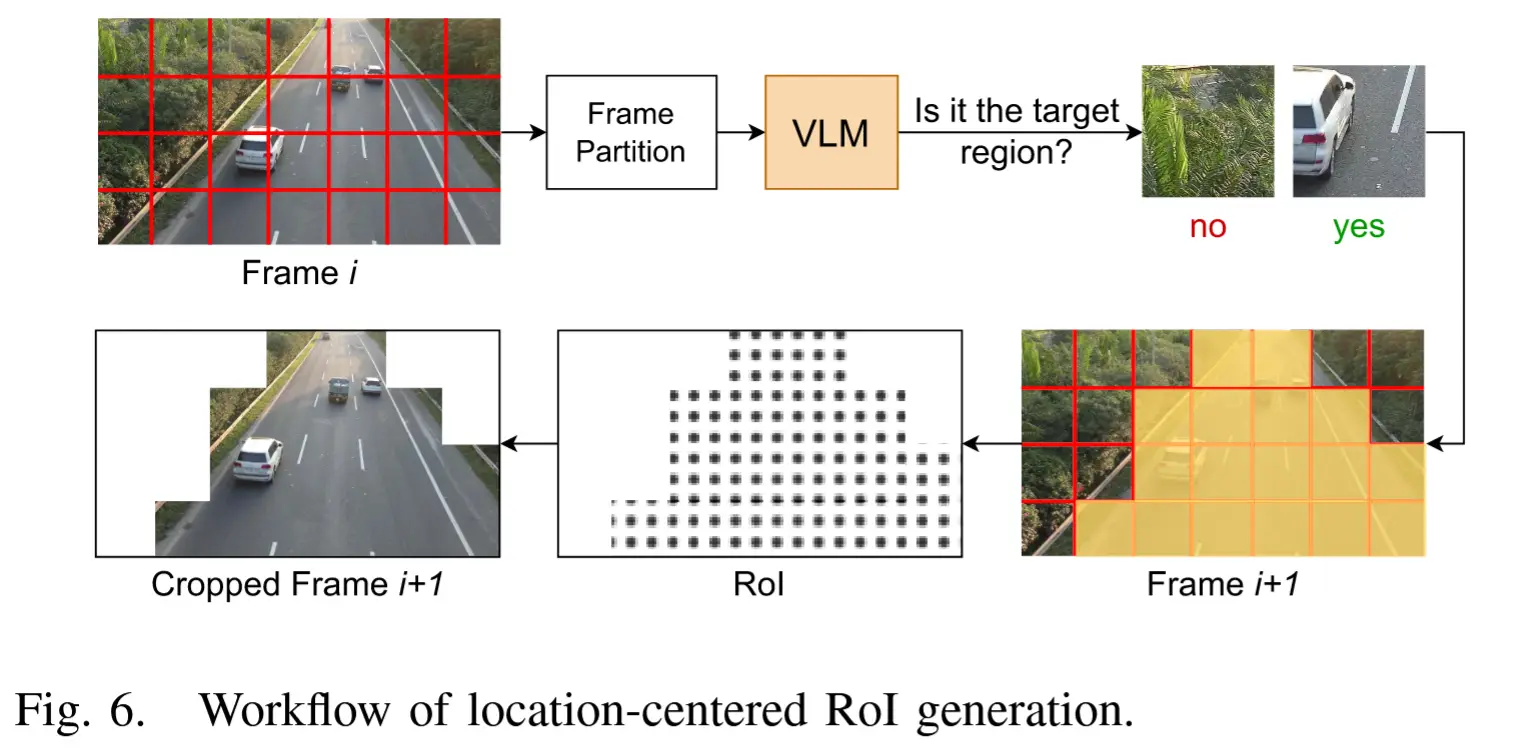
基本思路:作者提出了一种高效的基于图像块的 RoI 生成方法
图6展示了生成以位置为中心 RoI 的工作流程:
- 输入帧 i 首先被划分为 n 个 patches。对于每个 patch,VLM 判断其是否属于当前任务的目标区域。
- 该过程中的 VLM 提示词也经过精心设计,以降低推理延迟。提示语如下:
"Is this the target region? Respond with ‘yes’ or ‘no’ only.",使得响应长度仅为一个 token。 - 当所有 patch 分类完后,系统将据此定义 Rol,并用于后续帧的传输。
- 对于背景固定的场景,Rol 只需生成一次即可。为了检测环境变化,系统会周期性地重新生成以位置为中心的 Rol,并进行比较,以识别任何场景变化,一旦发现变化,就使用最新的 Rol。
注意,作者选择在原始图像上对图像块进行标注,并将带有标注的整张图像发送给 VLM。这种方法有助于 VLM 更好地理解图像块的上下文信息,从而做出更准确的判断。
3.3 任务导向的推理触发机制
现有的边缘-云协同视频分析系统通常采用固定采样率 [53]、基于低层视频特征过滤帧 [25],或在边缘端使用轻量级模型 [46] 来决定是否将帧传输至云端进行推理。
本文提出了一种任务导向的推理触发机制 ,利用 VLM 的推理能力智能地选择并处理需要推理的帧,从而降低推理成本。接下来介绍其两个组成模块。
3.3.1 边缘端帧率控制器
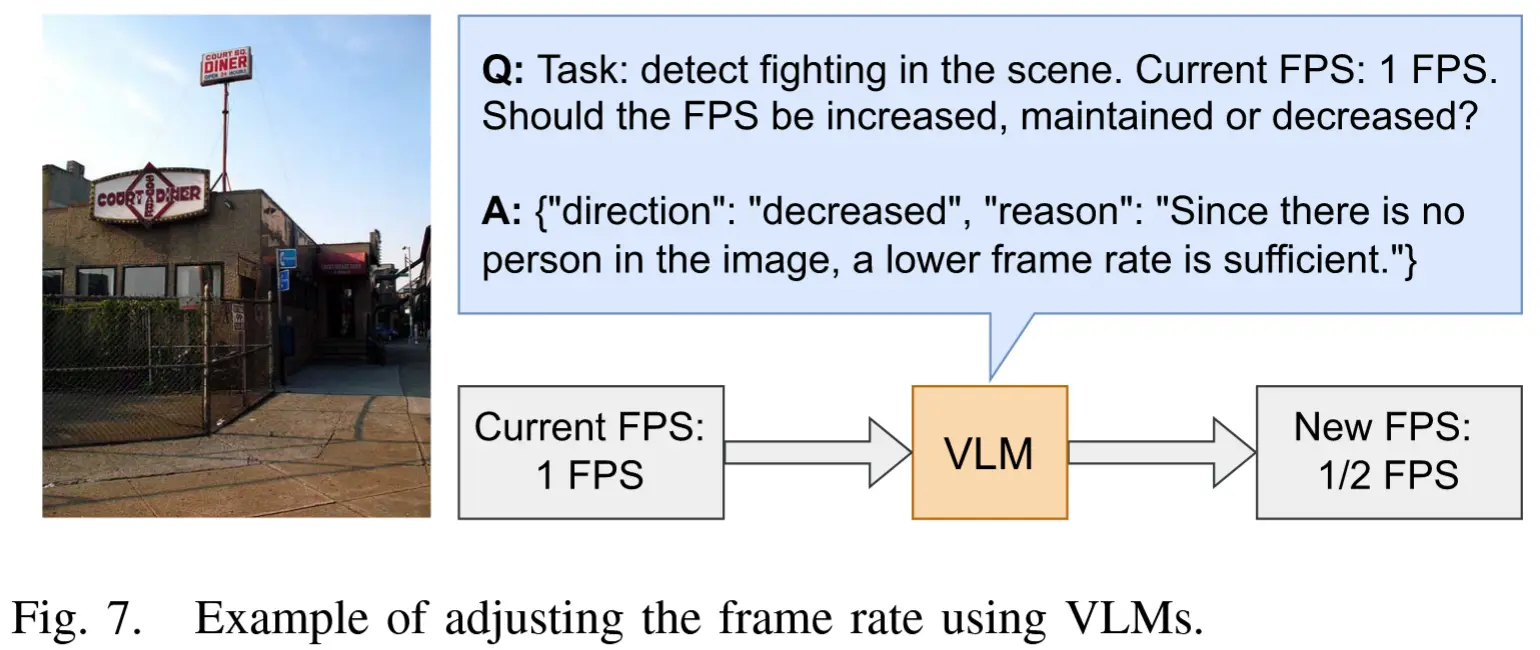
基本思路:帧率控制器通过利用 VLM 的推理能力,决定是否传输某一帧。该模块设计用于根据场景特征动态调整帧率,使系统能够实时适应突发的场景变化。
具体而言,对于给定的视频分析任务,首先设定一个初始帧率 f_{init} \in [f_{min}, f_{max}],对于每一帧,向 VLM 提出如下提示语:"Task: ⟨description_of_task⟩. Current FPS: ⟨current_frame_rate⟩. Should the FPS be increased, maintained, or decreased?" 。图7展示了一个示例。
完整的帧率控制器工作流程如 算法1 所示。
由于每次查询 VLM 来调整帧率会引入额外开销,因此仅在当前帧已发送至云端进行分析且自上次调整以来已过去预设时间周期 T 时才进行调整(第4和5行)。这种设计使得系统在需要时可以比降低帧率更快地提高帧率,从而更迅速地适应场景的突发变化。

3.3.2 云端推理控制器
基本思想:从边缘设备发送的一系列帧首先会被缓存在云端,然后输入到推理控制器中,以确定何时触发推理。
推理控制器的整体概念如图8所示。
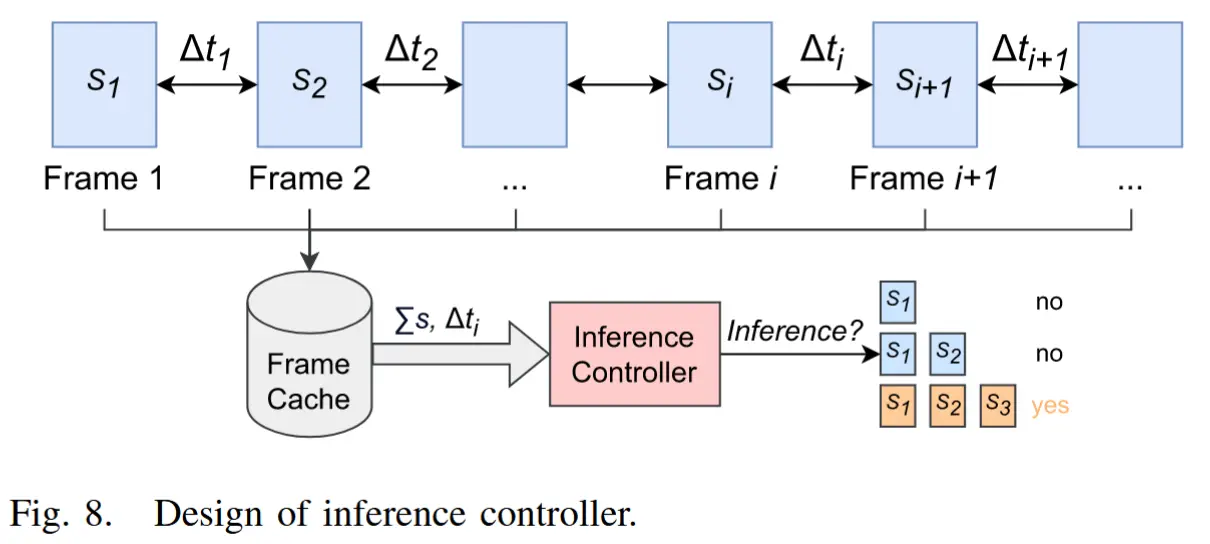
推理控制器必须考虑两个主要因素:
- 缓存帧的总像素大小。当帧的尺寸较小时(即 RoI 较小时),可以一次性组合和分析更多帧而不会丢失细节。
- 帧之间的时间差。随着第一帧与最后一帧之间的时间差增加,执行推理的紧迫性也随之增加,以便及时获得分析结果。
推理控制器的目标:在满足延迟目标的前提下,最大化分析准确性并最小化推理成本。
一系列帧表示为 \mathcal{F} = \{F_1, F_2, \dots, F_n\}。帧 F_i 的像素大小记为 s_i,其时间戳记为 T_i。帧之间的时差定义为 \Delta t_i = T_{i+1} - T_i。用户设置的延迟目标记为 \hat{L}。决策变量定义为 \alpha_i = \{0, 1\},其中 \alpha_i = 1 表示前 F_i 的所有缓存帧需要进行推理。等待推理的第一个缓存帧的索引记为 c。因此,\alpha_i 可以通过以下公式计算:
其中:
- \gamma 是像素区域的阈值;
- L_{\text{inf}} 是云端帧的推理延迟。
公式(1)含义:当缓存帧的总像素大小超过阈值 \gamma 或延迟目标即将被违反时,触发推理。
3.4 增强知识的模型推理
本节通过引入外部知识来增强VLM的推理能力。具体而言,我们将外部知识分为世界知识和模型知识两类。
3.4.1 世界知识
世界知识是指关于外部世界的相关信息,这些信息有助于视频分析任务中的推理过程。
本文中,世界知识包括以下三个方面:
- 任务的含义: 尽管VLM可以通过文本描述理解任务,但明确说明任务的含义可以帮助其提高判断力,尤其是在场景解释存在歧义的情况下。此外,用户对之前误报或漏检的反馈也可以被视为任务的含义,并纳入提示中,帮助VLM更好地理解任务并提升性能。
- 数据源的上下文: 数据源的设置对于VLM做出准确决策至关重要,因为它告知VLM待分析的数据是如何生成的。
- 当前时间戳: 时间戳信息为VLM提供了当前时间,这有助于决策过程。特别是在帧率控制中,这一点尤为重要。
3.4.2 模型知识
模型知识 指的是辅助模型的推理结果,例如目标检测模型和语义分割模型。在本节中,通过集成两种模型来增强VLM的推理能力:目标检测模型和活动识别模型。根据任务的具体需求,还可以进一步整合其他辅助模型以提高VLM的表现。
- 目标检测模型
- 目标检测模型能够为图像中的对象生成边界框和标签。这种模型在以下两种场景中非常有用:
- 回答与数量相关的问题
- 检测与特定对象类型相关的事件
- 具体流程如下:
- 首先,将帧输入目标检测模型,生成对象的边界框和标签。
- 然后,将这些信息整合到VLM的提示中。提示的结构如下:
"Total number of 〈object_category〉: 〈number〉. The 〈object_category〉 is annotated in 〈color〉."
- 图9展示了一个示例。
- 目标检测模型能够为图像中的对象生成边界框和标签。这种模型在以下两种场景中非常有用:
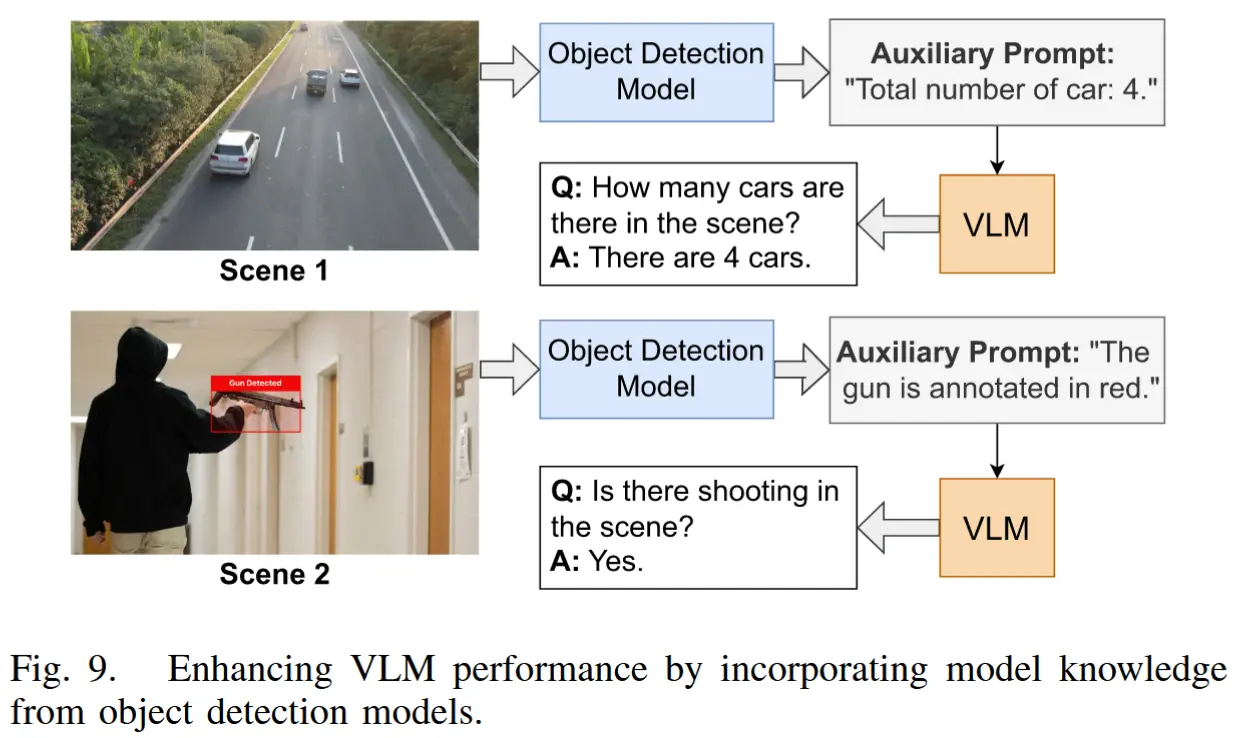
- 活动识别模型
- 活动识别模型的推理结果通常包括预测的活动类别及其置信度分数。
- 。由于本文关注的是基于事件的分析任务,活动识别模型的推理结果可以作为参考纳入VLM的提示中。提示的结构如下:
"Detected activity in the scene: <activity_category>. Confidence: <score>。"。
4 实验
4.1 实验设定
- 数据集:MSAD,一个真实世界的视频数据集,涵盖11种异常事件类型。
- 基线
- RTFM:一种弱监督的视频异常检测模型,通过训练一个特征幅度学习函数来有效识别视频中的事件。由于其训练集包含异常事件,将其作为对比的上限基准。
- SA_single:一种简单的方法,直接将帧从边缘设备逐个发送到云端,使用LLaVA进行推理。
- SA_mulit:缓存多个帧并一起发送到云端的LLaVA模型进行推理。缓存大小设置为3。
- 实验环境
- 边缘端:Jetson Xavier NX(8GB RAM)和Raspberry Pi 4B(4GB RAM)。
- 云端:RTX 3090 GPU(24GB VRAM)
- 网络连接:通过Tenda F3路由器(Wi-Fi 4)相连,使用iperf将可用带宽限制为10 Mbps。
- 实现细节:端云通信通过Socket API [56] 管理。
4.2 实验结果
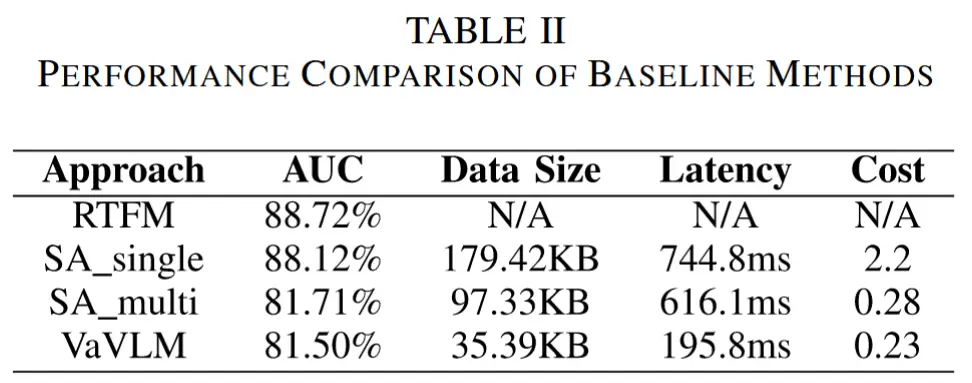
- 表 2 总结了各方法在 AUC(曲线下面积)、传输数据量、端到端延迟和计算成本方面的性能。
- 成本定义为每段视频平均每秒推理的帧数。
- 消融实验
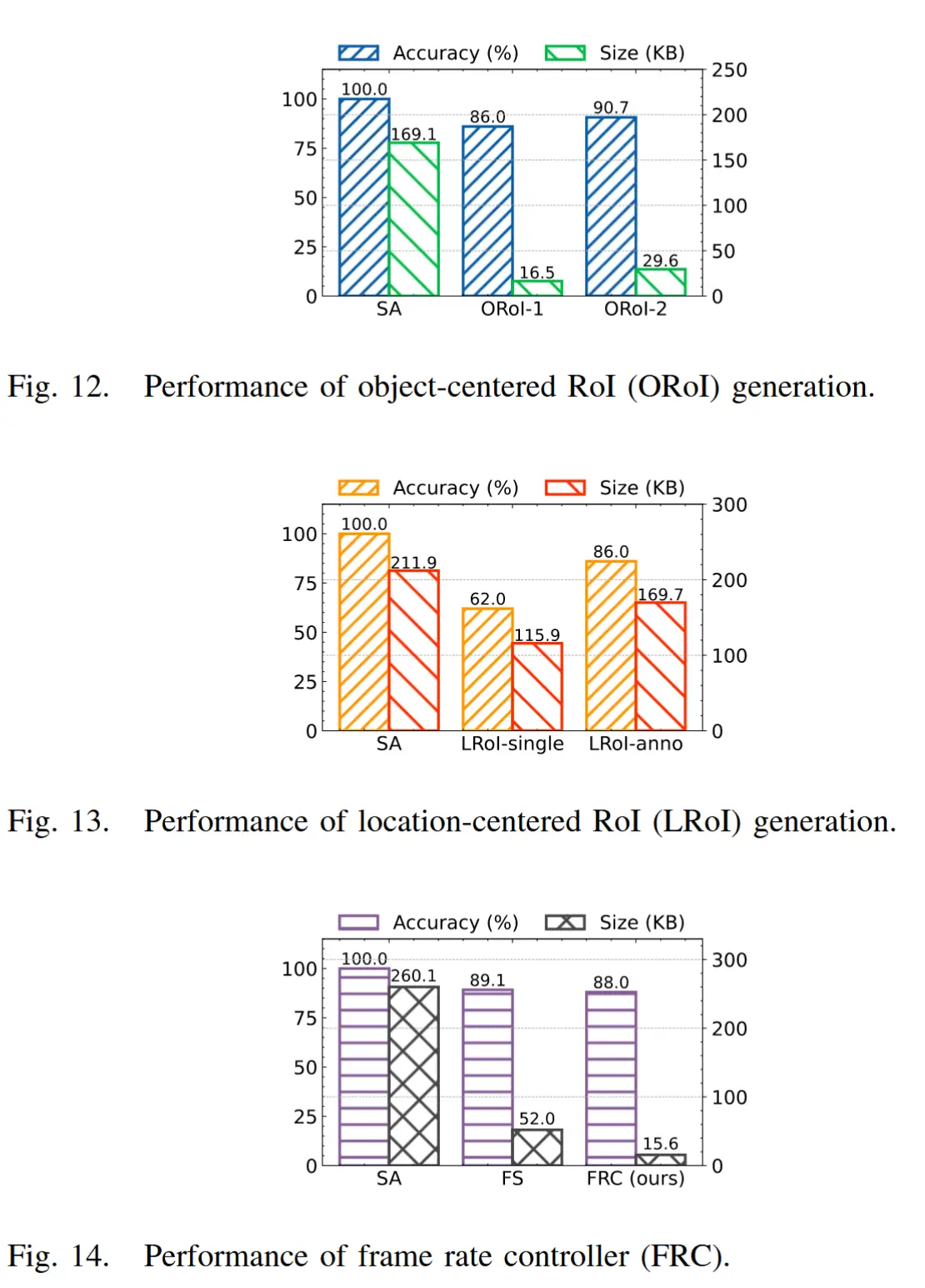
- 图12 展示了以对象为中心的 RoI 生成性能。其中,ORoI-α 表示启用了对象中心 RoI 生成模块的方法,α 是检测到的边界框的扩展比例。
- 图13 展示了以位置为中心的 RoI 生成性能。其中,"-single"表示将每个裁剪后的图像块单独发送给 LLM 进行判断。“-anno”表示将带有标注信息的整张图像发送给 LLM 进行判断。
- 图14 展示了边缘端的帧率控制器的性能。其中,FS表示固定采样率,FRC表示基于 VLM 的帧率控制器。
作者还进行了很多消融实验,不一一展示了。
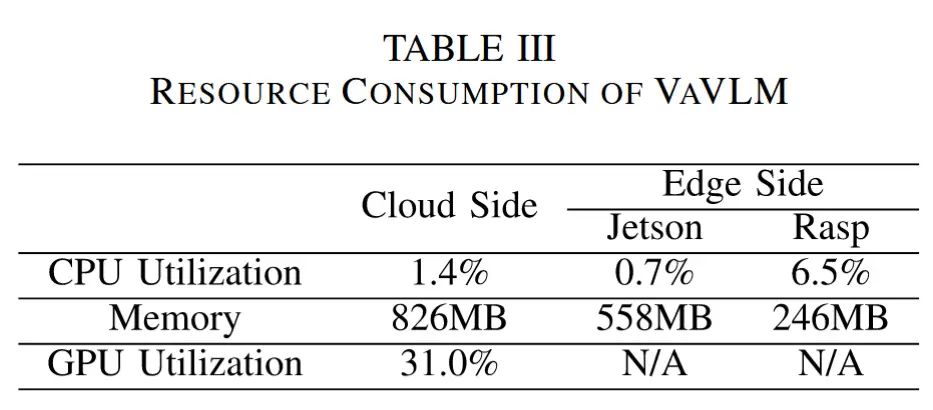
- 系统开销
- 表 III 中展示了 VaVLM 在云端服务器和边缘设备上专属占用的资源消耗 ,并且评估了两种不同的边缘设备。