- 论文- 《UniMTS: Unified Pre-training for Motion Time Series》
- 代码 - Github
- 关键词 - 大模型LLM、人体活动识别HAR、泛化、小样本、无监督学习、对比学习
1 引言
-
为什么研究HAR无监督学习?
- 由于隐私和安全问题,大规模收集运动时间序列数据较难。
- 这类数据形式抽象,难以手工标注。
- 因此,数据不足的问题阻碍了监督学习方法的发展。
-
三个运动时间序列领域特有的泛化挑战
- (1)设备佩戴位置的变化。
- (2)在数据采集过程中,设备可能处于任意方向(姿态)。
- (3)不同的运动时间序列数据集可能关注不同类型的活动, 针对特定类型活动训练的模型,通常难以泛化到由其他数据集引入的新活动类型中。
-
本文工作 - UniMTS
- 首个面向运动时间序列的统一预训练方法,能够在多种设备潜在因素和活动类型之间实现良好的泛化。
- 采用了一种对比学习框架
- 将运动时间序列与由大语言模型(LLM)增强的文本描述进行对齐。
- 有助于模型学习时间序列的语义信息,从而实现对各类活动的有效泛化。
- 为了获得可用于预训练的大规模运动时间序列数据,作者基于现有且涵盖广泛身体部位的运动骨架数据合成了这些时间序列。
- 作者使用时空图神经网络对这些合成的时间序列进行建模,以捕捉设备之间的时空关系,从而实现对不同设备位置的泛化。
- 此外,作者还实现了旋转不变性增强技术 ,以确保模型在测试阶段对设备方向变化具有鲁棒性。
2 相关工作
- 传统的运动时间序列分类方法
- 通常为每个数据集训练一个专用的分类器,可以分为两类:统计特征提取方法 和深度学习方法。后者包括:MA-CNN、SenseHAR、Rocket、DeepConvLSTM、AttnSense 和 THAT。
- 近期一些研究尝试引入生成能力进行辅助训练,例如 IMUGPT 可以根据活动的文本描述生成运动序列,并用于训练传统的分类模型。
- 一些面向通用任务的时间序列模型也被提出,如 TimesNet 、GPT4TS 和 TEST ,它们适用于包括分类在内的多种任务。
- 局限:这些模型大多在同一数据集上进行训练和测试,难以实现跨数据集的泛化能力。
- 自监督运动时间序列表示学习方法
- 这类方法首先通过自监督目标学习时间序列的通用表示,之后再对特定下游任务进行微调。常见的自监督策略包括:
- 掩码重建:如 TST、TARNet、LIMU-BERT;
- 对比学习:如 TNC、TS-TCC、TS2Vec、TF-C、FOCAL、CL-HAR、DDLearn;
- 其他自监督目标:如 BioBankSSL、Step2Heart。
- 局限:这些方法表示学习与微调阶段通常仍在相同或高度相似的数据集上进行,因此在面对多样化数据集时仍面临泛化能力不足的问题。
- 这类方法首先通过自监督目标学习时间序列的通用表示,之后再对特定下游任务进行微调。常见的自监督策略包括:
- 面向运动时间序列的预训练模型
- ImageBind 和 IMU2CLIP 利用大型视觉-语言模型 学习包含运动时间序列和文本在内的联合嵌入空间。然而,这两者均是在头戴式设备采集的运动数据上进行训练,限制了其在不同设备位置和方向上的泛化能力。
- HARGPT 使用 LLM 处理原始运动时间序列,并结合角色扮演(role-play)和思维链(chain-of-thought)等提示策略。
- ContextGPT 则设计了基于上下文信息的提示工程方法。
- 局限:LLM 并未直接在原始运动时间序列上进行训练,此类方法通常需要大量现实中难以获取的上下文信息,且在识别复杂活动时表现不佳。
- 其他相关工作
- 多模态动作识别方面,如 Ego4D 和 Ego-Exo4D 等基准任务结合了视频和音频模态。
- 而本文关注一种能耗更低且更具挑战性的场景:仅依赖运动时间序列的动作识别。
- 领域自适应方法大多假设源域和目标域具有相同的标签名称和类别数量,例如跨用户或跨数据集的领域自适应,且仅适用于共有的类别 [22, 35, 21]。
- 相比之下,本文关注一个更加通用但也更具挑战性的泛化场景:预训练数据集与下游任务数据集之间具有不同的标签名称。
- 多模态动作识别方面,如 Ego4D 和 Ego-Exo4D 等基准任务结合了视频和音频模态。
3 方法
如图2所示,UniMTS采用一种基于对比学习的预训练方法,流程如下:
- 首先从运动骨架数据中模拟生成运动时间序列 (第3.1节),并对其进行方向泛化的数据增强 (第3.2节)。
- 接着使用图编码器对模拟得到的时间序列进行建模,以捕捉不同关节之间的相关性,从而实现对不同设备位置的泛化 (第3.3.1节)。
- 最后为了增强语义学习,还利用LLM对文本描述进行丰富和扩展(第3.3.2节)。
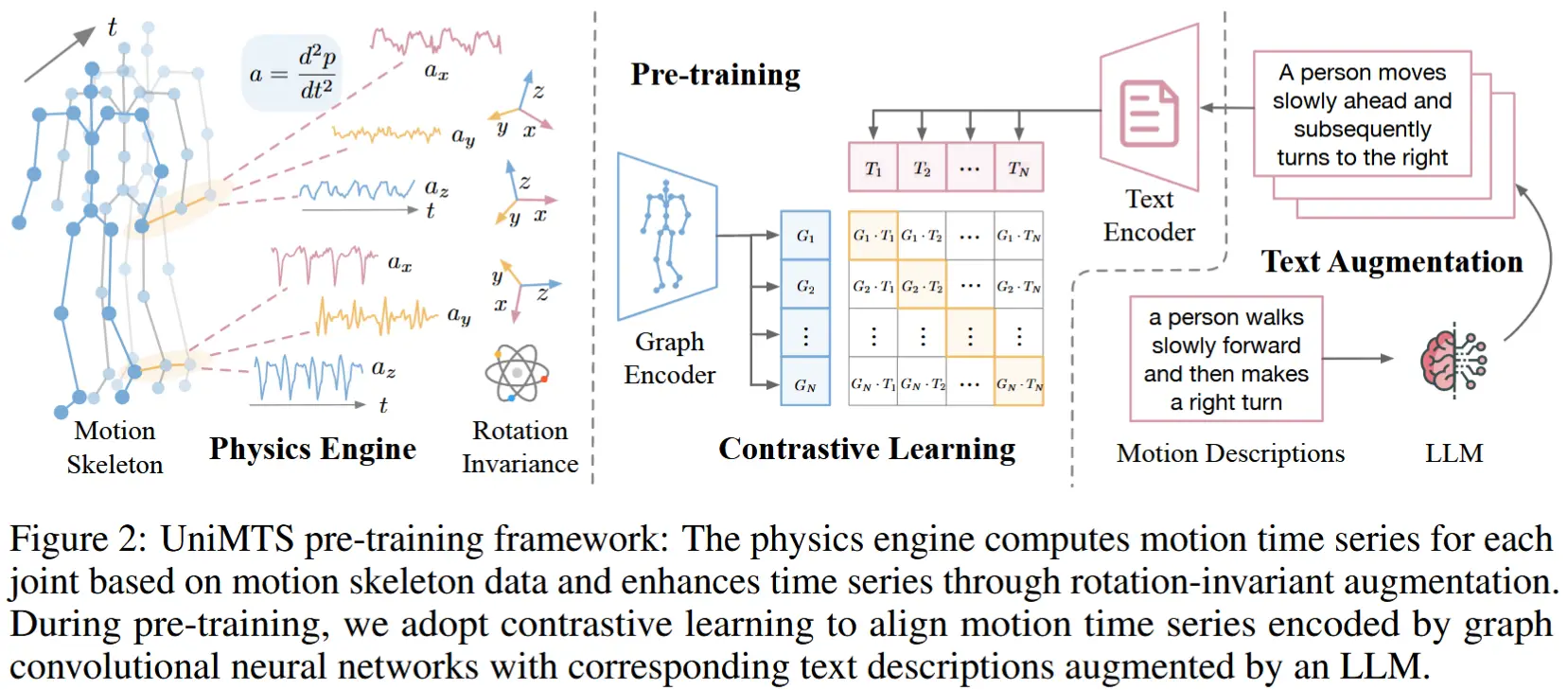
3.1 运动时间序列模拟的物理引擎
核心思想:应用运动方程 [65],从运动骨架数据中合成加速度和角速度的时间序列。
具体而言,对于每个骨骼关节 J_i ,将位置 \mathbf{p}_{J_i, \mathcal{G}}(从时间域 \mathcal{T} 映射到全局坐标系 \mathbb{R}^3)以及方向四元数 \mathbf{q}_{J_i, \mathcal{GL}}(从时间域 \mathcal{T} 映射到特殊正交群 SO(3),在哈密顿约定下表示局部坐标系 \mathcal{L} 到全局坐标系 \mathcal{G} 的旋转)作为输入。为了简化符号表示,后续内容中省略下标 \mathcal{G} 和 \mathcal{GL}。基于运动方程,通过计算位置 \mathbf{p}_{J_i} 的一阶导数和二阶导数来获得速度 \mathbf{v}_{J_i} 和加速度 \mathbf{a}_{J_i}。然后,利用对应的定向四元数序列 \mathbf{q}_{J_i},将这些结果从全局坐标系转换到局部坐标系。类似地,通过计算定向四元数 \mathbf{q}_{J_i} 的一阶导数,可以得到角速度 \boldsymbol{\omega}_{J_i}。数学上,这些计算公式如下:
其中,\otimes 表示四元数乘法运算,而 * 表示四元数共轭。
考虑到实践中传感器携带的噪声是固有的,物理引擎在模拟数据中引入了均值为零的高斯噪声。 将上述运动时间序列表示为 \mathbf{x}_{J_i}(t),它可以表示 \mathbf{a}_{J_i}(t) 或 \boldsymbol{\omega}_{J_i}(t)。带有噪声的时间序列 \tilde{\mathbf{x}}_{J_i}(t) 可以表示为:
其中,\mathbf{n}_{J_i}(t) 是均值为零、标准差为 \sigma 的高斯噪声。
3.2 旋转不变性增强
先前研究泛化能力较差的一个常见限制是未能考虑设备方向对运动时间序列的影响。因此,本文在预训练阶段应用了一种数据增强技术来模拟随机方向,从而使我们的学习模型在部署时实现旋转不变性。具体而言,在预训练过程中,对于每个关节 J_i ,为每次迭代采样一个随机旋转矩阵:
并在时间步 t = 1, 2, \cdots, T 上计算增强后的时间序列 \tilde{\mathbf{x}}_{J_i}^t,公式如下:
在一次迭代中,相同的 \mathbf{R}_{J_i}^\delta 被一致应用于 J_i 的所有时间序列和每个时间步 t = 1, 2, \cdots, T 。
3.3 对比学习
物理引擎生成了充足的运动时间序列数据,这些数据随后通过图神经网络进行编码,并通过对比学习 方式与其对应的文本嵌入进行对齐。
3.3.1 图编码器
为了捕捉不同关节在时间上的时空相关性,采用时空图卷积网络(Spatio-Temporal GCN) 作为运动时间序列的编码器。初始输入图表示如下:
- 骨骼关节 \mathcal{V} 包含关节特征 \mathbf{X} \in \mathbb{R}^{C \times T \times V} ,C、T、V分别表示信号通道数、时间步和关节节点数。
- 空间边 \mathcal{E}_s 根据骨骼结构 \mathcal{H} 连接相邻节点。
- 时间边 \mathcal{E}_t 连接时间上相邻的帧。
在实际应用中,设备可能无法覆盖完整的关节,而是随机分布在完整关节的子集上。为了模拟这种情况,在每次预训练迭代中,随机选择一部分关节,并将剩余关节的数据用零值掩码。我们将掩码表示为 \mathbf{M} \in \mathbb{R}^{C \times T \times V},因此关节特征掩码后:
图卷积网络 g_\phi 首先计算空间输出特征:
其中,K_s 表示空间核大小,\mathbf{A}_k^{ij} 表示节点 x_{J_i} 是否属于节点 x_{J_j} 的空间卷积采样子集 S_{J_j}^k,\Lambda_k^{-\frac{1}{2}} = \sum_l (\mathbf{A}_k^{il}) + \alpha 表示归一化的对角矩阵,其中 \alpha 设置为 0.001 以防止空行。\boldsymbol{\Phi}_k \in \mathbb{R}^{C' \times C \times 1 \times 1} 表示 1 \times 1 卷积操作的权重,C' 表示输出通道维度。
在进行空间卷积后,进一步对空间输出特征 \mathbf{X}_{\text{out}} 执行 K_t \times 1 的时间卷积,类似于经典的卷积操作,其中 K_t 表示时间核大小。最终的图表示 g_\phi(\mathbf{X}) 是通过在空间和时间维度上进行平均池化得到的,最后使用图平均池化层完成。
3.3.2 文本编码器
为了增加预训练语料库中成对文本描述的多样性,旨在应用 GPT-3.5 来增强原始运动文本描述。使用的提示模板如下:
The following one or multiple descriptions are describing the same human activities:
. Generate k paraphrases to describe the same activities.
将原始文本描述与通过LLM增强后的文本描述合并,并表示为 \mathbf{Y}。接着使用与 CLIP 相同的文本编码器 f_\theta 对其进行编码,利用其预训练权重进行初始化。
3.3.3 训练与推理
(预训练阶段)
对比学习最大化成对模拟运动时间序列和文本描述之间的相似性:
其中,B 表示批量大小,\gamma 是控制分布集中度的温度参数,\text{sim} 表示通过内积计算的相似性得分:
使用模拟的运动时间序列和增强后的文本描述对图编码器和文本编码器进行预训练。
(推理阶段)
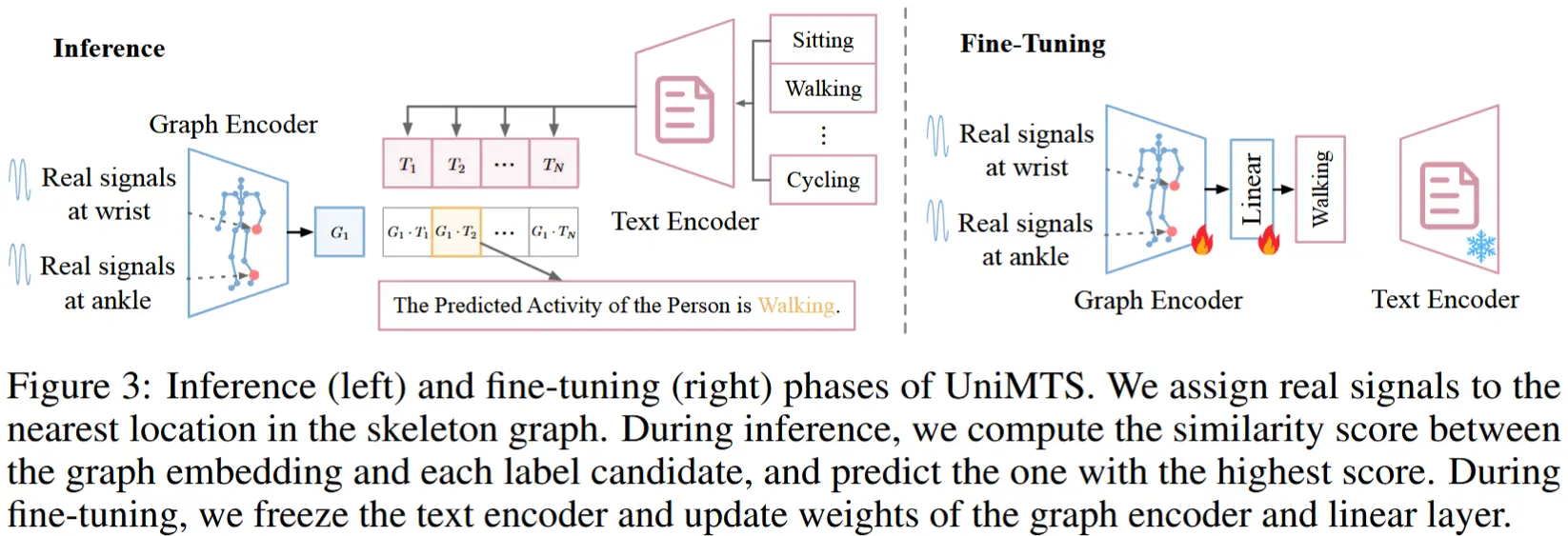
如图3左侧。对于文本编码器输入所有标签候选;对于图编码器,将真实的运动时间序列分配到骨架图中最接近的关节,并将其他关节设置为零值。计算图嵌入与每个标签候选的文本嵌入之间的相似性得分,并选择相似性得分最高的标签作为预测活动。
(微调阶段)(可选)
如图3右侧。具体而言,冻结文本编码器 f_\theta,并更新图编码器 g_\phi 的权重,随后添加一个线性分类器 h_\psi。按照与推理相同的流程,将真实的运动时间序列分配到骨架图中最接近的关节,并将其他关节设置为零值,构建图输入表示 \mathbf{X}。使用 \mathbf{X} 和基于交叉熵损失的独热编码标签 \mathbf{z} 进行微调,其中 \sigma(\cdot) 表示 softmax 操作:
4 实验
- 从现有的运动骨架数据集 HumanML3D [19] 中模拟生成运动时间序列
- 18个真实数据集进行测试,按照类别分为三个等级:
- 简单:Opportunity、UCI-HAR、MotionSense、w-HAR、Shoaib、HAR70+、RealWorld、TNDAHAR。
- 中等:PAMAP2、USC-HAD、Mhealth、Harth、UT-Complex、Wharf、WISDM、DSADS。
- 困难:UTD-MHAD、MMAct。
- 评估指标:准确率、Macro-F1、Top-2检索性能。
- 训练:单块A100上训练UniMTS。
4.1 零样本结果
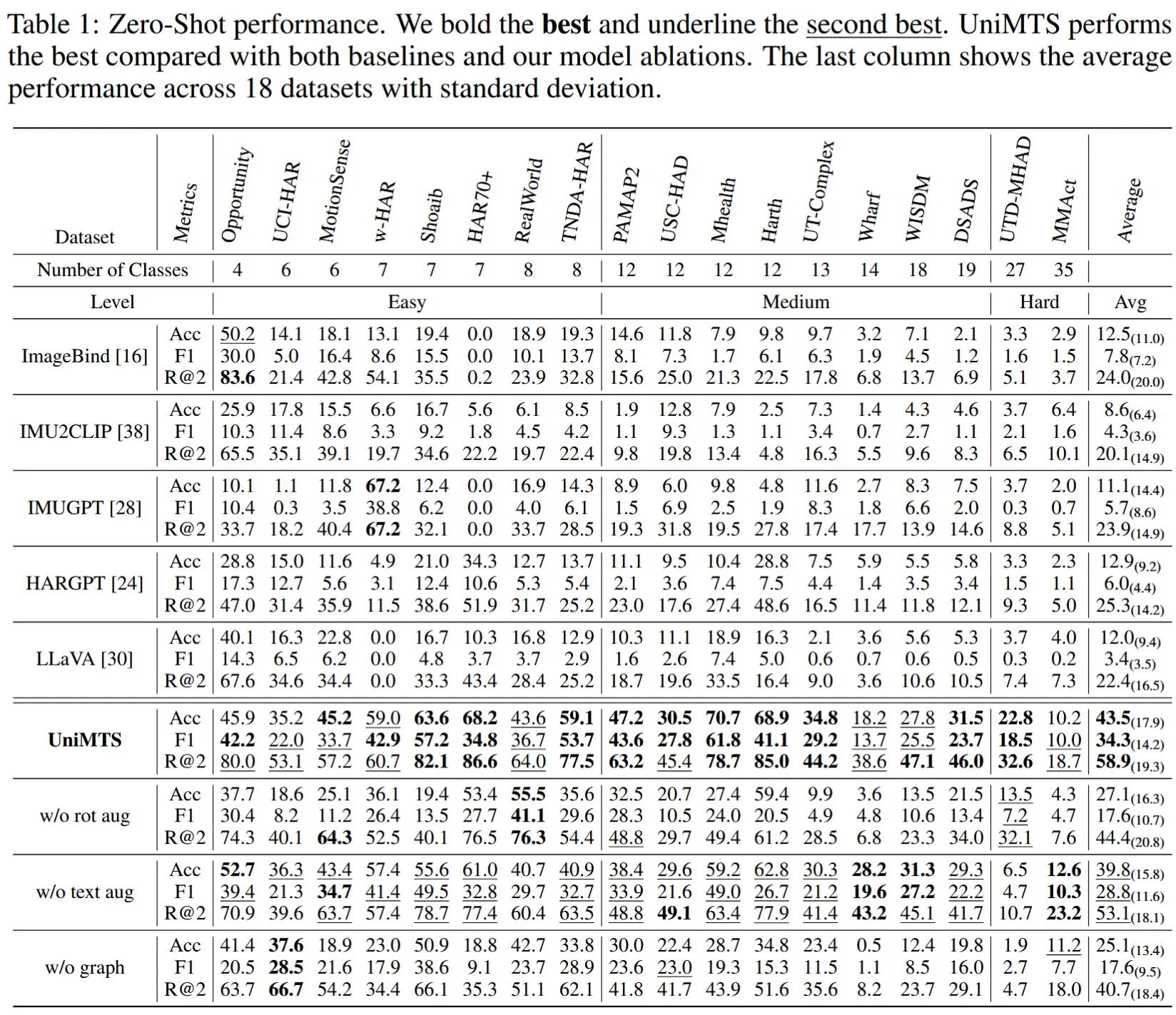
- 具有零样本能力的基线模型:ImageBind、IMU2CLIP、IMUGPT、HARGPT、LLaVA。
- 结果如表1所示
- ImageBind 和 IMU2CLIP 仅在单一位置(头戴设备)采集的数据上进行训练,限制了它们在其他设备位置上的泛化能力。
- IMUGPT 难以在不同活动类型之间实现跨数据集泛化,且需要针对每个下游任务单独训练。
- HARGPT 和 LLaVA 这些基于语言或视觉的大模型并非专门针对运动时间序列训练,因此更擅长处理简单、易于区分的活动。
4.2 少样本微调
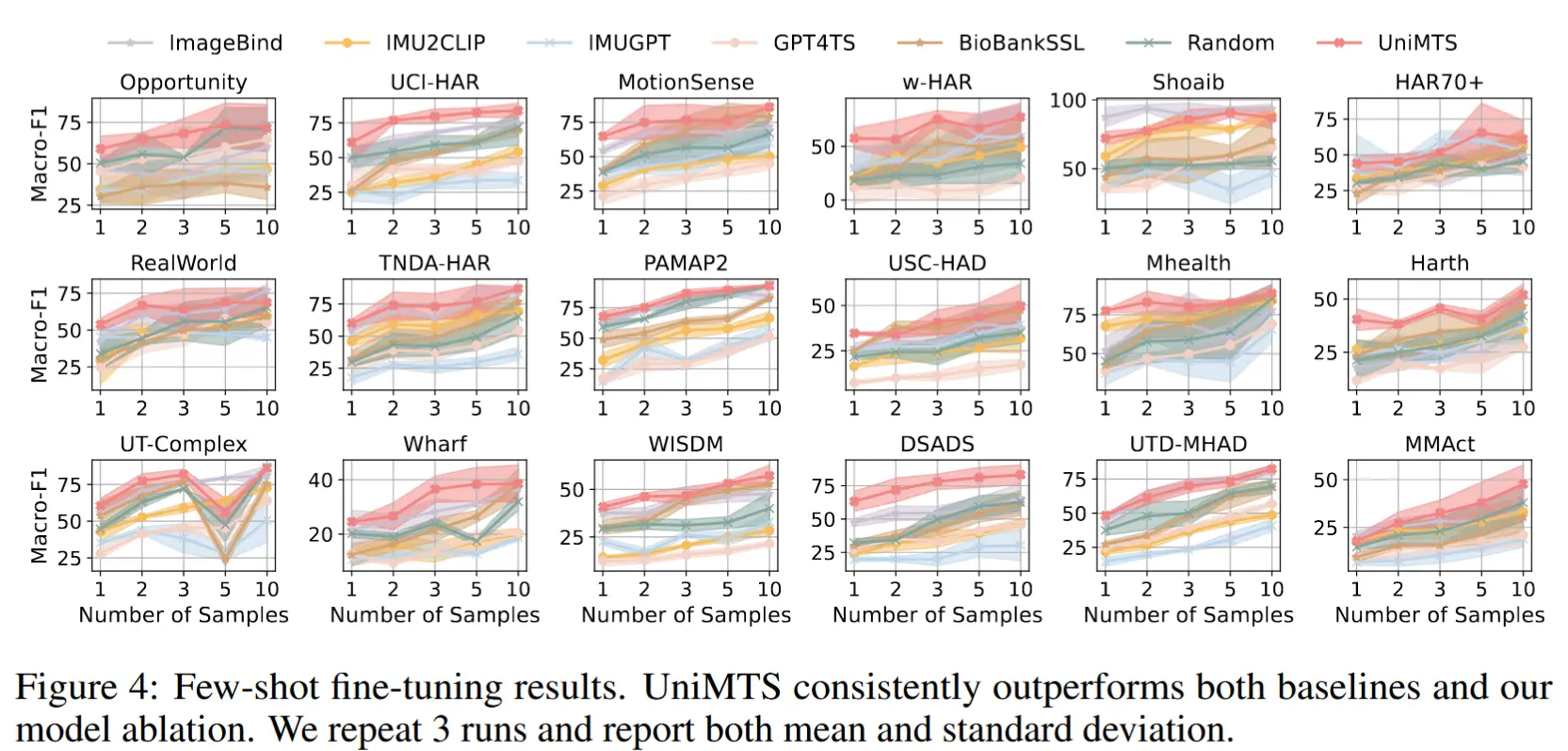
- 为每项活动分别提供 1、2、3、5 和 10 个样本。
- 基线:ImageBind、IMU2CLIP、IMUGPT、GPT4TS、BioBankSSL、与 UniMTS 拥有相同架构但随机初始化的模型。
- 结果如图4,UniMTS 在少样本微调设置下也表现出色,展示了其预训练的有效性。
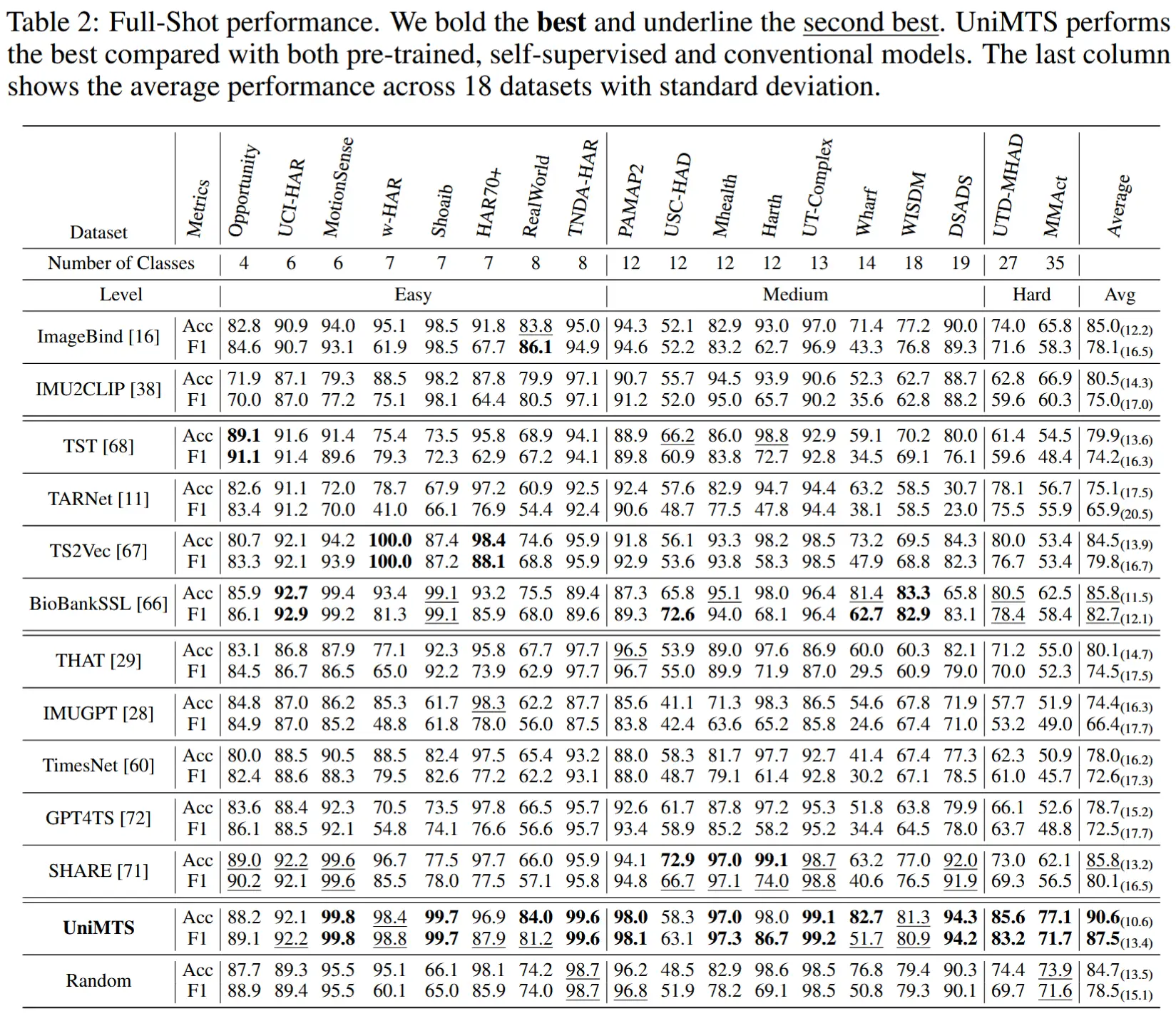
4.3 全样本
- 使用下游数据集中的全部训练样本对 UniMTS 和基线模型进行微调或训练。
- 使用了非常多的基线,结果如表2所示。