- 论文-《Cloud-Device Collaborative Learning for Multimodal Large Language Models》
- 关键词:云端-设备协作、多模态、大模型、CVPR2024
摘要
- 问题背景:多模态大语言模型(MLLMs)在图像描述生成、常识推理和视觉场景理解等多样化任务中展现出卓越性能,然而因参数量庞大,在客户端设备部署时面临严峻挑战,且直接对模型压缩会导致泛化能力显著下降。
- 解决办法
- 作者提出一种云-设备协作持续适应框架,旨在通过利用云端大规模MLLMs的强大能力,提升压缩后设备端部署模型的性能。
- 该框架包含三个核心组件:
- 设备到云的高效数据传输上行链路:采用 基于不确定性的令牌采样(UTS) 策略,有效过滤分布外令牌,从而降低传输成本并提升训练效率。
- 云端知识适配机制:基于适配器的知识蒸馏(AKD)方法,将大规模模型的精炼知识迁移至压缩后的轻量级设备端模型。
- 云到设备模型部署下行链路:设计 动态权重更新压缩(DWC) 策略用于下行链路传输,通过自适应选择和量化更新的权重参数,既提升传输效率,又缩小云端与设备端模型的表征差异。
- 实验效果:在多个多模态基准测试中的大量实验表明,本框架显著优于现有的知识蒸馏和云-设备协作方法,并且在实际场景实验验证了该方法的可行性
1 介绍
- MLLMs 模型压缩
- 优点:压缩后的模型在测试数据分布与训练数据分布高度一致时表现优异。
- 缺点:在真实场景中,非静态环境和数据分布偏移现象普遍存在,这使得轻量化模型面临显著性能衰减问题。
- 主要挑战:
- (1) 边缘设备的有限算力阻碍了模型的实时更新能力,导致在遭遇分布偏移时性能下降。
- (2) 压缩模型因容量有限,在持续变化的环境中难以充分适应,导致泛化能力不足。
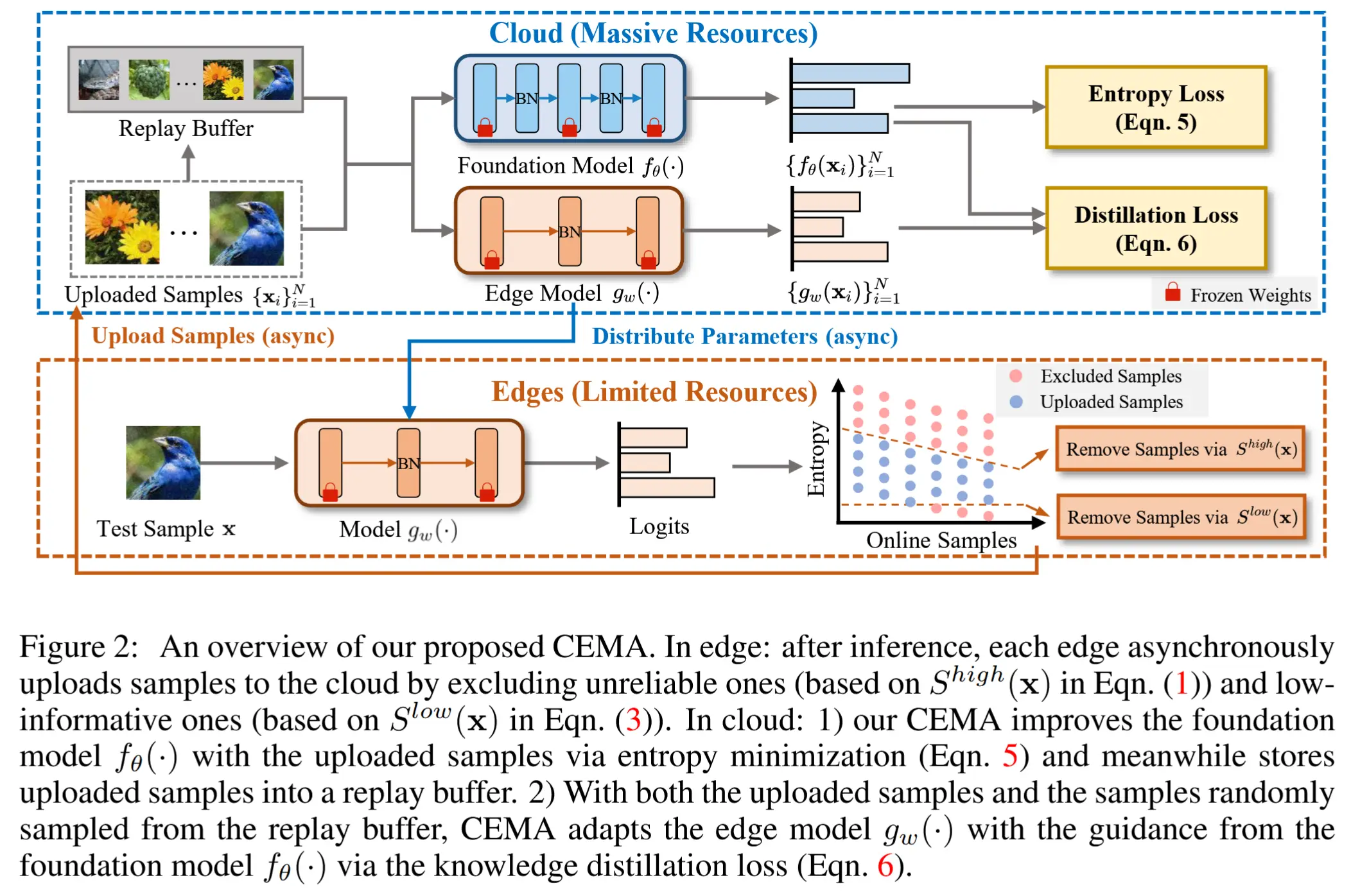
- 本文方法 -> 云-设备协作持续适应框架(CD-CCA)
- 如图1所示
- 核心思想:通过云端大规模MLLMs增强设备端压缩模型的泛化能力,实现“在保持设备端模型高效性的同时提升其动态环境适应性”的双重目标。
- 提出了全新的学习范式——云-设备协作持续适应,该范式包含三大核心组件:设备到云的上行链路、云端知识更新机制,以及云到设备的下行链路。
-
组件一:设备到云的上行链路
- 使用一种名为 基于不确定性的令牌采样(UTS)策略 的 由粗到细令牌过滤方法 ,以最小化上行传输成本。
- 其核心流程分为两步:
- 样本级过滤 :利用样本级不确定性识别并过滤目标分布数据中的极端案例。
- 令牌级过滤 :通过令牌级不确定性进行二次过滤,分离出分布外(out-of-distribution)令牌。
- 优点:该方法有效缓解了网络传输带宽限制,同时提升了云端服务器的训练效率。
-
组件二:云端知识更新
- 提出了一种专为MLLM设计的 基于适配器的知识蒸馏(AKD), 旨在将原始超大规模MLLM中的“暗知识”(dark knowledge)迁移至压缩后的轻量级MLLM中。
- 该方法聚焦于以下两点:
- 跨模态对齐能力增强 :针对跨模态变压器中的 可学习查询适配器 (learnable query adapter)进行知识蒸馏,提升轻量级MLLM的视觉-文本对齐能力。
- 语言推理能力优化 :进一步对 可学习语言适配器 (learnable language adapters)进行知识蒸馏(适配器被插入LLM中),以增强学生模型(student MLLM)的语言交互与推理能力。
-
组件三:云到设备的下行链路
- 针对设备端MLLM的动态更新权重参数,采用了一种自适应量化与压缩技术 。这些压缩后的权重参数通过下行链路传输至设备端,显著缩小了设备端与云端MLLM在表征能力上的差距。
2 方法
2.1 CD-CCA 框架概览
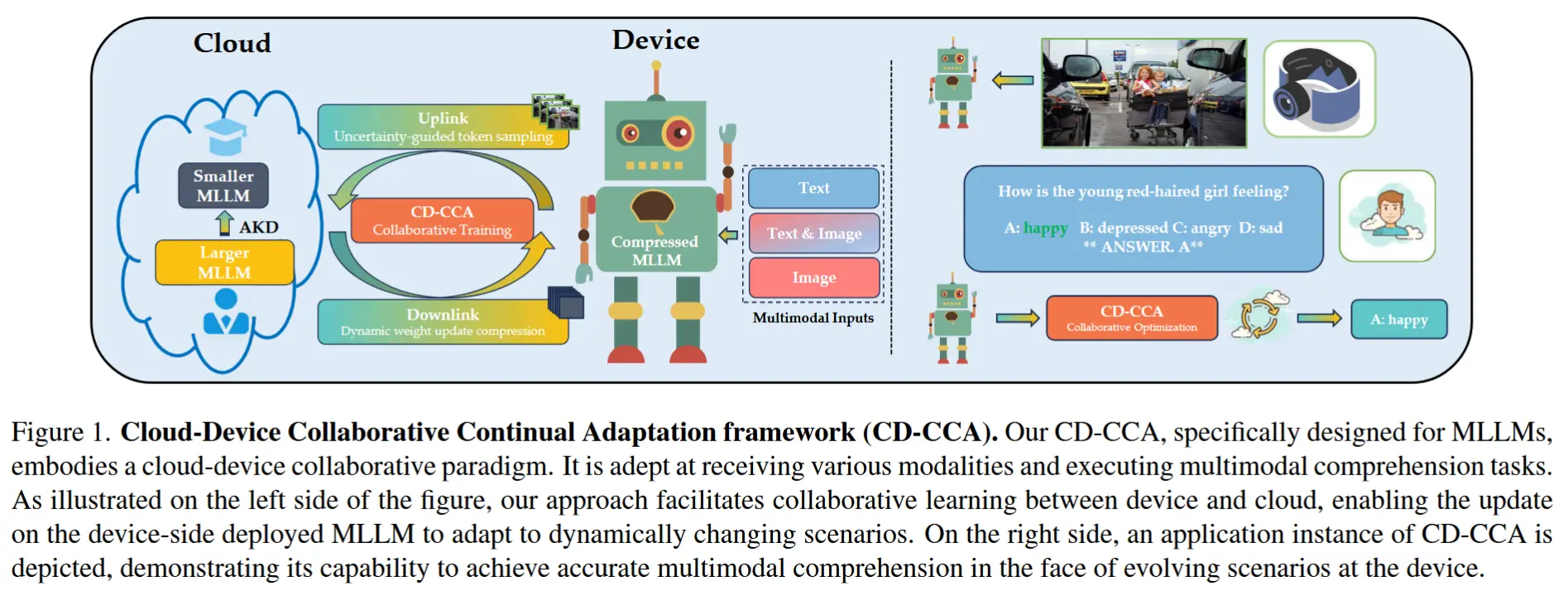
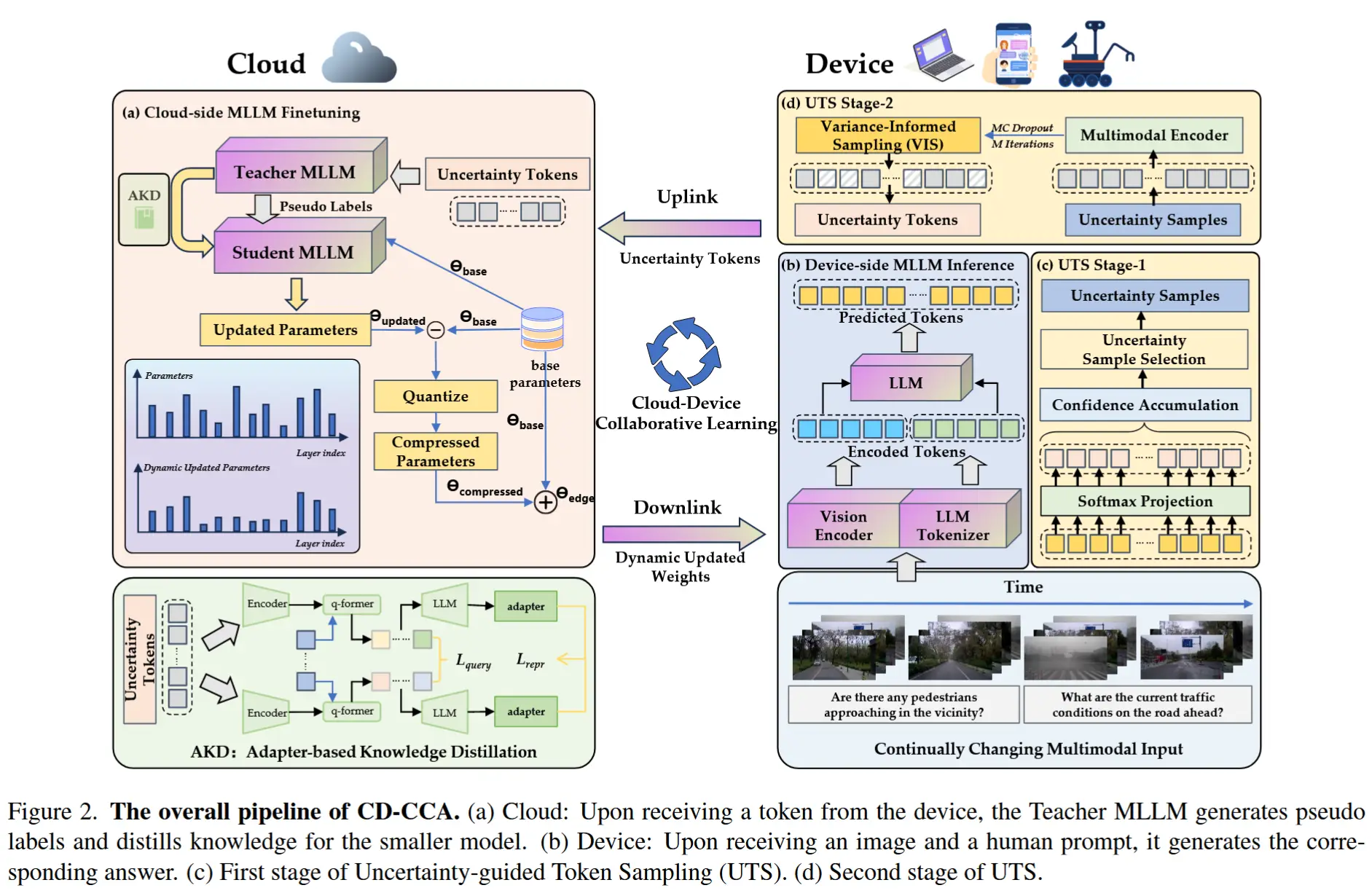
- CD-CCA框架如图2所示
-
该框架可以简洁的概括为以下优化过程:
M' = C( K( U(D,M_{edge}), M^{teacher}_{cloud} ), M^{student}_{cloud} ) \tag{1} -
其中 M′ 表示重新部署在边缘设备上的优化模型,D 表示多模态实例的数据集,U 描绘上行链路效率的 UTS,K 描述云端的 AKD,C 表示下行链路传输的动态权重更新压缩 (DWC)。
-
- 流程
- 首先,该框架采用了一种名为 不确定性引导令牌采样(UTS) 的创新方法,可显著过滤多模态数据的输入流,仅筛选最关键令牌供云端进行优化。(节省带宽+减少上行链路延迟)
- 随后,框架在云端利用 适配器知识蒸馏(AKD) 技术,将庞大教师模型的丰富知识蒸馏并迁移至紧凑的学生模型。(增强学生模型的泛化能力)
- 最后,框架通过 动态权重更新压缩(DWC) 这一创新策略,在下行链路传输前对更新的模型参数进行动态量化与压缩。(缓解模型更新的延迟问题)
2.2 基于不确定性的令牌采样(UTS)
- 核心见解:设备在现实场景中面临数据分布的动态变化,需持续适应的MLLMs必须具备选择性处理能力。通过识别和优先传输对模型适应性最有价值的多模态实例,优化云端协作效率。
- 第一阶段:基于熵的不确定性评估
-
边缘设备上参数为 \theta 的 MLLM,处理一个多模态实例 (v_i, t_i) \in D ,其不确定性U计算方式如下:
U (v_i, t_i; \theta) = − \sum_j p(y_{ij}|v_i, t_i; \theta) \ log p(y_{ij}|v_i, t_i; \theta) \tag{2} -
公式2通过计算预测令牌概率的熵值,量化实例的不确定性。不确定性较高的实例将被标记为需进一步分析的候选。
-
- 第二阶段:方差信息采样(VIS)
-
对第一阶段的预选实例进行二次筛选。
-
VIS 通过在编码后的多模态输入张量上应用蒙特卡洛Dropout,多次前向传播计算令牌表征的方差,识别出表征显著波动的令牌:
\sigma^2(v_i, t_i; \Theta) = \frac{1}{M} \sum_{m=1}^{M} \left( F_m(v_i, t_i; \Theta) - \bar{F}(v_i, t_i; \Theta) \right)^2 \tag{3} -
方差 \sigma_2 超过预定义阈值 \beta 的标记被保留,确保只考虑信息量最大的标记进行云处理,如方程 4 所示:
\tau(\sigma^2(v_i, t_i; \Theta), \beta) = \begin{cases} 1, & \text{if } \sigma^2(v_i, t_i; \Theta) > \beta \\ 0, & \text{otherwise} \end{cases} \tag{4}
-
- 通过这一两阶段策略,UTS显著减少了上行链路传输的数据量,优化带宽使用并降低延迟。其中,VIS通过筛选对模型学习贡献最大的数据点,体现了CD-CCA框架中“精准高效学习”的核心思想。
2.3 基于适配器的知识蒸馏(AKD)
- 核心思想:通过利用云端的算力优势,提升设备端部署MLLMs的性能。在此过程中,高容量教师MLLM与结构相同的学生MLLM在云端共存,通过 适配器 (adapter)实现定向知识迁移。
- 在AKD阶段,我们专注于微调学生模型,使其封装教师模型展现的高层多模态理解能力。
- 具体而言,适配器被用于对 查询表示(query representations) 和 跨注意力输出(cross-attention outputs) 进行微调,这两者是处理和融合多模态信息的核心模块。这些适配器作为定向修正模块,将学生模型的潜在空间与教师模型的精细化特征空间对齐,从而 将教师模型的广泛知识压缩到学生模型的紧凑结构中 。
- 这些适配器 拦截(intercept)并转换查询向量及注意力机制驱动的多模态表征。
蒸馏效果通过复合损失函数量化,包含以下核心组件:
- 查询对齐损失( L_{query} )
最小化学生模型与教师模型查询表示的差异,确保学生生成的查询能有效封装多模态数据的复杂性。
设教师查询特征为 Q^{(t)} \in R^{B×L×C},学生查询特征为 Q^{(s)} \in R^{B×L×C_s},查询对齐模拟 (Query Alignment imitation) 可以通过以下方式实现:
其中,\phi 将学生特征 Q^{(s)} 投影至与教师特征 Q^{(t)} 相同的通道维度。
- 表征对齐损失( L_{repr} )
旨在同步学生和教师模型之间的注意力驱动的多模态表示,增强学生处理和整合多模态线索的能力。
作者这里没有给出表征对齐损失的计算公式
- 交叉熵损失( L_{CE} )
目标 :利用教师模型对UTS筛选的高价值实例(如分布外数据)的输出作为伪标签,校准学生模型的参数更新。
利用教师模型在具有挑战性的多模态实例上的输出,作为伪标签。这些标签用于校准学生模型的参数更新,增强其解决多模态数据中固有复杂性的能力。
作者也没有给出交叉熵的公式,应该就是普通的交叉熵,利用学生模型和教师模型的输出标签做交叉熵。
- 总损失函数( L_{total} )
通过优化上述损失分量的加权和,AKD在模拟教师模型输出与保持学生模型固有特性之间实现了平衡协调。
2.4 动态权重更新压缩(DWC)
- DWC的核心思想
- DWC基于以下前提:高效的模型更新不仅取决于传输数据量,更取决于被更新参数的重要性 。
- 因此,DWC设计了一种量化方案,针对性压缩AKD阶段优化的关键参数,在保证模型性能的前提下最大化传输效率。
- 量化压缩流程
-
云端DWC的量化操作:
\theta_{compressed} = Quantize(\theta_{updated} - \theta_{base}, Q) \tag{7}- Q 是自适应量化函数
-
量化策略
- 重要参数保真 :对AKD阶段显著更新的参数(如跨模态适配器权重)采用低压缩比,保留高精度。
- 非关键参数压缩 :对变化较小的参数(如基础视觉编码器)采用高压缩比,减少传输负载。
-
设备端更新参数:
\theta_{edge} = \theta_{base} + \theta_{compressed} \tag{8}- 设备端模型直接在量化参数空间中运行,无需反量化操作,既节省计算资源,又保留云端蒸馏的优化效果。
-
- DWC 的优点
- 传输效率
- 动态适应性
- 资源友好性
2.5 协作学习策略
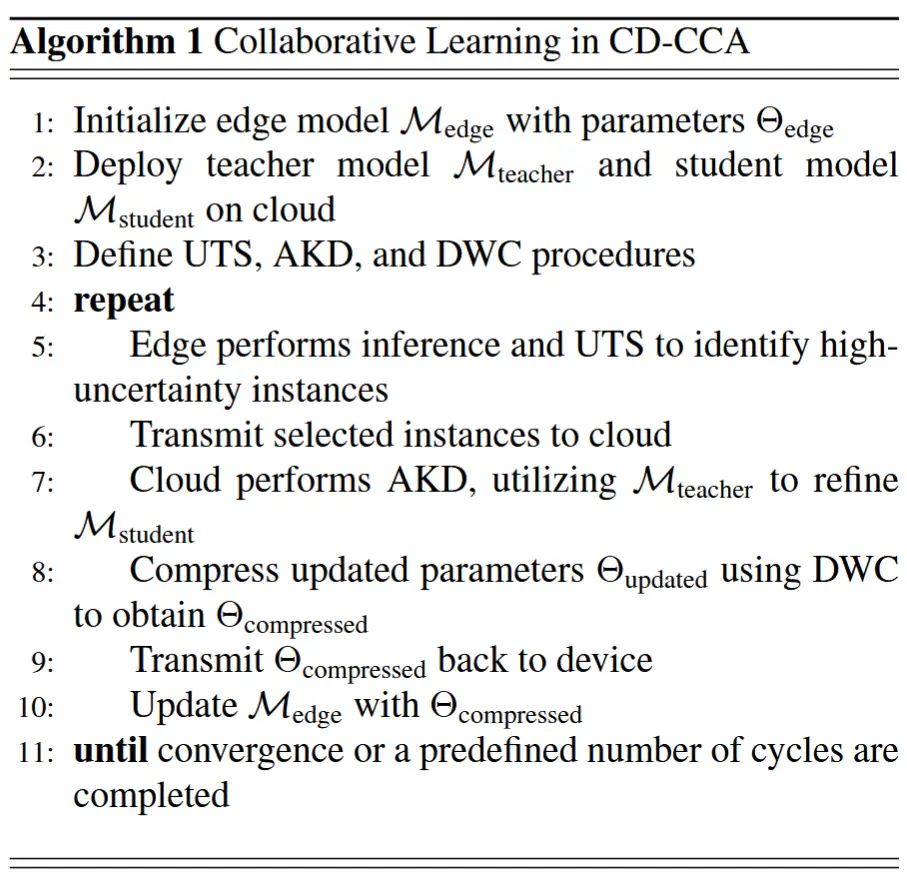
- CD-CCA的核心在于其协作学习策略 ,这是一种协同方法,能够协调云端与设备端之间的模型优化过程,如算法1所示。优化过程围绕两个关键方面展开:
- 边缘设备执行UTS :识别并转发具有挑战性的多模态实例至云端;
- 云端执行AKD和DWC :分别通过知识蒸馏(AKD)优化参数,并通过动态权重压缩(DWC)减少更新体积。
3 实验
3.1 实验设置
-
数据集
- 为验证CD-CCA框架在语言领域偏移(domain-shifted)场景下的持续泛化能力,使用两组数据集。
- VQA任务 :VQA-v2 → A-OKVQA(从标准问答到复杂开放问答)
- 图像描述任务 :COCO Caption 2017 → Nocaps(从常见场景到新领域场景)
-
评估指标
- VQA Accuracy :衡量视觉问答任务的准确性。
- BLeU-4 和 CIDEr :评估图像描述生成任务的质量
- 上行链路和下行链路传输的参数量与数据大小。
- 云-设备传输延迟
-
实现细节
- 模型架构
- 云端教师模型:LLaMA-Adapter + LLaMA2-13B
- 设备端学生模型:LLaMA-Adapter + LLaMA2-7B (Q-former 隐藏层数从12层减少至6层)
- 预训练:教师和学生模型均在大规模图文对数据集上进行预训练,包括COYO、LAION、CC3M、CC12M、SBU。
- 微调:用GPT4提供的52K单轮指令数据和COCO Caption的567K标注数据进行微调。
- 模型架构
3.2 对比分析
3.2.1 VQA 任务
- 对比方法
- Tent [4] :通过最小化熵更新BatchNorm层的可训练参数以适应测试数据。
- CoTTA [5] :利用权重平均和数据增强平均预测减少伪标签误差累积,并通过随机恢复(stochastically restore)缓解灾难性遗忘问题。
- PKD [42] :基于皮尔逊相关系数进行特征模仿,放松对特征大小的约束,专注于教师模型的关系信息传递。
- ChannelWiseDivergence [43] :归一化每个通道的激活图,生成软概率图,并最小化两个网络间的KL散度(Kullback-Leibler divergence)。
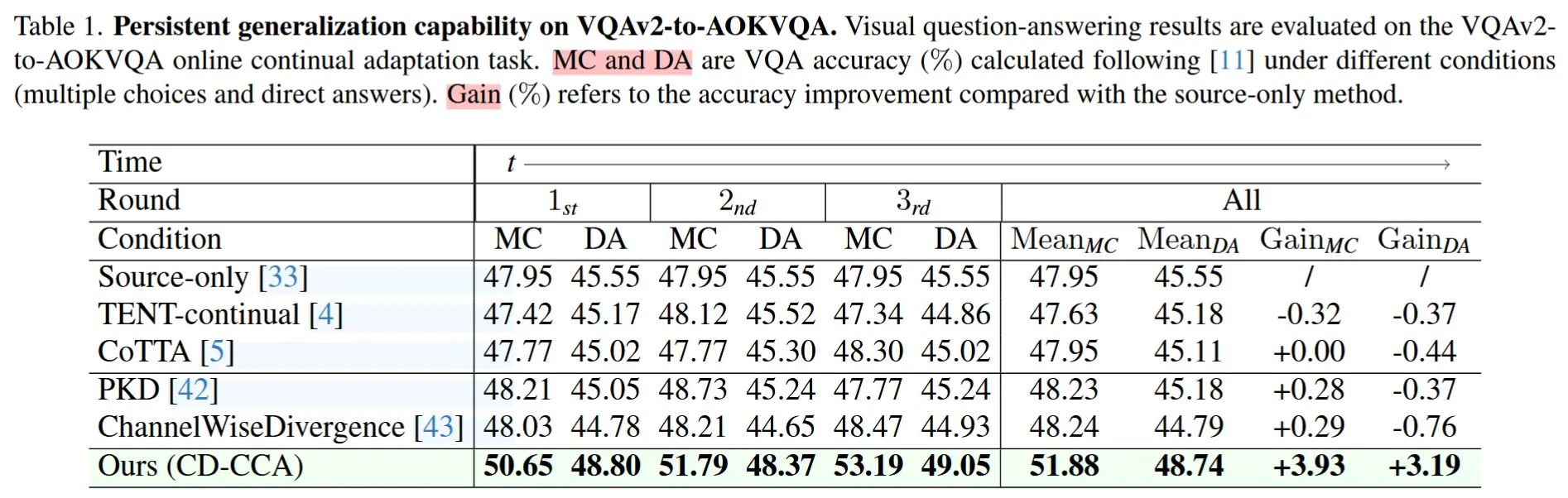
- VQA-v2 → A-OKVQA
- 实验方法:使用VQA-v2微调预训练的模型,再再A-OKVQA上评估VQA准确性,包含多选题MC和直接回答DA。
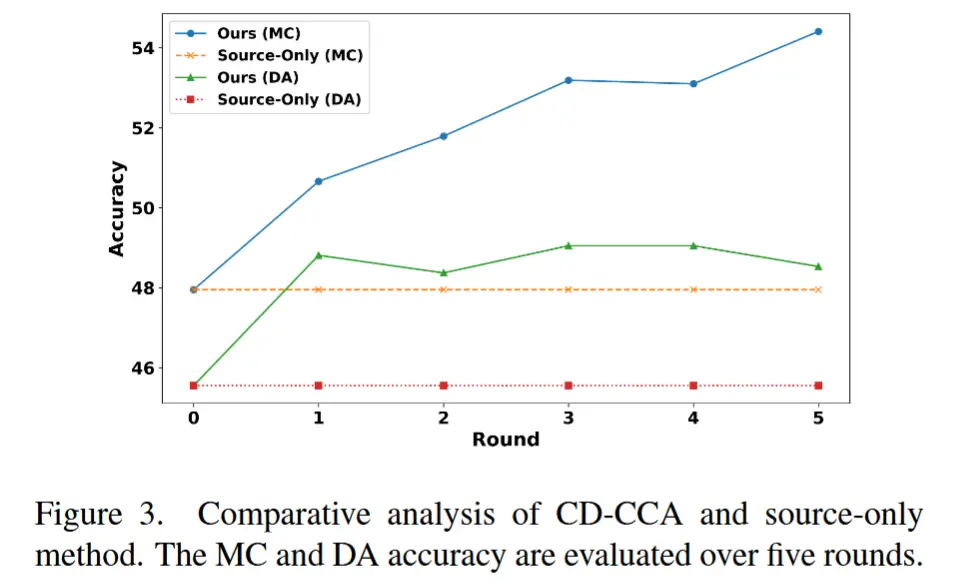
- 实验结果表1和图3。
- 结果分析:CD-CCA框架在单轮场景下已超越所有对比模型,在MC和DA问题上均达到最高准确率。
3.2.2 图像描述任务
-
数据预处理:根据训练集和测试集图像类别的重叠程度,按照参考文献[13]的方法,将测试图像分为三类:
- In-domain(领域内) :测试图像类别与训练集完全重叠。
- Near-domain(近领域) :测试图像类别部分与训练集重叠。
- Out-domain(领域外) :测试图像类别与训练集无重叠。
-
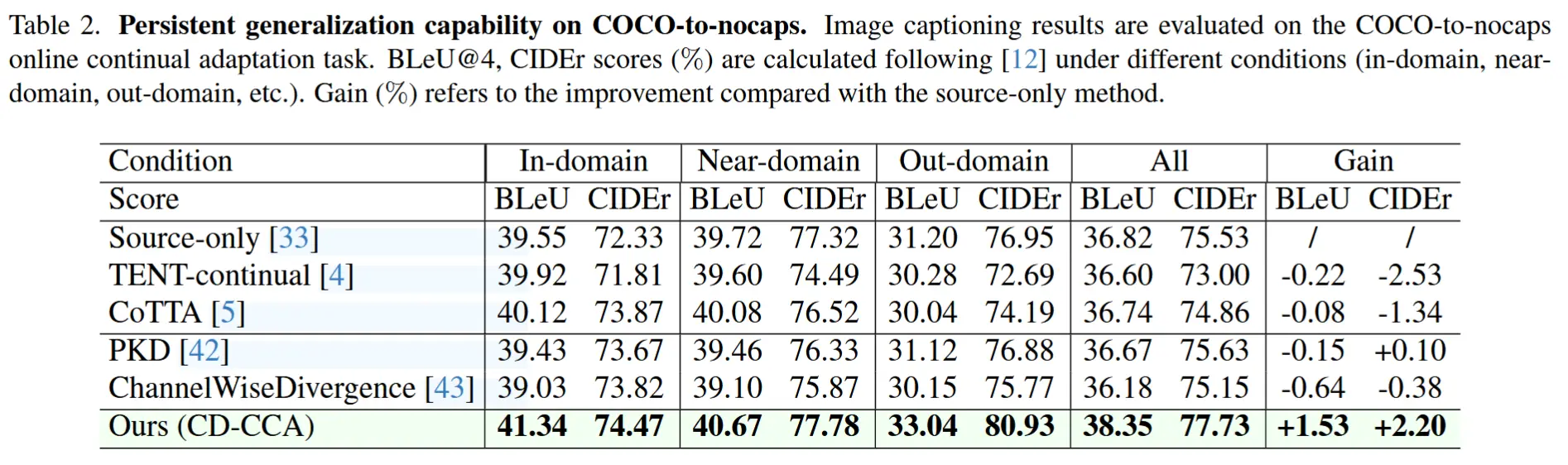
COCO -> nocaps
- 结果记录在表2中。
- CD-CCA框架在所有类别中均显著优于最佳对比方法,并且CD-CCA在Out-domain任务中的提升尤为突出,体现了其强大的泛化能力。
3.3 消融实验
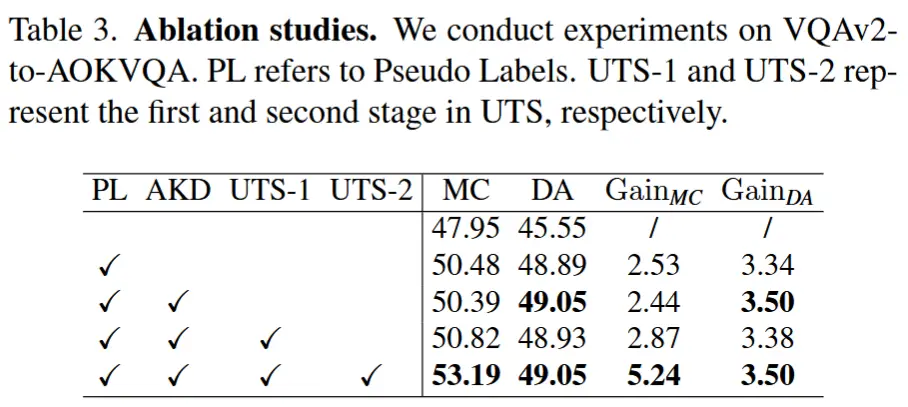
- 表3
- 在 VQAv2-to-AOKVQA 上进行实验。PL 是指伪标签,UTS-1 和 UTS-2 分别代表 UTS 的两个阶段。
- 结果表明 UTS 的两个个阶段、AKD 都有助于提高模型的性能。
伪标签(PL) 是指使用教师模型生成的预测结果作为学生模型的训练标签。
- 表4
- 使用不同的token采样策略和不同的掩码比率报告 VQA 分数。
- 当掩码比率设置为 50% 时,模型的性能最佳。
- 表5
- 在真机中验证传输参数。报告了对真实机器人系统中双向传输参数大小 (P) 、传输数据量 (D) 和传输延迟 (TL) 的定量分析。上行链路参数是使用 5 帧输入计算的。
- 与传输整个数据集相比,Uplink-UTS 传输数据量仅为 0.21%,传输延迟仅为 0.20%。
- Downdlink-DWC显著降低了传输到设备的模型的权重参数数量、数据数量和传输延迟,分别降低了 99.98%、99.99% 和 99.98%。(使用QLora作为量化函数)
4 结论
这种提出了 CD-CCA 来增强动态环境中的设备模型。开放世界场景中的实验结果表明,在领域偏移描述和 VQA 任务中,性能提高了 2.20% (CIDEr) 和 3.93% (MC)、3.19% (DA)。此外,实际实验表明,CD-CCA 的系统延迟能够支持实际应用。