- 论文 - 《HiProbe-VAD: Video Anomaly Detection via Hidden States Probing in Tuning-Free Multimodal LLMs》
- 关键词 - ACM MM '25、多模态大模型MLLM、中间隐藏状态、免微调
1 引言
-
现有工作的不足
- 先前的研究已尝试通过微调或提示工程将这些模型适配到特定的异常检测任务中。
- 然而,这些方法通常存在两个主要缺陷:
- 需要在VAD数据集上进行任务特定的微调,计算成本高昂,且通常依赖大量标注数据;
- 过度依赖从视觉输入生成的文本表征,可能导致在推理过程中丢失关键的视觉细节,从而造成对视频理解的不完整或偏差。
-
动机
- 本文发现,MLLMs的中间隐藏状态包含信息丰富的表征,相较于输出层,对异常具有更高的敏感性和线性可分性。(“中间层信息丰富现象”)
-
本文模型 - HiProbe-VAD
- HiProbe-VAD采用动态层显著性探测(Dynamic Layer Saliency Probing, DLSP)模块,在MLLM单次前向推理过程中,从中间层提取隐藏状态,并动态选择最具判别力的层次。
- 随后,集成一个基于逻辑回归的轻量级异常评分器和时间定位模块,以实现高效检测与精确定位。
- 最后,为了对检测到的异常提供可解释的洞察,将异常帧与正常帧输入到自回归过程中,生成对检测事件的详细文本描述。
2 相关工作
近年来对 LLMs 中间层的研究 [15, 17, 18, 33] 表明,与最终输出层相比,中间层通常包含更丰富、更具信息量的表征 [34, 42, 60]。研究表明,中间层在多种任务中表现优于最终层,这可能得益于其通过压缩和特征蒸馏等机制,在信息保留与噪声抑制之间实现了更好的平衡 [6, 39, 40]。此外,中间层在复杂推理任务中扮演关键角色:专为推理任务训练的模型往往在这些层次保留更多上下文信息,从而增强多步推理能力 [34, 35, 70]。受这些在通用LLMs中发现的规律启发,作者提出假设:预训练 MLLMs 的中间隐藏状态同样蕴含更丰富、更具判别性的表征。这一假设促使本文探索一种全新的免调优框架,通过有效探测MLLMs的中间层来实现视频异常检测。
3 面向视频异常检测的信息丰富现象
3.1 探索MLLMs中的中间层表征
为验证该假设在MLLMs中的有效性,作者对预训练 MLLMs 中不同层提取的隐藏状态表征进行了系统性分析。
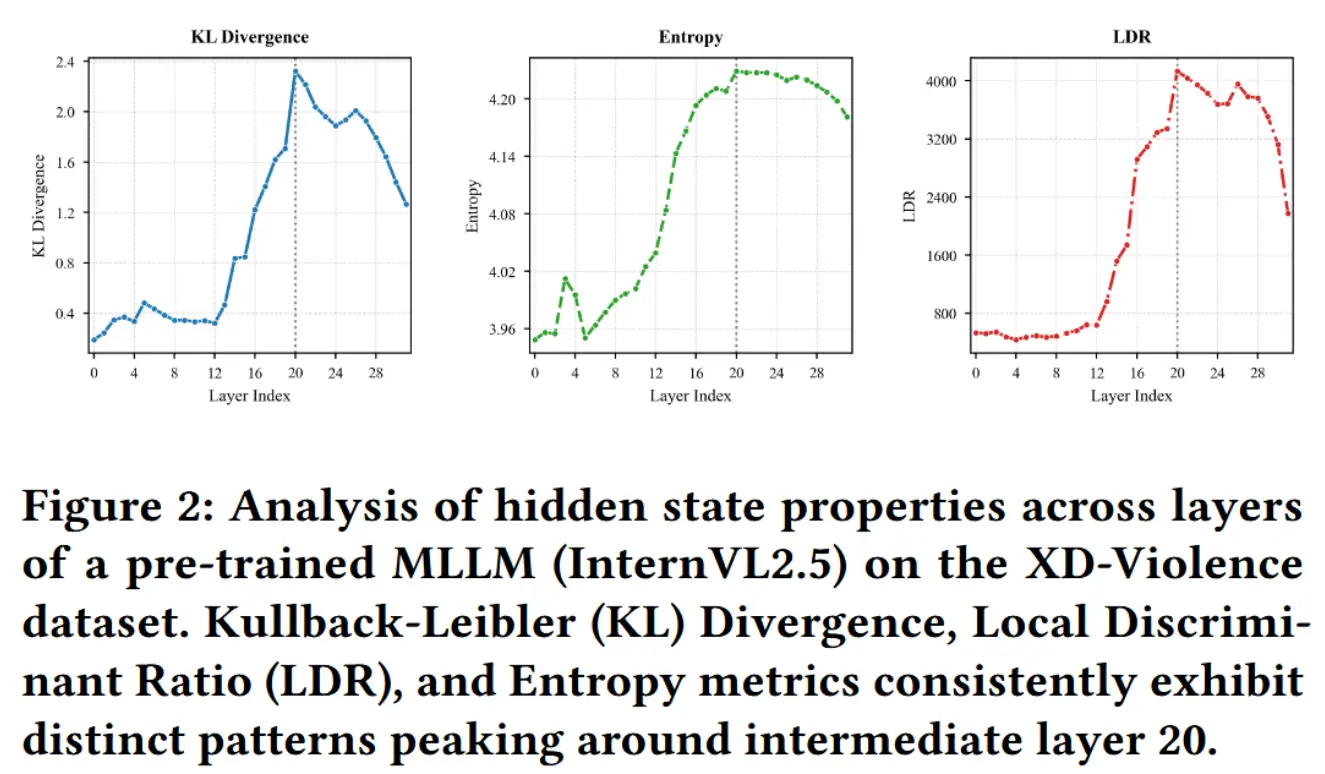
对于数据集 XD-Violence 和 UCF-Crime 的每一输入视频 V ,使用预训练的MLLM(InternVL2.5)进行一次前向推理。在此过程中,从每一层 l 中提取对应的隐藏状态 h_l 。随后,通过统计与几何分析方法,评估这些表征在区分正常与异常视频方面的有效性,重点关注特征质量的不同方面。
3.1.1 面向VAD的统计量化
为了从统计角度量化各层所捕获的信息,作者专注于量化提取出的隐藏状态 \mathbf{h}_l 的关键属性。采用了以下指标,旨在捕捉异常检测中特征质量的不同方面:
-
基于KL散度的异常敏感性: KL 散度用于衡量正常与异常特征之间的统计可区分性。对于第 l 层的每个特征维度 d ,我们假设正常样本的隐藏状态 (\mathbf{h}_l^N) 和异常样本的隐藏状态 (\mathbf{h}_l^A) 近似服从高斯分布,即分别服从 \mathcal{N}(\mu_{l,d}^N, (\sigma_{l,d}^N)^2) 和 \mathcal{N}(\mu_{l,d}^A, (\sigma_{l,d}^A)^2) 。这两个高斯分布之间在第 d 维的KL散度定义为:
D_{\text{KL}}^{(d)}(l) = \frac{1}{2} \left[ \log \left( \frac{(\sigma_{l,d}^A)^2}{(\sigma_{l,d}^N)^2} \right) + \frac{(\sigma_{l,d}^N)^2 + (\mu_{l,d}^N - \mu_{l,d}^A)^2}{(\sigma_{l,d}^A)^2} - 1 \right]. \tag{1}该层的总体异常敏感性 D_{\text{KL}}(l) 是所有特征维度 D 上KL散度的平均值:
D_{\text{KL}}(l) = \frac{1}{D} \sum_{d=1}^{D} D_{\text{KL}}^{(d)}(l). \tag{2}更高的 D_{\text{KL}}(l) 表示在第 l 层上,正常与异常特征之间的分布差异更大。
-
基于局部判别比(LDR)的类别可分性:局部判别比(Local Discriminant Ratio, LDR)用于衡量特征线性分离不同类别(正常与异常)的能力。对于第 l 层的每个特征维度 d ,我们计算LDR为正常特征均值 (\mu_{l,d}^N) 与异常特征均值 (\mu_{l,d}^A) 之差的平方,除以两者方差之和 ((\sigma_{l,d}^N)^2 + (\sigma_{l,d}^A)^2) ,并加入一个较小的常数 \varepsilon 以保证数值稳定性:
\text{LDR}^{(d)}(l) = \frac{(\mu_{l,d}^N - \mu_{l,d}^A)^2}{(\sigma_{l,d}^N)^2 + (\sigma_{l,d}^A)^2 + \varepsilon}. \tag{3}第 l 层的整体类别可分性是所有 D 个特征维度上的LDR均值:
\text{LDR}(l) = \frac{1}{D} \sum_{d=1}^{D} \text{LDR}^{(d)}(l). \tag{4}更高的 \text{LDR}(l) 表明正常与异常类别之间具有更强的线性可分性,意味着在该层中提取的特征更具判别能力。
-
基于特征熵的信息集中度:为了评估特征表示中的信息集中程度,对于第 l 层的每个特征维度 d ,我们将所有样本的特征值范围划分为固定数量 B 个等间距的区间(bins),并据此估计该维度的概率分布。第 d 维的熵计算如下:
H^{(d)}(l) = -\sum_{j=1}^{B} p(\mathbf{h}_l[d] \in \text{bin}_j) \log_2 p(\mathbf{h}_l[d] \in \text{bin}_j), \tag{5}其中 p(\mathbf{h}_l[d] \in \text{bin}_j) 表示特征值落入第 j 个区间的概率, \log_2 表示以 2 为底的对数,因为熵通常以比特(bits)为单位进行度量。第 l 层的整体熵是所有 D 个特征维度上熵的平均值:
H(l) = \frac{1}{D} \sum_{d=1}^{D} H^{(d)}(l). \tag{6}更高的熵值表明特征值在各个区间中分布更均匀,能够捕捉更丰富多样的信息。
图 2 展示了这些指标的趋势。可以看到,KL 散度、LDR 和熵在 MLLM 的中间层均呈现上升趋势,在约第 20 层达到峰值,随后在更深的层中略有下降。这表明正常样本与异常样本之间的统计可区分性以及所捕获信息的丰富性在中间层达到最大。后续在更深层次中的下降说明 MLLM 开始优先处理与下游文本生成任务相关的信息,从而牺牲了细粒度的异常相关特征和整体用于异常检测的信息丰富性。
3.1.2 隐藏状态可分性的验证
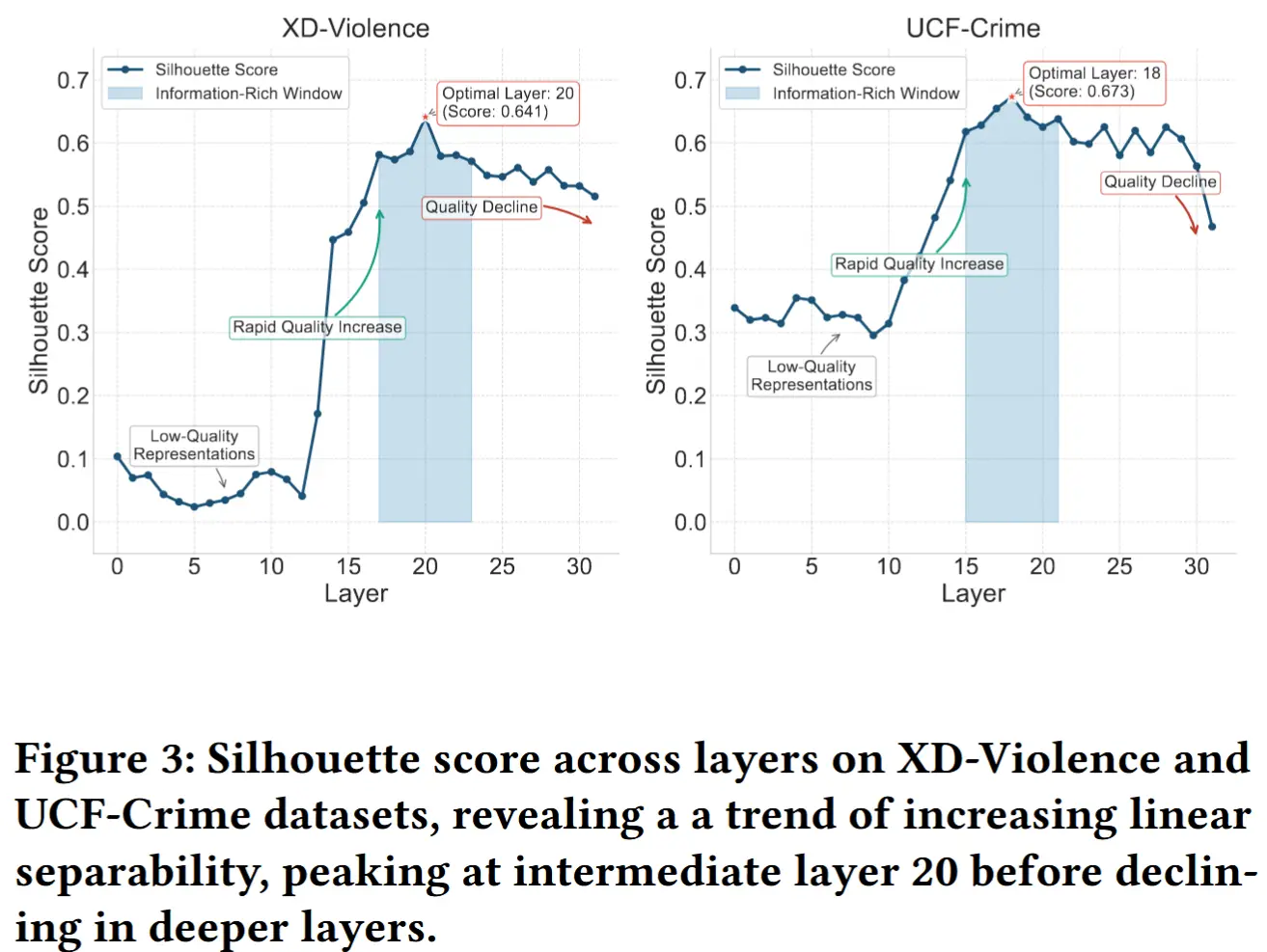
尽管上述统计指标为各层的判别能力提供了定量证据,作者还从几何角度对隐藏状态 \mathbf{h}_l 的线性可分性进行了分析,以进一步验证这些发现。这些实验旨在更直观地展示正常样本与异常样本在不同网络层中的分布情况。作者采用轮廓系数(Silhouette score) 来评估线性可分性。该指标用于衡量每个样本与其所属类别内其他样本的聚类紧密程度,相较于其他类别,轮廓系数越高,表示聚类结构越清晰,类别之间的线性可分性越好。
图3展示了轮廓系数均在第20层左右达到峰值。这一结果有力地支持了前面的假设,并与之前的统计分析结果一致,表明MLLM的中间层在区分正常与异常视频片段方面表现出优于浅层和深层的线性可分性。
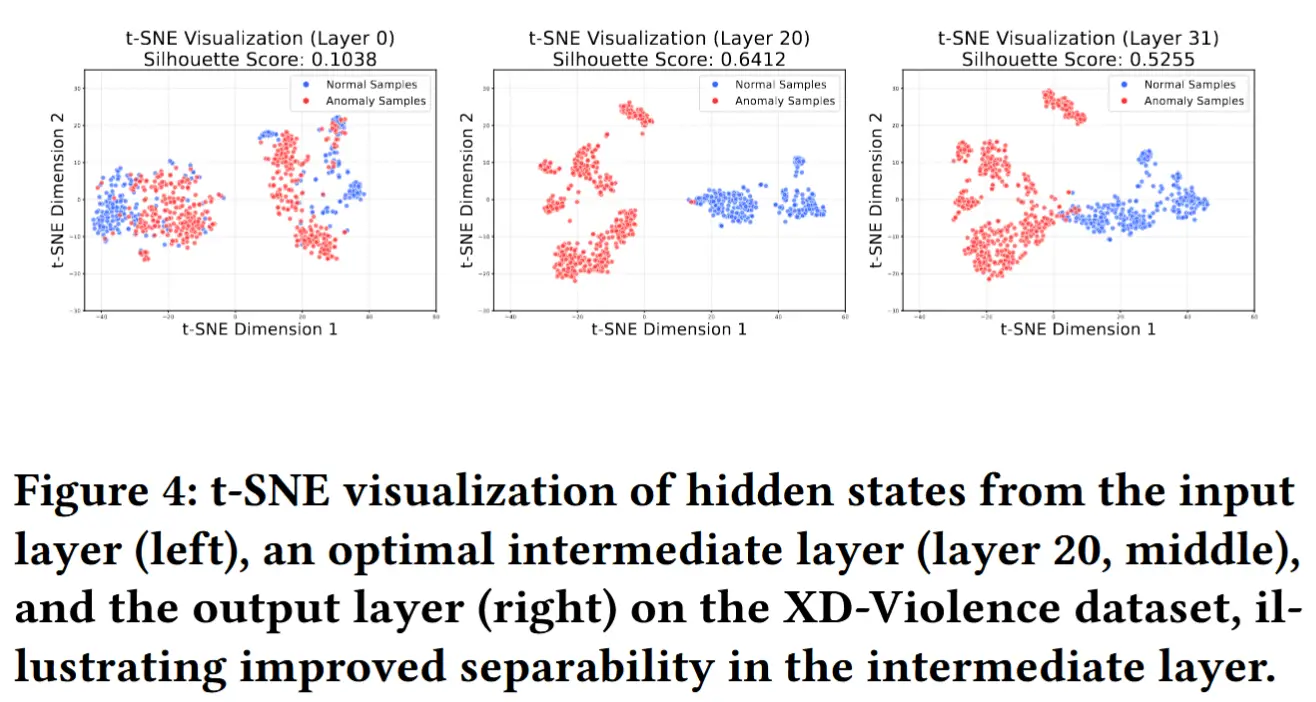
作者还采用t分布随机邻域嵌入(t-SNE)进行降维和可视化。图4展示了在XD-Violence数据集上,从输入层(第0层)、中间层(第20层)和最终输出层(第31层)提取的隐藏状态的t-SNE嵌入结果。可视化结果清晰地表明,从输入层到中间层,正常与异常样本的聚类分离程度逐步提升。
3.2 发现:MLLMs中的中间层信息丰富现象
基于上述实验与分析,确定了一个重要发现:中间层信息丰富现象。该发现揭示了预训练 MLLMs 内部所蕴含知识的强大能力与可迁移性,表明即使未经任务特定的微调,这些模型也具备执行复杂任务(如异常检测)的内在潜力。
作者将该现象归因于:预训练MLLMs中固有的强大跨模态表征学习能力。中间层在两个关键方面达到了最优平衡:一方面捕捉对检测细微异常至关重要的细粒度视觉线索,另一方面利用在预训练过程中获得的高层语义理解。
这一观察直接启发作者提出一种“探测机制”,即主动利用这些信息丰富的中间隐藏状态,从而在无需进行计算密集且数据依赖性强的微调的前提下实现异常检测。
4 HiProbe-VAD:基于隐藏状态探测的免调优视频异常检测
基于上述发现,作者提出HiProbe-VAD——一种高效且无需微调的视频异常检测(VAD)框架,充分利用预训练的 MLLMs。图5展示了HiProbe-VAD的整体架构,由三个核心组件构成:
- 动态层显著性探测模块(Dynamic Layer Saliency Probing, DLSP),用于提取隐藏状态并确定最适合VAD任务的中间层;
- 轻量级异常评分器,通过在选定层的特征上进行少样本探测(few-shot probing)进行训练,对输入视频帧进行异常打分;
- 时间异常定位模块,用于精确定位异常发生的具体帧。
最后,系统将汇总检测到的异常帧,并生成对所发现异常事件的全面文本描述,实现可解释的异常检测。
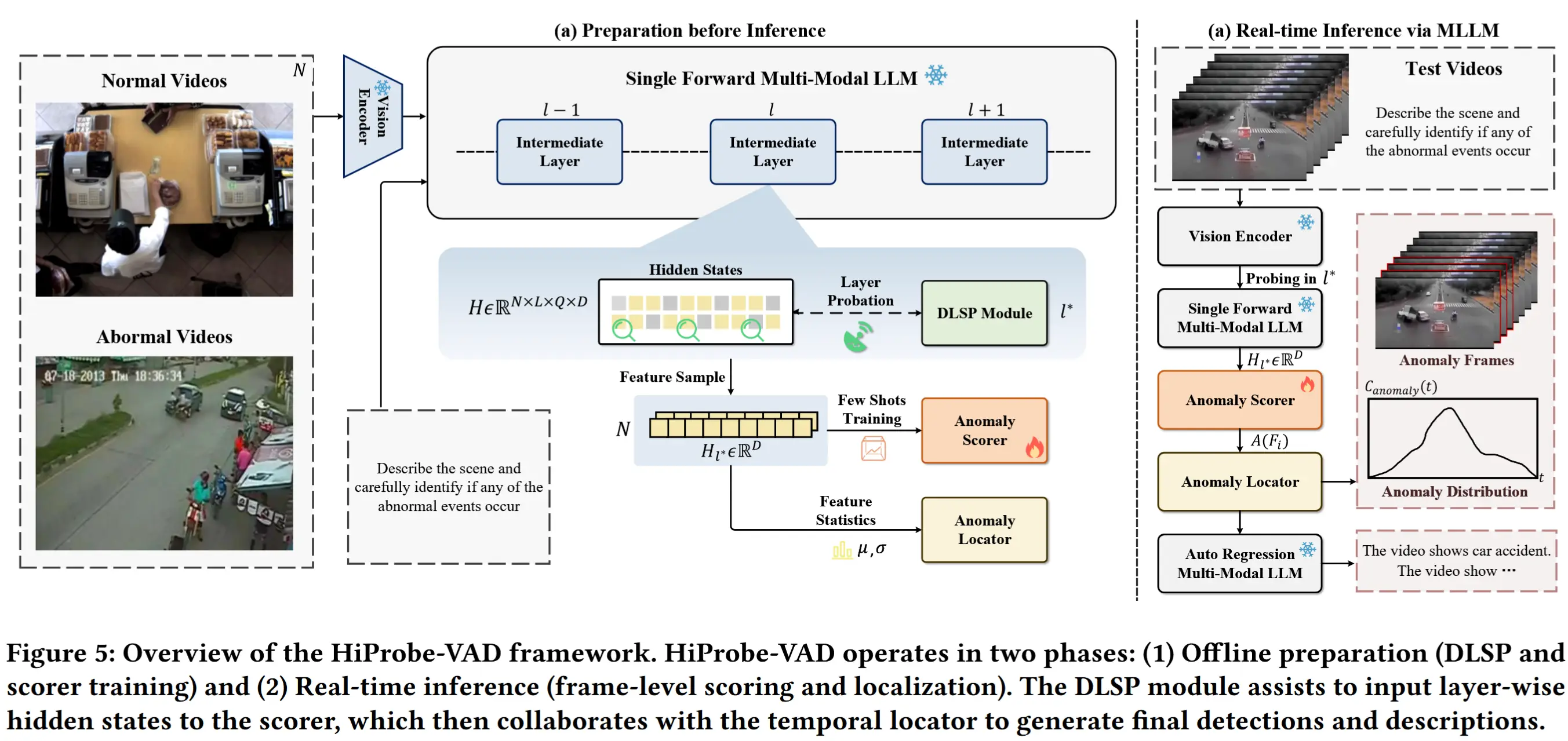
4.1 基于MLLM隐藏状态的预处理
在进行实时推理之前,需要从 MLLM 中识别出最优的中间层,并训练一个轻量级的异常评分器用于 VAD 。该阶段在视频级别上运行,利用从训练集的一个小子集(少量样本)中提取的隐藏状态,以获取全面的信息,从而实现有效的层选择和评分器训练。
4.1.1 动态层显著性探测
动态层显著性探测(Dynamic Layer Saliency Probing, DLSP)模块的目标是识别出能够提供最具判别性的特征的中间层 l^* 。该过程在UCF-Crime和XD-Violence数据集训练集的极小子集(约1%)上执行。对于该子集中每个视频 v ,在MLLM生成第一个token时,从每一层 l 提取隐藏状态 \mathbf{H}^{(v,l)} ,然后计算这些特征在正常与异常视频样本之间的异常敏感性(KL散度)、类别可分性(LDR)以及信息集中度(熵)。
为了有效融合这些指标,对所有层的KL散度、LDR和熵值分别进行Z-score标准化。对于任意指标 M \in \{D_{\text{KL}}(l), \text{LDR}(l), H(l)\} ,其归一化得分 \text{Norm}(M(l)) 计算如下:
其中 \mu_M 和 \sigma_M 分别表示指标 M 在所有层 \{1, \ldots, L\} 上的均值和标准差。随后,每层的显著性得分 S(l) 被定义为归一化后的KL散度、LDR和熵之和:
最优层 l^* 通过最大化该显著性得分选出:
这一基于视频级别的分析确保所选层在不同视频场景下具有鲁棒性和有效性。确定的最优层索引 l^* 将被用于后续训练异常评分器,并在实际推理过程中作为MLLM的输出层使用。
4.1.2 轻量级异常评分器训练
异常评分器采用一个轻量级的逻辑回归分类器,在DLSP模块识别出的最优层 l^* 的隐藏状态上离线训练。设 \mathbf{h}_{l^*}^{(i)} 表示第 i 个样本的重采样后隐藏状态。预测概率为:
其中 \sigma(\cdot) 为Sigmoid函数, \mathbf{w} 和 b 分别为待学习的权重向量和偏置项。该分类器通过最小化二元交叉熵损失来区分正常( y_i = 0 )和异常( y_i = 1 )样本:
使用LBFGS优化器训练1000个epoch。
4.2 HiProbe-VAD中的推理:帧级处理与解释
HiProbe-VAD在 MLLM 中的实时推理阶段专注于处理未见过的视频,以检测并定位异常帧,最终为视频生成全面的异常描述。
4.2.1 帧级异常评分
对于输入视频,将其分割为一系列帧序列,并从每个片段中均匀采样关键帧。对于从各片段采样的关键帧 F_i ,使用MLLM进行单次前向传播,从最优层 l^* 提取隐藏状态 \mathbf{h}_{l^*}(F_i) 。提取的特征随后输入轻量级异常评分器,以获得每个片段的异常概率 A(F_i) :
其中 \sigma 为Sigmoid函数, \mathbf{w} 和 b 是逻辑回归分类器学习到的权重向量和偏置项。该帧级评分过程为输入视频生成一个时间序列的异常概率,其中每一帧都关联一个分数,表示其为异常的概率。
4.2.2 时间异常定位
为了生成全面的异常描述,对帧级异常分数进行时间上的聚合。首先,对异常概率序列应用高斯核平滑,以降低噪声并获得更平滑的异常概率曲线 C(t) 。接着,通过设定阈值 T 来识别潜在的异常片段。该阈值根据DLSP模块在少量训练集上获得的异常分数均值 \mu_A 和标准差 \sigma_A 自适应确定:
连续帧若其平滑后的异常分数高于该阈值,则被归为异常片段;反之,低于阈值的帧则归为正常片段。
4.2.3 基于MLLMs的可解释性异常检测
为提供对检测到的异常的可解释性洞察,我们将异常片段和正常片段分别输入预训练的MLLMs进行自回归处理。该过程将视频片段转化为精确的文字描述,从而增强HiProbe-VAD框架的可解释性,帮助用户更深入地理解视频中检测到的异常行为。
5 实验
5.1 实验设置
- 数据集:UCF-Crime、XD-Violence
- 评估指标:帧级ROC-AUC 、 平均精度AP
- 实现细节
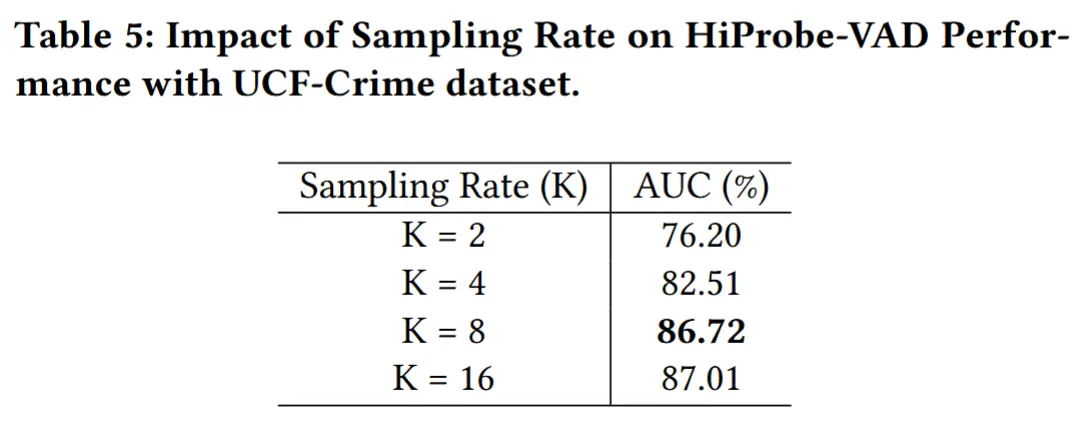
- 将每个 24 帧的视频片段均匀采样 K = 8 个关键帧。
- 以 InternVL2.5、Qwen2.5-VL、LLaVA-OneVision 和 Holmes-VAU 作为主干 MLLM
- 时间定位中使用的高斯核宽度 σ 设为 0.4,阈值参数 κ 设为 0.2。
- NVIDIA 4090 GPU
5.2 实验结果
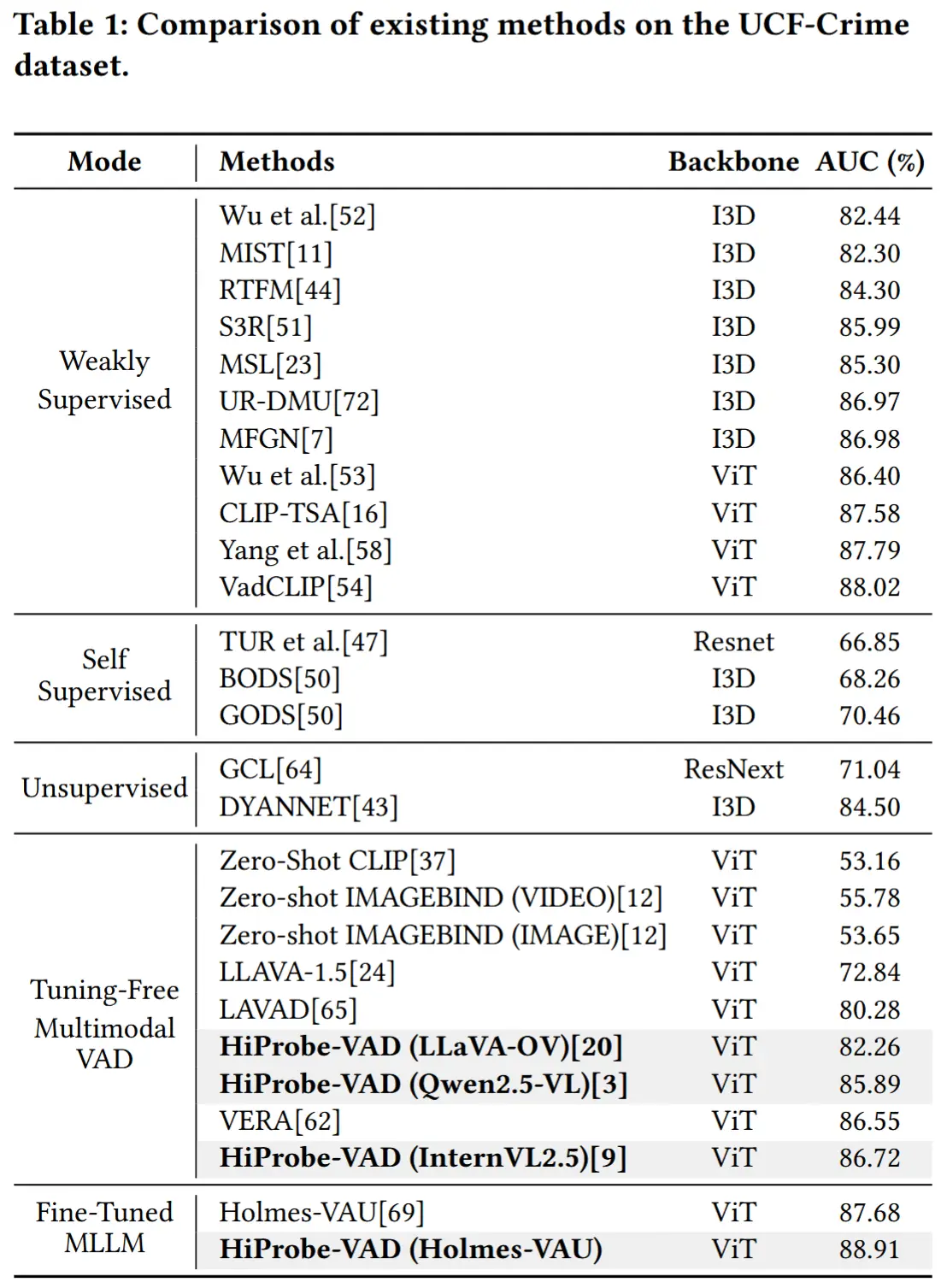
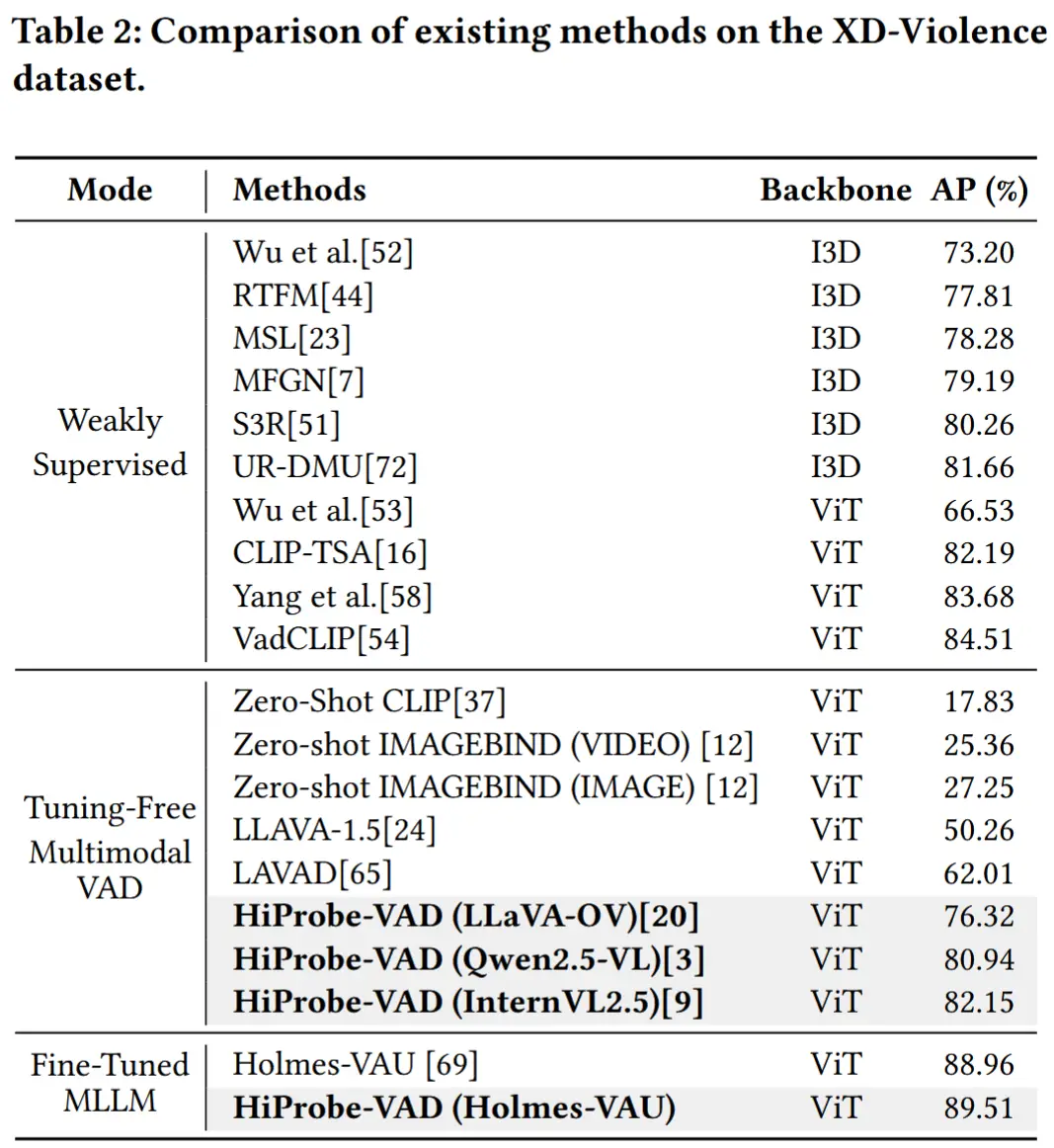
- 与SOTA对比
- 测试了不同主干模型,验证跨模型泛化能力
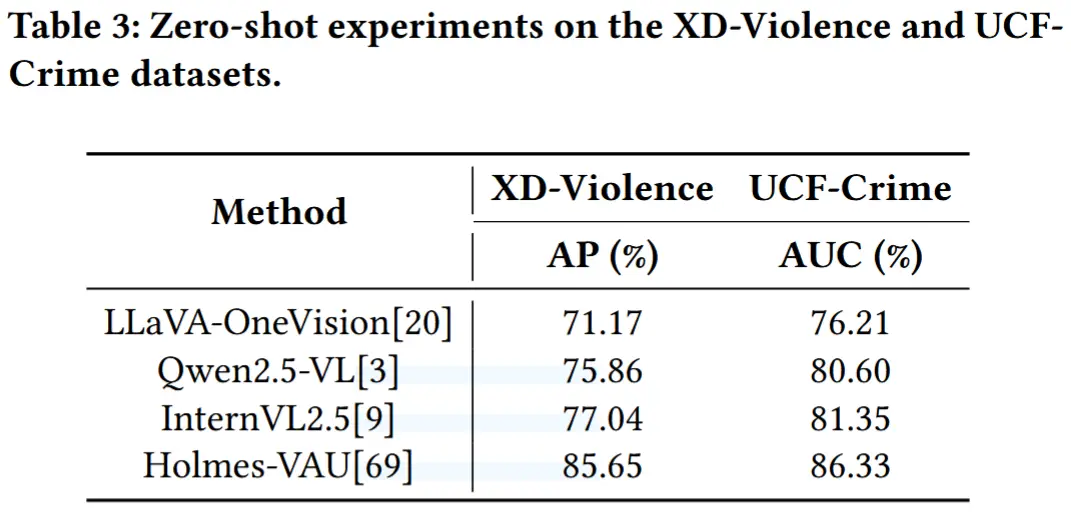
- 零样本泛化能力
- 仅在UCF-Crime上训练,然后在XD-Violence上测试,反之亦然。
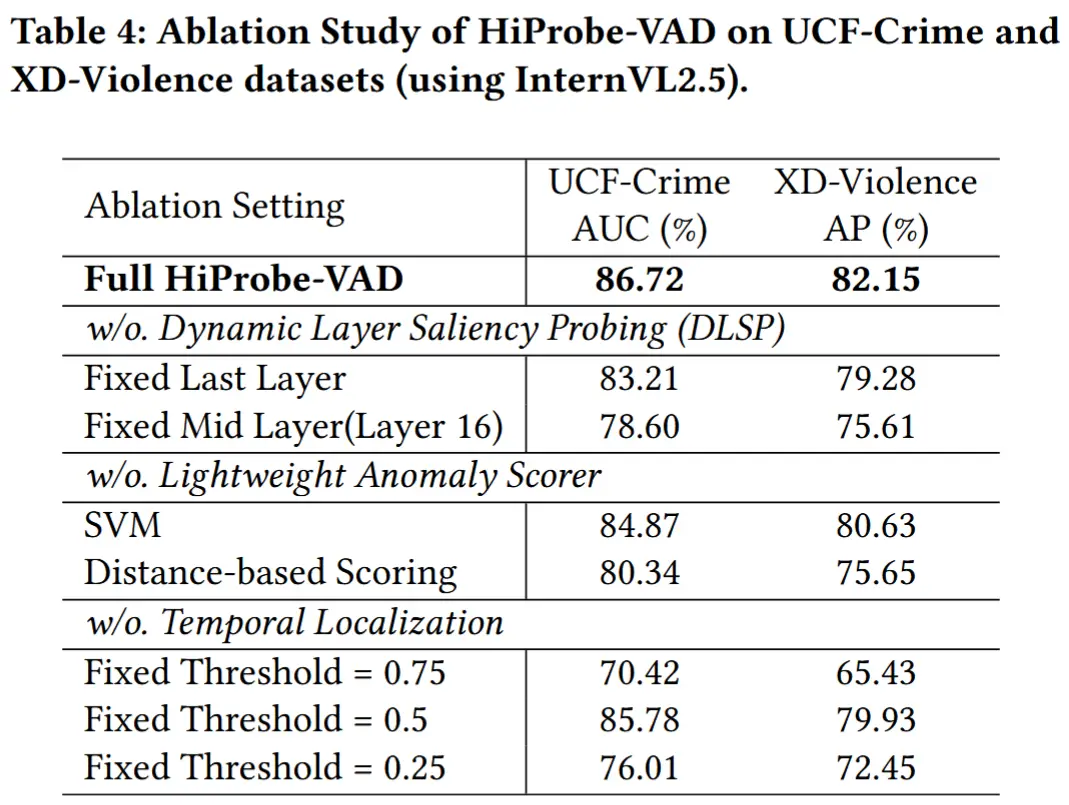
- 消融实验
- 分别消融 DLSP、轻量级异常评分器、时间定位模块的贡献
- 关键帧采样率的影响