- 论文 - 《Time-Series Representation Learning via Temporal and Contextual Contrasting》
- 代码 - Github
- 关键词 - IJCAI-21、时序表征学习、对比学习、人体活动识别HAR、睡眠阶段检测、
1 引言
-
时间序列数据
- 时间序列数据通常不具备人类可识别的明显模式,更难标注。
- 而深度学习方法依赖大量标注数据,这限制了这些方法应用于数据序列数据。
-
自监督学习
- 从未标注数据中提取有效的表征以用于下游任务。
- 各种自监督方法依赖于不同的预训练任务来训练模型并从无标签数据中学习表征,例如解谜任务和预测图像旋转角度。然而,这些预训练任务可能会限制所学表征的通用性。
-
本文研究问题:在无标签的时间序列数据中学习到良好的表征,同时捕捉其时间动态特性。
-
对比学习
- 该方法首先通过数据增强技术生成输入图像的不同视角(views),然后通过最大化来自同一样本的不同视角之间的相似性,并最小化与来自其他样本视角之间的相似性来学习表征。。
- 基于图像的对比学习方法难以很好地适用于时间序列数据,原因如下:
- 它们可能无法有效捕捉时间序列的关键特性——时间依赖性。
- 一些用于图像的增强技术(如颜色扰动)通常不适用于时间序列数据。
- 截至目前,针对时间序列数据的对比学习研究还较少。
-
本文工作 - TS-TCC
- 一种基于时序与上下文对比的时间序列表征学习框架。
- 首先,采用简单但高效的数据增强方法,适用于任何类型的时间序列数据,并据此生成两个不同但相关的输入视角。
- 接下来,作者提出了一种新的时间对比模块,通过设计一个具有挑战性的跨视角预测任务来学习鲁棒的表征:在某一时间步上,该模块利用一个增强视图中的过去潜在特征来预测另一个增强视图中的未来状态。这一新颖的操作将迫使模型通过更难的预测任务来学习对不同时间步和增强所带来的扰动具有鲁棒性的表征。
- 此外,作者还提出了一个上下文对比模块,以在时间对比模块所学得的鲁棒表征基础上进一步学习具有判别能力的表征。在该上下文对比模块中,我们的目标是最大化同一样本不同上下文之间的相似性,同时最小化不同样本之间上下文的相似性。
-
实验性能
- 在提出的 TS-TCC 所学到的特征之上训练线性分类器,其性能可以与监督训练相媲美。
- TS-TCC 在少量标签数据和迁移学习场景下也表现出很高的效率。
2 相关工作
2.1 自监督学习
- 对比学习方法通过从增强数据中学习不变表征开始崭露头角。
- MoCo 利用动量编码器(momentum encoder)从记忆库中获取负样本对来进行表征学习;
- SimCLR 通过使用更大的负样本批次代替了动量编码器;
- BYOL 甚至无需使用负样本,通过“自我引导”(bootstrapping)方式学习表征;
- SimSiam 支持忽略负样本的思想,仅依赖 Siamese 网络和停止梯度操作(stop-gradient)就达到了最先进的性能。
- 局限:这些方法是为了视觉特征设计的,由于时间序列数据具有不同的特性(如时间依赖性),这些方法可能无法直接适用于时间序列数据。
2.2 时间序列的自监督学习
- 一些研究尝试将预训练任务应用于时间序列数据。
- [Saeed 等, 2019] 在人类活动识别任务中,通过对数据应用多种变换并训练模型区分原始数据与变换后的数据,设计了一个二分类的预训练任务;
- SSL-ECG 方法 [P. Sarkar, 2020] 通过对心电图(ECG)数据应用六种变换,并根据变换类型分配伪标签,从而学习 ECG 表征;
- [Aggarwal 等, 2019] 通过建模局部与全局活动模式,学习对个体不敏感的表征。
- 一些研究尝试将对比学习用于时间序列数据。
- CPC(Contrastive Predictive Coding)[Oord 等, 2018] 通过在潜在空间中预测未来状态,在语音识别任务中取得了显著进展;
- [Mohsenvand 等, 2020] 设计了针对脑电图(EEG)的增强方法,并将 SimCLR 模型 [Chen 等, 2020] 扩展到 EEG 数据。
- 局限:现有方法通常只利用了时间序列的时间特征或全局特征。
- 本文不同之处:作者首先通过设计专门针对时间序列的数据增强方法,构建输入数据的不同视角;其次,作者提出了新的跨视角的时间与上下文对比模块,以提升时间序列的表征学习效果。(时间特征+全局特征)
3 方法
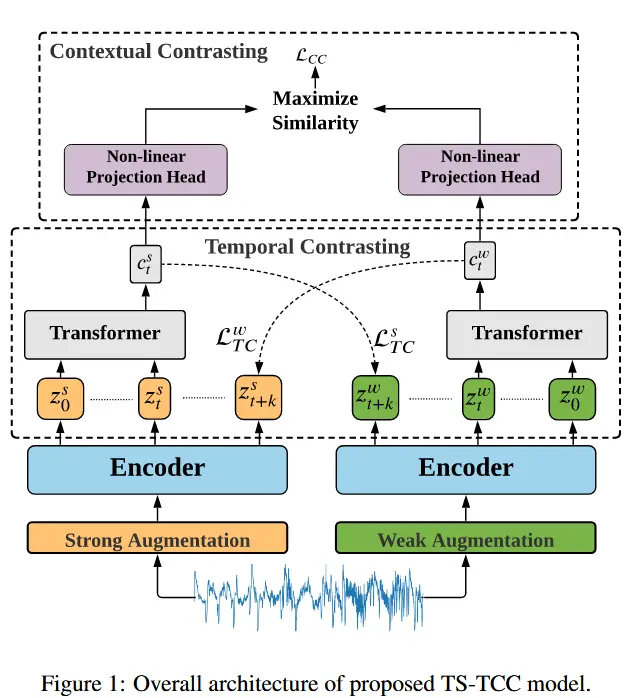
TS-TCC 框架如图1所示,首先基于强增强和弱增强方法,生成两个不同但相关的输入数据视角(views)。接着,使用一个时间对比模块,通过自回归模型来探索数据中的时间特征。最后,使用一个上下文对比模块,用于最大化来自同一样本但不同视角下自回归模型所提取上下文之间的一致性。
3.1 时间序列数据增强
传统的对比学习方法会使用同一种增强策略生成两个随机变体 x_1 和 x_2,即 x_1 \sim \mathcal{T} 和 x_2 \sim \mathcal{T}。然而,作者认为使用不同的增强策略可以提高所学表征的鲁棒性。因此,作者提出采用两种独立的增强方法,其中一种是弱增强,另一种是强增强。
- 弱增强 - “抖动与缩放”(jitter-and-scale)策略,在信号上添加随机扰动,并调整其幅度。
- 强增强 - “置换与抖动”(permutation-and-jitter)策略,其中置换包括将信号分割成随机数量的片段(最大值为 M),随机打乱这些片段并添加随机抖动。
值得注意的是,增强超参数的选择应根据时间序列数据的特性仔细确定。例如,较长序列的数据应用置换时的 M 值应该大于较短序列中的 M 值、归一化的时间序列数据抖动比例应远小于未归一化数据的抖动比例。
对于每个输入样本 x,将它的强增强视图表示为 x^s,弱增强视图表示为 x^w,其中 x^s \sim \mathcal{T}_s 和 x^w \sim \mathcal{T}_w。这些视图随后被传递给编码器以提取高维潜在表征。特别地,编码器采用三层卷积架构。对于输入 x,编码器将其映射到一个高维潜在表征 \mathbf{z} = f_{\text{enc}}(x)。我们定义 \mathbf{z} = [z_1, z_2, \dots, z_T],其中 T 是总的时间步数,z_i \in \mathbb{R}^d,其中 d 是特征长度。因此,可以得到强增强视图的表征 \mathbf{z}^s 和弱增强视图的表征 \mathbf{z}^w,然后将它们输入到时间对比模块中。
3.2 时间对比
时间对比模块通过对比损失在潜在空间中使用自回归模型提取时间特征。给定潜在表征 \mathbf{z},自回归模型 f_{ar} 将所有 \mathbf{z}_{\leq t} 汇总为一个上下文向量 c_t = f_{ar}(\mathbf{z}_{\leq t}),其中 c_t \in \mathbb{R}^h,h 是 f_{ar} 的隐藏维度。该上下文向量 c_t 然后被用于预测从 z_{t+1} 到 z_{t+k}(1 \leq k \leq K)的时间步。为了预测未来的时间步,采用 log-bilinear model(对数双线性模型),以保持输入 x_{t+k} 和 c_t 之间的互信息,使得 f_k(x_{t+k}, c_t) = \exp((\mathcal{W}_k(c_t))^T z_{t+k}),其中 \mathcal{W}_k 是一个线性函数,将 c_t 映射回与 z 相同的维度,即 \mathcal{W}_k: \mathbb{R}^{h \to d}。
在本文方法中,强增强生成 c_t^s,而弱增强生成 c_t^w。作者提出了一项具有挑战性的跨视角预测任务:利用强增强的上下文 c_t^s 来预测弱增强的未来时间步 z_{t+k}^w,反之亦然。对比损失试图最小化预测表征与同一样本的真实表征之间的点积,同时最大化其与小批量内其他样本 \mathcal{N}_{t,k} 的点积。因此,我们计算两个损失 \mathcal{L}_{TC}^s 和 \mathcal{L}_{TC}^w 如下:
作者使用 Transformer 作为自回归模型,因为它具有高效性和速度,并且将 L 个相同的 Transformer 层堆叠起来生成最终特征。受 BERT 模型的启发,在输入中添加了一个标记 c \in \mathbb{R}^h,其状态在输出中充当代表性的上下文向量。
Transformer 的操作首先将特征 \mathbf{z}_{\leq t} 应用到一个线性投影层 \mathcal{W}_{Tran},该层将特征映射到隐藏维度,即 \mathcal{W}_{Tran}: \mathbb{R}^d \to \mathbb{R}^h。线性投影的输出然后传递给 Transformer,即 \tilde{\mathbf{z}} = \mathcal{W}_{Tran}(\mathbf{z}_{\leq t}),\tilde{\mathbf{z}} \in \mathbb{R}^h。接下来,将上下文向量附加到特征向量中,使得输入特征变为 \psi_0 = [c; \tilde{\mathbf{z}}],其中下标 0 表示输入到第一层。然后,将 \psi_0 通过 Transformer 层,如下式所示:
最后,从最终输出中重新附加上下文向量,使得 c_t = \psi_L^0。这个上下文向量将成为后续上下文对比模块的输入。
3.3 上下文对比
上下文对比模块旨在学习更具判别性的表征。它首先通过一个非线性投影头对上下文进行非线性变换,类似于中的方法。投影头将上下文映射到上下文对比所应用的空间中。
给定一批 N 个输入样本,每个样本将从其两个增强视图中生成两个上下文,因此共有 2N 个上下文。对于一个上下文 c_t^i,我们将来自同一输入的另一个增强视图中的上下文 c_t^{i+} 定义为 c_t^i 的正样本,因此 (c_t^i, c_t^{i+}) 被视为一个正样本对。同时,来自同一批次中其他输入的剩余 (2N-2) 个上下文被视为 c_t^i 的负样本,即 c_t^i 可以与它的负样本形成 (2N-2) 个负样本对。因此,可以推导出一个上下文对比损失。
公式 (5) 定义了上下文对比损失函数 \mathcal{L}_{CC}。对于一个上下文 c_t^i,将它与其正样本 c_t^{i+} 的相似性除以其与其他所有 (2N-1) 个样本(包括正负样本对)的相似性,以归一化损失:
其中,\text{sim}(u, v) = u^T v / \|u\| \|v\| 表示 \ell_2 归一化后的 u 和 v 之间的余弦相似度,\mathbb{1}_{[m \neq i]} \in \{0, 1\} 是一个指示函数,当且仅当 m \neq i 时取值为 1,而 \tau 是温度参数。
总体自监督损失是两个时间对比损失和上下文对比损失的组合:
其中,\lambda_1 和 \lambda_2 是固定的标量超参数,表示每个损失的相对权重。
4 实验
4.1 实验设置
- 数据集
- 人体活动识别 UCI-HAR
- 睡眠阶段分类 Sleep-EDF
- 癫痫发作预测 Epileptic Seizure Recognition
- 故障诊断 FD
- 按照6:2:2划分训练集、验证集和测试集。
- 增强策略的超参数、学习率、Transformer参数等见论文。
4.2 与基线对比
- 基线方法
- Random Initialization:在随机初始化的编码器之上训练一个线性分类器;
- Supervised:对编码器和分类器都进行端到端的监督训练;
- SSL-ECG [P. Sarkar, 2020];
- CPC [Oord 等, 2018];
- SimCLR [Chen 等, 2020]:使用了针对时间序列的数据增强策略以适配本文任务。
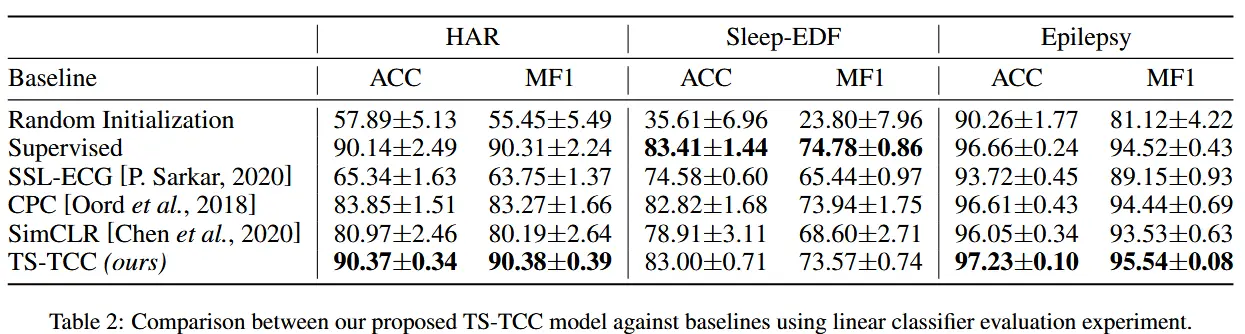
- 表2展示了我们的方法与基线方法在线性评估下的表现。
- TS-TCC 超过了所有三种最先进的方法。
- 对比学习方法(如 CPC、SimCLR 和我们的 TS-TCC)通常比基于预训练任务的方法(如 SSL-ECG)表现更好,说明对比学习能够学到更具不变性的特征。
4.3 半监督训练
- 半监督设置
- 分别使用训练集中 1%、5%、10%、50% 和 75% 的随机样本进行训练。
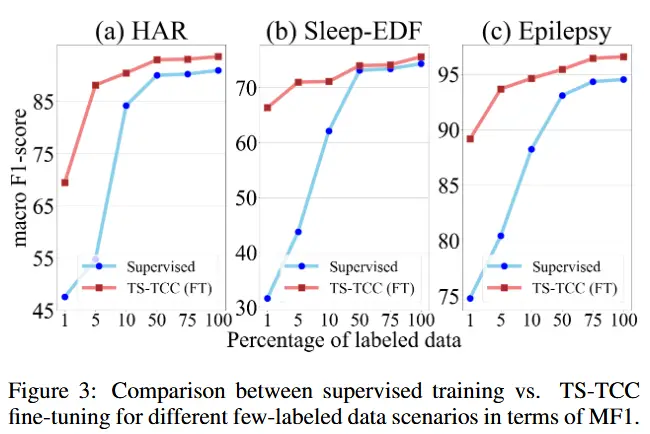
- 图3展示了结果:
- 在标签数据有限的情况下,监督训练效果较差,而 TS-TCC 微调在仅使用 1% 标签数据 的情况下就显著优于监督训练。
- 使用 仅 10% 的标签数据 进行 TS-TCC 微调的效果即可与使用 100% 标签数据 的监督训练相媲美,这充分体现了 TS-TCC 在半监督场景下的高效性和实用性。
4.4 迁移学习实验
- 在故障诊断(FD)数据集上评估模型在跨域场景下的表现。
- 具体来说,在一个工作条件(即源域)上训练模型,在另一个工作条件(即目标域)上进行测试。
- 表3展示了在12种跨域场景下的两种训练方式的表现。
- 总体而言,与监督训练相比,我们提出的方法在准确率方面平均提升了约 4%,显示出其更强的迁移能力。

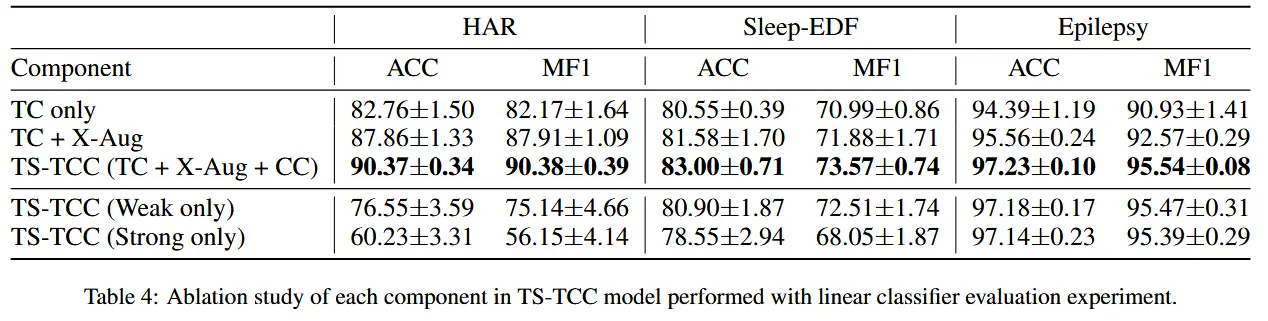
4.5 消融实验
- 构建了以下几种变体模型进行对比:
- 仅时间对比模块(TC only):不使用跨视角预测任务,每个分支只预测自己增强视图的未来时间步;
- 加入跨视角预测的时间对比模块(TC + X-Aug):在 TC 模块中引入跨视角预测任务;
- 完整 TS-TCC 模型(TC + X-Aug + CC):在上述基础上加入上下文对比模块;
- 使用****单一增强类型的 TS-TCC
- 表4展示了消融实验结果