- 论文 - 《Fast-DAVAD : Domain Adaptation for Fast Video Anomaly Detection on Resource-Constrained Edge Devices》
- 关键词 - 边缘智能、域适应、视频异常检测、资源限制、对抗学习、记忆模块
1 引言
- 研究背景
- 人工智能物联网(AIoT)的发展使得在智能边缘设备上实现低传输延迟和保障数据隐私的视频异常检测成为可能。然而,这些应用的性能受到现实世界复杂环境与训练数据之间存在的领域差异(domain shift)的制约。
- 现有的领域自适应方法由于模型复杂度较高,难以部署在资源受限的边缘设备上。并且真实场景中缺乏大量标注数据,难以支持模型的充分训练。
- 实现精确的VAD面临的挑战
- 异常事件具有不可预测性,且在不同环境中表现形式各异,导致对异常事件进行人工标注耗时耗力,
- 异常的类型和表现形式多样,单一场景中可能同时发生多种异常事件。
- 异常事件本身极为罕见,因为大多数监控视频均由正常画面构成,异常样本难以获取。
- 由于上述挑战,VAD 常被视为一种无监督学习任务,现有方法主要分为四类:
- 基于距离的方法通过训练数据建立正常行为模型,并通过衡量测试样本与该模型的偏离程度来判断异常得分,但通常依赖复杂的手工特征提取。
- 基于分类的方法旨在通过识别不同事件之间的分类边界来区分正常与异常。
- 基于重构的方法利用仅包含正常活动的样本训练深度模型,通过识别偏离正常模式的事件来检测异常 。
- 基于预测的方法利用已知结果来估计输入变量的重要性,并预测目标变量发生的概率。
- 本文方法 - Fast-DAVAD
- 一种无监督、端到端、轻量化的自适应视频异常检测框架,该框架由一个自编码器、多层次领域自适应模块以及一个记忆模块构成。
- 多层次对抗性领域自适应技术:在每次训练迭代中采用最小-最大(min-max)策略,结合自编码器和多层次领域自适应模块,减小源域与目标域之间的差异。通过对抗学习方式,将源域和目标域样本映射到同一特征空间,实现编码器与领域分类器的联合训练,并在多个特征层次上对齐分布,从而相比其他领域自适应方法显著提升了模型的鲁棒性。
- 轻量化适应边缘设备:设计了一个基于残差U-Net的模块,加快视频帧的编码与解码速度,同时保持检测精度;并引入一个轻量级记忆模块,该模块根据查询特征生成记忆特征,辅助视频帧的重构。记忆模块独立于神经网络,不参与梯度下降更新,显著降低了模型的计算开销。
2 相关工作
2.1 异常检测
- 无监督学习是异常检测中常见的类别之一,通常利用自编码器(autoencoder)提取正常事件的特征,并通过重构视频帧来区分异常事件。
- 相关工作略过。
2.2 领域自适应
- 领域自适应主要解决知识从源域向目标域迁移的问题,其核心假设是源域与目标域的边缘概率分布不同,但条件概率分布相同。
- Pan 等人将最大均值差异(Maximum Mean Discrepancy, MMD)引入损失函数,通过在再生希尔伯特核空间(RHKS)中最小化源域与目标域特征之间的距离来实现分布对齐。
- 受对抗学习启发,Ganin 等人提出了DANN(Domain-Adversarial Neural Network),其结构包括特征提取器、标签预测器和领域分类器,其中特征提取器试图通过学习到的特征“欺骗”领域分类器,从而消除域间差异。
- ADDA 首先通过最小化交叉熵损失训练源域的特征提取器和标签预测器,随后在固定参数的基础上以对抗方式训练目标域的特征提取器。
- 与上述领域自适应方法相比,本文更关注在资源受限设备上的领域自适应问题,并提出了一种轻量化的网络架构。
2.3 边缘智能
- 边缘智能是指边缘计算与人工智能的融合,通过在数据源附近执行智能任务,有效缓解带宽压力并缩短响应延迟。
- Wan 等人基于 时空兴趣点(Spatio-Temporal Interest Points, STIP) 丢弃冗余帧,并将视频分割为关键片段,从而减少处理的视频帧总数。
- Kim 等人 [26] 设计了一种实时视频处理方案,其后端CNN由浅层3D CNN和预训练的2D CNN组成,兼顾效率与性能。
- Ullah 等人 [27] 采用双流神经网络策略:第一路在边缘端进行实时异常检测,第二路在云端利用双向LSTM(BD-LSTM)进行更精细的异常分析,用于检测如虐待、攻击等异常事件。
- 目前仍缺乏能够在资源受限设备上直接完成模型训练的有效解决方案。
3 方法
3.1 问题定义
给定一个源域视频数据集 \mathbb{D}_s = \{I_i^s\}_{i=1}^{n_s} 和一个目标域视频数据集 \mathbb{D}_t = \{I_j^t\}_{j=1}^{n_t},其中 n_s 和 n_t 分别表示源域和目标域中的样本数量。这些视频帧分别从联合分布 p_s(x) 和 p_t(x)(满足 p_s \ne p_t)中采样,且共享一个公共特征空间 \mathcal{X}_s = \mathcal{X}_t。本文的目标是设计一个函数 G: x \rightarrow y,该函数能够最小化源域与目标域特征之间的距离,从而捕捉不同场景下的视频特性,并实现视频帧的重构。通过测量重构帧 \hat{I}_t 与真实帧 I_t 之间的差异 P(\hat{I}_t, I_t),识别出异常的视频帧。
3.2 框架
Fast-DAVAD框架如图2所示,该框架由编码器-解码器、多层次领域自适应模块以及一个记忆模块组成。具体而言,模型的工作流程如下:
- 自编码器将源域和目标域的视频帧嵌入到特征空间中,并实现帧的重构。
- 多层次对抗性领域自适应模块通过对抗训练,在不同特征层级上减小源域与目标域之间的差异。
- 记忆模块基于查询特征生成正常特征,辅助视频帧的重构。
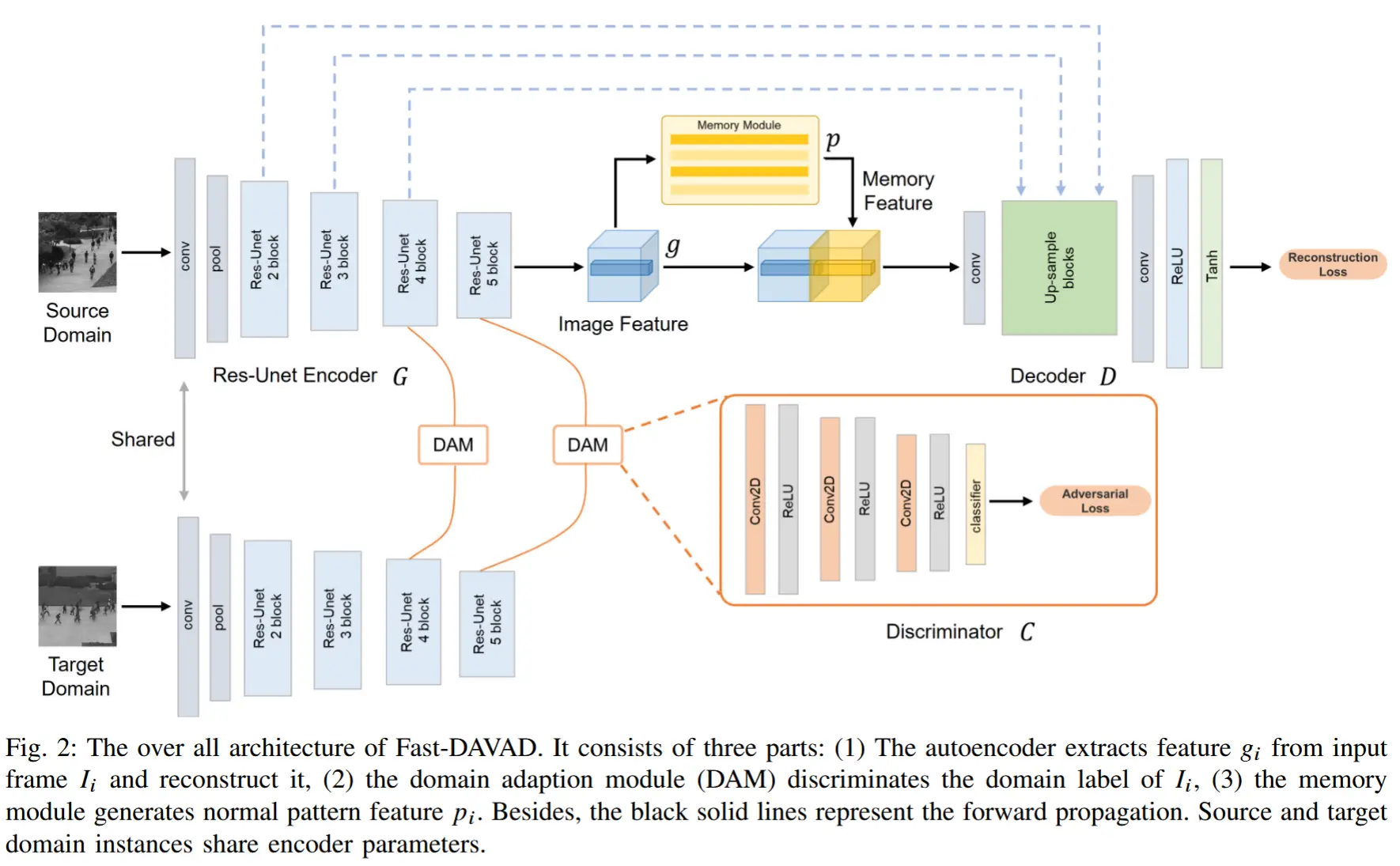
3.2.1 多层次对抗性领域自适应
多层次对抗性领域自适应目标:通过构建一个 领域判别器(DAM) 来区分来自两个域的特征,从而对齐源域和目标域的特征分布;与此同时,特征提取器 G 则试图混淆该领域判别器 C。
领域分类器 C 。领域分类器由全卷积组成,使用二元交叉熵损失来训练:
其中,g_i = G(I_i) 表示视频帧 I_i 的特征表示,当样本来自目标域时 y=0,反之来自源域时 y=1。
特征提取器 G 。特征提取器的训练损失由两部分组成:源域视频帧的重构损失+目标域视频帧的对抗损失。
源域视频帧的重构损失:使用特征提取器提取源域帧特征,并将其送入解码器进行重构,得到 重构损失:
其中,\mathcal{L}_{mse} 为均方误差损失。
目标域视频帧的对抗损失:将提取的目标域帧特征送入领域判别器以预测其所属领域的标签。为了尽可能使源域与目标域的特征分布接近,对抗损失可表示为:
为了确保异常检测的可靠性,作者在多个特征层级上进行异常识别。因此,多层次对抗损失可表示为:
其中,\lambda_{adv} 和 \lambda_{rec} 用于平衡两项损失。基于上述分析,最终目标是:
这意味着在最小化源域帧重构损失的同时,最大化目标域帧被误判为源域的概率,从而实现源域与目标域特征分布的有效对齐。
为什么多层次?
近期的研究工作 [28] 表明,仅在高层特征上进行对齐会忽略局部特征的匹配,且单一的适应策略在远离输出的低层特征尺度上效果不佳。
3.2.2 轻量级异常检测框架
为了实现快速异常检测,作者采用两种方法构建轻量级异常检测框架。
轻量级记忆模块。自编码器有时会因CNN强大的表征能力而过度重构视频帧,导致对异常的检测效果不佳。一些研究工作 [30] 尝试利用正常模式来辅助视频帧的重构。本文的记忆模块仅由 10,512 维的记忆项 p_n(其中 n = 1, \ldots, N = 10),以适应资源受限的环境。此外,作者将记忆模块与神经网络分离,使其能够独立于模型梯度下降过程进行更新,从而加快模型推理速度。
对于输入特征 G(I_i),其由 I = H \times W 个查询特征 g_i 组成,计算其与记忆项之间的相似性,并生成记忆特征:
然后将记忆特征 p_i 与查询特征 g_i 进行拼接,并送入解码器,从而实现基于正常模式的帧重构。
为了更新记忆项,计算每个记忆项与各个查询特征之间的权重,随后按照如下方式更新记忆项 p_n:
其中,v^{i,n} 是查询特征 g_i 与记忆项 p_n 之间的余弦相似度,f(\cdot) 表示L2范数函数。
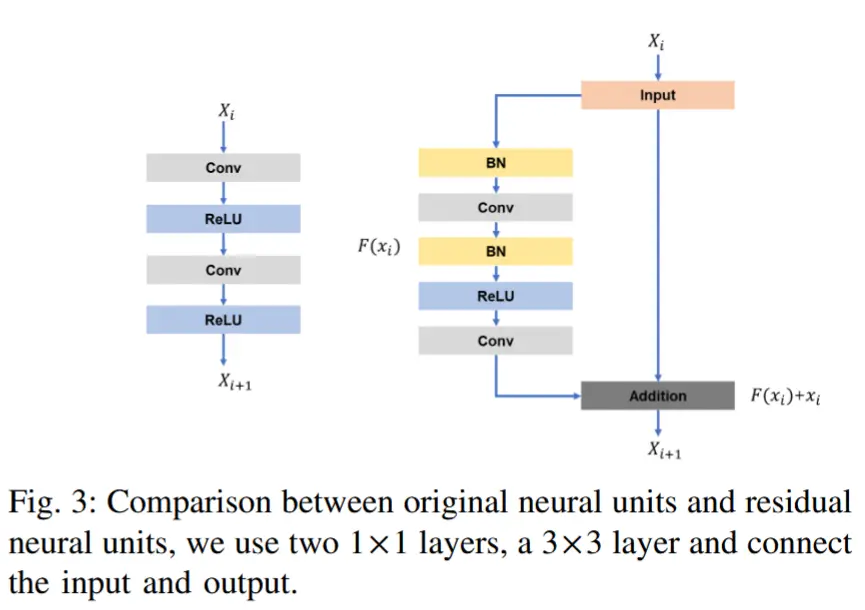
基于Res-Unet的自编码器。采用U-Net作为自编码器来重构视频帧,因为其可以通过特征拼接恢复边缘细节。然而,原始U-Net参数过多,难以实现快速推理,且随着网络深度增加可能引发梯度分散问题。受ResNet [31] 启发,我们将原始神经单元替换为残差神经单元。具体而言,残差单元由两个 1 \times 1 卷积层后接一个 3 \times 3 卷积层构成。此外,该结构连接了单元的输入和输出,能够在保持检测精度的同时降低计算成本。