- 论文 - 《Leveraging Synthetic Adult Datasets for Unsupervised Infant Pose Estimation》
- 代码 - 给的链接失效了
- 关键词 - 婴儿动作识别、无监督域适应、均值教师模型、流形先验
摘要
- 研究问题
- 针对婴儿的姿态估计发展仍较为有限。
- 现有的婴儿姿态估计算法依赖于完全监督的学习方法,需要大量标注数据。此外,这些算法在面对数据分布变化时泛化能力较差。
- 本文工作
- 本文提出了 SHIFT(SyntHetic Adult Datasets for Unsupervised InFanT Pose Estimation):一种利用合成成人数据集进行无监督婴儿姿态估计的新方法。
- SHIFT 基于伪标签的 Mean-Teacher 框架,以弥补婴儿标注数据的不足,并通过在学生模型与教师模型之间强制保持伪标签的一致性来应对数据分布偏移问题。
- 为了进一步提升模型性能,作者还引入了一种 infant manifold pose prior,以惩罚由 Mean-Teacher 框架生成的不合理姿态预测。
- 为了增强 SHIFT 对自遮挡情况的感知能力,作者提出了一种新的可见性一致性模块,以提高预测姿态与原始图像之间的对齐效果。
1 引言
- 婴儿姿态估计的应用场景:神经运动评估(发育障碍风险婴儿)[35,44]、面部表情识别 [27,43]、安全监控 [9]、可穿戴辅助机器人反馈控制 [28,29]。
- 当前方法局限:依赖全监督训练 ,使用整理好的婴儿数据集训练和测试,容易过拟合,泛化能力差。
- 提出假设:能否在无监督设置下 ,将预训练的成人姿态模型迁移到婴儿任务中?
- 研究现状
- 已有研究 [18,20] 尝试基于合成源数据训练的成人姿态估计算法迁移至“真实世界”图像。
- 但这些方法迁移到婴儿姿态图像时,表现不佳,可能的原因是:
- 成人和婴儿解剖结构差异。
- 动作模式不同,随成长才趋近成人。
- 姿态更复杂多样,成人数据未覆盖。
- 但这些方法迁移到婴儿姿态图像时,表现不佳,可能的原因是:
- 也有研究用合成成人数据预训练后,全监督微调 到婴儿数据 [14]。
- 仍需要访问带有标签的婴儿姿态数据集。
- 跨数据集泛化能力仍然较差。
- 已有研究 [18,20] 尝试基于合成源数据训练的成人姿态估计算法迁移至“真实世界”图像。
- 本文解决方案
- SHIFT(Leveraging SyntHetic Adult Datasets for Unsupervised InFanT Pose Estimation),即“利用合成成人数据集实现无监督的婴儿姿态估计”。
- 引入了 Mean-Teacher 模型训练机制,确保生成可靠的伪标签。
- 利用 数据增强策略,强制学生模型和教师模型之间的预测保持一致性。
- 除此以外,作者还引入了两种新的正则化方法,以加入针对婴儿特有的解剖学约束,帮助适应后的模型更准确地预测婴儿姿态。
- 1)婴儿姿态流形先验(Manifold Pose Prior):受 [40] 启发,符合解剖结构的姿态位于流形上 (零水平集),否则为不合理姿态。在训练中对不合理预测进行惩罚,提升姿态合理性。
- 2)可见性一致性模块(Visibility Consistency):训练一个函数:将关键点映射为轮廓图(Kp2Seg),结合预训练分割模型 [2] 提取婴儿掩码,强制姿态预测与图像中的婴儿轮廓保持一致,提升姿态-图像对齐能力。
2 相关工作
2.1 人体姿态估计
- 现有的姿态估计算法主要可以分为两大类范式:
- 自底向上方法:先找关键点再分人,如 OpenPose [7]。
- 自顶向下方法:先检测人再估姿态(更准),如 HourGlass [30]、HRNet [4] 等。
- 这些方法都需要大量标注的数据集。
2.2 婴儿姿态估计
- 主要数据集:
- MINI-RGBD [11]:利用统计三维形状模型 Skinned-Multi Infant Linear(SMIL)生成的合成婴儿视频。
- SyRIP [14]:包含真实 + 合成婴儿图像,同样使用 SMIL 模型生成。
- ZEDO-i [51]:用扩散模型做 2D→3D 提升。
- 所有方法均依赖标注数据 → SHIFT 首次尝试无监督迁移,无需婴儿标签
2.3 用于姿态估计的无监督域适应
- 无监督域适应(UDA)算法目标:将知识从带有标签的源域迁移到未带标签的目标域。
- 姿态估计UDA代表方法
- [18] 提出使用对抗训练学习域不变特征。
- Kim 等人 [20] 则采用 Mean-Teacher 框架 [39] 和风格迁移技术 [13],在无标签的目标数据上优化伪标签,分别实现了输出层和输入层的一致性对齐。
- SHIFT 受 [20] 启发,首次将其应用于婴儿姿态估计 ,从成人数据迁移到婴儿,无监督。
3 方法
-
数据设定
- 源域 S(成人)
- 标注数据集: D_S = \{(x_s^i, y_s^i)\}
- 输入图像: x_s \in \mathbb{R}^{H \times W \times 3}
- 关键点标签: y_s \in \mathbb{R}^{K \times 2}
- 目标域 T(婴儿)
- 未标注数据集: D_T = \{x_t^i\}
- 输入图像: x_t \in \mathbb{R}^{H \times W \times 3}
- 模型 \mathcal{M} :已在成人数据上预训练,用于预测关键点热图。
- 目标:将模型迁移到无标签的婴儿图像,提升性能。
- 源域 S(成人)
-
框架概述如图 2 所示,SHIFT 组成部分:
- 源域预训练: 使用监督损失初始化姿态估计模型权重。
- Mean-Teacher 自适应:利用 Mean-Teacher 框架 + 数据增强生成伪标签。同时,强制学生-教师输出一致性,提升迁移效果。
- 流形姿态先验:设计婴儿姿态的合理性约束,以捕捉婴儿姿态中的复杂解剖细节。
- 可见性一致性模块:通过对齐预测的姿态与婴儿分割掩码的可见性来实现适应。
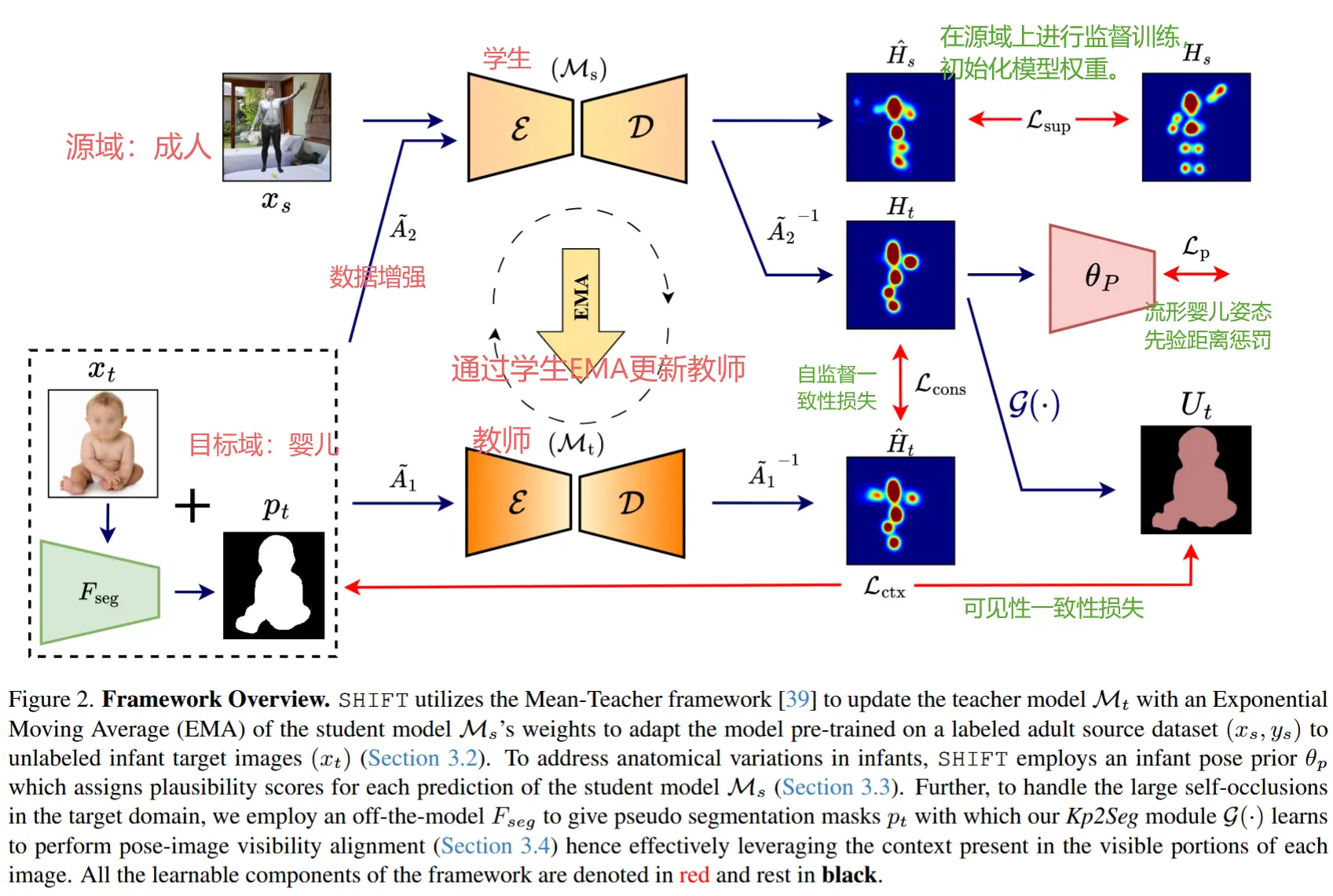
3.1 源域预训练
目标:使用源域预训练初始化姿态模型 \mathcal{M} 的权重。
方法:
- 使用监督学习,在成人数据集 D_S 上训练。
- 给定一个转换函数 \phi: \mathbb{R}^{K \times 2} \to \mathbb{R}^{K \times H' \times W'} ,其中 H' 和 W' 表示生成的热图的空间维度。将关键点标签 y_s 转换为高斯热图 H_s = \phi(y_s)
- 使用均方误差(MSE)损失优化模型:
3.2 估计空间适应
核心思想:使用 Mean-Teacher 框架 [39] 在无标签婴儿图像上生成伪标签,并通过一致性损失进行模型适应。
教师模型EMA更新:教师模型 \mathcal{M}_t 的权重更新通过学生模型权重的指数移动平均(EMA)完成:
衰减率 \alpha=0.999 。这种稳定性对于预训练至关重要,因为它增强了教师模型生成可靠伪标签的能力,避免过拟合,从而提高整体训练效率。
数据增强与一致性学习:分别对学生和教师的输入分别进行增强操作 \tilde{A_1} 和 \tilde{A_2} ,生成目标图像 x_t 的两种不同视图。与 [20] 类似,通过修补操作 P 对教师模型 \mathcal{M}_t 产生最高激活的关键点进行选择性修补: \hat{x}_t = P(\tilde{A}_2(x_t)) 。这有助于引导学生模型的热图预测 H_t = \phi(\mathcal{M}_s(\hat{x}_t)) 更加关注那些相对于遮挡关键点而言置信度较低的关键点。为了从教师模型 \mathcal{M}_t 中生成伪标签,只采样那些产生最大激活值的关键点: \hat{y}_t = \arg\max(\hat{H}_t) ,其中 \hat{H}_t = \phi(\mathcal{M}_t(\tilde{A}_1(x_t))) 。此外,为了减少噪声标签传播的影响,设置了一个固定的阈值 \tau_c 来过滤掉不可靠的伪标签。因此,学生模型 \mathcal{M}_s 在第 k 个关键点上的学习目标,针对学生热图 \hat{H}_t^k 和伪标签 \hat{x}_t^k ,由均方误差损失定义:
其中, N'_t 表示目标域(婴儿)图像的批次大小, \tilde{A}_1^{-1} 和 \tilde{A}_2^{-1} 分别表示增强操作的逆变换。阈值 \tau_c 旨在仅考虑高置信度的伪标签。因此,该损失函数在强制教师模型生成的伪标签与学生模型估计的关键点之间的一致性方面起着至关重要的作用。
3.3 流形婴儿姿态先验
英文:Manifold Infant Pose Prior
动机:强制学生模型和教师模型的估计空间一致性,无法感知目标域的不同解剖学特征。
解决方法:作者设计了一个流形先验,用于将所有物理上合理的婴儿姿态建模为零水平集(zero-level set)。该先验利用了 PoseNDF [40] 中引入的架构,基于婴儿姿态的物理合理性生成分数。该模块以跨数据集的方式离线训练,即先验是在与评估所用数据集不同的数据集上预训练的。由此产生的姿态先验模块 (\theta_p) 可以根据一组多样的解剖学变化来评估学生模型生成的姿态。
具体做法:为了设计一种领域无关的姿态表示,首先定义人体中解剖学上连接的一对关节集合。这些关节对以二维方向向量的形式表示,具体公式如下:
利用流形假设 [5],假设所有物理上合理的婴儿姿态可以位于一个流形上,该流形被定义为零水平集 \mathcal{P} = \{\theta \in \mathcal{V} \mid p(\theta) = 0\} ,其中 l 表示某个特定姿态偏离流形的距离。使用编码函数 p_{\text{enc}} 来存储这条个体姿态方向编码链。每个编码可以表示为:
而整体姿态编码表示为:
按照 [40] 的方法,构建了一个姿态编码-距离对的数据集 D_{pd} = \{(\theta_i, l_i)\}_{i=1}^{N_t} ,用于训练先验模型 \theta_p 。所有位于流形上的姿态都被赋值 l = 0 。先验模型随后通过多阶段训练方法进行训练,以确保其鲁棒性。
通过从 von Mises 分布中采样噪声来生成嘈杂的姿态。给定目标域中的第 i 张图像 x_t^i ,我们获得热图 H_t^i = \phi(\mathcal{M}_s(x_t^i)) ,并从目标域中获得的热图 H_t^i 的像素坐标计算一组归一化方向向量。这些归一化方向向量是针对 D_{pd} 中每一对解剖学上连接的关键点计算的。因此,对于给定的一对连接关键点 (m, n) ,我们有从初始像素坐标 p^m 到 p^n 的单位向量 \theta 。这可以表示为:
姿态适应
在适应过程中,利用这个训练好的先验,基于学生模型预测的姿态与合理姿态流形之间的距离,预测一个平均合理性得分。我们可以设置先验的目标 (\theta_p) 为预测预测姿态与我们在流形上预学习的合理姿态集合之间的距离 l 。这可以通过以下公式给出:
其中, N'_t 表示目标域图像的批次大小, T 是一个可微的方向函数,用于将学生模型的预测转换为一组方向向量,然后由先验处理以给出平均合理性得分。
3.4 场景感知适应
动机:大多数婴儿姿态数据集都面临高自遮挡的问题,例如当婴儿处于侧卧或俯卧位置时。受研究表明多模态解析可以作为丰富空间信息来源的启发 [23, 48],我们利用分割掩码为学生模型在训练过程中提供额外的上下文指导,以对齐姿态和图像空间。
提取分割掩码
首先使用 DeepLab-v3 [2] 从目标域 T 中提取二值前景-背景分割掩码。将这些预提取的伪掩码集合表示为 D_{\text{seg}} = \{p_t^i\}_{i=1}^{N_t} ,其中目标数据集 \mathbf{D}_T 包含 N_t 张图像。
将热图转换为分割掩码
在学生模型的估计空间中,使用 Kp2Seg 模块 \mathcal{G} 将获得的热图转换为分割掩码。对于目标域中的第 i 张图像 x_t^i ,我们有 \hat{H}_t^i = \phi(\mathcal{M}_s(\tilde{A}_2(x_t^i))) 作为学生模型预测的目标批次热图,从而得到分割掩码 U_t^i = \mathcal{G}(\hat{H}_t^i) ,其中 \mathcal{G}: \mathbb{R}^{K \times 2} \to \mathbb{R}^{H'' \times W''} 表示将热图映射到分割掩码的模块, H'' 和 W'' 表示获得的掩码的空间维度。
自监督一致性目标
p_t^i 和 U_t^i 之间的自监督一致性目标可以通过交叉熵损失函数表示为:
其中, N'_t 是目标域图像的批次大小, p_j^i 是第 i 个预提取伪掩码在像素 j 处的二值标签(0 或 1),而 U_{t,j}^i 是第 i 个映射分割掩码在像素 j 处的预测概率。
Kp2Seg 模块的工作原理
关键点到分割掩码编码模块 \mathcal{G} 作为一个映射函数,用于将学生模型预测的稀疏低分辨率热图(表示关键点)转换为密集高分辨率的分割掩码。利用 DC-GAN [34] 架构中的解码器,将其作为学习到的映射函数,将热图预测转换为分割掩码。
为了训练 \mathcal{G} ,作者准备了一个合成辅助数据集 D_{\text{aux}} = \{(g_s^i, p_s^i)\}_{i=1}^{N_s} ,其中 g_s^i 和 p_s^i 分别表示辅助数据集 D_{\text{aux}} 中的第 i 个真实姿态和预提取的分割掩码。然后, \mathcal{G} 以端到端的监督方式训练,将分割掩码从关键点映射出来。这可以被表述为预提取分割掩码 p_s 和映射后的分割掩码 u_s = \mathcal{G}(\phi(g_s^i)) 之间的交叉熵损失:
其中, N_s 表示源图像的批次大小。需要注意的是,在适应过程或离线训练中都不使用真实分割掩码,且我们在训练 \mathcal{G} 时不使用任何 RGB 信息,因此该模块是领域无关的。
3.5 整体适应
将上述所有损失项结合起来,学生模型 \mathcal{M}_s 使用加权适应目标进行训练:
超参数 \lambda_{\text{cons}} 设置为 1; \lambda_p = 1e-6 ; \lambda_{\text{ctx}} = 1e-5 。
4 实验
4.1 实验设定
- 数据集
- SURREAL:大规模的合成数据集,包含人物图像和25个关节点。
- MINI-RGBD:12,000张合成婴儿图像,并标注了25个关节点。编号“01-10”训练,“11-12”验证。
- SyRIP:1,000张合成婴儿图像和700张真实婴儿图像,标注了17个关节点。1,200张真实与合成样本进行训练,500张真实图像进行测试。
- 基础模型训练
- 采用 ResNet-101 作为姿态估计模型的主干网络。
- 先验模型训练 \theta_p
- 基于 PoseNDF 架构 训练姿态先验模型,采用多阶段训练策略,结合流形姿态和非流形姿态。
- 先验模块在构建的婴儿姿态先验数据集上进行跨数据集监督训练。
- Kp2Seg 模块训练 \mathcal{G}
- 采用 DC-GAN 架构作为 Kp2Seg 模块的基础结构。
- 使用 DeepLab-v3 从源域(成人)的合成图像中提取分割掩码。
作者给出了很多训练的详细参数和信息,这里不展示了。
- 无监督域适应基线
- UniFrame [20]
- RegDA [18]
- 有监督域适应基线
- FiDIP [14]
- Oracle:在目标域(婴儿)数据上以全监督方式训练得到的性能上限。
- Source-Only:直接将未经过适应的源域模型应用于目标域推理得到的性能下限。
- 评估指标:
- PCK(Percentage of Correct Keypoints),即预测关键点与真实关键点之间的距离在指定阈值内的比例。
- 后续报告的所有准确率均基于 PCK@0.05,即对 16 个关键点 计算在归一化距离 0.05 范围内的正确率。
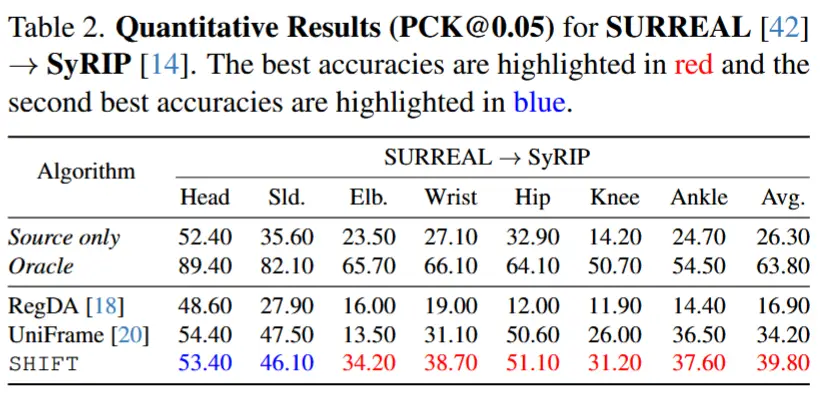
4.2 定量结果
- 使用两个 UDA 迁移场景:
- SURREAL(成人合成) → MINI-RGBD(婴儿合成)
- SURREAL(成人合成) → SyRIP(婴儿真实+合成)
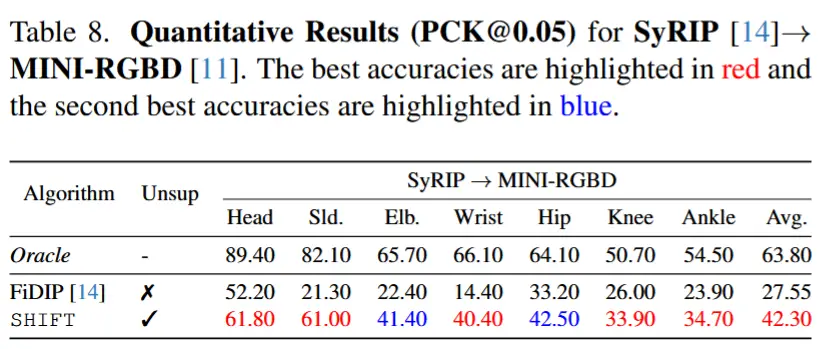
- SyRIP → MINI-RGBD 的无监督迁移评估,用于对比 FiDIP。

4.3 消融实验
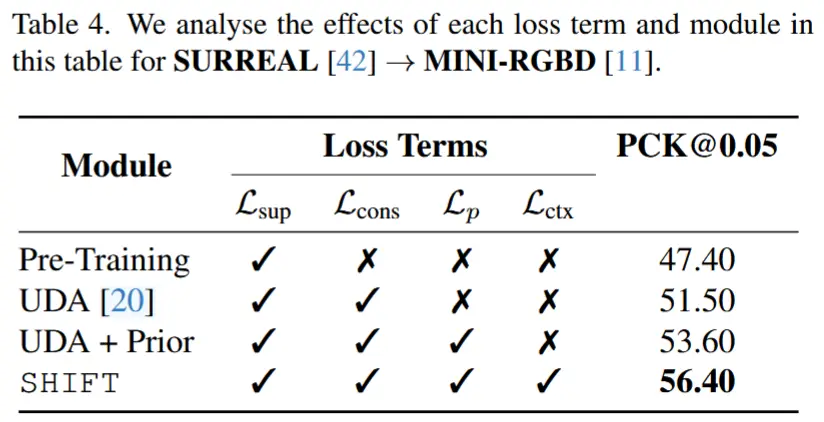
1. 损失项影响分析
- 在完整模型的基础上,逐步移除或禁用不同模块/损失项:
- 流形婴儿姿态先验(\mathcal{L}_p )
- Kp2Seg 可见性一致性模块(\mathcal{L}_{ctx})
- 自监督一致性损失(\mathcal{L}_{cons})
- 使用 PCK@0.05 指标评估各变体在目标域上的性能。
2. 伪标签阈值影响分析
- 设置多个不同的阈值进行实验
- 观察不同阈值对最终姿态估计性能的影响