- 论文 - 《STEAD: Spatio-Temporal Efficient Anomaly Detection for Time and Compute Sensitive Applications》
- 代码 - Github
- 关键词 - 实时推理、轻量化、时空建模、视频异常检测VAD、I3D、X3D
1 引言
- 动机
- 视频数据中固有的时间维度所带来的挑战与优势仍未被充分挖掘。
- 在模型的效率和实时推理方面,相关研究仍十分有限。
- 本文工作
- 提出了一种新的异常检测方法,STEAD(Spatio-Temporal Efficient Anomaly Detection),适用于对时间和计算资源敏感的自动化系统。
- 其主干网络采用 (2+1)D卷积 和 Performer线性注意力机制 构建,在不牺牲性能的前提下保证了计算效率。
2 相关工作
- 视频异常检测
- 早期方法依赖手工特征与统计模型[8]
- 近年来,引入了深度学习,例如CNN、GANs、双流网络架构[9-11]
- 更现代的方法使用视觉Transformer[12-13]
- 特征提取
- 先前的研究主要采用Inflated 3D ConvNet(I3D)作为特征提取器 [13-16],然而,I3D 模型在内存需求和计算资源方面成本较高,使其难以适用于实时推理应用。
- 在权衡计算效率与准确率的基础上,X3D 模型旨在从一个最小的二维骨干网络逐步扩展至时间长度、帧率、空间分辨率、通道宽度、网络深度和瓶颈宽度等多个维度。在训练过程中,每一步都会指示模型单独扩展每一个维度,并根据哪个维度的扩展在训练和验证后带来了最佳的计算与准确率之间的平衡,选择保留该维度。
- X3D 在许多流行数据集上表现出 Top-1 准确率,并且参数量还不到 I3D 的四分之,因此本文采用 X3D 模型来提取视频特征。
I3D 模型旨在解决视频识别中的时空特征学习问题,它成功的将二维卷积结构扩展为三维。为了实现这一点,该模型通过在时间维度上复制和池化二维卷积核,将其“膨胀”为三维。此外,该模型采用了双流设计,同时处理RGB图像和光流信息,以增强特征建模能力。
- 视觉Transformer
- 视觉 Transformer 在图像领域获得了巨大的成功。但是原始的 Transformer 架构在时间和空间复杂度上会随着图像尺寸呈二次增长,这使其在大规模应用中成为瓶颈。
- 为应对这一问题,研究人员提出了诸如 Linformer 和 Performer 等改进模型。Linformer 将计算复杂度降低至 O(nk),其中 k 是 n(序列长度)的一个低秩投影;而 Performer 则通过“正交随机特征快速注意力”(Fast Attention Via Orthogonal Random Features)在线性时间内近似注意力核函数。
- 本文的研究探索了这些高效技术,并将其应用于更高维的视频数据中,以提升时空异常检测的效率。
3 异常行为检测
3.1 总体架构
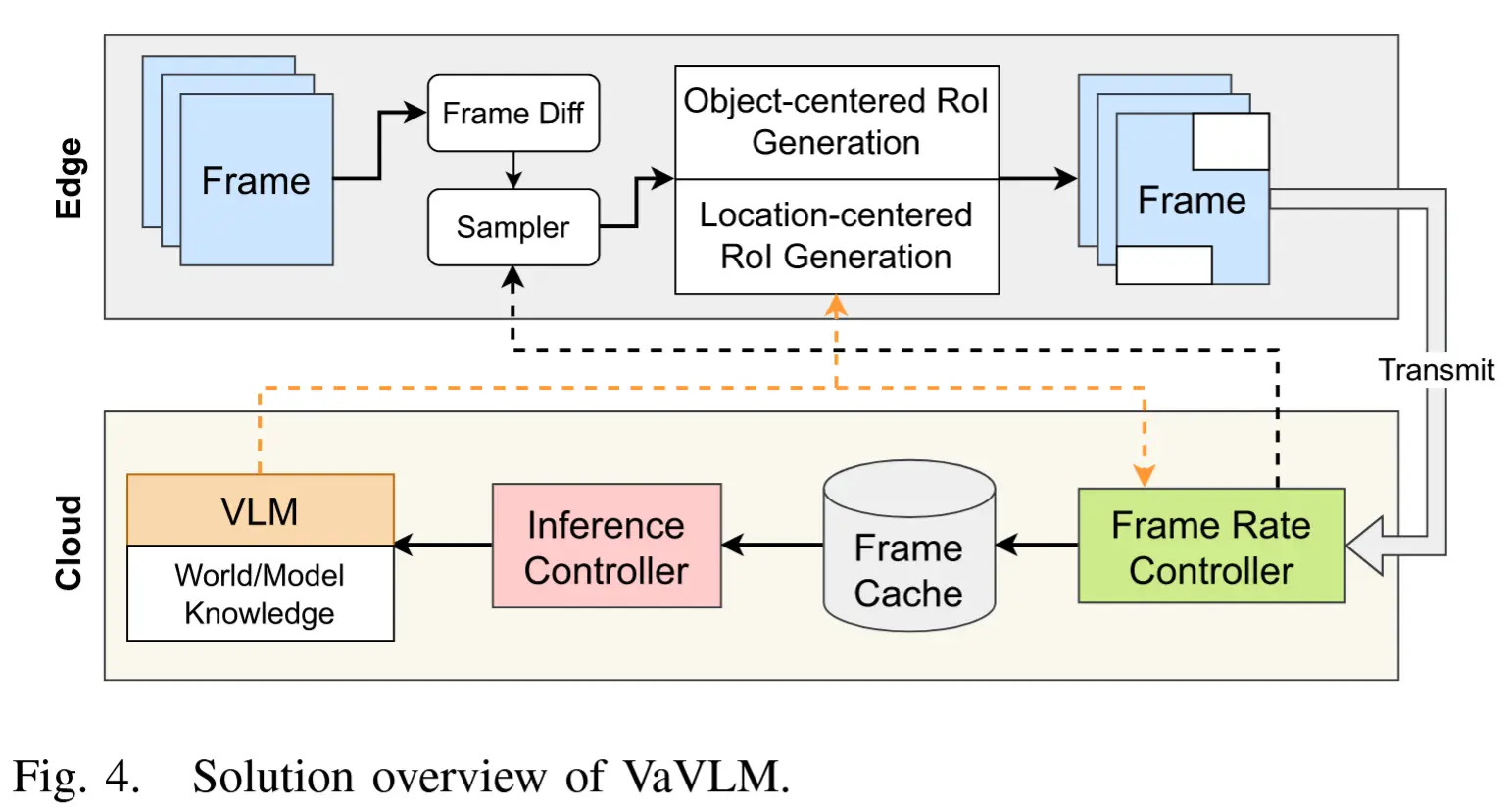
用于自动驾驶异常行为检测的整体架构如图3所示,整体流程如下:
- 视频首先经过中心裁剪处理,并均匀采样分割成多个片段(clips),然后通过 X3D 模型提取每个片段的特征。提取后的每个片段特征具有形状 C \times T \times H \times W ,其中 C 、 T 、 H 和 W 分别表示通道数、时间维度、高度和宽度。
- 接下来,这些片段特征被池化以获取每段视频中最显著的特征。
- 然后,视频特征作为输入传递到模型中,在模型中它们依次经过一个解耦的时空特征增强器和时空注意力块。在时空注意力块中,使用线性自注意力机制对特征之间的长程连接进行建模。
- 经过每个块处理后, T 、 H 、 W 被池化,最终得到一个大小为 d 的视频特征嵌入,其中 d 是最后一层的通道维度大小。
- 最后,采用**三元组损失(triplet loss)**进行训练,该损失旨在最大化正常样本和异常样本特征之间的数值可分离性。
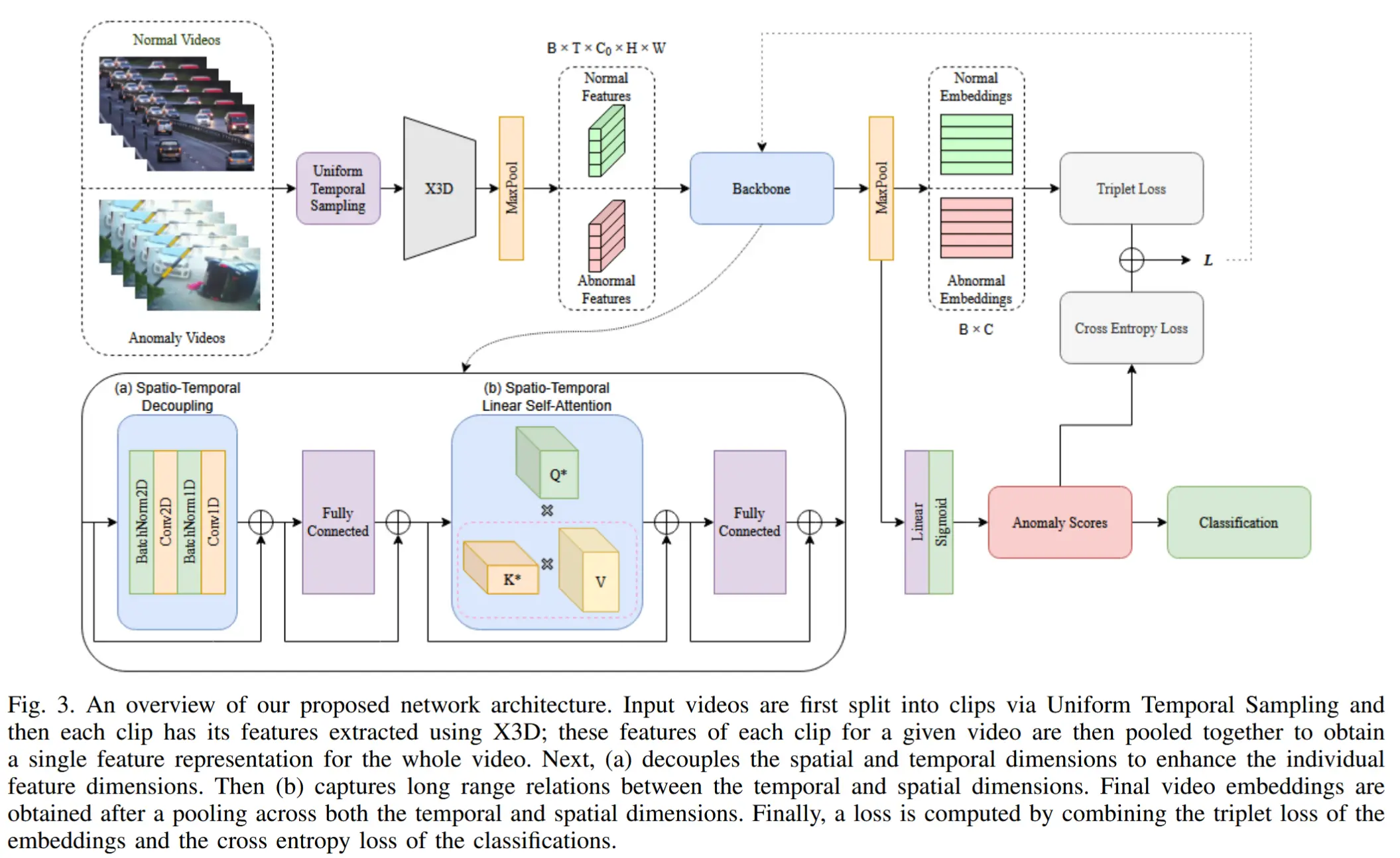
3.2 异常行为检测
解耦时空特征: 增强器遵循 (2+1)D 卷积架构,相较于直接执行 3D 卷积,它降低了计算复杂度。如图4所示,左边是传统的 I3D,右边是 (2+1)D 卷积,其中卷积被分成了空间卷积和时间卷积。特征增强器组成: (2+1)D 卷积+一层全连接层+GELU+一层全连接层,其中在每个模块之前应用 LayerNorm,并在每个模块之后添加残差连接。

时空注意力块: 采用 Performer 注意力架构,原始 Transformer 计算 \exp\left(\frac{Q K^T}{\sqrt{C}}\right) 时,会面临与 L 成二次关系的计算成本。Performer 注意力通过以下方式解决了这一问题:将 softmax 核函数近似表示为:
并重新排列注意力计算公式为:
其中
且 \phi: \mathbb{R}^C \to \mathbb{R}^{C'} 是一个特征映射,满足 d' > d 。通过将 Q 和 K 映射到更高维度 d' ,并对计算进行重新排列,可以实现对 softmax 核函数的准确逼近,同时将计算成本降低为与 (T \times H \times W) 线性相关的水平。
Performer 注意力之后是一个包含两层全连接层的 FFN,这两层之间使用 GELU 作为非线性激活函数。在每个模块之前应用 LayerNorm,并在每个模块之后添加残差连接。
三元组损失:为了鼓励正常样本和异常样本之间的特征可分离性,作者引入了三元组损失,如下所示,其中正常视频嵌入同时充当负样本和锚点:
其中 \mathbf{e}_i = \{\mathbf{e}_i^n, \mathbf{e}_j^a | i, j = 1, \dots, N\},\mathbf{e}_i^n 和 \mathbf{e}_j^a \in \mathbb{R}^d 分别表示第 i 个和第 j 个样本的正常和异常最终特征嵌入。每个批次大小为 2N,包含 N 个正常视频和 N 个异常视频。d 表示欧几里得距离。通过强制执行正常和异常特征嵌入之间的最大间隔 M,限制模型仅优化正常和异常嵌入之间的距离。嵌入距离函数 D 定义为欧几里得距离。
将此三元组损失函数与二元交叉熵损失结合:
其中 y_i 是 \mathbf{e}_i 的真实标签,\hat{y}_i 是对 \mathbf{e}_i 的预测,我们可以得到一个总体损失函数 \mathcal{L}:
其中 i = 1, \dots, 2N,且 \lambda \in \mathbb{R} 控制三元组损失项的权重。
4 实验
4.1 实验设置
- 数据集 UCF-Crime
- 两种架构
- STEAD-Base:提取的视频特征形状为 (C, T, H, W) = (192, 16, 10, 10),特征增强器模块和注意力模块的通道维度分别为192和128,且每个模块的深度均为3层。
- STEAD-Fast:提取的视频特征形状为 (C, T, H, W) = (192, 16, 10, 10),特征增强器模块和注意力模块的通道维度均为32,模块深度为1层。
- 评估指标:ROC-AUC
4.2 结果分析
- 表1 与sota方法进行对比

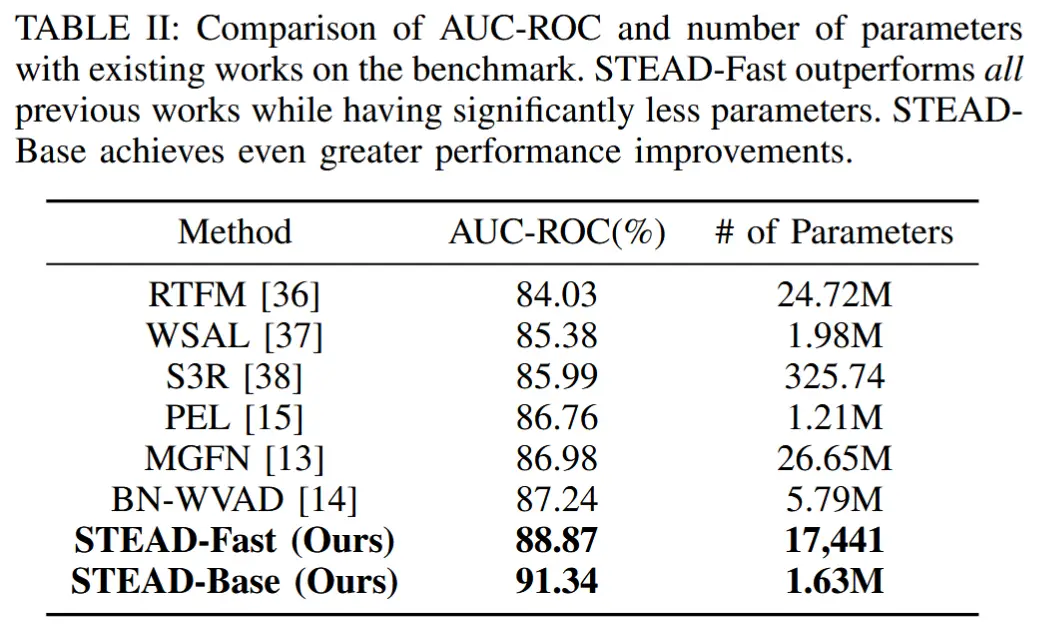
按照前面的方法介绍,把clip级的feature最大池化获得视频级的显著feature,也看了一下代码,所以这里的AUC-ROC是视频级的,但是以前的工作都是帧级的,似乎有点不公平。
- 表3 消融实验
- 分别对三元组损失、解耦时空特征增强块、时空注意力块进行消融。
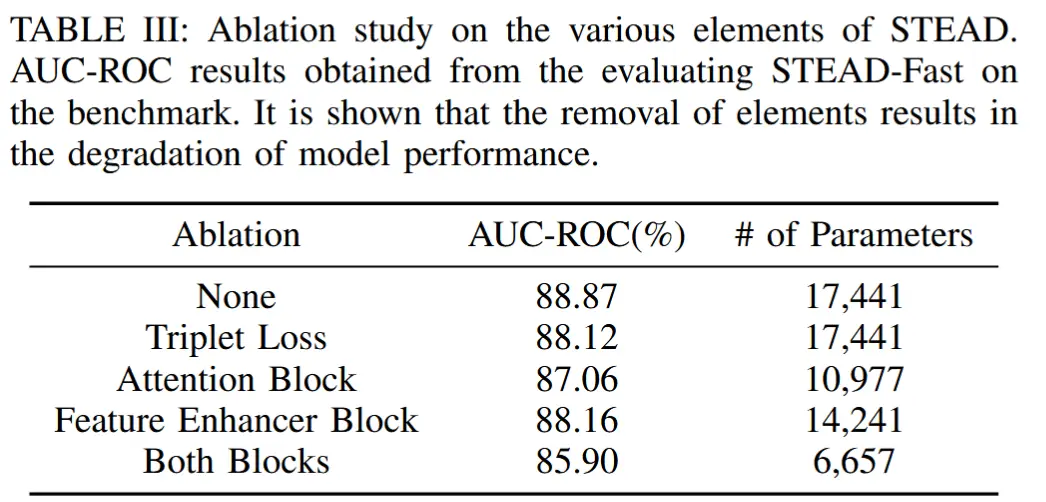
性能确实提升非常多,应该是UCF-Crime目前最佳性能了,参数量也减少了很多,不过这里的参数量没有包括X3D特征提取器的6.15M参数,因此在考虑实时推理时,延迟应该变化不大。