- 论文 - 《HARGPT: Are LLMs Zero-Shot Human Activity Recognizers?》
- 代码 - Github
- 关键词 - 评估工作、大模型GPT-4、人类活动识别HAR、零样本
注意这是一篇评估现有工作的文章。
摘要
- 研究问题:LLMs 是否具备零样本的人类活动识别(HAR)能力?
- 本文工作
- 证明了LLMs可以在仅使用适当提示的情况下,理解原始惯性测量单元(IMU)数据,并以零样本的方式完成HAR任务。
- HARGPT 将原始 IMU 数据输入给 GPT-4,使用了两个不同类间相似度的数据集,并利用角色扮演和“逐步思考”的策略进行提示设计,最终证明 LLMs 的效果优于基于传统机器学习和深度分类模型。
1 实验
1.1 实验设定
- 作者设计了两组不同难度的实验
- 实验一:验证 LLMs 是否能够区分具有明显差异的活动类型,例如“睡觉”和“走路”。
- 实验二:测试这些模型是否能够识别具有高度相似模式的活动,例如“上楼”和“下楼”。
- 数据集
- Capture24,类别差异显著,用于实验一。
- HHAR,类别相似,用于实验二。
- 基线模型
- 随机森林:一种用于分类的集成学习方法,它在训练过程中构建多个决策树,并通过投票机制提升分类性能。
- 支持向量机:一种基于最大间隔的监督学习模型。
- 深度卷积神经网络:DCNN 由卷积神经网络组成,能够从穿戴式传感器获取的多通道时间序列信号中自动学习特征。
- LIMU-LSTM [20]:一种基于长短期记忆网络(LSTM)构建的分类模型,按照时间顺序对输入特征进行分析,更适合处理具有时序特性的 IMU 数据。
- Prompt 结构设计
- 如图3所示,本文设计的提示设计仅包含一条指令和一个问题:
- 指令部分 旨在利用 LLMs 对 IMU 数据相关知识的理解;
- 问题部分 则提供了关于数据采集、降采样后的原始数据序列以及可能的人类活动类别等具体信息。
- 问题结尾处加入“请逐步进行分析”目的是引导模型生成详细的思维链(CoT)过程。(作为对比,作者将结尾换成了“请直接给出答案,不需要分析。”,以评估CoT的作用)
- 如图3所示,本文设计的提示设计仅包含一条指令和一个问题:

1.2 类间差异性实验
- 表1
- DO指的是直接输出(Direct Output, DO),即不需 CoT 。
- 借助其强大的理解能力和 CoT 提示机制,GPT-4 在所有未见样本的基准指标中都表现出色,平均 F1 分数达到了 0.795 。

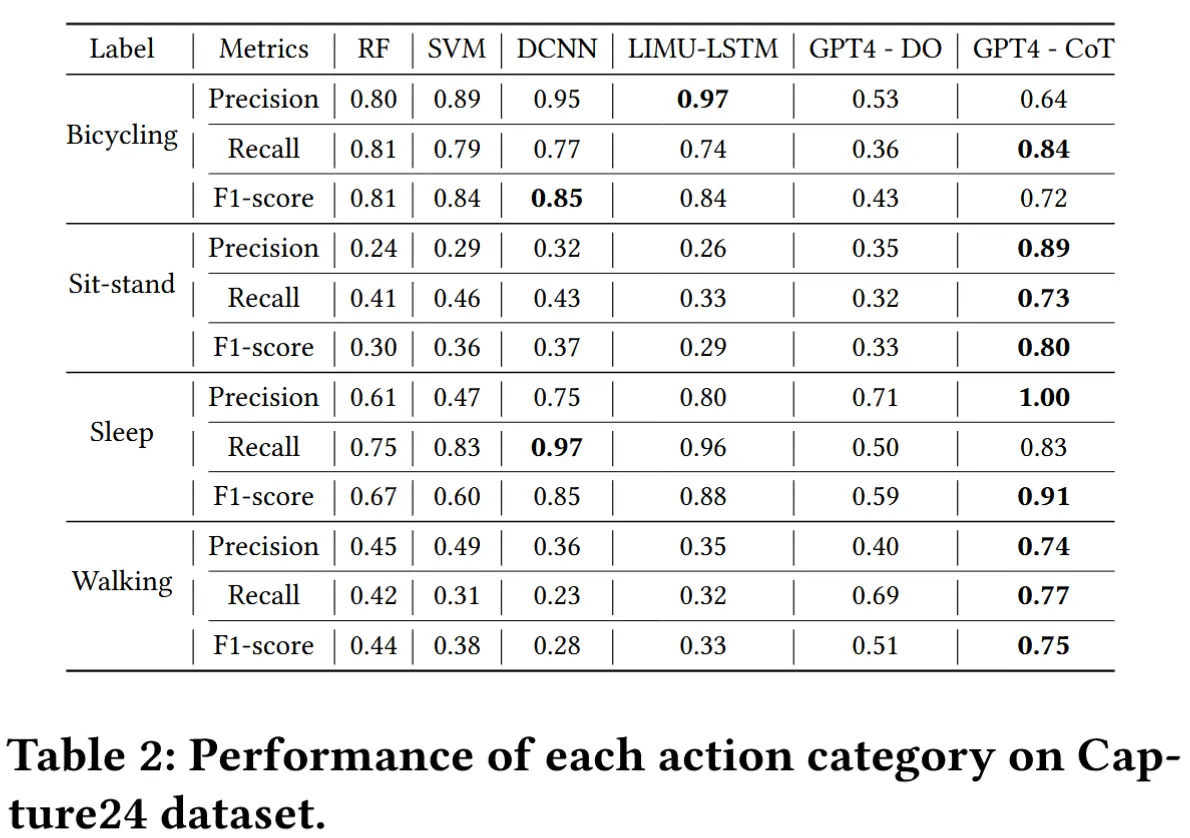
- 表2
- 展示了各分类的具体结果。
- GPT-4-CoT 实现了较为均衡的性能。
- 虽然 DCNN 和 LIMU-LSTM 在识别“Bicycling”和“Sleep”这类动作时准确率较高,但在识别“Sit-stand”和“Walking”等动作时准确性显著下降。
1.3 类间相似性实验
- 实验设定与第1.2节类似,只是换成了类间相似度更高的HHAR数据集,更具挑战性。
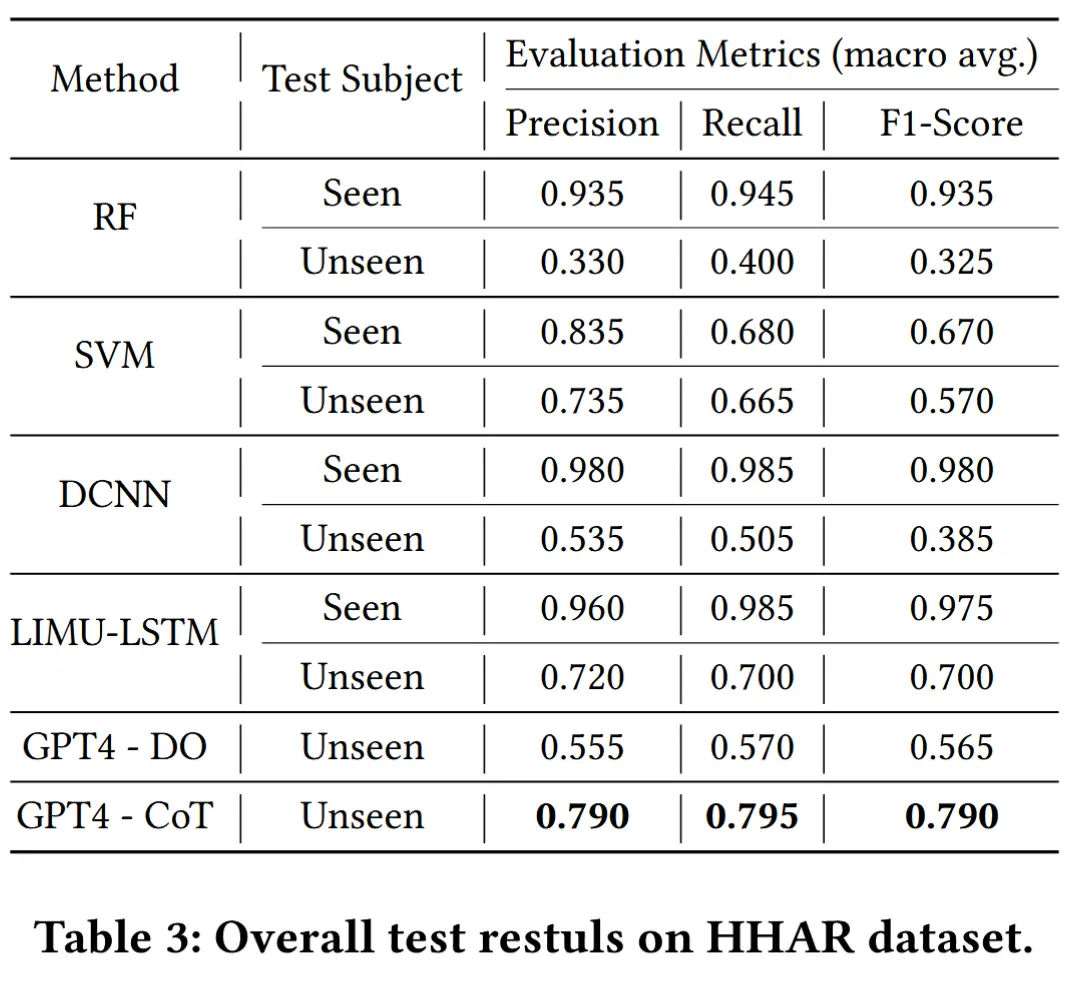
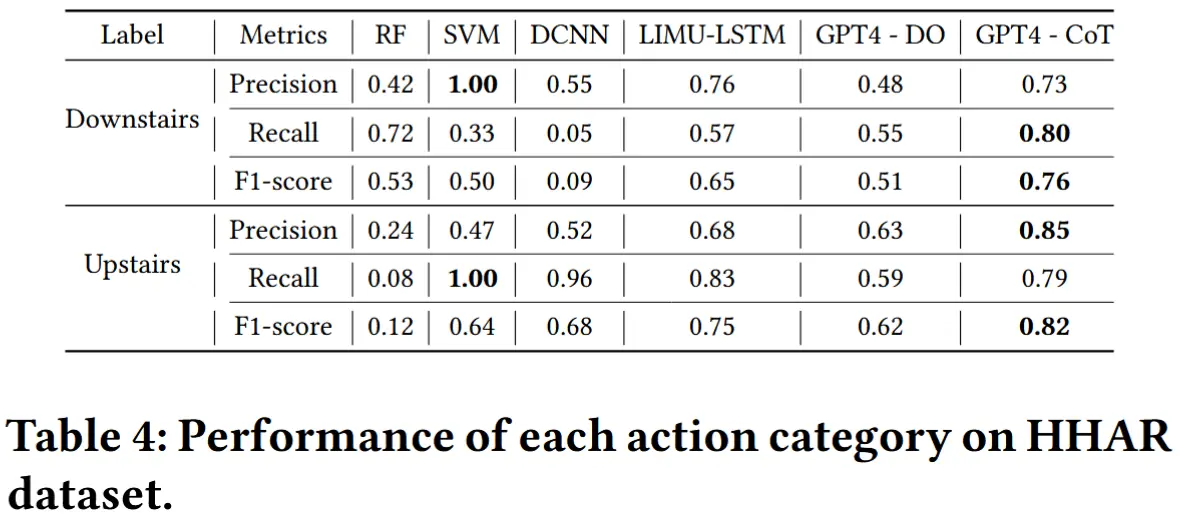
- 实验结果如表3和表4所示,GPT-4-CoT 表现出色,平均准确率接近 80% ,召回率和 F1 分数也令人满意。
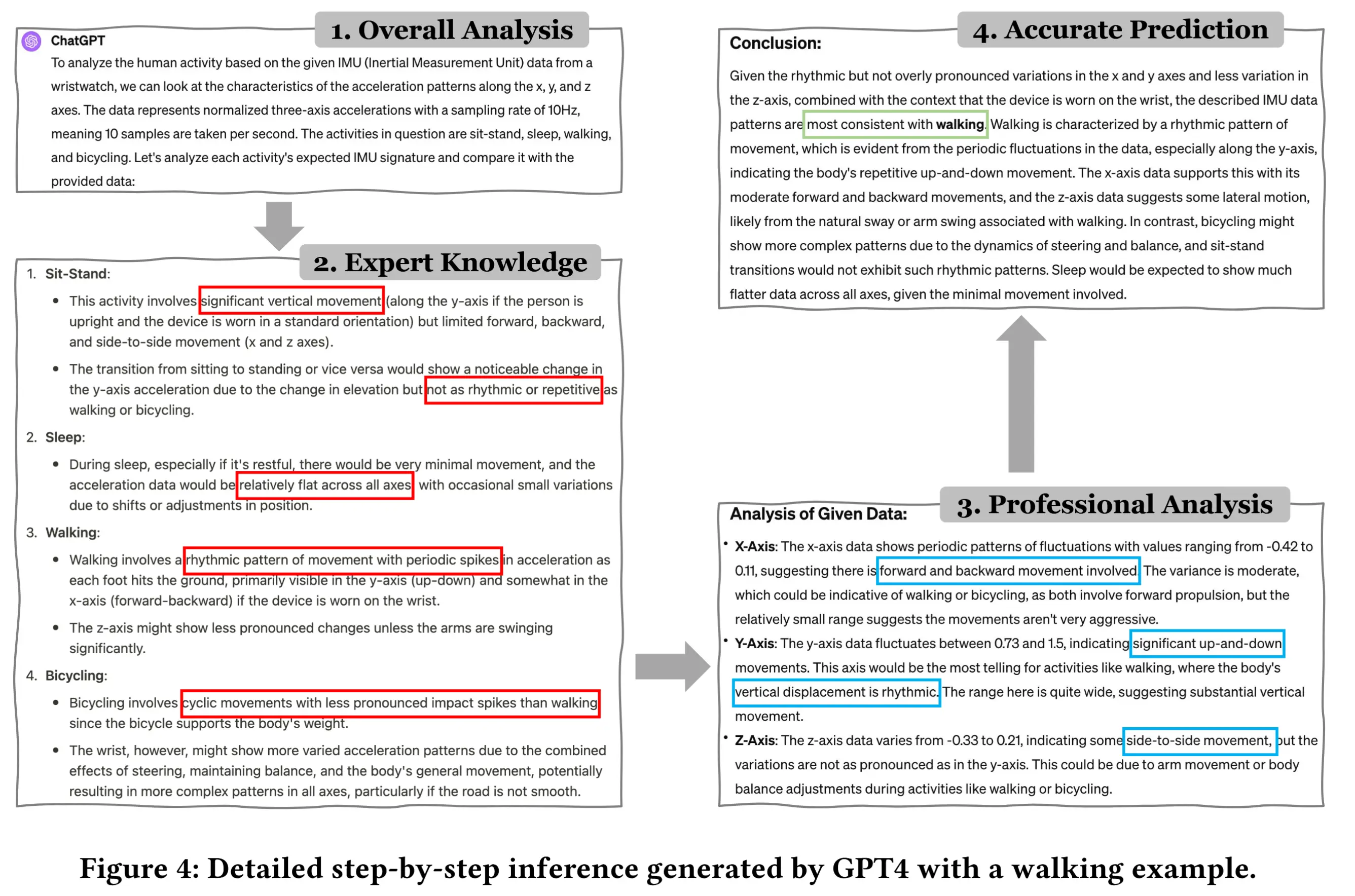
1.4 详细推理示例
- 图4展示了一个关于“走路”概念的完整推理过程示意图。
- 整个而推理过程分为4个部分:
- 问题理解阶段 :模型首先解释给定的信息,并明确自己需要解决的问题。
- 专家知识调用阶段 :结合隐藏的“专业知识”,模型准确描述每种动作对应的原始 IMU 数据特征。例如,“骑车”和“走路”都具有周期性特征,“睡觉”几乎无波动,“坐-站”则存在突变值。
- 数据分析阶段 :对输入的原始数据进一步分析,得出该数据具有周期性和上下波动的特征。
- 综合判断阶段 :在准确分析的基础上,结合已有知识,模型最终做出判断:该动作为“走路”。
2 未来工作与结论
- 结论:LLMs 能够在无需专家引导示例的情况下处理 IoT 传感器数据。
- 未来工作
- 仍需进一步研究来评估 LLMs 在何种程度和哪些场景下能够有效发挥作用。
- 通过加深我们对语言模型能力与局限性的理解,我们可以更好地利用其优势,推动对现实世界数据的认知与处理能力,甚至包括如 WiFi-CSI 等抽象数据形式的理解。