- 论文 - 《MotionGPT: Human Motion as a Foreign Language》
- 代码 - Github
- 关键词 - Neurips、运动-语言大模型、多任务、预训练+微调
1 摘要
- 研究问题
- 人类运动展现出与语言类似的语义结构,通常被视为一种“身体语言”。
- 通过将语言数据与大规模运动模型融合,进行能够提升运动相关任务性能的“运动-语言”联合预训练成为可能。
- 本文工作
- 提出了 MotionGPT——一个“运动-语言”模型,用于处理多种与运动相关的任务。
- 具体而言,本文采用离散向量量化方法对人体运动进行编码,将3D运动转化为“运动词元”(motion tokens),类似于文本中词元的生成过程。基于这种“运动词汇表”,在统一框架下对运动和文本进行语言建模,将人体运动视为一种特定的语言。
- 此外,受 prompt learning 的启发,本文使用运动与语言混合的数据进行预训练,并在基于提示的问答任务上对其进行微调。
2 背景与动机
- 目前尚未出现一个通用的、能够同时处理人类运动与语言的预训练模型。(注意这是23年的论文)
- 先前研究的局限性
- 1)通常将运动与语言视为分离的模态,依赖严格配对的运动与文本数据。
- 2)由于其监督信号是任务特定的,它们难以有效泛化到未见过的任务或数据,也缺乏对运动与语言之间整体关系的深入理解。
- 本文动机:致力于构建一个能够广泛适用于多种任务,并能从更丰富的运动与语言数据中学习深层次语义关联的预训练“运动-语言”模型。
3 方法
MotionGPT 框架如图2所示:
- 运动分词器 (motion tokenizer):将原始运动数据转换为离散运动词元。
- 动作词汇表(motion vocabulary):包含运动和文本Codebook。
- 运动感知语言模型:通过文本描述学习理解运动词元。
符号定义:
- 组成:运动编码器 \mathcal{E} 和运动解码器 \mathcal{D}
- 运动序列输入:包含 M 帧的运动序列 m^{1:M} = \{x^i\}_{i=1}^M
- 编码:将输入编码为 L 个运动词元 z^{1:L} = \{z^i\}_{i=1}^L,其中 L = M / l,l 表示对运动长度的时间下采样率。
- 文本输入:长度为 N 的句子 w^{1:N} = \{w^i\}_{i=1}^N,该句子描述了一个与运动相关的问题或需求
- 输出:MotionGPT 的目标是生成答案,即长度为 L 的词元序列 \hat{x}^{1:L} = \{\hat{x}^i\}_{i=1}^L。这些词元可以是人类运动词元 \hat{x}_m^{1:L},也可以是文本词元 \hat{x}_t^{1:L},最终生成的结果可以是一个运动序列 \hat{m}^{1:M} 或一段描述运动的文本 \hat{w}^{1:L}。
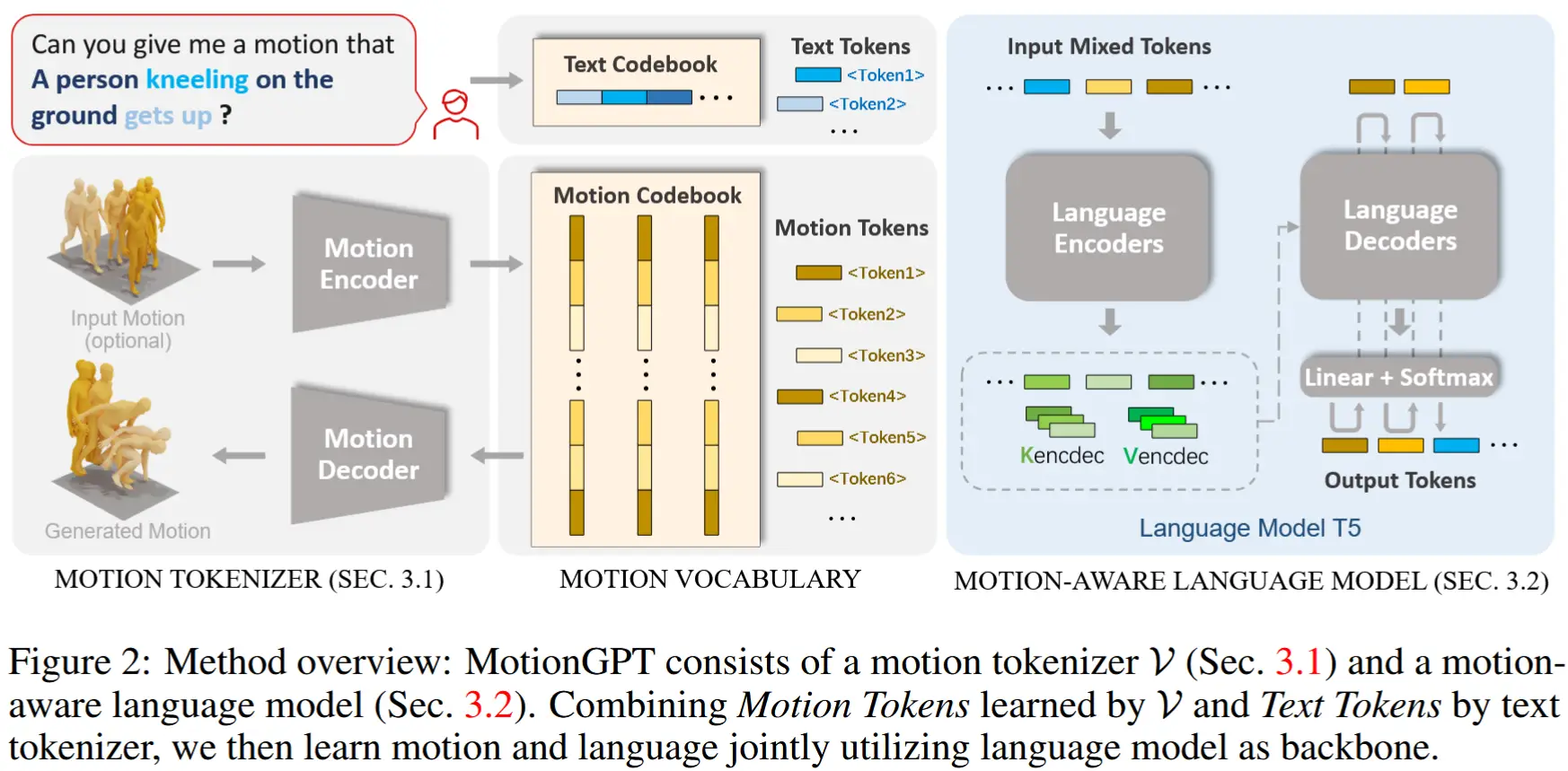
3.1 运动分词器
分词器 \mathcal{V} 结构:基于Vector Quantized Variational Autoencoders (VQ-VAE) 架构,由一个编码器 \mathcal{E} 和一个解码器 \mathcal{D} 组成。编码器生成具有高信息密度的离散运动词元,而解码器能够将这些运动词元重构为运动序列。
分词器运行公式化:运动编码器 \mathcal{E} 首先沿时间维度对给定的帧级运动特征 m^{1:M} 应用一维卷积,以获得潜在向量 \hat{z}^{1:L} = \mathcal{E}(m^{1:M})。接下来,通过离散量化将 \hat{z} 转换为一组代码本条目 z。可学习的代码本 Z = \{z^i\}_{i=1}^K \subset \mathbb{R}^d 包含 K 个潜在嵌入向量,每个向量的维度为 d。量化过程 Q(\cdot) 将每一行向量 b 替换为其在代码本 Z 中最近邻的条目 b_k,公式如下:
量化完成后,运动解码器 \mathcal{D} 将 z^{1:L} = \{z^i\}_{i=1}^L 投射回原始运动空间,生成包含 M 帧的运动序列 \hat{m}^{1:M}。
分词器训练方法:为了训练这个运动分词器,遵循 [12, 59] 的方法,使用三种不同的损失函数来训练和优化运动分词器:重构损失 \mathcal{L}_r、嵌入损失 \mathcal{L}_e 和 commitment 损失 \mathcal{L}_c,即 \mathcal{L}_{\mathcal{V}} = \mathcal{L}_r + \mathcal{L}_e + \mathcal{L}_c。为了进一步提升生成的运动质量,参考 [59] 的方法,在重构损失中引入 L1 平滑损失和速度正则化,并采用指数移动平均(EMA)和代码本重置技术 [39] 来增强训练期间的代码本利用率。
3.2 运动感知语言模型
为了实现语言与运动的统一建模,作者将运动词元 z^{1:L} 表示为索引序列 s^{1:L},并与基于 WordPiece 的文本词元融合。传统方法分别使用不同模块处理文本和运动,而本文提出将文本词汇表 V_t 与运动词汇表 V_m 合并为一个统一的“文本-运动”词汇表 V。其中 V_m 对应运动代码本 Z,并加入特殊标记如 <som> 和 <eom> 来表示运动起止。
这样,各种运动相关任务(如运动生成、描述、预测)都可以以统一格式建模,输入输出均来自同一词汇表 V,支持自然语言、运动或两者混合的表达。MotionGPT 基于 T5 架构,采用 Transformer 模型进行条件生成:源输入 X_s 经编码器处理,解码器自回归生成目标序列 X_t,通过最小化负对数似然优化模型参数:
在推理阶段,通过递归采样从分布中生成目标词元,直到遇到结束标记,从而逐步构建完整输出序列。
3.3 训练策略
由于 T5 模型仅在文本数据上进行训练,其词汇表为 V_t,因此需要通过学习运动词汇表 V_m 来将运动与语言联系起来,并使该语言模型能够理解人体运动概念。如图 3 所示,本文训练方案包括三个阶段:
- 运动分词器训练:专注于学习运动Codebook以将人体运动表示为离散词元。
- 运动-语言预训练阶段:包含无监督和有监督的目标,用于学习运动与语言之间的关系。
- 指令微调阶段:基于不同运动相关任务的提示指令对模型进行调整。
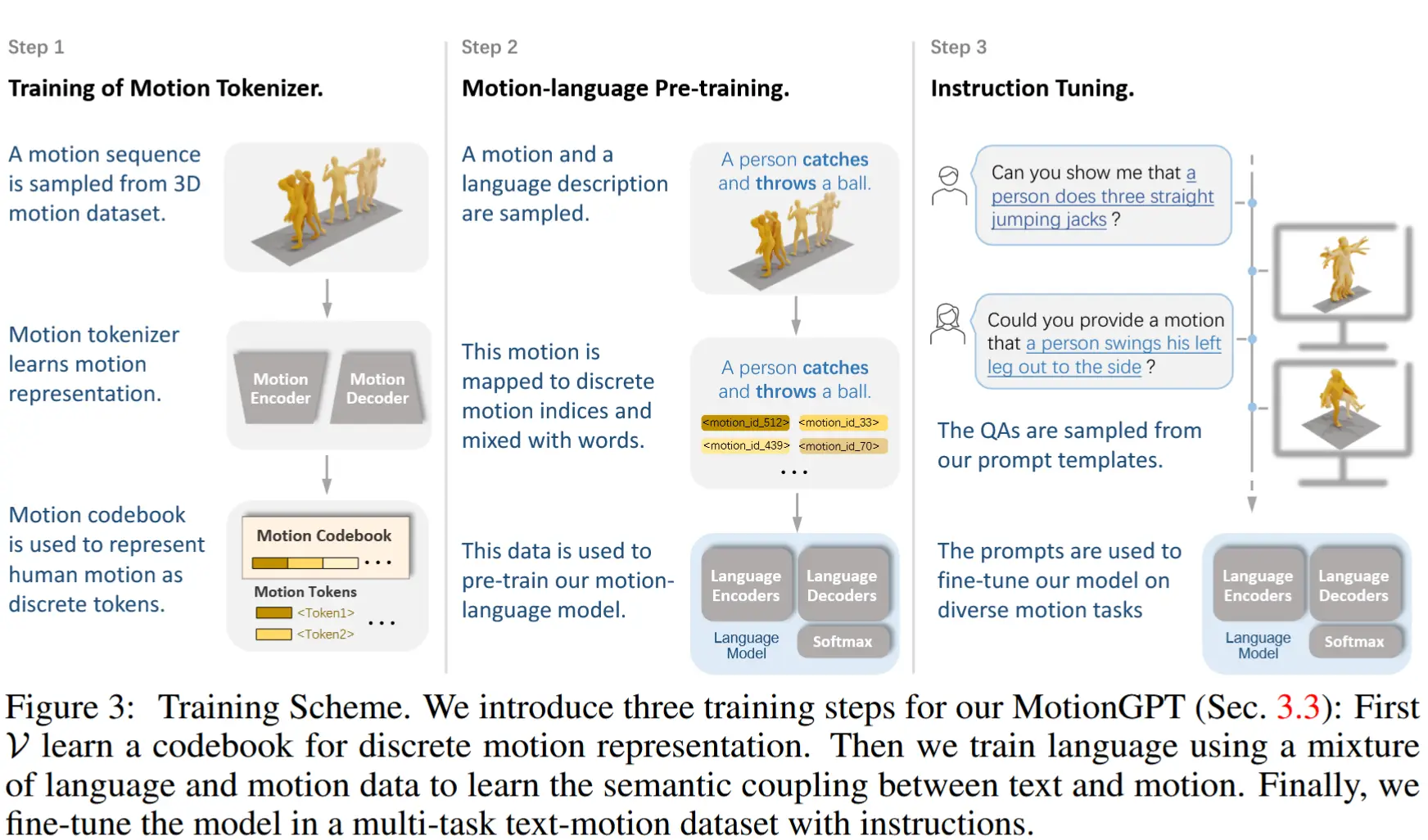
3.3.1 运动分词器训练
使用公式 (1) 中定义的目标来训练运动分词器。一旦优化完成,运动分词器在整个后续管道阶段中保持不变。
3.3.2 运动-语言预训练阶段
在T5模型的基础上,使用混合的语言与运动数据对MotionGPT进行进一步预训练,包含两种训练方式:
- 无监督目标:沿用T5的去噪目标,随机将输入词元中15%替换为哨兵标记,并构建输出序列以恢复被掩码的内容,提升模型泛化能力。
- 有监督目标:利用成对的文本-运动数据集 [11, 33],在翻译任务上训练模型理解语言与运动之间的关联。
3.3.3 指令微调阶段
基于HumanML3D和KIT等数据集构建了一个多任务指令数据集,定义了15类核心运动任务(如运动生成、描述、预测等),并为每个任务设计多种指令模板,共生成上千种任务形式。例如:
- 运动生成:“Can you generate a motion sequence that depicts ‘a person emulates the motions of a waltz dance’?”
- 运动描述:“Provide an accurate caption describing the motion of <motion_tokens>”
通过指令微调,MotionGPT在多个任务上表现出色,并展现出对新任务和提示的良好适应能力。