- 论文 - 《Cosmo: Contrastive Fusion Learning with Small Data for Multimodal Human Activity Recognition》
- 代码 - Github
- 关键词 - MobiCom2022、人类活动识别(HAR)、霍普金斯统计量、对比融合学习、云边协作
摘要
- 研究背景:人类活动识别(HAR)。尽管多模态传感系统在捕捉现实世界中复杂且动态的人类活动方面至关重要,但它们也带来了若干新挑战,其中包括标注的多模态数据有限的问题。
- 本文工作 - Cosmo
- 一种针对多模态HAR应用中小数据的对比融合学习新系统。
- Cosmo采用了一种新颖的两阶段训练策略,该策略利用了云端的未标注数据和边缘端有限的标注数据。通过整合基于融合的对比学习和质量引导的注意力机制,Cosmo能够有效提取不同模态之间的一致性和互补性信息,从而实现高效的融合。
1 引言
- 问题介绍
- HAR应用中开始融合多种传感器模态。
- 挑战:
- 不同类型的传感器对同一事件或活动通常会产生高度异构的信息。
- 标注数据的数量通常非常有限,因为在现实环境中标注多模态数据十分困难。(例如毫米波和IMU等传感器数据)
- HAR应用中的传感器数据通常涉及隐私敏感信息,无法传输到云端。
- 活动识别模型需要针对个体进行定制化,因为个体的活动可能随时间呈现动态特性,这要求使用连续的多模态数据进行设备端训练。
- 现有工作
- 大多数先前工作专注于特定的一对传感器模态,无法扩展到其他异构传感器模态的融合。
- 一些基于深度学习的通用多模态融合框架,但它们依赖于全监督学习方法,需要大量标注的多模态数据进行训练,因此不适合仅有少量标签数据的真实HAR应用。
- 对比学习在自监督表征学习领域被提出,以应对标注数据有限的挑战。然而,这些方法要么针对单模态的HAR任务,要么为其他领域的双相似模态任务设计,无法适用于深度图像和惯性测量等显著异构的多模态HAR应用。
- 传统的多模态融合监督学习模型通常在云端训练,因为其计算开销高且需要大量训练数据。
- 本文工作 - Cosmo
- 采用了一种新颖的两阶段训练策略,利用来自多个异构传感器的未标注数据和(有限的)标注数据。
- 在第一阶段,在云端训练,Cosmo采用了一种基于融合的对比学习方法,使用未标注的多模态数据训练特征编码器。通过这种方式,Cosmo能够提取不同模态之间共享的共同知识的一致性信息。
- 在第二阶段,在本地训练,设计了一种新的质量引导注意力机制,使分类器能够在仅有少量标注数据的情况下捕捉不同模态的优势,从而探索各模态之间的互补性信息。
- 随后,我们提出了一种新颖的迭代融合学习算法,进一步提高了系统的准确性和收敛性能。
- 采用了一种新颖的两阶段训练策略,利用来自多个异构传感器的未标注数据和(有限的)标注数据。

2 相关工作
2.1 多模态传感在HAR中的应用
- 多模态传感系统在识别复杂且动态的人类活动中变得越来越普遍。
- 该领域的大多数先前工作基于监督学习,这可能难以适应现实中仅有少量标注数据的情况。
- 为了应对收集和标注大规模训练数据的挑战,早期的RF感知方法[8]通过利用在线视频和射频信号之间的相关性来解决这一问题。
- 与此不同,Cosmo采用了一种新方法,通过利用更容易获取的未标注多模态数据来提升HAR应用中的融合性能。
2.2 自监督多模态学习
- 最近在自监督表征学习领域提出了对比多模态学习方法。
- 目前的大多数方法是基于两种相似模态开发的,它们要么通过对比不同模态来学习跨模态嵌入空间,要么在多模态特征之间进行互聚类,但这些方法仅捕捉跨模态共享的信息,未能充分利用多模态协同效应。
- 并且在现实世界的HAR应用中,传感器模态变得越来越异构。
- 在本研究中,作者提出了一种新颖的基于融合的对比学习框架,能够从异构多模态数据中提取关键信息以实现高效融合。作者还从有限的标注数据中探索不同模态的优势,并将其与从未标注数据中学到的信息有效结合。
3 动机
在本节中,作者通过三种监督学习方法之间的对比,得出了模态一致性和互补性向结合有利于得到更有益和鲁棒的性能。
- 实验信息
- 三种监督学习方法
- SingleModal:仅使用单个模态监督学习。
- Deepsense [56]:来自不同传感器模态的特征被拼接在一起以实现融合。
- AttnSense [36]:基于注意力机制的模块动态学习不同传感器特征拼接的权重。
- 实验数据集和模态:USC数据集,加速度计Acc和陀螺仪Gyro。
- 模型:五个CNN、两个门控循环单元层GRU和一个全连接层。
- 三种监督学习方法
- 实验结果
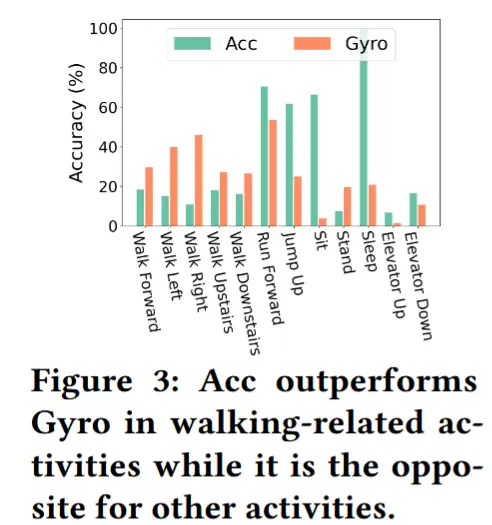
- 模态互补性:如图3所示,SingleModal方法中分别仅使用Acc和Gyro模态时,在每种活动的平均测试准确率,可以看到它们在不同活动中的测试准确率具有明显差异,这清楚地表明了模态之间的内在互补性。
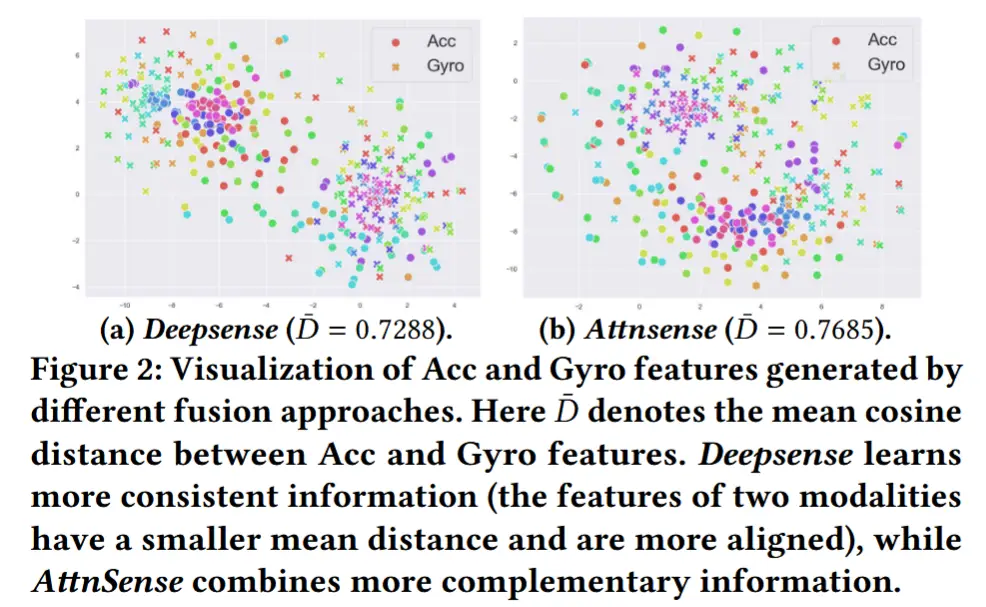
- 模态一致性:如图2(a)所示,通过t-SNE可视化了Deepsense生成的Acc和Gyro特征。颜色代表不同活动,点和叉表示不同模态。可以观察到两种模态的特征很好地对齐,并且几乎言对角线堆成,模态间的平均余弦距离为0.7288,这证明了模态之间的一致性。
- 结合一致性和互补性:如图2(b)所示,AttnSense生成的不同传感器特征的对齐程度低于图2(a)中Deepsense的结果。平均距离:Single-0.8067>AttenSense-0.7685>Deepsense-0.7288,这意味着,通过以不同权重拼接特征,AttnSense结合了来自不同模态的一致性和互补性信息。
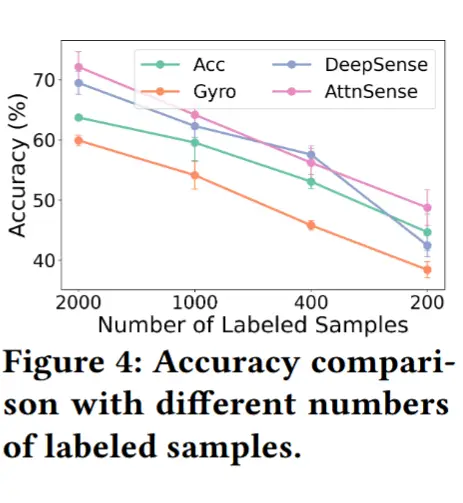
- 小数据量的影响
- 前面研究的是监督学习,需要标注数据。而HAR任务标注多模态数据极其困难,因此需要考虑在不同数量标注样本下的性能表现。
- 结果如图4所示,Deepsense仅在存在足够标注数据时才能提升相对于SingleModal的活动识别性能,这意味着仅捕捉一致性信息不足以提升融合性能。
- AttnSense通过为输入数据分配动态融合权重表现更好,然而,AttnSense相对于单模态的准确率提升仍然有限,因为少量的标注多模态数据不足以学习到稳健的融合策略。
4 系统概述
基于第3节动机,Cosmo的核心思想:采用了两阶段训练策略,首先从未标注的多模态数据中捕捉一致性信息,然后通过有限的标注数据迭代学习不同传感器的互补性信息。
在此,以深度相机与腕戴式可穿戴设备的融合为例(注意,Cosmo支持两种以上的模态融合)。图5展示了Cosmo的整体系统架构。
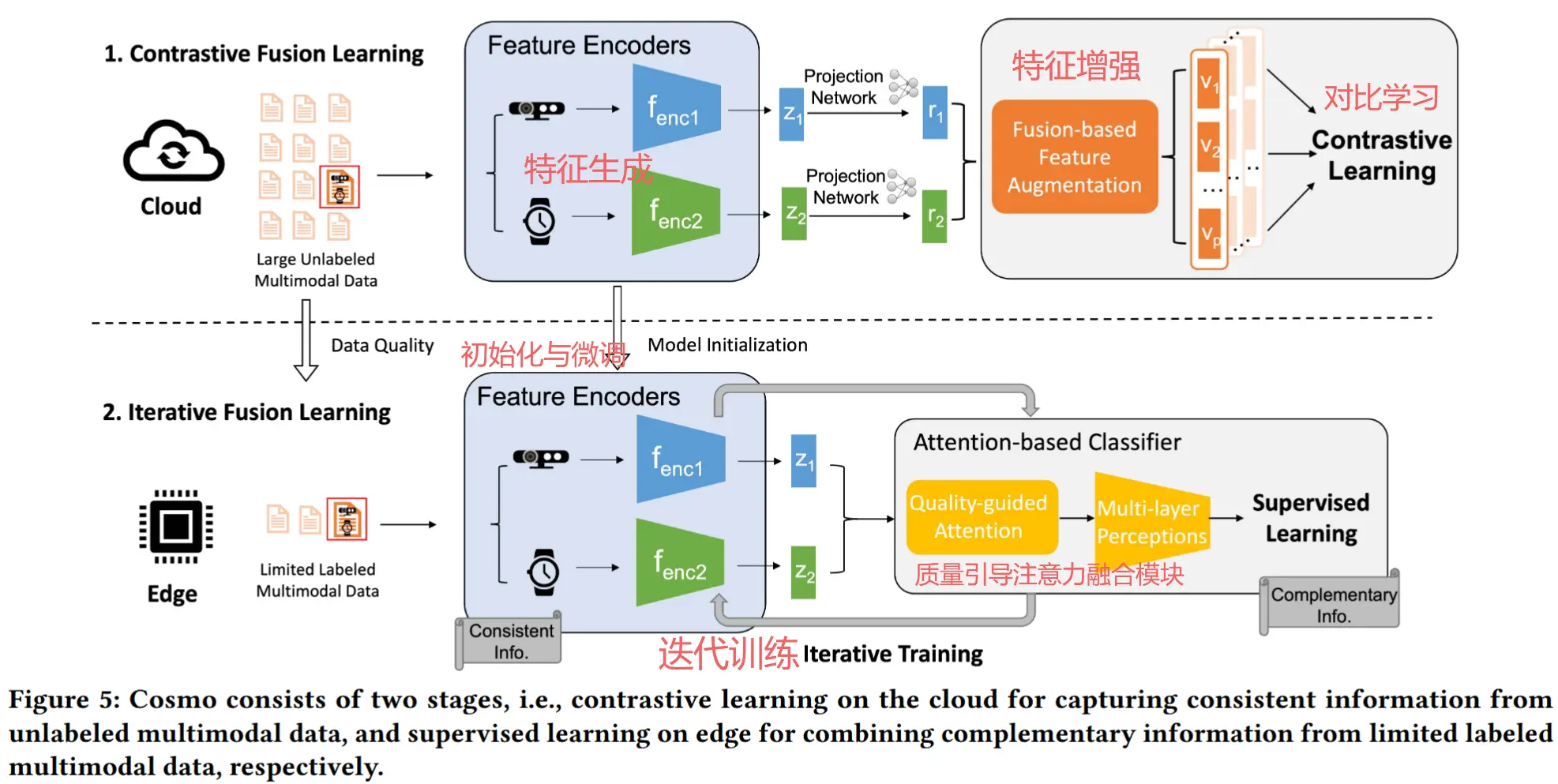
- 第一阶段
作者设计了一个基于融合的对比学习框架,用于训练每种模态的特征编码器,以从未标注的多模态数据中学习一致性信息。具体步骤如下:
- 特征生成:特征编码器生成单模态特征,再通过投影网络被转换到相同维度。
- 特征增强:一个基于融合的特征增强模块通过加权求和或拼接的方式将单模态特征广泛增强为一组融合特征。
- 对比学习:对比学习将来自同一样本的融合特征(正样本)聚集在一起,同时将来自其他样本的融合特征(负样本)推开。通过这种方式,特征编码器被训练为通过最大化不同模态特征之间的互信息来学习跨模态的一致性信息。
- 第二阶段
作者设计了一种迭代融合学习方法,以有效结合来自有限标注多模态数据的互补性信息。具体步骤如下:
- 初始化与微调:使用第一阶段训练得到的模型权重初始化特征编码器,然后对其进行微调。(注意只有特征编码器)
- 质量引导注意力融合模块:一个新颖的质量引导注意力融合模块,使分类器能够基于有限的标注数据捕捉不同模态的互补性信息。每个模态的数据质量通过未标注的多模态数据进行测量。互补性信息探索了不同模态中独特且独有的内容。
- 迭代训练:特征编码器和分类器将被迭代训练,逐步学习互补性信息,直到收敛。这种迭代学习设计的一个关键优势在于,它解决了从一致性特征中挖掘互补性信息的挑战,并防止模型退化为传统监督学习方法所学得的模型。
Cosmo的云-边架构实现方式具有以下几大优势:
- 低计算开销:计算开销较低,因此适合资源受限的边缘设备(第二阶段只用了少量数据训练)。
- 隐私保护:标注数据保留在本地,从而保护了用户隐私。
- 性能提升:通过允许用户提供少量标注(例如,标记午餐时间会自动为午餐期间的多模态数据打标签),整体训练性能可以逐步迭代提升。
5 Cosmo的设计
5.1 对比融合学习
第5.1节介绍第一阶段的对比融合学习方法。首先介绍表征学习框架中的主要组件,然后提出对比融合学习的损失函数。
5.1.1 表征学习框架
异构的传感器数据:多模态HAR应用中,不同传感器数据的模态和维度可能差异很大。例如,IMU传感器数据通常具有两个维度(即时间和9维向量),而深度视频则具有三个维度(即时间和2D深度图像)。因此需要首先使用不同的特征编码器提取深度单模态特征,然后通过投影网络将这些特征转换到相同维度。
对比学习:直接对比来自异构传感器模态的特征无法充分利用多模态协同效应。因此,作者提出了一种基于融合的特征增强模块,通过加权求和或拼接的方式将单模态特征广泛增强为一组融合特征。
接下来,分别介绍对比学习框架的三个主要组件。
- 单模态特征编码器
假设有 N 个未标注的多模态数据样本 \mathbf{x} = \{\mathbf{x}^i, \forall i = 1, ..., N\} ,其中 \mathbf{x}^i = \{\mathbf{x}_1^i, \mathbf{x}_2^i, ..., \mathbf{x}_M^i\} 包含 M ( M \geq 2 ) 个不同的模态。首先,不同模态的数据将分别输入到 M 个单模态特征编码器 (fenc_1(\cdot), ..., fenc_M(\cdot)) 中,生成 M 个表征向量:
其中 \mathbf{z}_j^i \in \mathbb{R}^{D_j} 是从第 j 个传感器模态提取的展平一维特征向量,维度为 D_j 。展平操作将使来自不同模态的异构特征更容易融合。此外,单模态特征编码器可以是任何现成的深度学习模型,具体取决于传感器模态。
- 特征投影网络
投影网络 (h_1(\cdot), ..., h_M(\cdot)) 将使用多层感知器将单模态特征映射到相同的维度:
这将确保输出特征在归一化后具有相同的维度 D ,并位于单位超球面上,即 \{\mathbf{r}_j^i, \forall j = 1, ..., M\} \in \mathbb{R}^D (作者实验中 D=128)。因此,投影网络可以统一来自不同模态的异构输入,为下一步的融合操作做好准备。
- 基于融合的特征增强
与直接对比 M 个不同模态的特征不同,在Cosmo中,对比不同模态的多种融合特征,以提取高效融合所需的一致性信息。具体来说,从样本 \mathbf{x}^i 中随机生成 P 个基于融合的特征增强 \{\mathbf{v}_k^i, \forall k = 1, ..., P\} 。每个增强表示传感器特征的不同融合组合,并包含原始数据样本的部分信息。这里, P 是增强特征的总数,与传感器模态的数量 M 无关。具体而言,第 i 个多模态数据样本的第 k 个融合特征增强由以下公式给出:
其中 \alpha_{1k}, ..., \alpha_{Mk} \in [0, 1] 是随机采样的权重,并且 \sum_{j=1}^M \alpha_{jk} = 1 。通过在统一的融合空间中对这些特征进行对比学习,特征编码器将生成对不同融合方案不变的特征。此外,特征增强可以根据具体应用和传感器模态进行设计。例如,对于更异构的模态(如深度图像和IMU数据),我们可以设置较大的采样范围(0.1–0.9);而对于相似的模态(如加速度计和陀螺仪数据),可以设置较小的采样范围(0.4–0.6)。然后,我们将增强特征归一化到单位超球面上,这使得在对比学习中可以使用内积来度量特征之间的距离。
5.1.2 对比融合损失
设计目标:训练特征编码器生成对不同融合方案不变的鲁棒表征。下面我们介绍为实现这一目标而设计的对比融合损失。
通过上述表征学习框架,我们将一个包含 N 个训练样本的小批量数据增强为 P \times N 个融合特征。令 s \in S \equiv \{1, 2, ..., P \times N\} 表示任意一个增强特征的索引, p \in P(s) 表示来自同一源样本的其他增强特征的索引。那么,索引为 s 的特征称为锚点特征,索引为 p 的特征称为正特征。来自其他数据样本的增强特征则作为负特征。这里, P(s) 是小批量中与 s 不同的所有正特征的索引集合。对比融合损失可以定义为:
其中, \mathbf{v}_s 是基于融合的增强模块输出的特征,符号 \cdot 表示特征向量的内积。
参数 \tau \in \mathbb{R}^+ 表示温度( \tau = 0.07 )。因此,最小化公式 (4) 中的对比融合损失将使正特征更接近,并将负特征推开。
对比融合学习设计的优势如下:
- 特征编码器的鲁棒性:特征编码器将被训练为生成对不同融合方案不变的单模态特征。
- 更快的收敛速度:基于预训练的特征编码器,在有限标注的多模态数据上的融合学习比传统的监督融合学习收敛得更快。
- 跨模态的一致性信息:学习到的表征将包含更多跨模态的一致性信息,这些信息对噪声多模态数据具有鲁棒性。
5.2 迭代融合学习
在第二阶段,首先介绍了一种新颖的质量引导注意力模块,用于在有限标注数据下的特征融合。然后,提出了一种迭代融合学习方法,以有效结合一致性和互补性信息。
5.2.1 质量引导注意力融合
注意本文的注意力,指的不是Transformer中的注意力,而是各种模态的权重参数。
设计动机:一个理想的HAR方法应该能够捕捉不同传感器模态之间在数据质量和贡献上的差异,并依赖更具信息量的传感器来提升融合性能。
基本思想:通过评估每个传感器模态的数据质量,动态调整其在融合中的权重,从而确保融合过程能够充分利用高质量数据,同时抑制低质量数据的影响。
- 先使用标注数据得到注意力权重
首先,单模态特征编码器将使用第一阶段训练得到的模型权重进行初始化,从而生成来自不同模态的深层特征 (\mathbf{z}_1^i, ..., \mathbf{z}_M^i) 。然后,将使用基于软融合的注意力模块来捕捉不同模态的互补性信息。融合注意力结构可以形式化如下:
这里,我们使用多层感知机MLP从 \mathbf{z}_j 中获取 \mu_j 。 \beta(\text{Attn})_1, ..., \beta(\text{Attn})_M 是由注意力模块生成的不同模态的权重。 尽管注意力模块能够捕捉不同模态的强度,但在标注数据有限的情况下,其效果可能不佳(生成的权重可能会包含干扰噪声和动态变化)。
- 再借助云端的大量未标注数据得到质量权重
因此,除了从有限标注数据中学到的权重外,作者还通过评估大量未标注数据的质量来引入另一组融合权重。具体而言,利用未标注数据的聚类能力来评估各个模态的质量。其原理是:潜在空间的聚类能力与其分类准确度高度相关。因此,当某一模态的数据具有更强的聚类倾向时,它将为分类任务提供更多有用的信息。
作者使用霍普金斯统计量(Hopkins statistic) 来量化未标注数据的聚类能力,这是一种介于0和1之间的统计指标。较高的霍普金斯统计量表示更强的聚类能力。此外,为了进一步减少其他动态因素对聚类能力测量的影响,作者还测量了聚类数量与真实类别数之间的绝对差值。具体而言,聚类的数量是通过K-means聚类后获得最高轮廓系数(Silhouette score,衡量聚类结果优劣的指标)的值确定的。假设第 j 个模态的霍普金斯统计量为 H(x_j) ,最优聚类数与类别数之间的绝对差值为 c_j ,则第 j 个模态的质量由以下公式计算:
然后,第 j 个模态的质量权重通过在所有模态中归一化质量指数得到:
- 两组权重融合后加权求和/拼接模态
接下来,将注意力模块生成的权重与使用未标注数据计算的质量权重结合起来,公式如下:
其中, \lambda 是调整质量权重影响的超参数,可以根据不同的数据集和设置进行调优。例如,当标注数据非常有限且嘈杂时,可以对大量未标注多模态数据给予更多信心,并选择较大的 \lambda 。然后,在所有 M 个模态中对组合权重 \beta_j 进行归一化,即 \beta_j = \beta_j / \sum_{j=1}^M \beta_j 。最后,基于质量引导的注意力权重 (\beta_1, ..., \beta_M) ,有以下两种适用于不同传感器模态的应用融合机制:
- 对于相似模态的传感器,并且当单模态特征具有相同维度时,使用加权求和:
- 对于极其异构的传感器模态或当单模态特征具有不同维度时,使用加权拼接:
通过结合从未标注多模态数据中计算的质量权重,基于注意力的融合模块可以实现更鲁棒的加权融合,来自每个模态的特征可以在HAR任务中提供不同的优势。
注意,质量权重是通过云端的大规模未标注多模态数据测量得到的,然后发送到边缘设备;而注意力模块则使用边缘设备上的有限标注多模态数据进行训练,生成注意力权重。
5.2.2 编码器与分类器之间的迭代训练
迭代训练动机:第一阶段训练的特征编码器实际上过滤掉了互补性信息,第二阶段如果简单的将编码器和分类器一起训练,可能导致遗忘特征编码器中继承的一致性知识
迭代学习方法:基于有限的标注数据有效结合不同传感器模态的一致性和互补性特性。这种迭代训练的目标是从标注的多模态数据中探索互补性信息,同时避免对特定传感器特征的过拟合。具体步骤如下:
- 初始化阶段:使用第一阶段训练得到的模型权重初始化特征编码器(丢弃投影网络和增强模块),并随机初始化分类器。
- 固定分类器微调编码器:在分类器固定的条件下,对特征编码器进行 T_{\text{iter}} 轮微调,其中超参数 T_{\text{iter}} 表示迭代训练的轮数。
- 固定编码器训练分类器:然后切换到在编码器固定的条件下对分类器进行 T_{\text{iter}} 轮训练,以平衡一致性和互补性信息。
- 重复迭代:上述过程将持续运行,直到达到预设的总训练轮数为止。
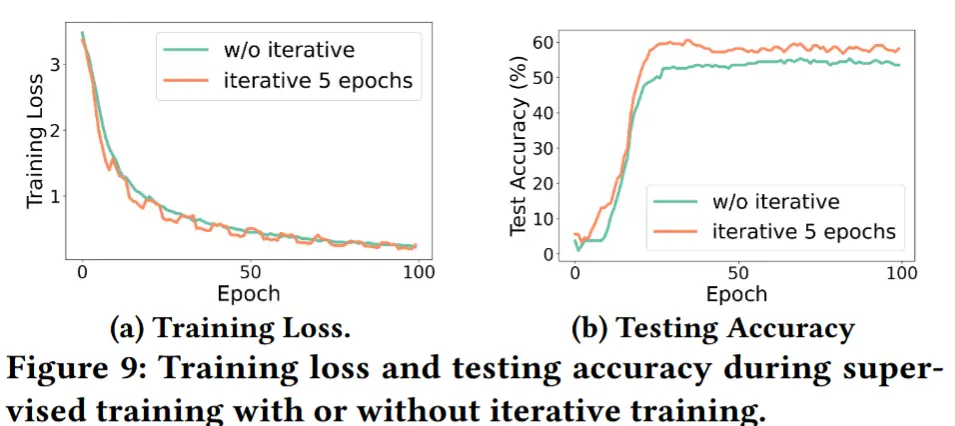
图9展示了在监督学习过程中是否采用迭代融合学习的性能对比。我们可以看到,通过迭代训练,训练损失曲线在每 T_{\text{iter}} 轮次中表现出方波行为。这是由于模型逐渐添加互补性信息,从而导致更好的测试准确率(如图9b所示)。