- 论文 - 《SUVAD: Semantic Understanding Based Video Anomaly Detection Using MLLM》
- 关键词 - ICASSP2025、无需训练的、多模态大模型、视觉-语言模型、视频异常检测
1 引言
-
现有工作不足
- 这些方法大多依赖特定场景,一旦场景发生变化,其性能会显著下降。
- 这些方法无法对检测到的异常提供解释说明。
- 这些方法在测试阶段无法在不重新训练模型的情况下灵活调整“正常”或“异常”事件的定义。
-
关键insight:现有基于视觉的方法主要通过拟合视觉模式来检测异常,而非对视频中的事件进行语义层面的理解。
-
本文方法 - SUVAD
- 基于语义理解(Semantic Understanding)的VAD
- 首先利用多模态大语言模型(MLLM)对训练视频进行语义理解,并根据标签生成对正常或异常事件的文本描述。
- 随后,SUVAD为测试视频的每一帧生成文本描述,并通过大语言模型(LLM)将其与正常和异常事件的描述进行比较,计算出相应的异常得分。根据该得分即可检测出异常帧,同时获得对异常事件的可解释性描述。
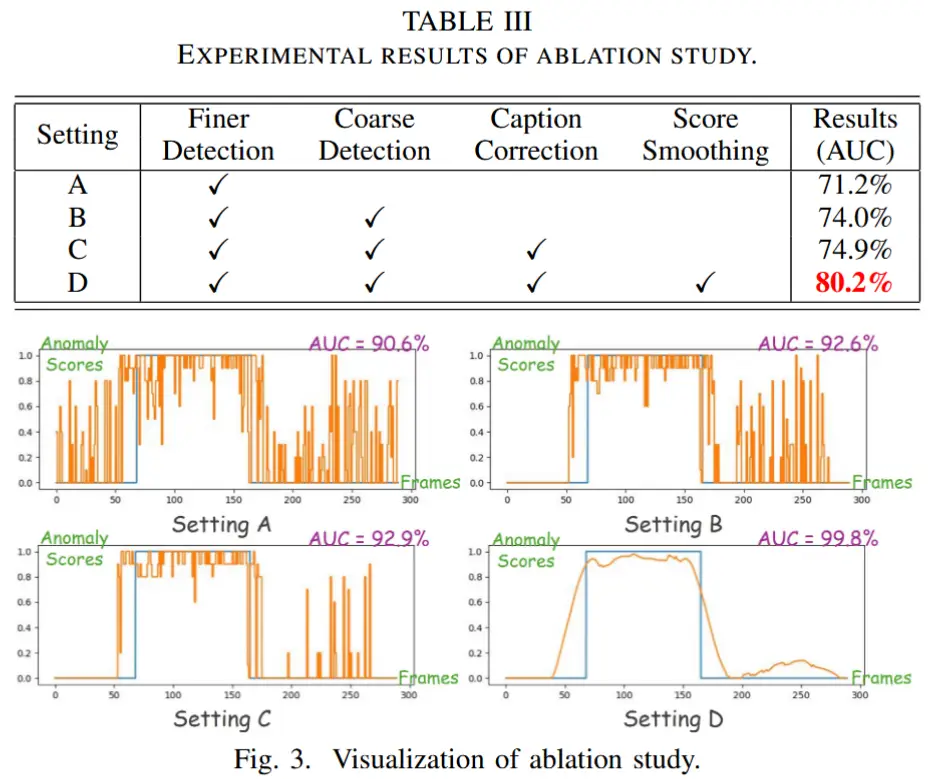
- 此外,作者设计了多种技术(如得分平滑和描述修正)以缓解大模型的幻觉问题。
- 最后,我们采用由粗到细的异常检测策略,有效抑制了幻觉问题,进一步提升了模型性能。
SUVAD 的最大优势:SUVAD可以方便地对检测到的异常提供解释说明,并通过文本输入灵活调整“正常”或“异常”事件的定义,而无需重新训练模型。
- 依赖视觉特征 vs. 依赖语义信息
2 方法
2.1 概述
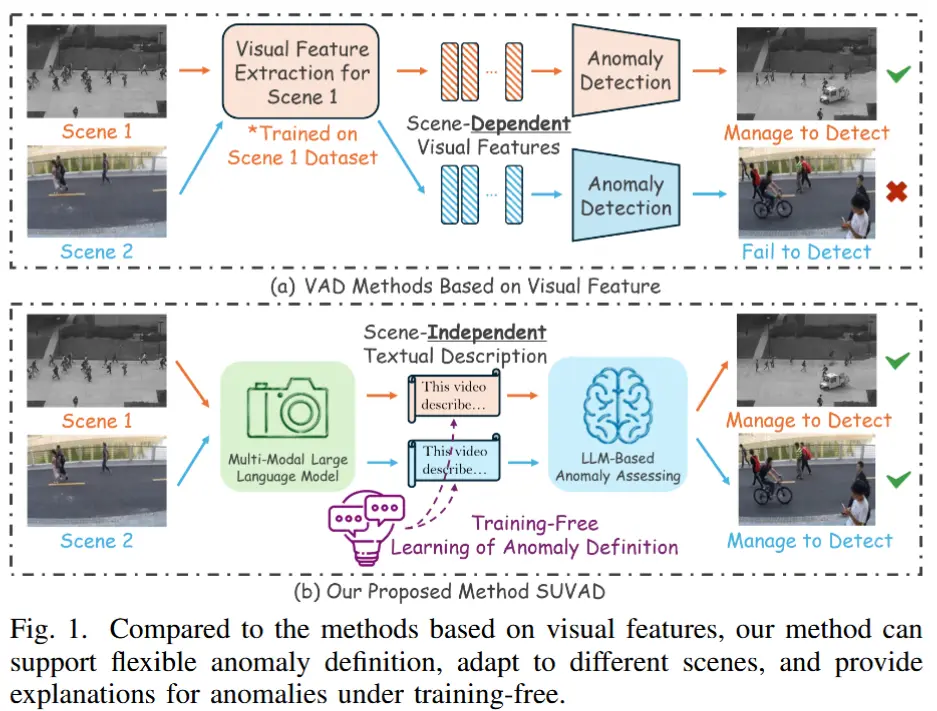
图2展示了本文提出的SUVAD方法的整体架构,通过三个阶段实现 VAD:
- 首先,SUVAD可接受任意形式的带标签文本、图像或视频输入,并生成正常事件 \mathbb{L}_n 和异常事件 \mathbb{L}_a 的列表。(如果是文本输入,则使用LLM进行总结;如果是图像或视频,则使用 MLLM 生成对应描述+ LLM 对描述归纳总结)
- 随后,SUVAD为测试视频片段生成文本描述,并通过将这些描述与事件列表进行比对,赋予视频级别的异常得分,并定位出高概率的异常片段。
- 最后,SUVAD进一步分析高概率异常片段中每一帧的描述,给出帧级别的异常得分。
为了缓解 MLLMs 的幻觉问题,作者引入了“描述修正”(Caption Correction)模块,用于在连续帧之间重新分配图像描述,并采用得分平滑技术以保证事件的连续性。
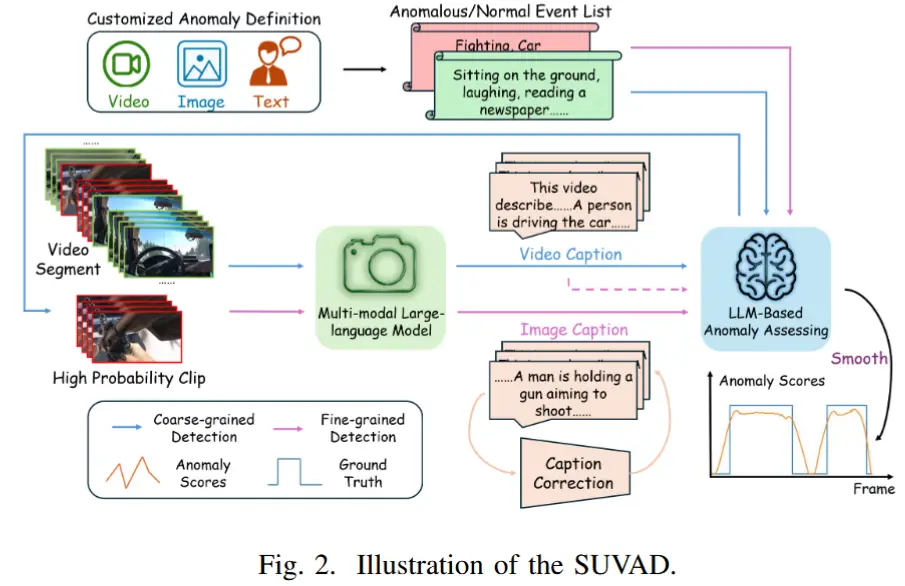
2.2 粗粒度异常检测
基本思路:SUVAD首先对测试视频进行粗粒度异常检测,以识别出最有可能包含异常的高概率视频片段。该策略在充分考虑视频帧之间关联信息的同时,也减少了后续的计算开销,并缓解了来自MLLMs的幻觉问题。
具体而言:
-
生成视频片段描述:对于一个测试视频 \mathbb{V}_{\text{test}},SUVAD首先按照固定间隔 d 将其划分为多个视频片段 \mathbb{C}_1, \mathbb{C}_2, \ldots, \mathbb{C}_n 。随后,SUVAD利用MLLMs(CogVLM2-video)为这些片段生成视频描述 Cap(\mathbb{C}_i) 。
-
生成片段级别异常得分和潜在异常事件列表:SUVAD使用 LLMs(Llama3) 将生成的视频描述与前一阶段产生的事件列表进行比较和分析。根据描述内容与事件列表之间的匹配程度,SUVAD为每个视频片段分配一个异常得分 s(\mathbb{C}_i) ,用于指示潜在的异常事件,并将这些事件总结为一个新的异常事件列表 \mathbb{L}'_a :
\mathbb{L}'_a = \bigcup_{i=1}^{n} \text{LLM}(Cap(\mathbb{C}_i), \mathbb{L}_a, \mathbb{L}_n). \tag{1}这里 s(\mathbb{C}_i) 采用双向评分机制:若仅提供正常事件列表,则检测描述中是否包含之外的内容;若仅提供异常列表,则评估描述与的匹配程度。
-
定位高概率异常片段:通过两种方法来定位,第一种是使用阈值 \tau ,SUVAD将得分超过该阈值的片段标记为高概率异常片段 \mathbb{H}_1 ;第二种利用MLLMs的时间定位能力,结合前述列表来发现可能被忽略但实际含有异常事件的片段 \mathbb{H}_2 。最终,取两者的交集 \mathbb{H} = \mathbb{H}_1 \cup \mathbb{H}_2 作为结果,并将其传递至下一处理阶段。
2.3 细粒度异常检测
基本思路:在完成粗粒度异常检测后,SUVAD对所识别出的高概率异常片段 \mathbb{H} 中的每一帧进行详细分析,并融合视频级和帧级的异常得分,以生成整体的异常评分。
-
描述修正:SUVAD为高概率异常片段中的每一帧 F_j 生成图像描述 Cap(F_j) 。为了进一步缓解幻觉问题的影响,SUVAD引入 “描述修正”模块 ,对生成的图像描述进行优化。具体而言,SUVAD利用一个 VLM,对若干相邻帧及其对应的图像描述进行编码,然后利用余弦相似度重新分配描述:
Cap(F_j)^* = Cap(F_{j+l}), \\ l = \arg\max_{k=j-w}^{j+w} < \Phi_I(F_j) \cdot \Phi_T(Cap(F_k)) >, \tag{3} -
生成帧级别异常得分:将修正后的图像描述与事件列表进行比对,得到帧级异常得分 s(F_j) 。再进行帧级与片段级的融合:
s(F_j)^* = \alpha \cdot s(\mathbb{C}_i) + \beta \cdot s(F_j),\quad F_j \in \mathbb{C}_i, \tag{4}其中 \alpha 和 \beta 为常数权重系数。
-
分数平滑:考虑到事件具有连续性,并为进一步避免MLLM中随机性对异常检测结果的影响,采用Savitzky-Golay滤波器对得分进行平滑处理:
s(F_j)^*_{smooth} = \overline{s(F_j)^*} = \frac{1}{Q} \sum_{p=-v}^{+v} s(F_{j+p})^* q_p, \tag{5}其中 q_p / Q 为平滑系数,通过最小二乘法进行多项式拟合确定。
3 实验
3.1 实验设定
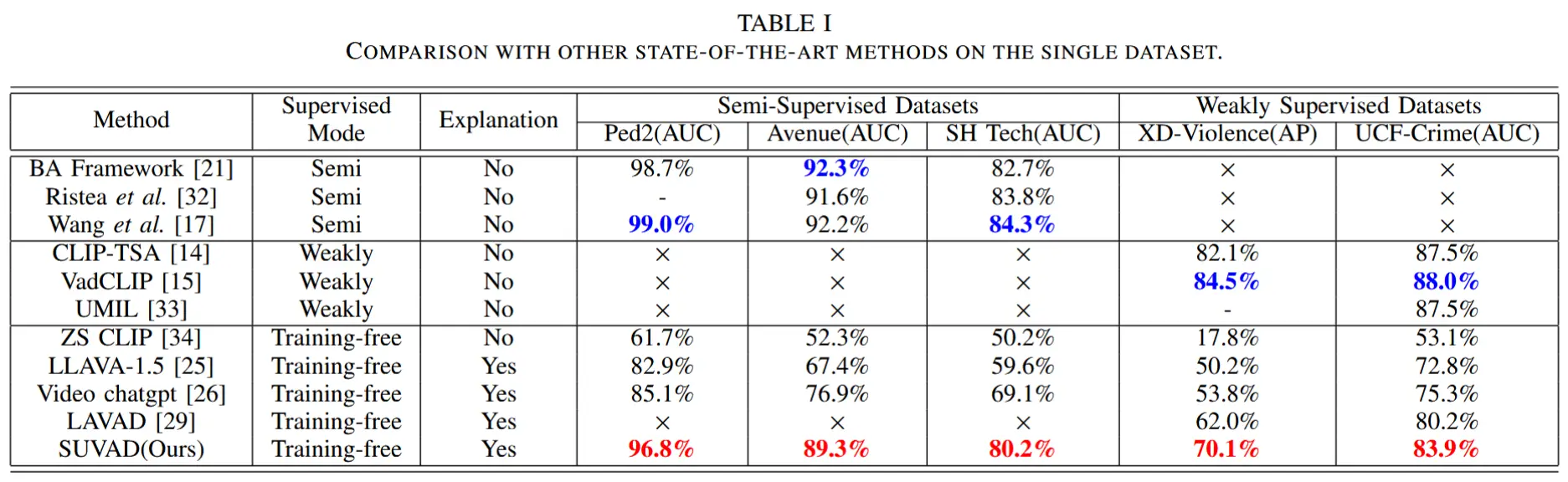
- 数据集和评估指标:Ped2(AUC) Avenue(AUC) SH Tech(AUC) XD-Violence(AP) UCF-Crime(AUC)
- 实现细节
- 图像描述:使用CogVLM2
- 视频描述:使用CogVLM2-video
- 文本分析和评分:使用llama3
- 超参数见论文。
3.2 实验结果
- 性能比较
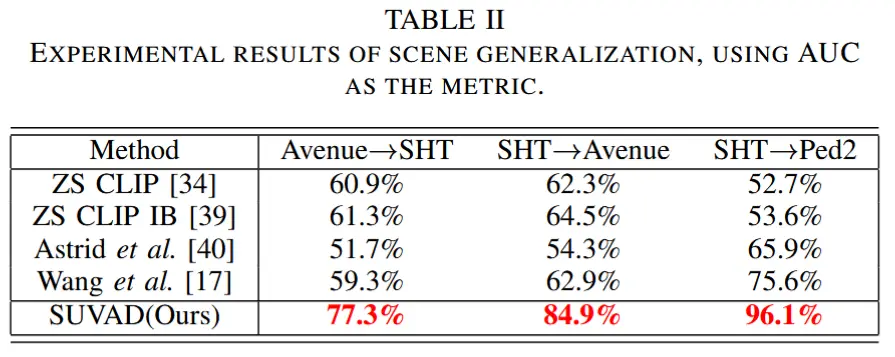
- 跨数据集/场景泛化
- 消融实验
- 对四个组件进行消融:粗粒度检测、细粒度检测、描述修正模块、Savitzky-Golay滤波器