- 论文 - 《Vad-R1: Towards Video Anomaly Reasoning via Perception-to-Cognition Chain-of-Thought》
- 代码 - Github
- 关键词 - reason推理能力、思维链COT、多模态大语言模型MLLMs、强化学习、新数据集、视频异常推理VAR、视频异常检测VAD
1 引言
-
基于多模态大语言模型 MLLMs 的 VAD 方法可以根据 MLLM 的作用分成两类
- 将 MLLM 视为辅助模块,即分类器预测出异常置信度后,再由 MLLM 提供补充性解释。
- 尝试利用 MLLM 直接进行异常检测与理解。
-
动机
- 现有 MLLMs + VAD 的工作可以分成两类:
- (1)将 MLLM 视为辅助模块,即分类器预测出异常置信度后,再由 MLLM 提供补充性解释。
- (2)尝试直接利用 MLLM 进行异常检测与理解。
- 局限:第一类,异常理解是在检测之后的一个步骤, MLLM 的输出并不直接促进异常检测过程。第二类MLLM 往往只是根据视频内容生成异常描述或进行简单的问答任务,缺乏真正的思考与分析能力。因此,在 VAD 领域中,推理能力仍未被充分探索。
- 现有 MLLMs + VAD 的工作可以分成两类:
-
针对上述动机,作者提出了一个新任务 --- 视频异常推理 VAR
- 目标:赋予 MLLM 对视频中异常事件进行结构化、逐步推理的能力。
- 与 VAD 和 VAU(Understand) 任务的不同之处:VAR 更注重深度分析,通过模拟人类的认知过程,实现上下文理解、行为解读以及规范违反分析。
-
VAR 的两大挑战:
- (1)现有的 VAD 数据集缺乏结构化的推理标注,难以用于训练和评估具有推理能力的模型。
- (2)如何有效地训练模型以获得推理能力仍然是一个开放性难题。与具有明确目标的任务不同,开放式 VAR 要求模型进行多步骤推理,难以定义清晰的训练目标或直接引导推理过程。
-
Vad-R1 框架
-
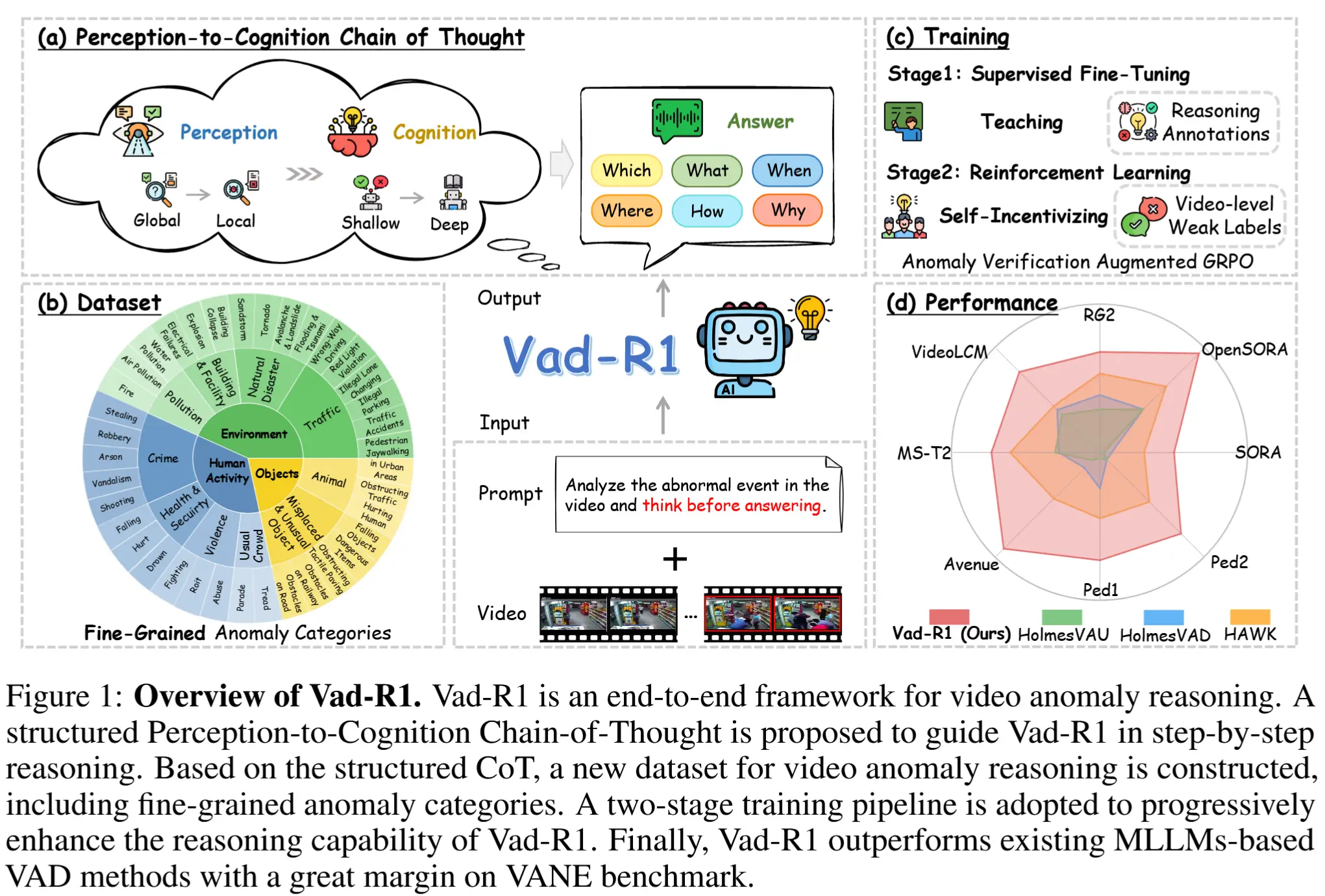
一种基于MLLM的端到端VAR框架,如图1所示。
-
图1(a)展示了一种感知到认知的思维链(P2C-CoT),模拟人类识别异常的过程,引导MLLM逐步推理异常情况。
- P2C-CoT首先引导模型从视频的整体环境逐步聚焦到可疑片段。
- 完成感知阶段后,模型将基于视觉线索从浅层到深层进行认知分析。
- 最终,模型输出分析结果作为回答,包括:异常类别、异常描述、异常发生的时间范围、异常的大致空间位置等。
-
图1(b)展示了作者构建了一个专门用于VAR任务的数据集——Vad-Reasoning。该数据集包含细粒度的异常类别,由两个互补的子集组成:
- 一个子集包含带有P2C-CoT标注的视频,这些标注由闭源模型逐步生成;
- 另一个子集包含大量视频,由于标注成本高昂,仅提供视频级别的弱标签。
-
图1(c)展示了受Deepseek-R1的启发,提出的两阶段的训练流程:
- 阶段一:监督微调,使用高质量的 CoT 标注视频进行监督微调,使基础MLLM具备基本的异常推理能力。
- 阶段二:强化学习,通过提出的 异常验证增强组相对策略优化算法(Anomaly Verification Augmented Group Relative Policy Optimization, AVA-GRPO) 进一步提升推理能力。
-
图1(d)展示了性能。
-
2 相关工作
这里只记录本人感兴趣的一些相关工作
- 标记压缩机制,以获取更长的上下文表示 [29, 71, 86, 23]。
- 在线视频流的理解 [6, 10, 74, 69]。
3 方法:Vad-R1
3.1 感知到认知的思维链
P2C-CoT 受人类的思维方式启发。如图2所示,P2C-CoT 从“感知”到“认知”共分为两个阶段、四个步骤,最终以简洁的答案总结推理过程。

感知(Perception)
P2C-CoT 的感知阶段体现了从全局观察到局部聚焦的过程:
- Step 1 全局感知:模型关注整个环境,描述场景并识别视频中的物体。这一步要求模型具备对视频中“正常性”的全面理解。
- Step 2 局部感知:在理解正常性的基础上,模型聚焦于偏离常规的事件,识别发生了什么(What)、发生的时间(When)与位置(Where)。
认知(Cognition)
接着,P2C-CoT 的认知阶段体现了从浅层认知到深层认知的过程:
- Step 3 浅层认知:模型评估事件的异常性,并结合相关视觉信号解释为何该事件被视为异常。
- Step 4 深层认知:模型进入更高层次的认知阶段,推理异常事件的潜在原因、违反的社会期望以及可能带来的影响。
回答(Answer)
如图2(b)所示,在完成推理过程后,模型应提供一个简明的回答,总结其对给定视频的判断。最终答案包含以下几个关键点:
- 异常类别(Which)
- 事件描述(What)
- 时空定位(When & Where)
- 原因(Why)
- 影响(How)
注意,回答(Answer)只有异常视频才有这一步。
3.2 数据集:Vad-Reasoning
-
数据集来源:UCF-Crime、XD-Violence、TAD、ShanghaiTech、UBnormal、ECVA。
-
异常类别的覆盖范围:包括三种异常分类体系,即人类活动异常、环境异常、物体异常,并继续划分为多个主类别和子类别。
-
数量级
- 训练集:8203个视频。测试集:438个视频。
- SFT阶段使用了1755个视频,具有高质量的推理过程标注(即P2C-CoT)。
- RL阶段使用了6448个视频,仅有视频级别的弱标签。
-
多阶段标注流程
- 首先,提示 Qwen-VL-Max 对视频帧进行密集描述,生成每一帧的内容理解;
- 然后,将这些帧级描述输入 Qwen-Max,在不同 prompt 引导下逐步生成结构化的 CoT 内容。
- 更多细节请参见论文的附录B。
3.3 AVA-GRPO
动机:原始的 GRPO 适用于文本,而在 VAR 这种多模态任务中,由于标注成本高昂,在 RL 阶段只有视频级别的弱标签可用,这使得仅依靠准确率和格式奖励来评估输出质量变得十分困难。
解决办法:AVA-GRPO(Anomaly Verification Augmented GRPO),通过引入一种自验证机制来生成额外的奖励信号,如图3右侧所示。

GRPO 概述
首先回顾原始的 GRPO。GRPO 放弃了价值模型,旨在最大化答案的相对优势。对于一个问题 q ,模型首先生成一组补全结果 O = \{o_i\}_{i=0}^G 。随后,基于预定义的奖励函数计算一组奖励 R = \{r_i\}_{i=0}^G 。然后,将这些奖励标准化以计算相对优势,公式如下:
其中, A_i 是 o_i 的优势分数,它能够更有效地评估单个答案的质量以及组内相对比较。此外,为了防止当前策略 \pi_\theta 过度偏离参考策略 \pi_{\text{ref}} ,GRPO 引入了一个 KL-散度正则化项。最终,GRPO 的目标函数可以表示为:
其中,比率 \frac{\pi_\theta(o_i \mid q)}{\pi_{\theta_{\text{old}}}(o_i \mid q)} 表示当前策略与旧策略之间的相对变化,而 \text{clip}() 操作将该比率约束在一个范围内。
异常验证奖励
AVA-GRPO 步骤概要:
- 对每个生成结果 o_i ,提取视频的预测类别;
- 根据预测结果对视频进行时间裁剪;
- 将裁剪后的视频重新输入模型,生成新答案;
- 比较原始答案与新答案,分配异常验证奖励。
两种情况:
-
原视频预测为异常:
- 裁剪掉检测出的异常时间段,只保留正常片段;
- 若裁剪后模型预测为正常,说明原预测正确+正向奖励。
-
原视频预测为正常:
- 随机裁剪视频开头或结尾(模拟“时间欺骗”现象);
- 若裁剪后模型预测为异常,说明原预测不可靠+负向奖励。
3.4 训练流程
Vad-R1 的训练分为两个阶段:
- 第一阶段:在 Vad-Reasoning-SFT 数据集上监督微调,模型的能力逐步从通用的多模态理解转向对视频异常的理解,并具备基本的异常推理能力。
- 第二阶段:在 Vad-Reasoning-RL 数据集上继续训练,使用 AVA-GRPO 强化学习算法。此阶段的目标是让模型摆脱在SFT阶段可能形成的“模式匹配”倾向,使其具备更灵活、更具泛化能力的异常推理能力。
4 实验
4.1 实验设置
-
所有实验均在 4 块 NVIDIA A100(80GB)GPU 上完成。
-
Vad-R1 基于 Qwen-2.5-VL-7B。
-
数据集:Vad-Reasoning 测试集和VANE [15]。
-
评估指标
- 异常推理能力:BLEU [43]、METEOR [3] 和 ROUGE [31] 等文本生成指标
- 异常检测能力:对异常分类任务,报告Accuracy、Precision、Recall和 F1 分数;对异常时间定位任务,报告 mIoU 和 R@K 指标。
-
基线模型
- 通用视频 MLLM [25, 30, 39, 83, 87]
- 具备推理能力的视频 MLLM [28, 64, 14, 88]
- 闭源模型 [56, 40, 52, 51]
- 基于 MLLM 的 VAD 方法 [50, 85, 84]
4.2 实验结果
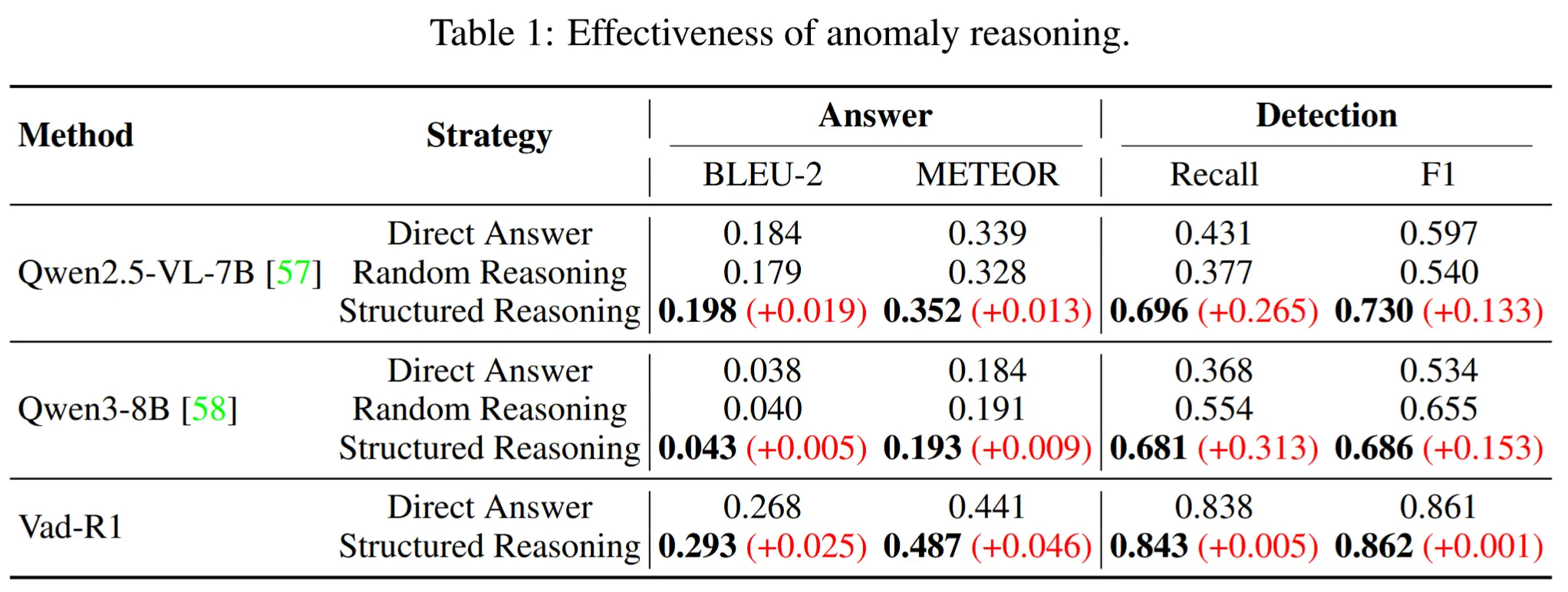
- 推理能力是否有助于提升异常检测?
- 表1展示了异常推理的有效性。
- 与直接输出答案相比,通过提示模型按照 P2C-CoT 进行推理,性能有明显提升。
- Vad-R1 在异常推理与检测方面的表现如何?
- 表2展示了在 Vad-Reasoning 测试集上,Vad-R1 的表现。
- 表3展示了在 VANE 基准上的实验结果。


-
模型是如何获得推理能力的?
- 表4展示了不同训练策略的有效性。
- SFT 阶段为模型提供了基础的推理能力,RL 阶段则在此基础上进一步增强了推理表现 。


