- 论文 - 《Video-LLaVA: Learning United Visual Representation by Alignment Before Projection》
- 代码 - Github
- 关键词 - 微调、LanguageBind、Vicuna、视频大模型、视觉-语言大模型
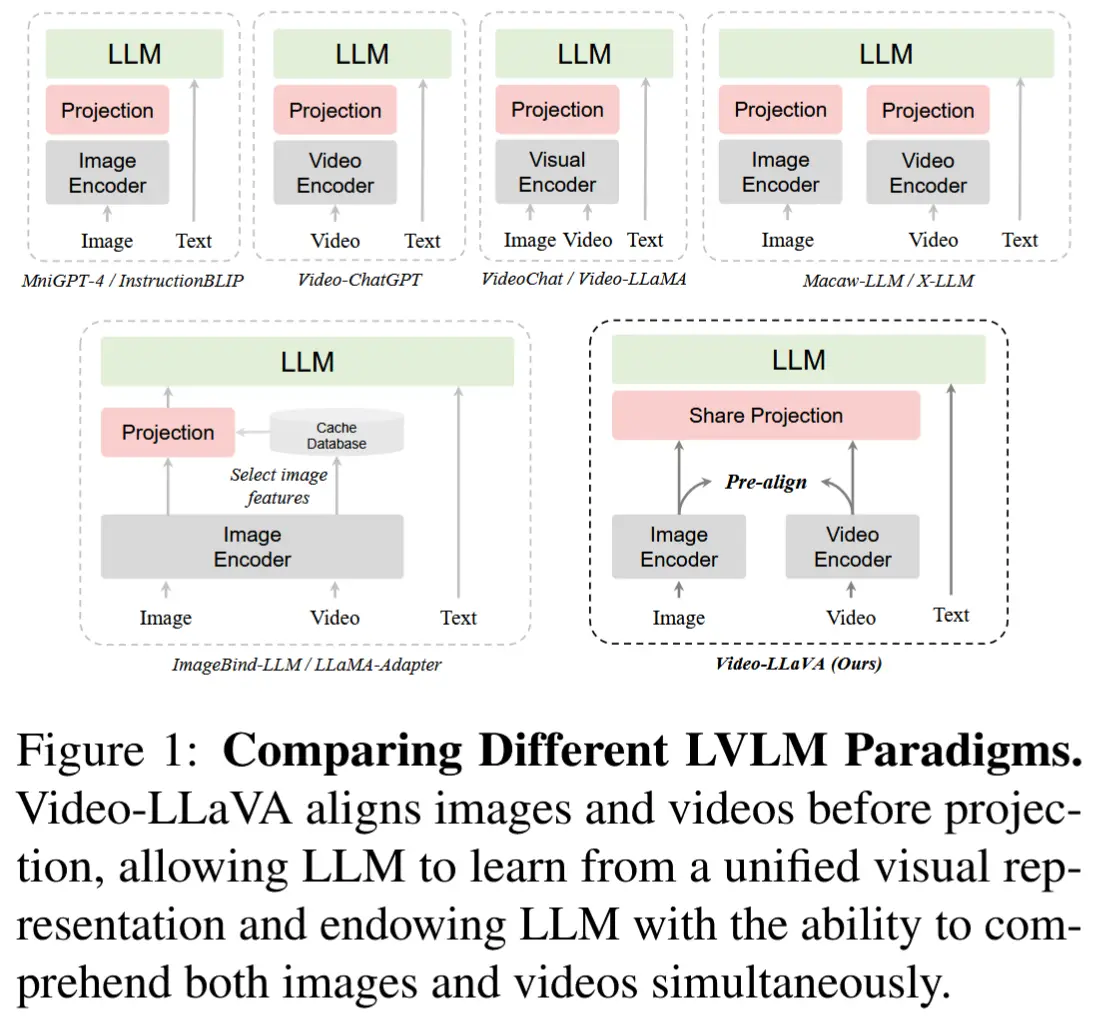
0 比较不同的 LVLM 范式
- 大型视觉-语言模型(LVLM)对比
1 Video-LLaVA
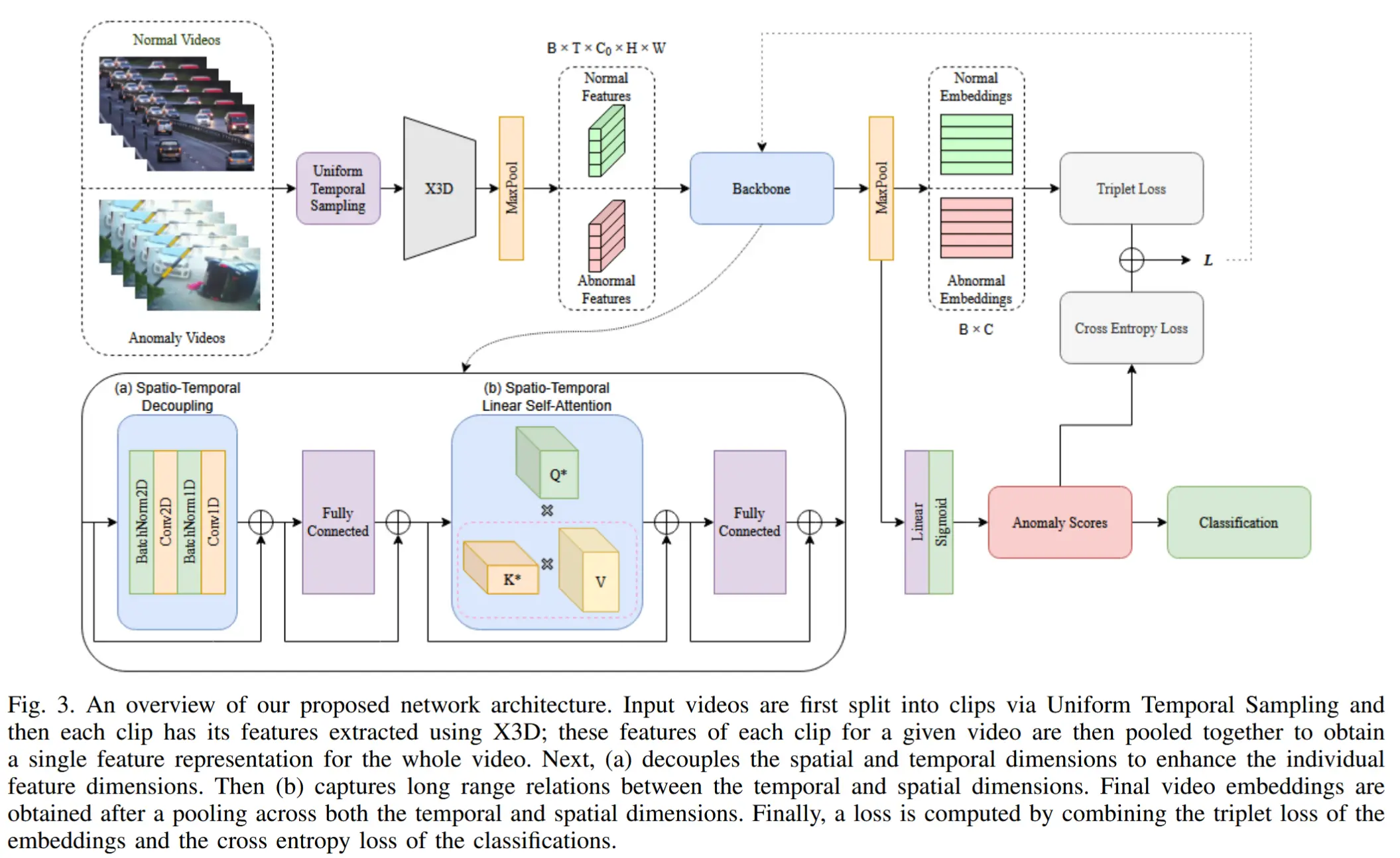
1.1 模型结构
1.1.1 框架概述
如图2所示,Video-LLaVA 包括以下组件:LanguageBind 编码器 f_V 、大型语言模型 f_L (Vicuna)、视觉投影层 f_P 、词嵌入层 f_T 。
处理流程:首先使用 LanguageBind 编码器获取视觉特征,将不同模态映射到文本特征空间中,从而提供统一的视觉表示。随后,这种统一的视觉表示通过共享的投影层进行编码,并与分词后的文本查询结合,输入至 LLM,以生成相应的响应。

1.1.2 统一的视觉表示
目标:将图像和视频映射到一个共享的特征空间中,使 LLM 能够基于统一的视觉表示进行学习。
方法:采用了 LanguageBind 中的模态编码器,该方法能够将图像和视频对齐到文本特征空间中,实现统一的视觉表示。
1.1.3 投影前对齐
LanguageBind 的训练流程:初始化来源于 OpenCLIP(Ilharco 等,2021),它天然地实现了图像与语言在共享特征空间中的对齐。随后,使用来自 VIDAL-10M 数据集的300万对视频-文本数据,将视频表示也对齐到语言空间中。通过共享语言特征空间,图像和视频的表示最终收敛到一个统一的视觉特征空间中。
因此,在 Video-LLaVA 中,视频编码器和图像编码器均初始化自 LanguageBind 编码器库。随后,统一的视觉表示经过共享的投影层后,被输入到 LLM 中,从而实现多模态的理解与推理。
1.2 训练流程
总体而言,Video-LLaVA 生成响应的过程与大型语言模型(GPT 系列)类似。给定文本输入 \mathbf{X}_\text{T} 和视觉信号 \mathbf{X}_\text{V} ,输入信号根据公式 (1) 被编码为一系列词元。通过最大化公式 (2) 中的似然概率,模型最终实现了多模态理解能力。
其中, L 是生成序列 \mathbf{X}_\text{A} 的长度, \theta 是可训练参数。动态地对图像和视频进行联合训练,其中每个批次同时包含图像和视频样本。
两个训练阶段和对应的数据集如图3所示。

1.2.1 Understanding 训练
在这一阶段,模型需要从一个广泛的图像/视频-文本配对数据集中学习解读视觉信号的能力。每个视觉信号对应一组单轮对话数据 (\mathbf{X}_\text{q}, \mathbf{X}_\text{a}) ,其中 \mathbf{X}_\text{T} = \mathbf{X}_\text{q} 是查询,而 \mathbf{X}_\text{a} 是对应的 ground truth。该阶段的训练目标是原始的自回归损失,模型在此过程中学习基本的视觉理解能力。在这个过程中,冻结模型的其他参数。
1.2.2 指令微调
在这一阶段,模型需要根据不同的指令生成相应的响应。这些指令通常涉及更复杂的视觉理解任务,而不仅仅是描述视觉信号。需要注意的是,对话数据 (\mathbf{X}_\text{q}^1, \mathbf{X}_\text{a}^1, \dots, \mathbf{X}_\text{q}^N, \mathbf{X}_\text{a}^N) 包含多轮对话。
其中, r 表示当前的轮次编号。如公式 (3) 所示,当 r > 1 时,将所有前一轮的对话内容与当前指令拼接起来作为本轮的输入。训练目标与上一阶段相同。经过这一阶段后,模型学会了根据不同的指令和请求生成相应的响应。LLM 也在这一阶段参与训练。
实验部分不展示了,感兴趣可以去看原论文。