- 论文 - 《Posture-based Infant Action Recognition in the Wild with Very Limited Data》
- 代码 - Github
- 关键词 - 婴儿动作识别、姿态估计、数据集InfAct、视频模态
摘要
- 研究问题
- 自动检测婴儿的动作视频有助于在婴儿期早期发现运动功能障碍。
- 目前大多数动作识别的方法和数据集都针对成人。
- 本文工作
- 提出了一种高效利用数据的婴儿动作识别流程,其核心思想是将一个动作用一个时间序列来建模,该序列由两种不同的稳定姿势组成,并在它们之间包含一个过渡阶段。
- 这些姿势通过逐帧分析估计出的婴儿2D和3D身体姿态进行检测,而动作序列则根据每帧的姿势驱动低维特征进行分割。
- 作者还创建并发布了首个面向婴儿动作识别的数据集——InfAct,该数据集包含200个完全标注的家庭视频,涵盖了多种常见的婴儿动作,旨在作为公共基准数据集。
1 引言
- 最近关注儿童和青少年识别行为或运动障碍的工作 [2,7,8,19,27,37,38]。
- 儿童动作识别的意义
- 婴儿期早期的运动发育与儿童时期认知、社交和语言能力的发展之间存在密切关联 [18, 22]。
- 儿童较差的运动技能也与发育迟缓有关,包括但不限于自闭症谱系障碍(ASD)和发展性语言障碍 [10, 32]。
- 该技术可以帮助识别高风险婴儿、评估行为干预项目的效果,并促进更有意义的照护者与婴儿之间的互动。
- 困难:基于视频的动作数据集规模小、且截至目前尚无公开可用的婴儿动作数据集。
- 本文工作
- 提出了一种新的婴儿动作识别算法,该方法通过将每个婴儿动作表示为“起始姿势状态 → 过渡状态 → 结束姿势状态”的序列来应对数据量有限的问题。
- 此外,作者还设计了一个视频分割模块,用于检测过渡状态的起始与结束时间点;结合分割结果以及逐帧的姿势概率信息,即可确定动作的类别标签。
- 为了推动该领域的发展,我们还整理并发布了首个面向婴儿动作识别的视频数据集(InfAct),包含200段婴儿视频,并附有精确的姿势状态和过渡阶段的标注信息。
动作姿势是根据阿尔伯塔婴儿运动量表(Alberta Infant Motor Scale, AIMS)[29]定义的,是婴儿在一岁前经历的主要发育里程碑动作。
2 相关工作
- 婴儿动作识别的挑战:主要源于数据稀缺问题——包括隐私顾虑、婴儿动作的高度变异性,以及非专业人士难以对其进行准确标注等因素。
- 本节将从方法和数据集两个角度来回顾相关工作。
- 婴儿姿态、姿势与动作识别
- [14] 构建了一个面向婴儿领域的姿态估计网络,该网络基于一个预训练的成人姿态估计模型进行领域适应,在 SyRIP 图像数据集上进行了训练与测试。
- [44] 提出了一种结合 ResNet-50 主干网络与关键点位置编码的联合特征编码模型,以生成高分辨率的婴儿姿态热力图。然而,该模型仅专注于婴儿仰卧状态下的姿态估计。
- [4] 提出了一种基于视觉 Transformer 的深度聚合框架用于婴儿姿态估计。他们利用了一个名为 AggPose 的大规模婴儿姿态数据集,其中包含姿态标签和临床标签,并通过其 Transformer 模型从视频中的运动帧中检测婴儿仰卧时的姿态。
- [48] 则提出了一种基于3D人体姿态估计和场景上下文信息的分层姿势分类器。他们结合了 ResNet-50、stacked hourglass network 和 3D 姿态估计方法进行姿势分类,并使用估计出的3D关键点来预测婴儿姿势。
- [9] 提出了 BabyNet 模型,用于捕捉婴儿伸手抓取的动作。该模型采用长短时记忆网络(LSTM)来建模伸手动作不同阶段之间的运动相关性,但并未涵盖其他类型的婴儿动作。
- 局限:上述研究大多仅限于基于图像的婴儿姿态或姿势预测,关于婴儿动作识别的研究仍较为有限。
- 婴儿姿态、姿势与动作数据集
- babyPose [26] 包含超过1000段早产儿(年龄在2至6个月之间)的视频,使用深度感知摄像头拍摄,并为每一帧标注了12个肢体关节位置。
- SyRIP [14] 是一个面向婴儿姿态估计的图像数据集,包含700张来自YouTube和Google图片的真实婴儿图像,以及通过渲染带有视角、姿态、背景和外观增强变化的SMIL(Skinned Multi-Infant Linear)身体模型生成的1000张合成婴儿图像。所有图像均标注了17个关键关节,每张真实图像还附带四种姿势类别标签(即仰卧、俯卧、坐姿和站姿)。
- MINI-RGBD [12] 被提出作为评估婴儿姿态估计算法的标准基准数据集。它包含了最多7个月大、处于仰卧状态的婴儿的RGB图像和深度图像。这些图像是通过 SMIL 模型生成的逼真婴儿身体运动序列,具有精确标注的2D和3D共24个关节点位置。
- AggPose [4] 提出用于训练深度聚合Transformer模型以实现人类/婴儿姿态检测。作者使用 General Movements Assessment(GMA)设备记录处于仰卧状态的婴儿运动视频,共采集了超过216小时的视频内容,并从中提取出1500万帧。他们从这些视频中随机采样了20,748帧,并由专业临床医生标注了婴儿的21个关键点位置。
- 局限:babyPose、MINI-RGBD 和 AggPose 主要聚焦于婴儿在仰卧状态下的简单姿势,只能用于姿态估计或行为分析,难以应对婴儿在学习翻身、坐起或站立等更复杂动作时的姿态和运动模式。SyRIP 仅适用于训练基于单帧图像的模型,无法用于动态动作学习,如动作或活动识别。
3 方法
- 数据集:一个全新的、面向真实场景(in-the-wild)的婴儿动作数据集。该数据集包含经过标注的婴儿动作视频,每段视频都被剪辑为仅包含一个从初始稳定姿势到最终稳定姿势之间的完整过渡过程(例如:坐姿 → 坐起-站立过渡 → 站立)。
- 三阶段处理流程:
- 基于姿态的婴儿姿势分类模型:模型对每一帧进行预测,输出当前帧的姿势类别及其对应的概率;
- 过渡状态分割模型:该模型被训练用于预测姿势过渡阶段(即两个稳定姿势之间)的起始和结束时间;
- 动作识别模型:通过对稳定姿势阶段前后的姿势预测概率信号进行平滑处理,识别出每个稳定阶段的姿势类别,并据此生成最终的动作标签。
- 问题定义:
将婴儿动作视为从一种稳定姿势到另一种稳定姿势的转变,其间包含一个过渡期,且稳定姿势被定义为持续时间至少为一秒的姿势。形式上,视频表示为图像帧序列 X = (x^1, \dots, x^T) ,其中 T 表示视频的总帧数。视频中婴儿动作的标签形式为 A = (p^s, p^e) ,其中 p^s 和 p^e 分别代表起始和结束的稳定姿势,它们属于集合 \{\text{Supine}, \text{Prone}, \text{Sitting}, \text{Standing}, \text{All-fours}\} ,这五个姿势类别来源于 AIMS 运动量表指南 [29]。我们还假设 p^s \neq p^e ,因此基于这些姿势组合可以得到 20 种可能的动作类别。对于给定的动作 A ,其稳定姿势之间的过渡期由 Y = (y^s, y^e) 给出,其中 y^s 是起始姿势 p^s 的最后一帧索引,而 y^e 是结束姿势 p^e 的第一帧索引,并且满足 y^e > y^s 。
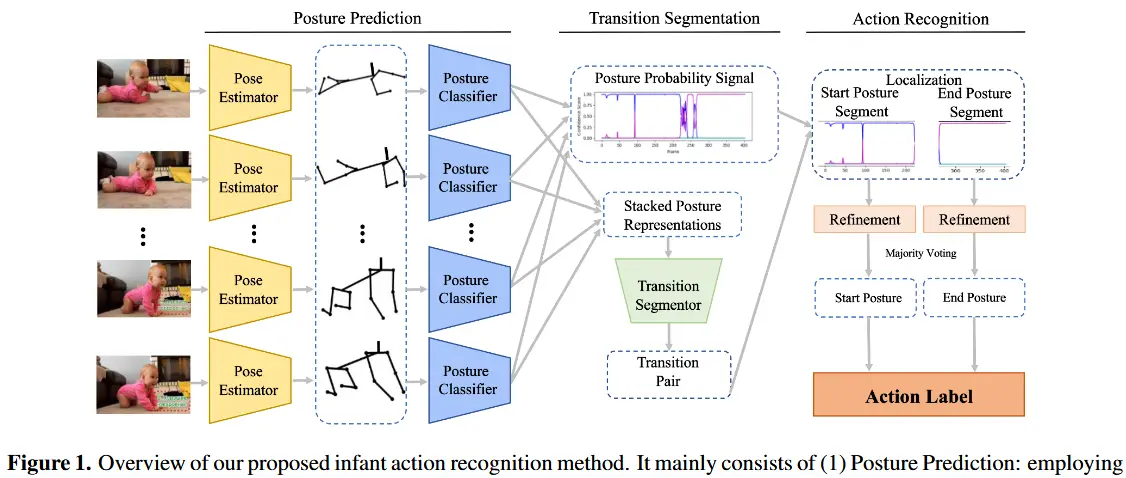
3.1 婴儿动作识别流水线
如前所述,婴儿动作识别方法按由姿势预测器、过渡分割器和动作识别器三部分组成。
3.1.1 姿势预测
作者对文献 [15] 中提出的独立于外观的姿势分类方法进行了修改,将其应用于动作视频序列 X 的每一帧 x^t ,以获得每帧的姿势预测 p^t ,其中 t \in \{1, \dots, T\} 。工作原理分为以下两步:
- 姿态估计:提取二维(2D)或三维(3D)人体骨骼姿态预测 J^t \in \mathbb{R}^{N \times D} ,其中 N = 12 表示骨骼关节的数量,而 D \in \{2, 3\} 表示坐标的维度(即空间维度)。底层的姿态估计器专门针对婴儿领域进行了调整
- 用于2D:为针对婴儿领域的优化域适应婴儿姿态(FiDIP)模型 [14]
- 用于3D:启发式弱监督3D人体姿态估计婴儿(HW-HuP-Infant)模型 [25]。
- 姿态分类:然后,将姿态 J^t 输入到基于2D或3D姿态的姿势分类器中,从而得到姿势预测 p^t 。然而,原始的姿势分类模型 [15] 只能输出四种姿势类别,因此作者使用从SyRIP数据集提取的五类图像重新训练其网络。(训练细节见第4.2节)
3.1.2 过渡分割
改编文献 [1] 中的语音序列分割模型来预测过渡期的帧索引 Y = (y^s, y^e) 。
- 输入:姿态估计模型的最后一层输出的底层特征向量 \bar{p} = (\bar{p}^1, \dots, \bar{p}^T) 。
- 语音序列分割模型:双向循环神经网络(Bi-RNN)。
- 输出:在训练过程中,模型会搜索可能的起始和结束过渡时间,输出预测的过渡状态 \bar{Y} 。
- 训练:最小化每个数据点 \bar{p} 预测的过渡状态 \bar{Y} 与真实标签 Y 之间的距离损失函数。
3.1.3 动作识别
- 任务:预测稳定起始段和稳定结束段的姿势类别。
- 分割处理:过渡分割预测给出了帧索引 Y = (y^s, y^e) ,从中可以分别导出稳定起始段和稳定结束段的子序列姿势预测: (p^1, \dots, p^{y^s}) 和 (p^{y^e}, \dots, p^T) 。
- 平滑预处理:应用不同的移动平均技术 [46] 来平滑短期波动并突出更长的趋势,从而获得平滑后的姿势序列 (\hat{p}^1, \dots, \hat{p}^{y^s}) 和 (\hat{p}^{y^e}, \dots, \hat{p}^T) 。
- 识别:通过多数投票聚合这些序列,生成最终的类别估计 A = (\hat{p}^s, \hat{p}^e) 。
3.2 InfAct:婴儿动作数据集
- 数据:包含200段婴儿活动视频片段和400张婴儿姿势图像,配有结构化的动作和过渡分割标签。
- 视频数据形式:包括从一个稳定起始姿势到另一个稳定结束姿势的过渡。动作片段被标注了过渡期的起始和结束时间戳,以及初始和最终稳定姿势阶段的姿势类别标签。
- 婴儿年龄:3至18个月。
- 视频片段的分辨率从720 × 576像素到1280 × 720像素不等。
- 录制环境:104段视频来自客厅,71段来自卧室,20段来自户外,3段来自浴室,1段来自厨房,1段来自操场。
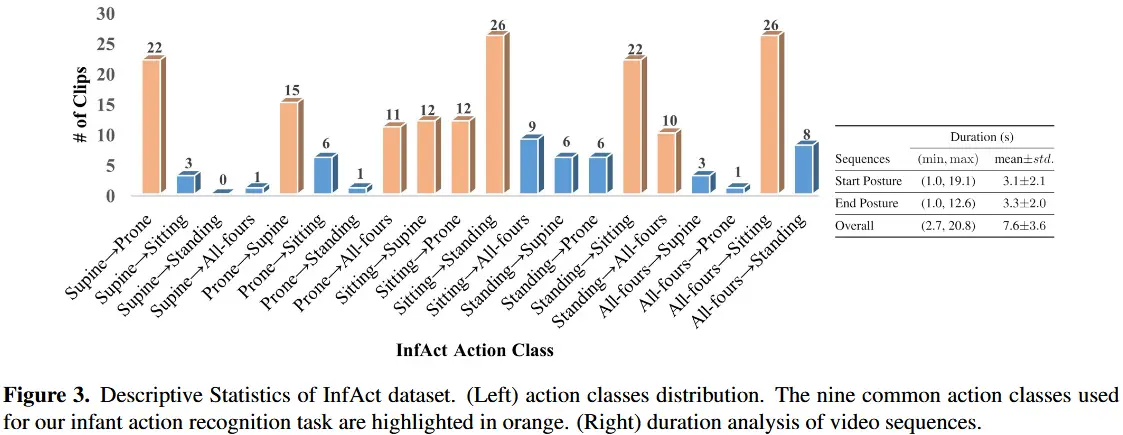
- 图3展示了InfAct的数据统计分析。
4 实验
使用InfAct数据集来评估三个模型组件的性能,包括姿势分类、过渡分割和动作识别。
4.1 数据集
- 数据集处理
- 对于动作识别组件,使用50段视频作为测试集。
- 对于过渡分割组件,使用剩余的150段作为训练集。
- 对于姿态分类组件,从InfAct每段视频的起始和结束位置各提取一帧图像(共400张),按照300:100划分训练集和测试集。同时,还对SyRIP数据集中的700张婴儿图像进行了重新标注,按照600:100的比例划分训练集和测试集。
4.2 基于姿态的姿势分类
- 模型训练和微调
- 首先在 SyRIP 数据集上训练了基于 2D 和 3D 姿态的姿势分类网络。
- 随后在 InfAct 的训练图像上对已训练好的网络进行微调。
- 模型结构包含四个全连接层。
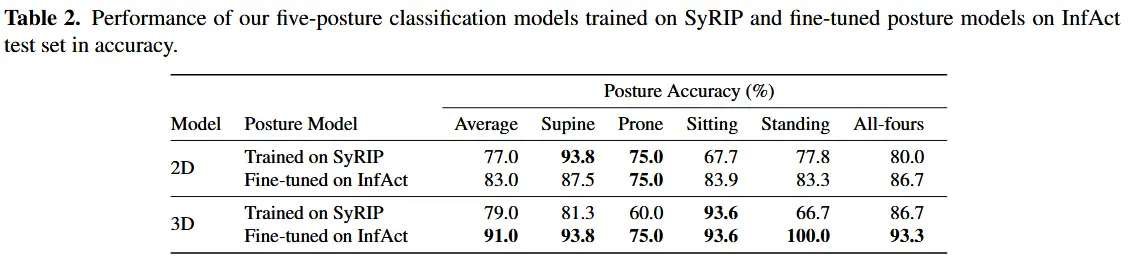
- 表2中报告了仅在 SyRIP 上训练的初始模型以及进一步在 InfAct 上微调后的模型的姿势预测准确率。
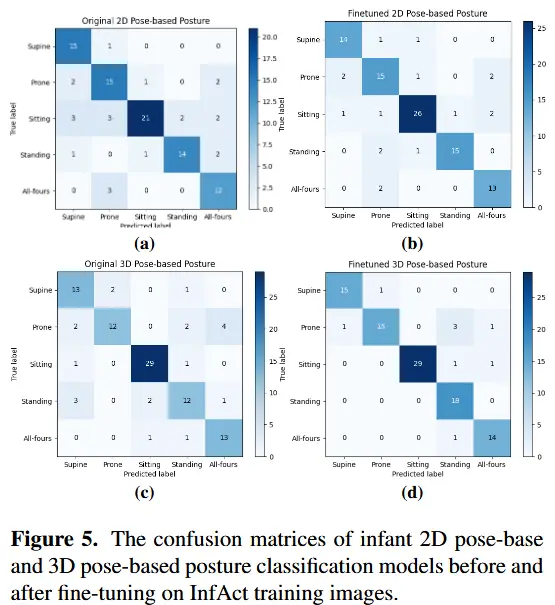
- 图5中对应的预测混淆矩阵进一步验证了模型的优异表现。
4.3 基于姿势的过渡阶段分割
- 模型训练
- 在 InfAct 数据集上训练了过渡分割网络,输入数据来源于前一步姿势估计模型的输出。
- 模型结构由两个双向LSTM(Bi-LSTM)层组成。
- 过渡分割的输入(姿态估计的输出)
- 姿势概率:对于长度为 L 的序列,输入维度为 L × C 的类别概率,其中 C 代表五个姿势类别。
- 关键点位置:对于长度为 L 的序列,通过PCA降维,将原本为 17×2 或 17×3 维度(取决于空间维度为2D或3D)的关键点坐标向量降至 K = 10 维,最终输入维度为 L × K。
- 姿势特征:通过对姿势估计模型倒数第二层中的图像特征表示向量进行PCA降维后得到的残差向量。通过PCA将原始16维特征向量降至 K = 10 维,整体输入维度为 L × K。
- 预测值 \tilde{Y} = (\tilde{y}^s, \tilde{y}^e) 相对于真实标签 Y = (y^s, y^e) 的损失由结构化损失(structured loss)给出:
-
其中, y^i 和 \tilde{y}^i 分别表示真实标签和预测值中的起始点或结束点, \tau 是一个阈值参数,用于控制损失函数的敏感度。
-
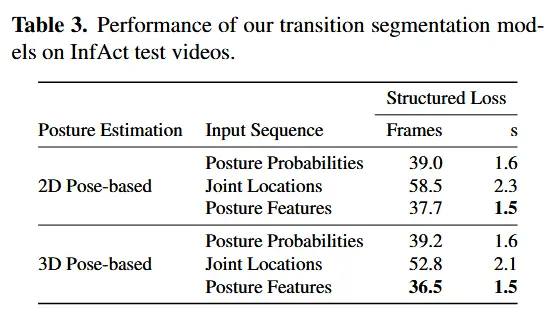
基于结构化损失(structured loss)的过渡阶段分割模型的测试结果如表3左侧所示。
- 使用姿势特征作为输入时,过渡阶段分割的性能最优。
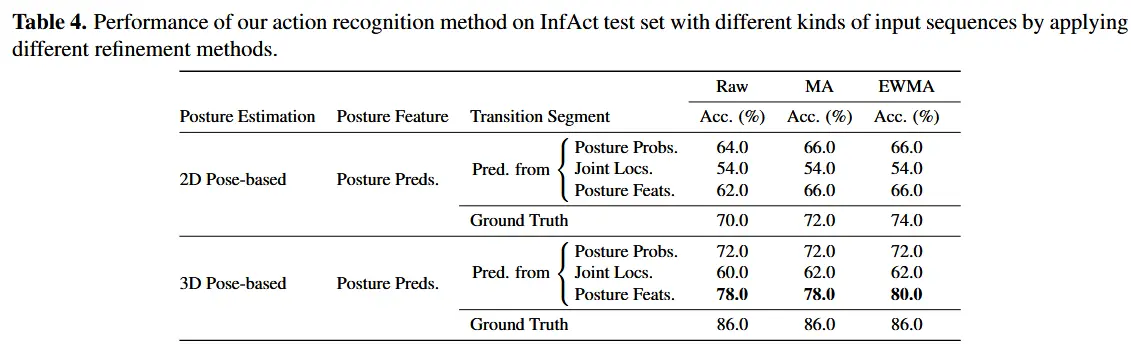
4.4 基于姿势的动作识别
动作识别的最后一步是对起始和结束阶段的稳定姿势进行多数投票,从而推断出整个视频片段的动作类别。作者测试了不同姿态估计模型(2D/3D)、不同输入特征(概率、坐标、特征)以及两种平滑方法(移动平均MA、指数加权移动平均EWMA)对结果的影响。
实验结果显示:
- 使用 3D姿态模型特征 作为输入的过渡段分割表现最佳;
- 分割性能显著影响最终动作识别:分割误差减少约0.8秒,动作识别准确率提升了高达24个百分点,达到 78.0%;
- 若使用真实标注的过渡段,准确率可进一步提升至 86.0%;
- 平滑方法中,EWMA略优于MA,但由于数据量有限,难以做出更明确的结论。
总体来看,动作识别性能主要由过渡段分割质量决定,且因“双阶段多数投票”机制,其准确率大致为姿势识别准确率的平方,因此任何在分割上的改进都会被放大到最终动作识别效果上。
本研究验证了在有限数据下,基于稳定姿势过渡模板的婴儿动作识别方法是可行的。