- 论文 - 《IMU2CLIP: Multimodal Contrastive Learning for IMU Motion Sensors from Egocentric Videos and Text》
- 代码 - Github
- 关键词 - Meta工作、多模态学习、IMU建模、对比学习、CLIP、
1 引言
- 目前尚缺乏类似的能力来对 IMU 信号进行高效编码的通用资源。(注意这是2022年的论文)
- 受近期利用大模型处理其他模态工作的启发,作者提出了 IMU2CLIP
- 一种预训练方法,该方法通过多模态对比学习,以无监督方式对齐视频 ↔ IMU ↔ 文本的平行数据。
- 该方法使 IMU2CLIP 能够将人体动作(由 IMU 传感器测量)转化为对应的文本描述和视频内容——同时保持这些模态之间的传递性。
- 具体而言,采用 CLIP 框架,其中包含已在大规模图文数据上预训练的视频编码器和语言模型,使 IMU 编码器能够从其他模态中迁移学习到丰富的语义表示。
- 为验证所提出方法的有效性,作者在多个基准任务以及 IMU2CLIP 所支持的新应用场景中对模型进行了评估,例如基于 IMU 的媒体检索,充分利用了 IMU2CLIP 所具备的模态传递性。
2 相关工作
2.1 对比学习
对比学习是一种高效的自监督学习框架,它通过将数据组织为相似/不相似的配对,来学习其表示特征。例如:
- SimCLR 是在数据增强设置下的单模态对比学习方法,作者提出通过对扰动图像进行对比学习来训练视觉编码器;
- 在多模态设置中,CLIP 利用图像与文本配对数据,从自然语言监督中学习视觉表示,在零样本图像分类、文本检索图像、图像生成描述等任务中表现出色;
- WAV2CLIP 提出通过蒸馏 CLIP 来学习音频表示。
本文延续这一研究方向,将其拓展至一种独特的多模态场景:利用 IMU 信号。
2.2 预训练资源
对于图像、文本等已有广泛研究的模态,已存在大量预训练资源。研究表明,这些预训练资源具备强大的零样本性能,在微调后更能在多个下游任务上超越全监督模型。
然而,目前尚无公开可用的用于编码 IMU 信号的类似资源。受此启发,作者提出了一种面向 IMU 这类独特传感器的大规模预训练方法。
2.3 Egocentric 数据集
本文特别关注第一视角(egocentric)数据集,这类数据集常用于理解佩戴者的行为活动,尤其适用于头戴式设备。
目前已构建的代表性 egocentric 数据集包括:Ego4D、Epic-Kitchens、Aria。
本文基于这些数据集设计了多个子任务,以全面评估 IMU2CLIP 的能力,并展示其未来应用的可行性。此外,本文实现了一个通用的多模态数据加载器,支持跨模态和跨数据集的研究。
2.3 IMU 建模
IMU 信号已被广泛应用于各类动作识别任务,如:姿态估计、步速估计、足部位置预测。
针对这些任务,已有多种深度学习架构被提出,包括:Transformer-CNN 模型 [4]、1D-CNN 与 GRU 混合模型 [21]、Bi-LSTM 模型 [22]。
本文提出了一个新的 IMU 模型架构,不同于以往专注于特定任务的 IMU 建模方法,本文目标是通过将 IMU 与其他模态(如图像和文本)对齐,学习其通用表示,从而支持更广泛的下游应用。
3 方法
IMU2CLIP中,训练一个 IMU 编码器,使其对某一时间段内的 IMU 数据的表示,与对应的视频帧的表示相似;在有文本的情况下,也与相应的文本描述或叙述对齐。
图2展示了整体方法框架。
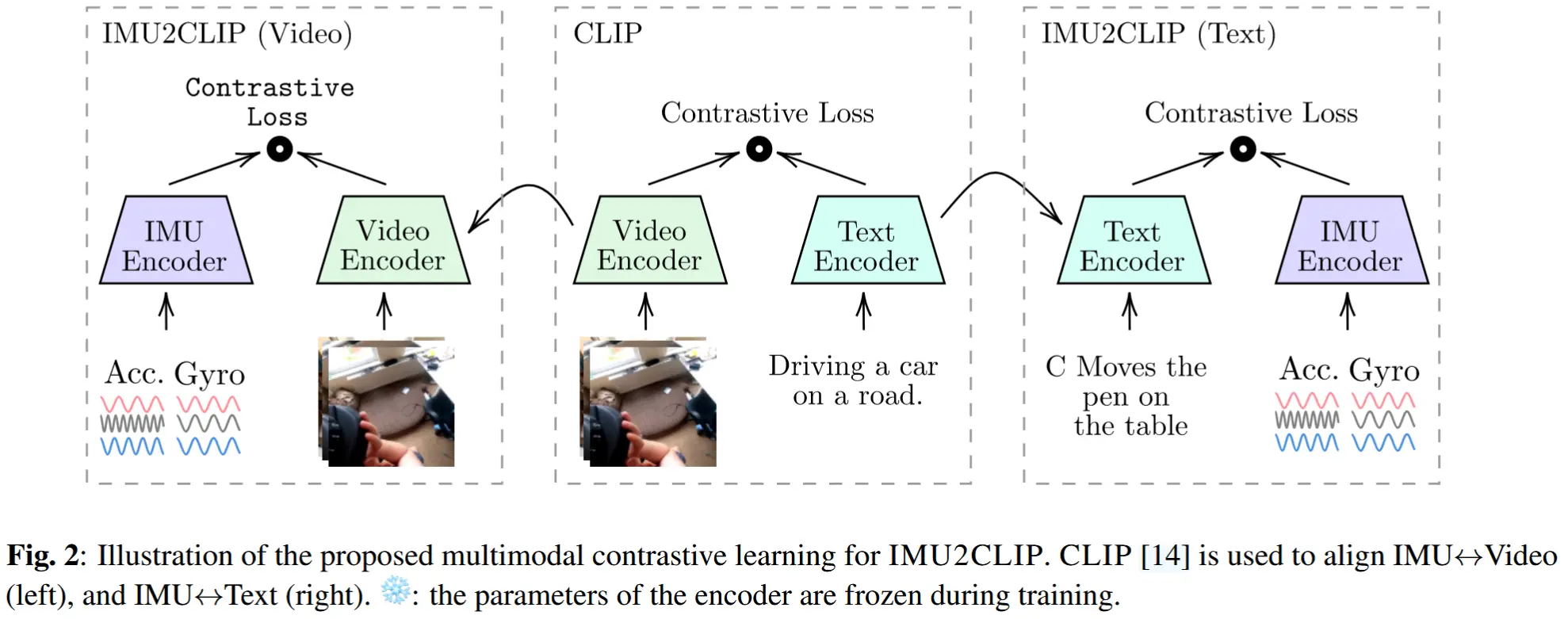
3.1 IMU 的跨模态对比学习
我们考虑一组大小为 B 的真实对齐窗口:\{(\mathbf{i}_1, \mathbf{v}_1, \mathbf{t}_1), ..., (\mathbf{i}_B, \mathbf{v}_B, \mathbf{t}_B)\},其中每个模态的嵌入位于单位超球面 S^D 上。由于嵌入是单位归一化的,相似度可以直接计算为它们的内积:
然后,可以基于平行信号之间的 跨模态相似性 定义 IMU to video 和 IMU to text 的检索分布:
其中,\gamma 是控制分布集中程度的温度参数。
然后,训练三种不同版本的 IMU2CLIP:(a) IMU ↔ 视频,(b) IMU ↔ 文本,以及 (c) IMU ↔ 视频 ↔ 文本。具体而言,将 IMU 表示投影到联合 CLIP 空间,以利用 CLIP 中已编码的视觉和文本知识。与 [8, 10] 类似,作者提出最小化对称的跨模态对比损失。对于 IMU ↔ 视频对齐,使用 IMU 到视频和视频到 IMU 的交叉熵损失之和:
同理,\mathcal{L}_{\text{i}\leftrightarrow\text{t}} 可以类似地定义,因此 \mathcal{L}_{\text{i}\leftrightarrow\text{v}\leftrightarrow\text{t}} = \mathcal{L}_{\text{i}\leftrightarrow\text{v}} + \mathcal{L}_{\text{i}\leftrightarrow\text{t}}。为了保留 CLIP 已有的文本-视觉对齐关系,将图像和文本 CLIP 编码器的参数冻结。
实现细节 为了加速训练,预处理每种媒体,使其具有等长的平行窗口。数据模块在给定时间戳处检索请求窗口大小的平行数据,并将其缓存以加快训练速度。此外,为了适应内存限制,在同一批次中池化负样本(随机打乱),从而减轻每个 GPU 的负载。
3.2 IMU 编码器架构
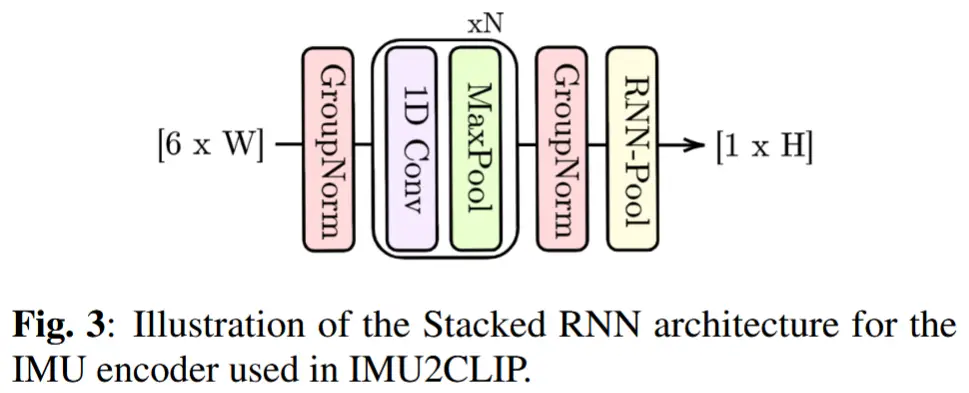
IMU编码器:堆叠的一维卷积神经网络(1D-CNN)和循环神经网络(RNN)架构。
如图3所示。首先,分别对加速度计(3D)和陀螺仪(3D)信号执行 GroupNorm 操作;然后,堆叠 N 层 1D-CNN,接着进行核大小为 5 的 Max Pooling;接着,再次执行 GroupNorm 来归一化输出特征;最后,使用 RNN(即实验中的 GRU)来组合 CNN 输出,从而生成最终的嵌入表示。
4 实验
4.1 实验设定
- 数据集:Ego4D 和 Aria。都包含视频和IMU信号,Ego4D的一部分片段还有文本叙述,
- 三种任务
- 任务一:通过文本查询检索 IMU 数据(Text → IMU)
- 任务二:基于 IMU 的视频检索(IMU → Video)
- 任务三:基于 IMU 的活动识别
4.2 实验结果
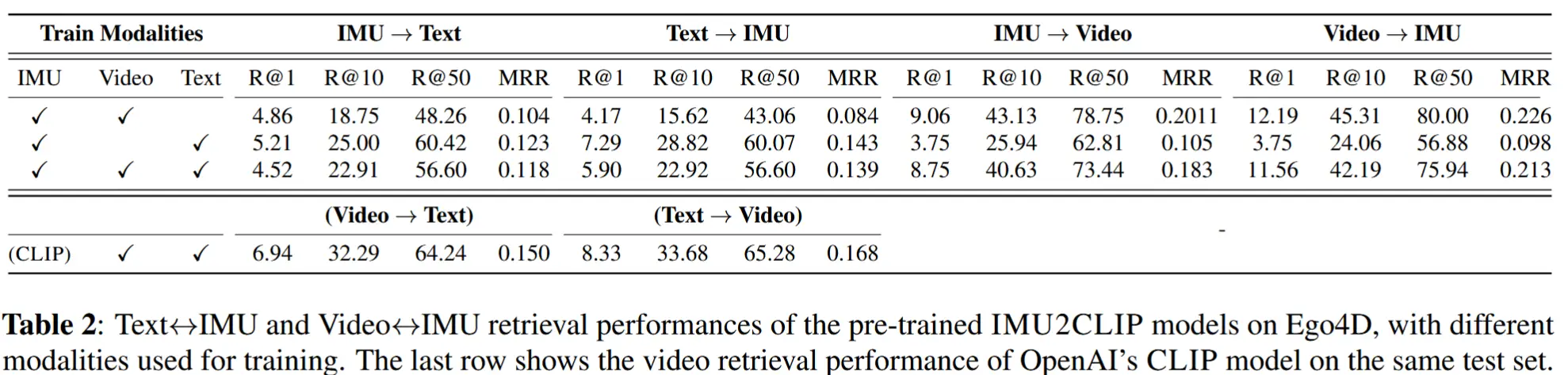
- 表2中的 Text→IMU 列显示了任务1的性能表现,表2中的 IMU→Video 列展示了任务2的表现。
- 总体来看,召回率更高,说明 IMU 信号与视频之间具备较高的兼容性。
- 当模型使用三种模态联合训练时,在所有任务中均表现出竞争力,而针对特定任务训练的双模态模型则取得了最佳性能。
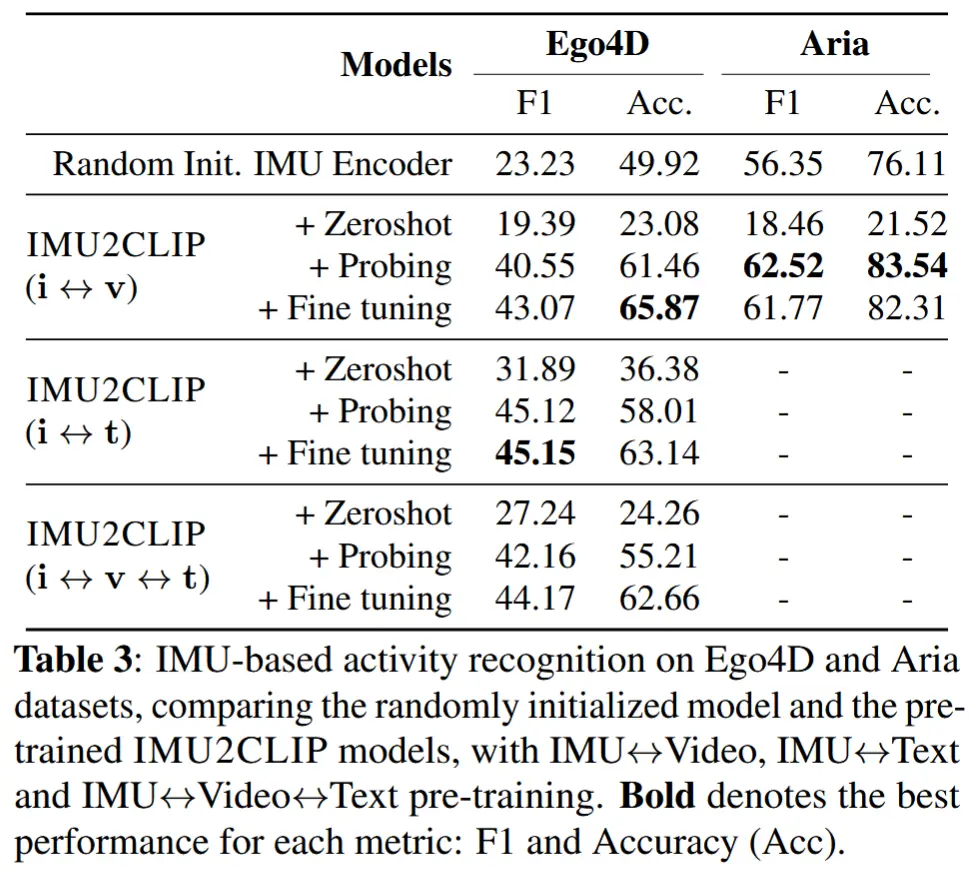
- 表3展示了 IMU2CLIP 在 Ego4D 和 Aria 数据集上的活动识别结果。
- Zeroshot:使用 CLIP 文本编码器对每类活动的名称(如 hiking、running)进行编码,并在投影后的 IMU 嵌入空间中使用最近邻分类器(不使用任何监督标签)。
- Probing:在 IMU 编码器顶部添加一个线性层,同时冻结编码器参数。
- Fine-tuning:允许整个编码器参数可训练。