- 论文 - 《Post-pre-training for Modality Alignment in Vision-Language Foundation Models》
- 代码 - Github
- 关键词 - CLIP-Refine、模态对齐、模态差距、自蒸馏
摘要
- 研究问题:
- CLIP的多模态特征空间仍然存在“模态差距”(modality gap),即图像和文本特征簇之间的差距,这限制了下游任务的表现。
- 已有研究尝试通过修改预训练或微调来解决模态差距问题,往往面临在大规模数据集上训练成本高昂,或导致零样本性能下降的问题。
- 本文工作
- 提出了 CLIP-Refine,这是一种介于预训练和微调之间的、用于 CLIP 模型的“后预训练”方法。CLIP-Refine 的目标是在小型图像-文本数据集上仅用 1 个训练周期(epoch)就能对齐特征空间,同时不损害零样本性能。
- 引入了两种技术:
- 随机特征对齐(RaFA) 通过最小化与从先验分布中采样的参考向量之间的距离,使图像和文本特征遵循一个共享的先验分布。
- 混合对比-蒸馏(HyCD) 则通过结合真实图像-文本配对标记和预训练 CLIP 模型输出生成的混合软标签来更新模型。这种方法有助于在保持原有知识的同时学习新的特征对齐能力。
1 引言
- 模态差距 Modality Gap
- 定义:CLIP 模型倾向于将图像和文本分别编码为各自模态的不同簇。
- 后果:CLIP 在精确地将图像和文本进行映射方面仍存在困难。例如:Liang 等人表明,模态差距会显著影响下游任务的表现,尤其是在细粒度分类任务中;Ray 等人则证明了 CLIP 模型常常无法从相应的描述中准确检索出图像中的局部物体和属性。
- CLIP模态差距现有研究
- 在预训练方面,一种方法是结合对比学习目标和辅助损失(如基于数据增强的自监督损失)进行多任务学习。另一种则是通过修改图像编码器和文本编码器的结构,使它们共享权重或特征图,从而显式地减少模态差距。
- 在微调方面,通过对目标任务上的可训练视觉/文本 token 进行提示调优(prompt tuning),可以显著提升目标任务的表现。这种方法通过在特征空间中匹配图像和文本来减少模态差距。最近,Yang 等人提出了跨模态共享适配器,通过引入少量额外参数来共享跨模态信息,并在目标任务上进行微调以解决问题。
- 局限性:预训练方法需要大规模数据集,成本高不实际;微调方法往往专注于特定的目标任务,导致零样本迁移性能下降。
- post-pre-train
- 目标:仅使用有限的计算资源和数据集,来缓解模态差距,并提升现成的预训练 CLIP 模型的零样本迁移性能。
- 挑战:简单的对齐方法,如直接最小化图像和文本特征之间的差距,会破坏特征空间在超球面上的“uniformity”,而uniformity是对比学习表示的一个重要性质;此外,在后预训练阶段使用对比损失函数会导致灾难性遗忘,即由于小批量(mini-batch)大小受限,预训练模型中的通用知识被过度拟合所覆盖。
- 本文方法CLIP-Refine
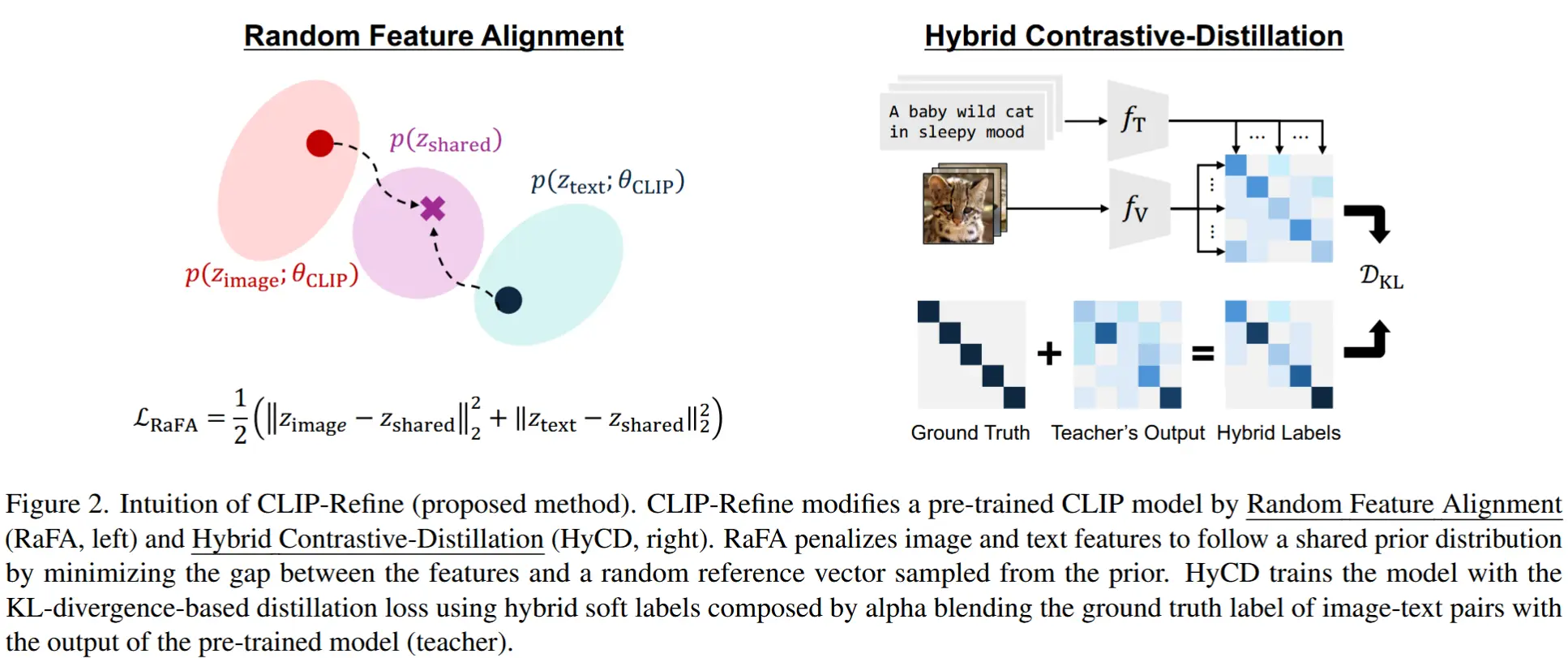
- 思路:将图像和文本特征分布优化为遵循一个共享的先验分布(如标准高斯分布)。
- 随机特征对齐(RaFA)
- 通过最小化图像/文本特征向量与从该先验分布中随机采样的参考向量之间的距离来完成对齐。在 RaFA 中,这些参考向量是图像-文本配对输入所共享的,因此 RaFA 显式地惩罚图像和文本特征,使其遵循相同的分布。
- 优点:通过这种方式匹配图像和文本特征分布,可以避免特征过度集中,同时保持样本间的均匀性,从而在多模态对齐和特征空间均匀性之间取得良好平衡。
- 混合对比-蒸馏(HyCD)
- 采用一种改进的自蒸馏损失,并结合图像-文本配对的监督信号。具体来说,应用知识蒸馏方法,其中教师模型为原始的预训练模型,目标是最小化教师模型与学生模型(即后预训练模型)输出之间的 KL 散度。此外,我们还通过融合教师模型的相似度矩阵与单位矩阵(代表图像-文本配对的真实标签),鼓励模型在保留已有知识的同时学习新的信息。
- 优点:避免灾难性遗忘。
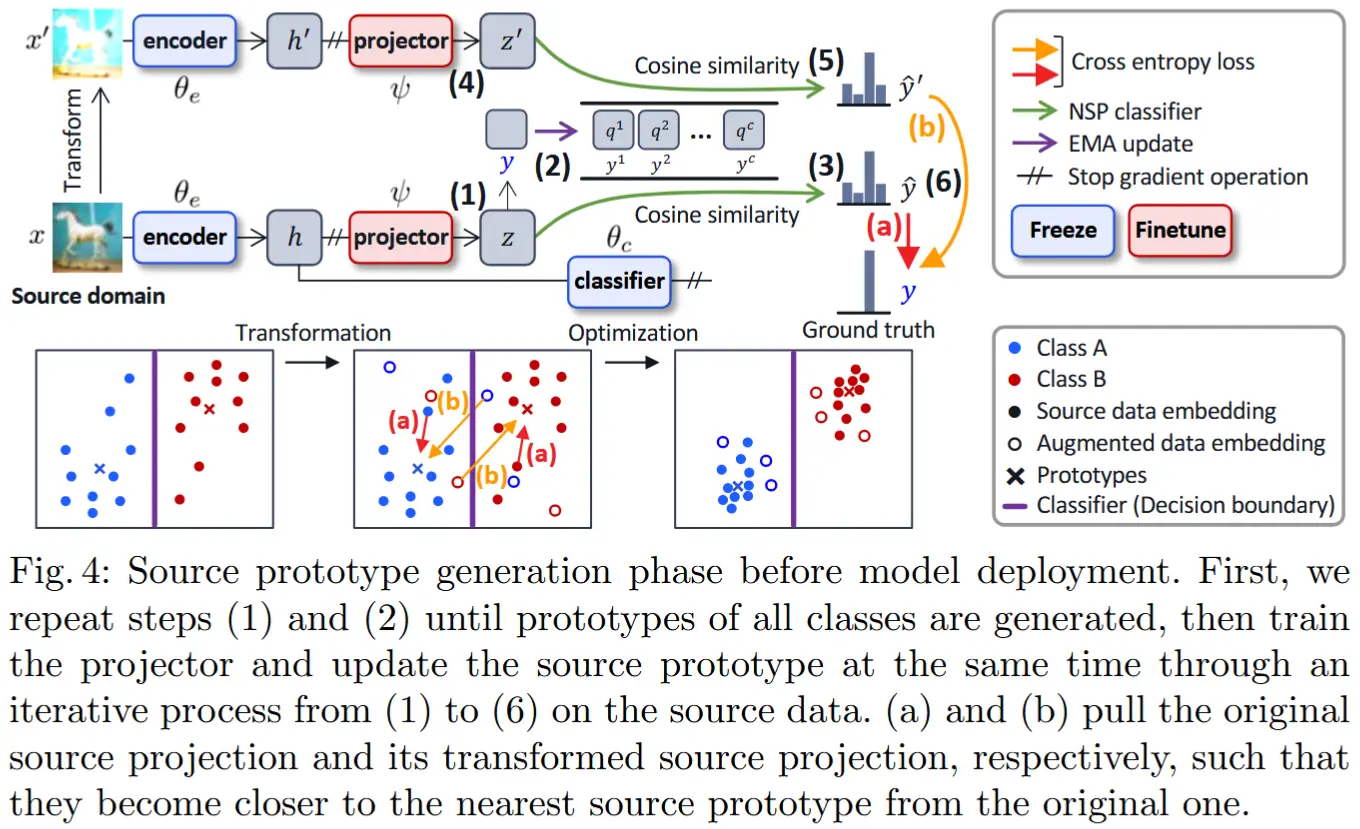
2 方法
算法1展示了 CLIP-Refine 的整体流程。

2.1 问题设定:后预训练
在后预训练设定下,可以访问由 CLIP 预训练的视觉编码器 f_V: \mathcal{X} \to \mathbb{R}^d 和文本编码器 f_T: \mathcal{T} \to \mathbb{R}^d ,其中参数为 \theta^{\text{CLIP}} = \{\theta_V^{\text{CLIP}}, \theta_T^{\text{CLIP}}\} ,\mathcal{X} 和 \mathcal{T} 分别表示图像空间和文本空间。在一个后预训练的图像-文本配对数据集 \mathcal{D} = \{(x_i, t_i)\}_{i=1}^N 上优化 f_V 的参数 \theta_V 和 f_T 的参数 \theta_T;我们假设 \mathcal{D} 比预训练数据集小得多,并且包含通用领域的图像和文本描述。
2.2 目标函数
在 CLIP-Refine 中,我们通过以下目标函数优化 \theta_V 和 \theta_T:
其中 \mathcal{L}_{\text{RaFA}} 是随机特征对齐损失,\mathcal{L}_{\text{HyCD}} 是混合对比蒸馏损失。
2.3 随机特征对齐
(直接最小化差距会导致泛化性能下降)
模态对齐最直接的方法就是最小化两种模态之间的特征差距。设 z_{\text{img}}^i = f_V(x^i; \theta_V) 和 z_{\text{txt}}^i = f_T(t^i; \theta_T) 是图像-文本配对 (x^i, t^i) 的归一化特征向量。一种用于最小化模态差距的简单损失可以定义为 L_2 距离形式:
然而,最小化该损失会降低泛化性能。
原因:这可以用“对齐”与“均匀性”之间的平衡来解释 ,这是对比表示学习中可迁移性的理想属性。“对齐”定义为特征空间中正样本(即图像-文本对)之间的差距,“均匀性”定义为超球面上所有特征之间的等间距分布。也就是说,最小化公式 (2) 可以增强正样本对的对齐,但通过改变特征分布破坏了超球面上的均匀性。事实上,[57] 中已经证明,在后预训练中仅使用对齐损失会因破坏均匀性而导致验证性能下降。
(提出解决办法 - 随机参考向量)
为了应对这一挑战,作者引入了匹配特征分布而非直接匹配成对特征的想法。换句话说,作者将预训练 CLIP 模型的多模态特征调整为遵循共享的先验分布 p(z)(例如标准高斯分布 \mathcal{N}(0, I))。受单模态微调中的随机特征正则化启发,将这一想法表述为最小化图像/文本特征向量 (z_{\text{img}}^i, z_{\text{txt}}^i) 与从共享先验 p(z) 中采样的随机参考向量 z_{\text{ref}}^i 之间的距离:
通过这一损失函数,可以期望:(i) 模态差距间接地通过共享的随机参考向量 z_{\text{ref}}^i 得到最小化;(ii) 特征向量逐渐遵循共享的先验分布 p(z) [63];(iii) 随机性有助于防止模型过拟合到数据集 \mathcal{D} [71],并恢复模型的容量。此外,作者发现 \mathcal{L}_{\text{RaFA}} 能够改善基线的均匀性(见表3),这意味着学习到的表示能够很好地迁移到下游任务。在整个论文中,默认使用标准高斯分布 \mathcal{N}(0, I) 作为 p(z)。(作者在第 4.4.1 节讨论了先验选择的影响)
2.4 混合对比蒸馏
后预训练的另一个重要目标是保留预训练 CLIP 模型中的已有知识。为此,本文基本策略是使用知识蒸馏损失对后预训练模型进行惩罚,其中冻结的预训练 CLIP 模型充当教师模型。根据 CLIP-KD 的公式 [64],定义基于 KL 散度的小批量知识蒸馏损失为:
其中 \tau 是温度参数,(z_{\text{img}}^{i,\text{P}}, z_{\text{txt}}^{j,\text{P}}) = (f_V(x^i; \theta_V^{\text{CLIP}}), f_T(t^j; \theta_T^{\text{CLIP}})) 是由预训练图像/文本编码器生成的特征向量,\mathcal{L}_{\text{T}\to\text{I}}^{\text{KD}} 通过交换图像特征和文本特征在公式 (6) 和 (7) 中的顺序来定义。
尽管最小化公式 (4) 可以保留已有知识,但作者发现它会强烈地将模型参数与预训练参数绑定在一起,从而干扰 RaFA。
为了协调 RaFA 和保留已有知识的目标,作者提出了一种技术,即将图像-文本配对的真实标签与教师输出信号混合。具体来说,通过指示函数 \mathbb{I}_{i=j} 的 \alpha-融合修改公式 (7),该函数在 i=j 时返回 1,否则返回 0,同时结合教师输出信号:
其中 \alpha 是一个超参数,用于平衡获取新知识和保留已有知识;默认情况下设置 \alpha=0.5,并在附录中讨论 \alpha 的影响。通过这一修改,后预训练模型可以通过参考教师输出中包含的相关知识,进一步增强跨模态对齐(即学习正确的图像-文本对,i=j)。通过使用 \hat{q}_{i,j}^{\text{I}\to\text{T}} 和 \hat{q}_{i,j}^{\text{T}\to\text{I}},计算混合对比蒸馏(HyCD)损失函数如下:
虽然 \mathcal{L}_{\text{HyCD}} 单独可以提升预训练 CLIP 模型的泛化性能,但将其与 \mathcal{L}_{\text{RaFA}} 结合使用,通过最小化模态差距而不丢失已有知识,能够实现更大的改进。
3 实验
具体实验就不展示了,展示一下关于特征空间和先验分布的实验。
- 模态差距缓解
- 作为定量评估,作者在表3中总结了模态差距、对齐性(alignment)和均匀性(uniformity)的得分。(计算方式见论文)
- HyCD + \mathcal{L}_{\text{align}} 方法在模态差距和对齐性指标上取得了最佳表现。然而,它显著降低了均匀性得分,这表明直接最小化 \mathcal{L}_{\text{align}} 会破坏由 CLIP 预训练构建的良好特征空间结构。
- 相比之下,CLIP-Refine 方法在所有三项指标上都实现了持续提升。这表明,在改善预训练 CLIP 模型泛化性能时,不仅要缩小图像与文本特征之间的差距,也要保持特征空间的均匀性。
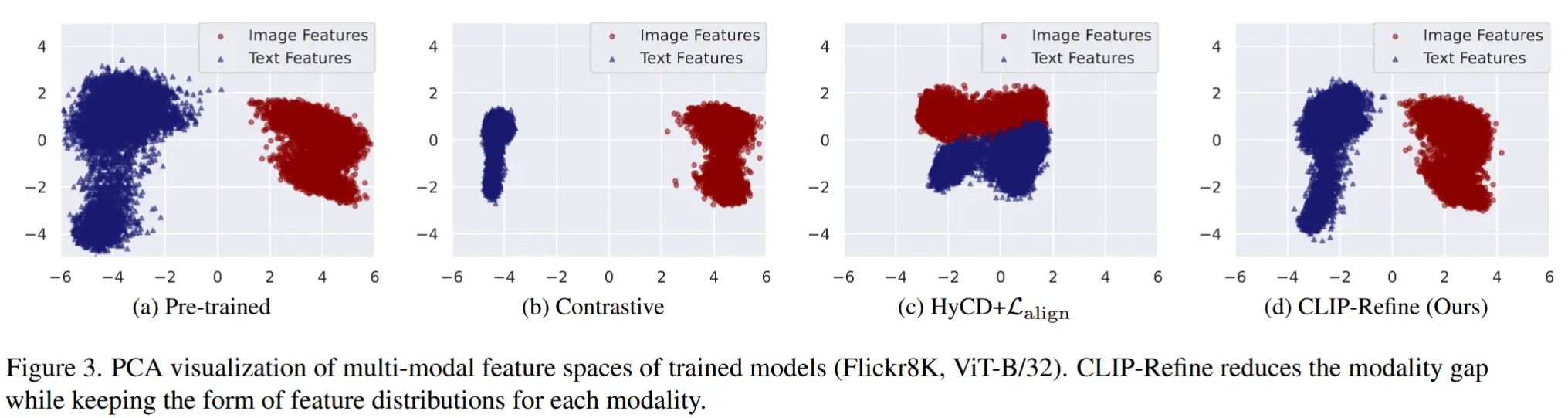
- 作为定性评估,图3展示了不同方法在后预训练阶段得到的特征的 PCA 可视化结果。
- 对比学习模型导致了较大的模态差距;
- HyCD + \mathcal{L}_{\text{align}} 成功将图像和文本特征聚集到同一区域,但扭曲了每种模态自身的特征分布;
- 而 CLIP-Refine 在保持预训练特征结构的同时,确实减少了模态差距。
- 作为定量评估,作者在表3中总结了模态差距、对齐性(alignment)和均匀性(uniformity)的得分。(计算方式见论文)
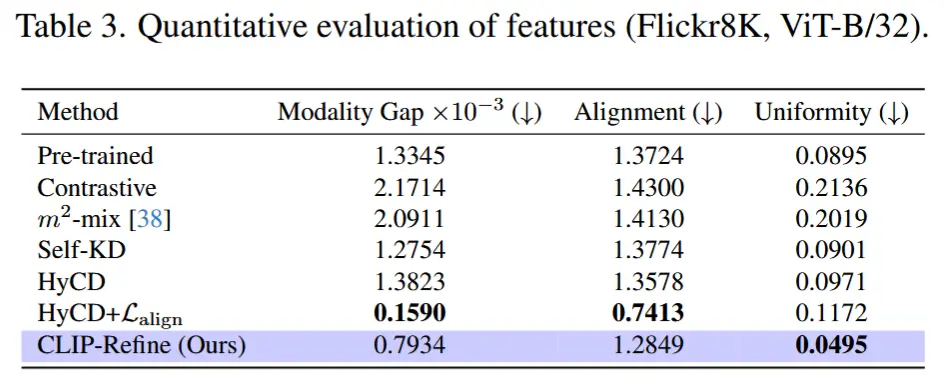
- 先验分布
- 作者尝试了以下几种先验分布:
- 标准高斯分布 \mathcal{N}(0, I) ;
- 均匀分布 U(0, 1) ;
- 使用预训练文本特征统计的高斯分布 \mathcal{N}(\mu_{\text{txt}}^{\text{P}}, (\sigma_{\text{txt}}^{\text{P}})^2) ;
- 使用预训练图像特征统计的高斯分布 \mathcal{N}(\mu_{\text{img}}^{\text{P}}, (\sigma_{\text{img}}^{\text{P}})^2) ;
- 使用所有图像和文本特征统计的高斯分布 \mathcal{N}(\mu_{\text{all}}^{\text{P}}, (\sigma_{\text{all}}^{\text{P}})^2) ,
- \mathcal{N}(0, \beta I) 的变体,通过调整 \beta \in \{0, 0.01, 0.1, 10, 100\} 。当 \beta = 0 时,表示 RaFA 不包含随机性,即 \frac{1}{2} (\|z_{\text{img}}^i\|^2 + \|z_{\text{txt}}^i\|^2) 。
- 表格 4 显示了在不同 p(z) 下的零样本分类性能、对齐性和均匀性得分。使用均匀分布 U(0, 1) 并未显著提升零样本性能和均匀性得分。这可能是因为来自 U(0, 1) 的随机参考向量并不一定集中在超球面上,与 \mathcal{N}(0, I) 相比,可能导致 \mathcal{L}_{\text{RaFA}} 引发的均匀性崩溃。有趣的是,在带有预训练统计的高斯分布中,使用文本特征的先验(即 \mathcal{N}(\mu_{\text{txt}}^{\text{P}}, (\sigma_{\text{txt}}^{\text{P}})^2) )显著提升了零样本性能。
- 作者尝试了以下几种先验分布: