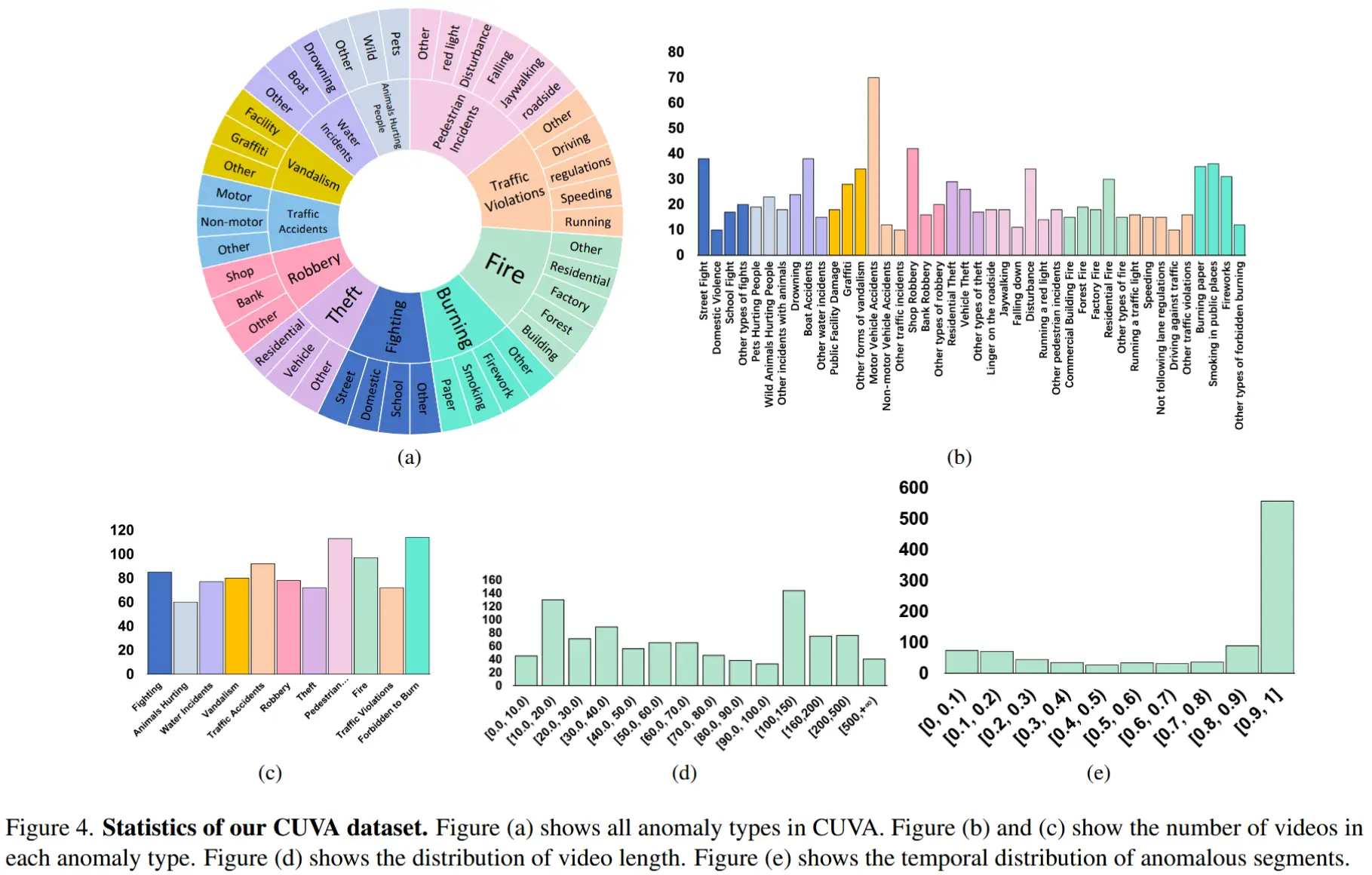
- 论文 - 《Video Anomaly Detection and Explanation via Large Language Models》
- 代码 - Github
- 关键词 - 弱监督视频异常学习WSVAD、大模型、视频大模型VLLM、微调、指令微调
1 引言
- 动机:基于异常评分的方法多年来占据主流地位,但存在以下问题:
- 阈值设定复杂:在面对多样化的视频内容和异常事件时,如何确定最优的阈值并不直观。
- 检测结果解释性差的问题:仅异常评分无法为用户提供足够的信息去理解上下文或确认异常背后的原因。
- 目标:自动化(即无需手动设定阈值)和可解释性(即能够解释为何某个事件被认为是异常的)。
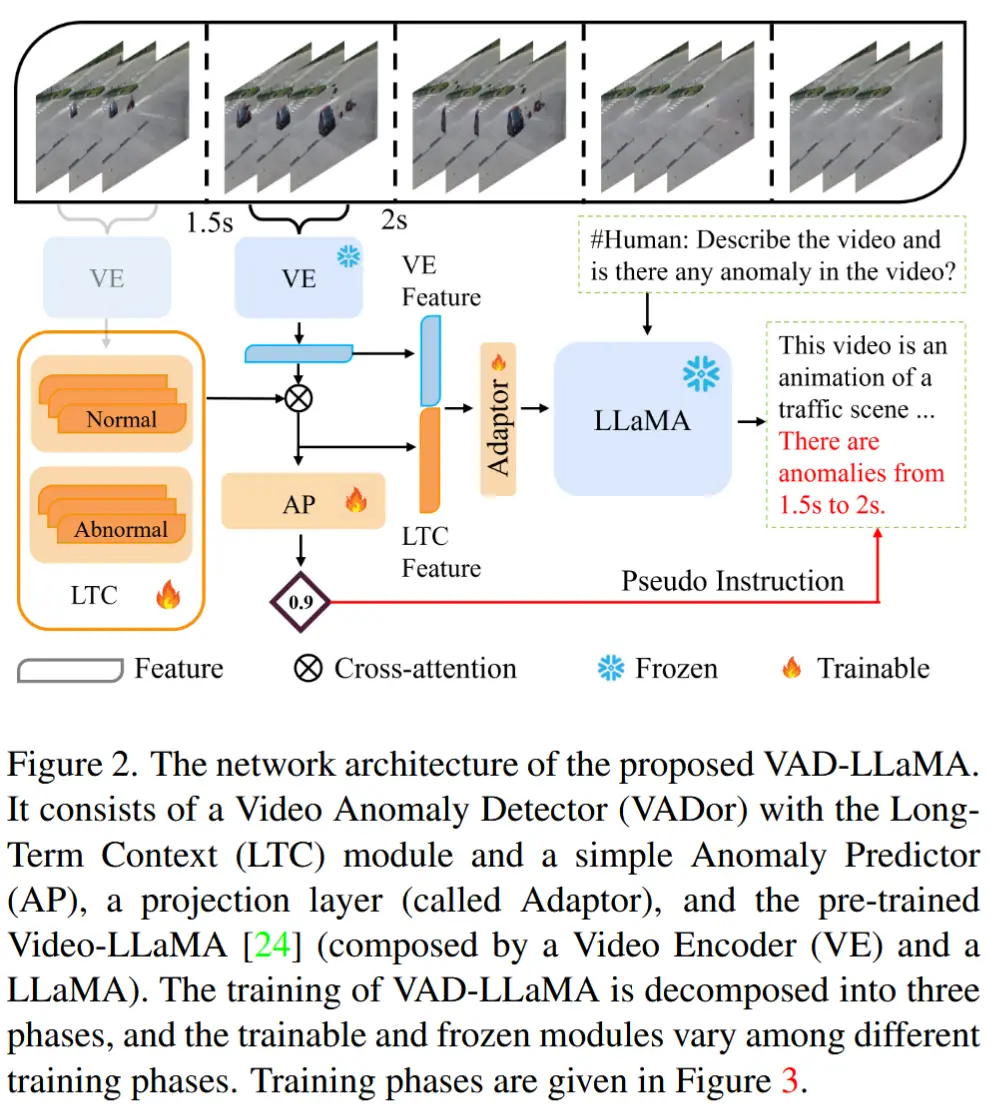
- 本文方法 - VAD-LLaMA
- 首次探索将基于视频的大型语言模型(VLLMs)引入VAD框架中。
- 由于 VLLM 对异常的理解和人类存在差异。因此,作者提出了视频异常检测器(Video Anomaly Detector,VADor),该检测器集成了来自Video-LLaMA 的模块。
- VADor 和 VLLM 协同训练的挑战:
- 1)目前开源的VLLMs缺乏对长时序上下文建模的能力。它们大多是基于短视频和简单场景进行训练的,而VAD任务中的视频具有高度复杂的上下文信息。
- 2)VAD数据及其标注的稀缺性。广泛使用的VAD数据集UCF-Crime [18] 是弱监督设置下的数据集,它仅提供视频级别的异常标签。
- 解决办法:
- 针对挑战1):在 VADor 中引入了一个新的长期上下文模块(Long-Term Context, LTC)。其核心思想是将视频的长期正常/异常上下文信息融合到视频表示中。
- 针对挑战2):提出了一种三阶段训练方法。
2 方法
本文方法旨在将预训练的大型视频-语言模型 Video-LLaMA 的通用视频表示能力迁移到 VAD 任务中。
2.1 模型架构
概述
如图2所示,VAD-LLaMA 由以下模块构成:
- VADor(LTC、两个全连接组成的异常预测器AP g)
- Video-LLaMA(视频编码器VE、LLaMA)
- Adapter f
视频编码器 VE
流程:
- 将一个视频序列划分为 m 个 segments。
- 对于每个 segments,随机采样一个视频 clip(连续帧),并输入到预训练的 VE 中提取特征。将第 i 个 clip 的 VE 特征表示为 \mathbf{x}_i, i \in \{1, \dots, m\} 。
VE 来自预训练好的 Video-LLaMA,由一个图像编码器(BLIP-2)和 Video-Qformer 组成。
长期上下文 LTC
LTC 模块被提出以解决“VE 特征缺乏长期上下文信息”问题。
具体解释:
- 收集具有最低(最高)异常分数的片段级别的 VE 特征,并将它们堆叠到一个正常(异常)列表中。正常列表表示为 \mathbf{N} = \{\mathbf{n}_j\}_{j=1}^K ,异常列表表示为 \mathbf{A} = \{\mathbf{A}_j\}_{j=1}^K 。(列表在线更新)
- 在 LTC 模块中引入了交叉注意力机制,用于将两个列表的信息整合到 VE 特征中。
- LTC 模块的输出特征不仅作为 AP 的输入,还与 VE 特征堆叠,用作 LLaMA 的 visual prompts。
特征适配器
在 VAD-LLaMA 中,添加了一个Adapter f (一个全连接层),用于将 visual prompts 转换为与 LLaMA 输入相同的维度,并对齐视觉特征分布与预训练的 LLaMA。
LLaMA
采用了版本为 vicuna-7b 的 LLaMA,并且基于指令微调LLM [1]。
2.2 模型训练
VAD-LLaMA 的训练流程如图3所示,采用三阶段方法进行训练:
- 阶段一:训练异常预测器 VADor,clip-level的 VE 特征输入到 VADor 中,建立预测初始异常分数的基线。
- 阶段二:联合训练 LTC 模块与VADor,将长期上下文信息融入表征学习和异常检测的过程中。
- 阶段三:指令调整 Adapter。通过 VADor 和 LTC 模块共同确定的改进后的异常分数被转换为伪指令。这些伪指令随后与简单的文本模板结合,作为 LLaMA 的指令微调数据。
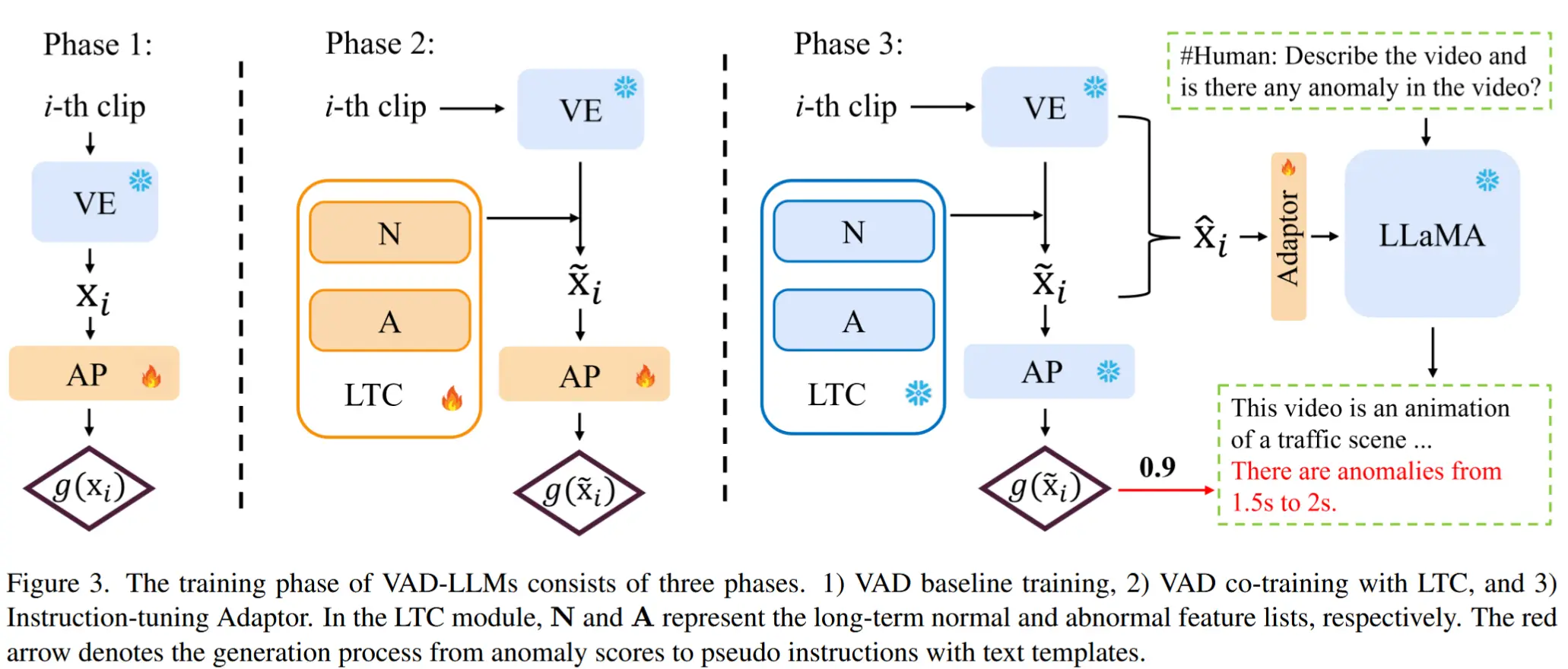
阶段1:训练 VADor
目的:这一阶段,通过直接将 VE 特征传递给异常预测函数 g 来训练一个简单的 VADor 基线模型。
思路:弱监督视频异常检测(WSVAD)设置下,使用多实例学习(MIL)实现。
具体解释:构建了一个元组集合 \mathcal{S} ,每个视频对应一个元组,其中包含由 g 在最异常片段上生成的预测值 y' 和对应的视频级别标签 y 。这个元组表示为 (y', y) ,其中 y' 被计算为 \max\{g(x_i)\}_{i=1}^m 。函数 g 的参数通过最小化二元交叉熵(BCE)损失进行训练:
由于大部分数据集只有视频级别的标签,因此 MIL 选择识别每个视频中异常分数最高的片段。通过BCE损失,对于正常视频,最小化 \max\{g(x_i)\}_{i=1}^m ;对于异常视频,最大化 \max\{g(x_i)\}_{i=1}^m 。
阶段2:联合训练 VADor 和 LTC
目的:增强 VADor 的长期视频表示能力。
思路:将其与一个新颖的 LTC 模块 联合训练。
具体解释:
-
建立列表并在线更新:在前向传播过程中,基于 VADor 基线预测的初步异常分数,选择具有前 K 个最低/最高分数的 VE 特征作为正常/异常列表( \mathbf{N} / \mathbf{A} )的元素。此外,当将新的视频片段输入 LTC 模块时,列表在线更新。
-
交叉注意力检索相似特征:为了将这些特征融入新视频片段的表示,引入交叉注意力机制,自动根据当前 VE 特征的相关性从 LTC 列表中检索上下文特征。具体而言,将当前的 VE 特征 \mathbf{x}_i 视为 Query,同时将堆叠在 LTC 列表 \mathbf{N} 和 \mathbf{A} 中的特征用作 Key 和 Value。以第 i 个 VE 特征为例,该过程如下:
(\mathbf{x}_i \times \mathbf{X}^\top) \times \mathbf{X}, \, \mathbf{X} \in \{\mathbf{N}, \mathbf{A}\}, \tag{2}分别将从公式 (2) 得到的注意力权重记为 \mathbf{n}_i 和 \mathbf{a}_i ,其中 \times 表示点积。
-
加权结合特征:然后根据这些权重检索相关特征,即特征相似度越高,注意力权重越高。再将这些特征与 VE 特征 \mathbf{x}_i 结合:
\tilde{\mathbf{x}}_i = \mathbf{x}_i + w_n \mathbf{n}_i + w_a \mathbf{a}_i, \tag{3}为了避免手动调整超参数,引入带有参数 w_n, w_a \in W 的神经软权重,自动平衡特征。
-
预测异常分数:经过交叉注意力处理后的特征被输入到异常预测函数AP。
-
BCE 损失联合训练:VADor 和 LTC 模块通过 BCE 损失(公式 (1) )进行联合训练和监督。
长短期上下文(LSTC)模块:为了进一步整合涉及事件变化的短期历史信息,作者添加了一个列表来存储过去的 K 个 VE 特征,表示为 \mathbf{H} = \{\mathbf{h}_j\}_{j=1}^K 。此时,LTC 模块升级为增强版,即 LSTC 模块。大量的实验表明,配备 LTC 和 LSTC 模块的 VADor 具有良好的效果。
阶段3:指令微调适配器
思路:添加一个 Adapter 将 VADor 与 Video-LLaMA 结合起来。并且由于训练数据有限,冻结其他模块,仅训练 Adapter 以实现对齐。
异常提示
动机:为了无缝地将视频表示和异常信息融入 LLaMA。
解决办法:利用 LTC 特征 \tilde{\mathbf{x}}_i 作为 异常提示,如图2所示,异常提示与 VE 特征堆叠在一起,形成 [\mathbf{x}_i, \tilde{\mathbf{x}}_i] 。然后,经过 Adapter f 投影。输出的特征嵌入 f(\tilde{\mathbf{x}}_i) 作为片段级别的软视觉提示,引导预训练的 LLaMA 根据视频片段的视觉内容和异常状态生成文本。
伪指令
动机:在 WSVAD 中没有帧级异常标注,直观上难以构建针对 LLaMA 的时间指令。
解决办法:作者提出将 VADor 输出的异常分数转换为伪指令,并手动组合与异常相关的文本模板来生成指令微调数据。
以下是微调指令数据的一个示例:
Question:
### Human: <Video> [Video Tokens] </video> [Video Description] Is there any anomaly in the video?
Answer:
### Assistant: Yes, there are anomalies from 1.5s to 2s.
其中:
[Video Tokens]表示视觉提示,即 \{\tilde{\mathbf{x}}_i\}_{i=1}^m 。[Video Description]是简单的视频片段细节,例如视频长度和帧采样率。- Answer 是根据 VADor 预测的异常分数转换而来的,例如图3中最高异常分 0.9 对应片段“1.5s to 2s”。
因此,对于第 i 个视频片段,视频指令对变为 (\hat{y}', \hat{y}) ,其中 \hat{y}' = [f(\tilde{\mathbf{x}}_i), Q] 表示 LLaMA 的输入,而 \hat{y} 表示从伪指令转换得到的文本嵌入。
简单来说,原本作者只有异常分最高的片段,但是没有指令微调数据。作者使用这种定式的转换,利用最高异常分数对 (y', y) 得到了微调指令对 (\hat{y}', \hat{y}) 。
为了避免在 VAD 视频上过拟合,引入了一个多样化的训练样本集 \mathcal{P} (UCF-Crime、WebVid)。
指令微调训练
最后,使用交叉熵损失训练适配器。交叉熵损失的公式如下:
其中, n 是 \hat{y} 中嵌入标记的数量, \hat{y}_j 是标记 j 的真实标签,而 \text{LLaMA}(\hat{y}')_j 是 LLaMA 对标记 j 的预测概率。
3 实验
3.1 实验设定
- 两个标准的弱监督VAD数据集:UCF-Crime和TAD(仅使用视频模态)
- 评估指标
- ROC AUC
- 面向整个测试集的 AUC_O;仅面向异常视频的 AUC_A
- 所有实验均在 4 块 Nvidia L40 GPU 上进行。
3.2 主要结果
- 弱监督 VAD
- 结果如表1、2所示
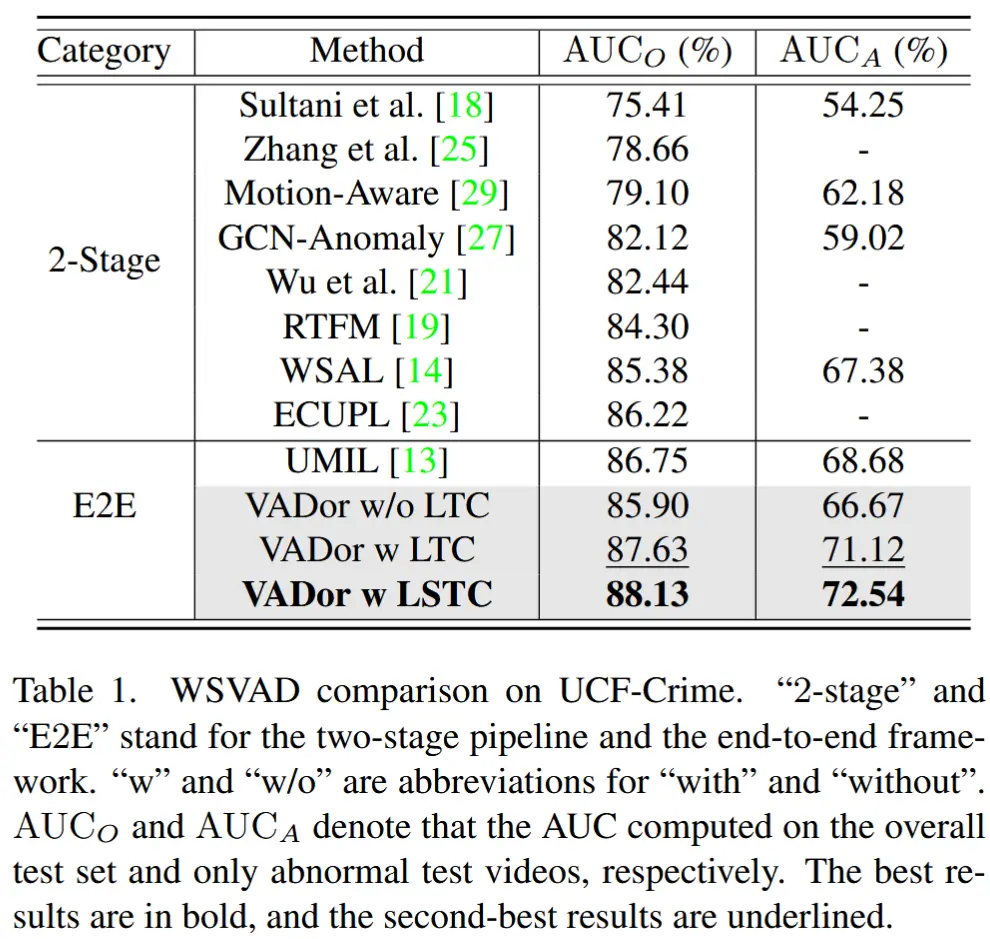
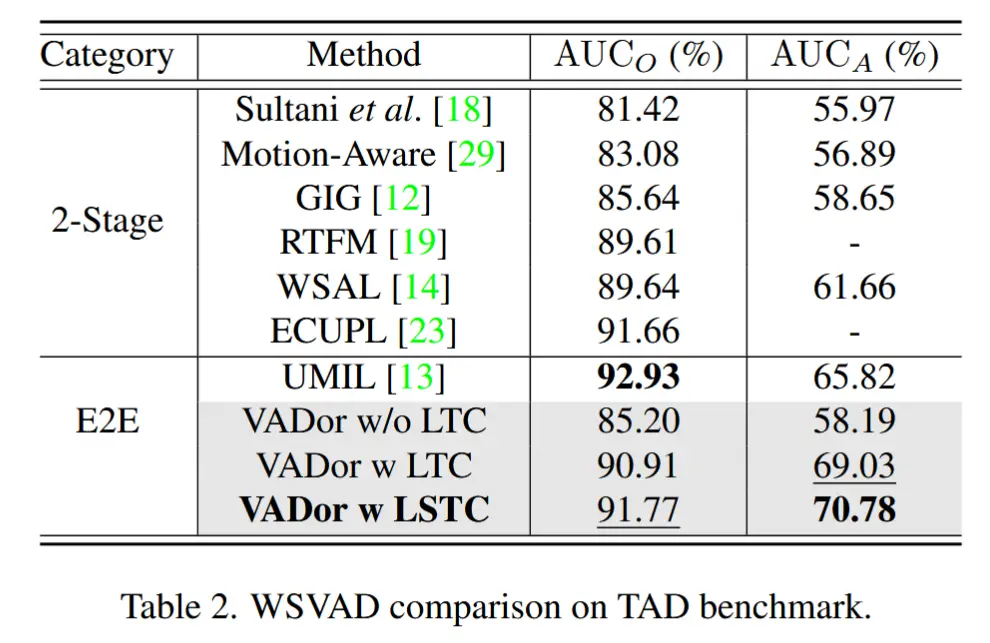
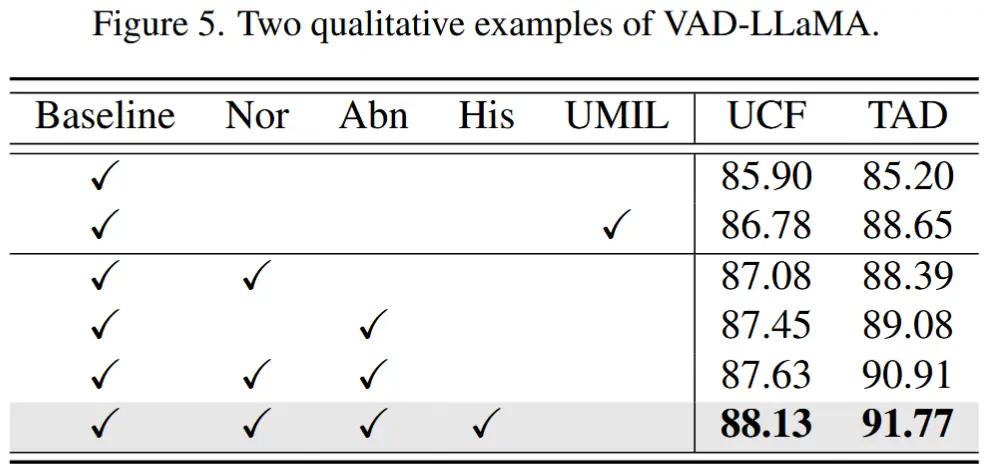
- 消融实验 - LTC 组件
- 结果如表3所示,“Nor”和“Abn”分别表示正常和异常列表。“His”代表短期历史列表。
- 挺理想的消融结果,性能逐步增加。
- 消融实验 - LTC 长度
- 结果如表4所示,K 表示特征列表的长度。
- 通常,K 的选择取决于异常检测对视频上下文的依赖程度。