- 论文 - 《Flashback: Memory-Driven Zero-shot, Real-time Video Anomaly Detection》
- 关键词 - 实时高效视频异常检测、基于记忆库、零样本、可解释性、视觉语言大模型VLM、无需训练
1 引言
-
VAD 有两个根本性的障碍阻碍了其在现实世界中的应用:领域依赖性和实时性要求。
- 为此,我们提出了 Flashback,一种零样本且实时的视频异常检测范式。
-
启发:受人类通过过往经验迅速判断当前场景是否异常的认知机制启发,Flashback 分为两个阶段:回忆(Recall) 和 响应(Respond)。
-
动机
- 现实世界中的 VAD 部署面临两个根本性的障碍:
- 领域依赖性:几乎所有的 VAD 方法都需要为每个新环境收集和标注特定领域的视频数据,并重新训练模型。
- 实时性限制:由于突发事件可能随时发生,因此每个视频片段的处理必须在其下一个片段到达之前完成。
- 现实世界中的 VAD 部署面临两个根本性的障碍:
-
相关工作
- 解决领域依赖性的研究:零样本 VAD,通常利用预训练的 VLM 和 LLM,例如描述生成和打分 [16,60],提示驱动方法 [1, 57, 58]。
- 解决实时性限制的研究:实时 VAD,例如端到端的弱监督模型 [23] 加快了推理速度、基于密度估计的检测器 [32] 能够达到每段约 200 毫秒的延迟。
- 局限:目前尚无一种方法能同时具备这两种优势。
-
启发:受人类通过过往经验迅速判断当前场景是否异常的认知机制启发。
-
本文工作 - Flashback 范式
- 两个阶段:
- 离线伪场景记忆构建: Flashback 利用一个冻结的 LLM 来生成涵盖广泛正常和异常场景的描述文本,而无需任何视频输入;随后通过视频-文本跨模态编码器将每条描述转换为嵌入向量,并将这些描述及其对应的嵌入一同存储在记忆库中。
- 在线描述检索推理: 输入视频被划分为固定长度的片段,每个片段的嵌入表示会通过相似度搜索与记忆库进行匹配,从而生成片段级别的异常得分;这些得分进一步在片段之间聚合,并经过平滑处理,得到帧级别的异常预测结果。
- 关键挑战:
- 表示偏差问题:即使在处理正常内容时,编码器也会系统性地倾向于偏向异常描述的表示。因此,作者引入了“排斥提示机制(Repulsive Prompting)”——即对正常与异常描述使用不同的提示模板,使得它们的嵌入表示在空间中保持良好分离。
- 残余异常偏好问题:在推理过程中,仍然可能存在对异常描述的轻微偏向。因此,作者采用了“比例异常惩罚(Scaled Anomaly Penalization)”,通过降低异常描述嵌入向量的幅值来加以校正。
- 优点:(1)通过将 LLM 完全从在线推理循环中解耦,Flashback 不需要额外的数据收集或微调。(2)Flashback 实现了真正的实时 VAD,同时还能通过检索到的描述提供人类可读的解释。
- 两个阶段:
2 Flashback 范式

2.1 问题陈述:Zero-shot VAD
设一个视频为帧序列 V = (I_t)_{t=1}^T 。VAD 的任务是为每一帧 I_t 分配一个异常分数 s_t \in [0, 1] 。在零样本VAD 中,检测器在训练过程中不接收目标域的视频或任何类型的标签,但仍需对未见过的数据输出帧级分数。形式上,训练集为空(\mathcal{V}_{\text{train}} = \varnothing)。
作者将 VAD 视为一种基于 离线伪场景记忆库 的在线检索任务。给定一个视频片段 V_s ,一个冻结的视频-文本编码器生成特征向量 \mathbf{v}_s ,并将其与预编码的描述向量 \mathbf{t}_j 进行比较。匹配度最高的 K 个描述定义了软权重 w_{s,k} ,片段得分 A_s 是这些匹配描述的加权平均值 A_s = \sum_k w_{s,k} y_{j_k} ,其中匹配的描述本身也充当解释。这一过程只需一次编码和少量点积运算,因此推理可以在实时完成。将长视频分割为重叠片段,并对得分进行平滑处理即可得到帧级预测 p_t。
2.2 离线回忆(数据准备)
伪描述记忆
这一步构建了在推理时查询的离线记忆库。使用 LLM 并提供两个提示。
- 上下文提示 P_C :模型被指示为正常和异常事件生成简短具有信息量的描述。
- 格式提示 P_F:为了保持输出可解析性,提供了一个包含两个字段的模式:"normal" 和 "anomalous",每个字段分别包含一个 "action category" 和一个自由形式的 "description"。
LLM 返回:
- 有序的描述列表 \mathcal{C}_N = (c_1^N, \dots, c_{N_N}^N) (正常场景)和 \mathcal{C}_A = (c_1^A, \dots, c_{N_A}^A) (异常场景)
- 附带其类别列表 \mathcal{K}_N = (\kappa_1^N, \dots, \kappa_{N_N}^N) 和 \mathcal{K}_A = (\kappa_1^A, \dots, \kappa_{N_A}^A) 。
- 将它们拼接形成:
其中 Y 存储二进制异常标志。所有描述仅需通过文本分支 f_{\text{text}} 编码一次并缓存,因此在推理过程中无需调用 LLM。
排斥提示
动机:描述相似场景的伪描述即使一个是正常的而另一个是异常的,也往往在嵌入空间中彼此靠近。
解决办法:排斥提示(repulsive prompting),将两组描述分开,同时不改变其核心含义。
具体而言:
(1)在每条描述中插入一个词。对于常规事件,该词为 "Normal";对于异常事件,该词为 "Anomalous"。
(2)每条描述会经过一个模板处理。将正常情况下的组合关键词加包装器称为 \mathcal{T}_N ,异常情况下的称为 \mathcal{T}_A ,两者不同。包装器可以在保留主句结构的同时嵌入动作类别。对模板化的描述进行编码得到两个描述特征集 \mathcal{Z}_N = f_{\text{text}}(\mathcal{T}_N(\mathcal{C}_N, \mathcal{K}_N)) 和 \mathcal{Z}_A = f_{\text{text}}(\mathcal{T}_A(\mathcal{C}_A, \mathcal{K}_A)) 。
\mathcal{Z}_N 和 \mathcal{Z}_A 的质心之间的夹角大于原始描述的夹角,值得注意的是,整个步骤仅增加了少量标记,并且不需要训练。
2.3 在线响应(推理)
比例异常惩罚(Scaled Anomaly Penalization)
动机:作者发现,异常事件的描述向量与视频特征之间的夹角通常比正常事件的描述向量更小。换句话说,模型对异常描述存在固有偏好。
解决方法:抑制这种偏好,在检索前重新缩放它们的嵌入:对于每个 \mathbf{t}_j \in \mathcal{Z}_A ,设置 \mathbf{t}_j = \alpha \cdot \mathbf{t}_j ,其中 \alpha \in (0, 1) 。因子 \alpha 降低了异常描述的点积幅度,从而减少了不必要的匹配,同时仅增加了少量计算开销。
异常得分计算
异常得分可以分为以下两大步骤:
- 伪描述检索
- 片段分割:将测试视频分割为长度为 T_{\text{segment}} 秒且重叠时间为 T_{\text{overlap}} < T_{\text{segment}} 的片段 (V_s) 。
- 特征提取:对于第 s 个片段 V_s ,通过 \mathbf{v}_s = f_{\text{video}}(V_s) 获取其特征。
- 检索并转换为权重:对于每个描述嵌入 \mathbf{t}_j \in \mathcal{Z} ,计算点积 \sigma_{s,j} = \mathbf{v}_s^\top \mathbf{t}_j 。保留点积最大的 K 个索引集合 \mathcal{J}_s ,并通过应用 softmax 转换为权重 (w_{s,k})_{k=1}^K 。
- 加权平均:获得片段异常得分 A_s ,即检索到的异常标志 y_s^* 的加权平均值。检索到的描述 \mathbf{c}_s^* 作为片段的即时文本解释返回。
- 帧级得分细化
- 求索引集合:设 \mathcal{S}_t 为覆盖第 t 帧的所有片段的索引集合。
- 得分优化:对这些片段的得分取平均值 p_t = \frac{1}{|\mathcal{S}_t|} \sum_{s \in \mathcal{S}_t} A_s ,并使用一维高斯函数对结果序列进行卷积。平滑后的曲线 (p_t) 即为我们的最终帧级预测。
2.4 计算复杂度
本节在实时设置中,将基于检索驱动的在线方法与现有的 VLM 管道的方法每片段计算成本进行了比较。
分析过程省略,结论是两种方法的成本可以表示为: C_{\text{VLM}} = C_{\text{video}} + C_{\text{LLM}} , C_{\text{Flashback}} = C_{\text{video}} + C_{\text{retrieve}} 。而它们之间的关系: C_{\text{LLM}} \gg C_{\text{video}} \gg C_{\text{retrieve}} 。
3 实验结果
3.1 实验设置
- 数据集:UCF-Crime、XD-Violence
- 评估指标:帧级 ROC 曲线下面积(AUC)、帧级平均精度(AP)
- 对比方法
- 弱监督方法:[9, 21, 26, 39, 44, 52–55, 58, 59, 61];
- 单类方法:[19, 30, 48];
- 无监督方法:[42, 43, 46, 47, 59];
- 零样本方法:[60]。
- 实现细节
- 记忆库用gpt-4o生成
- 跨模态编码器采用 ImageBind 和 PerceptionEncoder
- 所有实验均在一块 RTX 3090 GPU 上运行
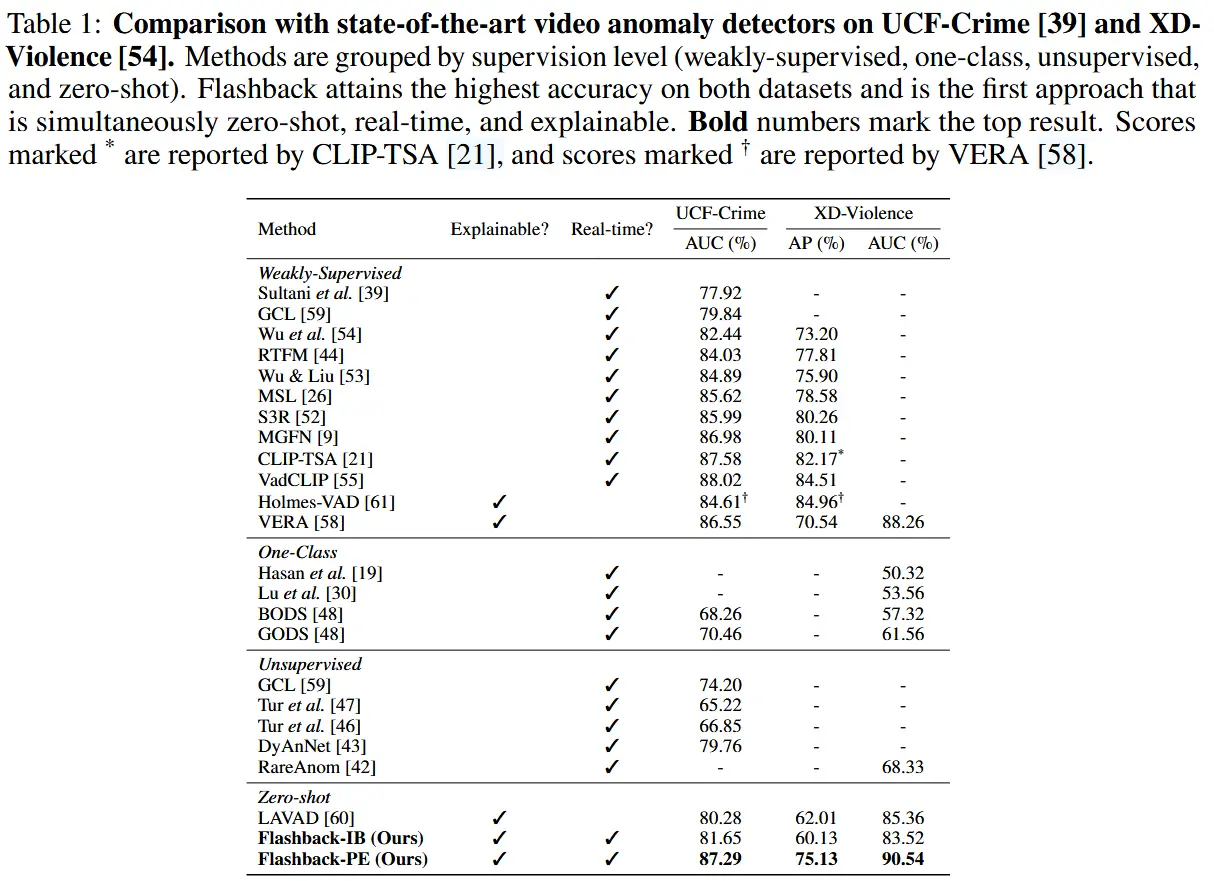
3.2 零样本sota对比
- 如表1所示
- Flashback 在所有零样本设置下均取得了最佳结果。
- Flashback 是首个同时具备零样本学习能力、实时处理能力和返回人类可读解释能力的视频异常检测系统。
3.3 吞吐量评估协议
定义实时检测:
检测器以固定长度 T_{\text{segment}} 的片段处理视频。连续的片段之间存在重叠时间 T_{\text{overlap}} ,因此在下一个片段到达之前的时间预算为:T_{\text{decision}} = T_{\text{segment}} - T_{\text{overlap}}。令 T_{\text{process}} 表示分析一个片段所需的实时时钟时间。当满足以下条件时,称该检测器为实时检测器:
T_{\text{decision}} \leq 1 \, \text{s} \quad \text{and} \quad T_{\text{process}} \leq T_{\text{decision}}. \tag{3}
- 表 2
- 在本实验中,设置 T_{\text{segment}} = 1s , \ T_{\text{overlap}} = 0 s,因此 T_{decision}=1s。
- Flashback 在 T_{\text{process}} = 0.713 \, \text{s} 内完成一个片段的处理,轻松满足了实时要求。
- 除此以外,Flashback 将 AP 从 LAVAD 的 62.01 提升至 75.13,同时将帧率从 1.26 fps 提升至 42.06 fps,速度提升了约 34 倍。

3.4 消融实验
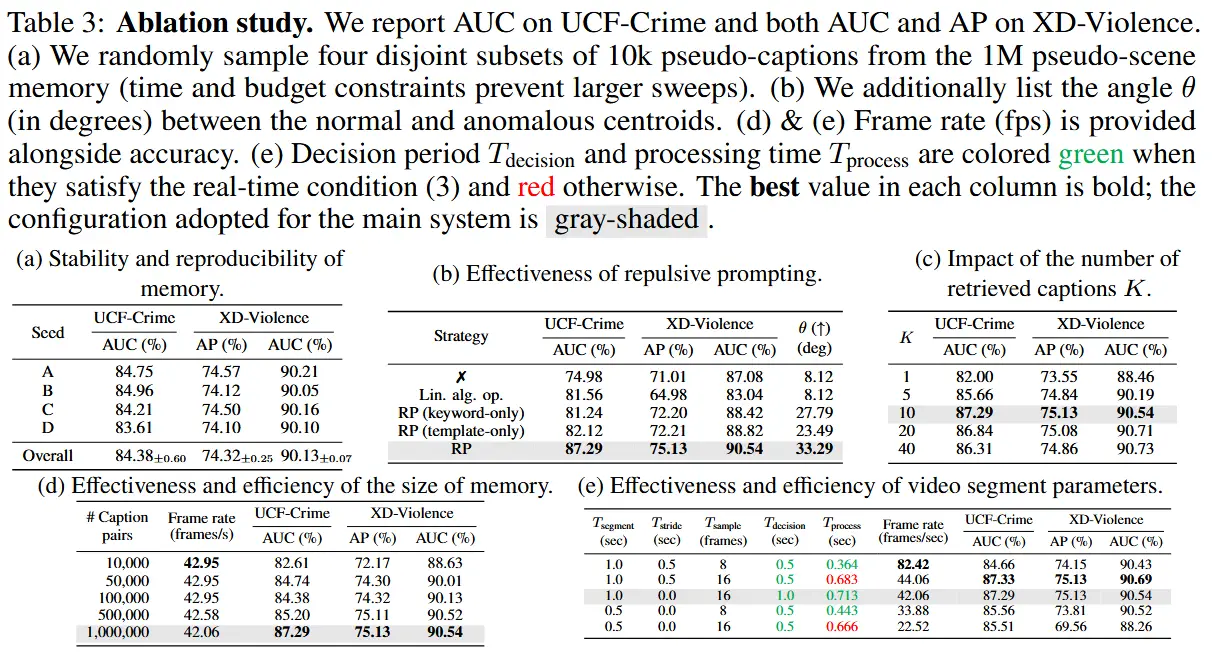
- 表3展示了多种设计的消融实验
- (a) 稳定性与可重复性:从包含 100 万条描述的记忆库中随机抽取四个互不重叠的 10 万条子集,并不做任何训练。
- (b)Repulsive Prompting:排斥提示由关键词"Normal"/"Anomalous"和模板包装器组成,进行消融实验。
- (c)Top-K 描述检索数 K:测试了 K ∈ {1, 5, 10, 20, 40} 对性能的影响。
- (d)记忆库大小与吞吐量:将记忆库大小从 1 万条扩展到 100 万条描述。
- (e)视频片段长度与采样率:使用多种不同采样率、重叠帧数的组合进行测试。