- 论文 - 《LLaSA: A Sensor-Aware LLM for Natural Language Reasoning of Human Activity from IMU Data》
- 代码 - Github
- 关键词 - 多模态大模型、人类活动问答模型、13B参数、微调、新数据集
摘要
- 研究问题:目前的系统仅能对可穿戴设备数据进行活动分类,而无法回答关于为什么会发生或其意义是什么等自然问题。
- 本文工作
- 提出了LLaSA(Large Language and Sensor Assistant),一个紧凑的13B参数模型,能够在原始IMU数据基础上支持“问任何问题”的开放式问答。
- LLaSA支持对话式、上下文感知的推理——可以解释传感器检测到的行为原因,并在现实场景中回答自由形式的问题。
- 为了推动这种基于传感器的问答任务的发展,作者发布了三个大规模数据集:SensorCaps、OpenSQA 和 Tune-OpenSQA。
1 引言
-
传感器LLM的意义
- 全球超过190亿台物联网设备持续不断地采集运动数据,然而大部分信息未被充分利用。
- 这种差距不仅限制了人们在健康、健身和康复领域的日常决策能力,也制约了日益依赖上下文感知、高频传感器流的增强现实(AR)和虚拟现实(VR)中更丰富的交互体验。
-
IMU 数据挑战
- IMU 数据由大量连续的低层次数值组成——噪声大、未经分割、并且缺乏语义结构。
- 使模型理解IMU数据需要将原始的、依赖上下文的时间序列模式与人类可理解的概念对齐——尤其是在面对开放式、因果类问题时。
- 有意义的运动模式通常跨越数百甚至数千个时间步,使得在语言模型有限的上下文窗口内保留时间结构变得困难。
-
已有工作 SensorLLM [23]
- 通过离散标签预测来优化分类准确率。
- 尽管这种方法足以应对识别任务,但在目标是解释事件发生原因或生成连贯、上下文感知的响应时就显得不足。
-
本文模型 LLaSA
- 一种多模态框架,能够在IMU信号基础上实现开放式、上下文感知的问答功能。
- 在接收到用户问题时,LLaSA 会处理 IMU 输入,使用一个具备传感器感知能力的主干网络对其进行编码,并将其与语言表示对齐,从而实现跨模态推理。
- LLaSA 的核心组成部分之一是其调优策略,旨在提升其对传感器数据的上下文感知推理能力。调优过程优先关注三个关键特性:科学准确性、叙述连贯性和回答可靠性。这一过程由基于 GPT 的评分指标指导,该指标用于评估回答质量,并不断优化模型生成基于事实、易于理解的解释的能力。
-
为填补将原始 IMU 信号与自然语言理解对齐的高质量数据集的空白,作者发布了三个大规模数据集:
- SensorCaps:包含 35,960 条 IMU 序列及其对应的描述性说明文本,支持对运动模式的理解;
- OpenSQA:包含 179,727 个问答对,专为因果推理与解释性推理设计;
- Tune-OpenSQA:包含 19,440 个指令跟随示例的微调集,经过精心整理,以优化模型的准确性、连贯性和可靠性。
2 LLaSA 架构
LLaSA架构如图2所示,以原始传感器数据和用户查询作为输入,并生成上下文感知的语言响应。包含四个关键组件:
- 传感器编码器:将原始的IMU传感器数据转换为紧凑的特征表示,从而减少上下文长度。
- 文本编码器:将输入的查询语句转化为查询嵌入。
- 投影层:将传感器嵌入和查询嵌入对齐到一个共享的表示空间中。
- 融合传感器信息的语言模型:接收来自传感器和查询的联合嵌入信息,生成最终的回答。
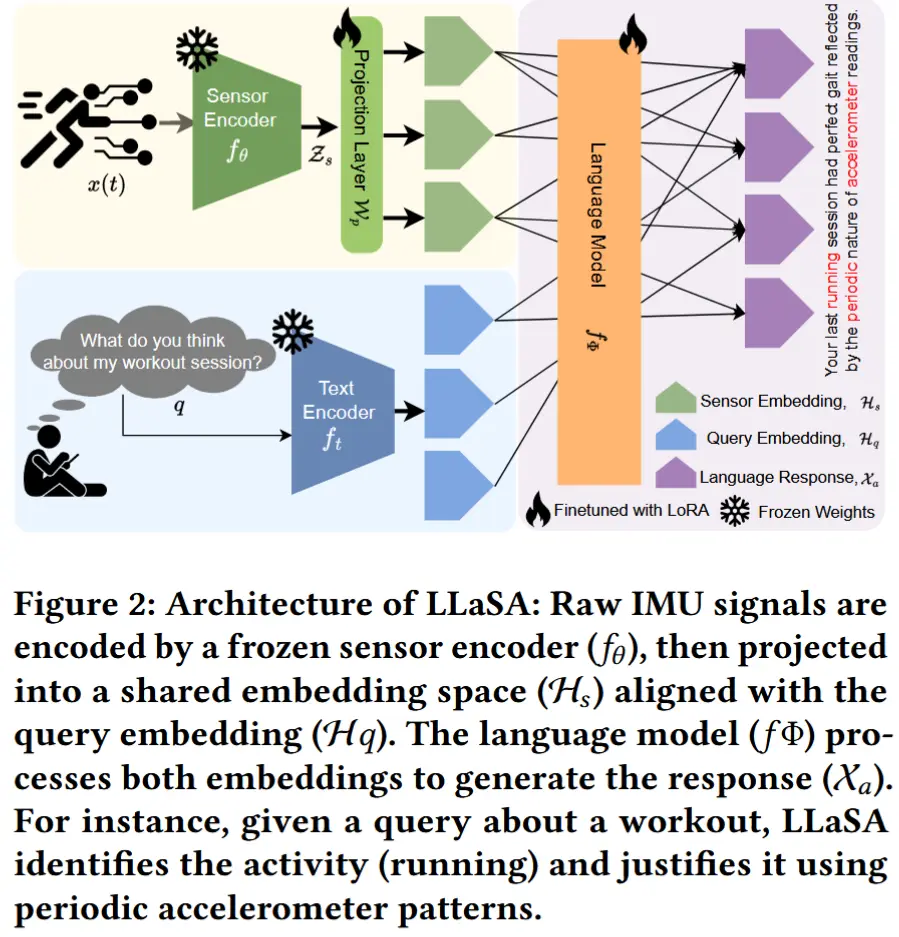
2.1 传感器编码器 f_\theta
给定原始传感器数据 x(t) \in \mathbb{R}^{C \times T} ,其中 C 表示通道数, T 表示总时间周期。使用一个预训练的传感器编码器(使用LIMU-BERT编码器部分 [41]),其嵌入大小为 k ,记为 f_\theta(\cdot) ,以提取有意义的传感器表示,同时减少上下文长度。编码后的传感器特征表示由以下公式给出:\mathcal{Z}_s = f_\theta(x(t)) \in \mathbb{R}^{\bar{c} \times \bar{k}}。编码器将原始 IMU 数据处理为上下文化的表示,而解码器则从这些表示中重构原始信号。隐空间表示 \mathcal{Z}_s 使用自注意力层捕捉时间依赖性和跨通道交互。
2.2 文本编码器 f_t(\cdot)
文本编码器 f_t(\cdot) 将输入查询 Q 转换为查询嵌入 \mathcal{H}_q \in \mathbb{R}^{\bar{c} \times k} ,其中 k 表示嵌入维度。作为文本编码器,作者使用了包含在 Llama 中的 SentencePiece 分词器。
2.3 投影层与对齐机制 W_p
将传感器数据整合到 LLMs 中需要投影机制,以将传感器嵌入与预训练的语言特征空间对齐。给定传感器特征 \mathcal{Z}_s \in \mathbb{R}^{\bar{c} \times \bar{k}} ,其中 \bar{k} 表示传感器特征维度,作者采用一个可学习的投影函数:
其中 W_p \in \mathbb{R}^{\bar{k} \times k} 是一个可训练矩阵, \sigma(\cdot) 是GELU非线性激活函数。投影后的传感器表示 \mathcal{H}_s 与查询嵌入 \mathcal{H}_q 进行拼接,形成模型输入:
这种对齐确保了传感器衍生的特征在LLM的语言空间中具有语义意义。投影层受多模态对齐技术启发,充当一种传感器自适应的分词器,将传感器特征细化到兼容的嵌入空间中。
2.4 传感器集成语言模型
传感器集成语言模型基于投影后的嵌入 \mathcal{H} ,以支持对传感器数据进行自然语言推理。受 LLaVA [25] 的启发,转换后的传感器嵌入取代了视觉语言模型中使用的传统视觉嵌入。
最终,组合表示 \mathcal{H} 被输入到LLM f_\Phi 中,生成感知传感器的语言响应:
在自回归解码过程中,模型根据多模态输入生成每个输出标记:
其中, x_{a,t} 表示时间步 t 上生成的标记, \phi 表示LLM的参数。
3 面向传感器上下文的语言模型优化
问题:与仅处理文本的任务不同,传感-语言模型必须处理噪声或缺失信号、保留时间模式,并在开放式回答中保持逻辑连贯性。使用通用的超参数设置往往会导致模糊或错误的输出,与传感器上下文脱节。
解决:作者提出了一种有针对性的调优策略,结合了超参数搜索与结构化评估,以促进因果推理和上下文对齐,提升基于传感器的回答的可靠性和可解释性,并且无需引入新的模型架构。
3.1 超参数优化策略
重点调优以下五个关键参数:
- 学习率\eta:用于在不同传感器上下文中实现稳定的模型适应;
- 批量大小B:用于平衡过拟合风险与内存使用;
- 权重衰减\lambda:用于正则化噪声模式;
- LoRA秩r:用于控制模型适配能力;
- 丢弃率p_{drop}:用于在不确定性条件下提高鲁棒性。
3.2 标准NLP指标的局限性
BLEU 和 ROUGE 词法相似度指标局限:
- 即使回答缺乏推理过程,这些指标也会因词汇重叠而给予高分。
- 依赖于表面层级的词汇重叠,忽略了多模态推理所需的语义和因果深度。
- 它们常常误判那些语义正确但用词不同的回答,并且无法考虑上下文敏感性。
- 对静态参考答案的依赖也限制了其在开放式、传感器驱动任务中的可扩展性。
然而,基于 GPT 的评分方法能够捕捉上下文深度和逻辑性,是一种更有意义的方式来调优和评估传感-语言模型。
3.3 面向传感器问答的LLM评估方法
为了克服词法指标的局限性,作者采用了一种基于 LLM 的评估框架,该框架从逻辑连贯性、传感器依据性和上下文相关性等方面对回答进行评分,使模型能够捕捉到语义正确性和推理质量。
如表1所示,传统指标常常因为措辞上的重叠而给予一些浅层回答高分,而基于GPT的评分则更倾向于那些具有因果解释并能与传感器信号对齐的回答。

3.4 评分框架
为了评估具备传感器感知能力的问答系统,作者提出了一种基于 LLM 生成评估结果、并结合领域特定标准的结构化评分框架。每个回答将从以下四个维度获得0到100分的评分:
- 正确性(Correctness):回答是否与预期的传感器行为一致;
- 完整性(Completeness):是否涵盖了相关的传感器信号属性;
- 一致性(Consistency):逻辑上是否与传感器上下文保持一致;
- 有用性(Helpfulness):回答是否具有实用信息价值。
使用 GPT-4o 和结构化提示,并结合参考答案、传感器位置信息和活动标签,计算出最终的质量得分:
质量评分的可靠性验证
为了评估质量评分的可靠性,作者让 GPT-4o 和 DeepseekV3 独立对一部分回答进行评分。随后,计算了组内相关系数(ICC) ,结果得到了 0.92 的 ICC 值(p = 0.0001,95% 置信区间:[0.73–0.98])。这一高 ICC 值表明评分者之间具有很强的一致性,证实该质量评分是衡量回答质量的有效指标。
3.5 模型与数据的扩展策略
为了在保持计算可行性的前提下增强模型对传感器信息的推理能力,作者采用了双重扩展策略:
- 模型扩展:通过调整模型架构规模,使其更好地捕捉细粒度的传感器模式,在表达能力和计算效率之间取得平衡;
- 数据扩展:引入更多样化的传感器叙述数据进行训练,提升模型对未见过的活动和上下文的泛化能力。
4 传感器-语言数据集
目前,大多数现有数据集都集中在活动标签上,限制了模型对行为的解释能力和开放式问答的表现。为解决这一问题,作者发布了三个开源数据集,训练模型使用自然语言解释原始 IMU 信号。
数据集部分简单介绍,作者在论文中详细介绍了数据集结构与处理流程、特征工程与标注、面向传感器叙述的提示词设计等等,感兴趣可以去看论文。
- SensorCaps:具备传感器感知能力的描述生成
- SensorCaps 教导模型在基本分类之外描述和解释运动模式 。基于公开的人类活动识别(HAR)数据集(见表2),该数据集提供了35,960条叙述性描述,捕捉运动动态及其上下文信息。
- OpenSQA:具备传感器感知能力的开放式问答数据集
- OpenSQA 建立在 SensorCaps 基础之上,新增了 179,727 对问答(QA pairs) ,用于训练 LLaSA 回答基于 IMU 数据的开放式问题。SensorCaps 提供了对运动模式的描述性叙述,而 OpenSQA 则进一步支持推理与解释——弥合原始传感器输入与类人理解之间的鸿沟。
- Tune-OpenSQA:面向传感器问答的调优数据集
- Tune-OpenSQA 包含 19,440 对问答对 ,专用于模型调优而非训练。与用于教学回答生成的 OpenSQA 不同,Tune-OpenSQA 的目标是提升 LLaSA 生成连贯、科学且具备上下文感知能力的解释的能力 。
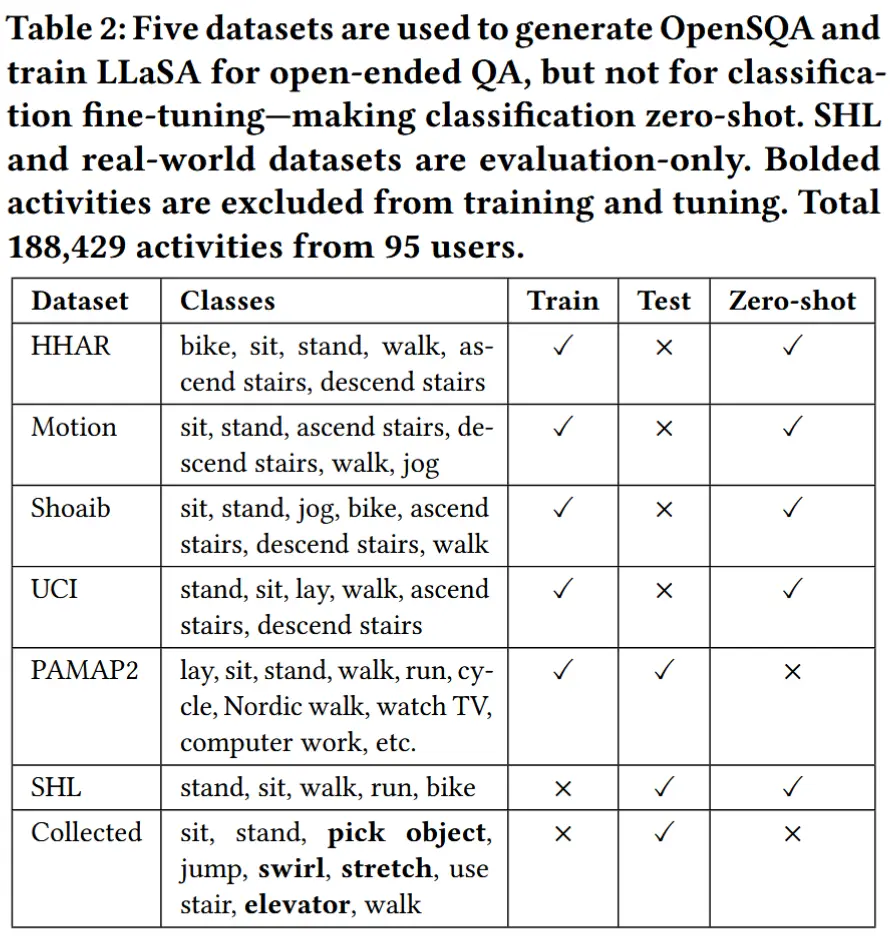
5 实现细节
- LIMU-BERT 预训练
- 使用来自四个标准 HAR 数据集的无标签数据对 LIMU-BERT 进行预训练,这些数据集包括:HHAR、UCI-HAR、MotionSense 和 Shoaib。
- 多模态投影层训练
- 使用 OpenSQA 数据集训练一个带有 GELU 激活函数的 MLP 投影层 W_p,用于将传感器特征与语言模型的 token 嵌入空间对齐。
- LLaSA 微调
- 在 Vicuna-7B-1.5 和 13B-1.5 模型基础上应用 LoRA [16] 微调,并结合预训练的投影层,采用类似 LLaVA 的指令微调方法。
6 开放式传感器感知问答评估
6.1 与基线 LLM 的比较
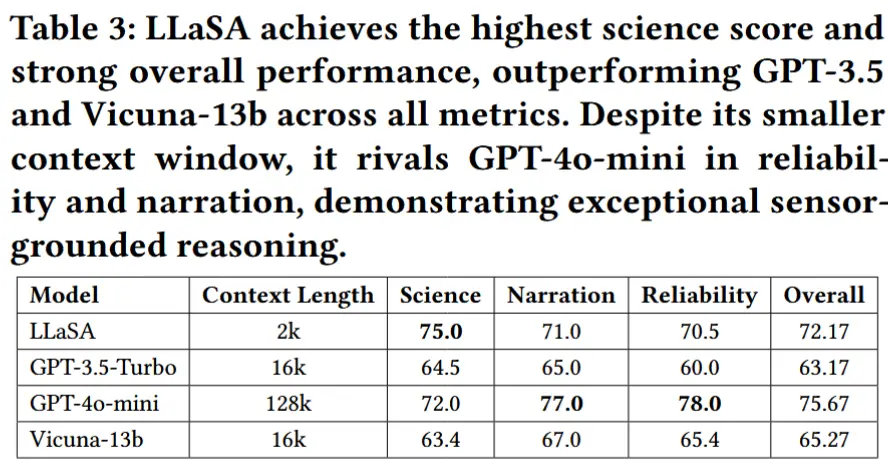
- 评估指标:scientific depth, narration quality, reliability
- LLaSA 在所有评估维度上都优于 GPT-3.5-Turbo 和 Vicuna-13b,基于传感器数据生成更准确、更上下文和更可靠的答案。它还在所有模型中获得了最高的科学分数,凸显了它在传感器知情推理方面的优势。
- 尽管 LLaSA 的 2K 上下文窗口很小,但其性能优于大型模型,容量高达 64× — 证明通过正确的调整,较小的模型可以在边缘提供快速、准确和传感器接地的推理。
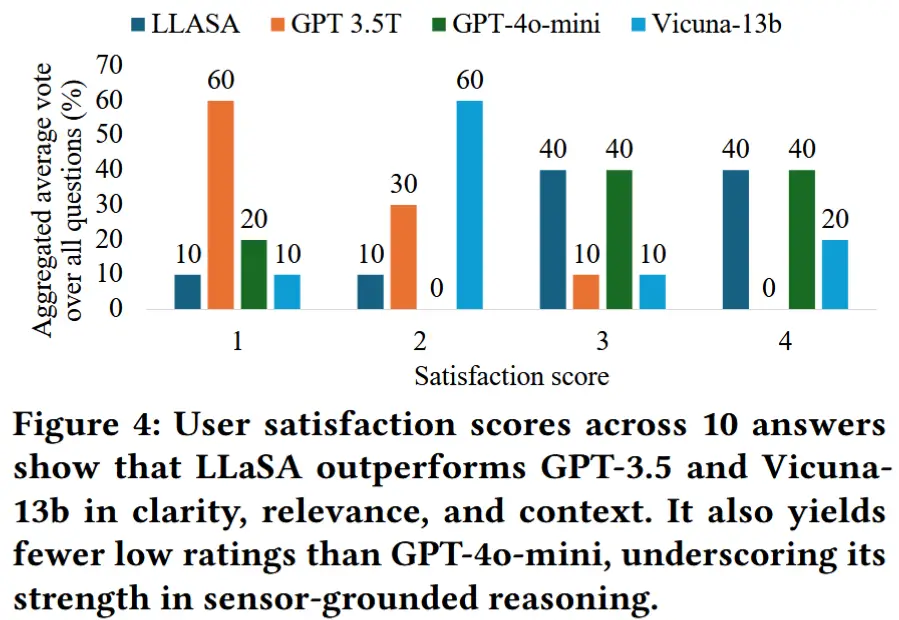
6.2 用户研究:QA 响应排名
- 数据集:10个问答对样例,涵盖科学性、叙述性和可靠性,基于GPT评分选取,确保质量分布均衡。
- 实验目的:评估模型在真实用户视角下的解释能力和可理解性。
- 实验设计
- 参与者对四个模型生成的回答进行排序,依据清晰度、相关性和上下文一致性,每条回答从1到4打分(4为最优);
- 每个问题附带传感器简介和可视化图表,帮助理解;
- 实验结果如图4
- LLaSA 在用户评价中展现出更强的解释力与上下文关联能力,验证了其在面向非专家用户的健康监测、行为识别等场景中的实用性。
6.3 泛化到真实世界数据
- 数据集:新采集的真实世界IMU数据,来自10名用户在自然环境中完成的9种活动,每人每类约20个样本,最终生成534个问答对。
- 评估指标:使用 GPT-4o 按照第 3.4 节提出的质量评分框架对回答质量打分。
- 实验结果如表4所示。

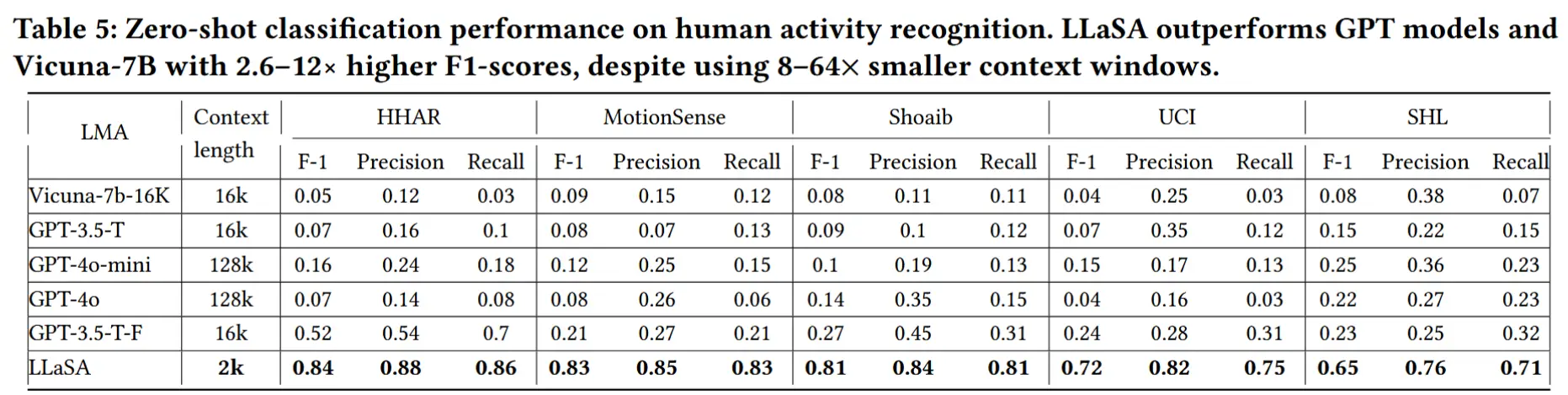
6.4 零样本活动识别
- 实验设计:模型在没有明确分类训练的情况下,根据候选活动标签选择最合适的类别。
- 实验结果如表5所示,LLaSA 在 zero-shot 条件下显著优于所有基线模型。