- 论文 - 《LIMU-BERT: Unleashing the Potential of Unlabeled Data for IMU Sensing Applications》
- 代码 - Github
- 关键词 - Sensys2021、IMU、HAR、自监督学习、训练、掩码、BERT、
摘要
- 研究问题:大多数现有方法需要大量精心标注的训练数据来构建基于IMU的感知模型,这导致了高昂的数据标注和训练成本。相比有标签数据,无标签的IMU数据则更为丰富且易于获取。
- 本文工作
- 提出了LIMU-BERT,一种新颖的表示学习模型,能够利用无标签的IMU数据,并从中提取通用而非特定任务的特征。借鉴自然语言处理模型BERT中的自监督训练机制,有效捕捉IMU传感器数据中的时间关系和特征分布。
- 通过细致分析IMU传感器的特性,作者提出了一系列针对性的技术手段,并据此对LIMU-BERT进行了适配优化,使其更贴合IMU感知任务的需求。所设计的模型轻量化程度高,便于部署在移动设备上。
1 引言
- LIMU-BERT核心思想:通过自监督训练技术提取通用特征。在完成特征表示的学习之后,只需少量有标签的IMU样本即可训练多个特定任务的推理模型。
- 目标:从IMU数据中希望提取哪些通用特征?
- IMU传感器单次测量值的分布特征
- 连续测量值之间的时间关系(时序关系)
- 如何从未标注的IMU数据中提取这些通用特征或表示?
- 受自监督学习技术的启发,借鉴BERT模型的核心框架来处理未标注的IMU数据,并从中提取通用特征。
- 然而,原始BERT是为自然语言数据设计的,在IMU数据方面存在不足。
- 为此,本文针对IMU感知任务提出了一系列关键技术,并嵌入BERT框架中,其中包括:
- 数据融合与归一化方法
- 高效的训练策略
- 结构优化设计
- 实验
- 在四个公开的IMU数据集上进行了广泛的实验。实验结果表明,基于LIMU-BERT增强的深度学习方法在人体活动识别和设备放置分类等应用中,准确率和F1-score指标上均提升了至少10%。
2 前置知识
2.1 表征学习
- 表征学习技术旨在从原始数据中提取特征表示或通用特征 。
- 传统方法依赖领域专家的知识或先验信息。近年来使用深度学习网络对大量标注数据进行自动表征学习。对于未标注数据,通常使用自监督学习。
- 基于Transformer的双向编码器表示(BERT)
- 包含两个自监督训练任务:
- Masked Language Model(MLM) :随机掩盖输入文本中的一部分词语,并训练模型预测这些被掩盖词语的原始标识;
- Next Sentence Prediction(NSP):判断给定的两句话是否为连续的上下文语句。
- 在完成自监督预训练之后,预训练模型可以连接特定任务的模型,通过有监督训练执行各种NLP任务。
- 包含两个自监督训练任务:
- 受BERT启发,作者希望在移动感知任务中采用自监督学习方法,同时作为时间序列类型的数据,IMU传感器数据同样包含丰富的上下文关系。因此,从无标签IMU数据中提取出的有效特征表示不仅可以提升下游推理模型的性能,还能显著降低对标注数据的需求。
2.2 IMU感知的独特性
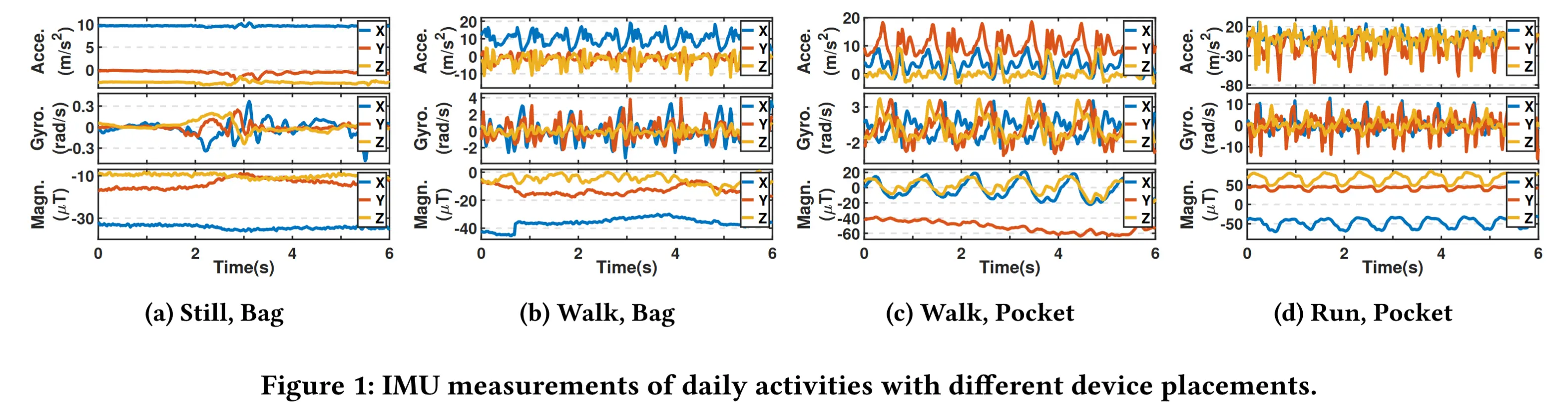
- 图1展示了在不同人体活动(行走/站立/跑步)和设备放置方式下(背包/口袋)采集的四组 IMU(加速度计、陀螺仪、磁力计)数据。
- 融合至关重要:三种数据对于同一活动的敏感性不同,因此 多传感器交叉参考 能够提供更多信息并提升整体性能。
- 分布特征至关重要:三种活动中不同数据的取值范围差异很大,IMU 读数的分布包含了丰富的信息。因此,作者认为如果希望从 IMU 数据中提取通用特征,在输入神经网络之前不应进行可能破坏原始数据分布信息的变换操作 。
- 上下文至关重要:行走和跑步在IMU数据中表现出明显的周期性模式,此外,当设备放置位置不同时,这种周期性模式也会发生变化。因此,时间关系 在IMU数据的表示学习中也起着至关重要的作用
- 效率至关重要:IMU数据采集自移动设备,需要实时处理,并且移动设备在计算能力和电池容量方面都受到限制。
2.3 潜在应用场景
本文将通过两个典型应用——人体活动识别(HAR) 和 设备放置分类(DPC) 来展示LIMU-BERT的有效性。
3 设计
3.1 概述
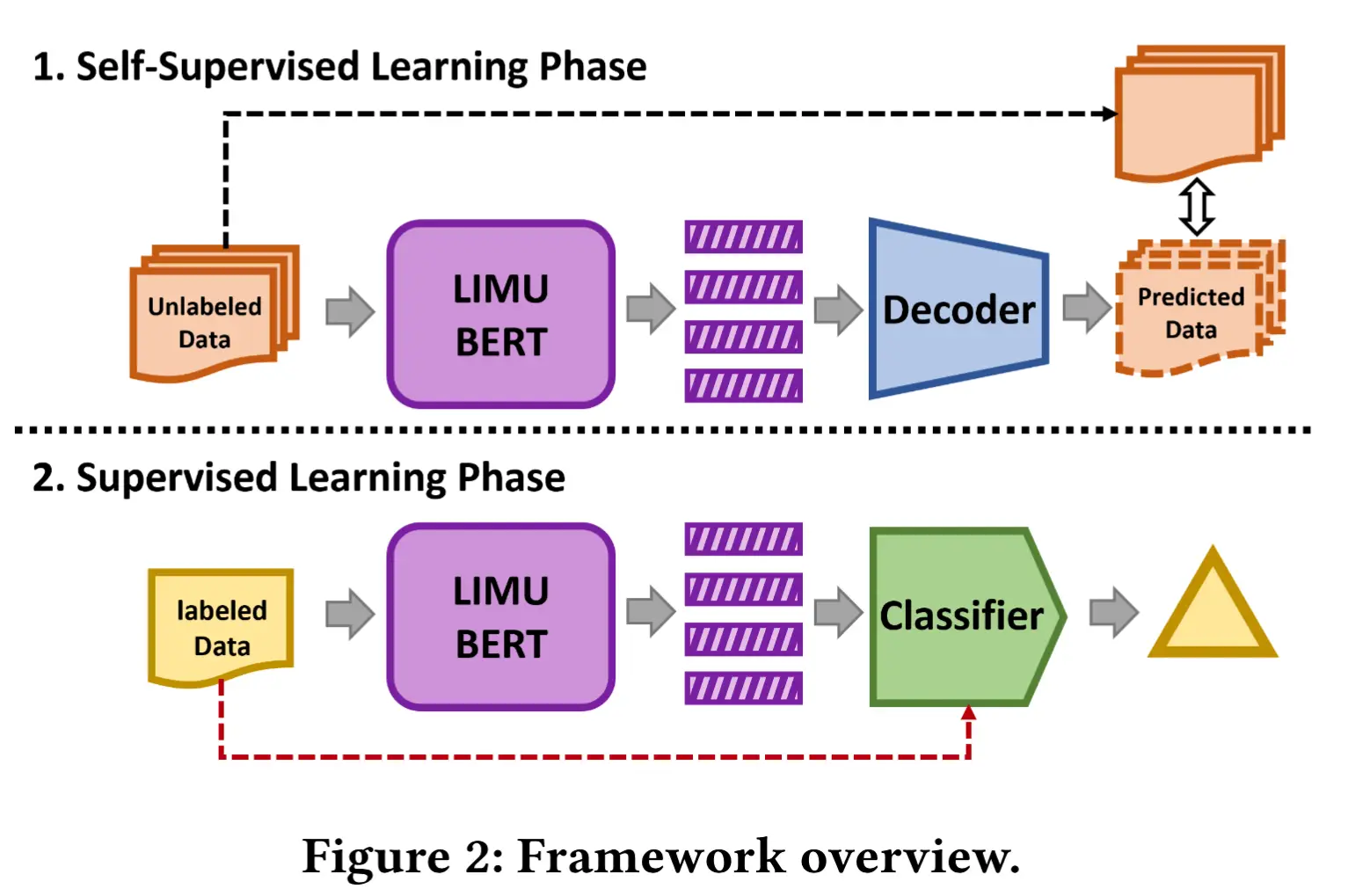
整个框架如图2所示
- 两个阶段
- 自监督学习:对部分无标签样本的传感器读数进行掩码处理,LIMU-BERT 与解码器联合工作,预测被掩码部分的原始数值。
- 有监督学习阶段:LIMU-BERT 的所有参数被冻结 ,仅使用有限数量的已标注特征表示来训练分类器。
- 三个核心组件:LIMU-BERT、解码器、分类器
3.2 数据融合与归一化
常见的归一化方法可能会导致分布信息的丢失,并可能对通用表示的质量产生负面影响。
作者设计了一种简单但有效的归一化方法,用于加速度计和磁力计的读数,以缩小范围差异,同时尽量不显著改变它们的分布。表示为:
其中:
- acc_i 表示加速度计在 i 轴上的测量值;
- mag_i 表示磁力计在 i 轴上的测量值;
- \alpha 是一个权重参数,用于缩放磁力计读数的范围(默认为2)。
对于磁力计读数,使用其大小进行归一化,因为磁力计读数容易受到环境因素的影响(磁力计三个轴之间的关系仍然保留)。而对于陀螺仪读数,保持其原始分布,因为它们本身通常是较小的数值。
归一化后的IMU读数被划分为固定窗口 X \in \mathbb{R}^{S_{dim} \times L} ,其中 L 是每个窗口中归一化读数的数量, S_{dim} 是收集的IMU特征的维度。例如,如果仅收集加速度计和陀螺仪数据,则 S_{dim} = 6 (因为每个传感器有三个维度)。一个IMU样本 X 在本文中也被称为一个IMU序列。 X^u 和 X^l 分别表示无标签样本和有标签样本。每个有标签样本 X^l_{[i]} \in X^l 对应一个真实标签 Y_{[i]} \in Y 。
IMU传感器的一个关键特性是其特征数量 S_{dim} 较小。为了扩展特征维度并融合IMU传感器,作者将归一化的传感器数据 X 通过一个线性层投影到更高维空间:
其中, W 是一个大小为 H_{dim} \times S_{dim} 的矩阵, H_{dim} 是隐藏维度,且大于 S_{dim} 。与归一化后的传感器数据 X 相比, I 包含了更多的隐式特征。
接下来,LIMU-BERT 使用 LN 对同一测量时间点的融合特征进行归一化:
其中, \epsilon 是一个很小的值,而 \gamma 和 \beta 是学习超参数。 E(I_{.j}) 和 \text{Var}(I_{.j}) 分别表示第 j 列元素的均值和方差。通过学习归一化层的参数,神经网络可以动态地对IMU传感器的隐式特征进行归一化。
3.3 学习表征
根据对IMU数据的观察,单次读数的分布 和 连续读数之间的时间关系 都是关键特征。作者分析了BERT两种自监督任务(MLM和NSP)后,发现:
- NSP并不适合IMU数据,因为人类活动频繁切换,不像语言的强连贯性。
- MLM任务在IMU中具有双重意义 :
- (1) 通过重构被掩码的读数,模型可学习到数据的分布特征;
- (2) 生成被掩码部分的表示过程迫使模型学习上下文关系。
综上,作者采用MLM作为LIMU-BERT的核心自监督任务。
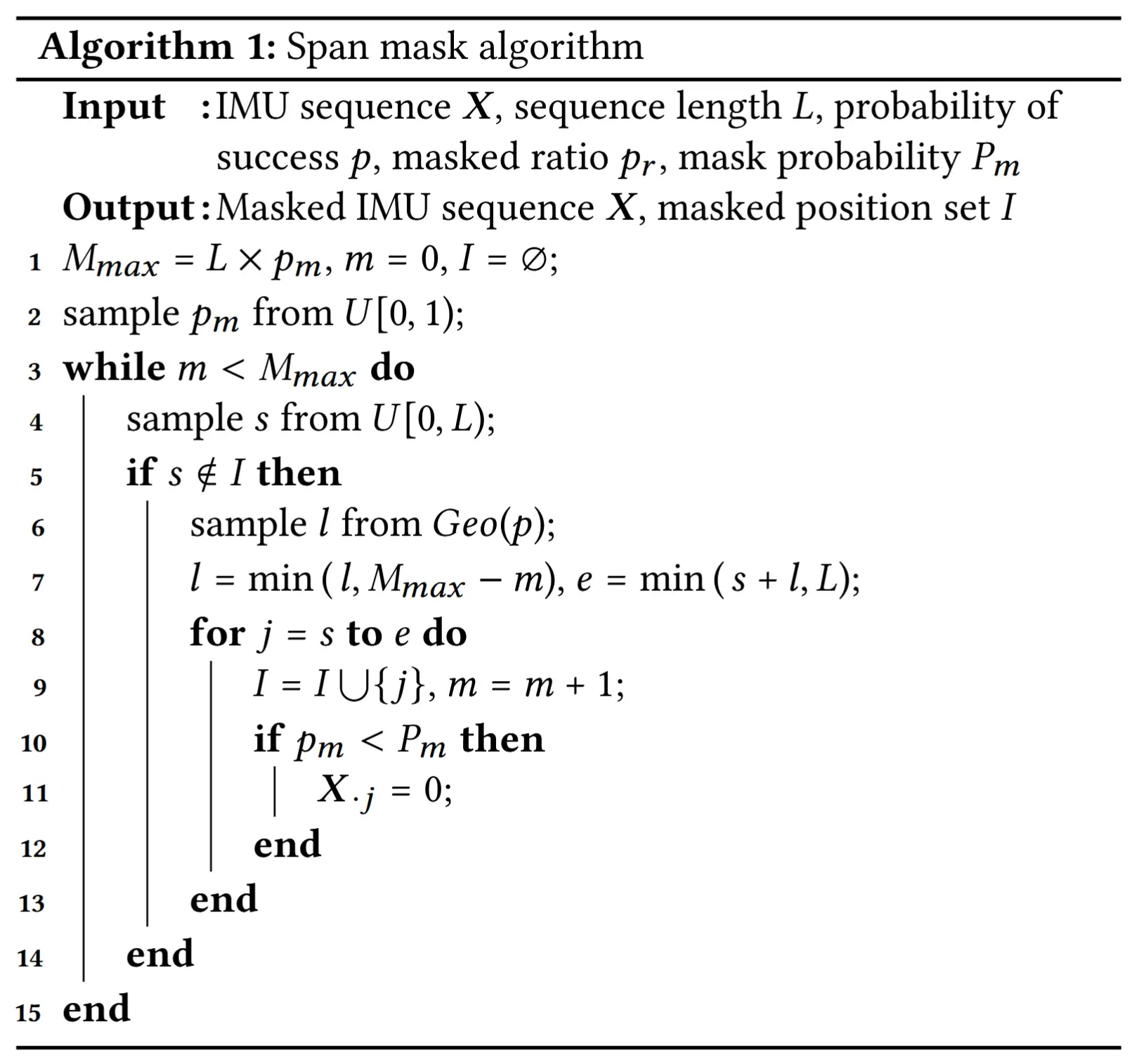
不同于BERT中MLM任务仅用一个标记掩码文本子序列,在IMU数据中,为了提供更具挑战性的条件并训练有效的模型,掩码更长的子序列。为了决定掩码子序列的长度,作者实现了一种Span Masking机制 [15],该机制从几何分布 \text{Geo}(p) 中采样掩码子序列的长度 l ,并在 l_{\text{max}} 处截断:
其中,成功概率 p 被设置为0.2, l_{\text{max}} 被设置为10。通过掩码更长的子序列,LIMU-BERT被迫更有效地学习IMU数据中的时间关系,并相应地从上下文中重构被掩码的子序列。(每个输入序列的IMU读数是在较长的时间段内(即6秒)收集的,包含更丰富的时序信息)
掩码方法的细节总结在算法1中。 U[a, b] 表示区间为 [a, b] 的离散均匀分布(第2行和第4行)。 M_{\text{max}} 是每个IMU序列中被掩码读数的最大数量(第7行),确保每次有 M_{\text{max}} 个读数被掩码。 s 和 e 分别是子序列的起始和结束索引。在第2行,从 [0, 1] 中采样 p_m ,仅当 p_m < P_m 时才进行掩码操作,即以概率 P_m 掩码数据。
由于监督学习阶段输入数据不会解掩码,导致两个阶段输入不同。为解决此问题,LIMU-BERT 学习处理未掩码和掩码数据。第11行将选中的读数值替换为0,掩码比例 p_r = 0.15 ,掩码概率 P_m = 0.8 。掩码位置集合 I 用于损失函数计算。
3.4 轻量化模型
LIMU-BERT 必须足够轻量,以便在移动设备上运行。为此,作者进行了以下定制化设计:
- 采用更低的采样率(20Hz)和表示维度 H_{dim}。现有研究六秒内100Hz采样率会使得序列长度 L=600 ,超过了BERT最大序列长度。并且 LIMU-BERT 的表示维度 H_{dim} 也小于原始 BERT。
- 引入跨层参数共享机制:LIMU-BERT 包含多个编码器层,但只有第一个编码器层的参数会被训练,其余层将共享该层的参数。
- 将 IMU 数据重建问题视为一个回归任务,而非分类任务:相比于分类任务中需要处理大量类别标签,回归任务可以避免使用复杂的输出层,从而大大简化了解码器结构。
3.5 LIMU-BERT 设计
自监督学习过程的详细工作流程如图3所示。
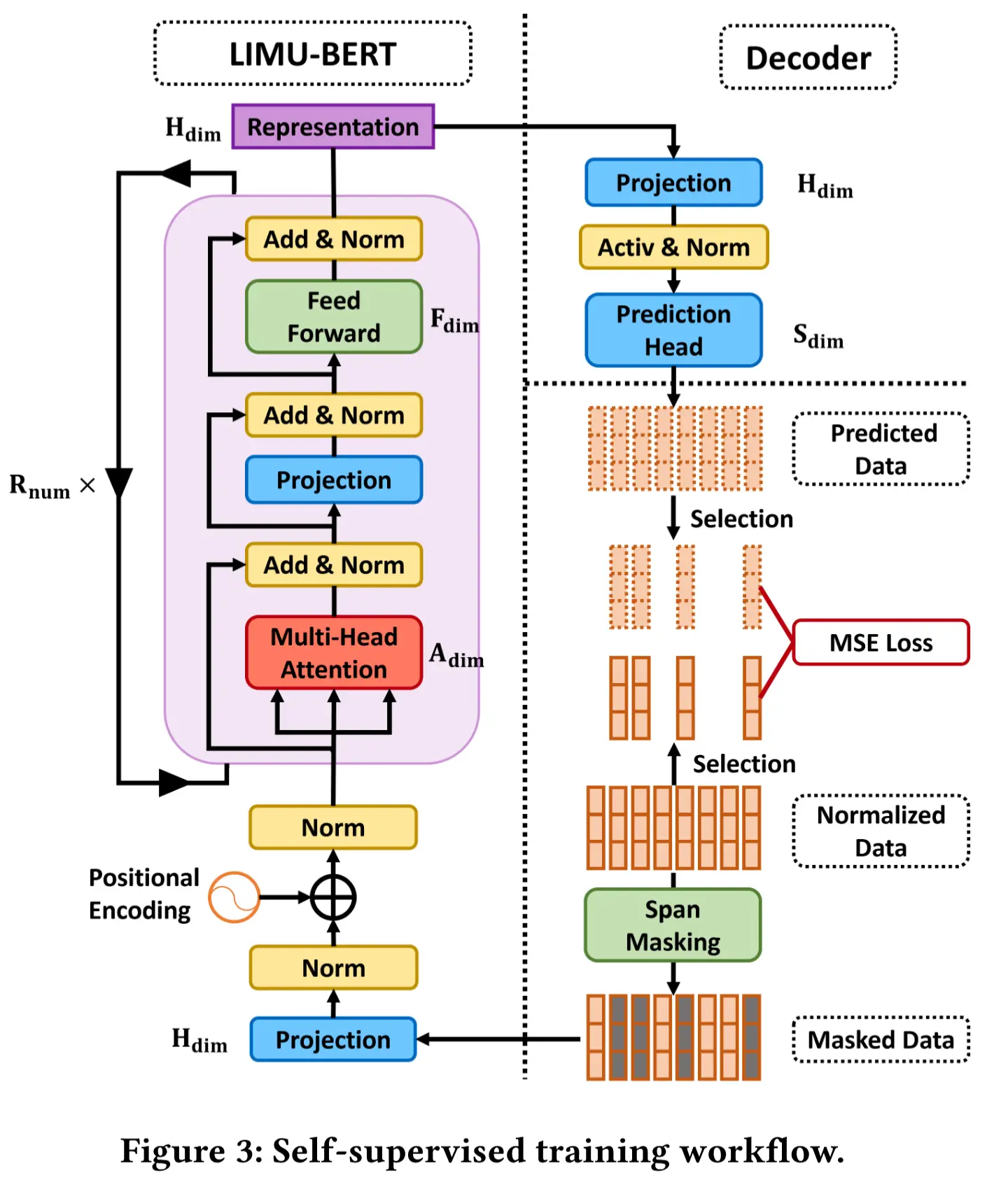
LIMU-BERT
LIMU-BERT 的目标是为无标签的 IMU 数据生成表示,其公式化如下:
其中, E 是一个 H_{dim} \times L 的矩阵。
首先,归一化数据 X 在输入到 LIMU-BERT 前进行掩码处理。第一个投影和层归一化组件分别实现方程(2) 和 (3) 。接下来添加位置编码,再经过第二层 LN,隐藏特征可以表示为
其中, PE(\cdot) 是位置嵌入函数,它将一个顺序(列)索引映射到一个长度为 H_{dim} 的向量。所有位置嵌入都是可训练的变量。 然后,注意力块(即图中的紫色矩形)将 H 作为输入,并重复 R_{num} 次后输出最终的表示,这一过程实现了跨层参数共享机制。注意力块中有三个残差块,可以表示为:
其中, r 是取值范围为 [1, R_{num}] 的整数。 \text{MultiAttn}(\cdot) 是一个包含 A_{num} 个头的自注意力层。 \text{Proj}(\cdot) 表示一个全连接层。 \text{FeedForward}(\cdot) 包含两个全连接层。在两个全连接层之间有一个GELU激活函数。最后,可以得到掩码 IMU 序列 X^m 的表示 E = H^{(R_{num})} 。
在 LIMU-BERT 中, R_{num} 和 H_{dim} 均设置为 4。根据之前的设计,在采样率为 20 Hz 的情况下,序列长度 L 设置为 120。
Decoder
解码器的目标是使用 LIMU-BERT 生成的表示来重构被掩码的 IMU 序列的原始值,其公式化如下:
其中, f_{\text{dec}} 包含三个组件:一个投影层、一个激活和归一化层,以及一个预测头。解码器可以公式化为:
其中, \text{Pred}(\cdot) 和 \text{Proj}(\cdot) 都是单个全连接层。最后,从被掩码的 IMU 序列中得到重构的 IMU 序列 \hat{X}^u 。
Training
正如我们之前提到的,重构问题被视为回归任务。因此,自监督阶段的损失函数定义如下:
其中, \text{MSE}(\cdot) 表示均方误差函数, |X^u| 是无标签样本的数量。仅计算被掩码的 IMU 子序列的重构损失。在自监督训练过程中,LIMU-BERT 和解码器的参数通过 Adam 优化器进行更新。
3.6 任务专用分类器设计
Classifier
使用无标签数据完成 LIMU-BERT 的训练后,它可以用于生成有标签 IMU 数据的特征表示。基于这些表示和对应标签,可通过 有监督学习 训练任务专用分类器,流程如图4所示。需要注意的是,这个阶段输入的 IMU 序列不会被掩码处理。

- 分类头设计:
- 由于输入的 IMU 序列时间较长,如果需要更细粒度的预测,可以对表示序列进行切片处理,从而设计出适用于具体任务的分类器。(可选步骤)
- 采用轻量级 GRU 分类器,由三个堆叠的GRU层组成,其隐藏层大小分别为20、20和10。
- 在GRU层之后,只有最后一个位置的隐藏状态被送入一个 dropout rate 为0.5的Dropout层,以减少过拟合。
- 随后是两个具有10个隐藏单元的全连接层,最后接一个Softmax层输出类别概率。
- 分类头替代方案
- 第一种替代方案使用了注意力机制,其中注意力组件的隐藏维度设置为36;
- 第二种是基于CNN的分类器,它包含三个2D卷积层,分别具有8、16和4个特征图,卷积核大小均为 (3,3);每个卷积层后接一个最大池化层,池化核大小为 (3,3),步长为 (2,1);
Training
为了支持多类别分类任务,作者在训练过程中采用了交叉熵损失函数(Cross Entropy Loss)。
需要注意的是,在有监督训练阶段,仅更新任务专用分类器的参数,LIMU-BERT 的参数保持冻结状态。
4 实验
4.1 实验设定
- 数据集:HHAR\UCI\MotionSense\Shoaib
- 预处理
- 首先将采样率下采样至 20 Hz ,并将连续的 IMU 数据切分为长度为 120 个测量值 的窗口,窗口之间无重叠。
- 按照8:1:1划分训练集、验证集和测试集。其中训练集进一步划分为99%的无标签和1%的有标签。
- 基线
- LIMU-GRU:基于本文框架构建的分类模型。其输入为 LIMU-BERT 学习到的特征表示,分类器采用第3.6节中介绍的 GRU 结构。
- DCNN [49] 一种基于深度卷积神经网络(CNN)的模型。
- DeepSense [51] :该模型采用深度结构融合多传感器数据并提取时序特征。
- TPN [33] :通过训练一个多任务时序 CNN 来识别施加在输入数据上的多种变换操作,然后将该 CNN 迁移至 HAR 分类任务中。
- R-GRU :作者实现的简单基线,直接在原始 IMU 数据上应用 GRU 分类器,不经过预训练或特征提取阶段。
- 超参数见论文。
- 评价指标:准确率和Macro F-score
4.2 HAR任务评估
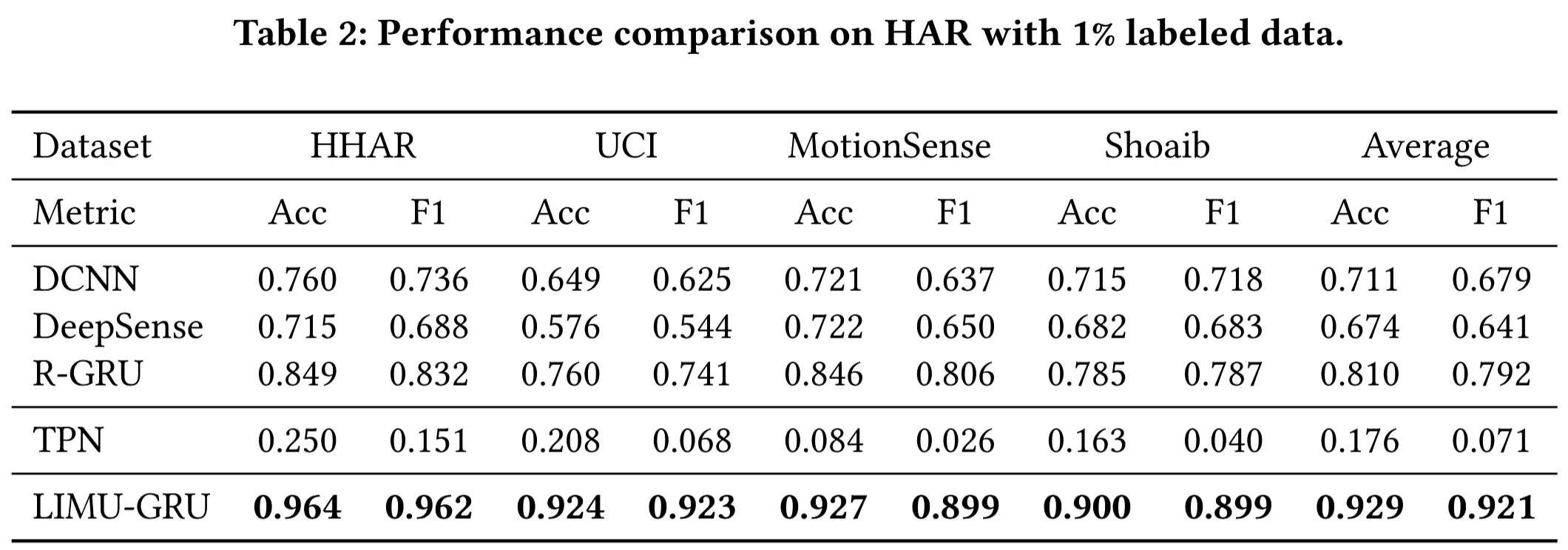
- 总体性能
- 表2展示了在 HAR 任务中的性能对比。
- 在所有数据集上,LIMU-GRU 均大幅优于其他基线模型
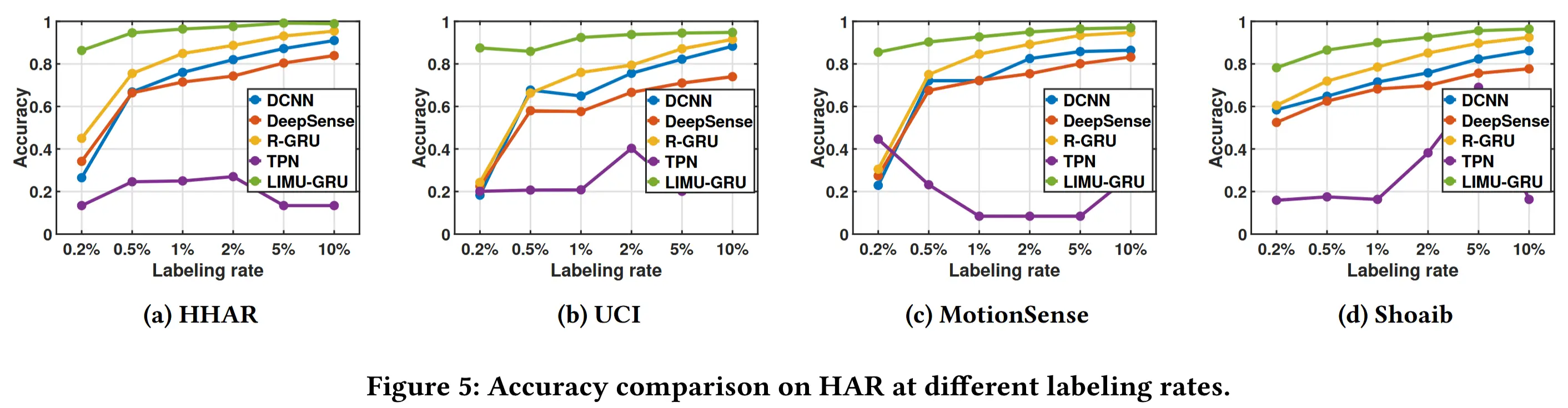
- 不同标注率性能对比
- 目的:评估 LIMU-GRU 在不同标注率(0.2% ~ 10%)下的泛化能力。
- LIMU-GRU 在所有标注率下均显著优于其他模型 ;
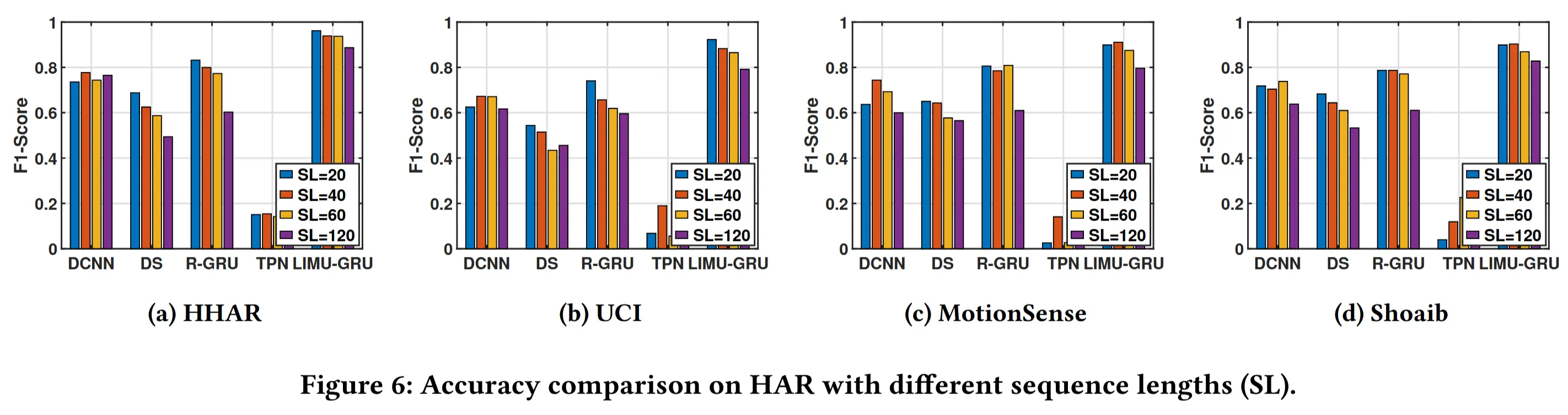
- 不同序列长度性能对比
- 目的:验证 LIMU-GRU 的性能提升是来源于从无标签数据中学到的通用表示,而非仅仅因为使用了更长的 IMU 序列。
- LIMU-GRU 在所有序列长度下均表现最优 ;
- 这里随着序列长度增加,性能有所下降,作者猜测有两个原因:一是因复杂度增加而出现过拟合,性能反而下降;二是更长的序列意味着更少的训练样本,加剧了标注不足的问题。
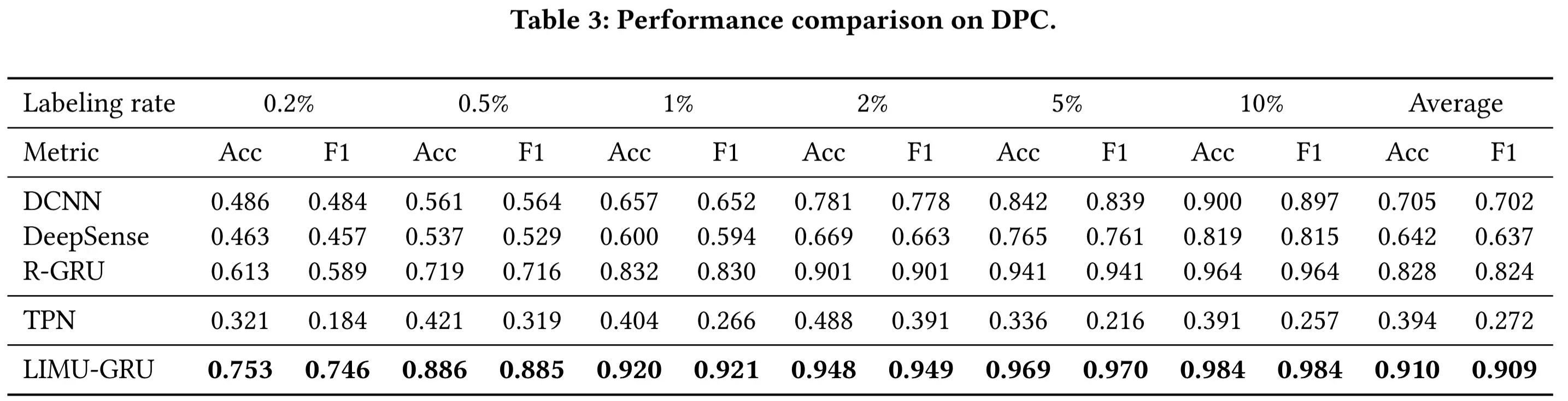
4.3 设备放置分类评估
- 设备放置分类(DPC)评估
- 目的:验证 LIMU-BERT 在设备放置分类任务(DPC)中的泛化能力。
- 在 Shoaib 数据集 上测试 LIMU-GRU 与其他模型的性能(仅该数据集包含设备放置的真实标签)。
- LIMU-GRU 在所有标注率下均优于所有基线模型。