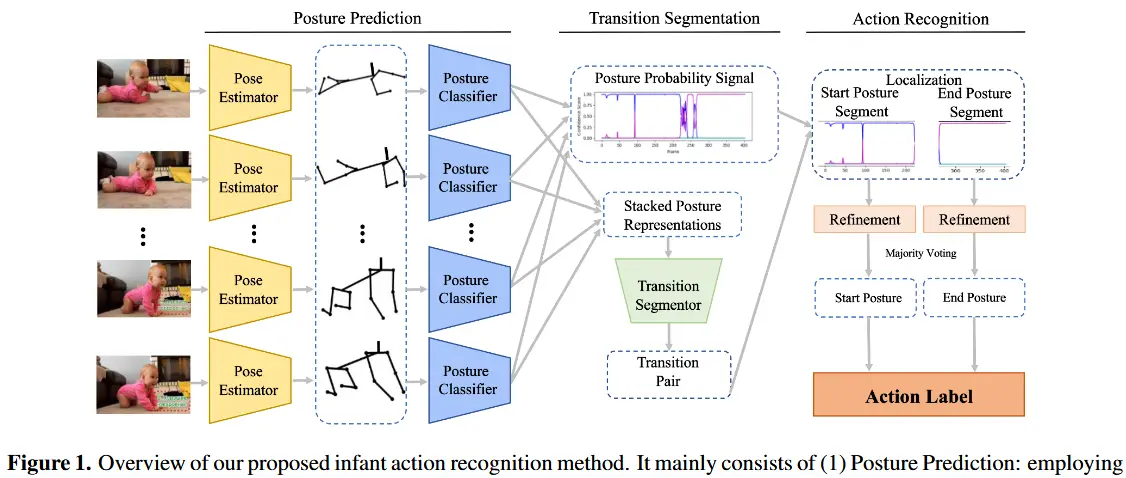
- 论文 - 《IMAGEBIND: One Embedding Space To Bind Them All》
- 代码 - Github
- 关键词 - CVPR2023、多模态联合学习、无监督学习、模态对齐、大模型
摘要
- 本文贡献
- (1)提出 ImageBind 方法,一种能够在六种不同模态之间学习联合嵌入空间的方法,包括:图像、文本、音频、深度、热成像和惯性测量单元(IMU)数据。ImageBind 借助大视觉-语言模型的强大能力,通过图像的自然配对关系将其零样本(zero-shot)能力扩展到新的模态。
- (2)本文证明,在训练这种联合嵌入空间时,并不需要所有组合的配对数据,仅需图像配对的数据就足以将各模态绑定在一起。
- (3)作者发现,这些新兴能力随着图像编码器性能的增强而提升,并在跨模态的零样本识别任务中达到了新的最先进水平,甚至超过了专门设计的监督模型。
1 引言
- 直观动机:一张图像可以将多种体验联系在一起,例如海滩的照片会想起海浪声、沙子触感、微风等等。
- 猜想:在一个统一的联合嵌入空间中,视觉特征应该通过与所有相关模态的对齐来学习。
- 困难:需要获取同一组图像下所有类型和组合的配对数据,缺乏大规模的多模态数据集,其中所有模态都同时存在。
- 解决办法 - ImageBind
- 利用网络规模的(图像,文本)配对数据,并结合自然界中存在的其他模态配对数据(如(视频,音频)、(图像,深度)等),来学习一个统一的联合嵌入空间。
- 这种方法使得 IMAGEBIND 能够隐式地将文本嵌入与其他模态对齐,从而在没有显式语义或文本配对的情况下,也能实现该模态上的零样本识别能力。
- 其他发现
- IMAGEBIND 可以初始化自大规模视觉-语言模型(如 CLIP),从而继承这些模型丰富的图像与文本表示能力。因此,IMAGEBIND 可以被应用于多种不同的模态和任务,且所需的训练量非常小。
- IMAGEBIND 在每种模态的任务上都具有强大的零样本分类和检索性能,这些新兴能力随着底层图像表示能力的增强而提升。
2 相关工作
- 语言-图像预训练
- CLIP [60]、ALIGN [31] 和 Florence [83] 收集了大量图文配对数据,并利用对比学习训练模型,将图像和语言输入嵌入到一个统一的联合空间中,展现出令人印象深刻的零样本性能。
- CoCa [82] 在对比损失的基础上增加了图像描述生成目标,以进一步提升性能。
- Flamingo [1] 能够处理任意交错的图像和文本输入,在多个少样本学习基准上达到了最先进水平。
- LiT [84] 则采用对比训练方式进行微调,并发现冻结图像编码器效果最佳。
- 局限:仅限图文两个模态。
- 多模态学习
- 已有研究探索了在有监督 [21, 42] 或自监督 [3, 20, 50, 70, 74] 情境下对多个模态进行联合训练。
- 与IMAGEBIND最为接近的是 Nagrani 等人 [51] 的研究,他们构建了一个弱标注的视频-音频-文本三元组数据集,使得可以训练多模态视频-音频编码器与文本特征匹配,从而实现出色的音频和视频检索与描述性能。
- AudioCLIP [27] 则将音频作为额外模态引入 CLIP 框架,实现了零样本音频分类。
- 局限:需要所有模态之间都存在显式的配对数据,或者需要监督信号。
3 方法
方法目标:通过图像作为桥梁,将多种模态联合在一起,在一个统一的嵌入空间中进行表示学习。
图2中展示了本文方法框架。

3.1 预备知识
- 特定模态对的对齐
- 通常使用对比学习,一种通用的学习嵌入空间的方法,它通过使用相关的样本对(正例)和不相关的样本对(负例)来进行训练。利用已对齐的观测数据对,对比学习可以实现不同模态之间的对齐。
- 然而,在每种情况下,联合嵌入空间都是基于相同的模态对进行训练和评估的。
- 使用文本提示的零样本图像分类
- CLIP 通过对齐嵌入空间,获得了强大的零样本分类能力。
- 要让其他模态也具备类似的零样本分类能力,通常需要专门使用该模态与文本的配对数据进行训练。
- 而IMAGEBIND 能够在没有文本配对数据的情况下,解锁其他模态的零样本分类能力。
3.2 使用图像绑定模态
IMAGEBIND 使用模态对 (\mathcal{I}, \mathcal{M}),其中 \mathcal{I} 表示图像,\mathcal{M} 表示另一种模态,来学习一个单一的联合嵌入空间,\mathcal{M} 的模态包括文本、音频、深度、热成像、IMU。
考虑模态对 (\mathcal{I}, \mathcal{M}) 的对齐观测值。给定一张图像 \mathbf{I}_i 和其在另一模态中的对应观测值 \mathbf{M}_i,我们将它们编码为归一化的嵌入:\mathbf{q}_i = f(\mathbf{I}_i) 和 \mathbf{k}_i = g(\mathbf{M}_i),其中 f, g 是深度网络。嵌入和编码器通过 InfoNCE 损失进行优化:
其中,\tau 是温度参数,j 表示无关的观测值,也称为“负样本”,将小批量中所有 j \neq i 的样本视为负样本。该损失使得嵌入 \mathbf{q}_i 和 \mathbf{k}_i 在联合嵌入空间中更接近,从而对齐了 \mathcal{I} 和 \mathcal{M}。在实践中,使用对称损失 L_{\mathcal{I}, \mathcal{M}} + L_{\mathcal{M}, \mathcal{I}}。
(未见模态对的新兴对齐)
IMAGEBIND 利用与图像配对的模态,即形式为 (\mathcal{I}, \mathcal{M}) 的模态对,将每个模态 \mathcal{M} 的嵌入与其对应的图像嵌入对齐。作者在嵌入空间中观察到一种新兴行为:仅使用 (\mathcal{I}, \mathcal{M}_1) 和 (\mathcal{I}, \mathcal{M}_2) 这样的配对进行训练,也能对两个模态对 (\mathcal{M}_1, \mathcal{M}_2) 实现对齐。这种行为使IMAGEBIND能够在无需针对模态 (\mathcal{M}_1, \mathcal{M}_2) 进行训练的情况下,执行广泛的零样本和跨模态检索任务。
3.3 实现细节
IMAGEBIND 在概念上简单,可以有多种实现方式。本节介绍的是基础而灵活的实现方案,以便于进行有效的研究和便捷的应用。
- 每个模态使用不同的模态编码器,但是全部使用Transformer架构。
- 图像:Vision Transformer。
- 视频:按照 [20] 的方法对 ViT 的 patch 投影层进行时间扩展(temporally inflate),使用从 2 秒视频中采样的 2 帧片段。
- 音频:参照 [22] 的方法,将 2 秒、采样率为 16kHz 的音频信号转换为梅尔频谱图(mel-spectrogram),使用 128 个频率通道。由于频谱图也是一种类似于图像的二维信号,使用 patch size 为 16、stride 为 10 的 ViT 来处理它。
- 热成像和深度图像:将它们视为单通道图像,并同样使用 ViT 进行编码。为了实现尺度不变性,按照 [21] 的做法将深度图像转换为视差图(disparity maps)。
- IMU 数据:提取 X、Y 和 Z 轴上的加速度计和陀螺仪数据。使用 5 秒的片段,共包含 2000 个时间步的 IMU 数据。通过一个核大小为 8 的一维卷积层进行投影,之后使用 Transformer 对结果序列进行编码。
- 文本:采用 CLIP [60] 中的文本编码器设计。
- 为每个编码器添加一个模态特定的线性投影头,用于输出固定维度 d 的嵌入向量。该嵌入向量经过归一化后,用于 Eq(1) 中的 InfoNCE 损失计算。
- 编码器可以使用其他模型已经训练好的编码器,省去重复训练。
这一策略不仅提升了模型性能,也增强了跨模态表示的统一性和泛化能力。
4 实验
- 自然配对的模态与数据集
- Audioset:视频音频对
- SUN RGB-D:图像深度图对
- LLVIP:图像热成像对
- Ego4D:视频IMU对
- 注意这些模态对不适用任何额外的监督信号(如类别标签、文本等)
- 大规模图文配对数据
- 直接使用已经预训练好的视觉编码器和文本编码器(来自OpenCLIP[11,30])
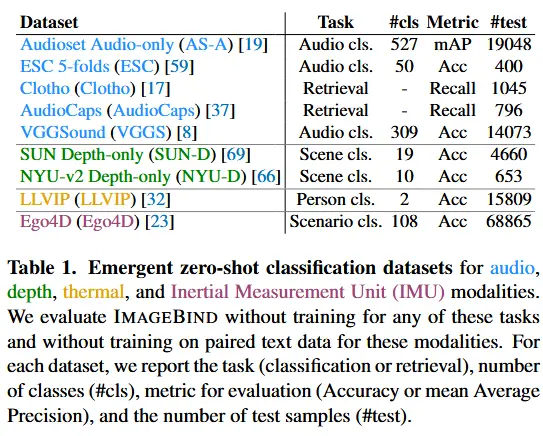
- 下游任务评估数据集如表1所示。
4.1 新兴零样本分类
- 新兴零样本分类:仅使用图像配对的数据(图像+文本、图像+音频)来绑定模态,IMAGEBIND 就可以执行(文本+音频)的零样本分类。换句话说,无需任何特定模态与文本的直接配对训练,就能实现跨模态的零样本识别 。
- 基线:由于没有类似能力的基线,作者选择了使用特定模态与文本配对训练的方法、CLIP、监督模型的上限性能作为基线。
- 结果如表2所示,IMAGEBIND 在新兴零样本分类任务中表现出色。在每一项基准任务中,IMAGEBIND 都取得了显著的性能提升,甚至优于针对特定模态和任务专门训练的监督模型 。

4.2 与先前工作的比较
- 将 IMAGEBIND 与先前工作在零样本检索和分类任务中进行比较
- 零样本文本到音频检索和分类
- 表3中将先前工作的零样本文本到音频检索和分类性能与 IMAGEBIND 的新兴检索和分类性能进行了比较,IMAGEBIND 在音频文本检索基准上显著优于先前的工作。

- 文本到音频和视频检索
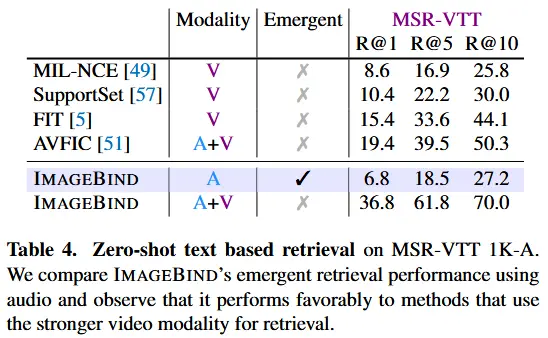
- 使用 MSR-VTT 1k-A 基准评估文本到音频和视频检索性能,结果见表4。
4.3 少样本分类
- 使用来自 IMAGEBIND 的音频和深度编码器,并分别在音频和深度分类任务上进行评估
- 少样本音频分类结果如图3左,使用自监督 AudioMAE 模型和监督型 AudioMAE 模型作为基线。
- 少样本深度分类结果如图3右,使用 MultiMAE 作为基线。