- 论文 - 《Layout-Agnostic Human Activity Recognition in Smart Homes through Textual Descriptions Of Sensor Triggers (TDOST)》
- 关键词 - Ubicomp2025、prompt工程、提示词设计、传感器网络、智能家居、环境传感器、大模型生成上下文文本
摘要
- 研究问题:大多数智能家居在布局上存在显著差异,例如平面布置和嵌入式传感器的具体配置不同,导致为特定家居训练的HAR模型泛化能力较差。
- 本文工作
- 作者提出了一种新颖的、与布局无关的智能家居HAR建模方法,该方法利用自然语言描述对原始传感器数据进行表征学习,从而实现模型迁移能力。
- 为此,作者设计了“传感器触发文本描述”(Textual Descriptions Of Sensor Triggers,简称TDOST),这些描述封装了传感器触发时的上下文条件,并为活动识别模型提供关于潜在活动的线索。
- 通过使用文本嵌入而非原始传感器数据,构建了可以在不同家庭环境中预测标准活动的识别系统,无需对目标家庭进行(重新)训练或适配。
1 引言
-
当前挑战
- 当前最先进的方法通过部署深度神经网络已经实现了可用的活动识别准确率,但这些方法依赖于大量带标签的训练数据,主要采用的是监督学习的方式。
- 由于每个家庭的布局(平面图)和传感器配置通常与原始训练场景存在显著差异,因此这些模型的训练需求必须针对每一个新家庭重新进行。
- 简单的解决办法是为目标家庭收集的带标签传感器数据重新训练HAR模型,然而,需要高昂计算和经济资源。
-
本文目标
- 构建一种与布局无关的HAR系统,能够对常见的活动集合在不同目标家庭中都具有良好的识别性能,且无需使用特定目标家庭的带标签样本数据进行重新训练。
-
假设
- 通过引入伴随原始传感器触发事件的上下文信息,并且这些信息通常可以以较低成本获取,就可以构建出无需目标数据再训练的通用型HAR系统。这类上下文信息包括但不限于传感器在环境中的位置、其感知模态以及传感器触发的时间等。
-
本文方法
- 为了利用上述额外的上下文信息,作者构建了富含触发上下文的传感器触发事件的自然语言描述:传感器触发文本描述(TDOST)。
- TDOST 能够通过自然语言句子有效抽象出房屋布局及其传感器触发细节的复杂性,并且可以使用预训练语言模型进行高效编码。
- 该方法仅需目标房屋的平面图以及各类元信息,例如房屋中存在的传感器数量和类型。这些信息只需从目标家庭中一次性获取,并由我们的处理流程自动导入,以将原始传感器触发事件转换为 TDOST。随后,这些 TDOST 可直接输入一个仅在源家庭带标签数据上训练过的深度分类器中。
2 相关工作
2.1 智能家居中的 HAR
- 智能家居中的HAR系统可以通过两种方式构建:
- (1) 知识驱动型方法(Knowledge-driven)
- (2) 数据驱动型方法(Data-driven)
- 知识驱动型
- 通常需要来自单个智能家居的信息,包括居住者的行为及其与环境之间的互动。
- 此类方法通常需要构建本体(Ontologies),这些本体可能基于为特定家庭设计的活动分类体系,或通过引导式学习来识别特定活动的上下文。
- 因此,这些方法依赖于领域专家的知识、上下文理解以及在个别智能家中长期收集的数据。
- 数据驱动型
- HAR 通常包含两个步骤:分段和分类。
- 常见的分段方法
- 窗口化(Windowing):例如基于时间片段 [52, 84] 或传感器触发次数 [9] 来设定窗口。然而,这些方法的缺点在于无法有效捕捉不同长度的活动模式。
- 动态窗口化方法:基于连续窗口间的统计指标(均值、方差、协方差)[87]、基于信息增益排序的方法 [5]、基于本体和规则的方法 [88, 91, 117]、识别频繁时间模式的方法 [101]。
- 变化点检测(Change point):[9, 13, 34, 113]。
- 常见的分类方法
- 传统方法:手动提取的特征 [32],然后通过如 KNN、HMM、朴素贝叶斯等分类器进行识别。
- 利用时空信息 [18, 27] 或基于上下文的信息(例如位置或持续时间)[44, 62]。
- 基于深度学习的方法:例如 LSTM [80]。
- 基于语言的嵌入技术 [17, 19]。
- 图神经网络 [78, 127]。
- 基于自监督学习的技术 [25]。
- 当前文献中,大部分都是采用预分割策略,即在预分割的活动数据上评估其方法的有效性,而手动分段的相对较少,因为预分割能够将由于分段不准确导致的误分类与分类器本身的性能限制区分开来,专注于活动建模本身(同本文一致)。
2.2 面向通用部署的 HAR 系统:技术基础
- 为每个家庭单独训练HAR系统不现实,因此研究者采用了迁移学习或领域自适应的方法,将在一个特定的源家庭中学到的知识应用到目标家庭中。
- 更正式地讲,源领域 D_s 和目标领域 D_t 在以下一个或多个方面存在差异:
- 特征集合不同
- 数据点的边缘分布不同
- 标签集合不同
当源域和目标域具有相同的标签集合时,该问题就转化为一个领域自适应问题 [22, 37, 45]。
-
迁移学习
- 定义:它通过弥合任务之间的差距,将从源任务中学到的知识用于提升目标任务的性能。
- 迁移学习方法主要分为三类:
- 实例迁移(Instance Transfer)
- 特征空间迁移(Feature Space Transfer)
- 参数迁移(Parameter Transfer)
-
实例迁移
- 定义:通过在源领域中获取的数据实例来向目标领域传递知识,其目标是解决跨领域的数据分布偏移问题。
- 常用的实例迁移方法:
- 实例加权:根据源模型对目标样本预测的置信度为其分配权重;
- 源领域选择:选择合适的源领域以实现有效的知识迁移;
- 实例标签映射:通常用于缓解源域与目标域之间样本分布的不匹配。
- 利用源数据生成目标领域的数据实例
-
特征空间迁移
-
目标:构建一个源领域和目标领域共享的特征空间。
-
常见的特征空间迁移方法:
- 传感器配置分析
- 稀疏编码
- 遗传算法
- 本体方法
- 元特征提取
- 特征相似性度量
-
此外,也可以使用神经网络来实现特征空间迁移,这类网络能够处理异构数据并将其投影到一个共同的特征空间中。例如:
- Autoencoder
- Graph Autoencoder
- LSTM
- GAN
-
-
参数共享
- 前面提到的使用神经网络来实现特征空间迁移的方法,也可以看作参数共享的方法。
-
本文工作假设在部署 HAR 系统时无法获得目标家庭的任何数据实例,但仍希望实现高效的活动识别能力。
2.3 面向时间序列分类的 LLMs
- 将 LLMs 应用于 HAR 这一时间序列分类问题并不直接可行,因为传感器数据本身是不可解释的。
- 因此,许多研究集中于设计能够容纳传感器数据并以足够上下文呈现给 LLMs 的prompt [28, 30, 48, 71]。
- Juttner 等人 [71] 使用 GPT-4 对 CASAS 数据集 [33] 中的日常活动进行推断并检测异常行为。
- 一些专门用于无监督 HAR 的方法也被提出,如基于 chain-of-thought 的方法 [69]、two-stage prompting [122] 和 learnable prompts [129]。
- 上述方法局限:不同数据集之间所设计提示缺乏统一性,难以复用。此外,每个提示必须包含整个数据集的上下文信息才能实现有效的识别,过于繁琐。
- 相比之下,本文方法不依赖 LLM 来标注任何数据点,而是仅需一次性生成多样化的文本描述,具有更低的成本。
3 TDOST 方法
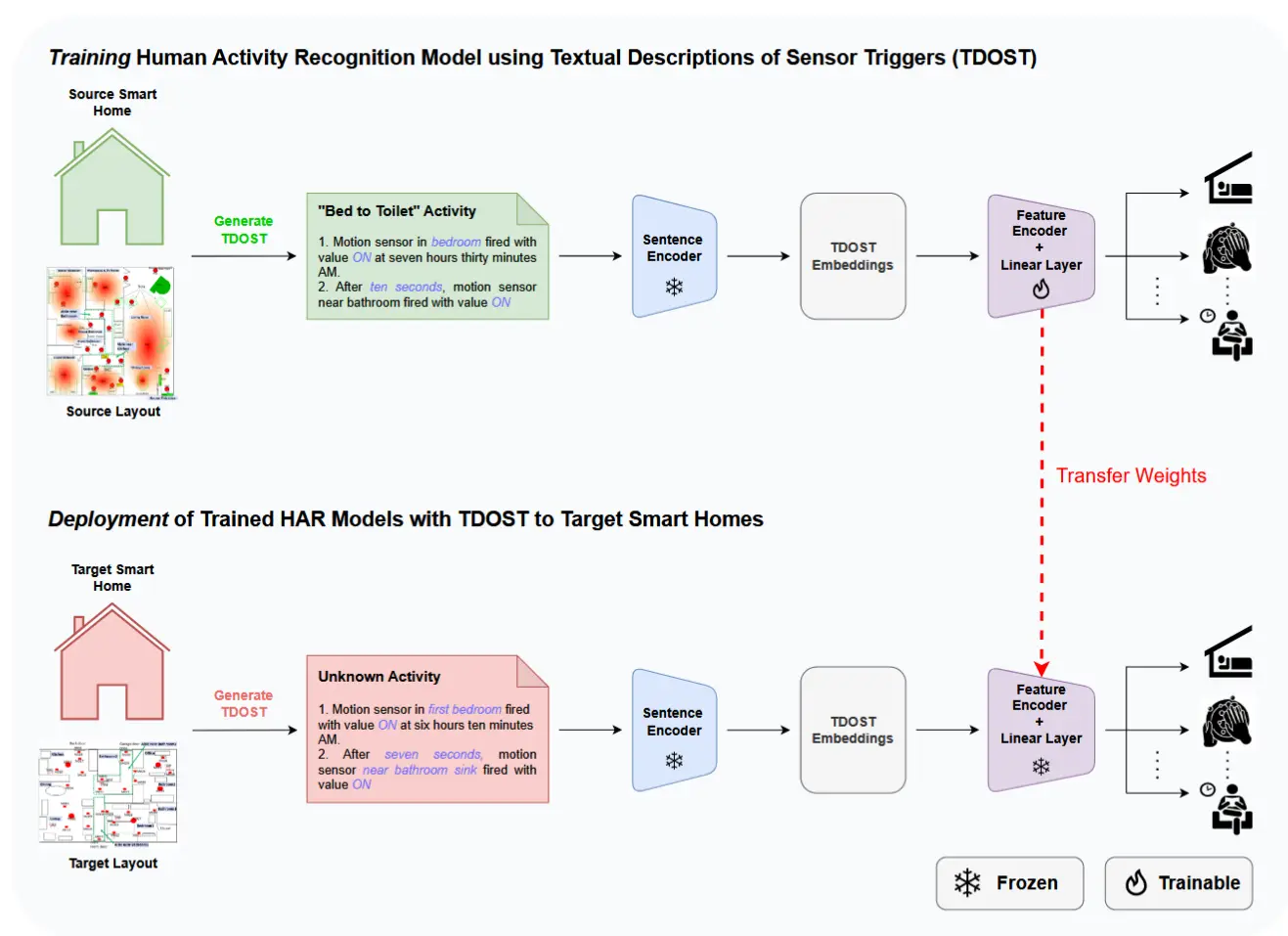
- 图1展示了方法的整体架构
- 首先,通过“传感器触发文本描述”(TDOST),将原始传感器数据转换为自然语言句子。
- 接着,使用一个预训练的句子编码器将这些 TDOST 映射到文本嵌入空间中。
- 然后,通过部署一个特征编码器和一个线性分类层,将这些句子表示适配到智能家居活动识别任务中。
- 在使用源家庭的数据对特征编码器和分类层进行训练之后,它们就可以用于在任何新的智能家居中识别标准活动。
- 对于目标家庭,仅需获取传感器的符号位置、类型以及房屋的平面图信息。这些信息将被用于推理流程中,以构建具有上下文信息的传感器触发文本描述。
3.1 文本描述生成
作者假设,能够在多个智能家居之间迁移的 HAR 模型,需要在训练过程中融合原始传感器数据和大量上下文信息。当前最先进的方法通常将传感器数据映射为离散符号并用于训练特征编码器 [80, 19],但未充分利用传感器的上下文信息(如位置、类型等)。
为此,作者提出构建基于自然语言的传感器触发文本描述(TDOST),其上下文信息来源于智能家居的布局(平面图和传感器布置)以及传感器类型等高层规格。这种方法有两大优势:
- 可以通过自然语言和背景知识轻松添加上下文信息;
- 生成的句子可利用预训练语言模型进行有效编码,这些模型具备常识推理能力且能提供跨布局迁移的表示空间,无需再训练。
为了生成具有信息量的文本描述,作者考虑了多种上下文来源,包括传感器的位置、类型和时间间隔。传感器的位置和类型为活动识别提供了关键线索,例如厨房中的运动传感器可能与“准备餐食”相关,而两次传感器触发的时间间隔也能反映潜在活动。
总体而言,作者提出了四种不同粒度级别的 TDOST 变体:
- TDOST-Basic:仅包含传感器触发的位置上下文和类型信息;
- TDOST-Temporal:在第1种基础上上,增加两次传感器触发之间的时间间隔信息;
- TDOST-LLM:为每次传感器触发使用 GPT-4 [1] 生成多个文本描述;
- TDOST-LLM+Temporal:在第3种基础上,加入传感器触发之间的相对时间信息。
3.1.1 TDOST-Basic
在该变体中,通过以下模板将传感器类型/模态和房屋中的符号化传感器位置(即位于哪个房间),以及编码后的传感器值作为上下文信息添加到原始传感器触发事件中:
<Sensor-Type> sensor in <Location of Sensor> fired with value <Sensor-Value>
example: motion sensor in bedroom fired with value ON
这种描述方式去除了任何与传感器标识相关的信息(如传感器ID),仅保留通用语义信息,例如其在房屋中的符号化位置及其二进制状态(ON/OFF)。
其中:
- 传感器类型定义了触发的传感器种类
- 符号化位置是指传感器安装的具体房间,依据房屋布局手动编码;
- 传感器值以原样添加到句子中(例如ON),但对于数值型数据,首先四舍五入再转换为文本形式(例如22.4->twenty-two)。
3.1.2 TDOST-Temporal
在该变体中,不使用绝对时间戳,而是捕捉连续两次传感器触发之间的时间间隔构建更优的活动表示。
因此,在 TDOST-Temporal 中,将两个触发事件之间的相对时间差添加到第二个传感器事件的描述中。此外,还对“位置”部分进行了更丰富的上下文扩展,例如将原本只是“卧室”的位置描述细化为“靠近前门的卧室”。
本变体同样采用基于模板的方式生成文本描述,对于序列中的每个传感器触发事件,使用以下两种模板之一:
1. <Temporal information> <Sensor-Type> sensor in <Location of Sensor> fired with value <Sensor-Value>
2. <Sensor-Type> sensor in <Location of Sensor> fired with value <Sensor-Value> <Temporal information>
example_1: five seconds later, the temperature sensor in kitchen near stove fired with value twenty-four
example_2: the temperature sensor in kitchen near stove fired with value twenty-four at seven hours thirty minutes AM
3.1.3 TDOST-LLM:
之前的 TDOST 版本手动将传感器数据转换为文本句子。在 TDOST-LLM 中,利用最先进的LLM(GPT-4.0)为每个传感器读数生成多样化的文本描述。其中,向 GPT-4.0 提供了以下提示:
# 大致意思:你是一个负责为传感器读数生成多样化文本和上下文信息的AI。请你为给定窗口中的每个传感器触发事件生成 3 条不同的文本句子。传感器触发格式为:(星期, 时间段, 传感器类型, 位置, 传感器值)。
You are an AI assistant responsible for generating diverse text descriptions and contextual information for each sensor reading, using relevant world knowledge.
Respond clearly and formally, avoiding poetic language, figurative expressions, or abstract phrasing. Generate 3 diverse text sentences for each sensor trigger in a given window of 5 triggers.
The sensor trigger format is: (Day of Week, Time, Sensor Type, Location, Sensor Value). Output the results as a JSON object where the key is the sensor trigger (Day of Week, Time, Sensor Type, Location, Sensor Value) and the value is a list of generated sentences. Sensor Trigger Window:
('Monday', 'Early Morning', 'Motion', 'between aisle and bathroom', 'OFF')
('Monday', 'Early Morning', 'Motion', 'bathroom', 'OFF')
('Monday', 'Early Morning', 'Motion', 'second bedroom', 'ON')
('Monday', 'Early Morning', 'Motion', 'second bedroom', 'OFF')
('Monday', 'Early Morning', 'Motion', 'between aisle and second bedroom', 'ON')
传感器读数以元组形式输入到 LLM 中,该元组包含一周中的某一天、当天的时间段、传感器类型、传感器的位置上下文以及其值。传感器类型、传感器值和位置上下文与之前定义的 TDOST-Temporal 相同。
为了限制对 LLM 的提示数量,将每个传感器触发事件中的绝对时间转换为更粗粒度的时间段,使用六种不同的时间段,分别是:“Night”(0-5h)、“Early Morning”(5-8h)、“Morning”(8-12h)、“Afternoon”(12-17h)、“Evening”(17-21h)和“Late Night”(21-23h)。
示例:
- 首先,传感器触发事件
(08:03:07, M41, OFF)。 - 接着被重新格式化为
('Thursday', 'Morning', 'Motion', 'bathroom', 'OFF'),然后添加到提示中给GPT-4.0。 - 最后GPT生成三条语义相同但是文本不同的句子:
- "The motion sensor in the bathroom reported an 'OFF' status on Thursday morning, indicating no presence in that area."
- "In the morning of Thursday, there was no detected motion in the bathroom, as reflected by the sensor's 'OFF' status."
- "The lack of movement in the bathroom during Thursday morning is confirmed by the 'OFF' reading from the motion sensor."
3.1.4 TDOST-LLM+Temporal:
对于这种编码变体,我们遵循3.1.3的过程。然而,在后处理步骤中,还为每条由 LLM 生成的句子添加了相对时间差。相对时间差有助于为句子增加更精细的时间信息,其定义与 TDOST-LLM 中的一致。使用以下两种模板之一来生成 TDOST-LLM+Temporal 描述:
1. <GPT-generated Sentence1> <Temporal information>, <GPT-generated Sentence2> <Temporal information>, <GPT-generated Sentence3> <Temporal information>
2. <Temporal information> <GPT-generated Sentence1>, <Temporal information> <GPT-generated Sentence2>, <Temporal information> <GPT-generated Sentence3>
该模板简而言之,就是为 LLM 生成的每个句子开头添加了传感器触发事件之间的相对时间差。仅在为活动序列的第一个读数生成句子的情况下,才会在句子末尾添加绝对时间。
现在,3.1.3节中的例子会更新成如下:
- "After seven seconds, the motion sensor in the bathroom reported an 'OFF' status on Thursday morning, indicating no presence in that area."
- "After seven seconds, in the morning of Thursday, there was no detected motion in the bathroom, as reflected by the sensor's 'OFF' status."
- "After seven seconds, the lack of movement in the bathroom during Thursday morning is confirmed by the 'OFF' reading from the motion sensor."
3.2 基于 TDOST 的布局无关人类活动识别方法
总体而言,基于 TDOST 的 HAR 在智能家居中的应用场景类似于一个两阶段过程:
3.2.1 在源家庭中训练
为了在源家庭中进行端到端的监督训练,假设可以访问带有标签的源训练数据。过程具体如下:
- 文本描述生成:首先使用四种 TDOST 变体之一,将源数据集中带标签的原始传感器数据转换为文本描述;
- 文本嵌入提取:接着,使用一个冻结的预训练语言模型(Sentence Transformer)来获取丰富的语义文本表示;
- 特征编码:然后,使用特征编码器(Bi-LSTM)捕捉文本表示序列中的长期依赖关系;
- 分类头训练:最后,训练一个分类头,将特征表示映射到对应的活动标签。
3.2.2 部署到目标家庭
首先,需要从目标家庭中收集房屋平面图以及传感器布置和类型的信息。作为数据预处理步骤,这些元数据被用来自动生成模板,从而自动地将目标家庭的传感器触发事件转换为文本句子。
具体步骤如下:
- 目标文本描述生成:将目标家庭的原始测试传感器数据根据所选模板,结合其房屋平面图和传感器信息,转换为文本描述;
- 文本嵌入生成:然后,使用与源模型相同的预训练模型,将这些目标文本描述转换为嵌入表示;
- 模型推理:最终,将目标文本嵌入输入到原本在源数据上训练完成的冻结 HAR 模型中,以预测目标环境中的活动。
在本文中,假设活动在源和目标中是相同或至少相似的,这使得源分类头可以继续使用。
4 实验
实验部分较多,只摘录了一些关键的信息。
-
数据集
- 来自 CASAS 的四个数据集:Aruba、Milan、Kyoto7、Cairo
- Orange4Home(Orange)
-
传感器非常丰富,包括噪音、电压、适度、运动、温度、门磁等。
-
为了实现跨家庭迁移,统一定义了一个标准活动集合:{放松、做饭、离家、回家、睡觉、进食、工作、起床如厕、洗澡、服药、个人卫生、其他}
-
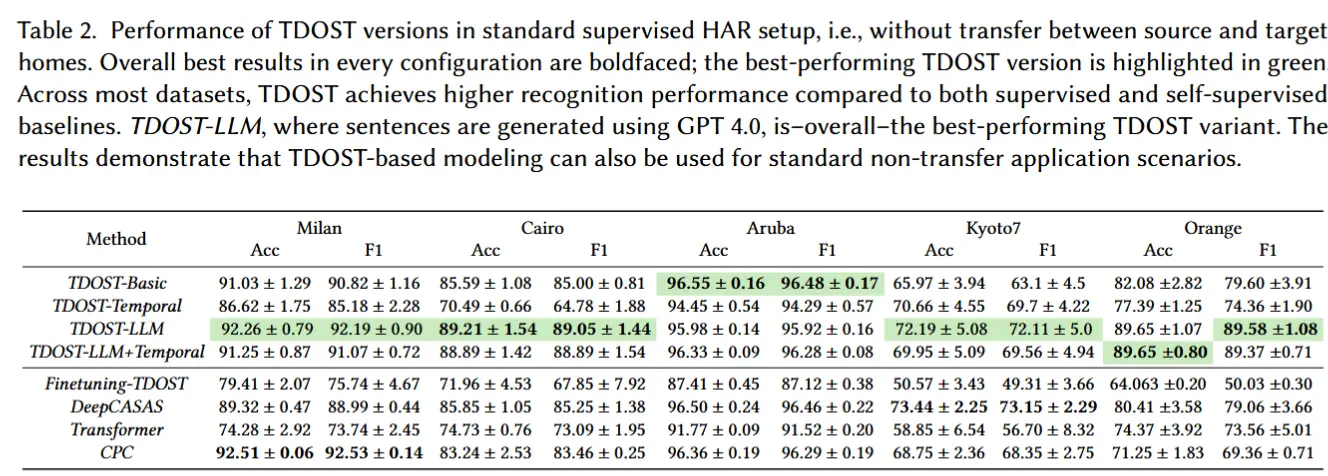
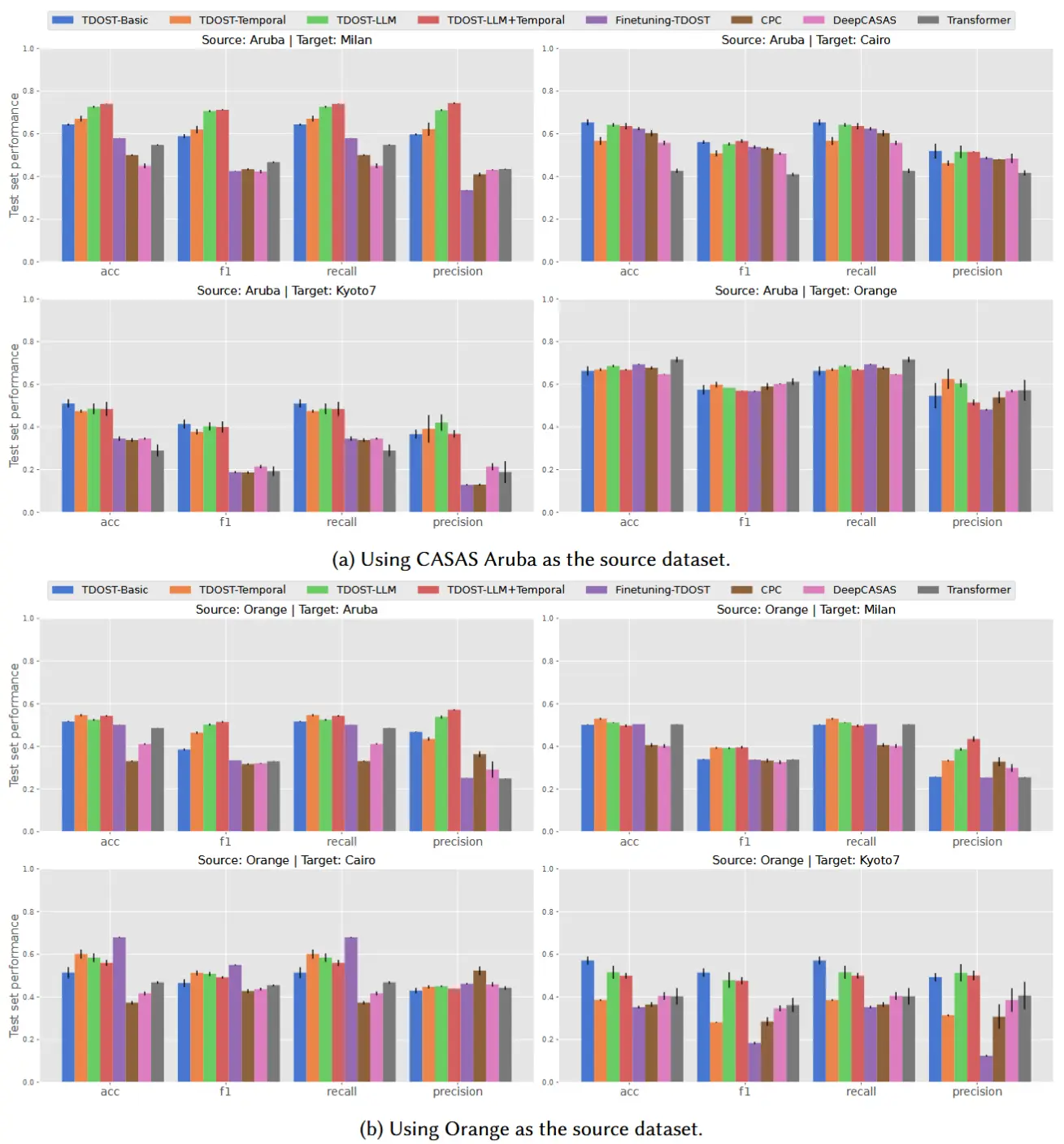
基于 TDOST 的布局无关活动识别方法在跨家庭迁移中的性能对比图
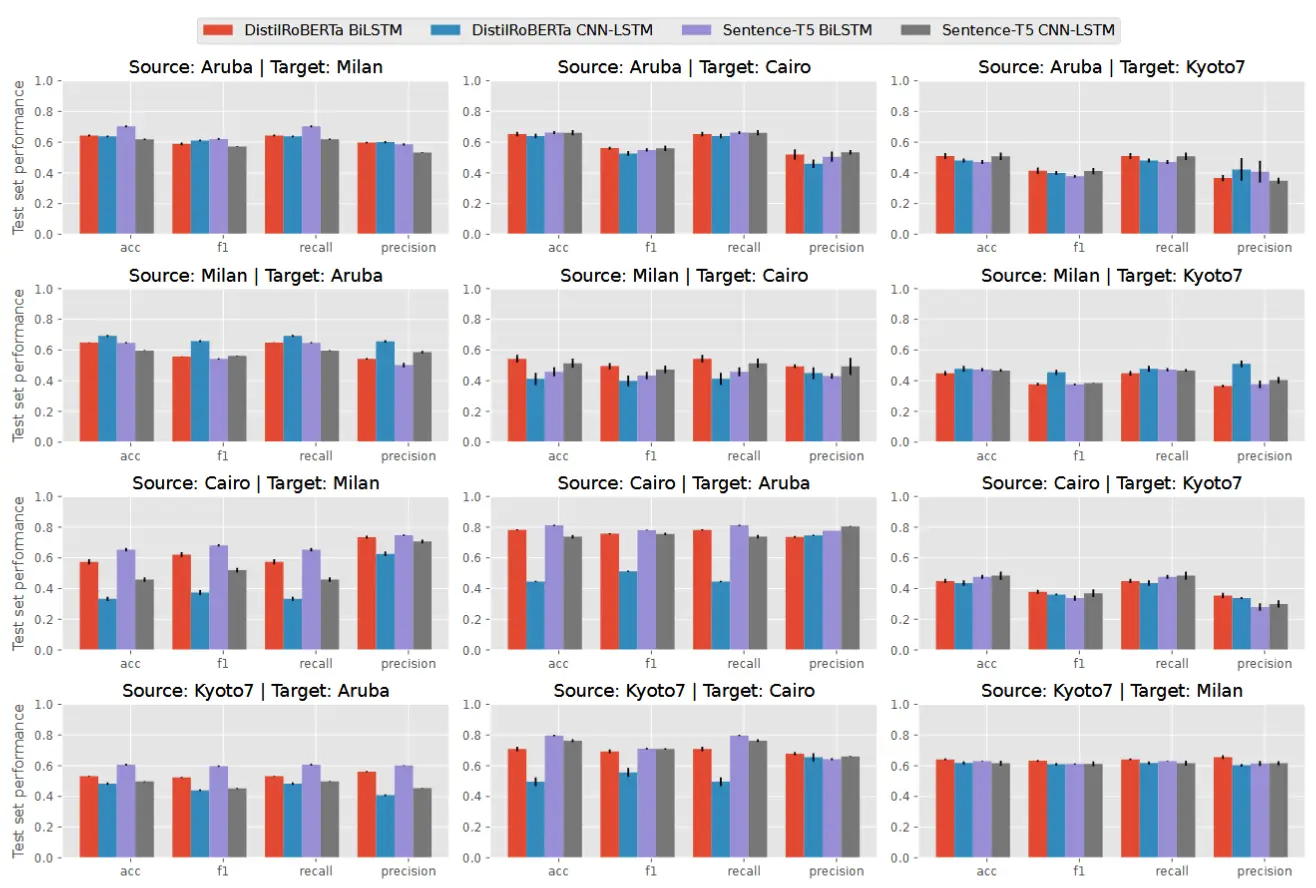
- 不同语言模型和分类器结构组合在 TDOST 方法中的性能对比图
- 不同 TDOST 方法在常规(非迁移)智能家居活动识别任务中的性能对比