- 论文 - 《STREAMMIND: Unlocking Full Frame Rate Streaming Video Dialogue through Event-Gated Cognition》
- 代码 - Github
- 关键词 - 流式视频对话、实时处理、视频大模型、高效处理、开源
摘要
- 研究问题:流式视频对话 (Streaming Video Dialogue)
- 本文工作
- 提出了 STREAMMIND,一种视频大语言模型框架,能够实现 超高清帧率 的视频处理,并支持 主动式、全天候 的实时响应,而无需用户显式干预。
- 为了解决 线性视频流速度与二次增长的Transformer计算成本之间的矛盾 这一关键挑战,作者提出了“事件门控的大语言模型调用机制 ”。在视频编码器和LLM之间引入了一个认知门网络 (Cognition Gate),仅在相关事件发生时才激活LLM进行推理。
- 为了以恒定成本实现事件特征提取,作者提出了一种基于状态空间方法的 事件保留特征提取器 (Event-Preserving Feature Extractor, EPFE),该模块可以生成一个融合时空信息的单一感知token。
- 这些技术使得视频大语言模型能够在保持 全帧率感知 的同时实现实时认知响应 。
1 引言
-
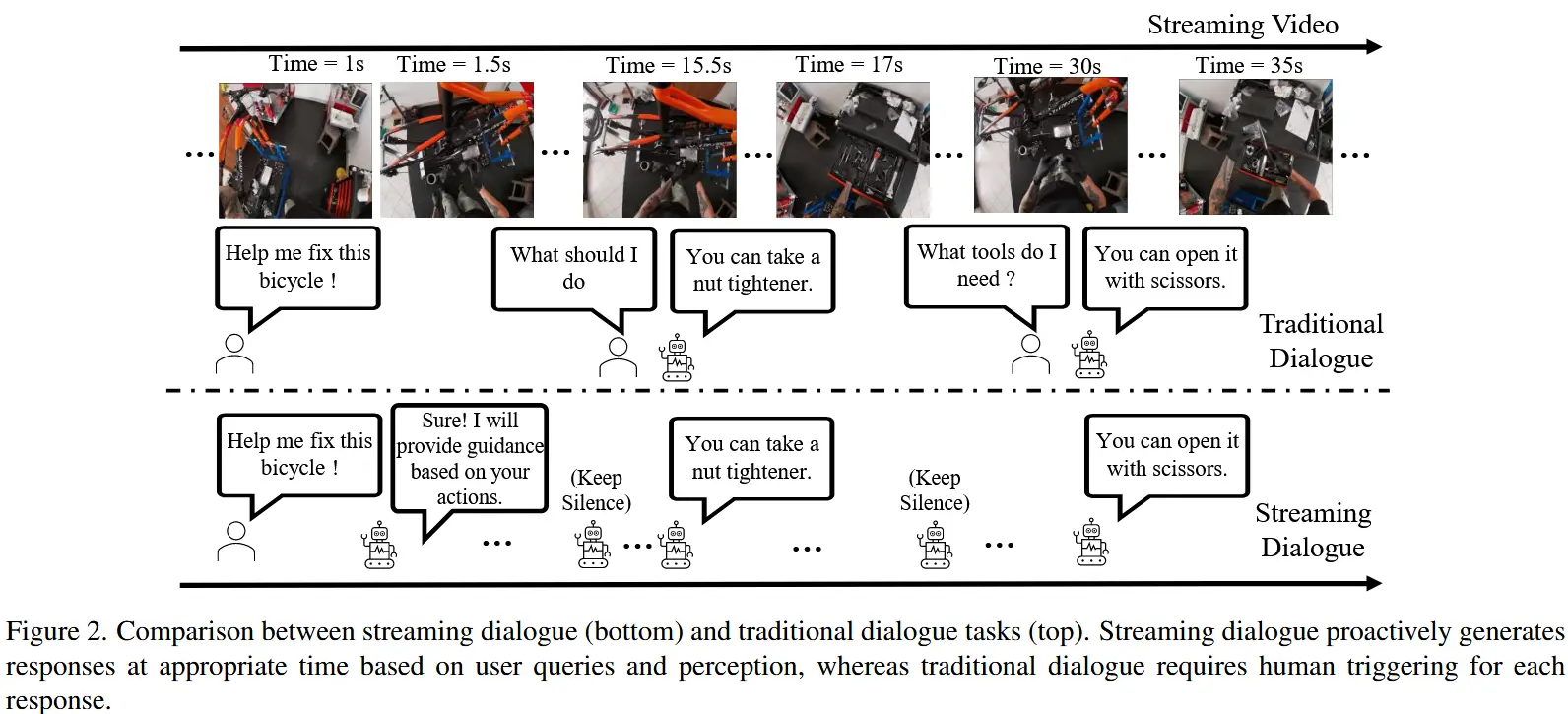
流式视频对话(StreamingVD)的核心挑战在于事件与响应之间的时间对齐要求。
- 即模型需要如图2所示:1)主动判断何时作出响应;2)在下一个事件发生之前,根据用户的问题实时作出回答。
- 然而,以当前的技术水平,这两个要求是相互矛盾的,无法同时满足。
-
现有工作
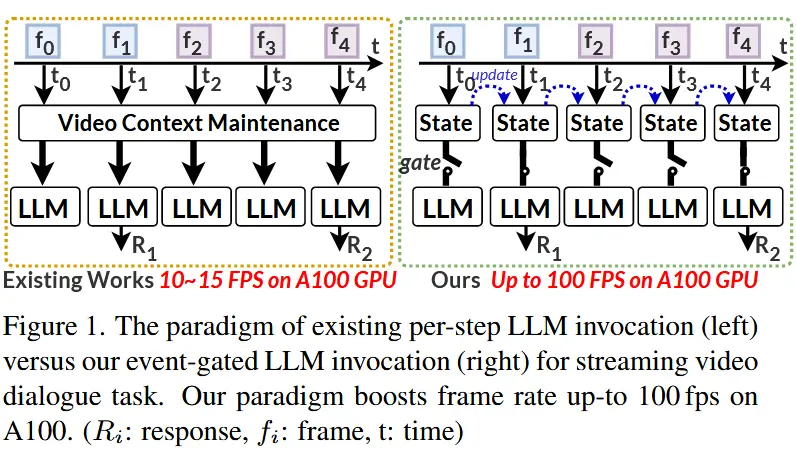
- VideoLLM-Online [8] 和 VideoLLMMoD [59] 提出了用于 StreamingVD 的每时间步调用大语言模型范式,如图1所示。
- 然而,由于LLM的计算复杂度为 O(n^3),而上下文窗口有限,这与视频帧流的线性增长 O(n) 不匹配,导致难以实现实时响应。
- 其他工作 [14, 44, 61, 71] 致力于提升离线视频对话的效率,以满足实时需求。但与传统的离线方法类似,它们仍然依赖用户的提问来触发响应,而不是由模型主动作出反应。
- 新范式
- 为了赋能流式视频对话,本文提出了一种全新的“感知-认知交错”范式,称为 事件门控的大语言模型调用机制,如图1所示。
- 因此,本文提出了一种基于事件的选择性认知过程。在视频编码器与LLM之间引入了一个“认知门”。视频编码器持续感知每一帧的视觉信号,只有当出现与用户问题相关的事件时,认知门才会打开并激活LLM进行响应。这一机制类似于文本提示触发LLM的过程。
- 然而,流式视觉信号缺乏明确的“结束点”。认知门正是填补这一空白的关键机制,它能够识别现实世界中的“物理提示”来决定是否激活LLM。
- 新范式的主要技术挑战:
- 现有VideoLLMs中的视频编码器仅能捕捉局部时空特征。导致随着视频帧流的增长,特征token数量线性增加,进而引发Transformer处理中的二次方计算复杂度。
- 认知门需要根据视觉特征和用户问题判断是否调用LLM。然而,若仅出于效率考虑,简单使用视觉与查询token之间的注意力机制,则限制了门的功能仅限于特征匹配或检索任务,难以做出具有深层语义理解的决策。
- 新框架 - STREAMMIND
- 面向 StreamingVD 的全新框架,并首次实现了处理速度与视频帧率的同步匹配。
- 该框架融合了以下两项关键技术:
- 视频编码器:事件保留特征提取器(EPFE)
- 受状态辅助模块(state-assisted module)在建模连续物理信号方面出色能力的启发,作者提出了基于状态辅助模块的 事件保留特征提取器。该模块能够在恒定成本下生成一个融合事件信息的单一感知token,供认知门使用,从而实现感知成本恒定。
- 认知门:浅层网络迁移方法
- 该认知门设计为重用LLM的浅层结构及其自回归训练方式,在训练过程中最大化“< response/silence >”等关键token的生成概率,从而实现高效的响应决策。
- 视频编码器:事件保留特征提取器(EPFE)
2 方法
2.1 任务讨论与定义
StreamingVD 问题的公式化
给定一个包含 T 帧的视频流 \mathcal{V}^I := [v_1, v_2, ..., v_T] 和一组查询集合 \mathcal{Q} := \{q_1, q_2, ..., q_N\}。
传统视频对话,会根据用户查询触发响应。对于在时间步 t_s 提出的查询 q_i ,它基于截至时间 t_s (1 < t_s \leq T) 的过去帧进行响应,无论是在在线还是离线场景中。
然而,StreamingVD 会在任何适当的时间步主动生成对查询的响应,直到查询终止于时间点 t_e (t_s < t_e \leq T) 。在每个时间步 t_i (t_s \leq t_i \leq t_e) ,StreamingVD 需要根据过去的帧和查询决定是否生成响应,其公式化如下:
其中:
- [Res^{t_i}] \in \{\text{[Txt]}^{t_i}, \text{[EOS]}^{t_i}\} 表示在时间步 t_i 生成响应或保持沉默,即 [\text{EOS}]。
- [\text{Ctx}^{<t_i}] 表示在时间步 t_i 之前从过去帧和查询中累积的上下文token。
- [\text{F}^{t_i}] 表示从时间步 t_i 的视频帧中提取的视觉特征。
2.2. STREAMMIND 的概述
对于流式视频序列 [v^{t_s \leq t_i \leq t_e}],STREAMMIND 模型执行以下过程,如图3所示:
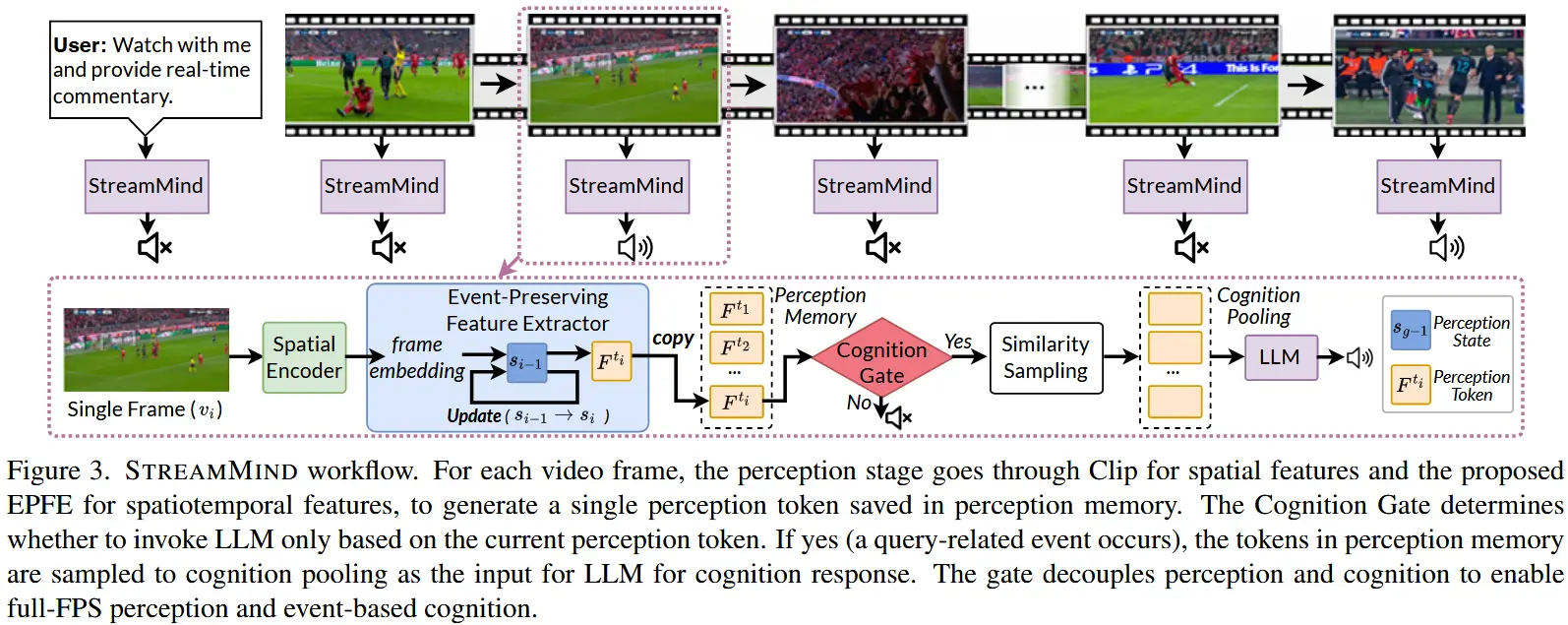
- 感知阶段
在连续的流式视频中,每一帧 v 都通过 CLIP 编码器提取空间特征。然后将这些特征输入到我们提出的 事件保留特征提取器(EPFE)。EPFE 更新其隐藏状态以关联帧在时间维度上的特征,并减少冗余的空间信息。这一过程生成一个新的感知token [\text{F}_{\text{per}}^{t_i}],并将其保存到感知记忆 \mathcal{M}_{\text{per}}^{t_i} 中。感知阶段可以公式化如下:
其中,\text{H}^{t_{i-1}} 表示前一时间步的隐藏状态。
- 认知门判断
在感知和认知中间引入了 认知门(Cognition Gate) \mathcal{G}。输入包括用户查询 [\text{Prompt}] 和每个时间步 t_i 生成的感知token [\text{F}_{\text{per}}^{t_i}]。认知门学习如何在时间步 t_i 决定是否触发认知阶段:
其中,[Res^{t_i}] \in \{\langle /response\rangle, \langle /silence\rangle\} 确定是否触发响应或保持沉默。
- 认知阶段
在接收到认知门的触发信号后,STREAMMIND 从感知记忆 \mathcal{M}_{\text{per}}^{t_i} 中采样感知token,并将其传递到认知池化(Cognition Pooling),作为大语言模型(LLM)的输入,从而生成响应。
2.3 感知阶段
动机:当前的视频编码器通常以恒定成本提取局部(数十帧)时空特征,并将所有生成的感知token输入到Transformer模型中,以提取长期的时间关系。这种计算成本为 O(n^3) ,远远落后于流式速率。
解决方案:
作者提出了 事件保留特征提取器(EPFE) 来替代现有的投影模块。EPFE 基于最先进的状态空间模型,即选择性状态空间模型(Selective State Space Model)[22]。对于每一帧,EPFE 动态关联空间特征和过去的内部状态,生成一个单一的感知token [\text{F}_{\text{per}}^{t_i}],并更新其状态。这使得流式视频处理速度与感知处理速度相匹配,从而实现全帧率的流式视频对话。
其中,\mathbf{A}、\mathbf{B} 和 \mathbf{C} 分别是可学习的状态矩阵、输入矩阵和输出矩阵。\mathbf{x}_t 是当前时间步的输入帧,\mathbf{h}_t 是内部隐藏状态,\mathbf{y}_t 输出的感知token。
优点:得益于选择性状态空间模型强大的时间建模能力,EPFE仅使用56M参数即可在恒定成本下学习长期事件级时空特征。
2.4 认知门
动机:
认知门需要基于当前的感知token和用户查询,实时判断是否调用大语言模型(LLM)。然而,采用简单的带有交叉注意力机制的Transformer模块判断能力有限,主要有两个原因:
- 认知门只能访问到当前时间步之前的信息,缺乏全局时间视角来进行决策。
- 用户查询可能并不直接对应特定视频帧。
因此,认知门需要具备大语言模型所拥有的世界知识。但由于LLM规模庞大,即使仅处理一个感知token也会带来高昂的计算成本。
解决方案:
为了解决这个问题,作者提出了 浅层网络迁移方法。该方法使用LLM的前几层初始化认知门,并在StreamVD数据集上以监督式自回归方式进行微调。通过这种方式,认知门能够继承LLM的部分语义理解和推理能力,同时保持低计算开销。(在本工作中,使用了四层结构)
2.5 训练策略
2.5.1 模型架构
模型架构如前面的图3所示,包含以下组件:
- CLIP 是预训练的空间特征提取器;
- EPFE 接收空间特征以及其内部状态,用于提取时空特征,并生成一个感知token;
- 认知门 则基于当前的感知token和用户查询判断是否调用LLM。
为实现上述功能,需要对 EPFE、认知门 进行训练,并且还要 对齐 EPFE 与 LLM 的表示空间。
2.5.2 数据准备
流式数据集是通过对现有的离线数据集进行处理构建而成的。为此,从离线数据集中去除重复的描述字幕,并通过以下方法将其转换为流式数据集(详见算法1):
- 预处理:合并相邻相同的字幕,并记录首次出现的时间戳作为该字幕的标注点;
- 静默/响应标签标注:为了训练认知门,在两个相邻字幕之间的视频帧中插入
< /silence >标记,这些标记用于指导认知门生成< /silence >响应;而对应有字幕事件的初始帧则标注为< /response >。

2.5.3 训练策略
本文采用两阶段训练策略,如图4所示。不同于以往典型的两阶段训练方法,本文的方法专门为认知门设计了独立的训练阶段。
- 第一阶段:使用流式数据集中的视频帧和字幕联合训练 LLM 和 EPFE,确保 EPFE 提取的时空特征与 LLM 的表示空间保持一致;
- 第二阶段:仅训练认知门,其初始化自LLM的浅层结构。该阶段也以类似LLM的自回归方式进行训练,目标是生成
< /silence >或< /response >标记,从而决定是否调用LLM。
由于 < /response > 标签远少于 < /silence >,作者在标准交叉熵损失函数中引入了类别平衡权重,以缓解类别不平衡问题。

3 实验
3.1 实验设置
-
数据集:Ego4D 和 SoccerNet-Caption
-
基线:VideoLLM-Online 和 VideoLLM-MOD
-
实现细节
- 基于每秒采样 2 帧(2 fps)的视频进行训练
- 使用8 块A100 GPU
-
评估指标
- Trigger Accuracy(触发准确率):评估流式视频大语言模型是否在整个视频流中在正确的帧(时间步)做出响应。
- Timing Validity(时间有效性):综合评估流式视频大语言模型是否在整个视频流中始终做出正确的决策 —— 在需要时发言,在无关帧保持沉默。
- BLEU、METEOR、ROUGE-L:对 StreamingVD 过程中的对话内容进行更全面的质量评估。
- LM-PPL (语言模型困惑度) 和 LM-Correctness (语言模型正确率):用于在特定时间戳上评估语言生成的准确性;
- TimeDiff (时间差):衡量流式视频大语言模型响应的时间对齐程度;
- Fluency :综合评估语言质量与时间一致性的指标。
3.2 流式与离线综合评估
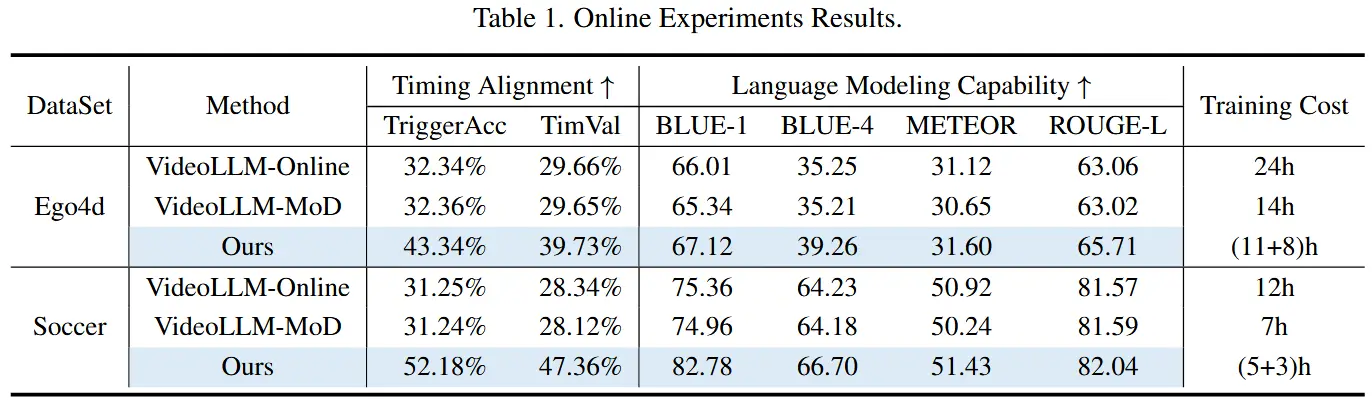
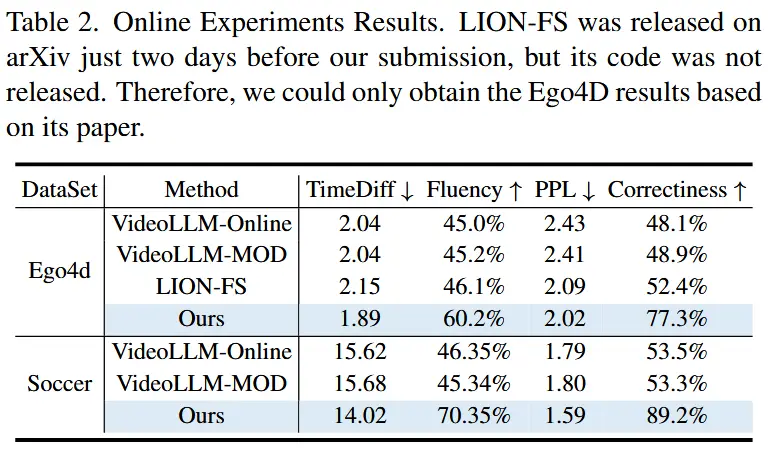
- 在线实验
- 实验结果展现在表1和表2中,使用不同的评估指标。
- STREAMMIND 展现出全面优于现有方法的表现。此外,STREAMMIND 的视频处理帧率比现有方法高出10倍
- 离线实验
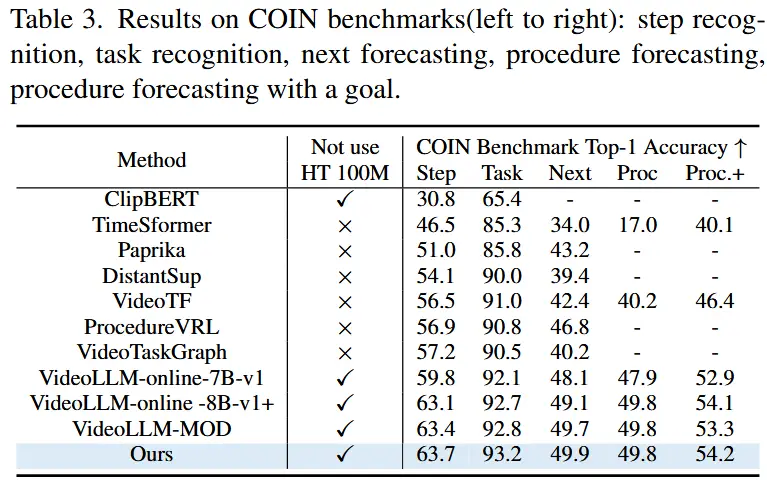
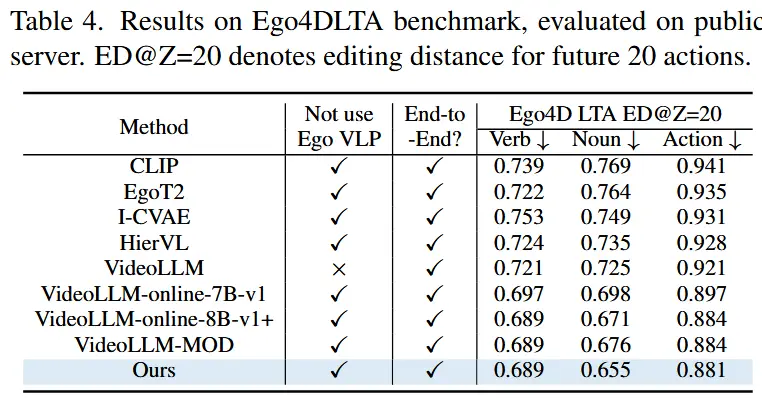
- 为了验证在传统离线视频任务中的有效性,作者还使用了 COIN [52] 和 Ego4D LTA [24] 数据集进行测试,覆盖六个常见任务。
- 结果如表3和表4所示,STREAMMIND在所有任务上均达到了SOTA。
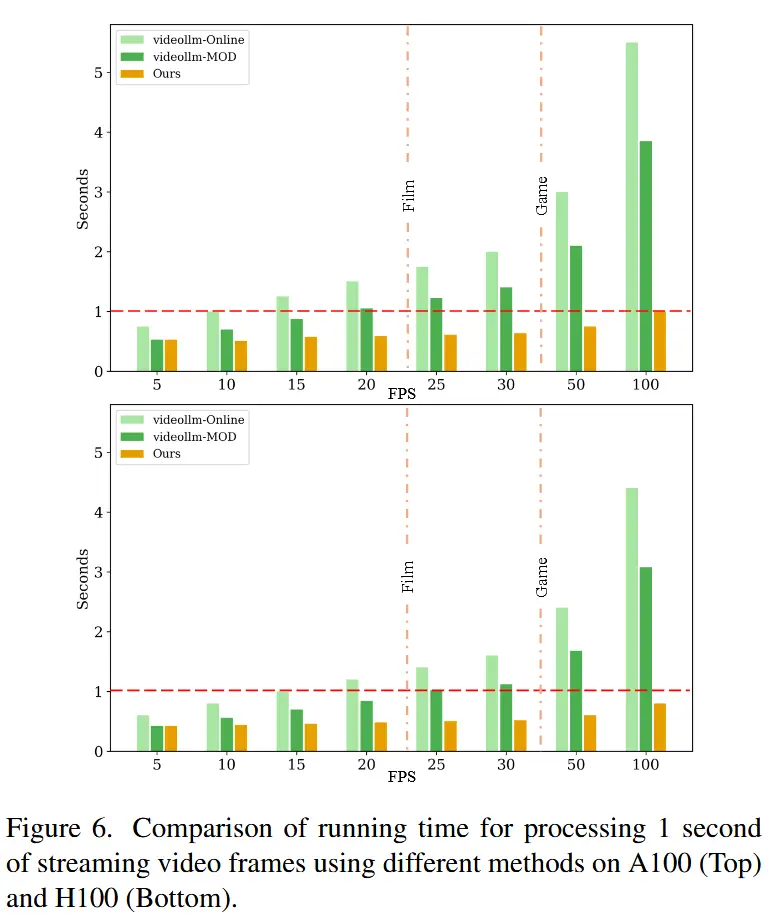
3.3 实时推理效率
- 为了验证实时推理性能, 在不同输入帧率(5 FPS 至 100 FPS)下对1秒视频的实际处理时间进行了比较。
- 如图6所示,处理时间低于1秒即意味着可以实现实时响应而不影响视频播放流畅度。
- STREAMMIND 实现了真正的实时性能。