- 论文 - 《OneLLM: One Framework to Align All Modalities with Language》
- 代码 - Github
- 关键词 - 多模态LLM、CVPR2024、8种多模态、统一编码器
摘要
- 问题背景:多模态大语言模型MLLMs的现有工作严重依赖于特定模态的编码器,这些编码器通常在架构上各不相同,并且局限于常见的模态。
- 本文模型 - OneLLM
- 一种通过统一框架将八种模态与语言对齐的MLLM。通过一个统一的多模态编码器和渐进式的多模态对齐流程实现了这一目标。
- 首先训练了一个图像投影模块,以连接视觉编码器与大语言模型(LLM)。
- 然后,我们通过混合多个图像投影模块和动态路由构建了一个通用投影模块(UPM)。
- 最后,我们利用该通用投影模块逐步将更多模态与大语言模型对齐。
- 新数据集:为了充分发挥OneLLM在指令跟随方面的潜力,作者还精心策划了一个综合性的多模态指令数据集,包含来自图像、音频、视频、点云、深度/法线图 (depth/normal map)、惯性测量单元(IMU)和功能性磁共振成像(fMRI)脑活动等模态的200万条数据。
- 实验:OneLLM在25个不同的基准测试中进行了评估,涵盖了多模态描述生成、问答和推理等任务,并在这些任务中表现出色。
1 引言
- 存在的问题
- 无论是视觉LLM,还是其他模态的LLM,都依赖于预训练的特定模态编码器和精心策划的指令微调数据集来确保其有效性。
- 然而,这些特定模态的编码器通常在架构上各不相同,要将它们统一到一个框架中需要相当大的努力。
- 此外,性能可靠的预训练编码器通常局限于广泛使用的模态,例如图像、音频和视频。
- 目标:构建一个统一且可扩展的编码器,能够处理广泛的模态。
- 启发
- 作者从最近关于将预训练Transformer迁移到下游模态的研究中获得了启发。
- Lu等人 [51] 证明,冻结的预训练语言Transformer可以在图像分类等下游模态任务中取得强劲的性能。MetaTransformer [103] 则展示了冻结的视觉编码器可以在12种不同的数据模态上取得有竞争力的结果。
- 综上,作者做出假设:为每个模态单独设计预训练编码器可能并非必要,一个经过良好预训练的Transformer可能充当通用的跨模态编码器。
- OneLLM
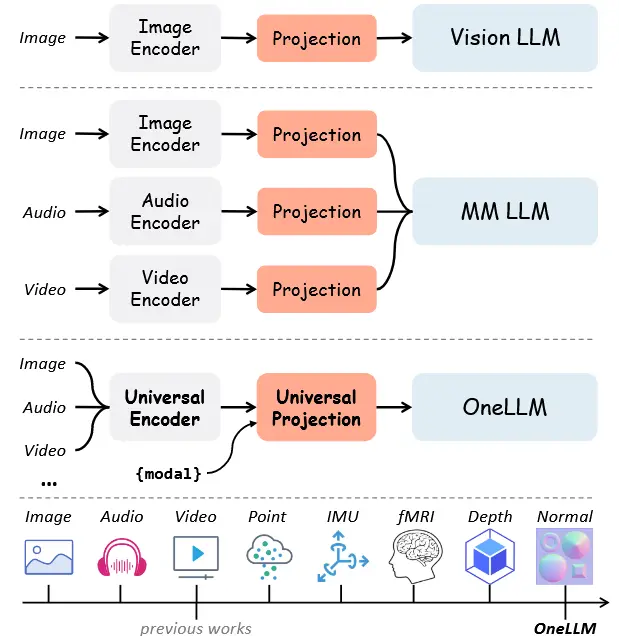
- 一种使用统一框架将八种模态与语言对齐的多模态大语言模型,如图1中间所示。
- OneLLM由 轻量级的模态分词器、通用编码器、通用投影模块(UPM)和大语言模型(LLM) 组成。
- 特定模态的分词器各自仅由一个卷积层组成,用于将输入信号转换为一系列标记。
- 编码器和投影模块在所有模态之间共享。
- 此外,添加了可学习的模态标记,以实现模态切换;并将不同长度的输入标记转换为固定长度的标记。
- 训练方法
- 思路:从一个视觉LLM出发,并以渐进的方式将其他模态与LLM对齐。
- (1)首先构建一个视觉LLM,使用预训练的 CLIP-ViT 作为图像编码器,辅以若干Transformer层作为图像投影模块,并使用 LLaMA2 作为LLM。在大量配对的图像-文本数据上进行预训练后,投影模块学会了将视觉表示映射到LLM的嵌入空间。
- (2)使用预训练的 CLIP-ViT 充当通用编码器。对于UPM,作者提出混合多个图像投影专家模型,作为通用的X-to-language接口。为了增强模型能力,我们还设计了一个动态路由机制,用于控制每个专家模型对给定输入的权重,从而使UPM成为一种软性的混合专家模型(MoE)。最后,根据数据规模逐步将更多模态与LLM对齐。
2 相关工作
2.1 大型视觉-语言模型
- Flamingo 通过交叉注意力层将冻结的视觉特征注入LLM,在广泛的视觉-语言任务中表现出色。
- BLIP2 使用Q-Former将视觉特征聚合为少量与LLM对齐的标记。
- LLaMA-Adapter 使用参数高效的微调方法连接预训练的CLIP 和 LLaMA ,能够处理封闭集的视觉问答和图像描述生成任务。
- LLaVA 使用线性层直接将视觉标记投影到LLM中。
- MiniGPT4 和其他一些工作 则将视觉标记重新采样为固定长度标记,从而降低LLM的计算成本。
- 本文工作也属于后者分支。我们为每个模态(即模态标记)预设了可学习的标记,这些标记用于聚合输入信息并为所有模态生成固定长度标记。
2.2 多模态大语言模型
- 除了视觉以外,还有其他工作将LLMs扩展到其他模态。
- X-LLM 使用特定模态的Q-Former和适配器,将预训练的图像、音频和视频编码器与LLM连接起来。
- ChatBridge 和 AnyMAL 采用了与X-LLM类似的架构,但分别使用 Perceiver 和线性层来对齐模态编码器与LLM。
- PandaGPT 和 ImageBind-LLM 利用 ImageBind 作为模态编码器,因此天然支持多模态输入。
- 局限:当前的MLLMs局限于支持常见的模态,例如图像、音频和视频。如何以统一框架扩展MLLMs以支持更多模态仍然是一个未解决的问题。
2.3 多模态-文本对齐
- 将多个模态对齐到一个联合嵌入空间对于跨模态任务至关重要,这可以分为两类工作:
- 判别性对齐:通过对比学习等方式,将不同模态映射到一个共享的嵌入空间,使它们在该空间中能够直接比较或匹配。目标是让模型学会区分“匹配”与“不匹配”的样本对。(例如CLIP、ImageBind)
- 生成性对齐:通过生成式方法,将一种模态(如图像)转化为另一种模态(如文本),或者直接生成与输入对应的输出内容。目标是让模型学会根据输入生成符合要求的结果。(例如GIT、BLIP2)
- 本文工作也属于生成性对齐。与之前的工作不同,本文直接将多模态输入对齐到LLM,从而跳过了训练模态编码器的阶段。
3 方法
本节介绍:架构->两个训练阶段:渐进式多模态对齐+统一多模态指令调整
3.1. 模型架构
图2展示了OneLLM的四个主要组件:模态特定分词器、通用编码器、通用投影模块(UPM)和大语言模型(LLM)。
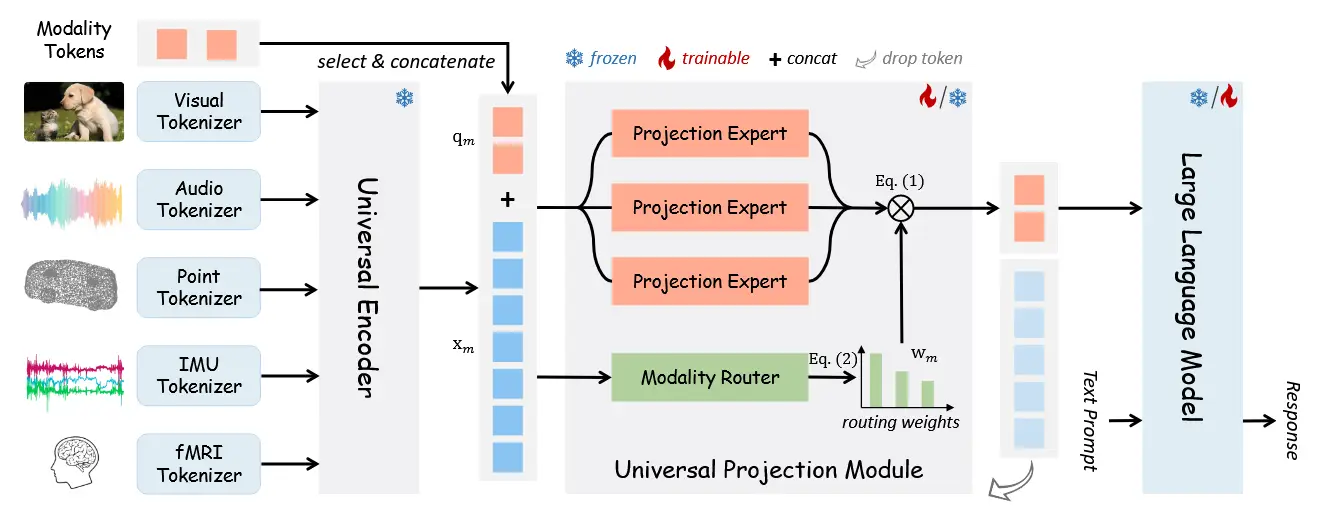
轻量级模态分词器
模态分词器的作用是将输入信号转换为标记序列,从而使基于Transformer的编码器能够处理这些标记。
将输入标记表示为 \mathbf{x} \in \mathbb{R}^{L \times D},其中 L 是序列长度,D 是标记维度。考虑到不同数据模态固有的差异,为每种模态设计了一个独立的分词器。对于包含二维位置信息的视觉输入(如图像和视频),使用一个2D卷积层作为分词器;对于其他模态,将输入转换为二维或一维序列,然后使用2D/1D卷积层进行标记化。例如,音频信号转换为 2D 频谱图,并使用 2D 几何先验对点云的子集进行采样。
通用编码器
利用预训练的视觉-语言模型作为所有模态的通用编码器。在OneLLM中,使用CLIP-ViT作为通用计算引擎。遵循之前的工作,在训练过程中保持CLIP-ViT的参数不变。需要注意的是,对于视频信号,将所有视频帧并行输入编码器,并在帧之间执行逐标记平均操作以加速训练。其他策略,如标记拼接,可能会进一步增强模型的视频理解能力。
通用投影模块
与现有针对特定模态的投影方法不同,作者提出了一种通用投影模块(UPM),用于将任何模态投影到LLM的嵌入空间。如图2所示,UPM由 K 个投影专家 \{P_k\} 组成,每个专家是一组在图像-文本数据上预训练的Transformer层。(虽然单个专家也可以实现任意模态到LLM的投影,但实验证明多个专家更有效且可扩展)
为了将多个专家集成到一个模块中,作者提出了一个动态模态路由器 R,用于控制每个专家的贡献并增加模型容量。路由器 R 的结构是一个简单的多层感知机,它接收输入标记并计算每个专家的路由权重,即软路由。此外,作者还引入了可学习的模态标记 \{\mathbf{q}_m\}_{m \in \mathcal{M}},用于在不同模态之间切换,其中 \mathcal{M} 是模态集合,\mathbf{q}_m \in \mathbb{R}^{N \times D} 包含 N 个维度为 D 的标记。在模态 m 的前向传播中,将输入标记 \mathbf{x}_m \in \mathbb{R}^{L \times D} 和模态标记 \mathbf{q}_m 连接后输入UPM:
其中 \mathbf{w}_m \in \mathbb{R}^{N \times K} 是路由权重,SoftMax函数 \sigma 确保 \sum_{k=1}^K \mathbf{w}_{m,k} = 1。对于任何模态 m,我们仅提取投影后的模态标记 \overline{\mathbf{q}}_m 作为输入信号的摘要,将 \mathbf{x}_m 从不同长度转换为统一的固定长度标记。
LLM
作者采用开源的LLaMA2作为框架中的LLM。输入到LLM的内容包括投影后的模态标记 \overline{\mathbf{q}}_m 和单词嵌入后的文本提示。注意,模态标记置于输入序列的开头。
3.2. 渐进式多模态对齐
由于数据规模的不平衡,直接在多模态数据上训练模型可能导致模态之间的表示偏差。为此,作者提出首先训练一个图像到文本的模型作为初始化,并逐步将其他模态对齐到LLM。
- 图像-文本对齐
一个基本的视觉LLM框架包括图像分词器、预训练的CLIP-ViT、图像投影模块 P_I 和LLM。考虑到图像-文本数据相对于其他模态相对丰富,作者首先在图像-文本数据上训练模型,以实现CLIP-ViT和LLM的良好对齐,即学习一个良好的图像到文本投影模块。预训练的 P_I 不仅充当连接图像和语言的桥梁,还为多模态文本对齐提供了良好的初始化,从而有效降低了将其他模态对齐到语言的成本。
- 多模态-文本对齐
多模态文本对齐可以视为一个持续学习过程。在时间点 t,已经在一组模态 \mathcal{M}_1 \cup \mathcal{M}_2 \cdots \mathcal{M}_{t-1} 上训练了模型,当前的训练数据来自 \mathcal{M}_t。为了避免灾难性遗忘,将均匀采样自先前训练的数据和当前数据。在本文中,作者根据数据量将多模态文本对齐划分为多个训练阶段:阶段I(图像)、阶段II(视频、音频和点云)以及阶段III(深度/法线图、IMU和fMRI)。如果希望支持新的模态,可以重复训练过程,即从先前的模态中采样类似数量的数据,并与当前模态联合训练模型。
- 多模态-文本数据集
为每种模态收集X-文本对的训练数据。
- 图像-文本对:LAION-400M [70] 和 LAION-COCO [69]。
- 视频、音频和点云:WebVid-2.5M [8]、WavCaps [56] 和 Cap3D [54]。
- depth/normal map:由于没有大规模的深度/法线图文本数据,使用预训练的DPT模型生成深度/法线图。源图像和文本分别来自CC3M [73]。
- IMU-文本对:Ego4D [27] 的IMU传感器数据。
- fMRI-文本对:使用NSD [5] 数据集中的fMRI信号,并将与视觉刺激相关的字幕作为文本注释。
需要注意的是,输入到LLM的内容是模态标记和描述标记的拼接。在这个阶段,不添加系统提示,以减少标记数量并加速训练。
3.3. 统一多模态指令微调
在完成多模态-文本对齐后,OneLLM成为一个可以为任何输入生成简短描述的多模态描述模型。为了充分释放OneLLM的多模态理解与推理能力,作者策划了一个大规模的多模态指令微调数据集,以进一步微调OneLLM。
多模态指令微调数据集
作者为每种模态收集了指令微调(IT)数据集,包含约200万条数据,涵盖了多种任务,例如详细描述/推理、对话、简短问答和描述生成。
- 图像IT数据集从以下数据集中采样:LLaVA-150K、COCO Caption、VQAv2、GQA、OKVQA、AOKVQA、OCRVQA、RefCOCO和Visual Genome。
- 视频IT:MSRVTTCap、MSRVTT-QA以及[104]的视频指令数据。
- 音频IT:AudioCaps [37] 和来自 [104] 的音频对话数据。
- 点云IT:[92]中包含70K条点云描述、对话和推理的数据集。
- 深度/法线图IT:从LLaVA-150K中随机采样了50K条视觉指令数据,并使用DPT模型 [19] 生成对应的深度/法线图。
- IMU和fMRI IT:从Ego4D [27] 和 NSD [5] 中随机采样了一部分数据。
提示设计
鉴于多模态IT数据集中包含多样化的模态和任务,作者精心设计了提示,以避免不同任务之间的冲突。作者根据数据集和任务设计了如下5种Prompt,具体内容见论文。
(a) 对于由GPT-4生成的IT数据集
(b) 对于描述生成任务
(c) 对于开放式问答任务
(d) 对于带选项的问答任务
(e) 对于IMU和fMRI数据集
尽管使用了这些固定的提示,我们的实验表明,OneLLM在推理阶段能够很好地泛化到开放式提示。
在指令微调阶段,将输入序列组织为:\{\overline{q}, Sys, [Inst_t, Ans_t]_{t=1}^T\},其中 \overline{q} 是模态标记,Sys 是系统提示,[Inst_t, Ans_t] 对应于对话中的第 t 个指令-答案对。需要注意的是,对于涉及多种模态的多模态输入(例如音频-视觉任务),将所有模态标记置于输入序列的开头。
对大语言模型(LLM)进行完全微调,并保持其余参数冻结。
4 实验
4.1 实验设置
- 架构
- 通用编码器:采用在LAION [70] 数据集上预训练的CLIP ViT Large。
- LLM:LLaMA2-7B。
- 通用投影模块UPM:包含K=3个投影专家,每个专家8个Transformer块组成。
- 训练细节:16块A100上进行3.2节中三个对齐阶段和3.3节指令微调训练,累计60万次迭代。
4.2 定量评估
作者在图像-文本、视频-文本、音频-文本、音频-视频-文本、点云-文本评估、深度/法线图-文本、IMU-文本、fMRI-文本上与不同的模型进行了评估,实验结果太多,不一一展示。
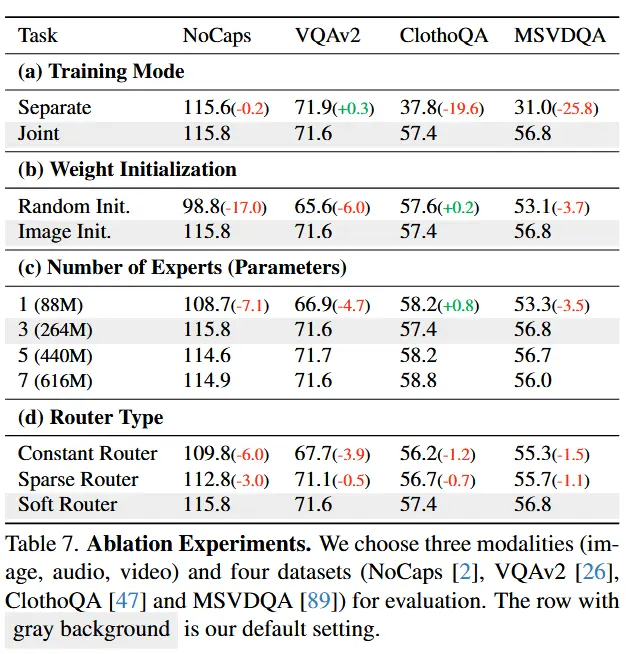
4.3 消融
- 如表7
- 作者设计了四个消融实验:单独训练 vs. 联合训练、图像对齐有助于多模态对齐、投影专家的数量、路由器类型。