- 论文 - 《Just Dance with π! A Poly-modal Inductor for Weakly-supervised Video Anomaly Detection》
- 代码 - 仓库关闭了
- 关键词 - CVPR' 25、弱监督视频异常检测WSVAD、多模态融合、视频异常检测VAD
很有意思的一篇论文,通过引入多种模态来增强RGB特征在复杂异常中的局限性。使用自编码器来生成多种伪模态,并使用现成的预训练模型来作为伪模态的真实标签进行训练,使得最终推理阶段不需要单独调用独立模态骨干网络。整个网络的核心就是 PMG 和 CMI 模块,一个负责生成伪模态特征,另一个负责对齐伪模态和RGB特征。最后的实验也非常完善,对于各模态的重要性做了验证和对比。
1 摘要
- insight
- 传统的弱监督视频异常检测(WSVAD)方法通常仅依赖RGB时空特征,而RGB特征在一些复杂的异常行为检测时区分能力不足。因此,必须引入额外模态来增强RGB时空特征。
- 多模态语义在WSVAD任务中的挑战:
- 数据稀缺且监督有限:异常检测任务的数据是稀疏且有限的,并且缺乏帧级标签,会导致跨模态关联模糊不清。
- 模态间差异性:由于每种模态在不同语义层级(从上下文到细粒度)捕捉独特特征,模态间存在内在差异,关联它们存在挑战。
- 推理开销增加:线性叠加多个模态将显著增加推理开销,阻碍实时应用。
- 本文方法 - π-VAD
- 提出一种新颖的“多模态诱导Transformer”用于弱监督视频异常检测,命名为 π-VAD。π-VAD从五种互补模态——姿态、深度、全景分割、光流和语言语义——中合成潜在嵌入,以增强并丰富基于RGB的分析。
- π-VAD包含两个可无缝集成至WSVAD框架的创新插件模块:
- 伪模态生成模块(PMG) 直接从RGB特征中生成各模态特有的合成原型嵌入,捕捉每种模态的独特特征。该方法通过避免推理阶段调用独立模态骨干网络,有效降低推理延迟,保持π-VAD运行效率。
- 跨模态诱导模块(CMI) 通过双重对齐过程,在统一的、以RGB为锚点的嵌入空间内对齐原本解耦的模态。首先,它通过对比对齐目标构建各模态与RGB之间的语义关联,确保多模态嵌入的协同融合;随后,CMI利用预训练的VAD模型引导对齐后的多模态表征,使其朝向统一的、任务感知且语义对齐的表示演进,确保所学对齐关系与异常检测任务高度相关。
- π-VAD是首个在WSVAD中全面利用多模态表征的框架,为视频分析中的复杂异常检测树立了全新范式。
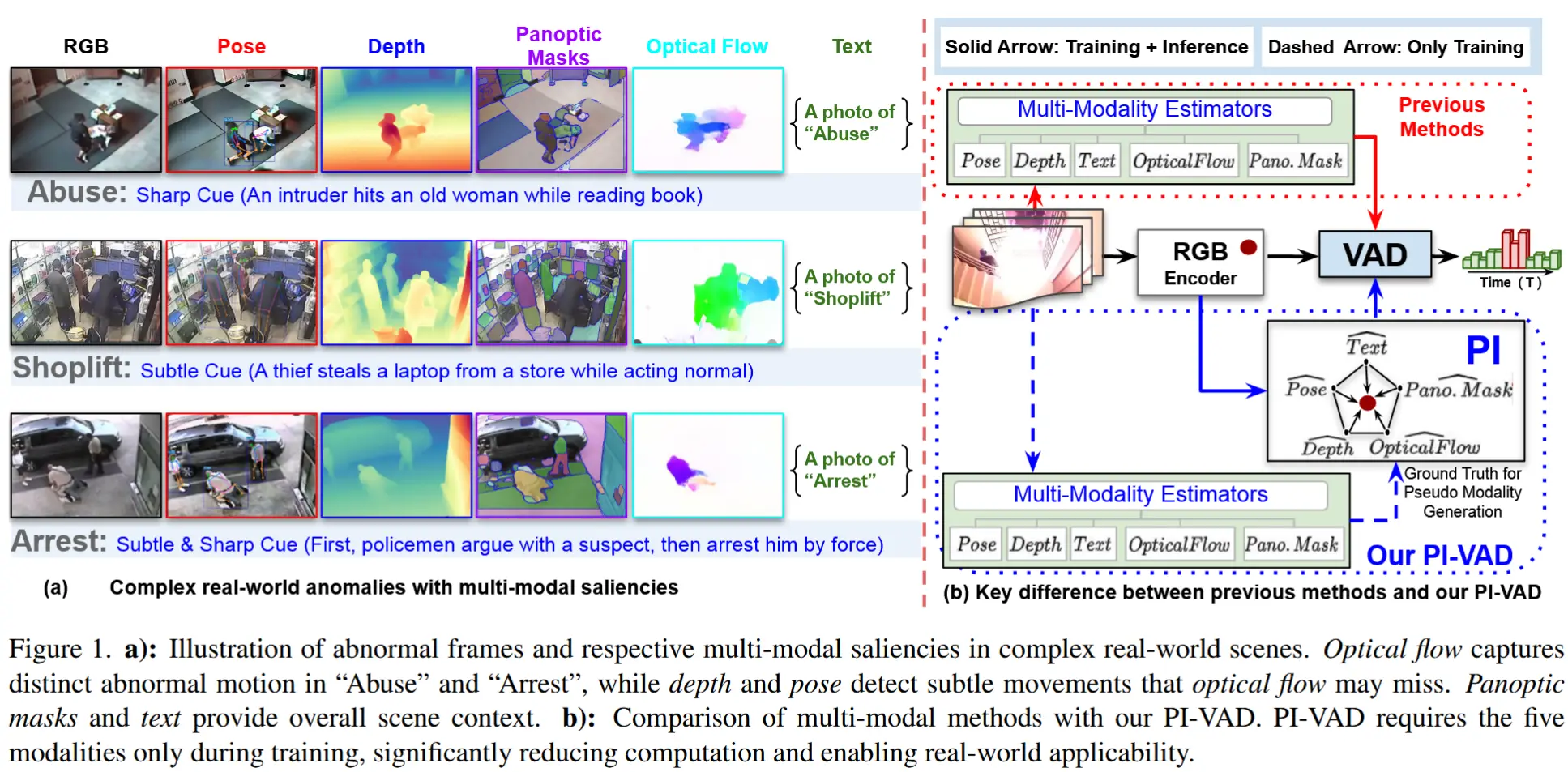
2 预备知识
- 单模态WSVAD
工作原理:视频 V 首先被划分为长度为16帧的非重叠片段,共得到 T 个片段。随后,使用预训练的三维卷积网络(例如 I3D )从每个片段中提取特征,形成特征图 \mathcal{F}_{RGB} \in \mathbb{R}^{T \times D} ,其中 D 表示特征维度。给定 \mathcal{F}_{RGB} ,单模态WSVAD方法的目标是训练一个RGB任务编码器,使其在仅能访问视频级标签的情况下,能够预测帧级别的异常分数。
- 多模态WSVAD
本文旨在探索在WSVAD任务中多模态表征学习的能力。尽管动作理解领域的多模态方法可以应用于WSVAD任务,但是其有效性取决于可用标注数据的数量。因此,本文提出一种新颖的多模态框架 π-VAD,该框架能够有效将超过五种模态与RGB关联,用于WSVAD任务。
- 与相近工作的区别
与本工作 π-VAD 最接近的先前研究是 π-ViT 。但是它们具有以下区别:
- π-ViT 和 π-VAD 均开创性地通过诱导机制将RGB与其他模态相结合,但 π-VAD 进一步拓展了这一边界,整合了超过五种模态。
- π-ViT 针对完全监督的动作识别任务进行优化,π-VAD 专为在数据和监督受限场景下的时序视频异常检测任务而设计。
- 为了在这些约束条件下实现鲁棒的多模态融合,π-VAD 将基于自编码器的表征与对比学习目标相结合,并采用引入蒸馏损失的教师-学生训练范式,从而确保跨模态之间具有更强的适应性与语义绑定能力。
3 π-VAD
π-VAD 结构如图2所示,采用一种教师-学生架构,并引入了一种新颖的多模态诱导器。尽管教师模型与学生模型具有相同的函数结构,但教师模型已在WSVAD任务上进行预训练并保持冻结,而学生模型则随机初始化。
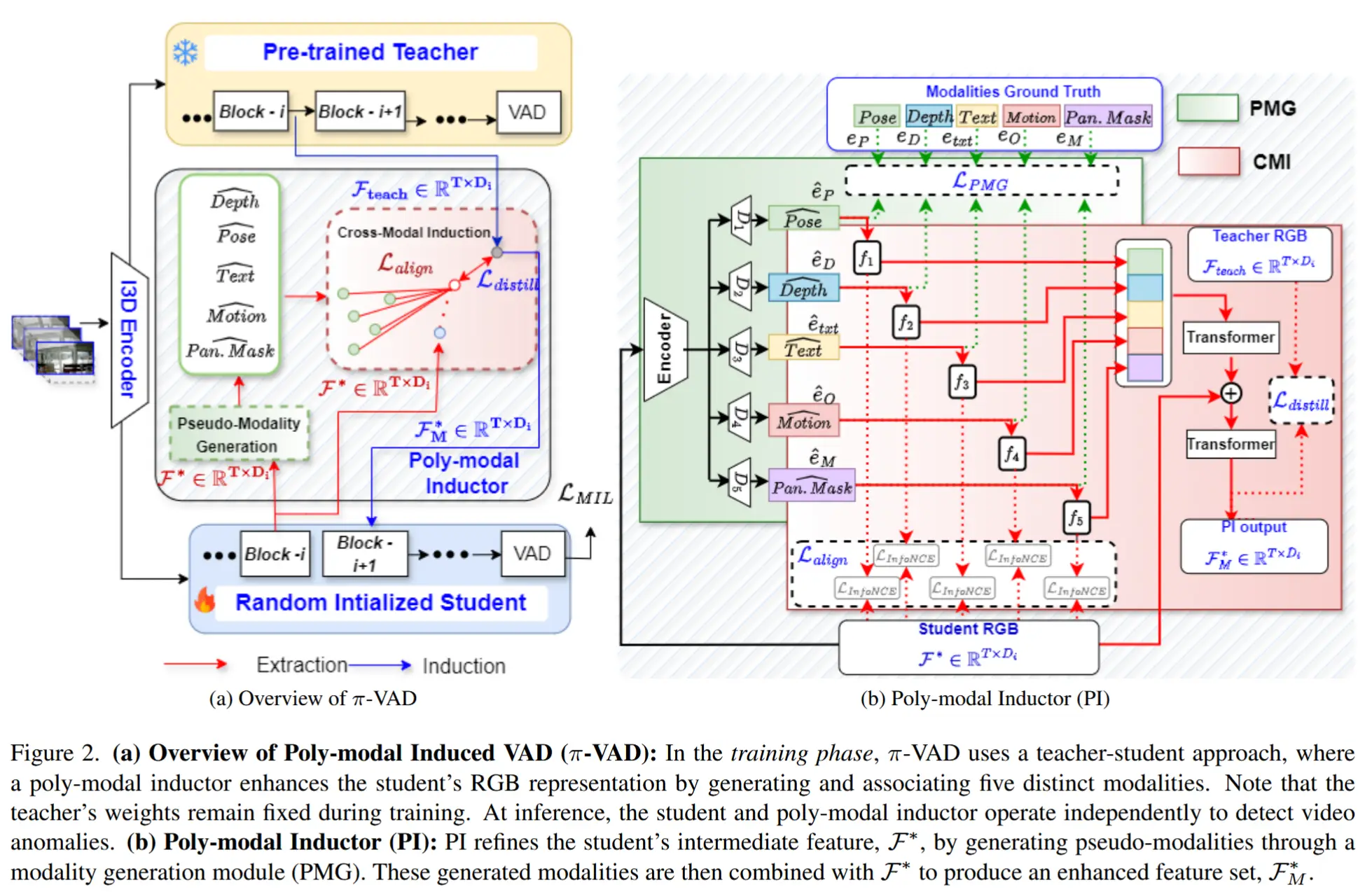
3.1 多模态诱导器
如图2(a)所示。多模态诱导器的目标是通过在一个统一的多模态特征空间中促进对异常事件判别性特征的学习,从而增强学生模型的RGB表征能力。
如图2(b)所示,多模态诱导器由两个核心模块实现:
- 伪模态生成(PMG)模块 学习实际模态成分的与异常相关的合成近似表示;
- 跨模态诱导(CMI)模块 促进PMG输出的多模态编码与学生模型RGB嵌入之间的语义对齐,同时确保该对齐过程与WSVAD任务相关。
3.2 伪模态生成模块
定义:PMG 模块旨在直接从学生模型的中间 RGB 特征表示中生成姿态、深度、全景掩码、光流和文本的嵌入表示。
两个关键目标:一是在推理阶段对多模态骨干网络的依赖;二是该方法能够有选择地保留仅对WSVAD任务至关重要的多模态线索,缓解引入冗余、噪声甚至冲突信息。
实现:PMG 包含一个编码器和五个并行的解码器。
- 作者有意保留一个共享编码器,用于学习所有模态共有的RGB特征。六个解码器以互斥方式运行,分别生成六种模态的输出。
- 编码器包含一个一维卷积层,用于将RGB嵌入投影到低维潜在空间中。
- 对于每个模态解码器,一个单线性层将RGB潜在表示转换为特定模态的RGB表示,同时保持潜在空间的维度。通过这种方式,从相同的RGB嵌入中生成多个视角,增强与特定模态相关的信息,同时抑制可能的噪声。
- 随后,使用一个一维卷积层作为解码器,生成模态嵌入 \hat{e}_j ,其中 j \in \{P, D, M, O, txt\} 。
- PMG 解码器训练方法:利用YOLOv7-pose、DepthAnythingV2、SAM、RAFT 和 VifiCLIP 的中间嵌入表示,分别作为姿态、深度、全景掩码、光流和文本模态的真实标签。PMG的联合训练目标由这些模态的重建损失构成,以确保生成的伪模态嵌入尽可能接近真实模态信息。
3.3 跨模态诱导模块
定义:CMI 模块旨在将生成的伪模态嵌入与RGB嵌入进行融合,构建一个共享的表征空间,以促进任务相关的所有关键特征。
目标:确保对片段 T_i 最相关的模态能够与RGB嵌入在统一的表征空间中收敛,从而增强多模态之间的关联性。
实现:
-
对片段级的每个伪模态嵌入与RGB嵌入之间应用双向InfoNCE对比损失。
-
双向方法提供了正负样本对之间更均衡的相似度度量。将来自同一片段的嵌入视为正样本对,而不同片段的嵌入视为负样本对。
-
嵌入之间的相似度、对比损失定义如下:
\text{sim}(\mathcal{F}^*(T_i), \hat{e}_j(T_i)) = \frac{\mathcal{F}^*(T_i) \cdot \hat{e}_j(T_i)}{\|\mathcal{F}^*(T_i)\| \|\hat{e}_j(T_i)\|}\mathcal{L}_{\text{InfoNCE}} = -\frac{1}{T} \sum_{i=1}^{T} \log \frac{\exp\left(\frac{\text{sim}(\mathcal{F}^*(T_i), \hat{e}_j(T_i))}{\tau}\right)}{\sum_{k=1, k \ne i}^{T} \exp\left(\frac{\text{sim}(\mathcal{F}^*(T_i), \hat{e}_j(T_k))}{\tau}\right)} \quad (2)\mathcal{L}_{\text{align}} = \sum_{i=1}^{5} \mathcal{L}_{\text{InfoNCE}}, \quad i \in \{P, D, M, O, \text{txt}\} \quad (3)
-
-
接下来,识别并优先处理每个片段中最相关的模态,通过减少跨模态冲突和噪声,生成面向任务的多模态嵌入。
- 首先,将每种模态对齐后的嵌入在嵌入维度上进行拼接。
- 然后,使用一连串Transformer块来显式编码它们之间的交叉相关性,从而突出最相关的模态。此外,在Transformer块之间加入学生模型输出的RGB嵌入 \mathcal{F}^* ,以利用来自多种模态的上下文相关信息,增强RGB表征。
- 其次,引导最后一个Transformer块输出的最终多模态结果 \mathcal{F}_M^* \in \mathbb{R}^{T \times D_i} ,使其趋近于针对WSVAD任务的特定表征(即教师模型输出的特征)。这一过程通过蒸馏机制实现,其目标是最小化 \mathcal{F}_M^* 与教师模型在同一阶段的预训练特征 \mathcal{F}_{\text{teach}} \in \mathbb{R}^{T \times D_i} 之间的差异。指导该最小化的蒸馏损失定义为:
\mathcal{L}_{\text{distill}} = \frac{1}{D_i} \sum_{k=1}^{D_i} (\mathcal{F}_{Mk}^* - \mathcal{F}_{\text{teach},k})^2. \quad (4)
3.4 π-VAD 优化
π-VAD 的优化分为两个阶段。
在第一阶段,学生模型、PMG 模块和 CMI 模块分别通过损失函数 \mathcal{L}_{PMG} 、 \mathcal{L}_{align} 和 \mathcal{L}_{distill} 进行预热训练。第一阶段的损失函数为:
在第二阶段,模型在WSVAD任务上进行训练,使用UR-DMU [41] 中标准的多示例学习(MIL)损失函数。为了避免对齐后的多模态信息在训练过程中发生解耦,最终的训练目标定义为:
其中, \lambda_1 和 \lambda_2 是超参数,用于调节蒸馏与对齐组件在训练过程中的影响权重,以实现训练过程的平衡。值得注意的是, \mathcal{L}_{PMG} 不经过缩放因子平衡,以确保在整个训练过程中生成的伪模态始终与真实模态保持一致,防止其偏离真实模态分布。
4 实验
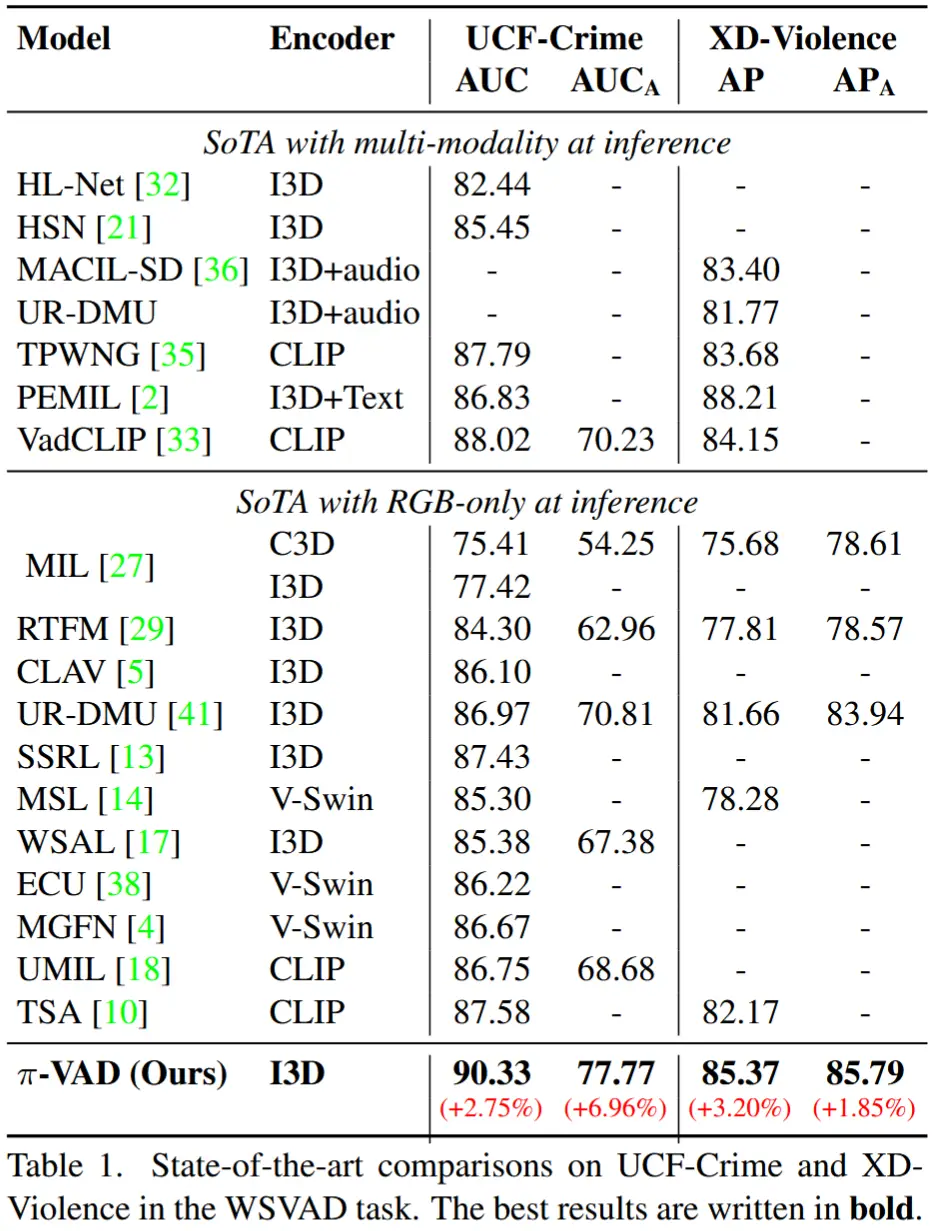
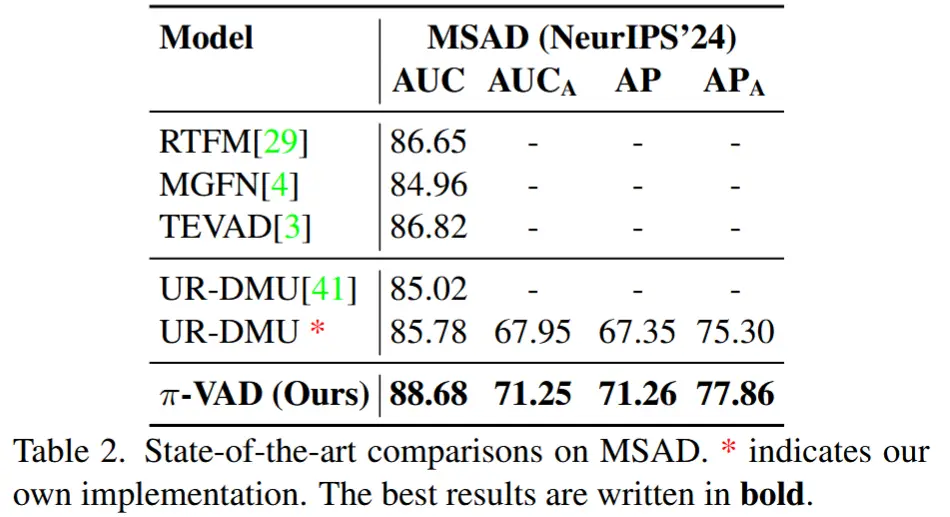
- 在UCF-Crime、XD-Violence、MSAD数据集上的性能比较
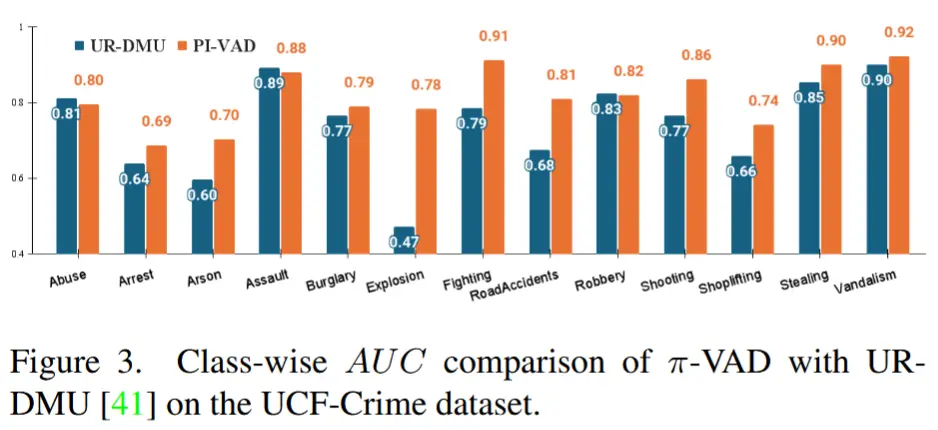
- π-VAD 与作为教师模型的基线方法(即 UR-DMU)在各类别上的性能对比。
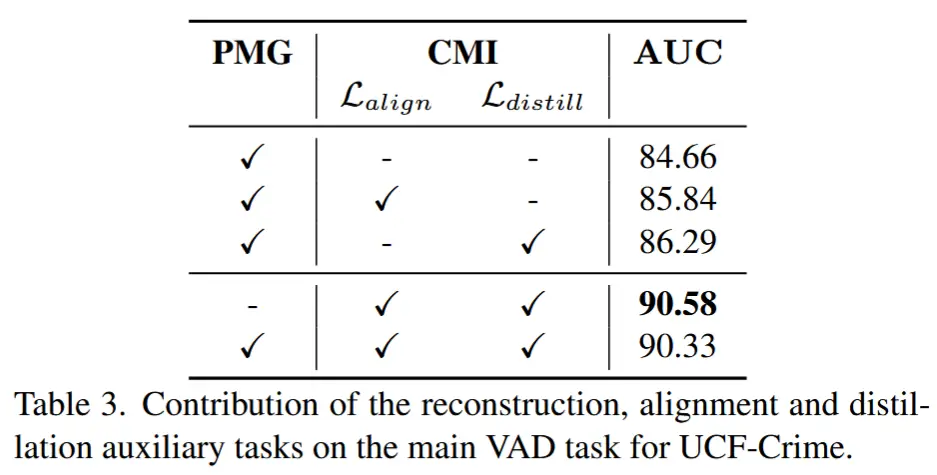
- 各组件消融实验
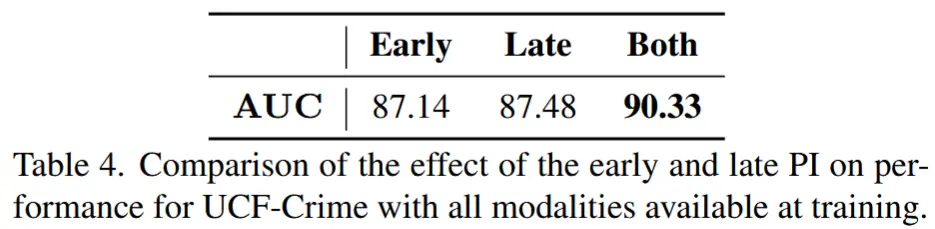
- 多模态诱导器PI的时期消融
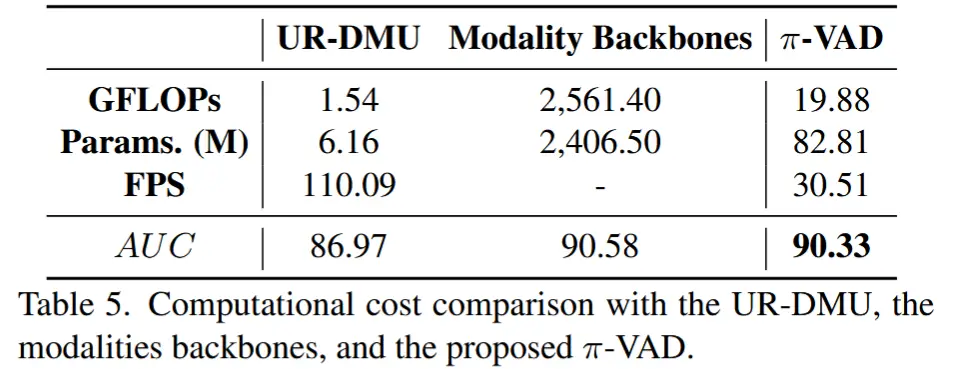
- 计算开销与性能之间的权衡关系
- 尽管 π-VAD 相比纯RGB基线方法需要更多的计算与内存资源,但其仍可实现实时推理性能——处理速度达每秒30帧,使其具备实际部署的可行性。
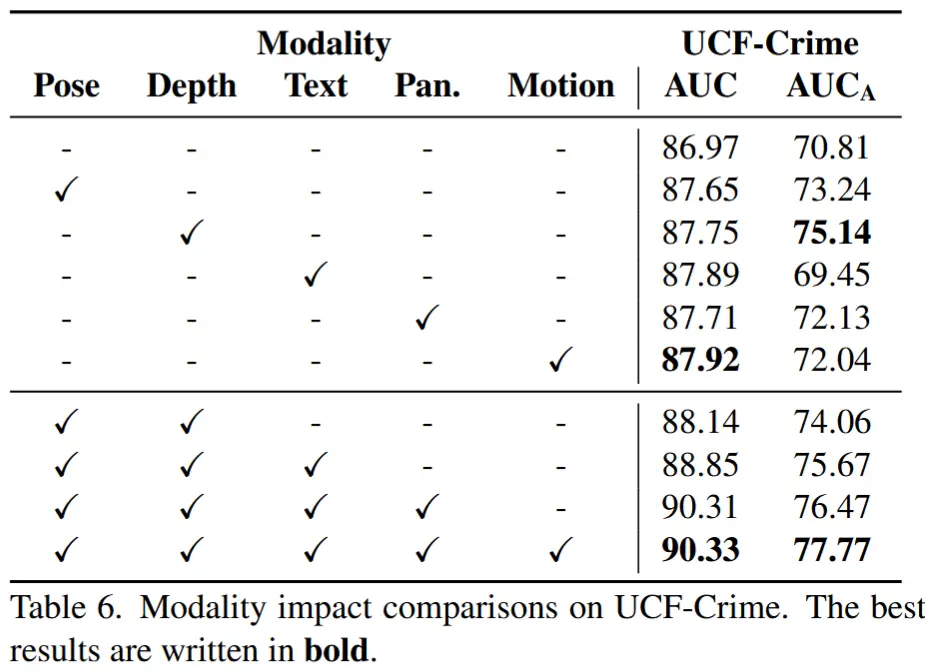
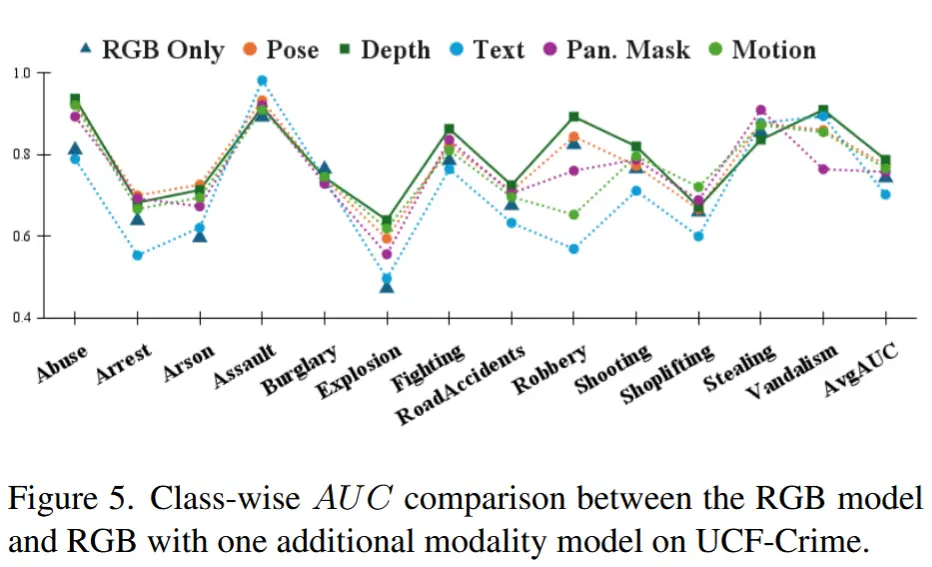
- 各模态重要性评估