- 论文 - 《The Evolution of Video Anomaly Detection: A Unified Framework from DNN to MLLM》
- 关键词 - 综述、视频异常检测、多模态大模型
这是一篇综述文章,深入介绍了MLLM和LLM技术在VAD领域的应用,并且按照多种VAD任务展开,每个任务都按照统一分析框架(范式、视频输入、模型架构、模型优化、性能比较)进行介绍。这是首篇专注于基于MLLM/LLM的VAD方法的全面综述。
1 引言
-
VAD 介绍
- 视频异常检测(VAD)专注于在视频数据中识别并定位非常规行为或事件。
- VAD将异常分解为三个维度的偏离:空间维度(例如未经授权的物体闯入)、时间维度(例如逆行、突然停止等异常运动)以及语义维度(例如持械斗殴等高风险行为)。
-
VAD 方法历史
- 最初,主要依赖基于特征工程的方法,针对特定数据集手工设计具有区分性的特征。
- 随后,基于领域知识采用主成分分析(PCA)或线性判别分析(LDA)等降维技术处理这些高维特征,并构建分类器以区分正常与异常样本。
- 接着,VAD领域涌现出大量基于深度学习的创新方法,最为常见的就是 DNN。
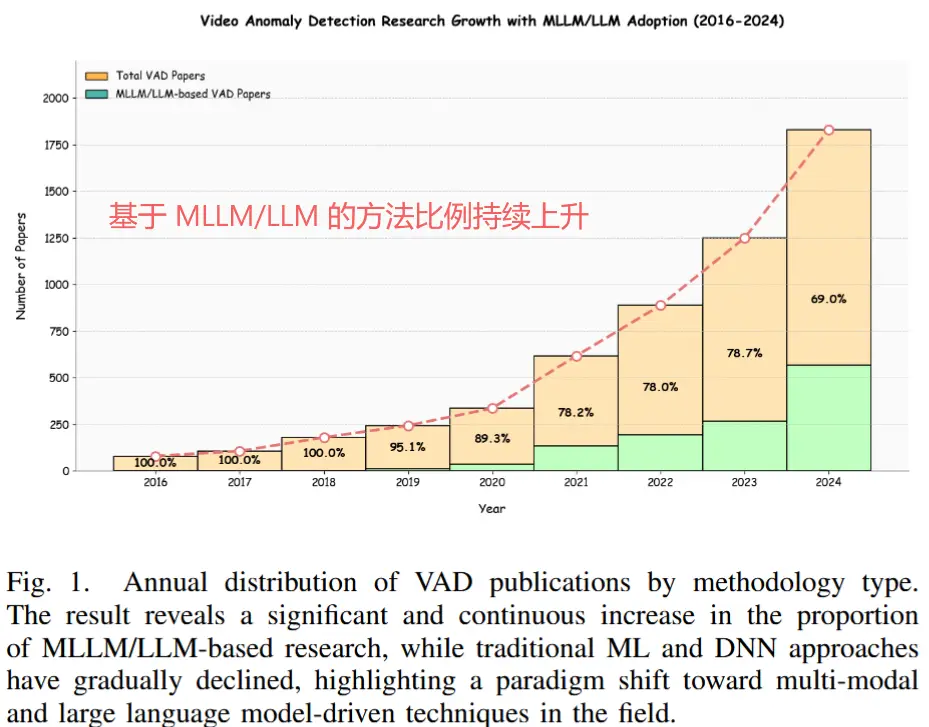
- 近年来,多模态大模型(MLLMs)和大语言模型(LLMs)的快速发展为视频异常检测(VAD)的技术框架带来了变革性的突破。
-
MLLMs 和 LLMs 从四个维度全面升级了 VAD 框架
- 在数据标注层面,传统 VAD 依赖人工标注的像素级或帧级标签;而 MLLMs 能够通过跨模态对齐实现“文本-视频”监督学习,将自然语言描述直接映射到异常语义原型,显著提升了检测效率 [10]。
- 在输入模态层面,VAD 从单一视频流分析演进为多模态协同分析,增强了在复杂场景下的语义理解能力 [11]。
- 在模型架构方面,由 MLLM/LLM 驱动的多模态预训练框架通过统一的视频-文本表征空间,增强了时空-语义联合异常检测能力 [12]。
- 在任务目标层面,VAD 从简单的“检测-定位”扩展到包含“可解释性诊断”、“跨模态检索”和“增量学习”等更丰富的功能,实现了更智能、更灵活的异常管理机制 [13]。
-
本综述的主要贡献可概括如下:
- 作者深入分析了MLLM和LLM技术进步所引发的VAD领域的变革,从基本逻辑层面阐释了语义信息如何成为推动VAD技术范式转变的核心驱动力。
- 作者重新审视并重新定义了VAD任务,提出了一种更具综合性与适应性的统一分析框架。在此基础上,作者系统深入地介绍了基于MLLM/LLM的VAD方法。这是首篇专注于基于MLLM/LLM的VAD方法的全面综述。
- 结合当前研究现状,作者提炼出VAD领域面临的关键挑战,并对未来可能取得突破的研究方向提出了前瞻性见解,为后续研究提供了方向性指导。
2 VAD 分析
- 为什么要引入 LLM ?
- 首先,作者将VAD任务分解为三个组成部分:视频流、数据标注和网络架构。
- 视频流提供不同层次的视觉信息;
- 数据标注则提供相应的语义信息;
- 网络架构的作用是连接视觉特征空间与语义特征空间,并在其中一个空间中学习分类边界。
- 传统的基于DNN的方法通常将来自语义特征空间的标注信息映射到视觉特征空间,并在该空间中学习分类边界。
- 然而,这种映射过程存在两个根本性局限:
- 1)人工预定义的映射规则受到标注信息偏见的影响,限制了模型的泛化能力;
- 2)语义信息的隐式使用严重削弱了模型的可解释性。
- 因此,参考人类大脑处理异常的方式:当接收到视觉信息后,人类首先将其抽象为语义表征;然后,根据任务需求,在语义空间中将这些抽象出的语义信息与预定义的规则进行比对,从而识别异常。
- 首先,作者将VAD任务分解为三个组成部分:视频流、数据标注和网络架构。
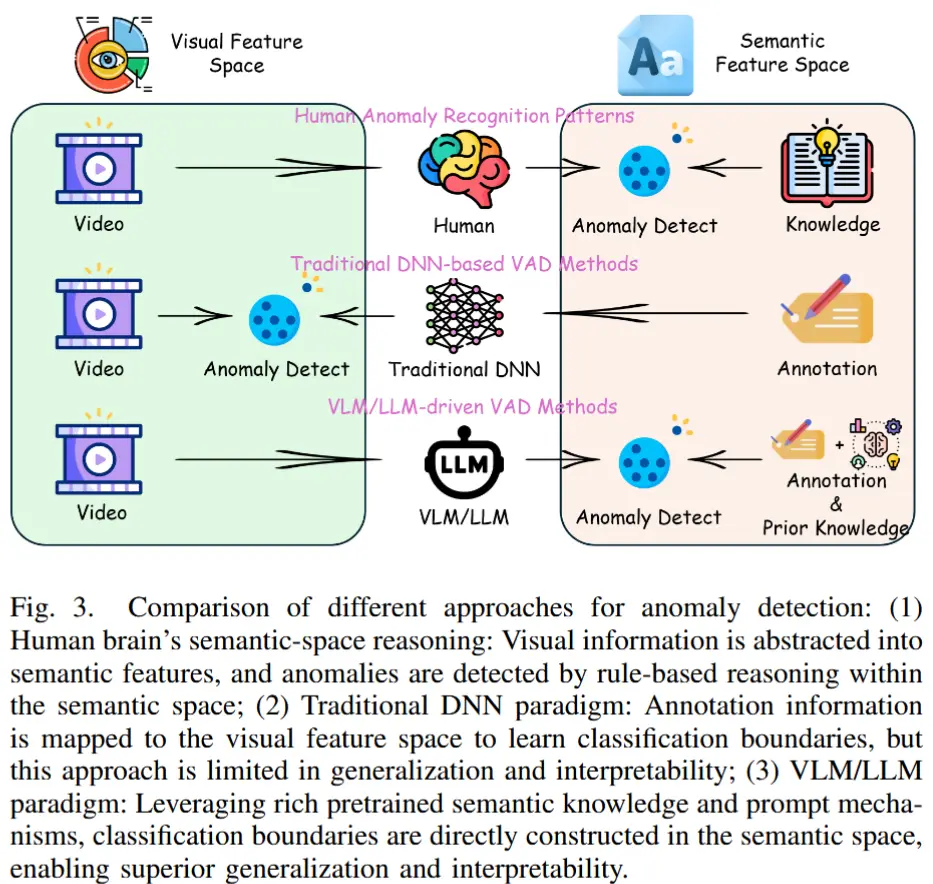
- LLMs和MLLMs具备三个对VAD领域尤为关键的特性:
- 1)LLMs/MLLMs能够将视觉信号直接抽象为可理解的语义信息;
- 2)这些模型在预训练阶段已积累了丰富的语义知识;
- 3)它们支持通过提示(prompt)方式进行无缝交互,无需额外的训练开销。
3 背景
3.1 任务目标
- VAD 任务目标可以分为两个方面:
- 视频异常定位 VTG:该任务要求模型在时间维度上对视频片段进行逐帧或逐片段的异常评分,从而定位异常发生的起止时间。
- 视频异常理解 VAU:传统的基于DNN的方法要求模型在特定监督条件下正确分类异常帧。随着MLLMs/LLMs的发展,VAU任务进一步扩展,涵盖对异常的描述性解释以及因果理解。
具体符号表示见论文。
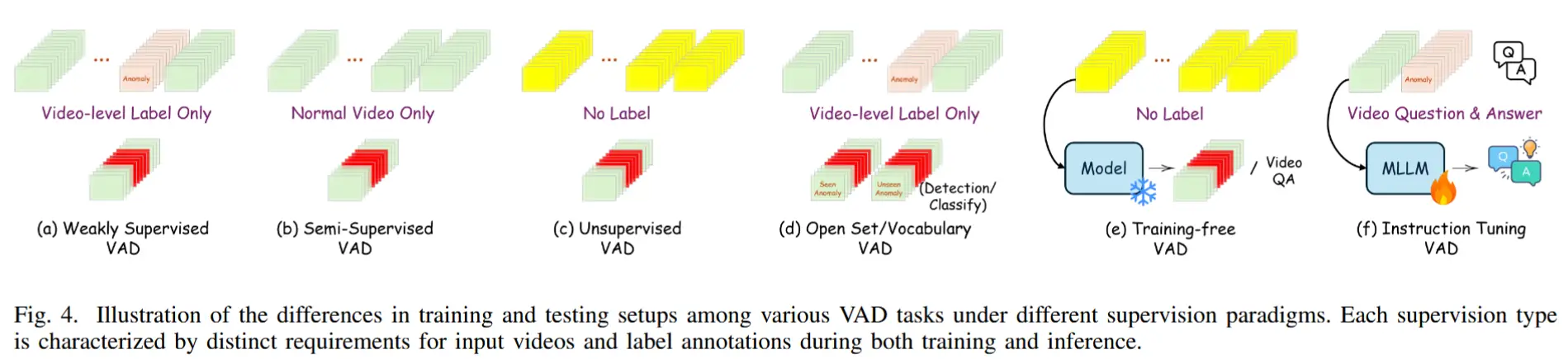
3.2 VAD 任务分类
-
弱监督 VAD
- 定义:训练用正常和异常视频,但异常只有视频级标签(无帧级标签)。
- 优点:比半监督更强,适应场景切换。
- 缺点:算法设计复杂,异常视频收集成本高。
-
无监督 VAD
- 定义:完全不依赖标注,从未标注视频中检测异常。
- 优点:可自我更新,无需数据标注。
- 缺点:缺乏监督信号,结构复杂,性能较差。
-
开集 VAD (Open-set)
- 定义:检测训练未见过的异常,但不要求识别其类别。
- 优点:泛化能力强,应用价值高。
- 缺点:需额外模块或伪异常生成。
-
开放词汇 VAD (Open-vocabulary)
- 定义:不仅检测,还需分类未见过的异常。
- 优点:识别能力更强。
- 缺点:难度高,依赖更精细的标签和模型能力。
-
无需训练 VAD (Training-free)
- 定义:直接利用 VLM/LLM 先验进行异常检测。
- 优点:高效灵活,快速适应新场景。
- 缺点:性能依赖规则和先验,计算开销大。
-
指令微调 VAD
- 定义:在特定数据上微调预训练模型以适应 VAD。
- 优点:结合预训练知识与任务特定优化,效果好。
- 缺点:需额外数据和算力,可能过拟合,泛化性下降。
3.3 数据集和评估指标
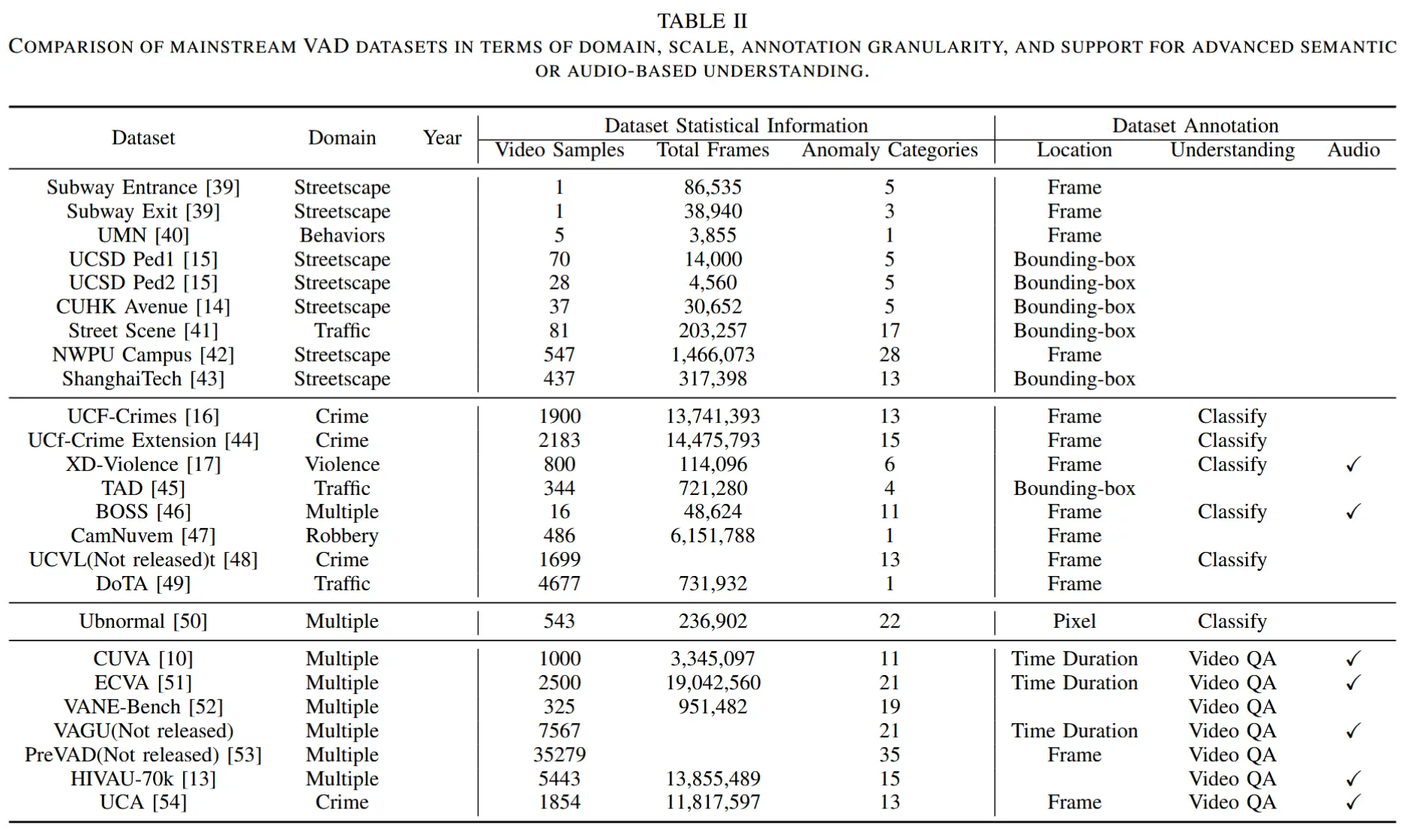
- 在表II中,作者对当前主流数据集进行了详细对比。
- 评估指标(具体计算公式见论文)
- AUC:AUC指的是ROC(受试者工作特征曲线)下的面积。ROC曲线通过比较不同阈值下的真正率(TPR)和假正率(FPR)绘制而成。
- EER(等错误率)和 EDR(等检测率):EER是指ROC曲线上FPR等于FNR(假负率)时的错误率,代表了系统在误报和漏报之间取得平衡的点。EDR则表示在特定检测阈值下,系统检测到的异常数量占总异常数量的比例,强调检测的完整性。
- Accuracy(准确率):准确率是一种常用于分类模型或诊断测试的性能指标,定义为正确预测数占总预测数的比例。
- RBDC(基于区域的检测准则):RBDC用于评估模型在单个视频帧内精确定位异常区域的能力。该指标通过比较模型检测到的异常区域与标注的真实区域来计算得分。
- TBDC(基于轨迹的检测准则): TBDC用于评估模型在时间维度上检测和跟踪异常的能力,衡量其在连续视频帧中定位异常的性能。
- AP(平均精度): AP指的是精确率-召回率曲线(Precision-Recall)下的面积。AP在正样本数量有限(如异常样本)的场景中尤为有效。
- BLEU、ROUGE、METEOR : 文本相似性评估指标。主要用于评估 VLMs 和 LLMs 用于 VAD 任务时相关的问答或字幕生成评估。
- 一些专门为 VAD 和大模型设计的指标[11][38]。
4 VAD 方法综述
4.1 总体概述
- 基于大模型的VAD方法在研究范式上展现出相对于传统DNN方法的相对独立性,同时也体现出显著的方法论延续性与技术互补性。
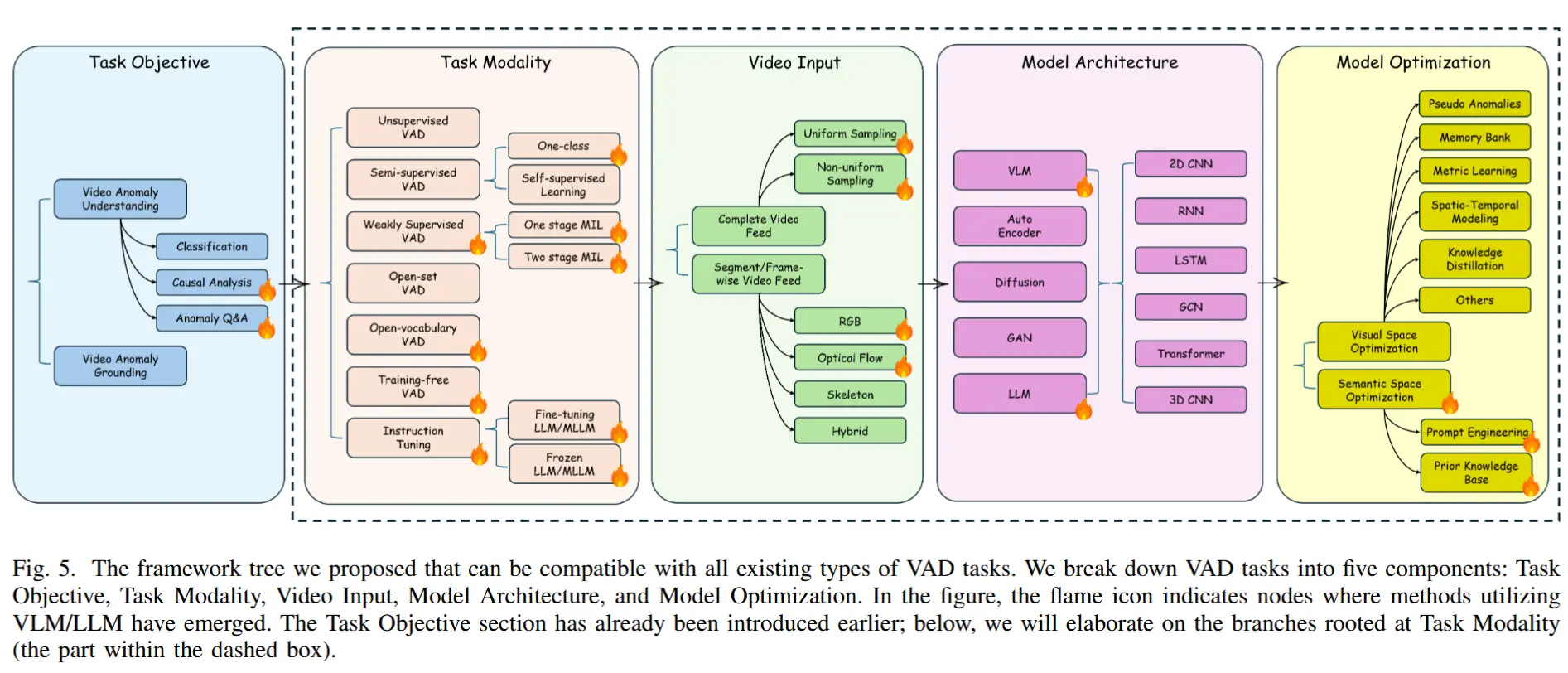
- 为了系统性地梳理该领域的最新进展,并构建一个统一的理论分析框架,我们提出了一种具有强兼容性的新型分类框架。该框架涵盖五个核心维度:任务目标、任务模态、视频输入、模型架构和模型优化,从而为传统DNN方法与VLM/LLM方法建立了一个统一的分析体系(见图5)。
4.2 任务目标
- 视频异常理解: 分为以下三个子任务:
- 分类:该任务通常与异常定位(anomaly grounding)联合建模,要求模型在时间维度上识别出包含异常的视频帧,同时准确判断异常事件的类别。早期研究中,I3D 和 VideoSwin 等时空特征提取网络取得了显著成果。随着 VLMs 和 LLMs 的发展,基于CLIP架构的方法在分类性能上展现出更强的泛化能力和优越表现。
- 异常问答: 可以看作视频问答任务在视频异常场景下的延伸。当前研究主要集中在两种范式:基于预训练知识的 Training-free VAD 和 Instruction-tuned VAD 。现有工作:LAVAD、SUVAD、VERA、AnomalyRuler等。
- 因果分析(Causal Analysis):在形式上与异常问答相似,但该任务对模型的因果推理能力提出了更高要求。它不仅需要准确描述异常现象,还需系统分析异常发生的原因及其潜在影响。由于强调精确的关键帧提取和时空因果链的构建,该任务比传统的问答任务更具挑战性。CUVA 框架通过可学习的多实例时空注意力模块实现关键帧定位,并建立了首个用于因果分析的基准数据集。后续研究如 ECVA 进一步优化了时空特征交互机制。
- 视频异常定位:VAD 领域主流且核心的任务,视频异常定位旨在精确识别异常事件的时间区间和空间分布。这里的定位包括时间维度和空间维度。
5 半监督 VAD (TBD)
6 弱监督 VAD
弱监督VAD 仅依赖于视频级异常标注,更贴近现实应用场景。
6.1 范式
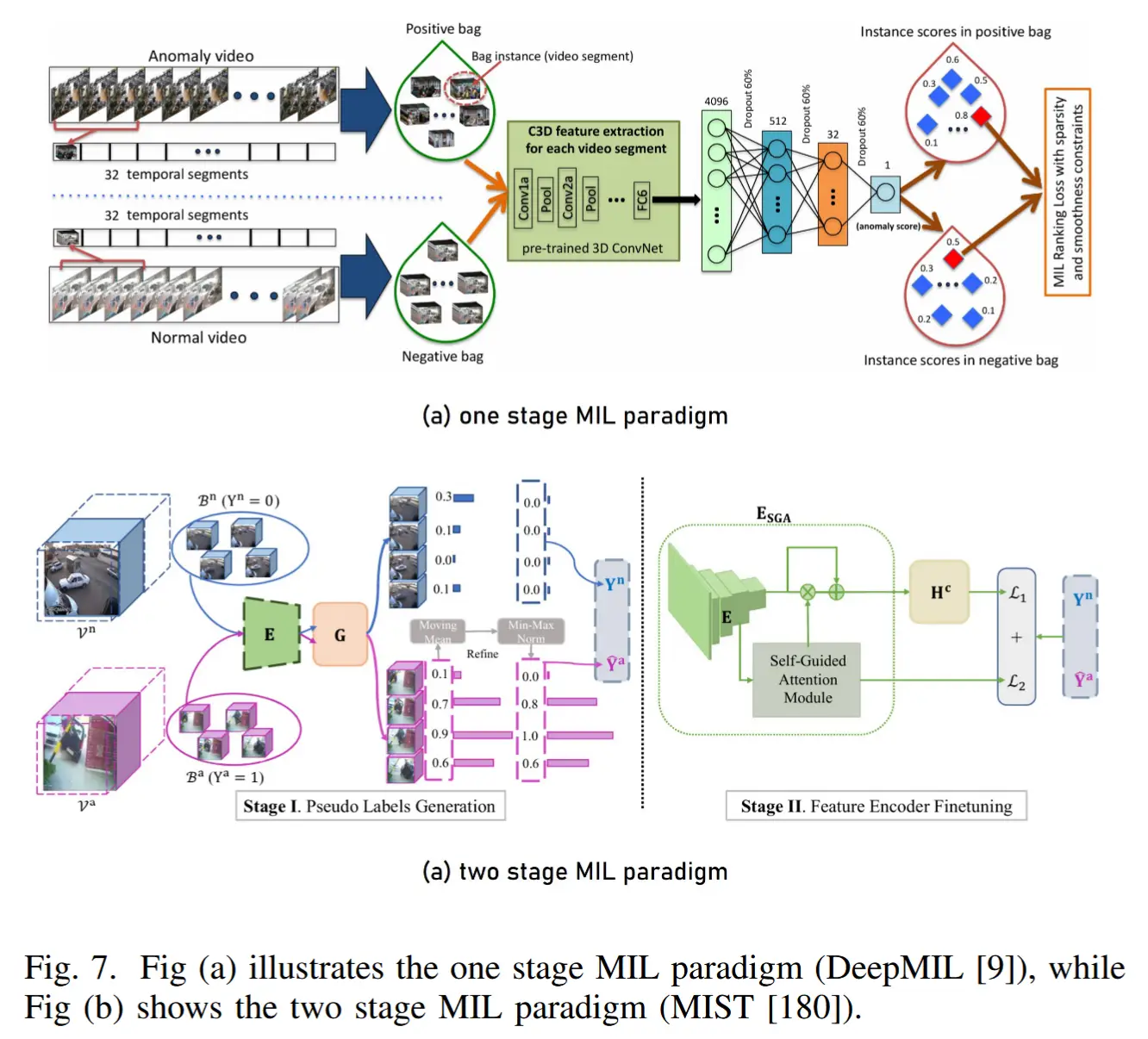
- 单阶段多实例学习 One Stage MIL
-
核心思想:识别正常视频和异常视频中最具可能的异常片段,并要求模型能够区分二者。
-
实现范式:具体而言,典型流程包括将长视频划分为多个片段,利用MIL机制从每个视频中选出最具代表性的top-k个片段,并最大化正常视频与异常视频中“最异常”片段之间的得分差异。
-
优化目标:
l_{osm} = \sum_t P\left(1, 1 - \max \Phi_{osm}(x_t^a, \theta) + \max \Phi_{osm}(x_t^n, \theta)\right), \quad (26)其中, x_t^a 表示来自异常视频的帧序列, x_t^n 表示来自正常视频的帧序列。
-
相关工作:现有研究尝试引入 VLM 的预训练知识,通过语义引导进一步优化模型的判别空间。例如:VadCLIP 基于 CLIP 设计了一种细粒度的双分支结构(语言分支与视觉分支),将 CLIP 的预训练知识迁移至弱监督VAD任务中。LPE 、AnomalyCLIP 和 TPWNG,则引入可学习提示与 CLIP 模型,以增强上下文建模能力和语义判别力。LAP 通过分析提示词与视频字幕之间的异常相似性,生成伪异常标签,从而引导模型识别潜在的异常事件。
-
单阶段MIL优缺点
- 结构简单、计算高效
- 由于仅依赖视频级标签,在明显异常时表现良好,却容易忽略细微或不易察觉的异常事件。
- 两阶段多实例学习 Two Stage MIL
- 核心思想:利用第一阶段训练的基础模型预测结果,自动选取高置信度的异常区域作为伪标签,用于模型的再训练,从而实现自适应性能增强。
- 相关工作:NoiseCleaner 、MIST、MSL 和 CUPL 等方法均采用了典型的两阶段MIL范式。
- 优缺点:
- 两阶段MIL方法在性能上表现优异。
- 存在计算复杂度高和伪标签噪声干扰等缺点。
6.2 视频输入
弱监督方法通常也以分段视频片段作为输入。通常包含以下模态输入:
- RGB:典型做法是将长视频划分为多个片段,并使用预训练视觉模型从每个片段中提取全局特征。常见的视觉模型有 C3D、I3D、3DResNet和TSN。
- 光流Optical Flow:以运动信息为核心的输入(如光流)也在弱监督VAD中有所探索。
- 音频:例如XD-Violence数据集提供了音频信号。
- 文本:多项研究 [33], [68], [176]–[178] 探索了使用可学习文本提示来引导视觉空间中决策边界的重构。
- 多模态融合:组合多种输入模态可有效弥补单一信号的局限性,从而提升模型性能。常见的包括:RGB + 光流 [190]、RGB + 音频 [191], [192]、RGB + 光流 + 音频 [193],以及近期兴起的 RGB + 文本组合 [33], [54], [176], [178]。
6.3 模型架构
常见架构对比:
- 3D CNN 擅长捕捉局部时空特征。
- LSTM 和 TCN 在建模序列依赖关系方面表现优异。
- GCN 适合表达实体间的关系(如人体骨架或动态图结构)。
- Transformer 凭借其建模全局依赖的能力,已成为该领域最具前景的架构之一。
6.4 模型优化
- 视觉空间优化
- 时空建模:异常事件通常表现为局部时空结构的扰动,因此主流方法强调对空间与时间特征的联合建模。一方面,时序建模用于捕捉片段间的动态变化;另一方面,空间建模旨在精确定位异常发生的具体区域。相关技术包括:
- 时序卷积网络[198], [199];
- 空洞卷积(Dilated Convolutions)[63];
- 图卷积网络(GCN)[64], [200];
- 条件随机场(CRF)[201];
- Transformer [60], [194]–[196]。
- 知识蒸馏:通过蒸馏,将信息丰富的教师模型(如多模态分支)所蕴含的知识迁移至学生模型(如单模态分支),从而在模态信息稀缺或缺失的情况下提升学生模型的检测性能 [192], [202]。
- 度量学习(Metric Learning):在特征空间中使相似特征紧凑聚集,使不相似特征彼此远离,从而提升判别能力。目前,大量研究 [62], [183], [194], [203], [204] 已利用度量学习增强特征判别性。
- 语义空间优化
- 提示工程:随着 CLIP 等视觉语言模型的广泛应用,提示工程已成为优化语义空间的一种创新方法。例如,CLIP-TSA [197]、VadCLIP [33]、LPE [176], [177] 以及 Yang 等人 [68] 的工作,均设计了特定的异常描述模板,引导模型关注异常事件的语义特征。
7 无监督 VAD (TBD)
8 无需训练 VAD
无需训练VAD(Training-Free VAD, TVAD)的核心思想是利用LLMs和MLLMs的语义交互能力和多模态理解能力,首先将视频总结为特定的文本描述(caption),再通过分析这些文本实现异常检测。
8.1 范式
TVAD 的核心在于如何挖掘 MLLMs 的潜力,以更有效地总结或分析视频内容。具体而言,MLLMs 首先对输入的视频序列或完整视频执行视频字幕生成或视频问答。随后,额外的LLMs或MLLMs进一步对生成的文本进行精炼与清洗,该过程可能重复多次。最终,基于数据集或人工提供的 prompt,LLM或MLLM对处理后的视频内容进行分析,并输出异常发生的概率。
- LAVAD 首次提出了一种TVAD范式,利用预训练的LLMs和VLMs进行时间维度上的聚合,在保持竞争力性能的同时,提供异常解释。
- SUVAD 在LAVAD基础上进一步改进,引入粗到细的异常分析与平滑模块,以缓解“幻觉”(hallucination)问题。此外,SUVAD利用MLLMs固有的视频分析能力,使模型能够自主判断数据集中正常与异常事件之间的区别。
- AnomalyRuler 提出一种基于规则的推理方法,在静态场景中表现出强大性能。
- AnyAnomaly 引入可定制化视频异常检测技术与模型,将用户定义的文本作为异常事件,通过上下文感知的视觉问答有效实现异常检测。
- VADSK 设计了两阶段的推理流程:先通过关键词识别进行推断,再在监控视频中检测异常。
- VERA 专注于 prompt engineering,提出一种语言驱动的学习框架,将提示视为可学习参数并持续优化;多个精心设计的提示能显著提升异常检测性能。
- MCANet 提出一种多模态字幕感知网络,融合现有的VLMs、ALMs和LLMs,动态生成并分析视频帧的文本描述,用于异常检测。
8.2 视频输入
由于异常事件占比小且计算资源限制,通常依赖采样策略。
目前,几乎所有基于MLLM的TVAD方法均采用视频分段后再进行精细分析与推理的策略(即Segment/Frame-wise Video Feed)。
此外,由于大部分 MLLMs 大多是在 RGB 视频流上进行预训练的,为了更好地适配这些模型的内在特性并发挥其能力,当前最常见的方式是将原始 RGB 视频切分为片段后输入模型。
- LAVAD 将视频划分为无重叠、固定长度的片段,然后使用字幕生成模型对每帧进行详细分析。
- AnomalyRuler、AnyAnomaly、VADSK 和 VERA 均采用此方法。
- SUVAD 进一步扩展了这一思路:首先在片段级别进行分析,识别出高概率存在异常的区域,再在这些区域内进行细致的帧级检测。
- MCANet 同时输入视频片段、单帧图像和音频,实现多流联合分析,增强多模态信息融合能力。
8.3 模型架构
现有工作主要是使用了各种 LLM/MLLM/VLM ,常见的有 CLIP、Qwen2.5-VL、Video-ChatGPT、Llama等。
- LAVAD 使用 BLIP2 作为视频理解模型,Llama-2-13b-chat 作为内容分析的语言模型。
- SUVAD 采用 GLM-4V 和 Llama-3-7b 分别完成视频理解和语义推理。
- VERA 评估了 InternVL2-8B、InternVL2-40B 和 Qwen2-VL-7B 在异常视频分析任务中的表现。
- 此外,许多主流MLLMs如 Video-ChatGPT、VTimeLLM、Qwen2.5-VL 和 TimeChat 也被广泛应用于VAD任务中。
- LAVAD 使用 CLIP 对片段级和帧级生成的标签进行清洗,从而获得更准确的视频内容描述。
- AnyAnomaly 利用 CLIP 引导模型注意力聚焦于场景中的主要内容,有效减少无关背景的干扰。
8.4 模型优化
由于TVAD不进行模型训练,也无法在视觉空间中对模型参数进行优化,因此,高效利用LLMs/MLLMs的指令跟随能力(语义空间优化)成为提升检测性能的关键。目前主要有两种主流策略:提示工程和先验知识库。
-
提示工程: 其核心是通过优化输入提示,引导模型关注视频中的关键内容,预定义待分析的异常类型、期望的输出格式以及应忽略的无关信息。
- VERA 使用一组持续更新的问题集,动态决定应优先关注哪些类型的异常。
- AnomalyRuler、AnyAnomaly 和 LAVAD 通过预先定义待检测的异常类型或明确描述正常事件,进一步缩小检测范围,实现更具针对性的异常识别。
-
先验知识库:先验知识库帮助LLMs/MLLMs更清晰地界定“什么是异常”以及“哪些信息可以忽略”。这些知识通常通过人工指定,或利用其他模型从训练数据中提取,并作为上下文信息嵌入提示中。
- SUVAD 和 AnomalyRuler 利用MLLM从训练集中生成“正常事件列表”,为模型提供明确的正常行为参考,从而将开放集异常检测转化为更易处理的闭集任务。
- VERA 则基于训练视频持续更新其问题集,确保提示始终保持对相关异常内容的精准聚焦。
9 指令微调 VAD
指令微调能够使大模型将其在预训练阶段获得的通用知识迁移至特定的异常检测任务中,从而增强模型对异常事件的理解能力与判别能力。
随着开源视频异常数据集的不断丰富以及多模态标注技术的进步,越来越多的研究者开始探索如何利用高质量的异常视频及其对应的自然语言描述,对大模型进行指令微调。此外,指令微调不仅可以直接更新大模型本身的参数,还可以通过冻结大模型、仅微调下游模块的方式实现高效适配,兼顾性能提升与计算效率。
9.1 范式
-
微调大语言模型/多模态大模型
-
这类方法在大模型已具备的通用视觉与语言知识基础上,通过构建或使用与异常相关的数据集和任务指令,进一步使模型学习异常事件的时空特征、语义描述以及推理能力。
-
具体流程通常包括以下关键步骤:
- 数据集构建与指令设计。
- 微调策略选择: LoRA、全参数微调、指令微调等。
- 多模态融合与时空建模:通过融合视频帧、光流、语义文本等多模态输入,设计合适的任务指令和输出格式,增强模型对异常事件的时空理解能力与语义可解释性。
-
代表性工作:
- HAWK:通过对大规模异常视频和多样化问答对进行微调,并在运动空间和视频空间中构建辅助一致性损失,在开放世界异常检测与问答解释任务上取得了SOTA性能。
- UCVL:通过在LLaVA-OneVision [231] 等模型上进行微调,提升了对复杂异常事件的理解能力。
- AssistPDA:提出时空关系蒸馏模块,将视觉语言模型(VLM)在离线场景下的长期时空建模能力迁移至实时场景,并构建了首个在线VAD数据集VAPDA127K。通过对该数据集进行微调,AssistPDA在统一框架下实现了视频异常预测、检测与分析。
- Holmes-VAU:构建了HIVAU-70k数据集,将传统弱监督范式与MLLM微调相结合,显著提升了异常检测性能。
-
-
冻结大模型 + 高效模块微调
-
冻结大模型的参数,将其作为固定的特征提取器或知识源,仅对上游或下游模块进行微调。该方法在大模型强大的抽象表征能力与上下游任务的高效适配需求之间实现了良好平衡,尤其适用于计算资源有限、需要实时推理或边缘部署的场景。
-
具体实现方式包括:
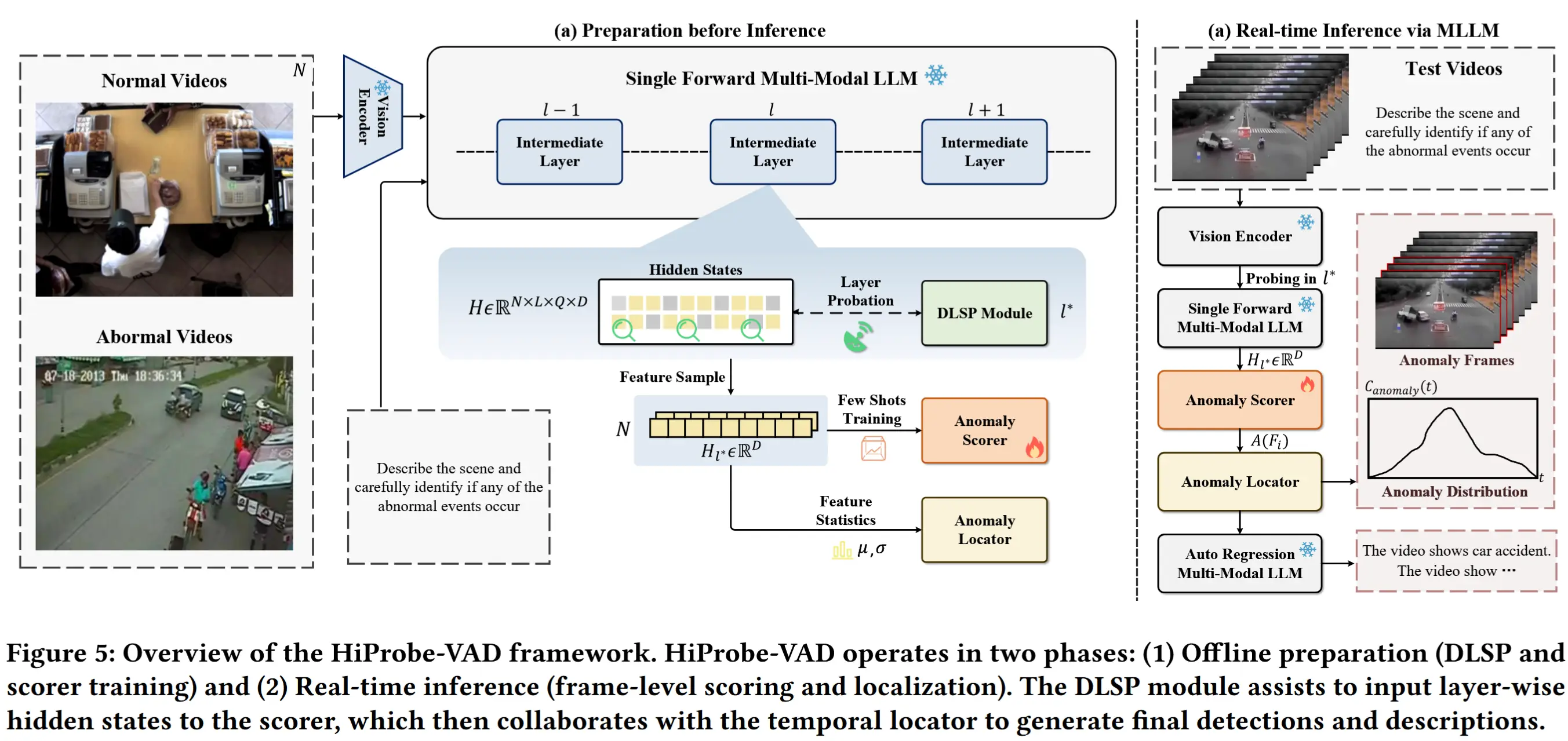
- 专用视频采样器学习:独立训练一个视频采样器,用于提取异常发生概率较高的帧,并将其输入后续的MLLM进行处理,从而提供更多异常线索,提升检测性能。
- 下游模块的高效微调:将大模型输出的特征或知识图谱传递给轻量级下游模块(如GNN、Transformer、检索网络等),仅训练或微调这些模块以适应特定的异常检测任务。
- 动态适应与增量学习:在冻结大模型的前提下,下游模块可通过在线学习、图结构更新或模块扩展等方式,快速适应新的异常类型或行为模式,从而增强模型的灵活性与鲁棒性。
-
代表性工作包括:
- SlowFastVAD:采用轻量级快速检测器与RAG增强的VLM协同工作。仅当检测到可疑片段时才调用VLM进行细粒度分析与推理,显著提升了推理效率和系统可扩展性。
- MissionGNN:在边缘设备上动态更新知识图结构,实现持续适应与高效推理。
- Vad-llama:采用三阶段训练流程,将长期上下文模块、视频异常检测器、异常预测变量和投影层与Llama模型结合,在UCF-Crime和TAD等基准上表现出色。
- VLAVAD:利用LLM的推理能力与选择性提示适配器(SPA)选择语义空间,并引入序列状态空间模块,显著增强了异常检测的可解释性。
- CUVA:对MIST [73] 选择器进行指令微调,自适应地筛选可能包含异常的视频帧,并输入至冻结的MLLM中,丰富了异常线索的提取,显著提升了对视频细节的理解能力以及长视频中异常的检测能力。
-
9.2 视频输入
- 完整视频输入
- 与大多数传统VAD方法采用分段或逐帧输入不同,指令微调型VAD充分利用大模型在时间建模和全局语义理解方面的强大能力,能够对完整的长视频片段进行整体输入与处理。
- 均匀采样
- 类似于现有的视觉问答任务,从整个视频片段中均匀采样帧,而不附加任何显式提示,是降低计算成本最基础、最直接的方法。
- 相关工作
- AssistPDA 使用 Qwen2-VL 视觉编码器处理分段的原始视频和连续视频帧,并通过STRD模块对提取的CLS token进行对齐后输入LLM进行推理。
- HAWK 利用 EVA CLIP 编码器结合Q-former,对视频帧和光流进行均匀特征提取。
- SlowFastVAD 直接采用VLM原始的采样策略,未作额外修改。
- 有点:实现简单,无额外开销。
- 缺点:异常事件在数据中占比极小,均匀采样往往会在异常视频片段中选取大量正常帧,可能误导模型,导致错误的语义理解与判断。
- 非均匀采样
- 非均匀采样旨在引导模型关注更可能包含异常的片段(而非无关区域)。
- 相关工作
- Holmes-VAU 采用自适应采样策略,沿时间轴动态关注感兴趣区域,优先选择更可能包含异常的帧,从而实现更细粒度的检测和更高的计算效率。
- CUVA 对MIST [73] 模块进行指令微调,使其能够选择与视频中异常事件高度相关的token。
- 优点:这类自适应策略在异常事件时间分布稀疏或高度依赖上下文时表现出色。
- 缺点:引入引导性采样模块也带来了额外的计算开销,并增加了训练成本。
- 分段/逐帧视频输入
- 部分方法采用密集视频分段并结合指令微调。
- 相关工作
- Vad-llama 将原始视频划分为等长片段,逐段输入模型,并采用三阶段微调策略,在UCF-Crime等基准上取得了显著性能提升。
- 优点:通过精细化处理局部片段,有助于捕捉局部异常细节,尤其适用于长视频中异常分布不均或需要高时间分辨率的场景。
- 缺点:牺牲部分全局上下文信息。
9.3 模型架构
目前,主流方法普遍采用如LLaVA-1.5、Qwen2-VL、CogVLM和InternVL2等代表性多模态大模型,这些模型在视觉与语言模态的对齐与理解方面表现出色,为下游任务提供了坚实的基础。
- CUVA 采用 VideoChatGPT 作为冻结的骨干模型,仅对额外的 MIST 模块 [73] 进行微调,从而充分挖掘预训练模型强大的表征能力。
- Holmes-VAU 以 InternVL2 作为主要的 MLLM,并结合基于 LoRA 的微调策略,使模型更好地适应多时间粒度下的异常理解任务。
- AssistPDA 使用 Qwen2VL 作为视觉编码器,并通过“时空关系蒸馏”(Spatio-Temporal Relation Distillation, STRD)模块,将其在离线场景中具备的长期时空建模能力迁移至在线推理框架,显著增强了模型的实时推理能力。
- HAWK 并未直接使用完整的 MLLM,而是采用轻量级的图神经网络(GNN)架构,融合大语言模型(LLM)和视觉语言模型(如 EVA CLIP),实现对开放场景中异常事件的高效、动态适应。这种设计提升了模型在实际应用中的灵活性与泛化能力。
9.4 模型优化
- 视觉空间优化
- 伪异常生成:伪异常生成是半监督VAD(SVAD)中的关键技术,其通过合成人工异常样本来模拟异常分布,从而增强训练效果。该方法有助于提升模型对未见异常的检测能力。
- HAWK 采纳并扩展了这一思想,通过在其知识图谱中动态调整和扰动节点,生成多样化的伪异常数据。这种方法不仅丰富了训练样本的分布,还使模型在训练过程中更好地适应复杂且不断变化的动态环境,显著提升了模型在真实场景中的泛化能力和鲁棒性。
- 记忆库:记忆库在捕捉正常行为分布方面发挥着关键作用。通过高效存储和检索正常样本的特征表示,记忆库为异常检测任务提供了有力支持。
- Holmes-VAU 利用记忆模块存储大量正常样本的特征,在推理阶段将测试样本的特征与记忆库中的特征进行比对。通过最大化正常与异常样本特征之间的距离,该方法有效增强了模型区分异常的能力,提高了检测精度。
- 时空建模:时空建模对于提升模型对输入数据中关键区域的关注能力至关重要。通过联合建模空间与时间信息,模型能够更全面地理解视频序列中的动态变化和显著事件。
- AssistPDA 引入“时空关系蒸馏”(STRD)模块,有效融合视觉输入与时间信息,增强模型对异常事件前后上下文线索的感知能力,使其能够捕捉与异常相关的细微时空关系,从而提升检测性能。
- 伪异常生成:伪异常生成是半监督VAD(SVAD)中的关键技术,其通过合成人工异常样本来模拟异常分布,从而增强训练效果。该方法有助于提升模型对未见异常的检测能力。
- 语义空间优化
-
提示工程
- Holmes-VAU 采用分层式提示设计,包括“描述”(Caption)、“判断”(Judgment)和“分析”(Analysis)三个阶段的提示,逐步引导模型生成高质量的异常分析结果。
- AssistPDA 通过优化自然语言提示,提升模型对复杂用户查询的响应能力,从而增强其对异常事件的识别与解释能力。
- CUVA 引入多轮问题优化机制,使用一系列有针对性的问题引导模型聚焦视频中的异常现象,不仅提升了异常检测的有效性,也增强了模型的交互能力。
-
先验知识库
- 引入知识库显著增强了模型对复杂场景的理解能力。通过融合结构化知识,模型能够动态更新环境中的异常模式,并结合常识推理,高效检测此前未见过的异常。
- HAWK 利用知识图谱对异常事件进行动态建模与管理,使其能够快速适应新出现的异常类型。同时,其轻量化设计确保了模型在边缘计算设备上的高效推理与部署。
-