- 论文 - 《Real-Time Video Inference on Edge Devices via Adaptive Model Streaming》
- 代码 - Github
- 关键词 - 实时视频推理、边缘智能、蒸馏、端云协作、适应、ICCV2021
摘要
- 研究问题
- 在移动电话和无人机等边缘设备上进行实时视频推理具有挑战性,因为深度神经网络的计算成本很高。
- 解决办法 - 自适应模型流 Adaptive Model Streaming, AMS
- 提出了自适应模型流(Adaptive Model Streaming, AMS),这是一种新方法,旨在提高边缘设备上用于视频推理的高效轻量级模型的性能。
- AMS 使用远程服务器不断训练和调整运行在边缘设备上的小型模型,通过从一个大型的、最先进的模型在线知识蒸馏来提升其在实时视频上的表现。
- 实验结果
- 与预训练模型相比,在多个视频数据集上平均交并比(Intersection-over-Union)提高了 0.4%-17.8%。本文的原型系统可以在三星 Galaxy S10+ 手机上以 30 帧每秒的速度执行视频分割,摄像头到标签的延迟为 40 毫秒,使用不到 300 Kbps 的设备上行和下行带宽。
1 介绍
-
实时视频推理
- 实时视频推理是许多应用的核心组件,然而,最先进的 DNN 模型在低功耗边缘设备(例如手机、无人机、消费级机器人 [57, 58])上运行成本过高。
- 提高推理效率的一个有前景的方法是为 特定视频和任务定制一个轻量级模型。
- 其基本思想是利用知识蒸馏 [30] 将知识从一个大型“教师”模型传递到一个小的“学生”模型。
- Noscope [33] 在离线状态下训练一个学生模型,用于检测某些特定视频中的少数目标类别。
- Just-In-Time [46] 将这一思想扩展到实时动态视频中,通过在线训练学生模型,使其适应不断到达的视频帧。
- 但是这些方法对于边缘设备上的设备端推理来说却不可行。一是因为离线方法并不理想,二是在边缘设备上在线训练学生模型计算上是不可行的。
-
本文方法 - 自适应模型流 AMS
- 这是一种针对边缘设备上的实时视频推理的新方法,该方法将知识蒸馏卸载到通过网络与边缘设备通信的远程服务器上。
- AMS 不断调整运行在边缘设备上的小型学生模型,以实时提升其对特定视频的准确性。边缘设备定期向远程服务器发送样本视频帧,服务器使用这些帧对(边缘设备模型的副本)进行微调,使其模仿大型教师模型,并将更新后的学生模型发送(或“流式传输”)回边缘设备。
-
新挑战一 - 通信开销
- 解决办法:在 适当选择的近期帧范围 内训练学生模型——既不过小而导致过拟合,也不过大以至于超出模型的泛化能力——与 Just-In-Time 训练相比,可以在减少一个数量级的模型更新次数的情况下实现高精度。
-
新挑战二 - 带宽
- 对于下行链路,作者开发了一种 坐标下降算法,每次更新时只训练并发送一小部分模型参数。作者的方法识别出对模型精度影响最大的参数子集,并且兼容像 Adam [36] 这样在训练迭代中维护状态(例如梯度矩)的优化器。
- 对于上行链路,作者提出了 动态调整边缘设备帧采样率 的算法,根据视频中场景变化的速度来进行调整。
- 综合这些技术,对于一个具有挑战性的语义分割任务,它们将下行链路和上行链路带宽分别降低到仅 181–225 Kbps 和 57–296 Kbps(针对不同视频)。
- 图 1 展示了三个可视化示例,比较了 AMS 与这些基线方法的准确性。

2 相关工作
-
设备端推理
- 小模型:手动设计和通过神经架构搜索(NAS)生成。
- 模型量化和权重剪枝技术。
- 针对视频推理,一些技术通过使用光流方法跳过某些帧的推理来分摊推理成本 [68, 67, 32]。
- 尽管取得了这些进展,轻量级模型与最先进的解决方案之间仍然存在显著的性能差距 [16, 31]。AMS 可以与设备端优化技术互补,并且也能从中受益。
-
远程推理
- Cloud-Only:一些方案将全部或部分计算卸载到远程机器上,高带宽、高延迟、受网络影响严重。
- Edge Compution:通过将远程机器部署在靠近边缘设备的位置减轻了这些问题,但并未完全消除它们,并且带来了额外的基础设施和维护成本。
- 相比之下,AMS 需要的带宽远低于远程推理,且由于推理是在本地设备上完成的,因此受网络延迟或中断的影响较小。
-
在线学习
- 常见的就是最小化动态后悔值(dynamic regret)或跟踪后悔值(tracking regret)的算法,动态后悔值将在线学习器的性能与一系列最优解进行比较。
- 其他工作则聚焦于“专家”设定,其中学习器维护多个模型并在每个时刻选择最佳模型。
- AMS 基于在线梯度下降,因为对于每段视频在服务器上跟踪多个模型的成本过高。
3 自适应模型流 AMS
图 2 提供了 AMS 的概览。每个边缘设备会 缓存采样的视频帧持续 T_{update} 秒,然后将这些缓存的帧 压缩 并发送到远程服务器。服务器使用这些帧通过 监督知识蒸馏 训练边缘设备模型的一个副本,并将模型更新发送回边缘设备。为了具体说明,本文以 语义分割任务 为例描述的设计,但该方法具有通用性,可以适配到其他任务。
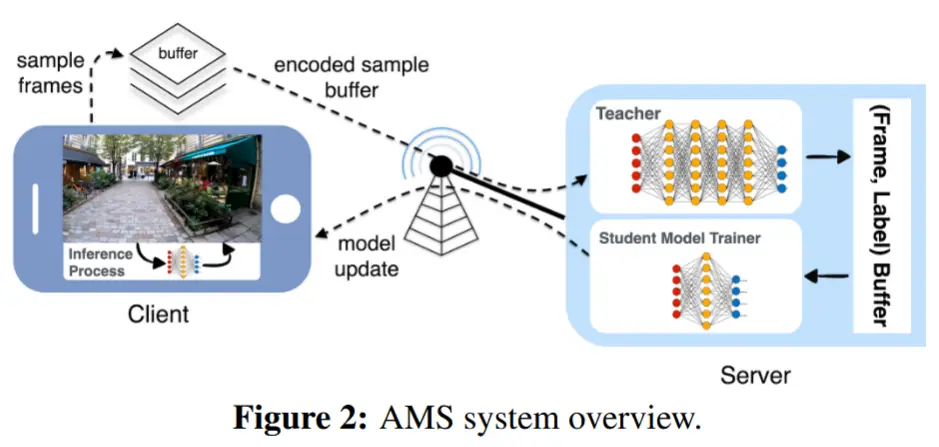
- 服务器
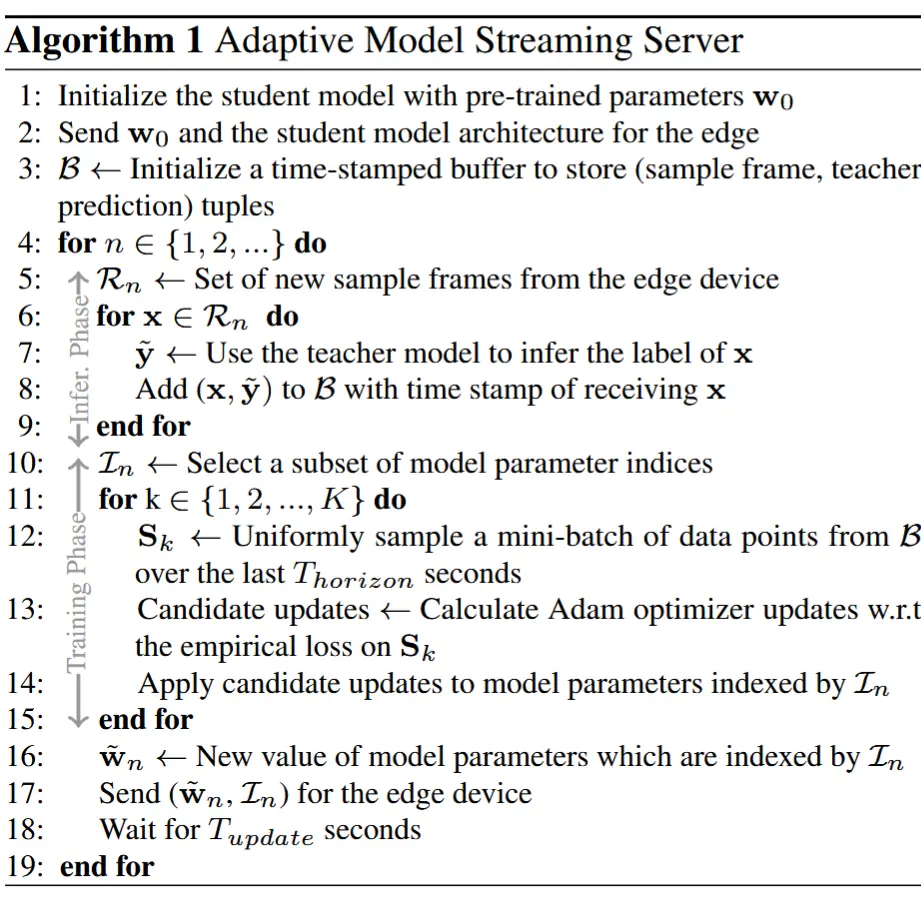
- 算法 1 展示了服务器为单个边缘设备服务的过程。AMS 算法在服务器上每次接收到边缘设备的新一批帧时迭代运行。它包括两个阶段:推理阶段 和 训练阶段。
- 推理阶段:为了进行训练,服务器首先需要为传入的视频帧生成标签。它使用一个最先进的分割模型作为“教师”模型来生成这些标签,从而实现监督知识蒸馏。服务器在新帧上运行教师模型,并将这些帧、它们的时间戳和生成的标签添加到训练数据缓冲区 B 中。
- 训练阶段:服务器训练学生模型以最小化过去 T_{horizon} 秒视频中缓冲区内的样本帧的损失。为了减少带宽使用,服务器 选择一小部分参数 进行 每次模型更新,并在随机采样的小批量帧上训练这些参数 K 次 迭代。
- 边缘设备
- 边缘设备在接收到新模型后立即部署它们以执行本地推理。
- 为了在切换模型时不影响推理过程,边缘设备在内存中维护一个运行中模型的非活动副本,并将模型更新应用到该副本上。一旦准备就绪,它会交换活动模型和非活动模型。
- 此外,边缘设备按照服务器指定的帧采样率对视频帧进行采样,并每隔 T_{update} 秒将这些帧发送到服务器。
3.1 减少下行链路带宽
- 下行链路带宽取决于以下两个因素:
- (i) 更新学生模型的频率
- (ii) 每次模型更新的成本
3.1.1 训练频率如何确定?
训练频率的关键在于每次模型更新所使用的训练时间窗口(T_{horizon})。
先前的工作 Just-In-Time [46] 在检测到模型精度低于某个阈值时对模型进行训练,并且仅使用最近的一帧进行训练(直到精度超过阈值)。这种方法容易对最近的帧过度拟合,因此需要频繁重新训练以维持所需的精度。
尽管轻量级模型的容量小于大型模型,但它们仍能在一定程度上泛化。因此,AMS 并未对一帧或少数几帧进行狭隘的过度拟合,而是采用了数分钟的训练时间窗口。这减少了模型更新的频率,并有助于缓解场景变化时模型滞后导致的精度急剧下降。
对于使用 DeeplabV3 和 MobileNetV2 骨干网络作为学生模型的语义分割任务, T_{horizon} = 4 分钟 和 T_{update} = 10 秒 在各种视频中均表现良好(见 §4)。然而,这些参数的最佳值可能取决于模型容量和视频特性 。例如,容量较低的学生模型可能受益于更短的 T_{horizon} 和 T_{update},而几乎没有场景变化的静态视频可以使用更长的 T_{update}。
3.1.2 更新哪些参数?
直接将整个学生模型发送到边缘设备可能会消耗大量带宽。为了减少带宽使用,AMS 采用了坐标下降法,在每次训练阶段中仅训练一小部分参数(例如 5%),记作 \mathcal{I}_n,并将这些参数发送到边缘设备。
为了选择 \mathcal{I}_n,利用 模型梯度 来识别 更新时对损失函数改进最大的参数(坐标)。一种标准方法是 Gauss-Southwell 选择规则,即更新梯度幅度最大的参数。这种方法适用于简单的无状态优化器(如随机梯度下降 SGD),但对于像 Adam [36] 这样在训练迭代间维护内部状态的优化器,则需要更精细的处理。
Adam 在每次迭代中 跟踪梯度的一阶和二阶矩的移动平均值,并利用这一状态根据梯度中的“噪声”幅度 动态调整每个参数的学习率。Adam 的内部状态更新依赖于当前迭代中访问的参数空间点。因此,为了确保内部状态正确,不能简单地在 K 次迭代中计算 Adam 的更新,然后在最后仅保留变化最大的坐标。必须提前知道要更新哪些坐标,以便在整个训练过程中一致地更新 Adam 的内部状态。
在 Adam 优化器中采用的坐标下降方法在每个训练阶段开始时,基于前一阶段中变化最大的坐标计算出要更新的参数子集。这一子集在该训练阶段的 K 次迭代中固定不变。
算法 2 中的伪代码描述了第 n 个训练阶段的过程。每个训练阶段包括 K 次迭代,数据来自视频过去 T_{horizon} 秒内的随机采样小批量数据点。在第 k 次迭代中,按照典型的 Adam 规则更新优化器的一阶和二阶矩(m_{n,k} 和 v_{n,k})(第 7–10 行)。然后,计算所有模型参数的 Adam 更新值 u_{n,k}(第 11–12 行)。然而,仅对由二进制掩码 b_n 确定的参数应用更新(第 13 行)。这里,bn 是一个与模型参数大小相同的向量,在属于 \mathcal{I}_n 的索引位置为 1,其余位置为 0。根据向量 u_{n-1} 中绝对值最大的参数比例选择 \mathcal{I}_n(第 1 行)。在每个训练阶段结束时,更新 u_n,以反映所有参数的最新 Adam 更新(第 15 行)。在第一个训练阶段,\mathcal{I}_n 是随机均匀选择的。

在每个训练阶段结束时,服务器发送更新后的参数 w_n 及其索引 \mathcal{I}_n。对于索引,服务器发送一个标识参数位置的 bit-vector。由于该位向量是稀疏的,因此可以对其进行压缩,在本文的实现中使用 gzip 来完成这一操作。总体而言,通过使用基于梯度引导的坐标下降法,在每次模型更新中仅发送 5% 的参数,与更新完整模型相比,下行链路带宽减少了 13.3 倍,且性能损失可以忽略不计。
3.2 减少上行链路带宽
AMS 根据视频中场景变化的程度和速度,动态调整边缘设备的帧采样率。这有助于减少静态或缓慢变化视频的上行链路(边缘设备到服务器)带宽以及服务器负载。
为了获得一个鲁棒的场景变化信号,作者定义了一个指标,即 \phi-score,用于跟踪视频帧标签的变化率。与原始像素相比,标签通常取值于一个更小的空间,因此提供了更鲁棒的信号来衡量变化。服务器使用教师模型的标签计算 \phi-score。考虑一组帧序列 \{I_k\}_{k=0}^n,并用 \{\mathcal{T}(I_k)\}_{k=0}^n 表示教师模型在这组帧上的输出。对于每一帧 I_k,使用相同的损失函数分别计算 \mathcal{T}(I_k) 和 \mathcal{T}(I_{k-1}) 作为预测和真实标签,从而定义 \phi_k。换句话说,将 \phi_k 设置为教师模型在 I_k 上的预测相对于标签 \mathcal{T}(I_{k-1}) 的损失(误差)。因此,\phi_k 值越小,表示 I_k 和 I_{k-1} 的标签越相似,即静止场景倾向于获得较低的分数。
服务器计算最近帧的平均 \phi-score,并定期(例如,每隔 \delta t = 10 秒)更新边缘设备的采样率,以尝试将 \phi-score 维持在一个目标值 \phi_{\text{target}} 附近:
其中 \eta_r 是步长参数,符号 [\cdot]^{r_{\max}}_{r_{\min}} 表示采样率被限制在范围 [r_{\min}, r_{\max}] 内。在本文的实现中,使用 r_{\min} = 0.1 fps和 r_{\max} = 1 fps。
图 3 展示了一个驾驶视频的自适应采样率示例。注意当汽车停在红灯后面时,采样率会降低,而一旦绿灯亮起且汽车开始移动时,采样率又会增加。
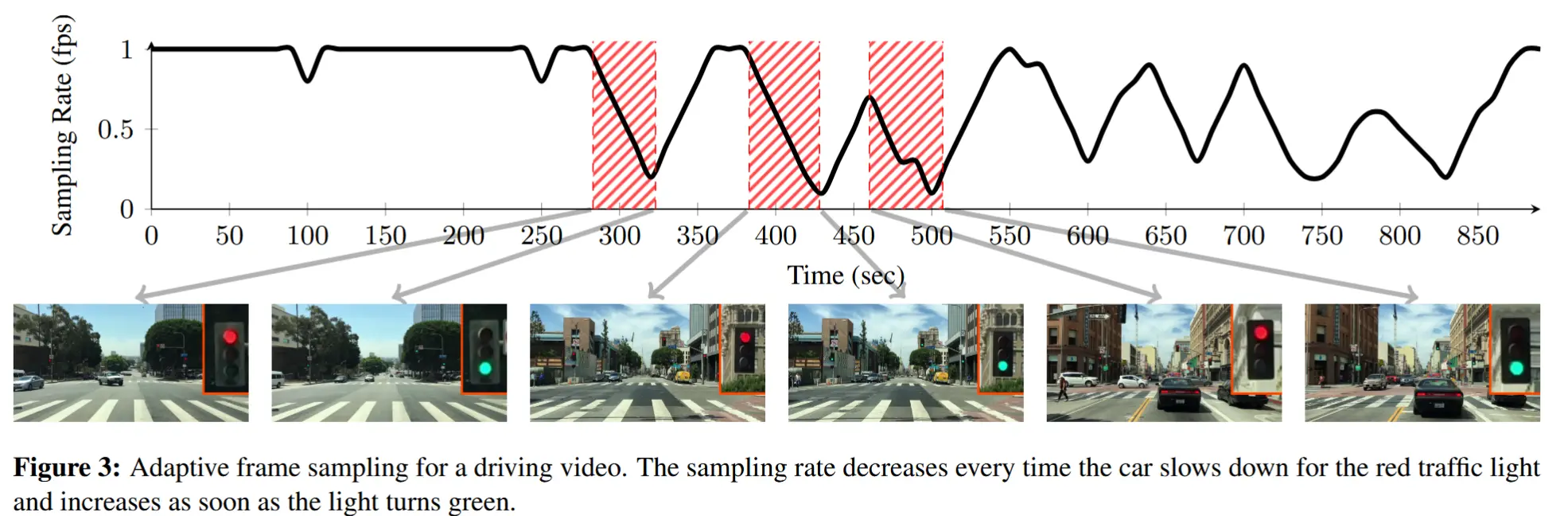
压缩:边缘设备不会立即发送采样的帧。相反,它会缓存与一个模型更新间隔(T_{update},由服务器告知边缘设备)相对应的样本,并在该缓冲区上运行 H.264 视频编码以在传输前进行压缩。边缘设备填充压缩缓冲区并传输新一批样本所需的时间,通过与上一步的训练阶段重叠而对服务器隐藏。性能对训练数据传输延迟并不十分敏感。
4 实验
4.1 实验设置
- 语义分割数据集
- Cityscapes:法兰克福的驾驶序列(1 个视频,时长 46 分钟)
- LVS:包含 28 个视频,总时长为 8 小时。
- A2D2:包含 3 个视频,总时长为 36 分钟。
- Outdoor Scenes :作者收集的视频,涵盖了固定摄像头和以步行、跑步和驾驶速度移动的摄像头等场景。
- 指标
- 平均交并比(mIoU):该指标计算每个类别的交并比(定义为真阳性数除以真阳性、假阴性和假阳性的总和),并对所有类别取平均值。
- AMS 细节
- 为了评估不同方案的准确性,将边缘设备输出与教师模型输出进行比较。
- 对于 Cityscapes、A2D2 和 Outdoor Scenes 数据集,使用在 Cityscapes 上训练的 DeeplabV3 模型作为教师模型。
- 对于 LVS 数据集,使用在 MS-COCO 数据集上训练的 Mask R-CNN 作为教师模型。
- 边缘设备上,使用分辨率为 512×256 的 DeeplabV3(带有 MobileNetV2 [54] 骨干网络),在服务器端使用单个 NVIDIA Tesla V100 GPU。
- 基线方法
- 无定制化(No Customization): 在边缘设备上运行一个预训练模型。
- 一次性定制化(One-Time) :在服务器上对视频的前 60 秒内容微调整个模型,并将其发送到边缘设备。
- 远程+跟踪(Remote+Tracking) :在远程服务器上使用教师模型推断采样帧的标签(每秒一帧),然后将这些标签发送到设备。
- 即时定制化(Just-In-Time) :在服务器上部署了由 [46] 提出的在线蒸馏算法。该方案在最近的采样帧上训练学生模型,直到其训练精度达到阈值。
4.2 主要结果
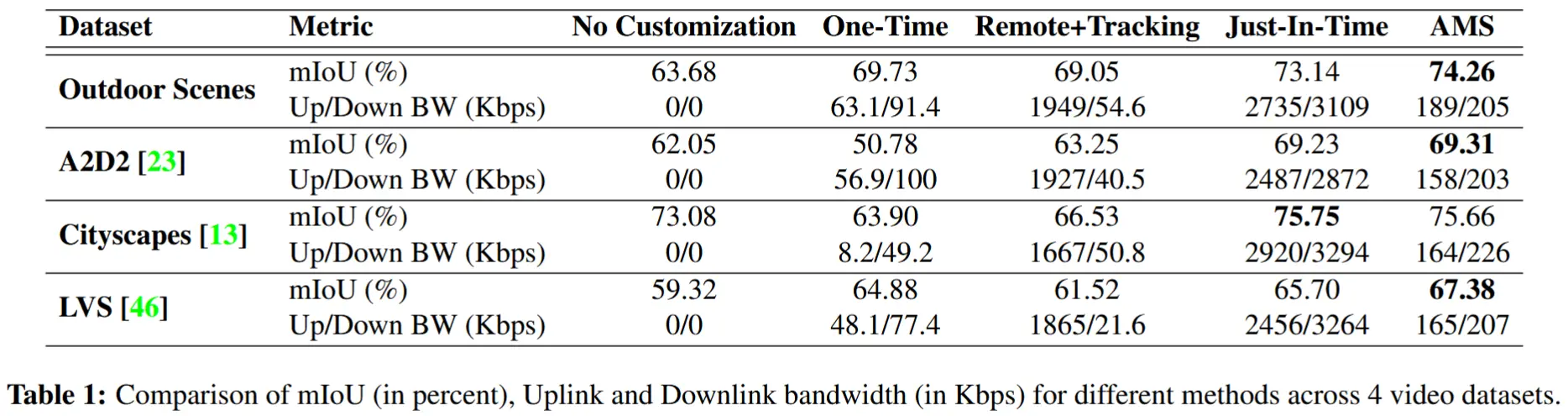
- 表 1 总结了四个数据集的结果
- 报告了每个数据集中视频的平均 mIoU、上行链路和下行链路带宽。
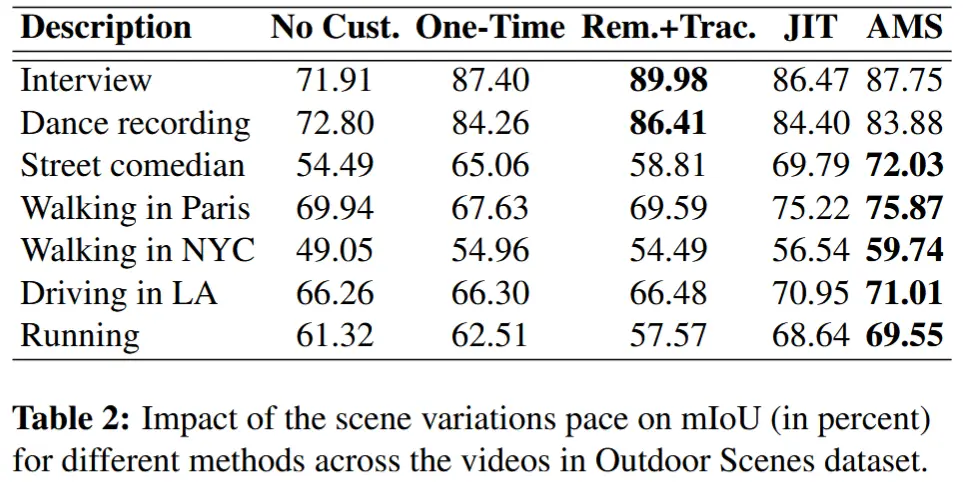
- 表 2 中报告了 Outdoor Scenes 数据集的每视频结果
- 从表1和表2可以得到以下结论:
- 适应边缘模型显著提升了 mIoU
- 一次性定制化(One-Time)有时更好,有时更差
- 远程+跟踪(Remote+Tracking)在静态视频中表现更好
- 即时定制化(Just-In-Time)的 mIoU 最接近 AMS,但带宽需求更高
- 从表1和表2可以得到以下结论:
除此以外还包括以下实验
Impact of AMS and Just-In-Time parameters
Impact of the gradient-guided method
Robustness to scene changes
Multiple edge devices