- 论文 - 《LFTR: Learning-Free Token Reduction for Multimodal Large Language Models》
- 关键词 - 即插即用、高效压缩、多模态大模型MLLM、视频、Token剪枝、时间空间、相似性、视频问答、无需训练
1 引言
- 动机:多模态大语言模型 MLLMs 实际部署常常受到高计算成本和长推理时间的限制。然而,当前的模型压缩技术和token减少方法大多数依赖于对MLLM的微调或重新训练。
- 本文方法 - 无需学习Token减少 (LFTR)
- 一种即插即用的面向 Video-based MLLMs 的方法。
- 方法特点:模型无关性,可以无缝集成到广泛的现有架构中,无需额外训练。
- 方法概述:该方法从时间和空间两个维度出发,针对视觉token中存在的冗余性进行处理。
- 在时间维度上,所提出的方法计算相邻时间帧之间每个图像 patch token的相似性或差异性,并对重要性较低的 token 进行合并。
- 在空间维度上,提出了两种不同的策略:(1) 评估每个空间图像块与当前帧语义内容的相关性;(2) 评估每个token与输入文本提示之间的相关性,从而选择与文本最相关的空间图像块token。
- 大量实验表明,所提方法可实现高达16倍的token减少量,在显著加速MLLM推理的同时,保持甚至提升模型的推理性能。
- 为什么是 MLLMs ?
注意力机制的计算复杂度与输入序列token数呈二次关系,而视觉图像的token数相对文本token数要大很多,因此 MLLM 往往面临更加严重的计算成本和长推理时间的限制。
- 有什么好处?
通过减少 token,不仅有望提升推理效率,而且通过移除无关或冗余的视觉内容,有可能增强模型对视觉输入的理解和推理能力。
2 相关工作
2.1 MLLMs
- LLMs 和 MLLMs 工作:GPT-4、CLIP、Flamingo、LLaVA、MiniGPT-4 等等。
- 这些模型在处理高分辨率输入时通常依赖大量的视觉 token,导致训练和推理阶段的计算开销显著增加。为缓解这一问题的相关策略,包括低比特量化 [15] 和架构压缩 [13]。例如:
- TinyLLaVA [51] 探索了轻量级架构与优化训练范式,在性能上接近更大的模型。
- MoELLaVA [23] 利用专家混合框架(MoE)来提升稀疏性和效率。
2.2 面向 LLMs 的 Token 减少方法
- Token 减少已成为提升基于 Transformer 架构计算效率的重要技术,尤其是在视觉和多模态任务中。
- 相关工作
- 早期的方法
- 主要集中在 token 剪枝 [22, 34, 44] 和 token 合并 [6, 32]。
- 近年来的方法
- DiffRate [10] 和 PPT [41],则在统一框架下结合剪枝与合并策略,在推理过程中自适应地减少 token 冗余性。
- 最新的方法
- CrossGET [36] 和 MADTP [7] 利用对齐 token 来保留信息量较大的视觉表示。
- LLaVA-PruMerge [35] 利用空间冗余性,通过衡量类别 token 和 patch token 之间的相似性,使用聚类方法识别可压缩区域。
- Qwen-VL [40] 使用采样器将视觉 token 序列下采样到固定长度。
- FastV [9] 在解码器层中采用“提前丢弃”策略,以去除无信息量的 token,提供了一种轻量但有效的替代方案。
- 早期的方法
- 局限:许多方法需要进行架构修改、专门的融合策略或微调,这可能限制其在通用场景或无需训练的环境中的适用性。
3 方法
本文提出的一种针对视觉模态的时间和空间维度的token压缩方法,整体架构如图1所示。即插即用、无缝集成、无需重新训练。
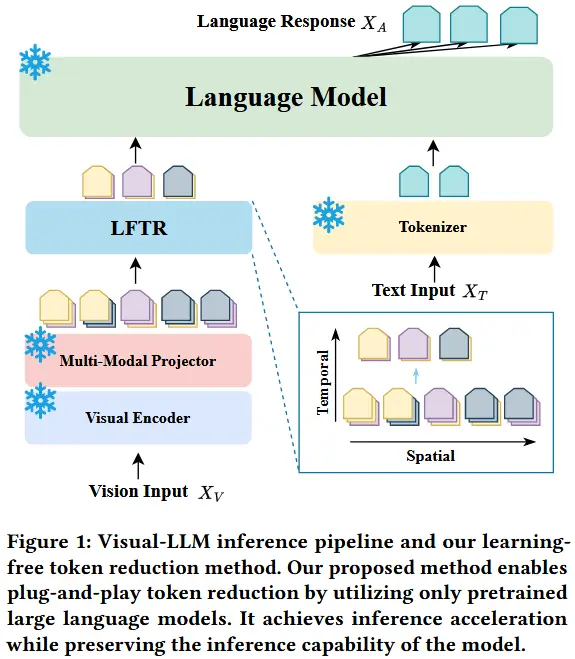
3.1 时间维度 Token 减少
Differential-Based Significance Weights
动机:对于视频,相邻帧之间通常存在显著的冗余性,因为静态物体和背景在时间上保持一致。
思路:计算相邻帧之间的差异,以评估每个空间 patch token 在时间序列中的重要性,并合并重要性较低的token。
具体做法:
如图3所示,不同时间帧 i 中同一空间位置 p 的token表示为 Z_{V_{i,p}} (其中 i = 1, \dots, N_t , N_t 表示采样的视频帧数量)。通过计算相邻帧之间的差异来量化其重要性:
其中, d 是嵌入维度。通过设置一个token减少率 r_m ,并选择重要性较低的token,将这些不重要的token与其前一时间步对应的token合并,从而在保留关键信息的同时减少token数量。
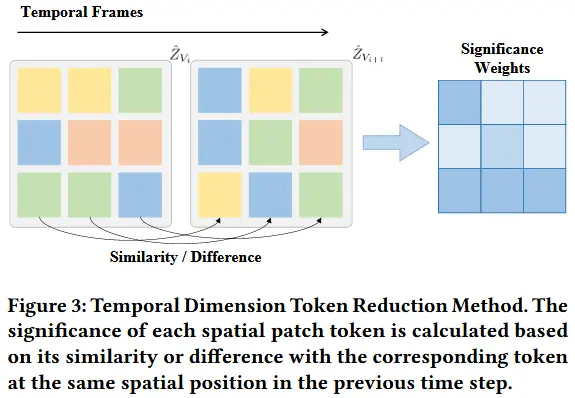
Similarity-Based Significance Weights
思路:计算相邻时间帧中空间 patch token 之间的相似性,以评估其重要性,并基于此进行token合并。
类似地,重要性权重可以通过以下方式计算:
其中,\hat{Z}_{V_{i,p}} = \frac{Z_{V_{i,p}}}{\|Z_{V_{i,p}}\|} 是归一化的token。token合并策略与之前的方法保持一致。
通过这种方法,在空间维度上的并行合并操作提高了执行效率。结果是,视觉输入的时间帧总数从 N_t 减少到 (1 - r_m) \times N_t ,遵循时间维度的减少过程。这种方法能够在最小化信息损失的情况下实现高token减少率,从而生成更简洁的视觉表示,促进语言模型的高效推理和推理能力。
3.2 空间维度 Token 减少
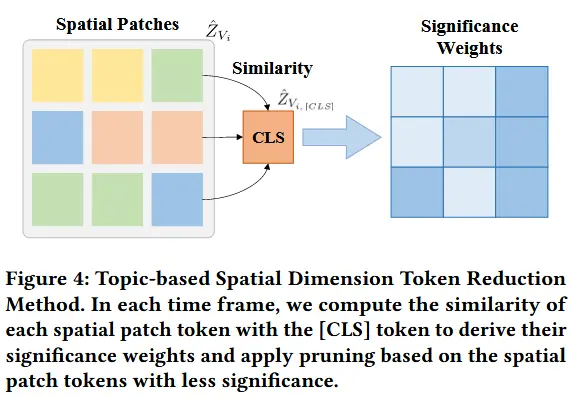
Topic-based Significance Weights
动机:在输入的每一帧视频中,只有部分空间图像块包含关键的或与主题相关的信息。通常,只需关注图像中的这些关键区域,就能实现对内容的有效理解。
基本思路:利用视觉编码器(例如 CLIP-ViT)中的 [CLS] token 来识别每帧中包含主题相关信息的区域,并据此剪枝不相关的空间图像块。
如图4所示,通过计算每个token与 [CLS] token 的余弦相似性来计算其相关权重:
给定一个空间token减少率 r_p ,我们选择相关性最低的 r_p \times N_s 个空间token,并丢弃这些不相关的token。使用这种方法,每帧将保留 (1 - r_p) \times N_s 个token。这种减少过程也是并行进行的。
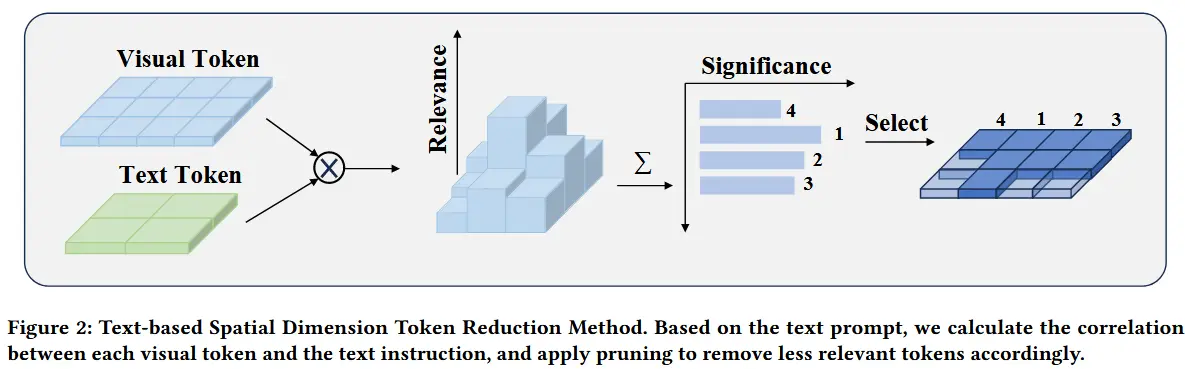
Text-based Significance Weights
动机:对于涉及文本提示的视觉任务,每个空间patch与文本提示的相关性可以作为空间token减少的重要指标。
如图2所示,对于投影后的视觉token Z_V 和嵌入的文本提示 Z_T,可以通过将视觉token与文本提示相乘来计算相关权重:
其中,L_P 是输入文本提示的token长度。基于相关权重,选择与文本提示相关性更强的视觉token。
其中, \text{top}_k = r_p \times N_s 由给定的空间token减少率决定,每帧保留 (1 - r_p) \times N_s 个token。
注意,空间和时间维度的token减少策略都是正交的,可以联合应用。
4 实验
4.1 在 Video-LLM 上的零样本评估
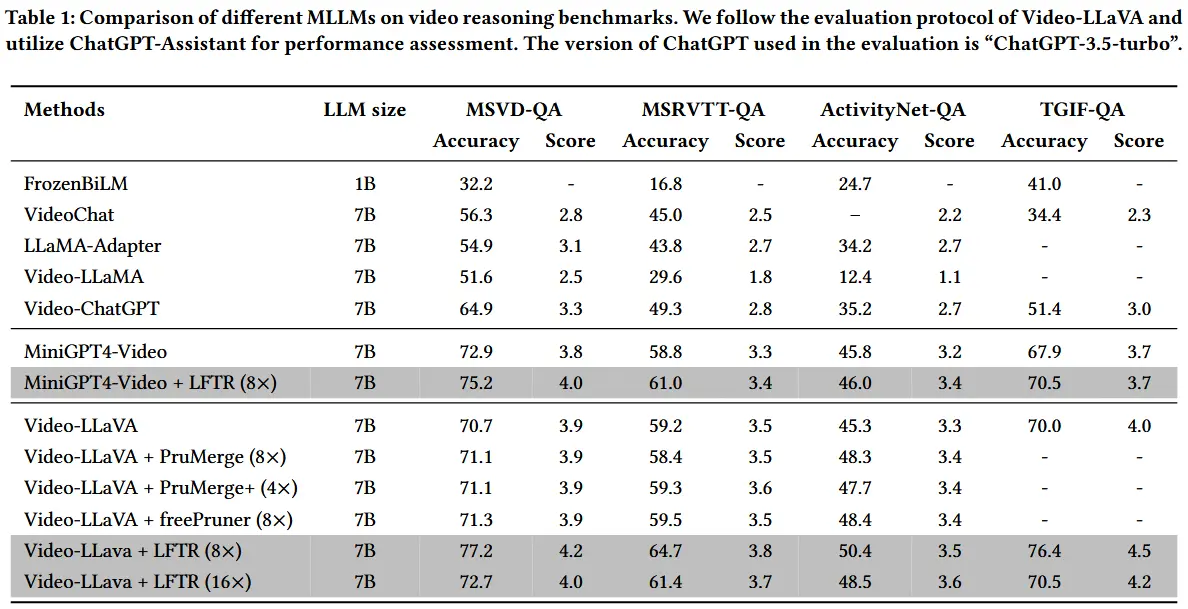
- 表1
- 作者将 LFTR 应用于 Video-LLaVA 和 MiniGPT4-Video,并且没有进行任何训练和微调,达到了 8× 和 16× 的 token 减少率。
- 在四个主流视频问答基准上进行零样本推理能力评估。
4.2 效率分析
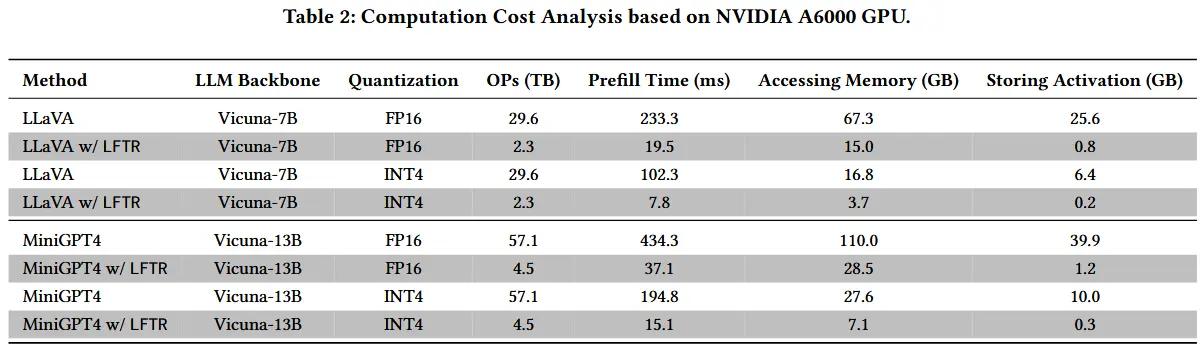
- 表2
- 采用了基于 roofline 模型的 LLM Viewer 框架,对 LFTR 对 LLM 处理效率的理论影响进行了分析。
- 理论场景设计:使用 CLIP-ViT、224 × 224 的图像、从视频输入中采样 8 帧、生成总共 2056 个视觉 token、文本提示假设包含 50 个 token、FP16 和 INT4 量化、启用了 Flash Attention。
- 理论计算开销如下表。
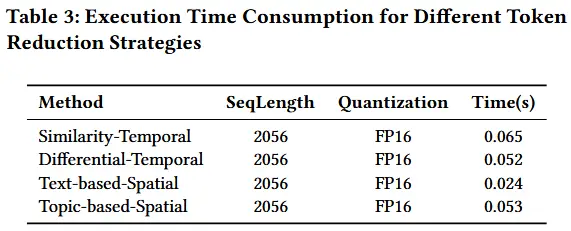
- 表3
- 分析了 LFTR token 减少过程引入的运行时开销,比较了在时间和空间维度上四种不同的 token 减少策略。
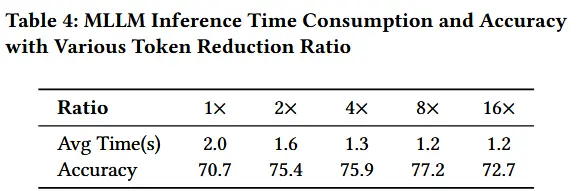
- 表4
- 在相同的实验设置下报告了 13,000 个 Video-QA 样本 的平均推理时间。评估了不同 token 减少比例及其对推理时间的影响。
4.3 消融
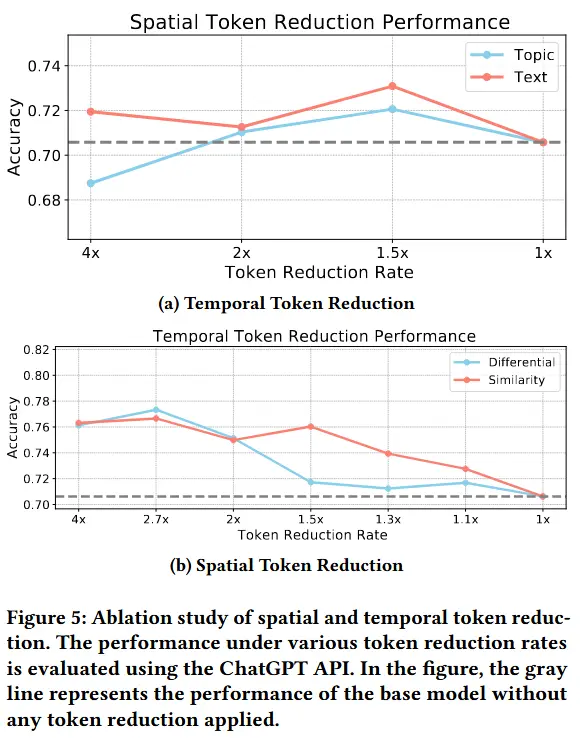
- 图5
- 验证本文提出的时间维度和空间维度 token 减少策略在单独应用时、并在不同 token 减少率下的性能表现。
- 在 MSVD-VQA 数据集 上进行了实验,通过 ChatGPT-3.5-turbo 进行评估准确率。