- 论文 - 《Uncovering What, Why and How: A Comprehensive Benchmark for Causation Understanding of Video Anomaly》
- 代码 - Github
- 关键词 - 新基准、新评估指标、因果推理、异常可解释性、视频异常检测VAD、视频异常理解VAA、prompt
1 引言
- 动机:现有的视频异常理解(VAU)方法核数据集主要集中在上述的异常检测与定位任务上,而对这些异常事件背后的原因及其所产生的影响的研究仍相对匮乏。
- 举例:如图 1 所示,一辆白色车停在路边,随后一辆深灰色汽车编导撞上了一辆黑色汽车。要理解该事故的原因,模型需要解决以下问题:
- 捕捉长视频中的关键线索:模型需要在 Frame B 识别出白色汽车,而这距离事故发生的 Frame D 相隔 7 秒。因此模型必须具备捕捉长时序依赖关系的能力。
- 建立因果逻辑链:模型还需进一步学习视频中不同片段之间的丰富交互关系,,从而构建起异常事件的因果链条,以支持后续的解释生成和结果推断。

- 面对更具实际意义的真实场景,当前数据集存在的局限性:
- 缺乏对原因与影响的解释:现有的标注信息未提供对潜在原因、事件影响以及目标异常类型的详细描述;
- 缺乏合适的评估指标:现有的文本生成相关的评价指标(BLEU 和 ROUGE) 被用于衡量基于文本的解释或描述质量,但它们仅适用于纯文本模态,无法直接应用于多模态的 VAU 任务;
- 视频长度有限:目前大多数 VAU 数据集中的样本视频长度通常不足30秒,不足以应对现实世界中的挑战。
- 针对上述局限性,本文的贡献如下:
- 构建了一个面向视频异常因果理解的综合基准——CUVA。具体而言,作者人工撰写了详尽的自由文本,以描述异常事件的起因、结果、事件描述及其之间的关系。数据集聚焦三个关键问题:“发生了什么异常?”、“为什么会发生?”以及“该异常的严重程度如何?”
- 还提出了一种新的评估指标 MMEval,旨在更好地与人类判断对齐,用于衡量现有 LLMs 在理解视频异常因果关系方面的能力。
- 设计了一种 prompt-based 的新方法,结合视频大语言模型(VLM)来捕捉关键线索并构建因果逻辑链。
2 CUVA 基准
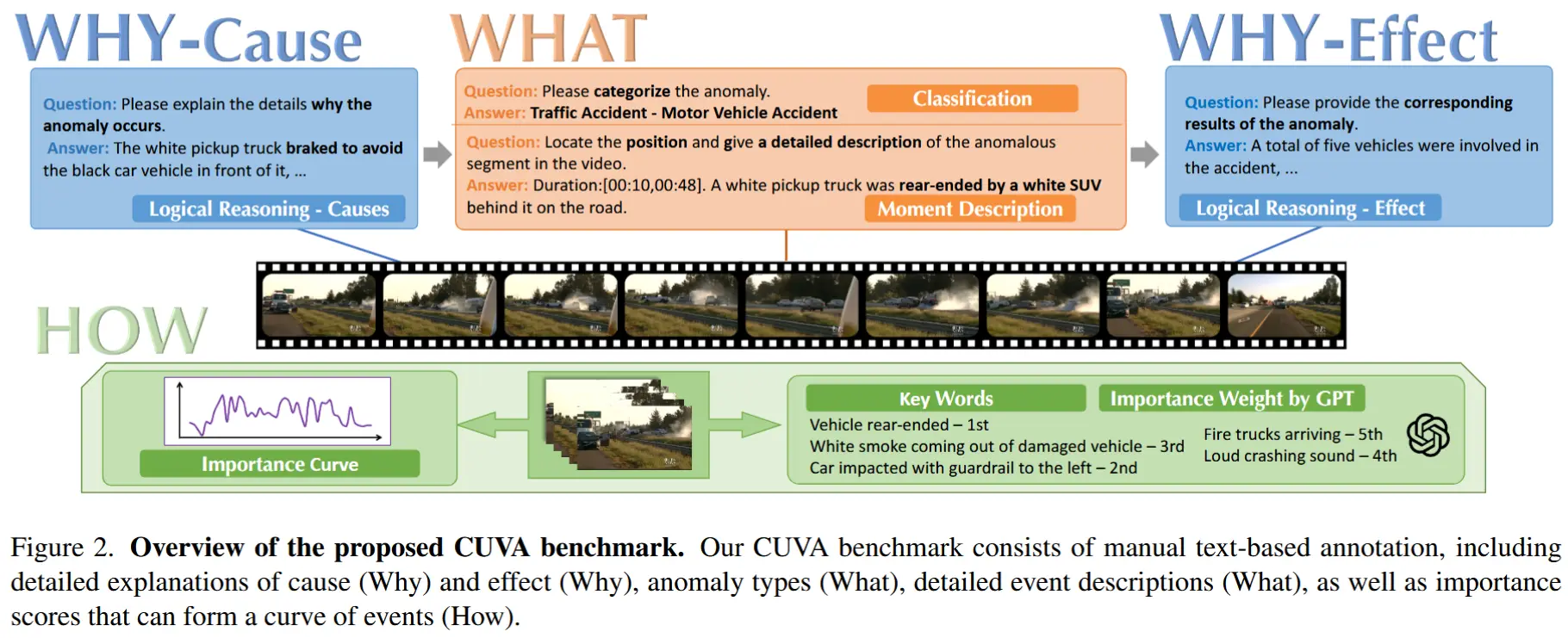
CUVA 的整体结构如图2所示。
2.1 任务定义
如前所述,CUVA 聚焦于三个问题。
- 发生了什么异常?
该任务包括两个目标:
- 异常分类:涵盖视频中存在的所有异常类别。每段视频可能包含多个不同层级的异常类别,考验模型在多粒度级别上识别异常类别的能力。
- 异常时刻描述:包括异常发生的时间戳以及对该异常事件的详细描述。
- 为何会发生此异常?
该任务旨在描述视频中的因果关系。
- 异常推理:描述视频中异常发生的根本原因,考验模型的视频理解与推理能力。
- 异常结果:描述视频中异常事件所带来的影响,测试模型处理视频中异常事件细节的能力。
- 该异常有多严重?
该任务旨在反映视频中异常严重程度的变化趋势。为此,我们提出了一种新颖的标注方法,称为重要性曲线。重要性曲线的具体构建流程如图3所示。

2.2 数据集收集
作者从主流视频平台(如 Bilibili 和 YouTube)爬取了大量视频数据,并剔除了不合适的视频。进行分析后,确定了11个主要类别,此外还对每个主类别进行了进一步细分。
2.3 标注流程
数据集构建流程包含三个阶段:预处理、人工标注和重要性曲线处理。
- 预处理
- 从 Bilibili 和 YouTube 上爬取视频内容。
- 手动对所收集的视频进行剪辑,以确保视频内容的质量,并通过人工筛选排除非伦理内容和敏感信息。
- 最终共获得1,000段异常视频片段。
- 人工标注
- 根据设计好的标注文档,使用英文对视频进行标注,标注工作分为两个轮次进行。
- 重要性曲线后处理
- 初始生成的重要性曲线可能无法准确反映异常发生的时间段。
- 因此,我们结合以下三项任务对重要性曲线进行优化:视频描述生成、视频蕴含判断和视频定位。
- 采用投票机制来精确识别出与给定关键语句相对应的视频时间段。
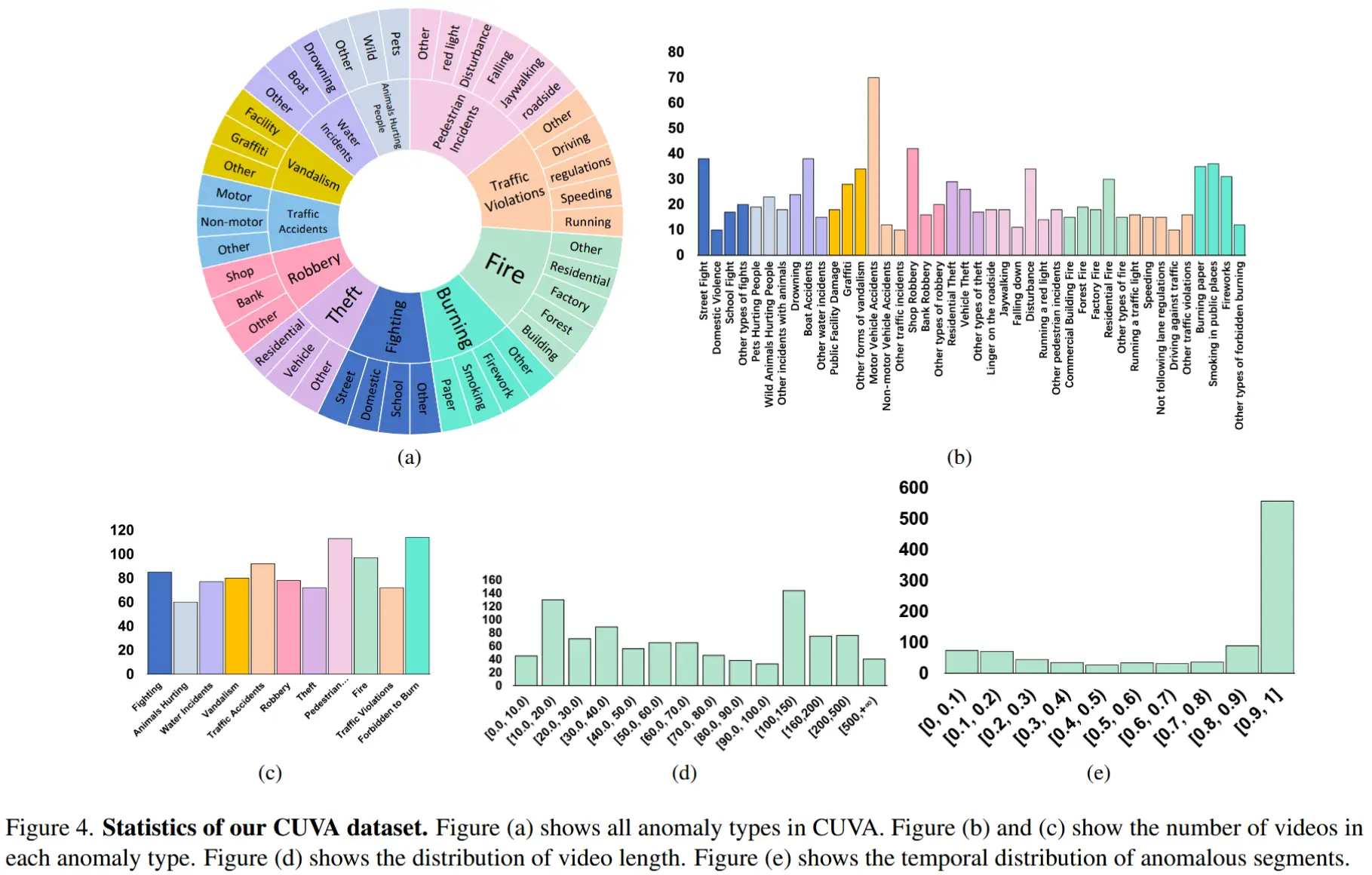
2.4 数据集统计
统计结果如图4所示
- 包含1,000段视频片段和6,000组问答对。
- 总视频时长为32.46小时,平均每段视频包含3,345帧图像,帧图像以每秒60帧(FPS)的速度从原始视频中提取。
- 将异常事件划分为11种场景,共计42种不同类型的异常。
- (a)展示异常种类;(b)和(c)展示异常种类分布情况;(d)展示视频长度分布;(e)展示各视频异常事件占比分布。
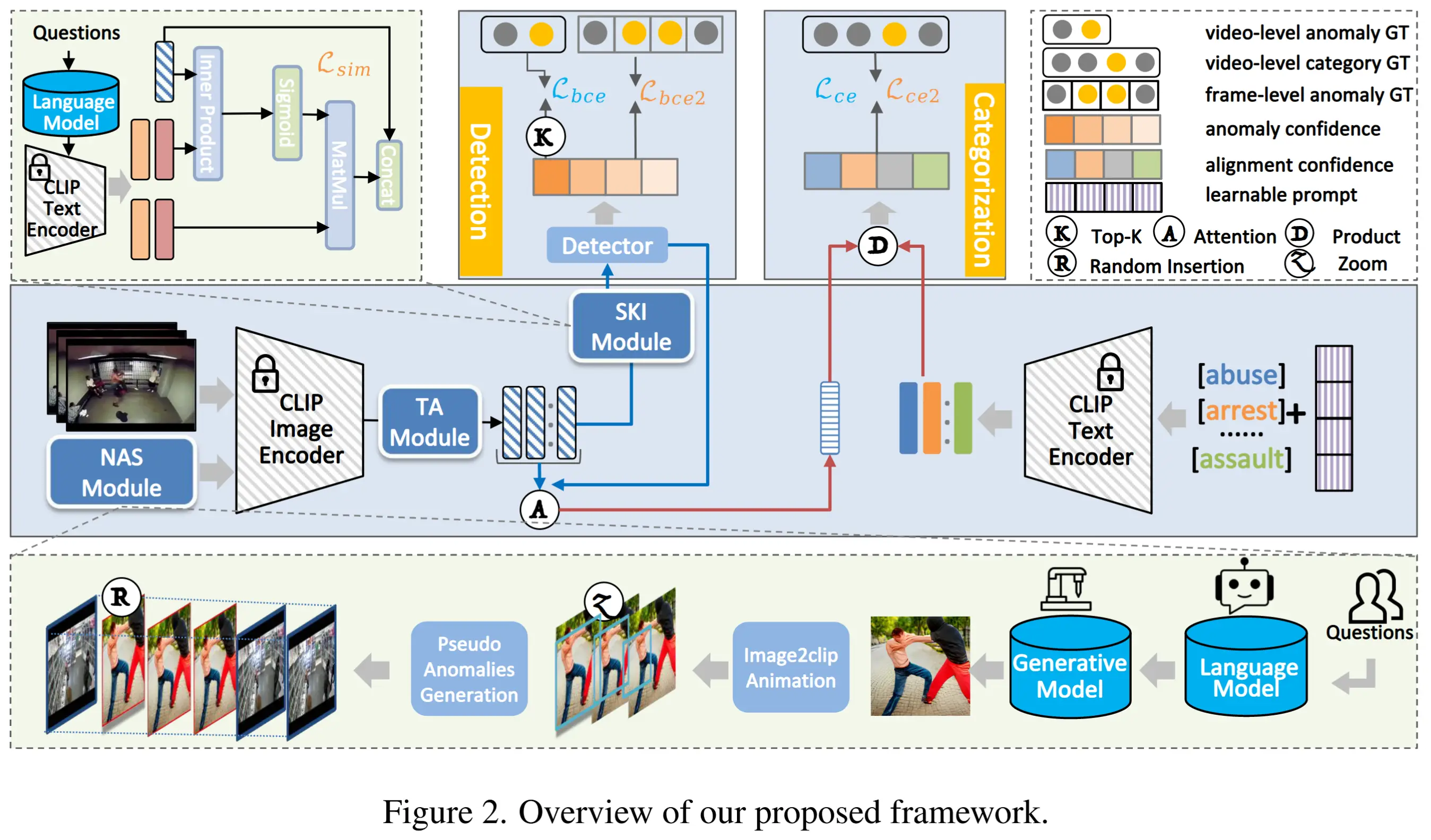
3 方法:Anomaly Guardian
本节介绍一种新颖的 prompt-based 的方法,命名为 Anomaly Guardian。借助视频大语言模型(VLM)出色的逻辑推理能力,我们将其作为本方法的基础,用于构建异常事件的因果逻辑链条。
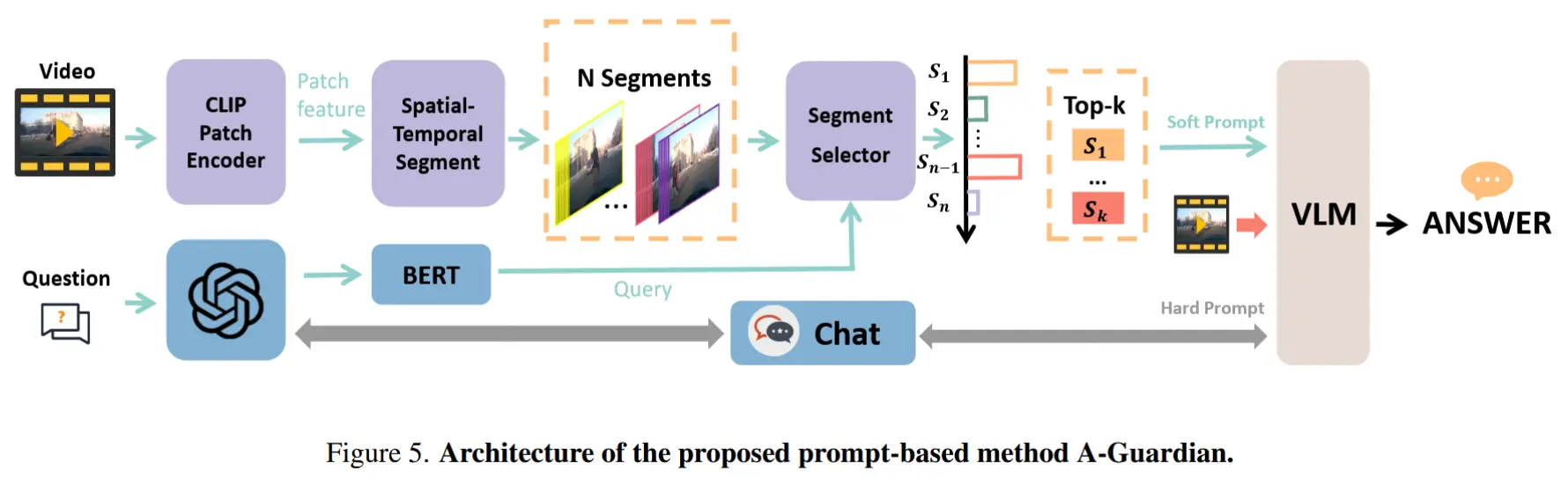
3.1 Hard Prompt 设计
关键点:
- 使用一个包含示例的指令提示,借助 ChatGPT 来协助确认和补充用户提示,从而帮助 VLM 更好地理解用户的意图。
- 由于长视频中存在大量事件,采用 多轮对话机制 来辅助 VLM 识别与异常发生更相关的视频事件,从而提供更加准确的回答。
3.2 Soft Prompt 设计
基本思想:利用 MIST [17] 中的选择器(selector) 来更好地捕捉与 ChatGPT 处理的问题相关的时空特征。
步骤:
-
划分视频和块:将视频均匀划分为 N 段,每段包含 T 帧。为了更好地捕捉不同粒度视觉概念之间的交互,将每一帧进一步划分为 M 个 patches。
-
提取特征:使用带有冻结参数的 CLIP 提取块级别的特征,表示为 \mathbf{P} = \{p^1, p^2, \dots, p^m\},其中 p^m \in \mathbb{R}^{T \times M \times D},且 D 是每个块级别特征的维度。
-
块特征池化:对块特征的空间维度进行池化操作以获得帧特征。
f_{kt} = \text{Pooling}(p_{kt,1}, p_{kt,2}, \dots, p_{kt,M}) \tag{1}其中,p_{kt,m} 表示第 k 段第 t 帧中的第 m 个块。
-
帧特征池化:沿时间维度对帧特征进行池化操作,得到段特征,其中 f_{kt} \in \mathbb{R}^{T \times D}:
s_k = \text{Pooling}(f_{k1}, f_{k2}, \dots, f_{kT}) \tag{2} -
问题特征池化:问题特征是通过对词特征进行池化操作获得的,其中 w_z \in \mathbb{R}^{Z \times D},且 q \in \mathbb{R}^{D}:
q = \text{Pooling}(w_1, \dots, w_Z) \tag{3} -
选择块特征:使用跨模态时间注意力和 MIST 中的 top-k 选择方法,从视频片段中选取前 k 个块特征,其公式如下。
\mathbf{X}_t = \text{selector}_{Top_k}\left(\text{softmax}\left(\frac{q \cdot \mathbf{s}^T}{\sqrt{d_k}}\right), \mathbf{S}\right) \tag{4}
3.3 答案预测
最后,将 hard prompts 与 soft prompts 进行拼接,并输入到视频大语言模型(VLM)中进行推理。在训练阶段,使用 GPT 生成候选答案并对数据进行增强处理。仅对 selector 进行微调,通过优化 softmax 交叉熵损失函数,使预测的相似度得分与真实标签保持一致。
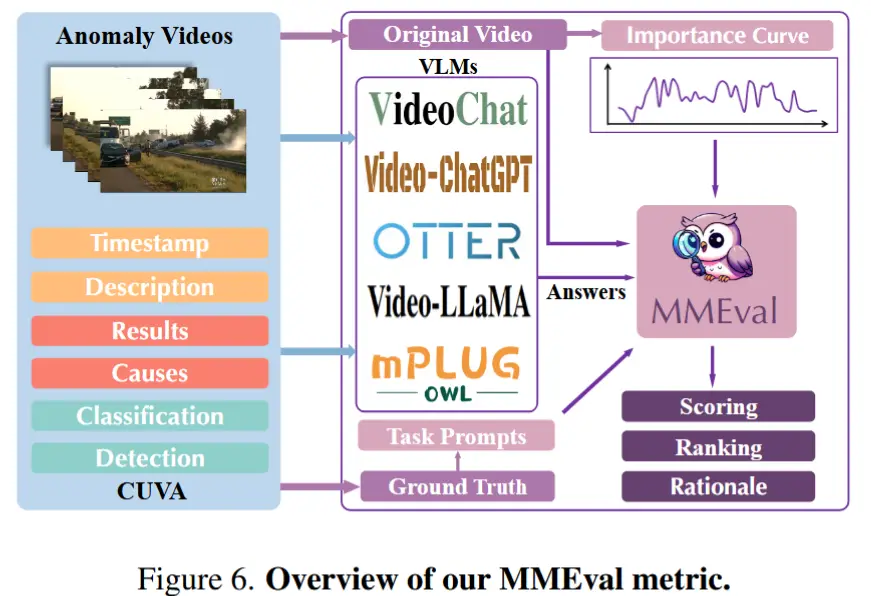
4 MMEval 指标
动机:CUVA 是一个多模态数据集(融合了视频、文本和附加评论),这就要求评估不能仅仅依赖于自然语言生成类指标,而应更全面地考虑多模态输入信息。
因此,作者提出了一种新的评估指标——MMEval,如图6所示。
具体解释 MMEval:
- 使用基础模型:选择 Video-ChatGPT ,并通过自然语言提示引导 MMEval 明确待评估的任务类型。
- 设计了三个自然语言提示:即2.1节中的三个问题“发生了什么异常?”...
- 利用曲线标签增强鲁棒性:通过设置阈值,从曲线中提取出异常事件的关键时间段。在这些关键时间段内进行密集采样,从而引导 VLM 更加关注视频中的异常片段。
- MMEval 指标可用于打分、排序,并提供基于自然语言的解释理由。
5 实验
5.1 实现细节
- 采用 CLIP-L/14 视觉编码器提取视频的空间与时间特征。
- 使用包含70亿参数的 Vicuna-v1.1 模型,并以 LLaVA 的权重对其进行初始化。
- 所有实验均在四块 NVIDIA A40 GPU 上运行,每项任务大约耗时8小时。
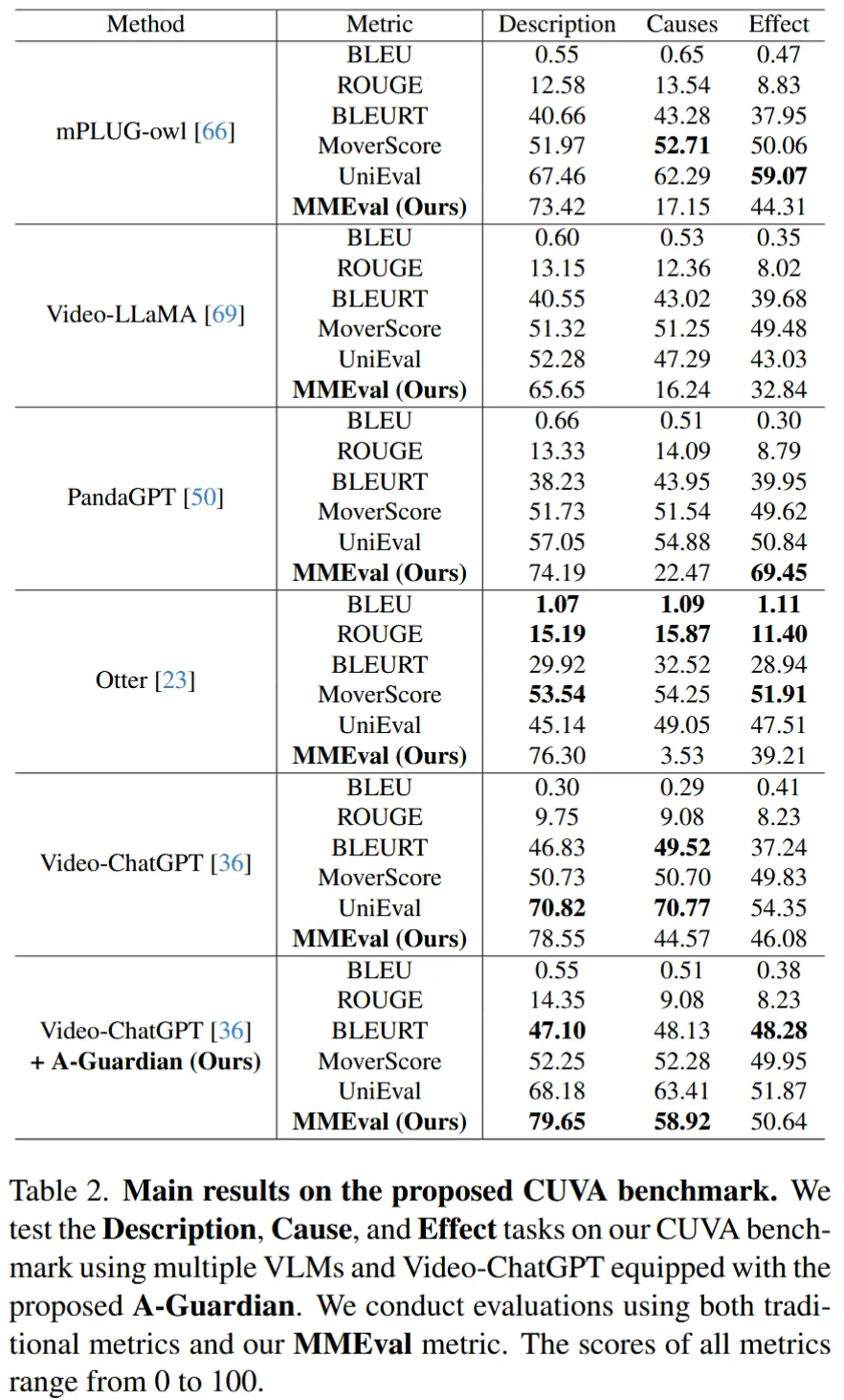
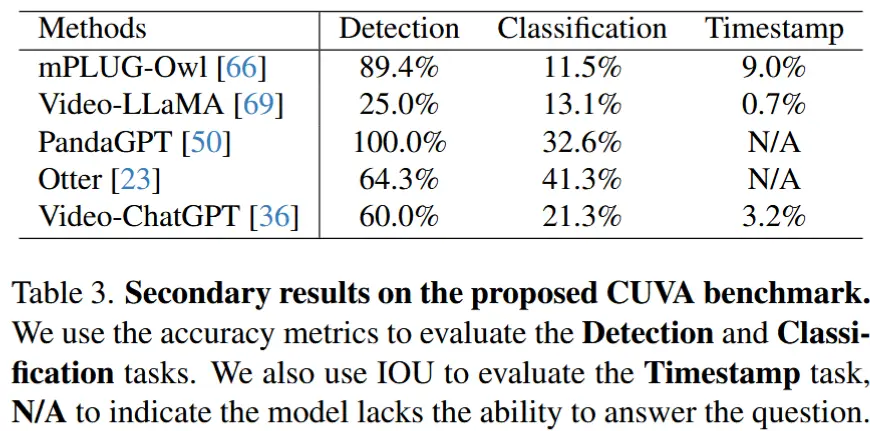
5.2 主要结果
- 作者在 CUVA 基准上进行测试。
- 对于自由文本生成任务(例如 Cause、Effect、Description),使用了多个评估指标,结果在表2。
- 对于其他结构化任务(例如 Detection、Classification、Timestamp ),评估准确率或 IOU,0.结果在表3。