- 论文 - 《SpotVLM: Cloud-edge Collaborative Real-time VLM based on Context Transfer》
- 关键词 - 云边协同、视觉-语言大模型VLM、文本上下文、视觉聚焦、大小模型混合、实时视频
这篇介绍了一种新的大小模型协同方式,大模型通过更强的文本生成和视觉编码能力,可以指导小模型的后续生成。这与以往的云边协同、大小模型协同方式都不一样,idea 挺眼前一亮的。大模型通过生成文本,进行压缩后作为上下文添加进小模型的prompt中。同时大模型的目标检测结果作为ROIs可以引导小模型关注更重要的图像patch
1 引言
缩写:Small VLM(SVLM);Large VLM(LVLM)
-
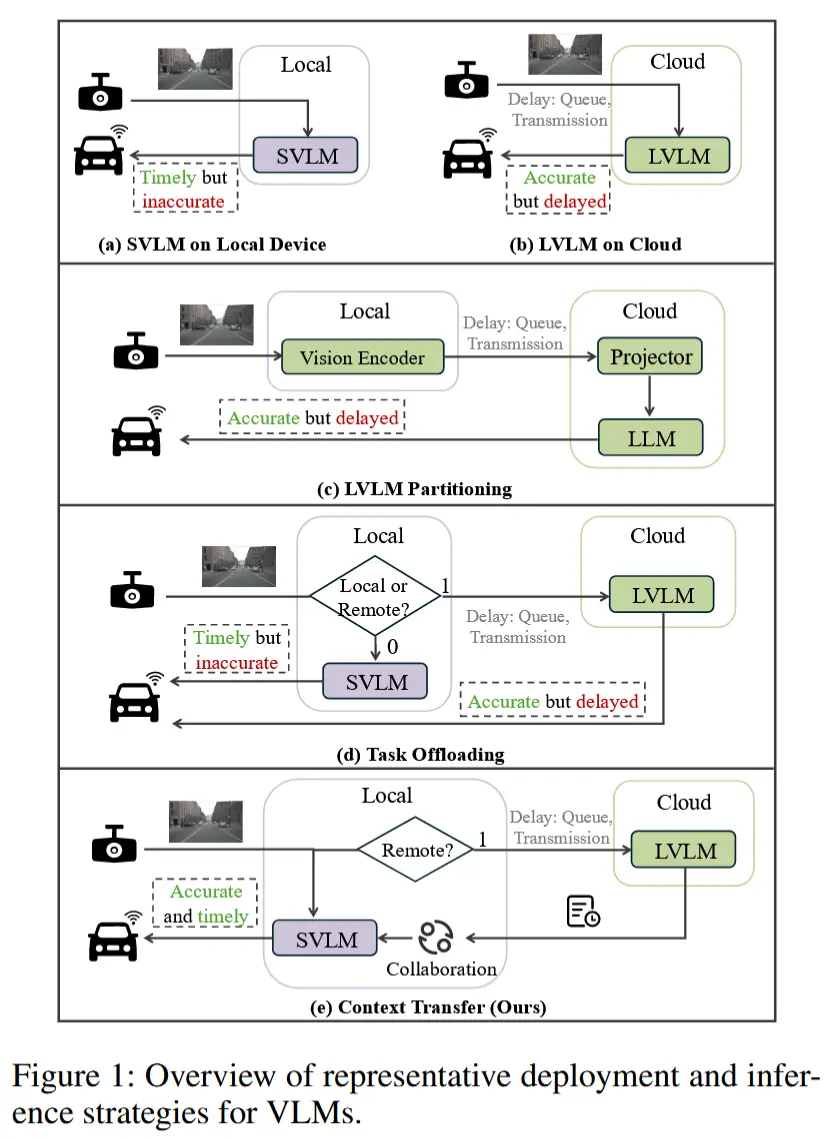
研究背景:VLM正日益应用于自动驾驶、人机交互等实时场景,这些应用要求系统能够基于精准感知提供快速可靠的响应。为此,现有工作通常采用云边协同架构,主要分为两类:
- 模型分割:依据硬件约束将 LVLM 拆分部署于云端与边缘。例如,Distributed VLM(Li 等,2025b)将视觉编码器置于边缘,提取特征后上传至云端,再与文本信息融合并由大语言模型(LLM)进行处理;
- 动态任务卸载:根据任务复杂度与系统状态决定是否将输入路由至云端进行 LVLM 推理。例如,ADAS(Hu 等,2024b)综合考虑延迟与服务质量(QoS)等因素,仅在必要时将任务卸载至云端。
-
现有工作局限:这些方法未能有效应对云端延迟波动(例如网络波动导致的累计延迟),也忽视了延迟但高精度的LVLM输出所蕴含的巨大潜力。
-
分析LVLM和SVLM性能差距的根源,得出核心观察:
- 高质量文本上下文的利用:历史上下文在生成高质量输出中起着关键作用。例如,Qwen-VL在多轮交互中采用累计输入结构(前一轮的输入与响应+当前查询),直至达到最大长度。这种机制使模型能够跨轮次整合信息,增强语义一致性与推理深度,并且形成一个性能增强的反馈闭环。而小模型虽然也采用类似的策略,但是生成能力有限、历史内容质量较低。
- 语义显著图像区域的视觉定位:SVLMs 在视觉内容与文本描述对齐方面较弱,尤其是在处理细粒度语义或复杂场景时尤为明显。先前研究表明,LVLMs 可自动裁剪出语义丰富的图像区域作为精炼输入,从而提升视觉推理的关注焦点与语义可解释性。引导小模型聚焦于任务相关的图像区域,有助于其更好理解复杂的视觉与语言线索,最终提升推理性能。
-
本文工作
- 提出“上下文迁移”范式:将 Large VLM(LVLM) 的延迟输出视为历史上下文,用以实时引导 Small VLM(SVLM) 的推理过程。
- 设计“上下文替换”模块:从高质量LVLM响应中提取关键文本片段,根据当前任务上下文重组并嵌入为新的历史上下文,以替代原始低质量的历史记录。这些富含信息的示例隐式引导小模型关注此前忽略的语义相关视觉线索,从而增强跨模态关联与推理能力。
- 引入“视觉聚焦”模块 VFM:该模块基于LVLM的历史预测结果,识别语义显著的图像区域,并用于指导SVLM:通过掩码去除无关图像块以减少视觉token数量、提升效率,同时将注意力集中于关键区域以强化视觉-语言对齐。为实现动态视觉聚焦,边缘设备在历史帧与当前帧间执行特征匹配,将语义一致的区域赋予更高权重,使SVLM能够继承并转移注意力至当前帧中的任务相关区域。
2 架构
本节以自动驾驶场景中 1 FPS帧率的多目标识别任务为例,展示所提出的协同架构。
2.1 工作流
前向摄像头持续采集视频帧并发送至边缘设备。对于每个带时间戳的帧,边缘设备根据上一次云端交互的延迟情况,动态决定是否将其上传至云端。同时,每一帧均在本地由SVLM进行实时推理。
对于已上传至云端的帧,LVLM的响应依据其延迟情况进行处理:
- 若响应在1秒内返回,则直接采纳并存储;
- 若响应延迟超过阈值,则暂存以供后续使用,当前帧的实时结果由SVLM提供。
如图2所示,LVLM返回的结果包含两个关键组成部分:
- 针对输入查询的响应内容,记为
<answer>; - 推理过程中注意力聚焦的图像区域,标记为
<ROI>。
这两个输出分别从文本与视觉维度为后续帧提供语义引导。此外,返回结果中还包含原始帧的时间戳,使系统能够评估当前云侧延迟,并判断该结果在语义引导中的时间相关性,从而决定其是否可用于上下文更新。
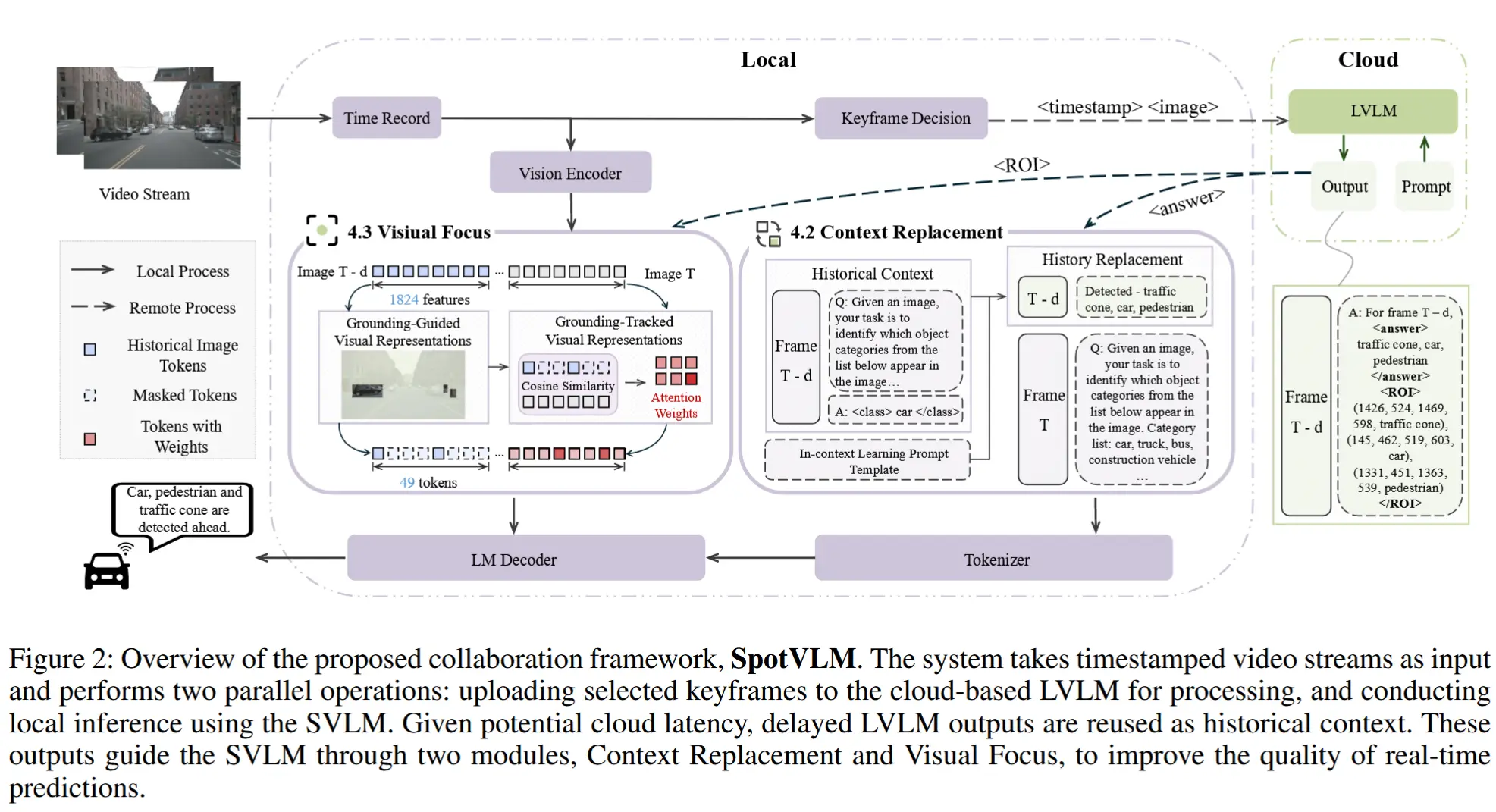
2.2 上下文替换
上下文替换模块由两个关键机制组成:上下文迁移和上下文替换。具体步骤如下:
-
LVLM 生成的高质量输出会持续更新并存储于边缘侧缓存中,记为:
\mathcal{H}_{T-d}^{L V L M} \leftarrow L V L M(I_{T-d}, Q_{T-d}), \quad (1)其中,I_{T-d} 和 Q_{T-d} 分别表示帧 T-d 的图像和问题。
-
当处理帧 T 时,SVLM 收到 LVLM 关于帧 T-d 的处理结果,此时计算该结果的延迟(即 d )。如果延迟在预设阈值 \delta 范围内,则 SVLM 使用 LVLM 的响应替换其原始输出 \mathcal{H}_{T-d}^{SVLM} \leftarrow \mathcal{H}_{T-d}^{LVLM},并将其融入历史上下文中,用于指导对帧 T 的推理。
-
由于边缘设备资源限制和小模型的上下文窗口限制,简单堆叠多轮输入可能导致 token 截断。因此,作者设计了一个上下文学习提示模板,用于压缩和总结对话历史,供 SVLM 使用,压缩结果记为 \tilde{\mathcal{H}} 。
综上所述,在文本协同策略的支持下,SVLM 在帧 T 接收到的输入结构对应图中“上下文替换模块”右侧部分,具体如下:
2.3 视觉聚焦
具备强大定位能力的 LVLM 能够识别与任务相关的图像区域,并将其传输至边缘侧的 SVLM。基于此,SVLM 可从两个角度主动聚焦于关键视觉区域。
Grounding-Guided Visual Representation
LVLM 返回的兴趣区域(ROIs)指导 SVLM 在历史帧上进行视觉定位。大多数 VLM(包括 Qwen-2.5-VL-3B)采用视觉 Transformer ,将缩放后的输入图像划分为图像块(patches),并编码为视觉 token 。然而,其中许多 token 与推理任务无关。为加速推理并增强注意力聚焦,将 ROIs 映射到对应的图像块,仅选择与任务相关的部分。该选择形式化定义如下:
其中,\mathcal{P} 表示所有图像块的集合,p_i 是与 ROI 存在空间重叠的图像块。在多目标识别任务中,对每个目标类别选取最大的 ROI。如图所示,用于投影的特征数量减少至 49,从而显著降低计算成本。
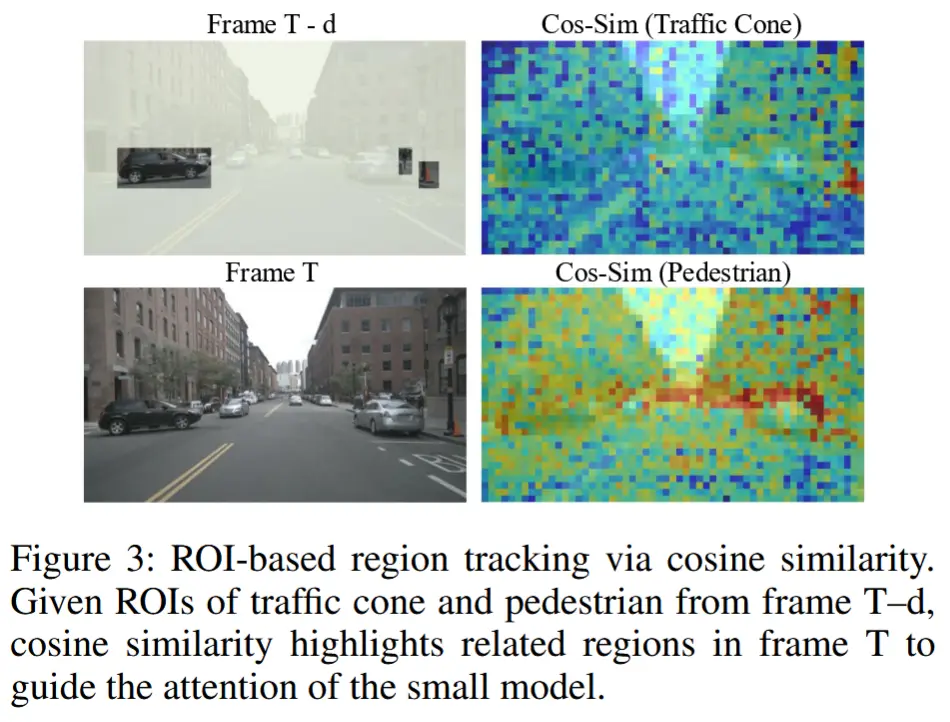
Grounding-Tracked Visual Representation
LVLM 提供的 ROIs 是基于帧 T-d 的,而 SVLM 需要处理的帧 T,因此 ROIs 存在偏差,需要对目标进行跨帧追踪。而 SVLM 的定位能力有限,难以准确定位。因此,作者采用计算视觉特征的余弦相似度来进行追踪。
首先,计算在 T-d 帧上类别 c 的对象特征向量。令 \mathcal{P}_{T-d}^{(c)} 表示帧 T-d 上类别 c 的图像块索引集合,\mathbf{v}_i^{(T-d)} 为第 i 个图像块的视觉特征。因此,帧 T-d 上类别 c 的对象特征向量为:
接着,计算帧 T-d 的 ROI 特征与帧 T 的视觉特征之间的余弦相似度,从而获得每个潜在类别 c 在帧 T 上的相似度图 S^{(c)}:
其中,\mathbf{v}_j^{(T)} 表示帧 T 上第 j 个图像块的特征,N 为图像块总数。该跨帧计算得到的图像块级相似度分数可聚合为统一的相似度向量 s,定义如下:
然后,可利用 s 构建基于定位追踪的视觉权重 W_s ,其公式如下:
其中, \mu 和 b 是可调的缩放参数,用于控制视觉权重的大小。
为进一步根据语义关联性自适应调整视觉表示,作者引入一种门控token更新机制,实现对视觉token的动态调制。该更新过程定义为:
其中, t 表示原始视觉token, \alpha \in [0, 1] 是一个控制系数,用于平衡已知目标类别与新出现目标之间的权重。动态预测的权重 W_s 基于特征相似性对视觉token进行调制,从而在语义一致性引导下实现自适应的token精炼。
3 实验
3.1 实验设定
- 评估任务和数据集
- 实时多目标识别:nuScenes、BDD100K (MOT),都是自动驾驶场景
- 实时手势识别:IPN Hands
- 实时视频帧字幕生成:Actions for Cooking Eggs (ACE)
- 评估指标
- 对于目标识别任务:Micro-F1、Macro-F1 和 0-1 精确匹配(0-1 EM)
- 对于手势识别和字幕生成:Accuracy
- 实时保证:所有评估任务均受实时性约束(1–2 FPS)。若系统未能在 1 秒内返回有效结果,则该帧输出视为无效(空)。
- 实现细节
- 直接使用 VLM 的官方预训练版本,不微调。
- 为了平衡速度与性能,保留前两帧作为历史上下文。
- SpotVLM 始终将云端反馈视为 SVLM 历史上下文中“最远”的一帧。
3.2 实验结果
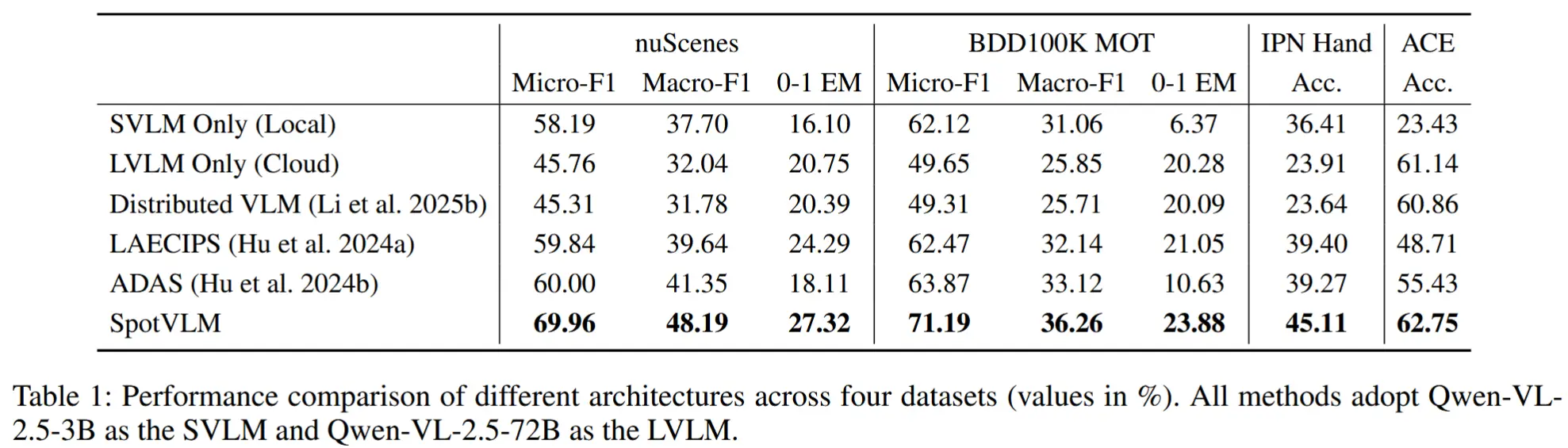
- 整体性能
- 基线:仅边缘端的Qwen2.5-VL-3B、仅云端的Qwen2.5-VL-72B、Distributed VLM、LAECIPS 和 ADAS
- 结论
- 由于云端延迟,仅云端的大模型F1分数反而低于仅边缘端的小模型。
- 协同架构 LAECIPS 和 SpotVLM 在四个数据集上均表现出稳定优异的性能。
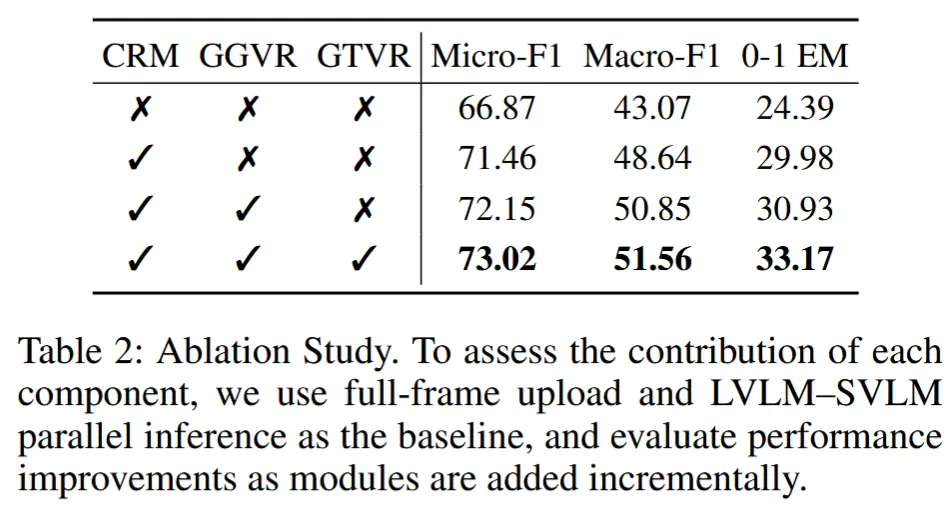
- 消融实验
- 消融组件:上下文替换模块(CRM)、基于定位引导的视觉表示(GGVR) 和 基于定位追踪的视觉表示(GTVR)
- 为隔离各组件影响,所有图像帧均上传至云端,排除了帧选择与上传策略的干扰。
- 结论:
- CRM 带来最显著的性能提升,因其有效注入了高质量文本上下文;
- 自适应性研究
- 更换边缘端的小模型与云端的大模型。
- 无论模型配置如何变化,SpotVLM 的协同策略始终能稳定提升实时推理性能。

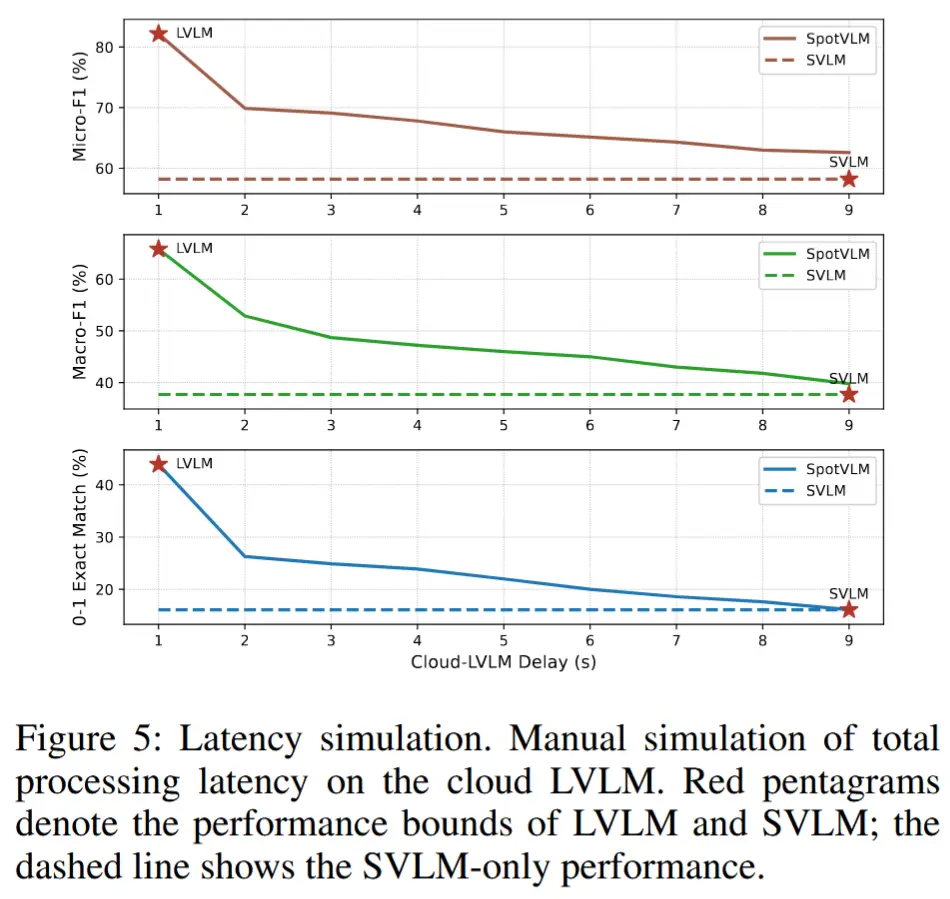
- 延迟分析
- 通过人为设定 LVLM 响应的不同返回延迟进行实验。
- 当延迟为 1 秒(即 LVLM 输出总能在实时阈值内返回),系统性能等同于直接使用 LVLM。
- 从 2 秒延迟 开始,LVLM 输出已无法满足实时要求,仅能作为历史上下文用于引导 SVLM 推理;
- 随着延迟继续增加(如 9 秒),帧间时间相关性减弱,整体性能逐渐下降;