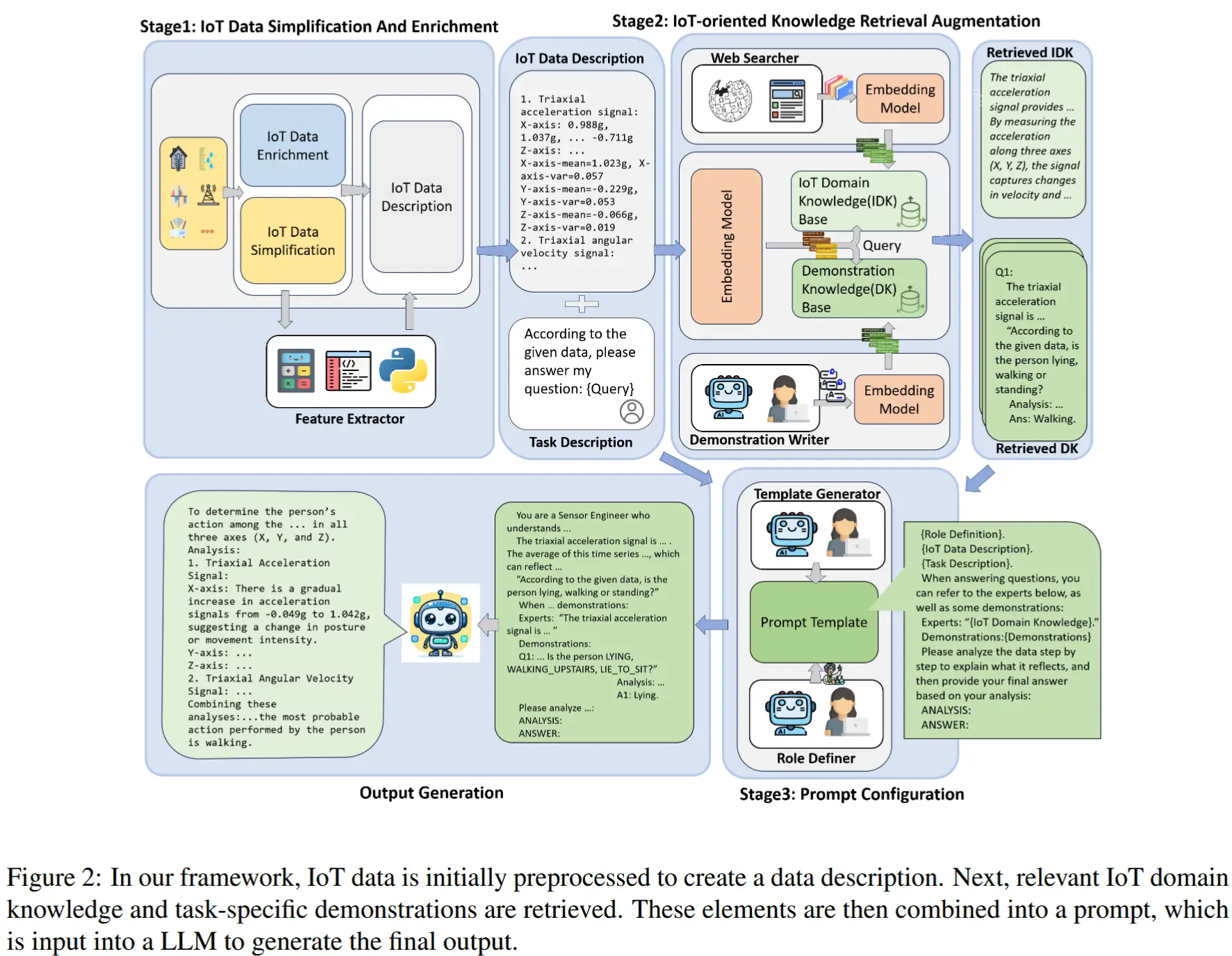
- 论文 - 《BabyNet: A Lightweight Network for Infant Reaching Action Recognition in Unconstrained Environments to Support Future Pediatric Rehabilitation Applications》
- 关键词 - 婴儿动作识别、HAR、新数据集
摘要
- 研究问题:稀缺的儿童领域人体动作识别HAR
- 本文工作
- 提出了 BabyNet,一种轻量级(参数数量少)的网络结构,用于从固定摄像头中识别人类婴儿的伸手抓取动作。
- 作者构建了一个带有标注的数据集,包含不同婴儿在非受限环境(如家庭场景)中坐姿状态下的多种伸手动作。
- 本文方法利用标注边界框的空间与时间关联性,来判断伸手动作的开始与结束,并检测完整的伸手行为。
1 引言
- 婴幼儿动作识别的意义:可用于儿童安全监控 [4–6]、研究婴儿与看护者的互动 [7]、发现神经运动障碍的诊断标志 [1、2、8–10],以及构建智能环境和辅助可穿戴机器人设备中的动作-感知闭环系统 [11–15]。
- 婴儿运动动作识别算法的挑战
- 由于学习和成长过程的影响,婴幼儿在个体内部及个体之间的动作表现存在天然的多样性。
- 例如,以“伸手抓取”为例,其运动学特征会随着婴儿逐渐适应环境、任务和生物力学约束而发生变化 [17-18]。
- 由于隐私问题,婴儿行为数据集数量稀缺[3、28、29],并且它们不适用于本文聚焦的婴儿伸手动作识别任务。
- 专注于伸手动作的原因
- 婴幼儿最早发展的运动里程碑之一,标志着他们开始探索周围环境并进行学习。
- 在儿科康复领域,提升婴儿的伸手能力是一个重要的目标[30、31]。
- 基于视觉的伸手动作识别可以为辅助上肢设备提供自主判断依据,决定应向儿童用户反馈多少被动/主动辅助 [15]。
- 本文贡献
- 构建了一个专注于婴儿伸手动作的新数据集。
- 涵盖正常发育婴儿以及有手臂活动障碍的婴儿的伸手行为。
- 数据集中还包含了对伸手动作的详细标注和边界框信息,如:伸手的起始与结束时间、接触物体、手臂在动作开始与结束时的位置等。
- 提出了 BabyNet,一种专门用于婴儿伸手动作识别的新网络结构。
- 基于长短期记忆模块(LSTM),通过时空建模来捕捉伸手动作的不同阶段特征。
- 提供一种轻量级但在性能上可媲美更大规模网络的高效模型结构。
- 构建了一个专注于婴儿伸手动作的新数据集。
2 相关工作
2.1 HAR 方法概述
- 具体工作略
- 局限:这些方法大多依赖于以成人为主要对象的动作数据集 [22–27],缺乏针对婴幼儿动作的专门设计与评估。
2.2 用于康复的动作识别技术
- 近年来,一种新的研究趋势正在兴起:将技术应用于真实世界中的康复训练,以增加训练强度并更好地实现训练效果的迁移 [49、50]。
- 特别是对于婴儿来说,然而,将训练从实验室或诊所转移到现实环境中也带来了一系列挑战,例如及时准确的效果评估,以及很多时候缺乏专业的康复治疗师。为此,相关研究通常采用虚拟现实或基于摄像头的系统 [51–54] 来支持这类环境下的康复训练。
- 特别是在儿科康复背景下,近年来的研究趋势是利用动作识别技术提升辅助设备交互的效率与效果。
- 社交类人机器人可通过自主执行一组预设的手臂姿势供儿童模仿,从而实现非接触式的上肢康复训练 [55]。
- Kokkoni 等人 [13] 开发了一个面向婴儿的学习环境,结合了社交辅助机器人和身体承重支撑技术。
- [3、13] 使用 Kinect 摄像头捕捉婴儿动作,并开发了动作识别算法来实现婴儿与机器人之间的闭环交互。
- 本文提出的动作识别方法与上述思路一致,但应用于不同的技术平台。本文的未来目标是通过识别伸手动作,实现针对婴儿的可穿戴式上肢设备的自动化控制,从而在伸手过程中提供被动/主动反馈。
3、方法
3.1 婴儿伸手动作数据集
- 数据集简要介绍
- 视频数据来自 YouTube
- 数据集中既包含正常发育的婴儿,也包括有手臂运动障碍的婴儿。大多数视频是在自然(非受限)环境中录制的,如家庭或诊所。
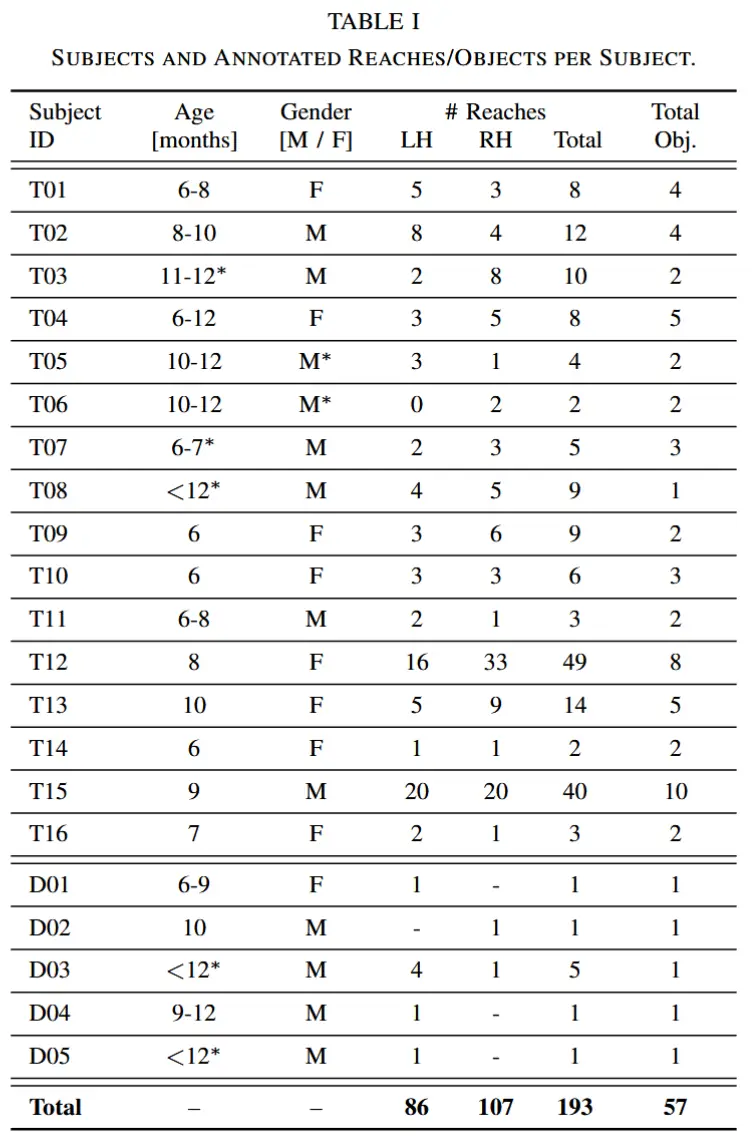
- 通过20个视频收集了21名不同婴儿执行的 193 次伸手动作(见表I),视频描述中提供了婴儿的年龄和性别信息。
- 所有视频标注了每个伸手动作的开始帧(Reaching Onset, RN)和结束帧(Reaching Offset, RF)。
- 整个标注过程共识别出193次伸手动作,其中左手(LH)86次,右手(RH)107次,共涉及57种不同的物体
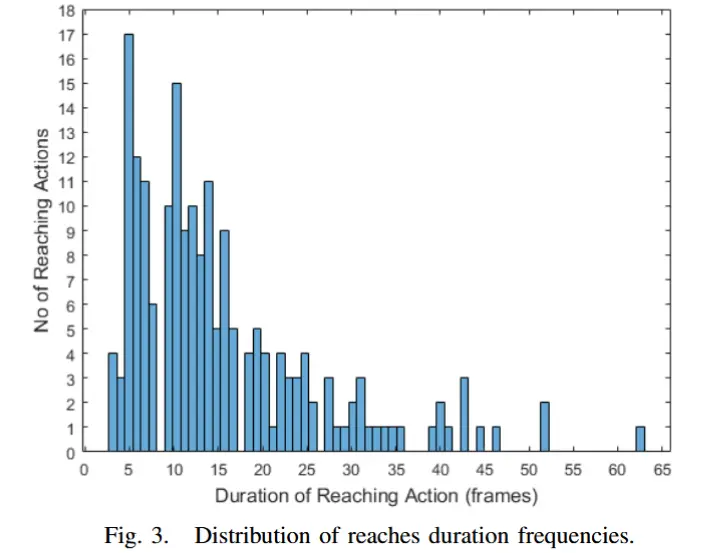
- 图3展示了数据集中所有伸手动作的持续时间分布情况。可以看出,伸手动作的时长存在较大变异性,但大多数动作持续时间集中在5到15帧之间。
3.2 边界框标注
-
为了评估婴儿在伸手过程中的空间与时间关联性,对每一帧中进行边界框检测与标注。
-
作者团队从整个数据集共 2,984 帧中随机抽取了 607 张图像进行标注。对于每一帧图像,为以下对象创建了边界框:
- 婴儿整体;
- 左手(LH);
- 右手(RH);
- 以及参与伸手动作的物体。
-
作者采用基于 COCO 数据集预训练的 YOLOv3 目标检测模型,并使用已标注的数据微调,以帮助自动化处理剩余帧的数据。
- 目标检测模型的训练与测试采用 75% 训练集 / 25% 测试集 的划分方式。
3.3 对比的基线方法
为了评估作者提出的网络结构性能,选用了以下基线网络结构进行对比实验:
- 多层感知机(MLP):四层网络,具有两个输入和四个输出,用于基本的动作分类任务。
- ResNet:基于预训练的 ResNet-50 模型 ,作者重新训练了第四层中的最后一个 Bottleneck 块以及全连接层,以探索是否可以避免过拟合问题。
- ResNet+LSTM:在上述 ResNet-50 模型中,作者在最后一个残差块的平均池化层后加入了一个 LSTM 模块,旨在捕捉伸手动作的时序相关特征。
- 结合光流的 LSTM(O-LSTM):使用单层 LSTM 并加入 50% 的 dropout 层,该模型利用光流图像提供的运动信息进行训练。
除了 O-LSTM 外,所有模型都直接以 224×224 尺寸的 RGB 图像作为输入,并在新数据集上进行了训练与评估。其中,ResNet 和 ResNet+LSTM 还采用了数据增强技术(包括图像平移、缩放和旋转),以提升泛化能力。
3.4 提出的 BabyNet 算法
BabyNet 的流程图如图4所示。给定一个视频帧序列 \mathbf{T} ,令 \mathbf{X} = \{x^{\mathbf{T}}_k\} 表示在帧序列中检测到的对象,\mathbf{H} = \{h^{\mathbf{T}}_L, h^{\mathbf{T}}_R\} 分别表示左、右手在帧中的检测结果。需要注意的是,作者没有引入任何跟踪信息,而是依赖于边界框的中心位置作为图像中手和物体位置的主要信息来源。边界框的坐标是通过目标检测获得的,并且与对象标签一起提供。
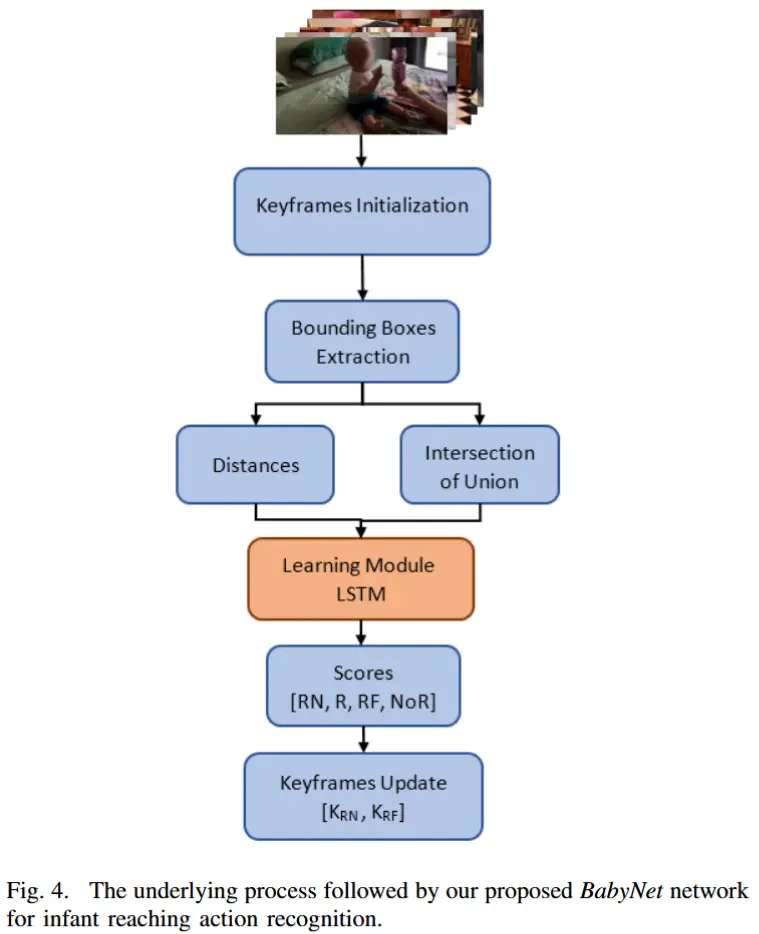
3.4.1 边界框信息提取
首先,通过目标检测获取每个帧中的边界框坐标:
- 对象 \mathbf{X} 的边界框坐标;
- 左手 h^{\mathbf{T}}_L 和右手 h^{\mathbf{T}}_R 的边界框坐标。
这些边界框的中心位置被用作手和物体的位置信息。
3.4.2 伸手开始阶段
利用当前帧 \mathbf{T}_j 中的手部 \{h^{\mathbf{T}}_L, h^{\mathbf{T}}_R\} 和对象 x_i 的边界框坐标,计算它们之间的距离 d^j_i。具体步骤如下:
- 起始检测条件:如果当前帧的距离 d^j_i 比前一帧的距离 d^{j-1}_i 更小(即 d^j_i - d^{j-1}_i < 0),则认为伸手动作的起始检测仍然有效,当前帧 \mathbf{T}_{RN} 可以保留为关键帧。
- 起始无效条件:如果 d^j_i - d^{j-1}_i \geq 0 并且这种正向增加连续持续了四个连续帧,则起始检测无效,此时可以将当前帧 \mathbf{T}_i 设置为新的关键帧 \mathbf{T}_{RN}。
这种方法有助于避免在起始阶段出现假阴性情况。
3.4.3 伸手结束阶段
在伸手过程中,通过计算手部 \{h^{\mathbf{T}}_L, h^{\mathbf{T}}_R\} 和对象 x_i 的交并比( IOU) 来判断伸手动作是否结束。具体步骤如下:
- 偏移检测条件:计算当前帧中手部和对象的 IOU 值,并将其与预设的阈值进行比较。
- 如果 IOU 小于阈值,则认为伸手动作未完成,当前的关键帧 \mathbf{T}_{RF} 保持不变。
- 如果 IOU 大于或等于阈值,则认为伸手动作结束,当前帧 \mathbf{T}_i 被标记为新的关键帧 \mathbf{T}_{RF}。
这种方法确保了伸手动作结束点的准确检测。
3.4.4 BabyNet 核心结构
我们的 BabyNet 使用 LSTM 结构来学习输入中边界框之间的关系,输入的两个特征包括:
- 手部和对象之间的距离;
- 手部和对象的交并比(IOU)。
输出是以下四种标签的得分:
- 起始(RN):用于标识伸手动作的起始帧;
- 偏移(RF):用于标识伸手动作的结束帧;
- 伸手(R):用于标识从起始帧 \mathbf{T}_{RN} 到偏移帧 \mathbf{T}_{RF} 之间的所有帧;
- 无伸手(NoR):用于标识起始帧之前和偏移帧之后的所有帧。
3.4.5 实现细节
BabyNet 的输入为两个特征(T=2),输出为四个标签(RN、RF、NoR、R)。初步测试表明,选择 T=2 可以在不引起过拟合的情况下提高时间相关预测的准确性。BabyNet 使用 Adam 优化器和交叉熵损失函数进行训练,学习率为 0.001。
在初步测试中,我们使用了一个包含 63 次伸手的小数据集,其中:
- 60% 用于训练;
- 15% 用于验证;
- 25% 用于测试。
虽然 BabyNet(以及 MLP)在小数据集上表现良好,但较大的网络结构(如 ResNet 变体和 O-LSTM)容易对数据集产生过拟合。为了解决这一问题,作者在完整数据集(193 次伸手)上测试了更大的网络,同时保持 BabyNet 和 MLP 在 63 次伸手的数据规模上进行训练。
4 实验结果
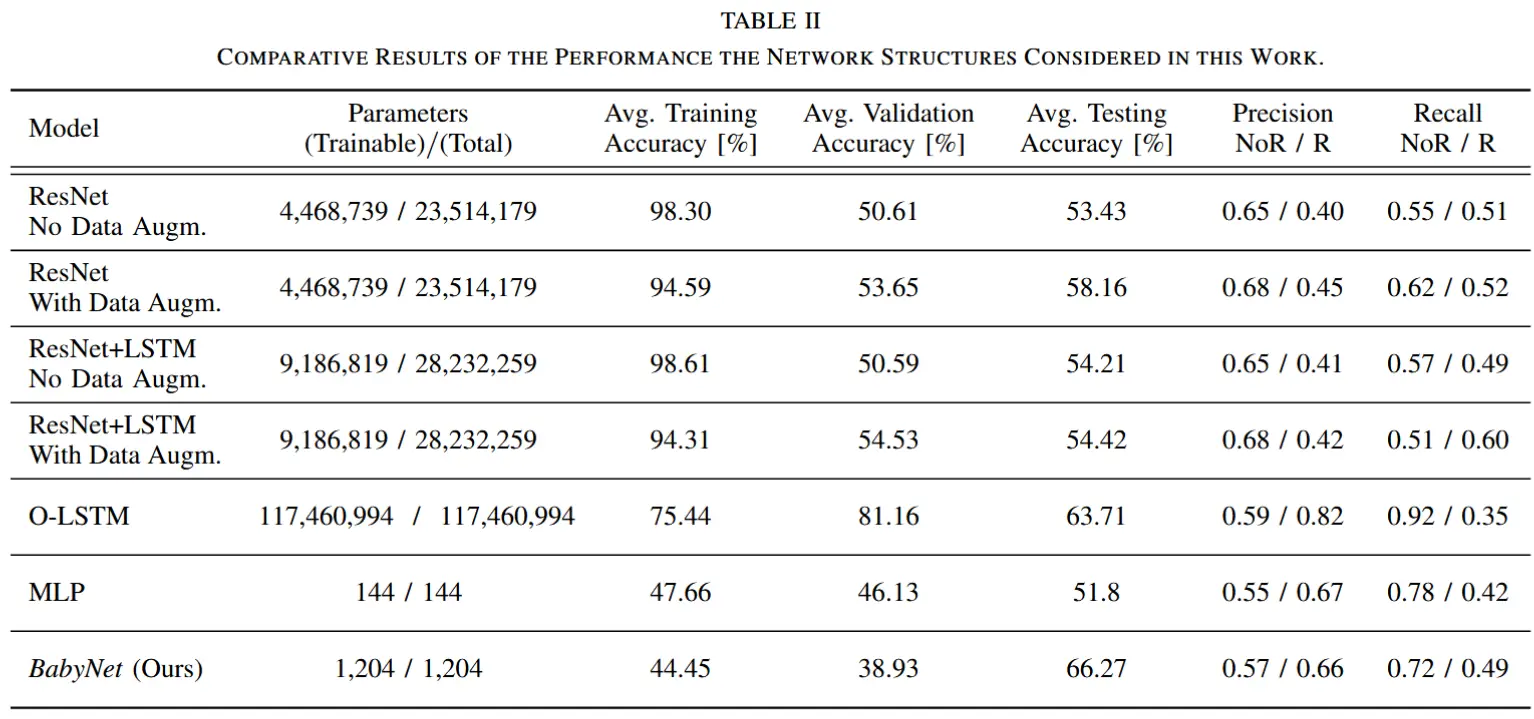
- ResNet 结构:带数据增强的 ResNet 表现出较高的平均测试准确率(58.16%),但对伸手动作的召回率较低。
- O-LSTM 结构:使用光流图像训练,平均测试准确率最高(63.71%),但对伸手动作的召回率较低(0.35),且参数量较大。
- BabyNet:在平均测试准确率上表现最优,尽管参数量较小且训练数据较少。其关键帧预测延迟低,能够较好地识别伸手动作的运动模式和过渡。
- MLP 结构:参数量最小,但性能最差,无法有效学习伸手动作的运动模式,且关键帧预测延迟较高。
- 总体而言,BabyNet 在性能、参数量和泛化能力上表现出色,是本文提出的最佳解决方案。
- BabyNet 训练准确率较低可能是因为训练数据量较小,但随着更多数据的加入,训练准确率会继续提升。
感觉这篇论文好像没什么创新点,用的方法和基线都非常普通,主要贡献在提供了一个数据集。