- 论文 - 《AnyAnomaly: Zero-Shot Customizable Video Anomaly Detection with LVLM》
- 代码 - Github
- 关键词 - 关键帧采样、无需微调/训练、零样本、视频异常检测、视觉语言模型VLM
这篇论文主要是利用VLM的通用泛化能力来实现零样本视频异常检测,并且提出了一种可定制视频异常检测的能力,即用户可以通过文本来自定义异常类别或事件。动机非常简单,方法和动机的联系相对较弱,方法上主要目标是提高VLM的异常检测能力,并且保持无需训练的特性。
1 引言
-
现有工作局限性:现有VAD模型难以适应多样化的环境,在面对新环境时,往往需要重新训练模型或开发独立的AI模型。
-
动机:可以利用大模型的泛化能力,实现零样本的VAD。
-
新技术:“可定制视频异常检测”(C-VAD)将用户自定义的文本视为异常事件,并在视频中检测包含这些事件的帧。这意味着,随着视觉-文本分析泛化能力的提升,异常检测在各种环境中的效果也将随之增强。
-
使用 VLM 是实现零样本C-VAD的有效途径。然而,简单的向模型提供prompt进行异常检测存在以下局限性:
- 由于大型视觉语言模型(LVLM)计算开销巨大,导致推理延迟高;
- 受限于监控视频的特性(如前景-背景不平衡、物体密集拥挤),难以精准分析特定目标;
- 因无法利用时序信息,难以检测与动作相关的异常事件。
-
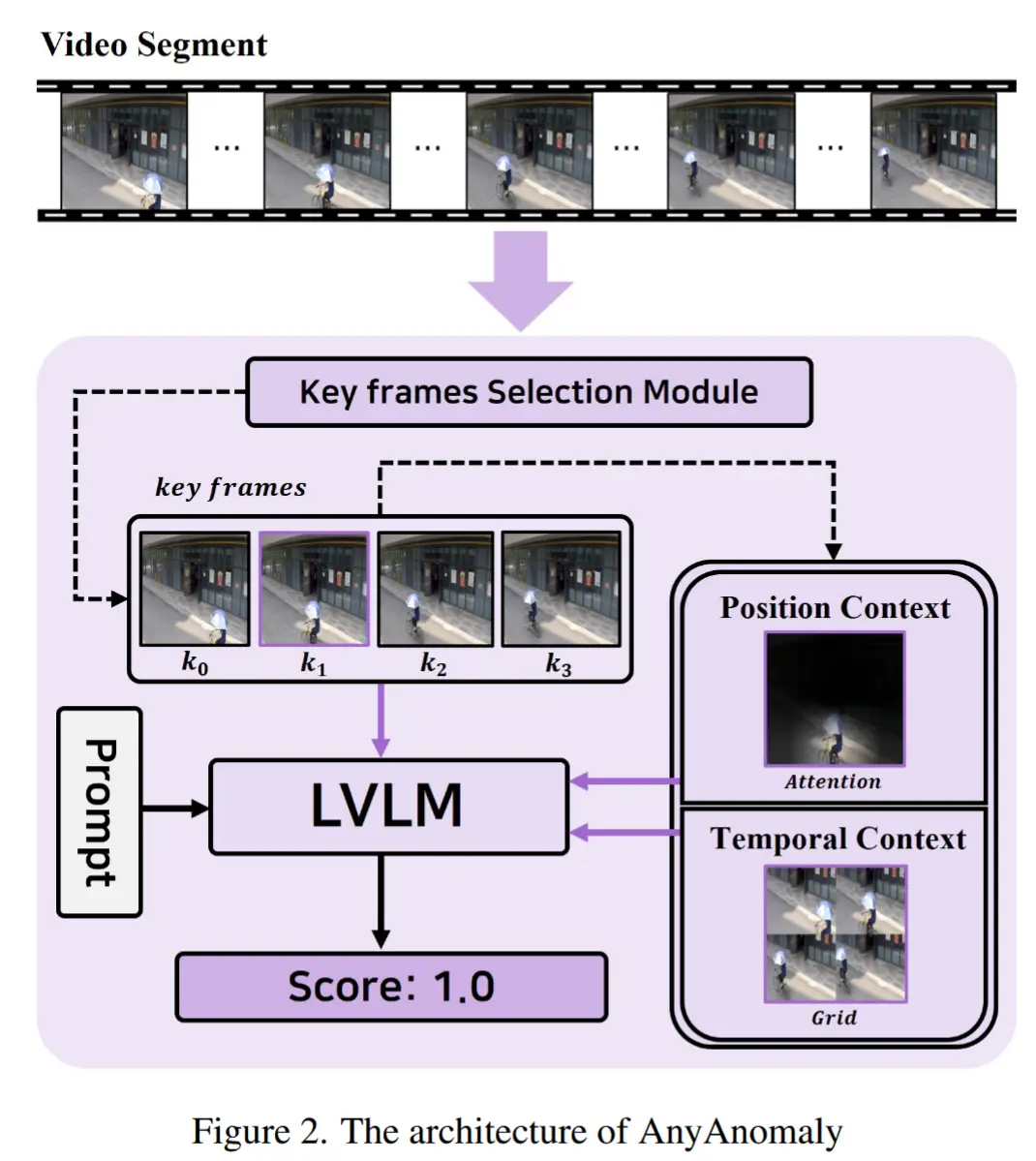
为克服上述局限性,作者设计了如图2所示结构的 AnyAnomaly 模型。
- 首先,为降低延迟,采用片段级处理方法,将连续帧聚合成单个片段进行处理。为此,我们引入了一个关键帧选择模块(KSM),用于从每个片段中挑选最具代表性的关键帧,并在片段级别执行视觉问答。
- 其次,摒弃了简单的图像-文本匹配方式,转而提出一种上下文感知的VQA方法,以实现对场景更深层次的理解。为此,作者额外引入了两种上下文信息:
- 位置上下文(PC):PC 通过强调帧内重要区域,增强LVLM对特定目标的分析能力。
- 时序上下文(TC):TC 将场景随时间的变化结构化为网格形式,从而提升LVLM对动作类异常的识别能力。
- 值得注意的是,KSM模块与上下文生成模块均无需训练,可直接部署,从而轻松实现C-VAD,无需额外数据或模型微调。
2 方法
2.1 概述
图2展示了AnyAnomaly模型的结构,该模型执行上下文感知的视觉问答(VQA)。
处理流程:
- 输入一段包含 N 帧的视频片段 S,关键帧选择模块(KSM)从 S 中选出一组关键帧 K = \{k_0, \ldots, k_3\} 。
- 在所选的关键帧中,最具代表性的帧 \hat{k} 用于生成位置上下文(PC),而整个关键帧集合 K 则用于构建时序上下文(TC)。
- 随后, \hat{k} 、PC 和 TC 被作为图像输入提供给 LVLM ,用户提供的文本 X 则与 prompt 结合,作为文本输入。
- 最终,LVLM 的响应结果被整合,用于计算异常得分。
用户定义的文本 X 是用户希望检测的异常事件的自然语言描述。它可以是一个单词、多种事件或复杂行为。对于多事件情况,每个事件关键词将被单独处理,视为一个独立的单词。
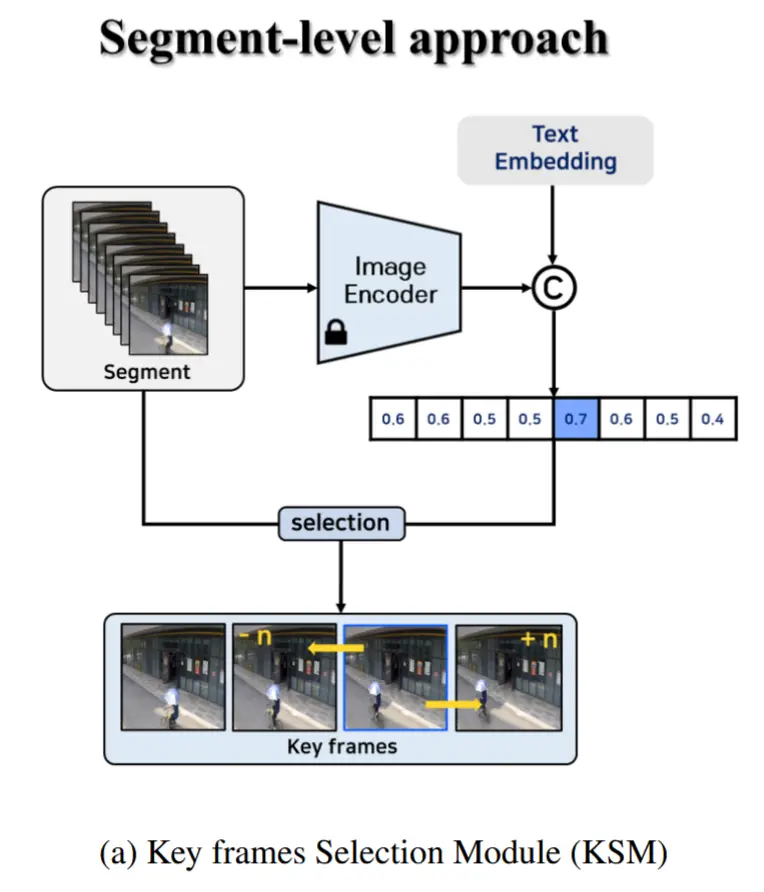
2.2. 关键帧选择模块
图3a展示了KSM,使用预训练的 CLIP 模型选取了四个能代表该视频片段的帧作为集合 K 。
具体而言,视频片段 S 和用户文本 X 分别输入到图像编码器 E_I 和文本编码器 E_T ,通过计算 N 个图像嵌入向量与文本嵌入向量之间的点积来获得相似度。相似度最高的帧被选为最具代表性的帧 \hat{k} :
代表性帧 \hat{k} 的索引,记作 \hat{i} ,用于选择其他关键帧。将视频片段划分为四个等大小的组,并从每组中选取第 \hat{i} \mod \frac{N}{4} 帧。例如,当 N=8 且 \hat{i}=4 时,每组的第0帧被选中,最终得到的关键帧集合为 K = \{s_0, s_2, s_4, s_6\} 。该过程定义如下:
通过KSM,集合 K 的生成综合考虑了文本对齐性和时间均匀性,从而有效支持上下文信息的构建。
2.3. 上下文生成
核心思想:上下文分为PC(位置上下文)和 TC(时序上下文)。其中:
- PC 通过基于 WinCLIP 的注意力机制(WA) 生成,用于提升大型视觉语言模型(LVLM)对目标的分析能力;
- TC 通过网格图像生成(GIG) 方法构建,增强 LVLM 对动作行为的分析能力。
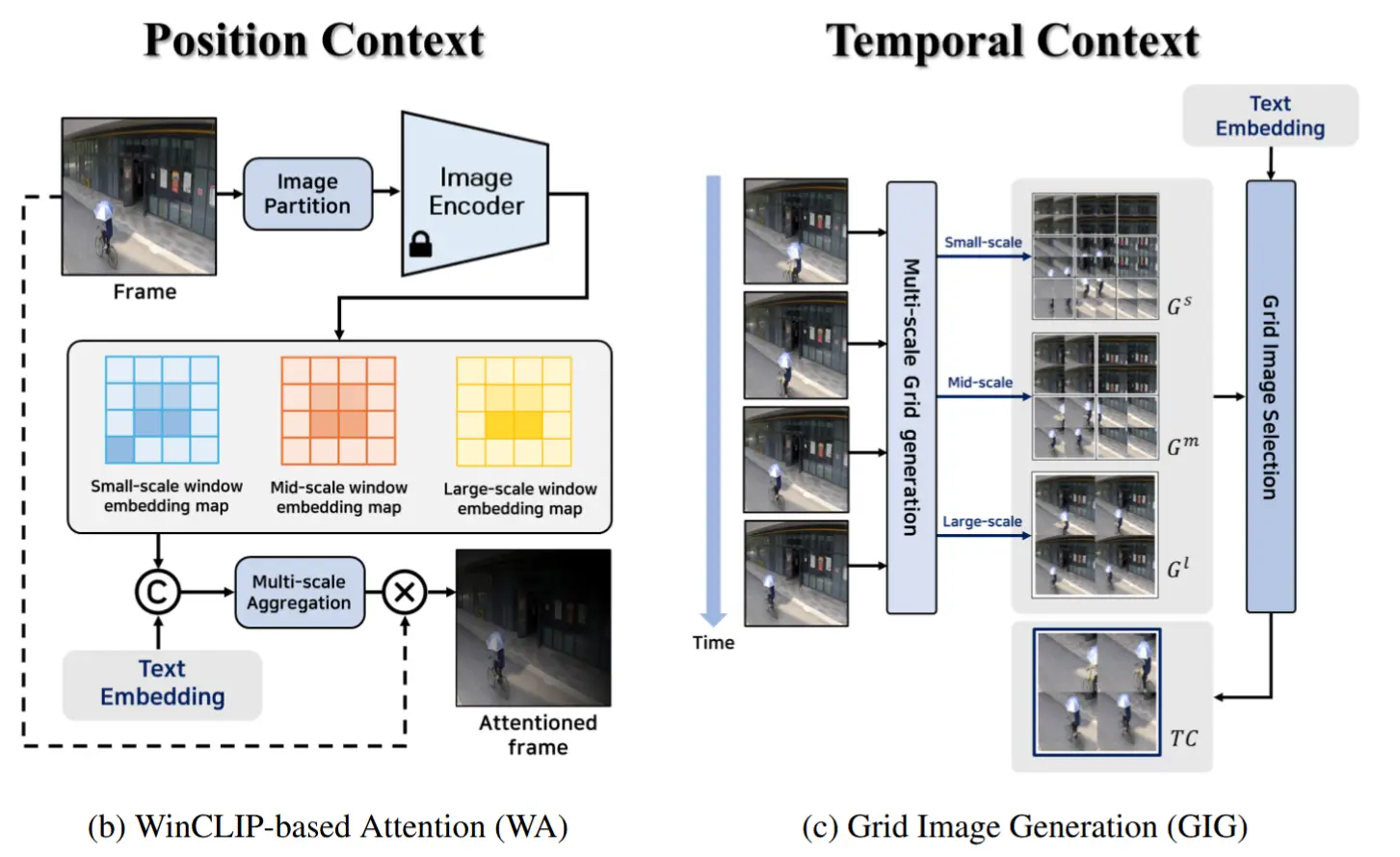
2.3.1 WinCLIP-based Attention
WA 方法借鉴 Jeong [12] 提出的 WinCLIP 技术,用于突出代表性帧 \hat{k} 中与用户文本 X 相关的区域。首先,将 \hat{k} 划分为多个窗口,并使用图像编码器 E_I 为每个窗口生成独立的嵌入向量。通过调整窗口大小,所有窗口的嵌入向量被收集形成一个小尺度窗口嵌入图 W^s 、中尺度窗口嵌入图 W^m 和大尺度窗口嵌入图 W^l ,并分别计算这些嵌入图与文本嵌入 z \in \mathbb{R}^D 之间的相似度。最终的相似度图 M 是通过对三个尺度上的相似度进行平均得到:
将 Jeong [12] 提出的模板与用户文本 X 进行结合,并通过文本编码器 E_T 生成文本嵌入 z 。最后,将相似度图 M 与原始图像 \hat{k} 相乘,生成位置上下文 PC:
其中, f_{\text{norm}} 表示最小-最大归一化, \odot 表示逐元素相乘。在插值和重整形后, M 被调整至与 \hat{k} 相同的分辨率。由于 PC 集成了多尺度的相似性信息,因此对物体大小和位置具有鲁棒性,即使在包含多个物体的复杂场景中也能有效工作。
2.3.2 Grid Image Generation
图3c 展示了 GIG 方法,其包含两个阶段。
在多尺度网格生成阶段,关键帧集合 K 用于在不同尺度上生成网格图像。类似于 WA 中的过程, K 中的每一帧被划分为多个窗口,相同位置的窗口以 2\times2 的网格格式连接,生成单个网格图像。该过程定义如下:
其中, u_j^i 表示从 k_j 生成的第 i 个窗口, g^i 表示第 i 个网格图像。我们分别定义小、中、大尺度窗口生成的网格图像集合为 G^s 、 G^m 和 G^l 。
在网格图像选择阶段,上述生成的集合被聚合为一个整体集合 G^{all} :
随后,采用与KSM中相同的方法(即基于文本相似度),从 G^{all} 中选择与用户文本 X 最相似的网格图像作为时序上下文 TC:
通过该过程生成的 TC 反映了同一背景下的物体随时间的运动轨迹,有利于动作分析,并对不同大小的物体具有鲁棒性。
2.4. 异常检测
我们并未对大型视觉语言模型(LVLM)进行微调,而是提出了一种新的提示(prompt)和上下文机制,以实现上下文感知的视觉问答(VQA)。VQA 的输出结果被用作异常得分,从而实现无需训练的零样本异常检测。
2.4.1 提示设计
图4展示了所提出的提示 P 。该提示包含三个主要部分:
- “task”定义了LVLM应执行的操作,即判断用户提供的文本 X 是否出现在图像中。
- “consideration”指明了在评估过程中需要考虑的因素;
- “output”则规定了评估结果的呈现格式。
为了利用思维链(CoT)的效果,作者要求模型在返回异常得分的同时提供简要推理过程,并将得分保留一位小数。当使用TC进行VQA时,在“task”与“consideration”之间插入一个额外元素——“context”,向LVLM传达TC中行与列的语义信息。

2.4.2 异常评分
然而,由于LVLM仅接受单张图像作为输入,同时利用原始图像和附加信息存在挑战。为解决这一问题,作者采用 后融合(late fusion) 策略。具体而言, \hat{k} 、PC 和 TC 分别作为图像输入送入LVLM,LVLM为每个输入返回一个异常得分,这三个得分通过加权融合计算最终的异常得分 ascore :
其中, \gamma 是超参数,用于调节各上下文信息在最终得分中的占比。
最后,为了生成帧级异常得分,将每个片段的 ascore 复制至该片段长度,并应用一维高斯滤波器进行时间平滑处理。
3 实验
3.1 实验设置
- 数据集
- 三个传统VAD数据集:CUHK Avenue(Ave)、ShanghaiTech Campus(ShT)、UBnormal(UB)
- 作者在其他数据集基础上自建的C-VAD数据集:Customizable-ShT(C-ShT)、Customizable-Ave(C-Ave)
- 评估指标:micro AUROC
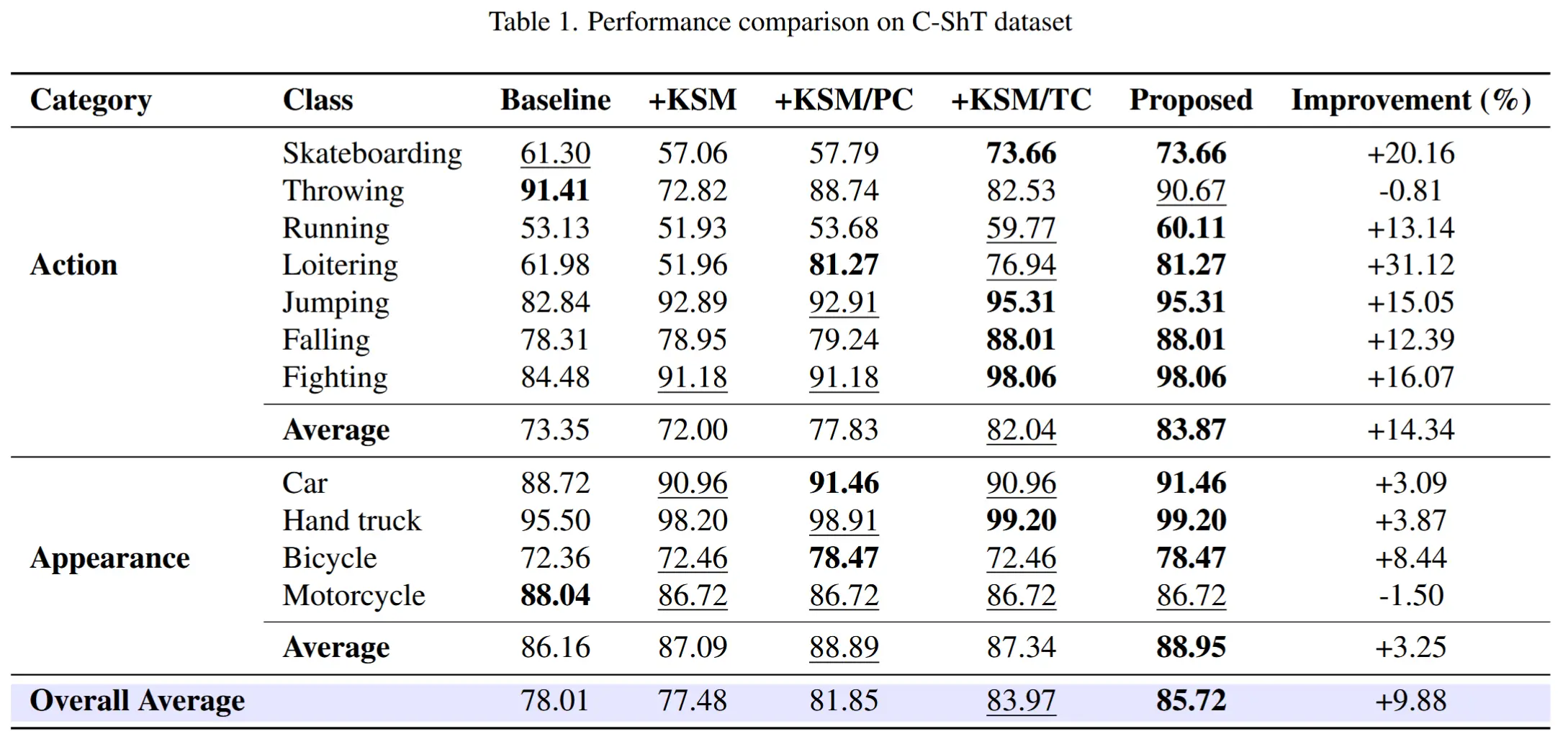
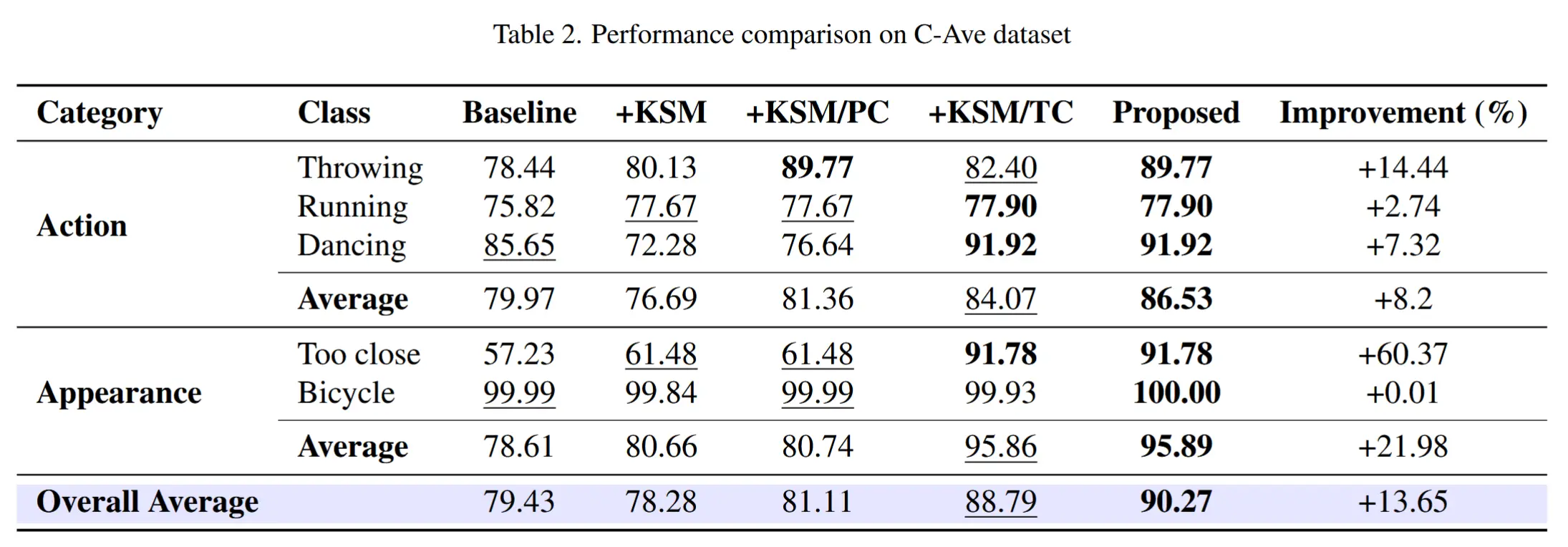
3.2 实验结果
- 表1和表2展示了在C-VAD数据集上的评估结果。
- 作者按照异常类别分成了“动作类”和“外观类”两种异常,并分别进行了实验。
- 作者还进行了消融实验,分别对KSM和两个上下文(PC TC)进行消融,
- 结论:
- 所提模型在C-ShT和C-Ave数据集上分别实现了9.88%和13.65%的性能提升。
- 仅引入位置上下文(PC)后,相比仅使用KSM,性能分别提升5.64%和3.62%,这是因为LVLM能聚焦于与用户文本X相关的物体进行分析;
- 引入时序上下文(TC)后,相比仅使用KSM,性能分别提升8.38%和14.43%,尤其在“动作类”异常上提升显著,表明网格图像中提供的时序信息对于动作分析至关重要。
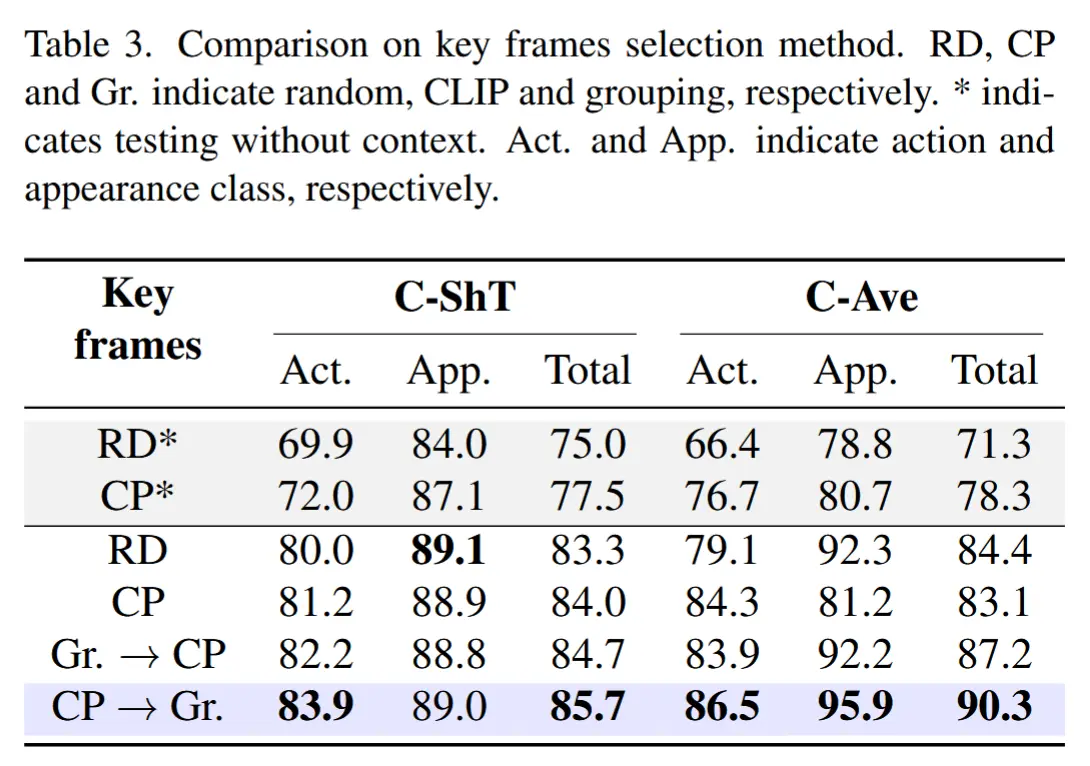
- 消融-关键帧选择
- 三种变体:RD(随机选择)、CP(基于CLIP的帧选择,仅考虑文本对齐)、GR(分组)(这里可以分为先分组再用CLIP选择、先CLIP选择再分组)。此外,RD* 和 CP* 方法未使用上下文信息。
- 结论:先用CLIP筛选后再进行分组,可使关键帧在时间上分布均匀,同时兼顾文本对齐与时间均匀性。
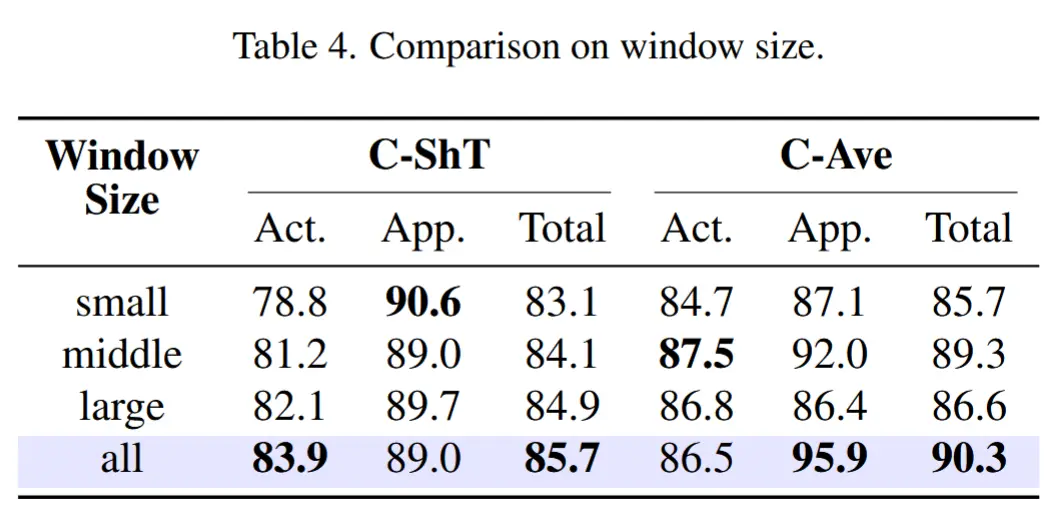
- 表4展示了在PC和TC中采用不同窗口大小的实验结果
- 对于动作类异常,在C-ShT数据集上大窗口表现最优,在C-Ave数据集上中等窗口表现最佳。
- 对于外观类异常,C-ShT数据集以小窗口效果最好,而C-Ave数据集以中等窗口最优。
- 融合三种尺度窗口的方法取得了整体最优性能。
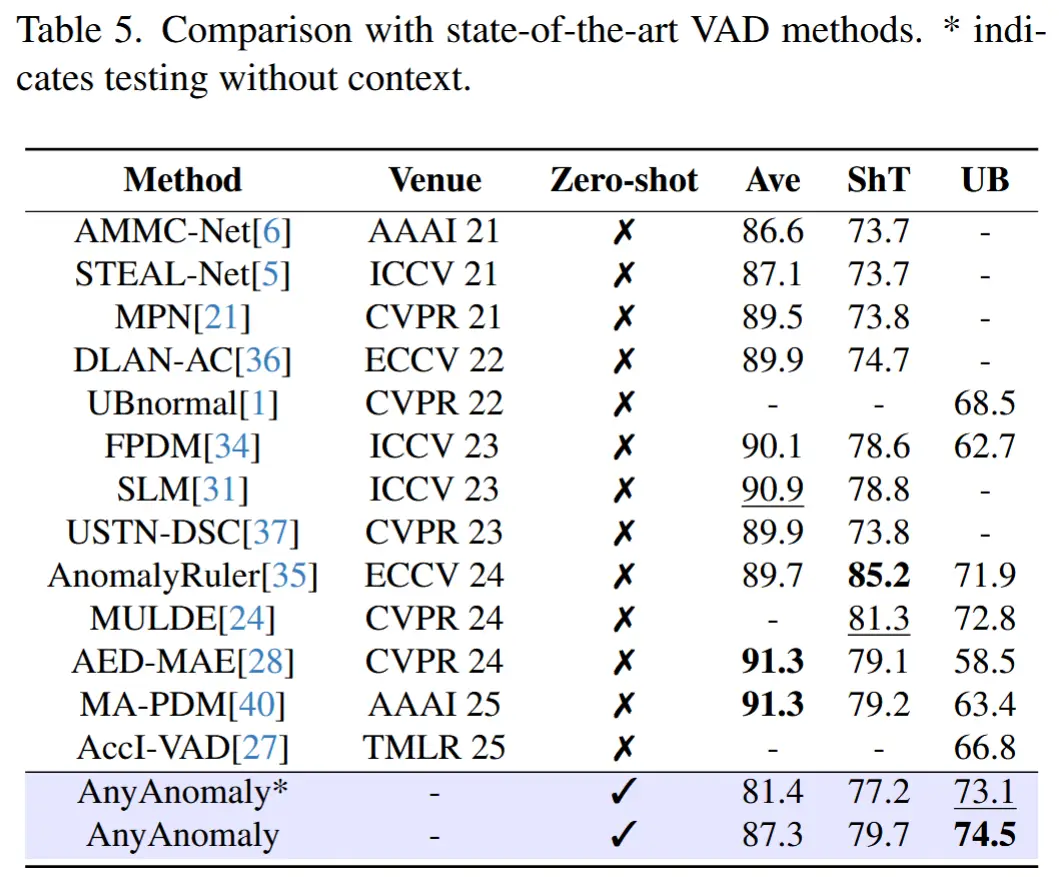
- 表5展示了与传统VAD的SOTA方法进行性能对比
- 尽管AnyAnomaly未在任何VAD数据集上进行训练,其性能仍可与当前最优方法相媲美。
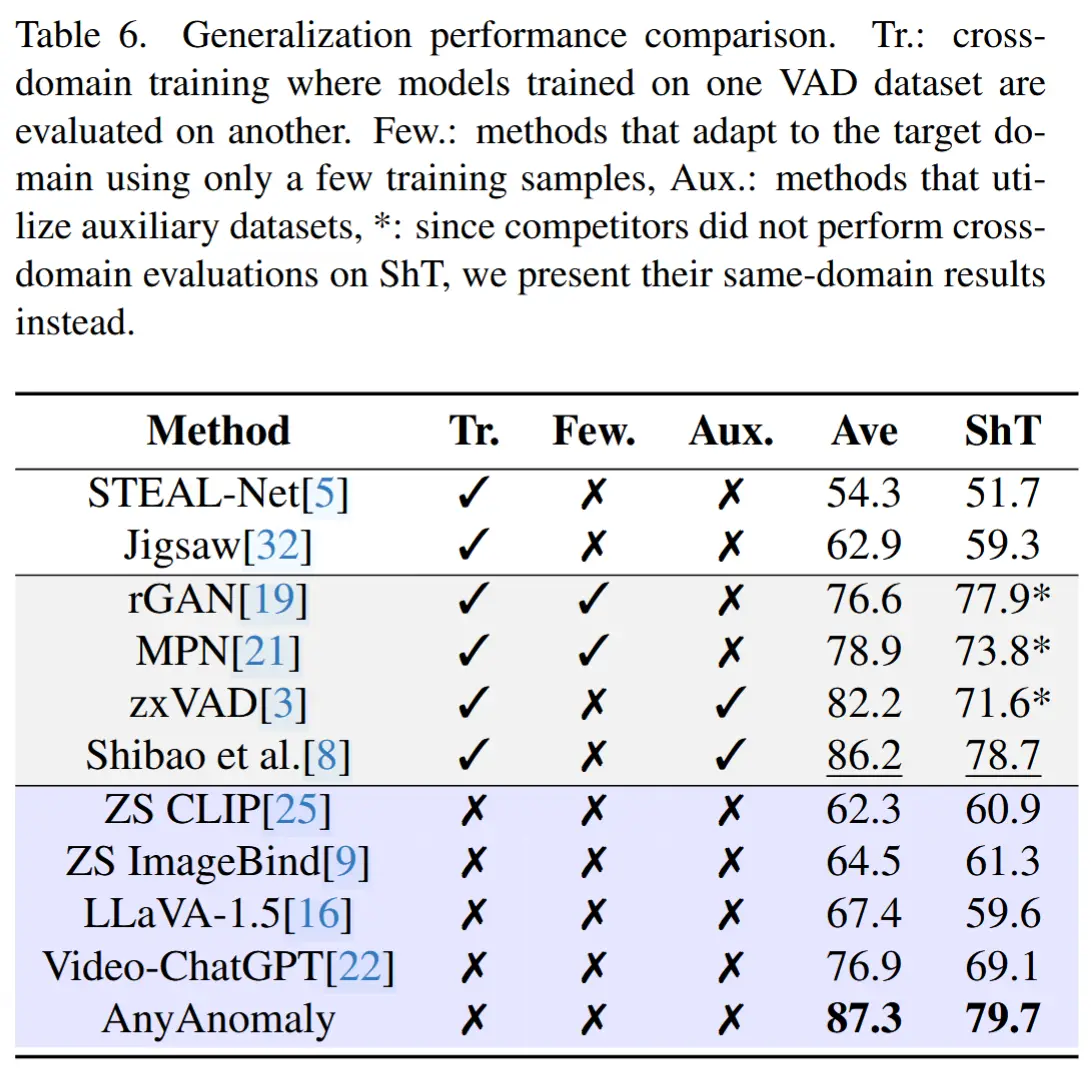
- 表7展示了泛化性能对比