- 论文 - 《MobileVLM V2: Faster and Stronger Baseline for Vision Language Model》
- 代码 - Github
- 关键词 - 边缘智能、高效大模型、视觉-语言模型VLM
1 引言
- 动机:打造小型视觉-语言模型VLM。
- 本文工作 - MobileVLM V2
- V2 在 MobileVLM 的基础上进行了三个关键改进:
- 挖掘对小型 VLMs 有效的训练数据:使用了由 ShareGPT4V 提供的 120 万高质量图像-文本对来有效对齐视觉-语言特征,并引入多种任务以提高数据多样性和指令跟随能力,例如 ScienceQA、TextVQA、SBU 等。
- 探索高效的训练策略:不同于以往工作冻结LLM和编码器,本文对投影器和LLM同时进行训练。
- 高性能轻量级投影器:引入了一种更加简洁但强大的投影机制来连接视觉和语言模型。通过增强图像 token 的位置信息表示,可以显著减少图像 token 的数量而不造成明显的性能下降。
- 性能:MobileVLM V2 1.7B在标准VLM基准测试中表现优于或媲美于规模大得多的3B级别VLM模型。
- V2 在 MobileVLM 的基础上进行了三个关键改进:
2 方法介绍
-
MobileVLM V2 的整体架构如图2所示,包含以下组件:
- 预训练的视觉编码器 CLIP
- 预训练的大语言模型 MobileLLaMA
- 面向移动设备的投影器 LDPv2
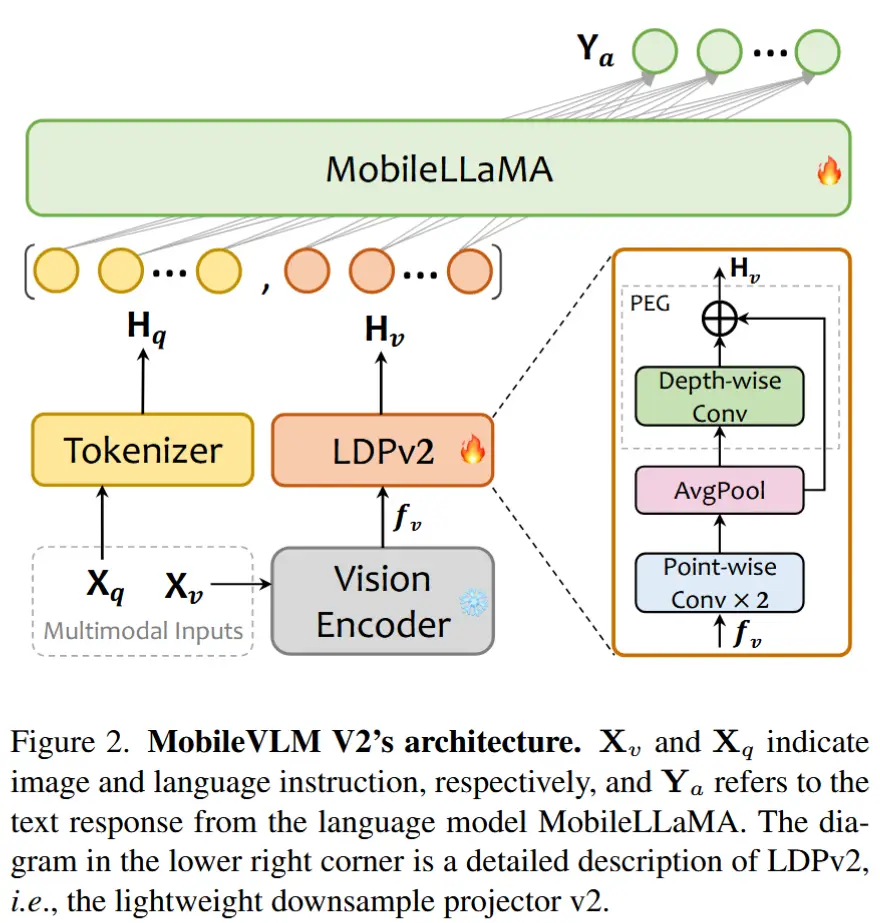
2.1 视觉编码器
使用预训练的 CLIP ViT-L/14 作为视觉编码器 \mathbf{F}_{\text{enc}} 。
具体而言,图像 \mathbf{X}_v \in \mathbb{R}^{H \times W \times C} 首先被调整为分辨率 336 \times 336 ,并以步幅 P = 14 划分为 patch。然后提取高级视觉嵌入 f_v \in \mathbb{R}^{N_v \times D_v} ,用于表示图像的语义信息,其中 N_v = HW / P^2 表示序列长度, D_v 表示视觉嵌入的隐藏尺寸。形式上:
2.2 语言模型
采用预训练的 MobileLLaMA-1.4/2.7B-Chat 作为基础 LLM 。
选择 MobileLLaMA 的理由:
- MobileLLaMA 开箱即用,并且专为资源受限设备设计。
- MobileLLaMA 与 LLaMA2 共享相同的分词器(tokenizer),这有助于无痛地执行蒸馏过程。
- MobileLLaMA 是在开放数据集上训练的,不存在因数据泄露而导致评估污染的风险。
具体而言,文本输入 \mathbf{X}_q 首先被分词并处理为文本 token \mathbf{H}_q \in \mathbb{R}^{N_t \times D_t},其中 N_t 表示文本 token 的序列长度, D_t 是词嵌入空间的隐藏尺寸。文本 token \mathbf{H}_q 和视觉 token \mathbf{H}_v 经过投影器转换后,被拼接为语言模型的输入。最终响应 \mathbf{Y}_a 以自回归方式生成,其长度为 L ,如下所示:
2.3 轻量级下采样投影器
轻量级下采样投影器 LDPv2 基于 LDP 改进而来,相比之下减少了 99.8% 的参数。LDPv2 包含三个组件:
- 特征变换:在图像 token 上使用两个逐点卷积层来匹配 LLM 的特征维度。
- token 减少:引入一个平均池化层来极度压缩图像 token 的数量。
- 位置信息增强:应用一个非常简单但有效的模块 PEG(with skip connection),以增强位置信息。
形式上,LDPv2(记为 \mathbf{P} )将视觉嵌入 f_v \in \mathbb{R}^{N_v \times D_v} 转换为经过位置增强的模态对齐视觉 token \mathbf{H}_v 。给定一个平均核 k ,剩余 token 的数量仅为输入特征的 1/k^2 。具体而言,LDPv2 定义如下:
其中, PW 和 DW 分别表示逐点卷积和深度可分离卷积, \text{GELU} 是激活层,而 \text{AvgPool}_{2\times2} 是一个 2 \times 2 平均池化层。
2.4 训练策略
MobileVLM V2 训练过程分为预训练和多任务训练两个阶段,注意两个阶段中始终同时打开投影器和大语言模型,同时冻结视觉编码器。
2.4.1 预训练
初始化:分别从 CLIP ViT-L/14 和 MobileLLaMA 初始化视觉编码器和语言模型的权重。
训练目标:使用 next token 预测的自回归损失函数,使模型能够更好地学习在视觉信息上下文中生成语言的复杂性。
数据集:ShareGPT4V-PT,包含 120 万图像-文本对,这个数据集对于提升模型的图像-文本对齐能力至关重要。
2.4.2 多任务训练
模型当前状态:MobileVLM V2 已具备初步理解图像内容的能力。然而,它在利用视觉信息进行分析和对话方面仍缺乏熟练度,尤其是在一系列下游任务中。
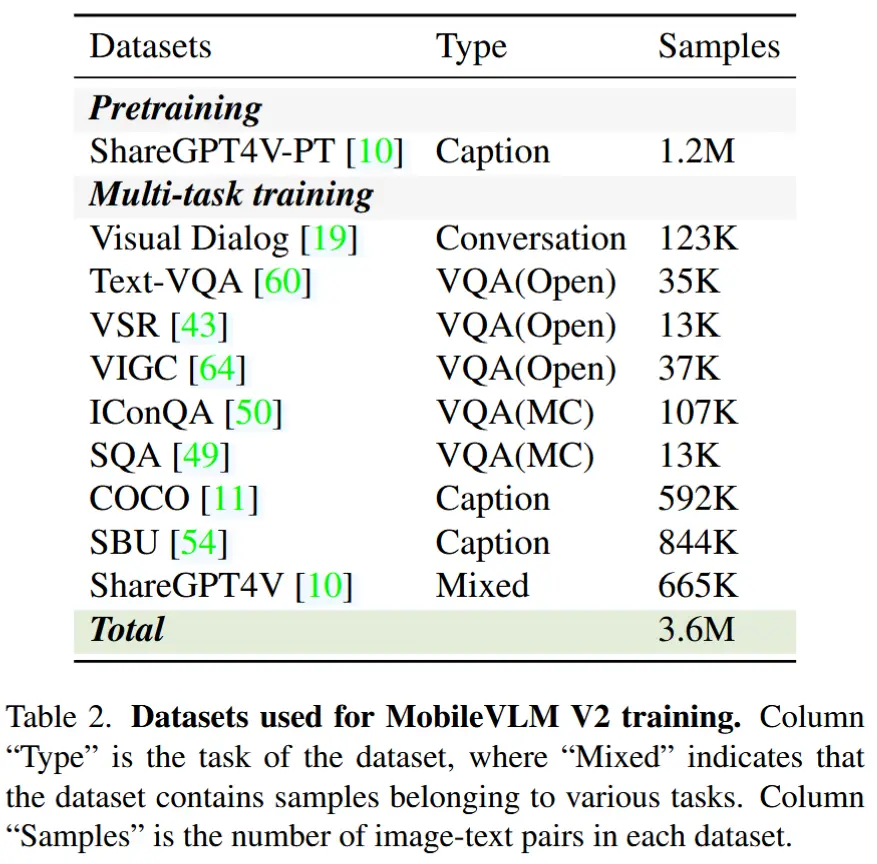
引入多种视觉-语言任务,如表2所示,包括以下任务:
- 通过 Visual Dialog 数据集 [19] 提升对话能力。
- 通过 TextVQA 数据集 [60] 提升 OCR 技能。
- 通过 COCO Caption [11] 和 SBU [54] 数据集提升场景理解能力。
- 通过 VSR 数据集 [43] 等提升位置理解能力。
关于各数据集中对话格式的示例,请参见论文附录 A。
实验部分见论文,两个训练阶段都在8 块 A100 进行,分别训练 5 和 9 个小时。

