![[MIT6.5940] Lect 15 GAN, Video and Point Cloud](/upload/宏村.webp)
一、Efficient GANs
Ⅰ、Background
-
生成式对抗网络GAN(Generative Adversarial Networks)是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。
-
生成对抗网络一般由一个生成器(生成网络),和一个判别器(判别网络)组成。
- 生成器的作用是,通过学习训练集数据的特征,在判别器的指导下,将随机噪声分布尽量拟合为训练数据的真实分布,从而生成具有训练集特征的相似数据。当推理阶段时只使用生成器生成图片即可。
- 判别器则负责区分输入的数据是真实的还是生成器生成的假数据,并反馈给生成器。判别器仅在训练阶段需要使用,用于指导生成器。
- 两个网络交替训练,能力同步提高,直到生成网络生成的数据能够以假乱真,并与与判别网络的能力达到一定均衡。
-
GAN的损失函数如下
E_x[log(D(x))] + E_z[log(1-D(G(z)))]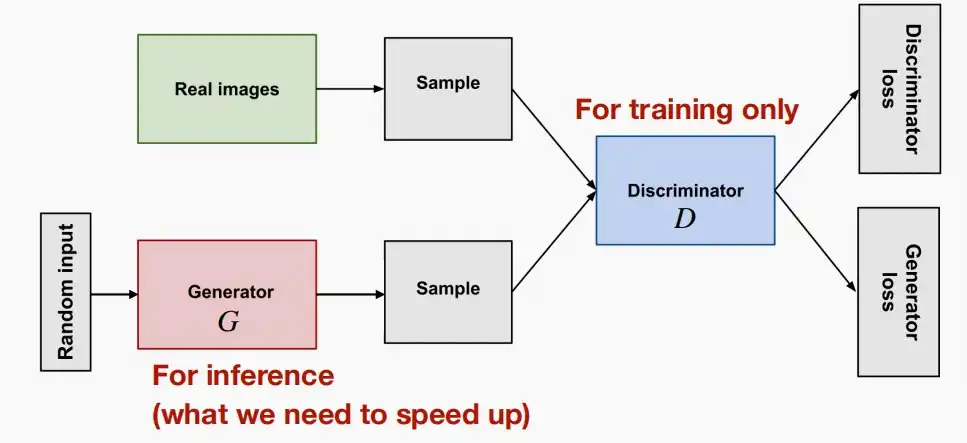
- GAN分为Conditional和unconditional两种
- 无条件GAN:意味着生成器仅接受噪声,通常是高斯噪声,并将其映射到特定的输出图像。
- 有条件GAN:生成器和判别器除了噪声外,还接受魔种形式的调节输入,例如分类标签、分割图等。有条件GAN更受欢迎,因为它们能执行一些实用任务,例如用于绘画的GauGAN、用于图像编辑的扩散模型。

- 挑战
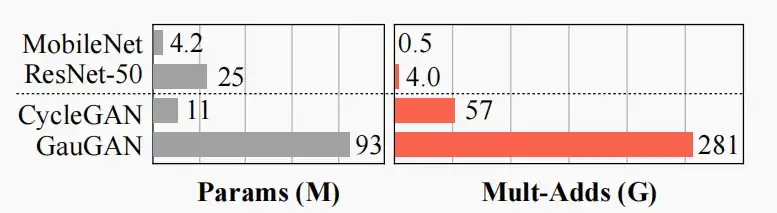
- 尽管GAN模型具备强大的能力,但其问题在于通常需要大量的计算资源。
- 如下图,CycleGAN和GauGAN的参数和乘加运算相比判别模型MobileNet和ResNet要大几个数量级。
Ⅱ、GAN Compression (compress generators with NAS+distillation)
- 《GAN Compression: Learning Efficient Architectures for Conditional GANs》 [Li et al., 2020]
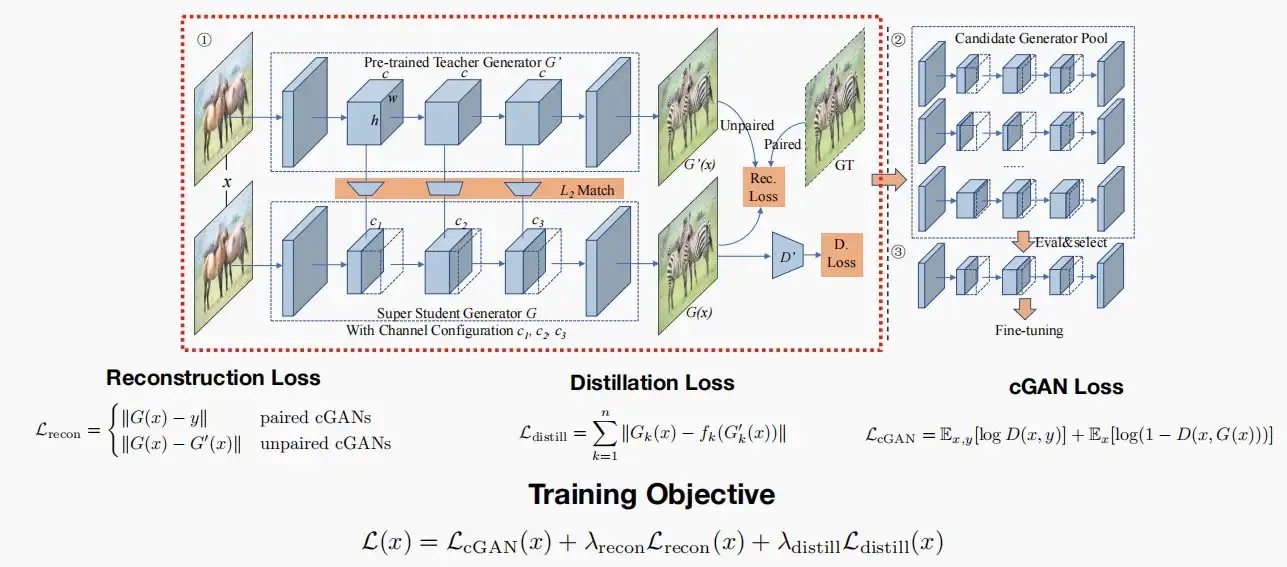
- 基本思路:给定一个预训练的大模型生成器,我们希望将其提炼成一个更小的学生生成器。
- 其使用了三个损失函数,在Lect 9中有讲解到。
- 下图中左半部分包含一个预训练的Teacher生成器G',通过Distill获得轻量级的Student生成器G。右上部分是通过训练获得的多个子生成器sub-generators,通过右下部分的选择评估获取最终的最优子生成器。
- 如下图为GAN与其他模型的计算量和结果对比图。左图为根据描边上色,GAN Compression实现计算量压缩11.8×。右图为马映射到斑马,虽然CycleGAN也可以加速,但是质量明显低于GAN Compression。

Ⅲ、Anycost GAN (dynamic cost vs. quality trade-off)
- 《Anycost gans for interactive image synthesis and editing》 [Lin et al., 2021]
- 动机
- GAN可用于图像编辑。但是生成速度缓慢,阻碍了交互式应用程序。
- 作者从传统的渲染流水线汲取灵感,当人们尝试渲染3D场景时,并非每次调整都直接渲染至最终结果,而是先渲染一个低质量的效果以便人们调整。
- 因此,作者希望快速模型和慢速模型的输出在视觉上保持一致,以便用于输出预览。
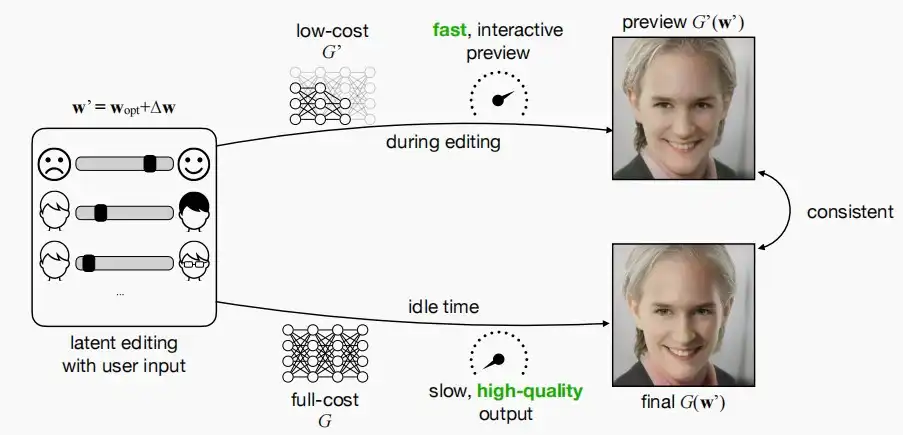
- 作者从两个维度出发:不同分辨率和不同通道数,因为这两者基本上是影响模型成本最显著的两个维度。
- 不同的分辨率
- 作者回顾了几种同样具有生成器和判别器的GAN模型,并分析
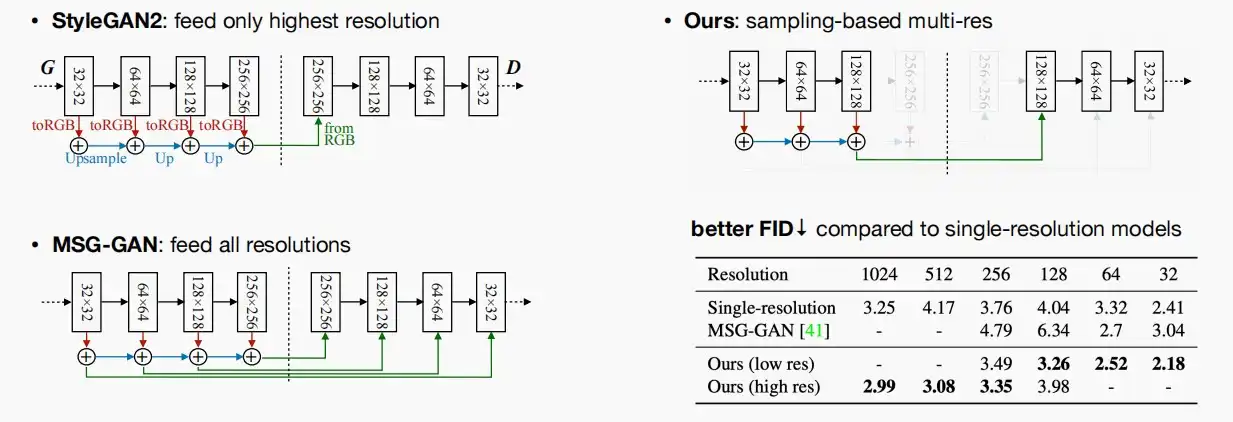
- StyleGAN2:仅将生成器最高分辨率256×256的图像输入给判别器进行判别,不符合目的。
- MSG-GAN:将每个分辨率都输入对应的判别器进行判别,这样计算量较大,且判别器可以看到各种分辨率的图像影响判别,图像质量较差。
- 作者提出的模型:在每次训练迭代中,不是将所有分辨率都输入判别器,而是抽样一个特定的分辨率输入。
- 根据实验结果,基于采样的模型解析获得了更优异的性能。因此对于单分辨率结果,它意味着正在训练一个特定的GAN模型,且该分辨率为唯一。
- 作者回顾了几种同样具有生成器和判别器的GAN模型,并分析
- 不同的通道
- 在训练过程中,只需对不同的通道配置进行采样,与分辨率的处理方式类似。
- 问题一:GAN训练仅确保输出结果具有真实感,但它实际上并未促进不同通道数之间的一致性。
- 解决:简单地在不同通道的输出之间添加了这种关联损失。
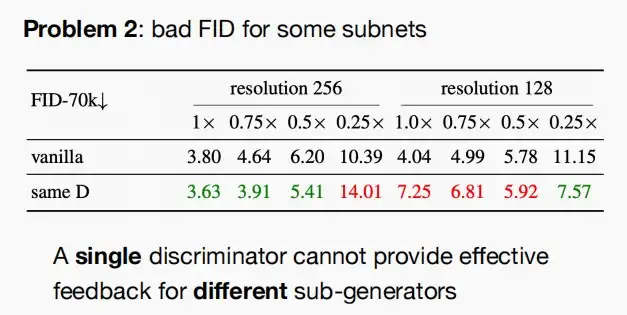
- 问题二:单个鉴别器不能为不同的子发生器提供有效的反馈。
- 解决:只需让判别器了解生成器的结构,将样本生成器的结构编码为一个向量,并利用一个简单的线性层来调制判别器的输出,从而使判别器意识到生成器的样本通道配置器。解决后效果如下图,可以实现各级别的改进。

- Anycost GAN的效果如下图,即使是最低的分辨率和最少的通道数,也可以获得相当不错的生成效果。

Ⅳ、Differentiable Augmentation (data efficient training of GANs)
- 昂贵的数据
- 收集数据需要几个月甚至数年的时间,以及高昂的标记成本。
- GANs的训练结果极大程度依赖于大量高质量的数据。如果数据有限,GANs将会严重恶化。‘
- StyleGANs虽然可以生成样本,但是当数据较少时生成的样本质量也很差。
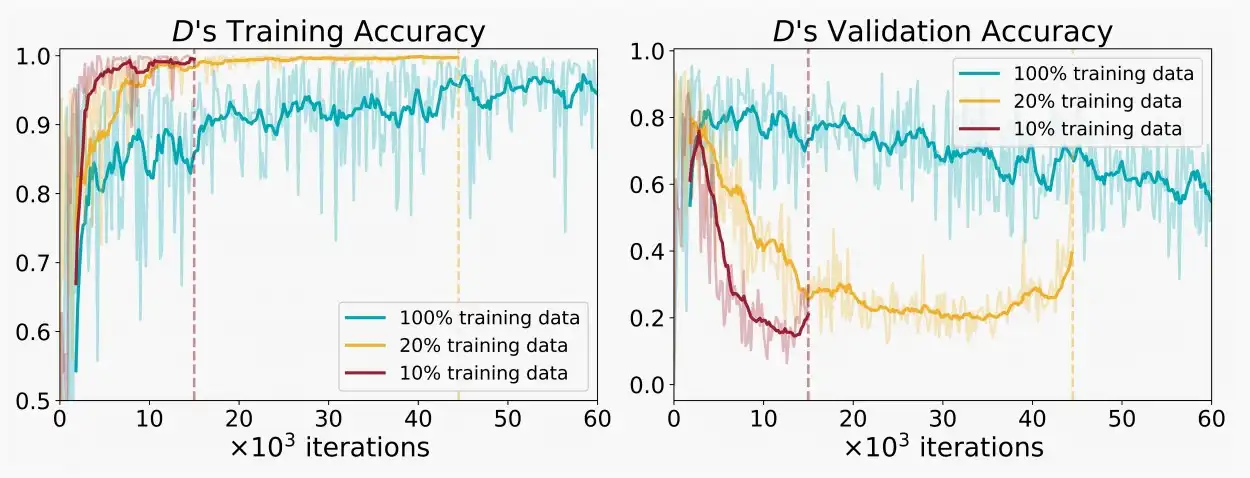
- 如下图发现,判别器过拟合较少的数据,导致较差的生成器性能。例如对于10%的训练数据较少,在较少的迭代次数内即可导致过拟合,验证准确率也逐渐下降,相对其他比例最低。
- 传统上,数据增强对于过拟合是有效的。那如何使用数据增强GANs?
- 《Differentiable Augmentation for Data-Efficient GAN Training》 [Zhao et al., 2020]
- 方法一:仅增强真实图像
- GANs是分别迭代训练判别器和生成器的,因此我们可以在训练判别器时对真实图像进行增强。
- 然而,作者发现当更改真实样本x为T(x)后,会导致生成器生成增强的图像,这显然是不够真实有效的。例如对真实图像使用裁剪,导致生成器最后生成的图像也带有裁剪。
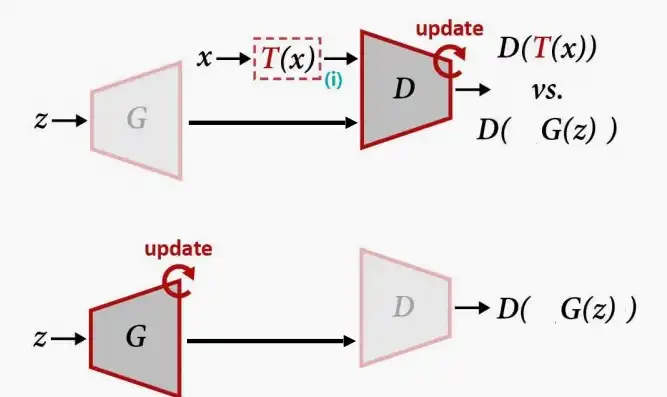
- 方法二:增强真实图像和生成图像
- 为了解决方法一的问题,想到可以对生成器生成的图像同样进行增强,使得原本的G(x)变成T(G(x)),确保生成器不去学习那些增强效果。
- 然而从右图的实验结果可以看出,经过迭代训练后,生成器可以很好的学会真实样本,而判别器的判别成功准确率却非常低。这是因为对于判别器而言任务十分困难,需要分辨经过增强后的真实数据与生成数据,打破了GAN两者的平衡。
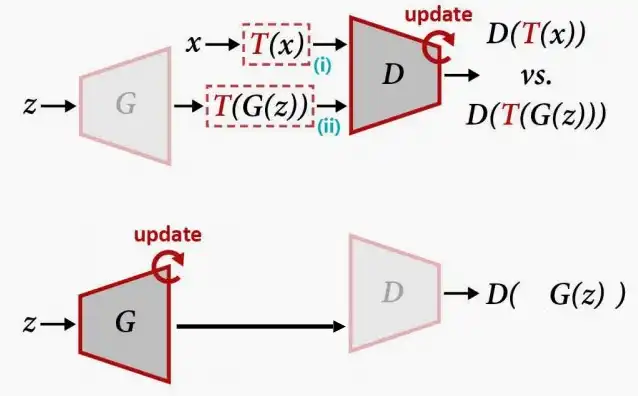
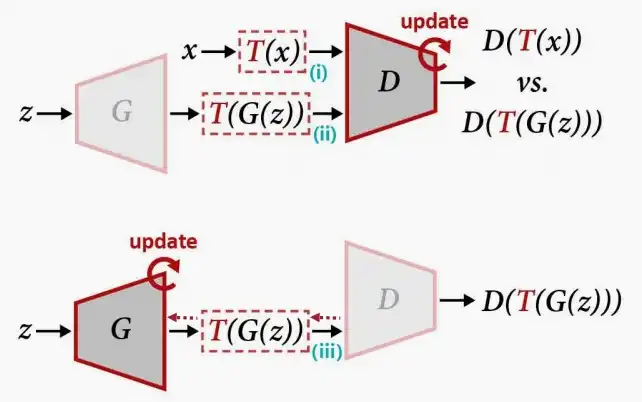
- 方法三:Differentiable Augmentation可微分增强
- 在方法二的基础上进一步改进,当训练生成器时同样使用数据增强。
- 思路:希望数据增强可微分,以便能够传播梯度,且希望同时应用到生成器和判别器。
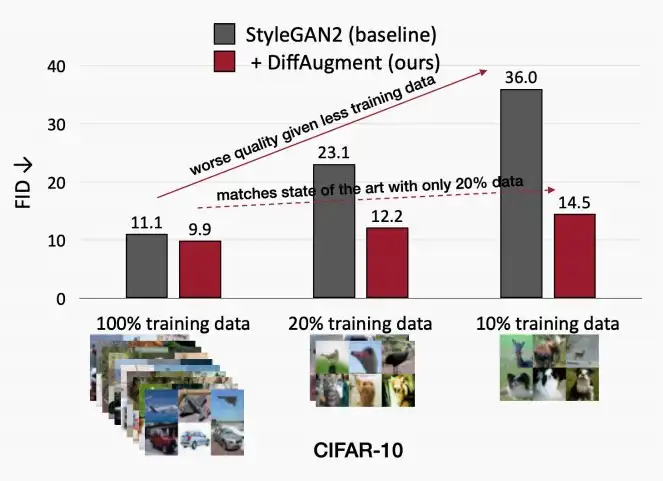
- 如下图,使用StyleGANs+DiffAugment后,low-shot情况下生成样本质量明显更高。
二、Efficient Video Understanding
Ⅰ、Background
- 本lect仅讨论视频识别,不涉及视频生成领域。
- 视频呈爆炸式增长:每天有10个5小时的视频被上传到YouTube上。高效的视频处理对于云计算和边缘计算都是必不可少的。
- 许多应用:
- 动作/手势识别
- 场景理解
- 视频搜索广告
- 为自动驾驶的视频预测
- 视频处理和图像处理之间的区别:时间建模。例如一个视频从头往尾看和从尾往头看会有不同意思。
Ⅱ、2D CNNs for video understanding
- 最简单的就是使用2D CNNs,应用于视频的每一帧(类似于图像),对每一帧进行二维分类并汇总得分。
- 这种方法适用于不考虑时间信息的数据集,但若处理的是与时间相关的数据集,那么这种方法显然不会太有效。

- 如果需要考虑时间,可以采用一个双流方法Two steam method: 空间+时间
- 除了RGB输入,还需要计算光流(optical flow),即意味着对于给定的两个帧,需要计算帧中每个像素的移动。
- 缺点:光流的计算相当慢
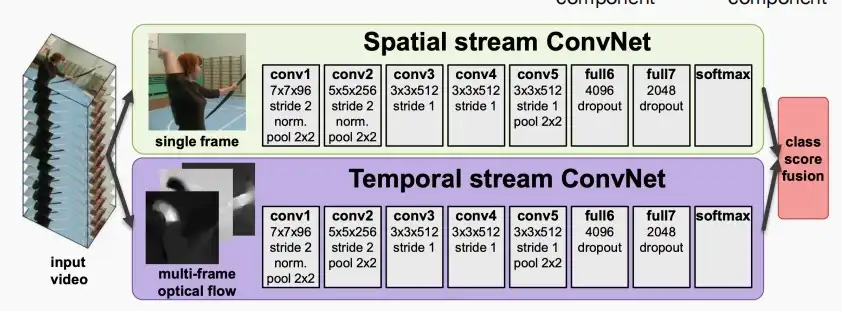
- 除了上述两者,还可以选择2D CNN + Post-fusion (例如LSTM)
- low-level信息在主干推理过程中丢失。
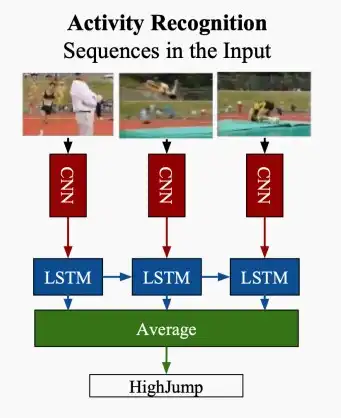
- 2D CNNs用于视频识别的优缺点
- 优点:计算效率高。可以重用来自图像识别领域现有的二维CNN。
- 缺点:
- 聚合二维CNN不能建模时间信息。对视频基准测试的精度较低。
- 光流的计算速度非常慢(比深度网络本身要慢得多)。
- Late fusion不能建模low level的时间关系。
Ⅲ、3D CNNs for video understanding
- C3D三维卷积网络
- 不仅沿着图像的高度和宽度进行卷积,还沿着时间维度进行卷积,因而能够同时处理空间与时间信息。
- 缺点:参数众多,容易过拟合;数据效率低。

- I3D:将3D卷积模块初始化为一个预先训练好的2D模型,然后沿着时间维度膨胀卷积核。
- 跨时间维度重复这些权重以进行初始化。
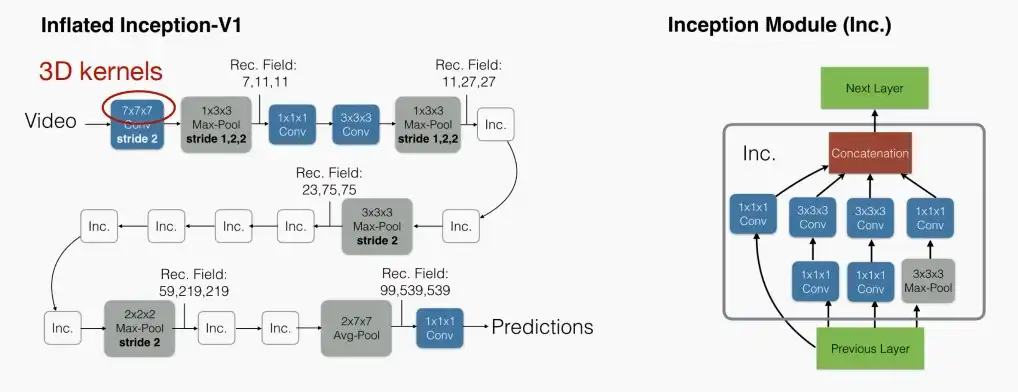
- 基于3D CNN方法的优缺点
- 优点
- 从编译器初始阶段就融入了时间建模
- 可以建模低、中、高级信息
- 缺点
- 由于额外的时间维度,成本较大(模型规模、计算)
- 优点
Ⅳ、Temporal Shift Module (TSM)
- 《TSM: Temporal Shift Module for Efficient Video Understanding》[Lin et al., 2019]
- 不采用3D卷积,而是将部分特征沿着时间维度进行平移,以交换信息。
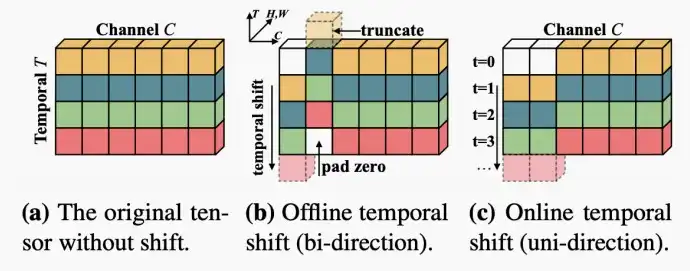
- 在平移时,分为双向和单向两种方式。对于离线视频分析,我们已知过去和未来的信息,可以使用双向平移;而对于在线视频分析,我们仅仅知道过去的信息,可以使用单向平移。
- 如下图中,短轴代表时间,在图(b)中进行双向平移,在图(c)中进行单项平移。
- 该方法可以插入到现成的2D CNN中,以零流量和零参数为代价实现时间建模,在参数数量和计算量方面没有任何成本。
- Offline TSM models
- Offline处理时,帧被分批一起处理。
- 仅需将TSM模块插入2D CNN中,如下图在两个卷积层之间添加。
- 并采用恒等映射或残差连接,以恢复因移位操作而丢失的信息(图中白色部分)。
- 应用范围:动作识别、跌倒检测、视频推荐等
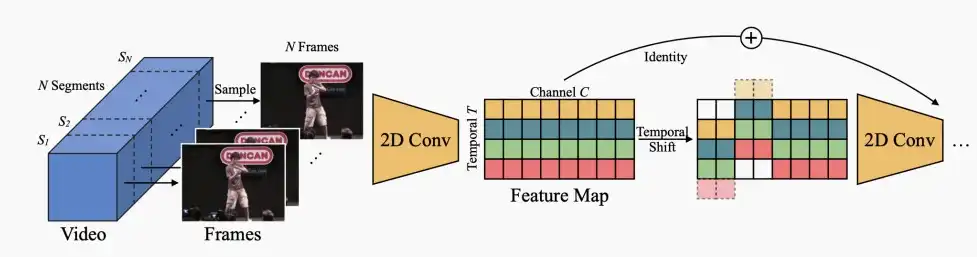
- Online TSM models
- 逐帧处理,流媒体方式。
- 把之前的frames平移到当前的frames上,从而也达到了时序信息建模的作用,从而实现在线的识别功能。
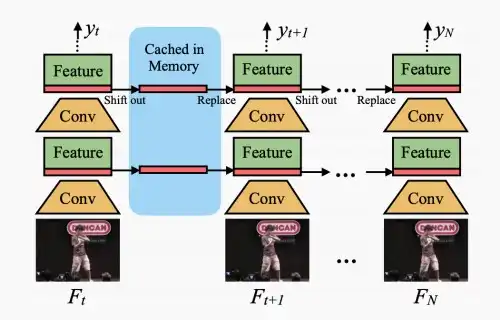
- 使用Something-Something数据集进行实验可知,TSM相比于ECO和I3D方法具有更少的计算量和准确率。
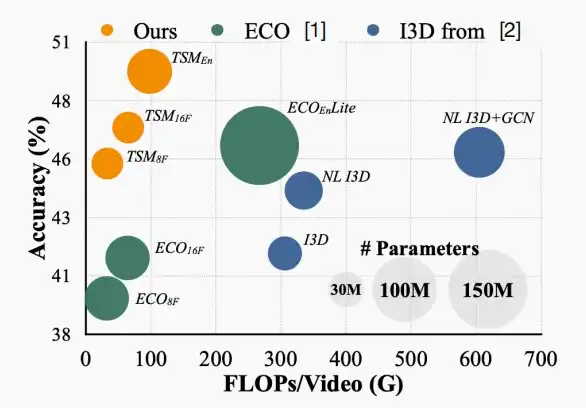
- 左图,在不同的数据集上比较在线和离线视频识别的延迟和准确率,可知在线视频识别带来的延迟开销是微乎其微的。
- 右图,数据集UCF101,可以看出TSM在仅观测到小部分视频后即可得到较高的准确率,性能较好。
- 作者还进行了进一步研究,发现每个通道学习不同的语义,例如下图中,通道5关注的是移动东西到远处,通道446关注的是将东西移到左边。


三、Efficient Point Cloud Recognition
- 对于前面讨论的图像,它们具有密集且规律的特点,可以使用卷积层处理。而对于点云来说,具有许多挑战:
- 极其稀疏
- 在内存中不规则存储
- 需要特殊的操作和系统进行处理
- 因此这类计算问题相当棘手,且点云的场景通常需要在边缘设备上处理,例如VR头显、自动驾驶汽车,这意味着资源是有限的,效率是十分重要的。
Ⅰ、Point-Voxel CNN (PVCNN)
- 《Point-Voxel CNN for Efficient 3D Deep Learning》 [Liu et al., NeurIPS 2019]
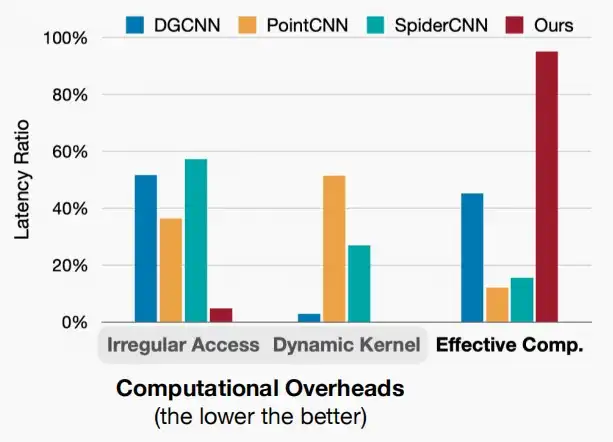
- 如图对先前的方法如DGCNN、PointCNN和SpiderCNN进行性能分析,其实际有效计算量占比非常比,甚至低于20%,大部分时间耗费在收集邻近点。
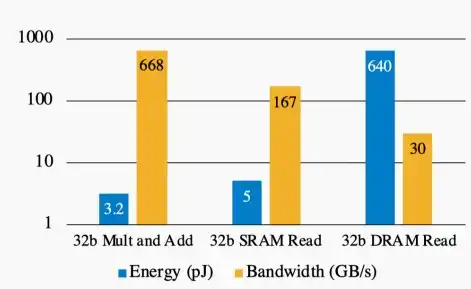
- 考虑到硬件因素,内存的操作比算数操作代价更大。在内存操作中,会消耗很大的能量,却只有很小的运算带宽,而算数运算的能量消耗小,运算速度快。如下图所示:
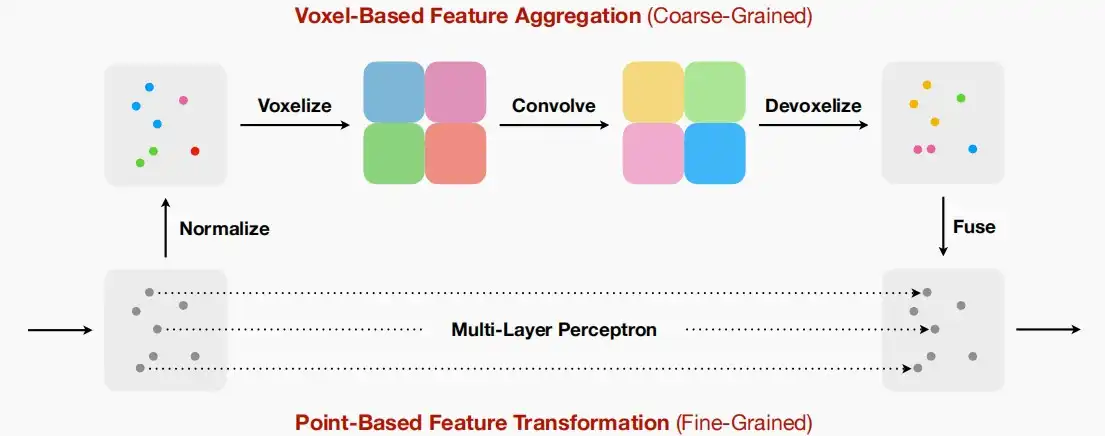
- Point-Voxel CNN
- 框架如下图,两个分支,通过基于Voxel(体素)的方法提取局部特征,利用Point的方法提取全局特征,然后将两个特征融合。
- 基于Voxel的分支对卷积具有更好的规律性和不规则访问/动态核代价,是相邻邻域信息聚合的更好选择。
- 基于点的分支可以保持高分辨率,缓解体素化过程中的信息损失。由于收集邻近点速度较慢,因此只需使用MLP进行特征学习,无需建模点与点之间的关系。
- 这种双分支设计使得能够同时受益于体素分支的规律性,并消除分支中的不规则内存访问,同时仍提供更高分辨率的信息。
- 框架如下图,两个分支,通过基于Voxel(体素)的方法提取局部特征,利用Point的方法提取全局特征,然后将两个特征融合。
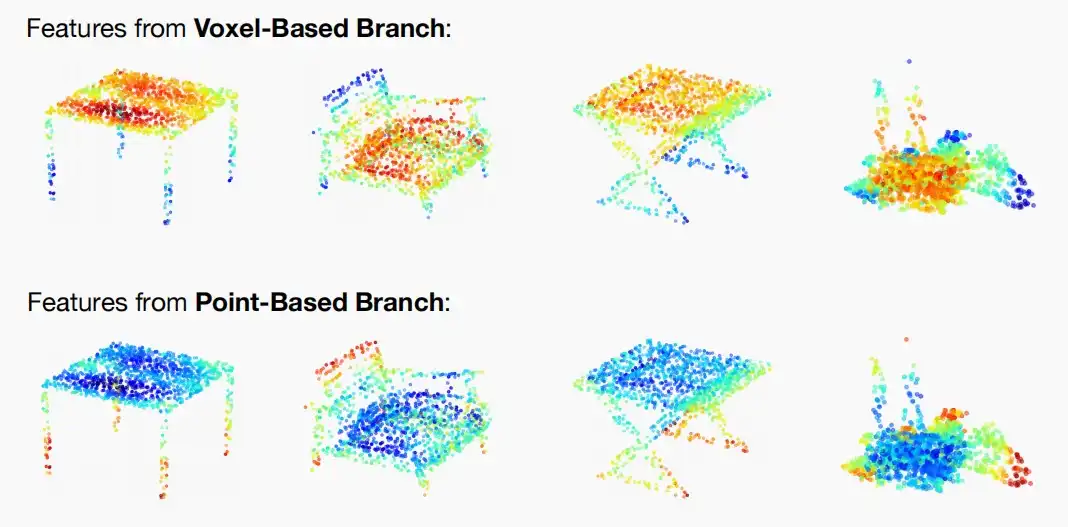
- 如下图为基于体素和点分支的可视化热图
- 由于体素分支分辨率更低,主要关注大体结构
- 点分支主要聚焦于高分辨率细节
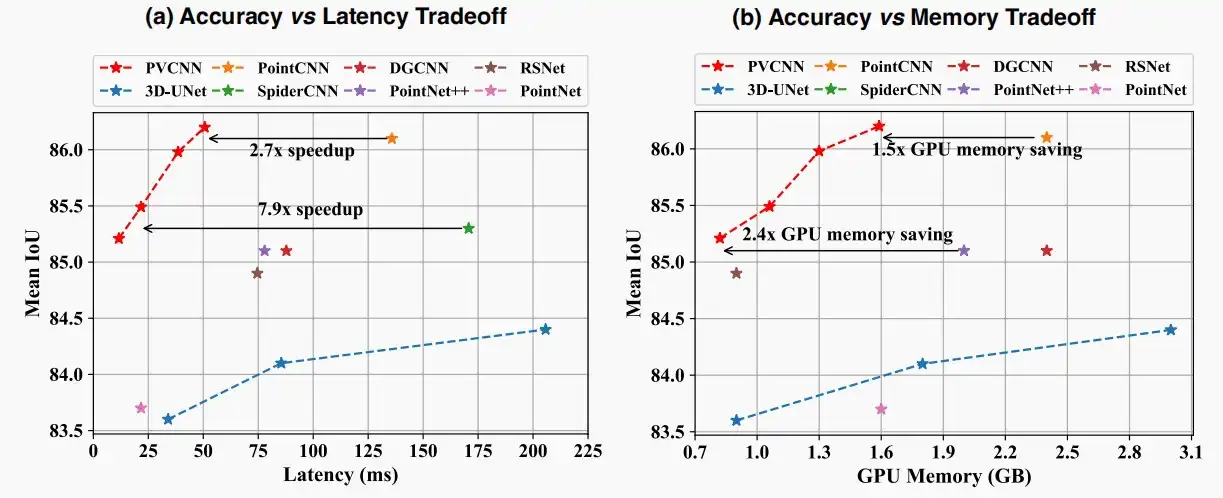
- 如下图为对比语义分割的准确性,使用IOU指标,考察延迟和GPU内存两个方面。
- IOU指标全称Intersection over Union,是计算语义分割模型性能的重要指标之一。它通过计算预测结果和真实标签的交集与并集之间的比值来衡量模型性能,具体计算方法是基于像素级别的IoU(Intersection over Union)的平均值。
- 可以看出本文提出的PVCNN具有最高的平均IOU,且延迟和GPU内存较低。
- Point-Voxel Convolution的局限性
- 在PVCNN中使用低分辨率体素来模拟空间关系,使用类似MLP的高分辨率处理方式来处理高分辨率信息。
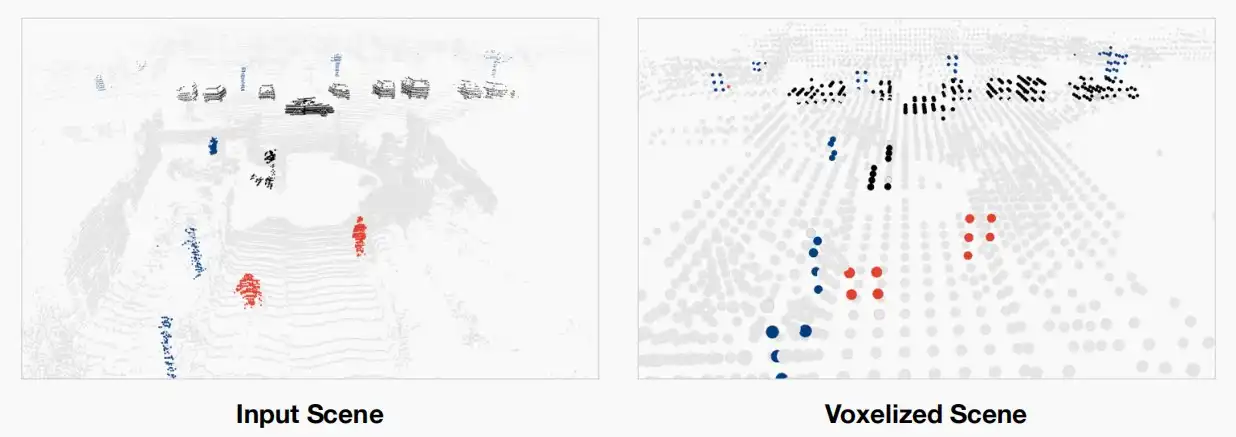
- 但由于采用低分辨率体素化,后期仍发现会导致严重的信息丢失。
- 如下图中输入和体素化后的场景对比,可以看到右边的行人和前方的车都产生了严重的信息丢失,低分辨率导致无法看清。
Ⅱ、Sparse Point-Voxel Convolution (SPVConv)
- 《Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution》 [Tang et al., ECCV 2020]
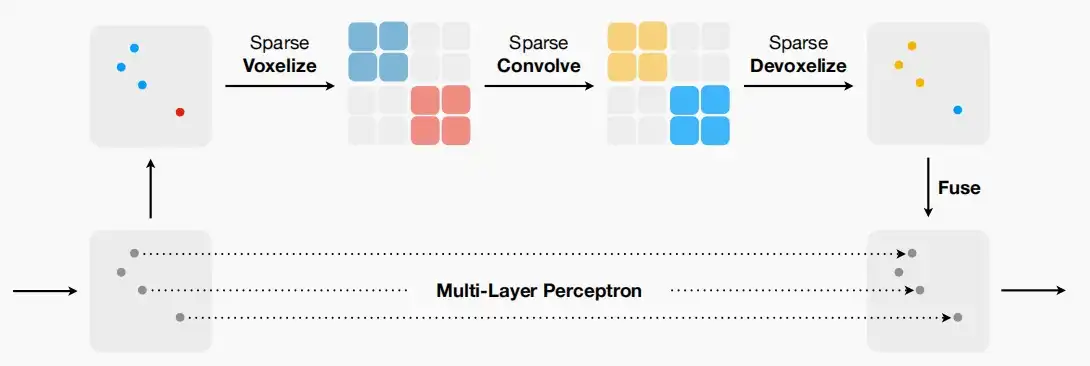
- 本文中基于上述PVCNN的局限性出发,替换了低分辨率体素化,同时为了避免高GPU需求的卷积,作者采用了稀疏卷积的方法,仅在存在点的位置应用卷积,跳过了未激活的区域以显着减少内存消耗。
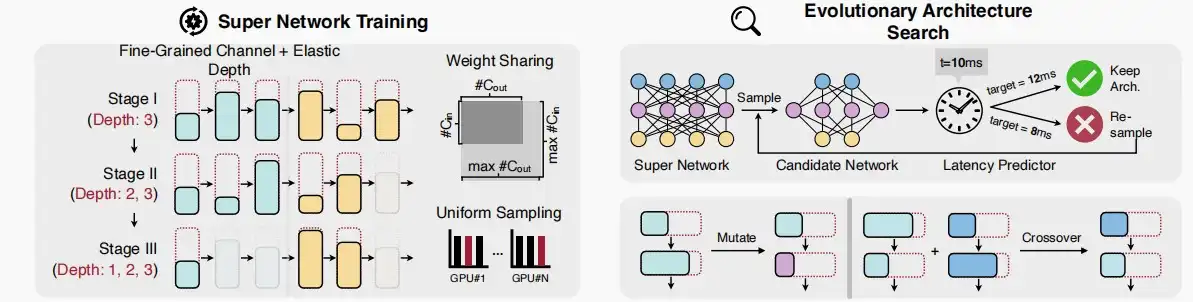
- 作者还提出了3D-NAS,一种搜寻高效的3D结构。
- 即使使用上述的模块,设计高效的神经网络仍然具有挑战性。需要调整网络架构(例如所有层的通道数和内核大小),以满足实际应用的约束条件,例如,延迟,能耗和准确性。因此引入了3D-NAS。
- 本文还提出了“范围图像”(range image)作为场景的另一种表示,与体素和点一起作为输入,提高模型的准确率。
- 范围图像实质上是将点云沿视线方向进行投影,以获取每个像素的距离范围的2D映射。
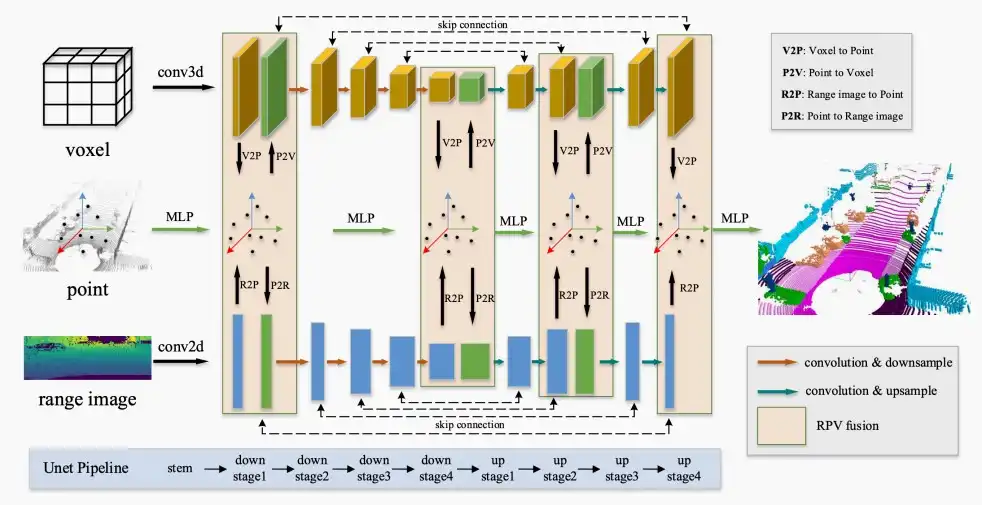
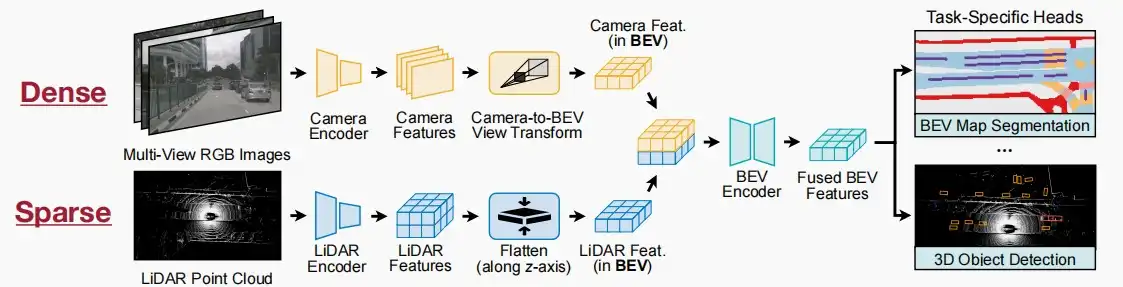
Ⅲ、BEVFusion
- BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird's-Eye View Representation [Liu et al., arXiv 2022]
- BEVFusion是一个在BEV(bird eye vision)视角下的一个多任务多传感器融合统一范式, 在共享的BEV空间下统一多模态特征,找到适合多任务多模态特征融合的统一表示,让融合后的特征同时保留语义、几何等信息。
- 多任务:检测车辆和行人,分割车道和可行驶区域等。
- 多传感器:摄像机产生密集的图像,LiDAR产生稀疏的点云。
- 数据流的两个分支:一个密集分支用于相机,一个稀疏分支用于LiDAR