- 论文 - 《Leveraging Foundation Models for Zero-Shot IoT Sensing》
- 代码 - Github
- 关键词 - 零样本学习、IMU、人类活动识别HAR、大模型、WiFi、毫米波mmWave、对比学习
摘要
- 研究问题
- 边缘物联网IoT上的深度学习模型通常在监督条件下运行,无法识别与训练数据不同的未见类别。零样本学习(ZSL专门解决这个问题
- 然而,利用FMs的泛化知识来实现基于毫米波、惯性测量单元(IMU)和Wi-Fi等信号的零样本物联网感知尚未得到充分研究。
- 本文工作
- 作者将物联网数据嵌入与基础模型文本编码器生成的语义嵌入进行对齐,以实现零样本物联网感知。
- 为了利用控制物联网传感器信号生成的物理原理,从而提取更有效的用于语义嵌入的提示,作者提出使用交叉注意力机制,将一个在训练数据上自动优化的可学习软提示与一个编码了物联网感知任务领域知识的辅助硬提示相结合。
- 为了解决由于训练过程中缺乏未见类别数据而导致物联网嵌入偏向已见类别的问题,作者提出通过数据增强合成未见类别的物联网数据,并用于微调物联网特征提取器和嵌入投影器。
1 引言
- 研究意义/为什么将零样本学习用于物联网感知任务?
- 由于物联网数据缺乏可读性,并且需要昂贵的标注过程,物联网数据集通常只包含有限数量的类别。
- 零样本学习ZSL:借助语义信息的帮助,将知识从已见类转移到未见类,从而实现对未见类数据的分类。
- 本文目的:旨在探索使用基础模型,该类模型被认为通过对多样化和大规模训练数据的学习,具备了对世界的泛化理解能力,从而生成更有效且上下文相关的语义嵌入,用于零样本物联网感知。
- 本文工作
- 通过将基于毫米波、IMU和Wi-Fi信号的物联网数据嵌入与基础模型文本编码器生成的语义嵌入进行对齐,从而利用FMs的泛化知识实现零样本物联网感知。
- 首先,物联网传感器信号通常遵循一定的物理规律,这些规律为生成鲁棒语义嵌入的有效提示工程提供了强有力的监督信息。为了解决这一问题,我们采用交叉注意力机制,将一个通过训练数据自动优化的可学习软提示与一个编码领域知识的辅助硬提示相结合。
- 其次,由于训练过程中仅涉及已见类数据,零样本学习模型容易偏向已见类。为了解决这种偏差问题,我们提出使用数据增强方法合成未见类别的物联网数据,并用于微调我们的物联网特征提取器和嵌入投影器。
- 方法工作流程
- 对类别标签进行提示工程处理,并使用FM的文本编码器提取其语义嵌入作为类别原型表示;同时,使用物联网特征提取器从物联网传感器信号中提取特征,并通过物联网嵌入投影器将这些特征投影到语义空间中。
- 在模型训练阶段,使用对比学习来对齐类别原型与物联网嵌入。
- 在零样本分类阶段,进行开放集检测以识别未见类别的数据,并利用FM进行零样本学习。
2 背景与相关工作
2.1 基础模型
- FMs用于其他模态
- 例如:音频、深度、IMU和红外 [34, 8]。
- 通常做法:这些多模态FMs使用基于transformer的编码器提取不同模态的嵌入特征。随后,通过对比学习学习一个联合嵌入空间,将不同模态的嵌入与一个“绑定”模态(即视觉或语言)的嵌入进行对齐。所学到的联合嵌入可用于多种任务,例如跨模态检索、跨模态生成以及通过算术组合不同模态。
- 本文不同之处
- 不同于现有专注于FMs在未见数据集 [18, 21] 或未观测数据对 [8, 34] 上的零样本迁移能力的研究,本工作旨在研究FM在分类任务中推广到未见对象类别的零样本能力,这种设置在物联网感知任务中更具实际意义。
2.2 零样本学习
- 零样本学习:借助包含已见类和未见类知识的语义信息,对未见类别的数据进行分类。传统的ZSL方法主要关注将数据分类到未见类别中
- 广义零样本学习(Generalized ZSL):对已见类和未见类的数据样本同时进行分类。
- GZSL 方法可分为基于嵌入和基于生成
- 基于嵌入的GZSL [2, 11] 学习从数据特征空间到语义空间的投影函数。其目标是将属于同一类别的数据嵌入映射到语义空间中的真实标签。易于实现,但由于训练过程中缺乏未见类数据特征,通常偏向于已见类。
- 基于生成的GZSL [25, 5] 则训练一个模型,基于已见类数据的特征和已见类与未见类的语义信息,生成未见类数据的合成特征。这些生成的未见类特征可用于监督学习,从而训练一个可对已见类和未见类数据样本进行分类的模型。基于生成的GZSL通过合成未见类特征缓解了偏向问题。然而,生成模型在训练过程中不稳定,且容易出现模型崩溃的问题。
2.3 零样本物联网感知
- 一些研究采用手工设计的属性或词向量(如Word2Vec、BERT、GloVe)构建语义空间用于零样本物联网感知,但存在扩展性差、任务无关噪声等问题。
- 文献 [22] 提出使用人类活动视频构建视觉语义空间,用于基于IMU的零样本人体活动识别,性能优于词向量方法。
- [33] 将多种物联网数据嵌入(包括视频、LiDAR和毫米波)与从CLIP 中提取的文本嵌入进行联合对齐,用于人类活动识别。通过这种统一的语义空间,不仅可以识别已见类的动作,还可以通过在语义空间中查找最近的文本嵌入来识别未见类的动作。然而,该方法需要在一个自建的多模态对齐数据集上进行联合训练,在现实中如果系统需要添加新的传感器模态,则其可用性受到限制。
- EdgeFM [27] 是一种边缘-云协同系统,它通过在云端利用基础模型进行选择性知识查询,使资源受限的边缘设备具备零样本识别能力。然而,其展示的零样本能力仅限于基础模型已支持的模态,包括视频、图像和音频。
3 问题定义
我们针对由边缘-云协同系统支持的深度学习驱动的物联网感知任务,该系统包含以下组件:
- 边缘设备:运行一个小型DNN f(\cdot) ,可以对一组已见类别 \mathcal{S} = \{c_i^s\}_{i=1}^{N_s} 进行分类。该模型 f(\cdot) 在监督设置下使用已见训练集 D^s = \{(\mathbf{x}_i^s, y_i^s)\}_{i=1}^{N_{train}} \in \mathcal{X} \times \mathcal{S} 进行训练,其中 \mathbf{x}_i^s \in \mathbb{R}^d 是原始物联网数据,y_i^s 是真实标签,\mathcal{X} 表示物联网数据空间。测试数据包括已见类别和未见类别的样本,表示为 D^{test} = \{\mathbf{x}_i^{test}\}_{i=1}^{N_{test}} \in \mathcal{X} 。
- 云端服务器:运行一个大型基础模型 \Phi(\cdot),云端维护一份感兴趣的未见类别列表 \mathcal{U} = \{c_i^u\}_{i=1}^{N_u},这些类别位于已见类别集合 \mathcal{S} 之外。注意,\mathcal{U} 可以由用户指定,也可以包括物联网感知任务中常见的已见类别。
主要目标是有效实现以下两个步骤:
- 在本地边缘设备上检测来自未见类别的数据样本 \mathbf{x}^u,并将其输入到专用 DNN f(\cdot) 中;
- 利用云端的 FM \Phi(\cdot) 对检测到的未见类别数据进行零样本分类,为其分配正确的标签 y^u \in \mathcal{U}。
为了实现这一目标,对于每个传入的物联网数据样本,首先在边缘提取其物联网嵌入,并进行开放集检测。如果被认为已见类别样本,则使用本地专用 DNN 进行预测。否则,被认为是未见类别数据,则将其上传云端。
4 方法论
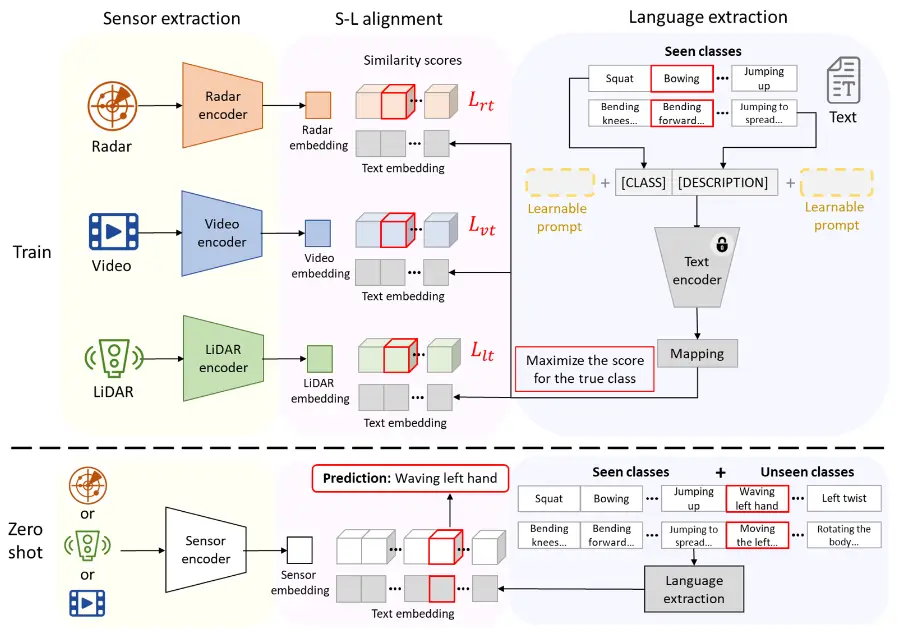
方法概述如图1所示,主要包括类别原型提取、物联网嵌入提取、模型训练和零样本分类模块。
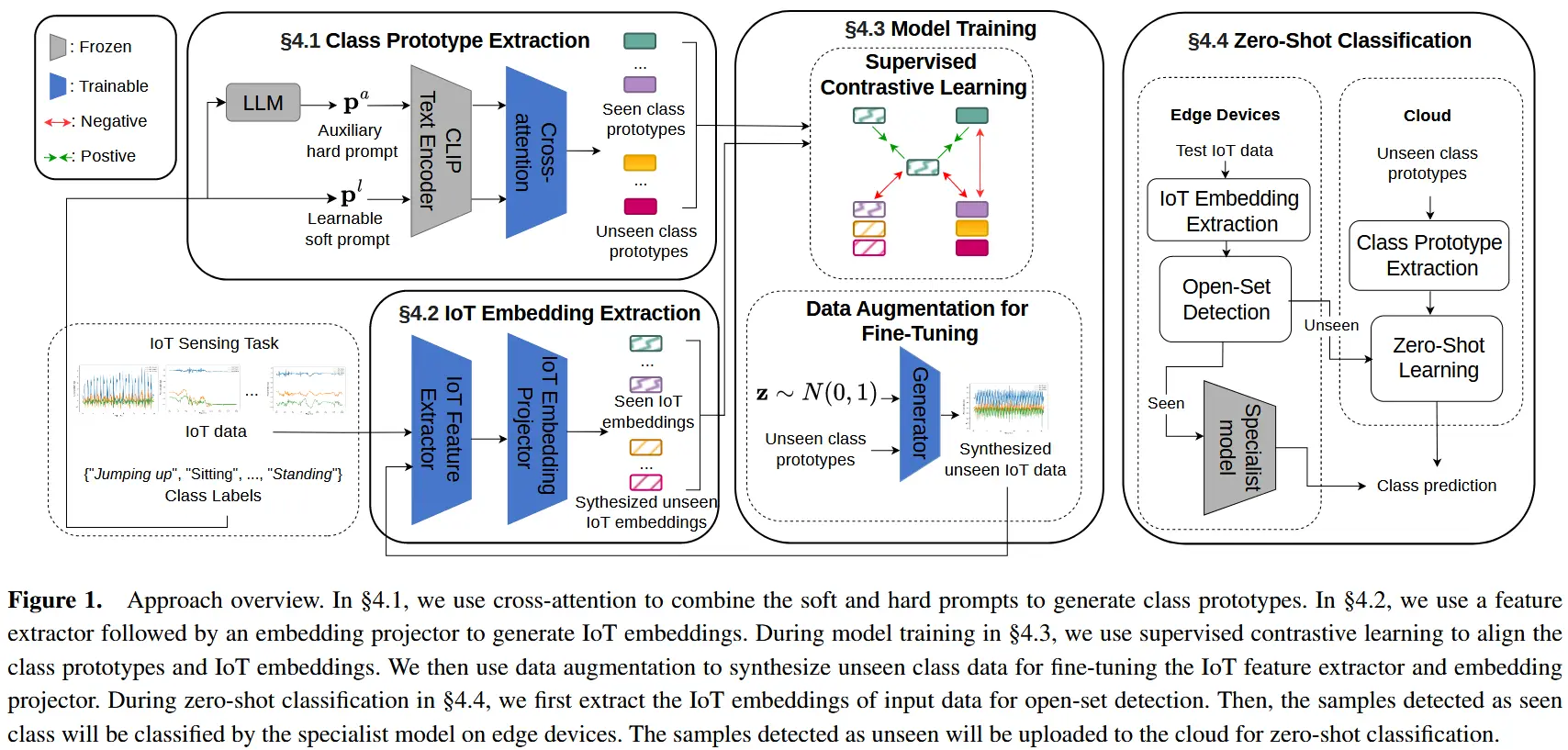
4.1 类别原型提取
在零样本学习中,类别原型封装了每个类的核心语义特征。推理时通过测量数据嵌入与类别原型的相似性来分类。本工作利用CLIP文本编码器从任务特定提示中提取类别原型,提示分为硬提示(自然语言指令)和软提示(可学习向量)。硬提示可整合领域知识但需手动设计,软提示能自动适应任务但缺乏可解释性。为结合两者优势,作者提出使用交叉注意力机制融合软提示和硬提示,生成有效且全面的类别原型。
可学习的软提示
CLIP 中默认的提示是通过将类别名称插入预定义的提示模板中构建的,例如,“a photo of {class name}”。然而,这种固定的提示难以适应下游任务。为了解决这一问题并避免繁琐的手动提示工程,本文从头开始学习一个软提示,旨在将文本嵌入与物联网数据嵌入对齐。遵循文献 [32],在提示的中间位置放置类别标记。对于每个类别 c ,可学习的软提示 \mathbf{p}^l(c) 表示为:
其中 \oplus 表示拼接操作,\mathbf{l}_i, (i=1 \cdots M) 表示第 i 个可学习的标记向量, c 是类别名称,例如,“walking forward”。可学习的提示通过在训练数据上优化损失函数(公式1见4.3)进行训练。提取的可学习文本嵌入 \mathbf{t}^l(c) = \Phi_{\text{text}}(\mathbf{p}^l(c)) 具有与物联网数据嵌入相同的维度。学习到的提示标记向量 \mathbf{l}_i, (i=1 \cdots M) 对所有类别共享,且具有任务特定性。
辅助硬提示
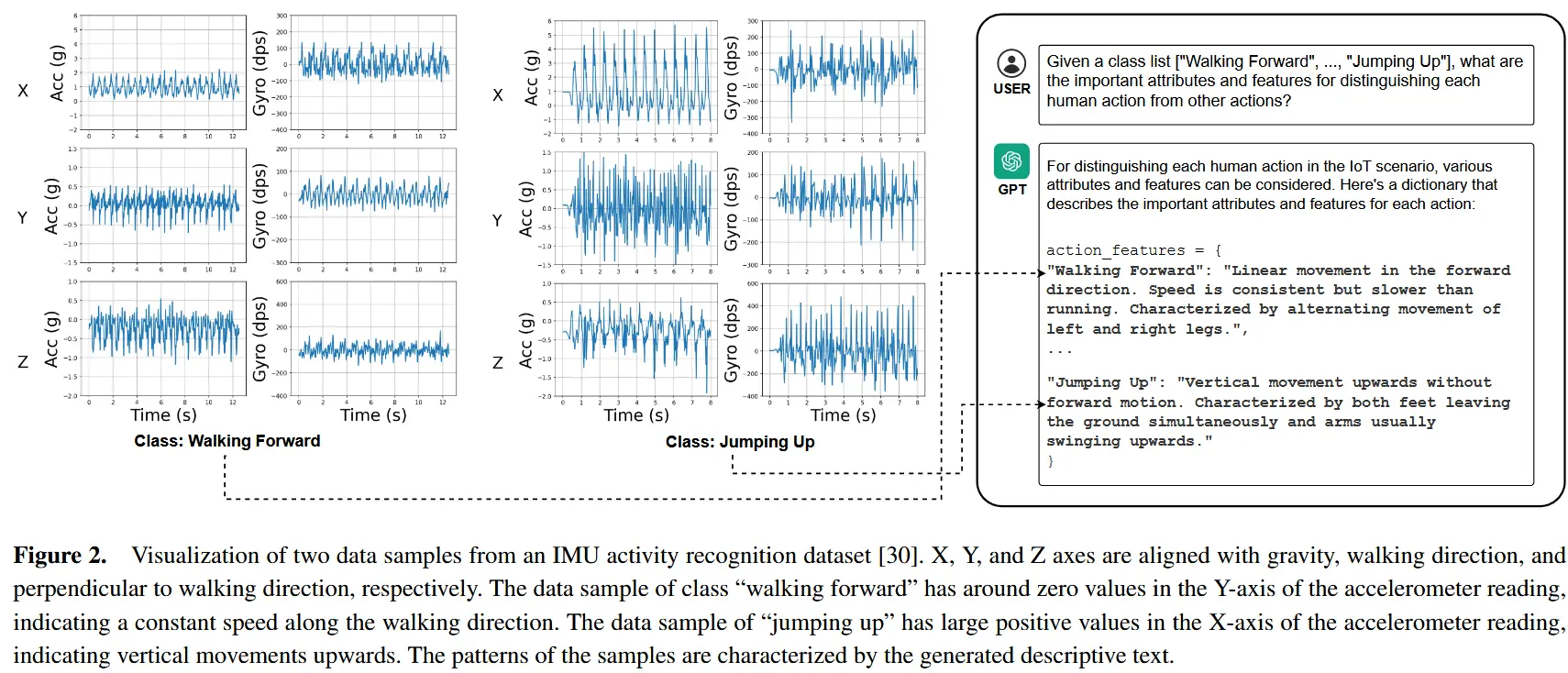
可学习的软提示通过在语义空间中对齐文本嵌入与物联网数据嵌入,提供任务特定上下文。物联网数据遵循物理原理,这些原理可作为提示设计的强大监督信息(如图2所示,USC-HAD [30] 数据集中两类样本模式不同)。为了利用控制物联网传感器信号生成的物理原理,进一步使用辅助硬提示提供类别特定信息,用于构建语义嵌入。
为了自动化这一过程,我们使用GPT-3.5生成类别条件描述性文本,具体步骤如下:首先将所有类别的列表输入LLM;然后,针对每个类别 c ,查询LLM:“如何区分类别 c 与其他类别?”, 随后对答案进行标记化,以导出辅助硬提示 \mathbf{p}^a(c),该提示将被输入到CLIP的文本编码器中,以生成辅助文本嵌入 \mathbf{t}^a(c) = \Phi_{\text{text}}(\mathbf{p}^a(c)),其维度与物联网嵌入相同。图2展示了部分由GPT生成的示例答案。
使用交叉注意力融合提示
为了结合可学习的软提示和辅助硬提示的优点,使用交叉注意力机制将两个提示的文本嵌入融合在一起。具体而言,将 \mathbf{t}^l 设置为 \mathbf{K},并将 \mathbf{t}^a 设置为 \mathbf{Q} 和 \mathbf{V}。核心思想是计算query和key输入之间的注意力权重,其中嵌入了 \mathbf{t}^a 中有用的类别特定上下文信息,然后使用这些权重聚合value输入 \mathbf{t}^l。具体来说,\mathbf{Q} = \rho_{\mathbf{Q}}(\mathbf{t}^l)、\mathbf{K} = \rho_{\mathbf{K}}(\mathbf{t}^a),以及 \mathbf{V} = \rho_{\mathbf{V}}(\mathbf{t}^l),其中 \rho_m(\cdot), (m \in \{\mathbf{Q}, \mathbf{K}, \mathbf{V}\}) 是单层全连接神经网络。\rho_m(\cdot) 在训练数据上优化,损失函数为4.3节中的公式1。
输出嵌入记,即类别原型记为:
其中 d_{\mathbf{K}} 是 \mathbf{K} 的维度。语义空间由所有类别原型的集合 \mathcal{T} = \{\mathbf{t}(c) \mid c \in \mathcal{S} \cup \mathcal{U}\} 构成。
4.2 物联网嵌入提取
对于每个物联网数据\mathbf{x}_i,首先使用一个特征提取器 \mu(\cdot) 提取其特征 \mathbf{h}_i = \mu(\mathbf{x}_i)。特征提取器 \mu(\cdot) 可以是CNN、ResNet或Transformer,取决于物联网感知模态。然后,使用一个嵌入投影器 g(\cdot),将物联网特征 \mathbf{h}_i 投射到与类别原型对齐的共享语义空间,并导出物联网嵌入 \mathbf{e}_i = g(\mathbf{h}_i)。
4.3 模型训练
训练阶段冻结CLIP的文本编码器 \Phi_{\text{text}}(\cdot),并采用监督对比学习策略进行模型训练。
监督对比学习
首先,在训练集 D^s 上联合训练软提示 \mathbf{p}^l、交叉注意力模块中的特征提取器 \mu(\cdot) 和物联网嵌入投影器 g(\cdot),使用监督对比损失。
在一个随机采样的批次数据 \{(\mathbf{x}_i^s, y_i^s)\}_{i=1}^{N_B} 中:
- 正样本对包括:(1) 同一类别中的两个物联网数据样本;(2) 一个物联网数据样本及其类别标签文本。
- 负样本对包括:(1) 属于不同类别的两个物联网数据样本;(2) 一个物联网数据样本和与其自身类别不同的类别标签; (3) 两个不同的类别标签。
令 i \in I \equiv \{1 \cdots N_B\} 表示训练批次中数据的索引,j \in J \equiv \{1 \cdots N_T\} 表示不同类别的索引。定义监督对比损失为:
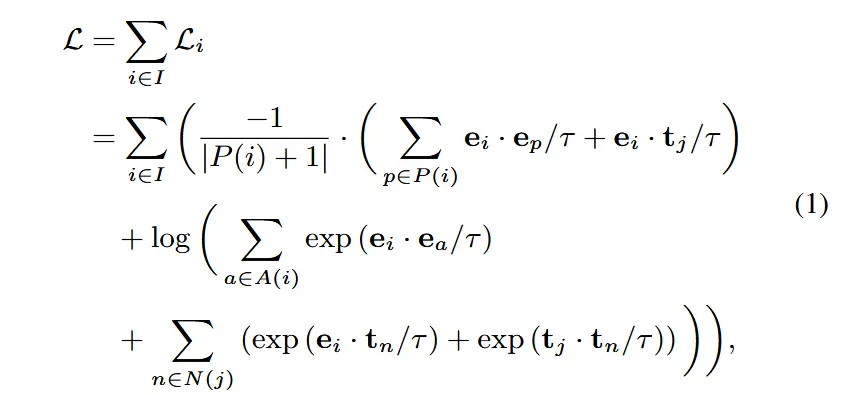
其中,对于每个物联网数据样本 \mathbf{x}_i,\mathbf{e}_i 是其物联网嵌入,\mathbf{t}_j 是其对应的类别原型,A(i) \equiv I \setminus \{i\},N(j) \equiv J \setminus \{j\},P(i) \equiv \{p \in A(i) : y_p = y_i\},而 \tau 是一个正温度标量。
数据增强用于微调
前面描述的模型训练过程仅在已见类别的数据上进行训练,因此,未见类别的物联网嵌入倾向于偏向已见类别。
为了解决这一偏差问题,作者提出在生成对抗网络(GAN)设置下训练一个生成模型,以合成未见类别的数据样本。使用增强后的未见类数据对物联网特征提取器和嵌入投影器进行微调。
给定训练集 D^s,学习一个条件生成器 G(\cdot),其输入为类别原型 \mathbf{t}(y) 和随机高斯噪声向量 \mathbf{z},旨在输出属于类别 y 的合成物联网数据 \tilde{\mathbf{x}} \in \mathcal{X}。注意,类别原型 \mathbf{t}(y) 由冻结的文本分支生成。为了实现这一目标,作者修改了 [25] 中的损失,并定义数据增强损失为:
其中,\mathcal{L}_{\text{WGAN}} = \mathbb{E}[D(\mathbf{x}, \mathbf{t}(y))] - \mathbb{E}[D(\tilde{\mathbf{x}}, \mathbf{t}(y))] - \xi \mathbb{E}\left[\left\|\nabla_{\tilde{\mathbf{x}}} D(\tilde{\mathbf{x}}, \mathbf{t}(y))\right\|_2 - 1\right]^2,其中 D(\cdot) 是判别器,\mathbf{x} 是真实数据,\tilde{\mathbf{x}} = G(\mathbf{z}, \mathbf{t}) 是生成的数据,\alpha \sim U(0, 1),\xi 是惩罚系数。\mathcal{L}_{\text{CLS}} = -\mathbb{E}[\log \Pr(y \mid \tilde{\mathbf{x}}; \theta)] 是由线性Softmax分类器计算的分类损失,该分类器由参数 \theta 控制,并在 D^s 上预训练。生成器的目标是最小化 \mathcal{L}_{\text{DA}}。
生成器 G(\cdot) 试图通过生成被认为是真实的物联网数据来欺骗判别器 D(\cdot),而判别器 D(\cdot) 则试图区分真实数据与合成数据。在生成器 G(\cdot) 训练完成后,使用它生成一个包含未见类别的合成训练集 D^{aug} = \{(\tilde{\mathbf{x}}_i^u, y_i^u)\}_{i=1}^{N_{aug}} \in \mathcal{X} \times \mathcal{U},并利用该合成训练集对物联网特征提取器和嵌入投影器进行微调,优化目标如公式 (1) 所示。
4.4 零样本分类
零样本分类分解为两个步骤:(1)在本地边缘设备上开放集检测。(2)云端的FM进行零样本学习。
开放集检测
二分类问题。作者开发了一种基于距离的方法来进行开放集检测。首先,基于训练集 D^s,根据数据样本的类别对物联网嵌入进行聚类,并将这些聚类表示为 \{E_i^s\}_{i=1}^{N_s},**其中 N_s 是已见类别的数量。**每个已见类簇 E_i^s \ (i = 1 \cdots N_s) 包含一组物联网嵌入 \{\mathbf{e}_{i,j}\}_{j=1}^{N_i},其中 N_i 是类簇 E_i^s 中的数据样本数量。对于输入测试样本 \mathbf{x}^{\text{test}} \in D^{\text{test}},计算其物联网嵌入 \mathbf{e}^{\text{test}} 与每个类簇中物联网嵌入之间的欧氏距离:
然后,对 d_{i,j} 进行排序,以获得每个类簇的第 k_i 小的距离,记为 d_i^{(k_i)}。使用基于阈值的准则来判断输入样本是否属于已见或未见类别:
其中,1 \big| \cdot \big| 是指示函数,\lambda_i 是通过经验决定的类别特定距离阈值,它通过验证集来确定。
零样本学习
对于检测到的“未见”测试样本 \mathbf{x}^{\text{det}},将其物联网嵌入 \mathbf{e}^{\text{det}} 上传到云端的FM进行零样本学习。具体而言,我们计算 \mathbf{e}^{\text{det}} 与所有类别原型 \{\mathbf{t}(c_i^u), c_i^u \in \mathcal{U}\} 之间的相似度分数,即点积。然后,具有最高相似度分数的类别被预测为 \mathbf{x}^{\text{det}} 的标签:
其中,\mathbf{t}(c_i^u) 是未见类别 c_i^u 的类别原型。
5 实验评估
5.1 实验设定
- 模态:IMU、mmWave、WiFi
- 数据集
- USC-HAD:采用了IMU数据,划分为 9 个已见类别和 3 个未见类别。
- PAMAP2:采用了IMU数据,划分为 9 个已见类别和 3 个未见类别。
- MM-Fi:采用了Wi-Fi和mmWave数据,划分为 22 个已见类别和 5 个未见类别。
- 采用 K 折交叉验证策略将每个数据集划分为已见类和未见类。
- 对于已见类别的数据样本,按照 8:1:1 的比例划分为训练集、验证集和测试集。测试集中已见类别和未见类别的样本数量相等。
- 对于所有模态,采用 ViT 作为物联网特征提取器。
- 其余超参数见论文。
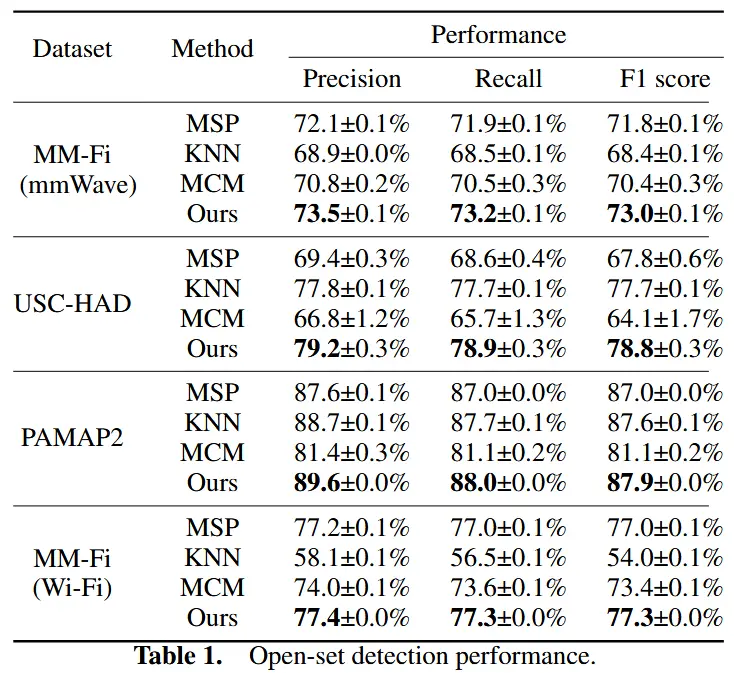
5.2 开放集检测性能
-
基线
- MSP:基于交叉熵损失训练的模型输出的最大 softmax 概率检测未见类。
- KNN:计算输入特征与训练集中第 k 个最近邻的距离进行检测,使用加噪等增强手段。
- MCM:通过图像特征与文本嵌入之间的距离判断是否为未见类,使用基础模型生成嵌入。
-
结果如表1所示
- 本文的监督对比损失能学习更具区分性的物联网嵌入。
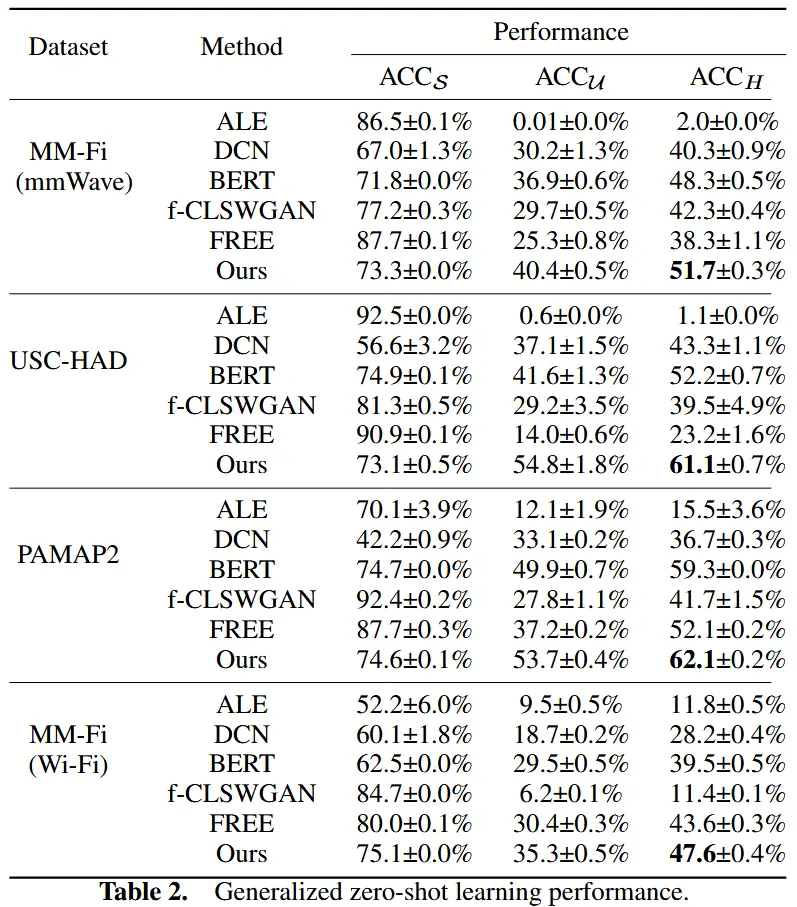
5.3 零样本分类性能
-
广义零样本学习基线
- ALE、DCN:基于嵌入的方法,通过图像特征与类别嵌入的匹配进行分类。
- BERT:使用预训练 BERT 替代 CLIP 文本编码器作为基线。
- f-CLSWGAN、FREE:生成式方法,通过生成未见类特征进行零样本学习。
-
评估指标
- 已见类准确率 ACC_S
- 未见类准确率 ACC_U
- 调和平均准确率 ACC_H = (2 × ACC_S × ACC_U) / (ACC_S + ACC_U) ,
- ACC_H 越低,说明偏向已见类越严重。
-
结果如表2所示
- 本文方法在所有数据集上均取得最高的 ACCU 和 ACCH,表明其在未见类识别中表现最佳,并有效缓解了对已见类的偏差问题。
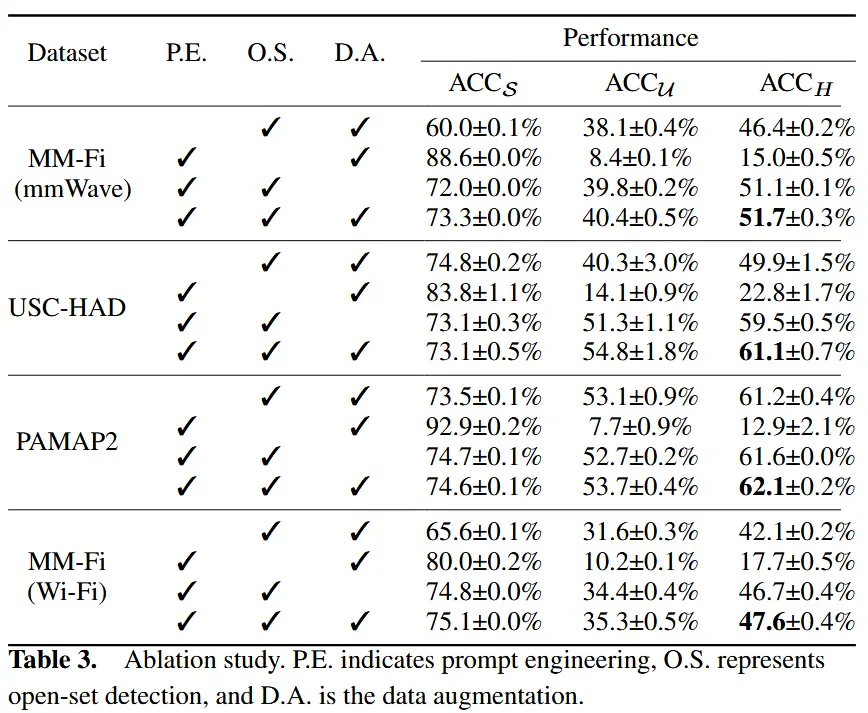
5.4 消融实验
为分析提示工程、开放集检测和数据增强模块的有效性,我们进行了消融实验,逐一移除这些组件,结果如表3所示。
- 提示工程:使用固定提示模板 “The human action of [CLASS]” 替代可学习提示。导致ACC_U和ACC_H显著下降。
- 开放集检测:移除开放集检测模块,直接将物联网嵌入与所有类别(已见+未见)进行匹配。虽然ACC_S上升,但 ACC_U 和 ACC_H 明显下降。
- 数据增强:不使用合成的未见类数据进行模型微调。ACC_U 下降