![[MIT6.5940] Lect 14 Vision Transformer](/upload/宏村.webp)
一、Basics of Vision Transformer (ViT)
- 对于图像数据而言,其数据格式为[H, W, C]是三维矩阵明显不是Transformer想要的。所以需要先通过一个Embedding层来对数据做个变换。
- 如何输入2D的图片?
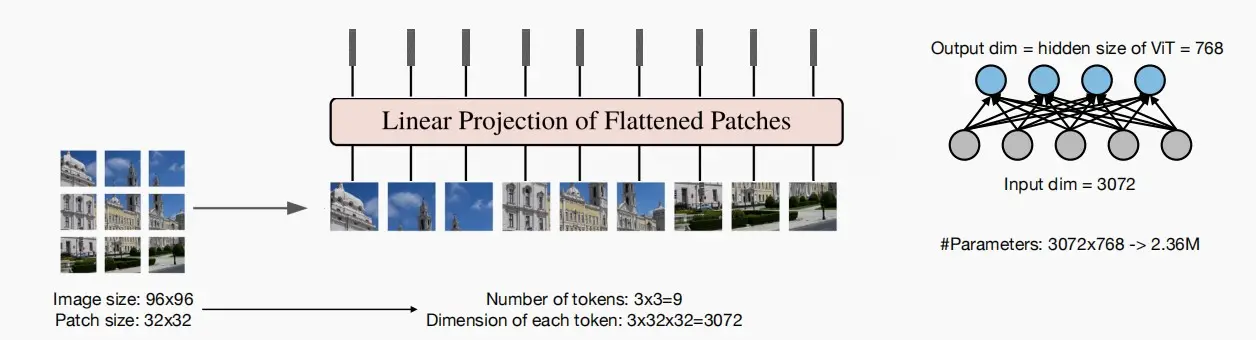
- 一种自然的方式是将图像分割称多个小块,每个小块我们将其视为一个token,在下图示例中,我们有九个补丁,然后将它们放入一维数组中,以此将二维图像转换为补丁序列。
- 原图像大小96×96,分成9个patch,即9个tokens,每个token维度大小为3072。
- 然后把每个patch输入到embedding层,即图中的‘Linear Projection of Flattened Patches’,通过该层以后,可以得到一系列向量(token),9个patch都会得到它们对应的向量。在实际实现中,使用卷积层实现embedding。
- 之后,可以将其处理方式完全等同于处理语言的方式。
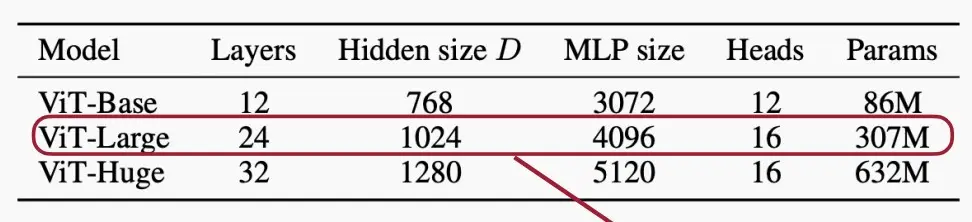
- 下图为VIT的几种变体,分为Large、base、Huge三种,后面如果跟数字则代表patch的大小,如ViT-L/16表示ViT-large且patch大小为16×16。
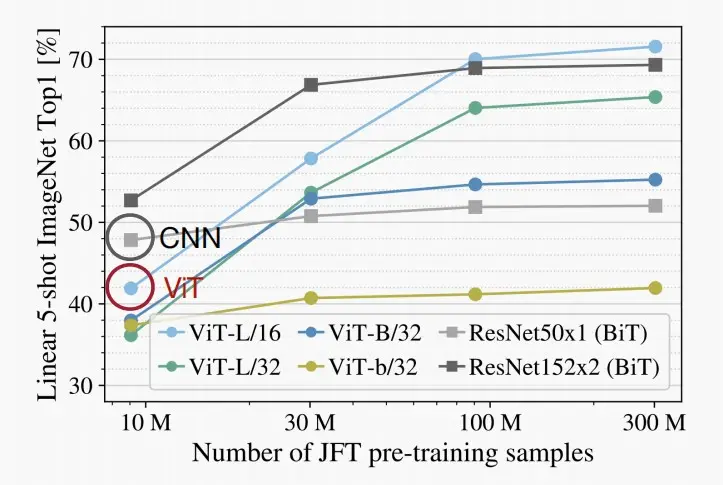
- 如下图为在ImageNet的准确度对比图,当样本数据较少时,ViT性能不如CNN,但当数据增多时,ViT明显优于CNN。
二、Efficient ViT & acceleration techniques
- 《EfficientViT: Multi-Scale Linear Attention for High-Resolution Dense Prediction》
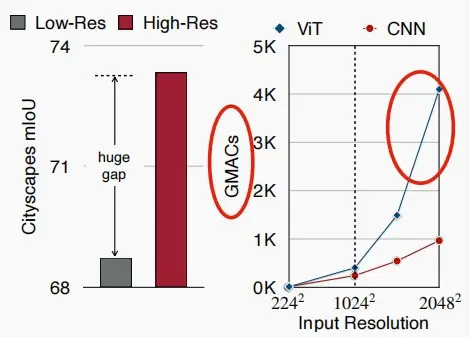
- 将ViT应用于高分辨率的图像是很困难的。
- 高分辨率对于在密集的预测任务(如分割)中获得良好的性能至关重要,比如自动驾驶中高低分辨率将极大影响对行人和非机动车的判断。
- 如下图所示,ViT的计算成本随着输入分辨率的增加而呈二次增长,远超CNN。原因是注意力图是N的平方,因此若像素数量增加,注意力图的大小及其计算量以分辨率的平方级增长。
Ⅰ、Window attention
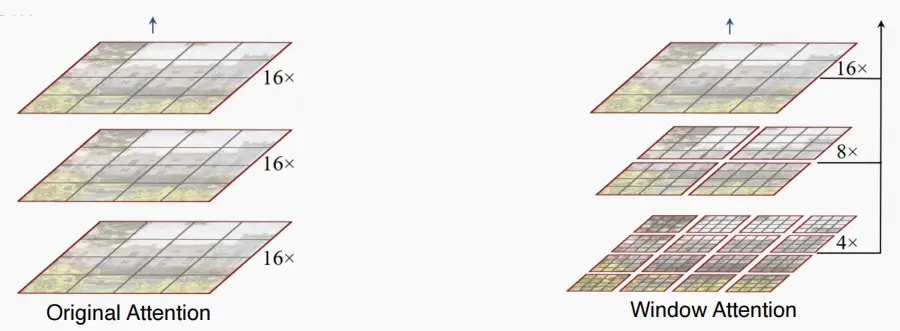
- 克服计算量随分辨率平方增长问题的自然方法是采用窗口注意力机制。
- 窗口注意不是对所有token进行注意力计算,而是在固定大小的局部窗口(例如,7x7)局部窗口中进行注意计算。
- 每个窗口中的token数量都是固定的。因此,计算复杂度是线性的。
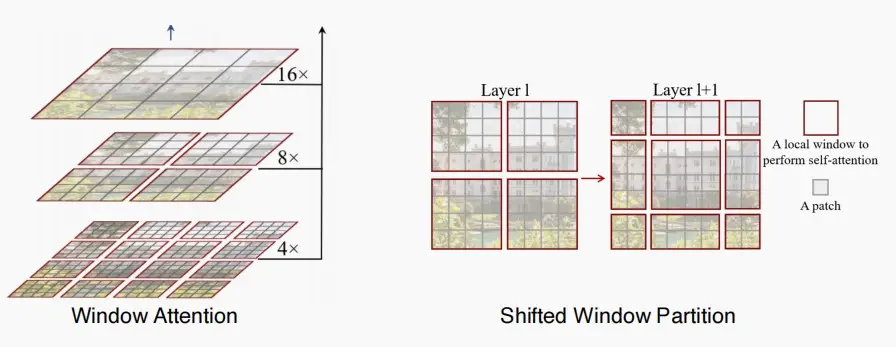
- 逐渐下采样特征贴图的大小。
- 问题:没有跨窗口信息交换
- 解决方案:添加偏移操作,出自论文《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》 [Liu et al., 2021]
- 在第i层和第i+1层之间,将像素平移两个单位,以便相邻窗口能够交换信息,允许信息流动。
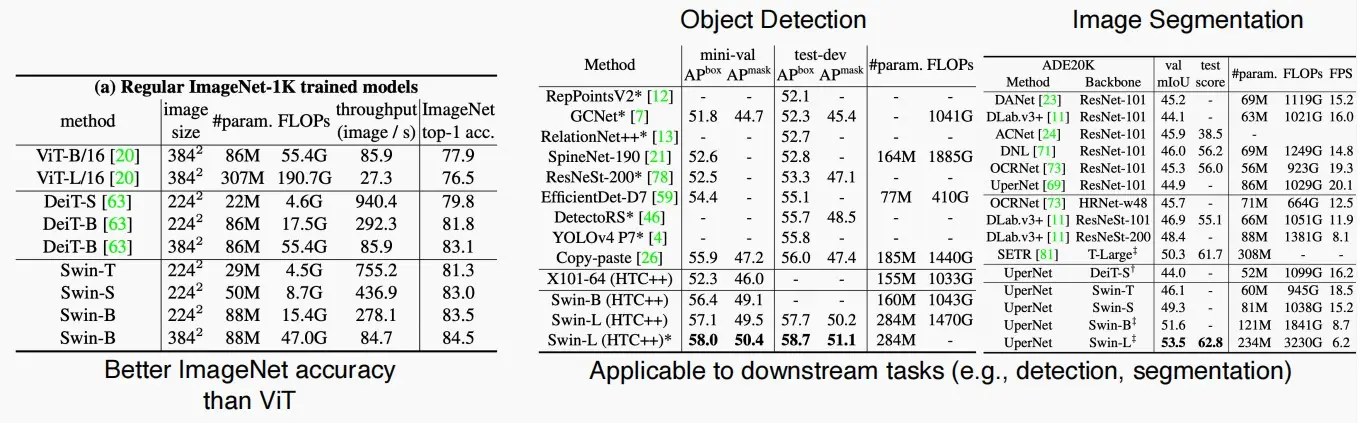
- 在这种方式下,作者从ImageNet分类、目标检测和图像分割三个任务进行实验,Swin Transformer相比原始的ViT都取得不错的表现。
- Sparse Window Attention稀疏窗口注意
- 《FlatFormer: Sparse Window Transformer with Equal-Size Grouping》[Liu et al., CVPR 2023]
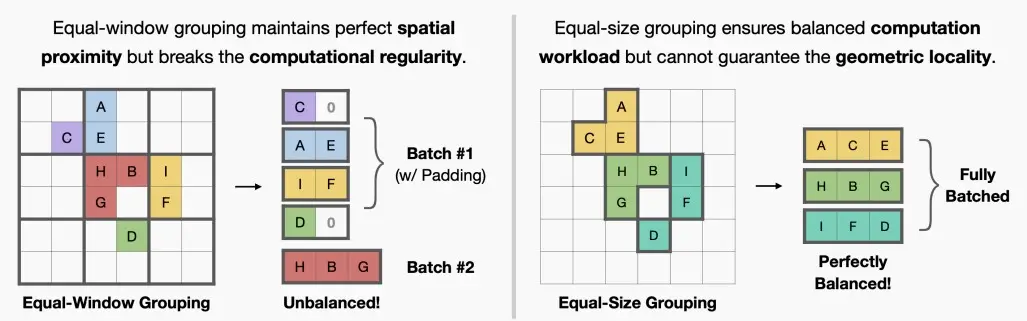
- 本文提出了FlatFormer,通过以空间邻近度为代价换取更好的计算规律来弥补延迟差距。作者首先对点云进行窗口排序,并将其分成大小相等的组(下图右),而不是形状相等的窗口(下图左)。这样,可以有效地避免昂贵的结构化和填充开销。然后,在组内应用自注意力来提取局部特征,交替排序轴来收集不同方向的特征,并移动窗口以跨组交换特征。
- 形状相等的窗口维持了空间近似性,但是破坏了计算规则性。
- 大小相等的组平衡了计算负载,但是破坏了空间邻近度。
Ⅱ、Linear attention
- Replace Softmax Attention with Linear Attention
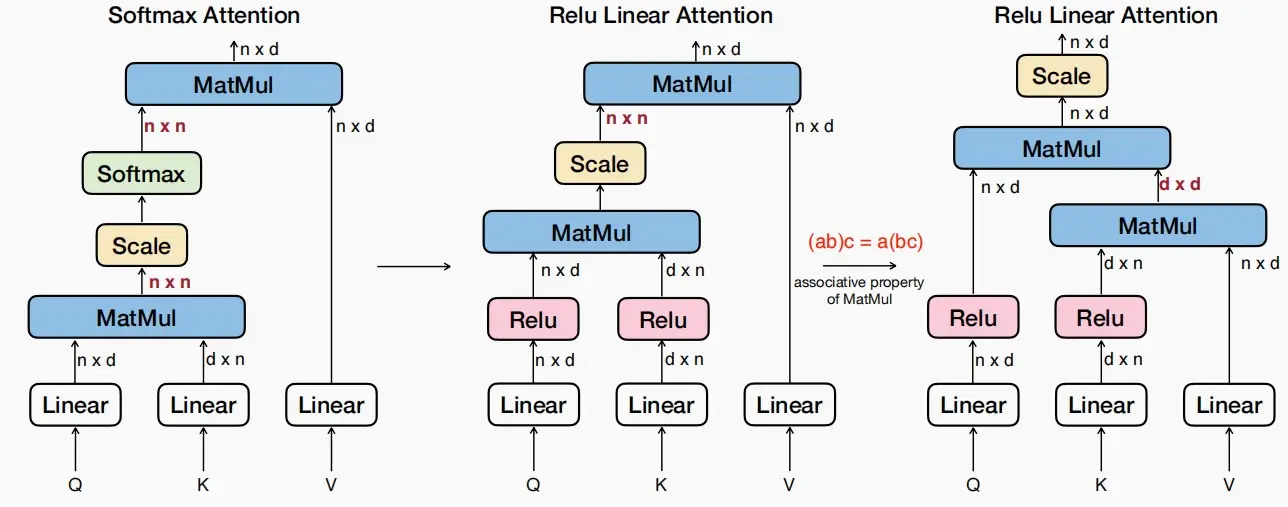
- 左图为传统的QKV注意力计算方式,对于Q和K相乘后得到大小为n×n的QK^T矩阵,接着在除\sqrt{d}进行缩放和softmax,这就是使得内存和计算变成O(n^2)的地方。
- 中间图对其进行优化,使用线性相似ReLU函数取代了原本的非线性相似exp函数,为右图进一步优化做铺垫。
- 右图中,直接取消了非线性的softmax,这样一来一切都是线性的,可以得到(ab)c=(a)bc,因此可以改变QKV的相乘顺序,使得复杂度下降到O(n)。
- Linear Attention局限性
- 如图,使用ReLU Linear Attention,不能产生尖锐的分布,而是非常柔和。因此,它擅长捕获全局上下文信息,但不擅长捕获局部信息。
- 同时它缺乏多尺度学习能力。

- 如何在不失去效率的情况下解决线性注意的局限性?
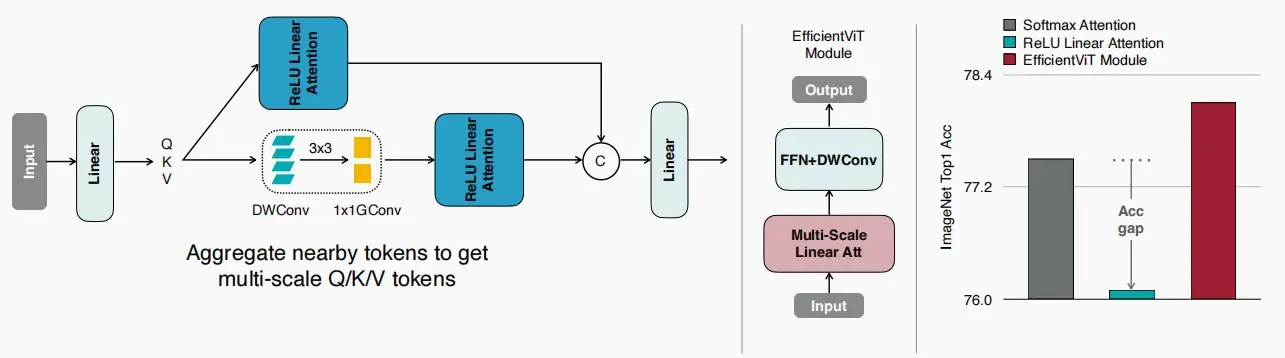
- 想到卷积可以提取局部特征,因此可以结合卷积和Linear Attention。
- 如下图,除了关键的线性注意力分支,可以添加另一个结合了卷积与线性注意力分支,在论文中采用了深度可分离卷积,这是一种轻量级的方法,随后通过组卷积来降低计算成本,并聚合邻近的token,以便进行局部特征建模,从何获取多尺度的token。
- 从右侧可以看出,准确度差距不仅得以填补,实际上还得到了提升。
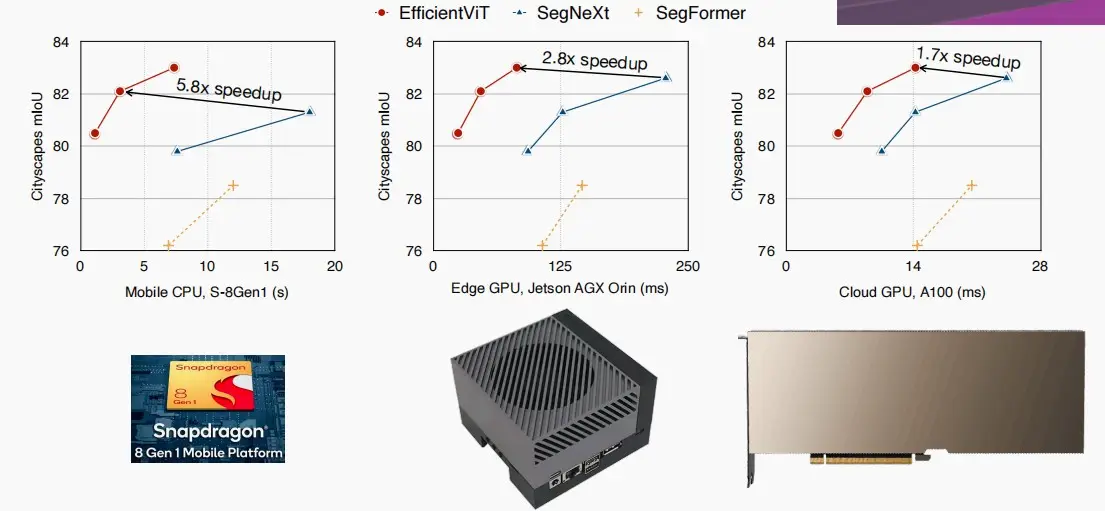
- 如图,使用Linear Attention为移动设备、自动驾驶设备以及云数据中心GPU带来了显著的速度提升,分别实现了1.7×~5.8×倍的加速。
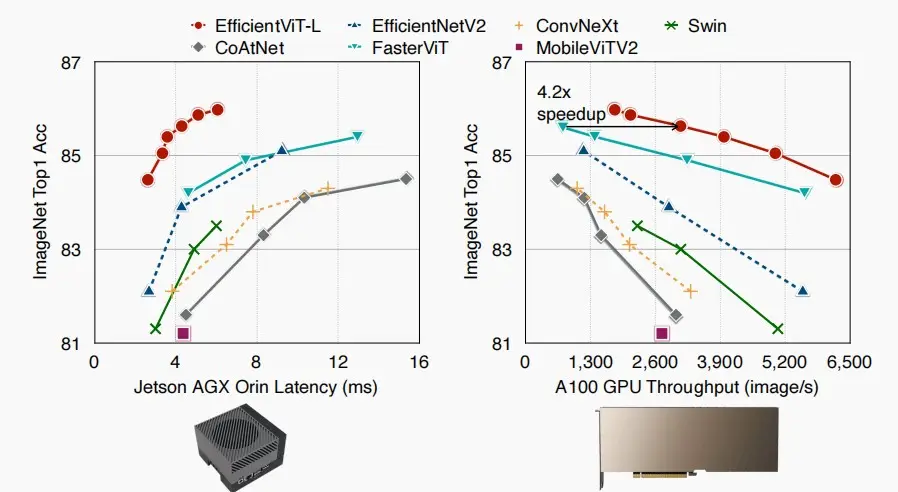
- 如下图,各模型在图像分类上的对比图,延迟与准确率的关系,吞吐量与准确率的关系,相对之下EfficientViT-L都优于其他模型。
Ⅲ、Sparse attention
- 《SparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer》 [Chen et al., CVPR 2023]
- 高分辨率和稀疏像素、低分辨率和密集像素两者相比,哪个更好?
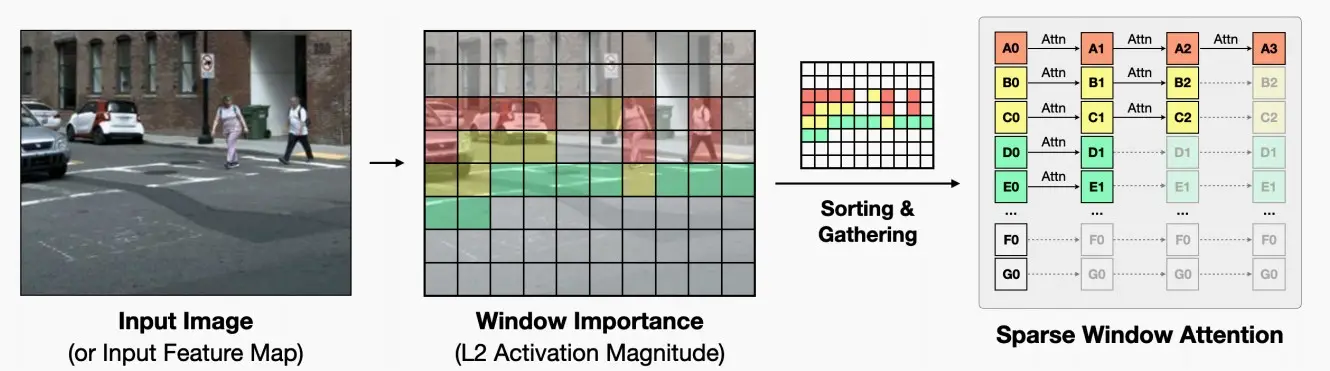
- Window Activation Pruning窗口激活剪枝
- 论文将每个patch的重要性定义为其L2激活大小,根据重要性排序对patch进行剪枝,将稀疏性引入窗口化注意力机制中。
- 与传统的权重修剪不同,重要性得分是与输入相关的,需要在推断期间计算,这可能会增加延迟。为了减少这种开销,我们在每个阶段仅计算一次窗口重要性得分,并在该阶段的所有块中重复使用,摊销开销。
- Sparsity-Aware Adaptation稀疏感知自适应
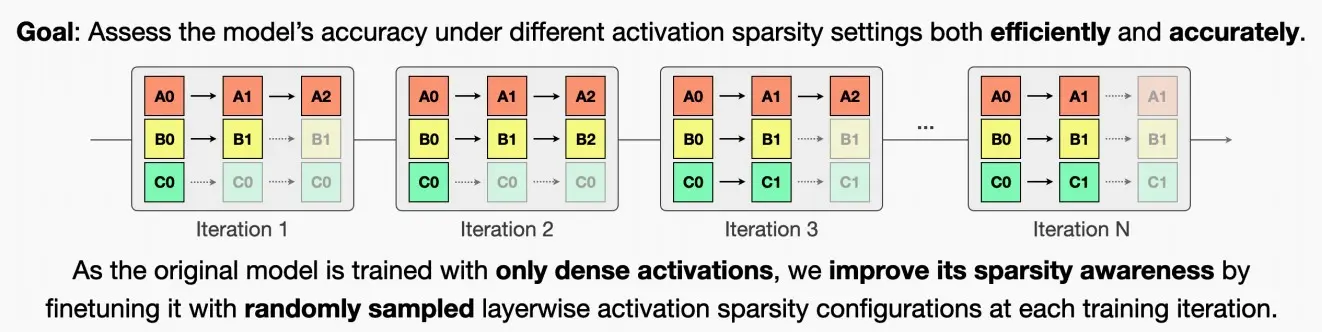
- 为了找到最优的混合稀疏配置,需要评估不同稀疏设置下模型的准确性。直接评估带有稀疏性的原始模型的准确性可能会产生不可靠的结果。
- 因此本文提出了Sparsity-Aware Adaptation,通过在每次训练迭代中,对预训练模型进行微调,采用随机抽样的层级激活稀疏性。在不同的迭代中,我们采样不同的部分,不同的子激活。这样可以在不进行全面重新训练的情况下更准确地评估不同混合稀疏配置的性能。
- Resource-Constrained Search资源受限搜索
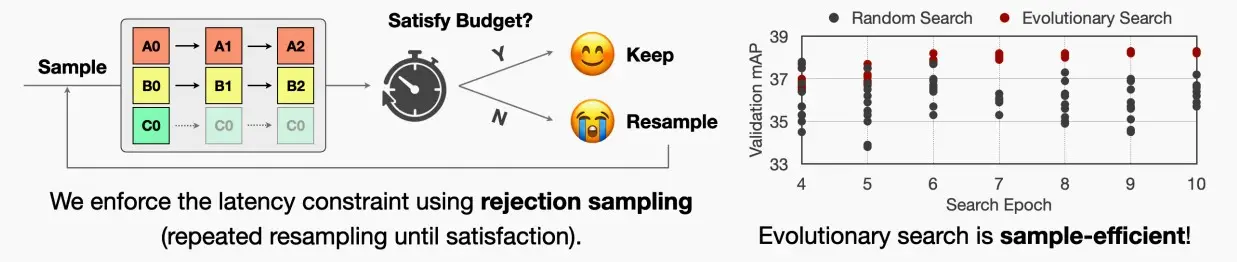
- 先通过稀疏感知适应来准确评估模型的性能后,然后在指定的资源限制内搜索最佳的稀疏配置。
- 本文考虑了两种资源限制:与硬件无关的理论计算成本以及与硬件相关的测量延迟。为了进行稀疏搜索,采用了进化算法。首先,使用拒绝抽样,即重复抽样直到满足要求,从搜索空间中随机抽取 n 个网络来初始化种群,以确保每个候选者都符合指定的资源约束条件。
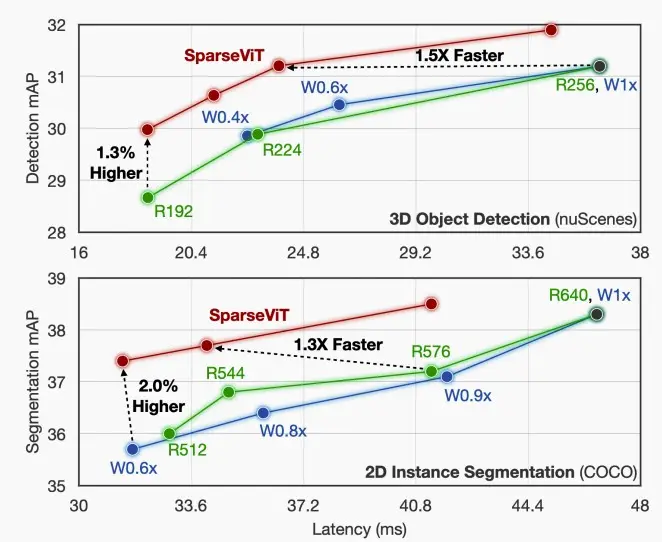
- 因此,前面的问题可以得到答案,稀疏且高分辨率(下图红线)的情况,相较于密集且低分辨率(下图蓝线)的情况更优。
三、Self-supervised learning for ViT
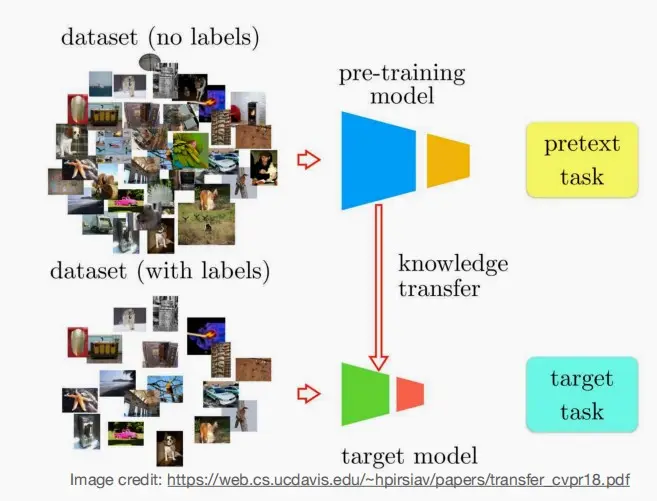
- 由第二部分开头可知,只有当数据集数量足够多时,ViT的性能才能超越CNNs。而数据集是稀有且昂贵的,因此研究利用未标记数据来训练ViT是十分有意义的,即自监督学习。
- 大致如下图,先使用未标记的数据来预训练模型,接着对于具体的下游任务,只需要使用少量的有标记数据进行知识迁移,即可使得模型适应下游任务。
Ⅰ、Contrastive learning
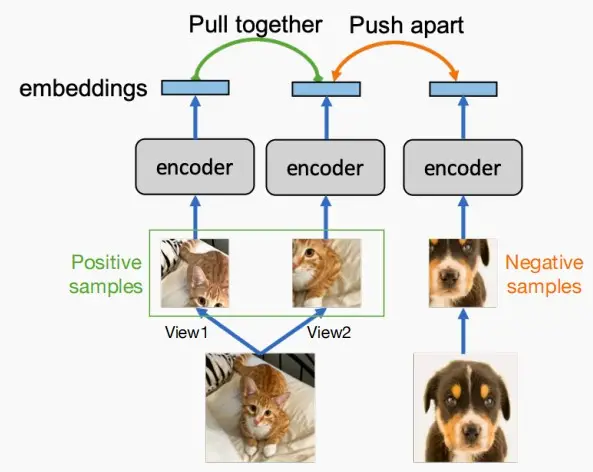
- 在对比学习中,由于没有标记,样本分为两种:
- Positive正样本:同一图像的随机视图。
- Negative负样本:其他图像的随机视图。
- 如下图中左边两边图为同一图像的两个视角,而右边两图为完全不同的猫和狗图像。
- 因此对于模型来说,应当使得正样本之间的距离足够近,而负样本之间的距离足够远,使得模型能区分它们。
- 在小数据集上直接训练大型ViT模型并不能取得良好的效果。在大多数情况下,随着模型尺寸的增加,精度会降低。
- 自监督的ViT模型比有监督的模型具有更强的性能。当使用较大的ViT模型时,精度会提高。

- Multi-Modal Contrastive Learning
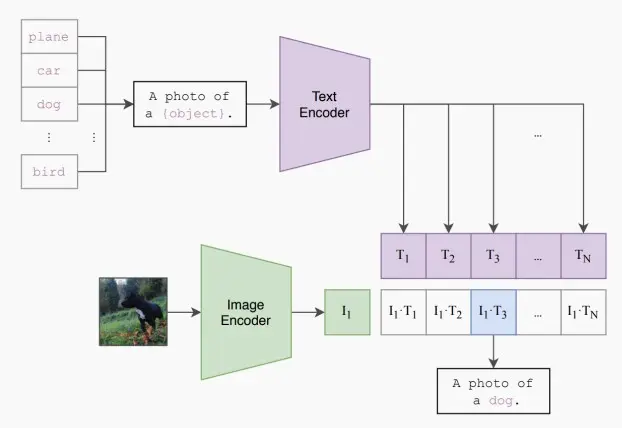
- 《Learning Transferable Visual Models From Natural Language Supervision》 [Radford et al., 2021]
- 之前只关注图像域,现在将图像与语言领域相结合,每张图像都关联着一个描述,这样我们就可以将其分别通过图像编码器和文本编码器进行处理。因此,我们可以采用这种方式,利用成对的图像与文本数据进行大规模对比学习。
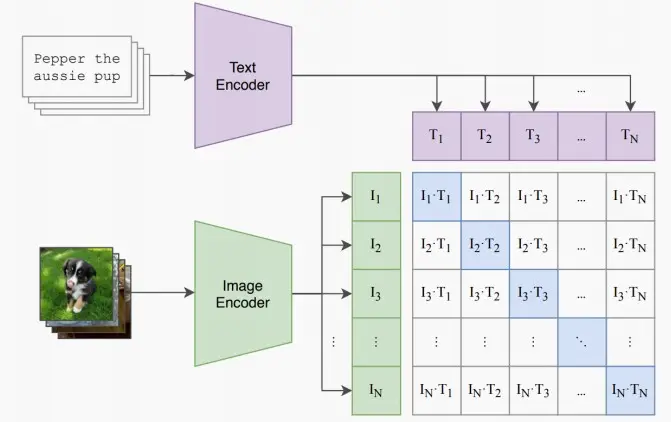
- 在推理阶段,输入一张新的图像,类别无需训练时见过,CLIP使用开放词汇应对任意数量的类别,关注不同词汇与图像之间的相似度,输出最相似的词汇。
Ⅱ、Masked image modeling
- 《Masked Autoencoders Are Scalable Vision Learners》 [He et al., 2022]
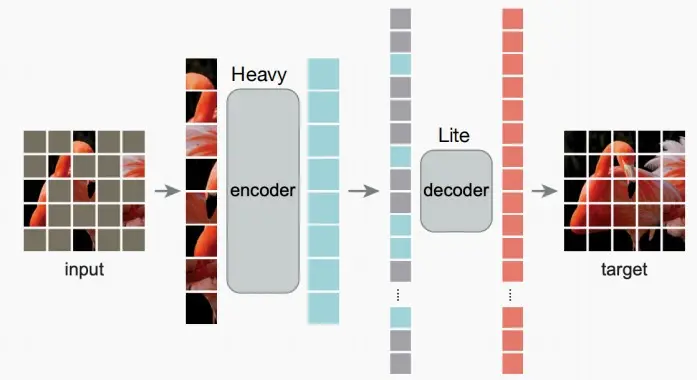
- 与掩码语言模型类似,掩码图像模型随机屏蔽图像patch,并预测它们。
- Heavy编码器只处理未被屏蔽的token。(与语言掩码模型不同,掩码token同样被输入至Transformer)
- Lite解码器处理所有token。
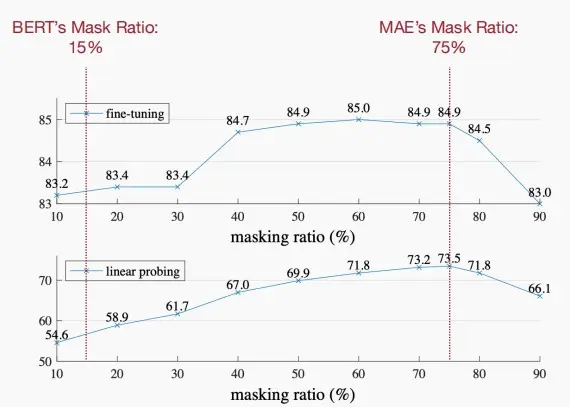
- 在视觉中使用比语言更高的掩码比:图像数据的信息密度低于语言数据。
- 如下图,对于MAE的最佳掩码比为75%,而对于掩码语言模型BERT的最佳掩码比为15%。
四、Multi-modal LLM
- 前面介绍了Transformer用于视觉的例子,现在介绍多模态LLM,包括视觉和语言。
- 主要通过两种方式
- Cross-attention to inject visual info into LLM(Flamingo)
- Visual tokens as input(PaLM-E)
Ⅰ、Cross attention (Flamingo)
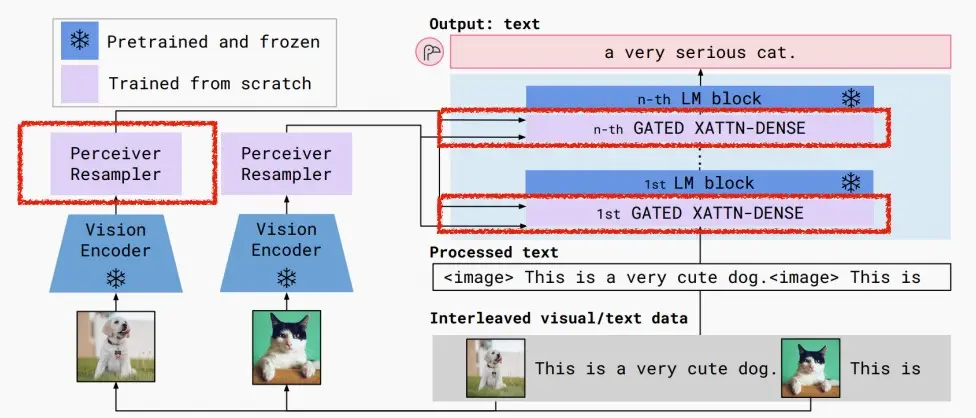
- Flamingo采用了所谓的感知重采样(Perceiver Resampler)技术和门控交叉注意力技术(Gated Cross-Attention)进行视觉多模态信息和LLM的融合,整体结构如下图所示。
- 其中视觉编码器和LLM都是固定参数而不在训练中更新。
- 感知重采样器将不同分辨率/长度的图像转换成定长的多模态语义向量,通过门控注意力单元将信息融入固定的LLM中,最终实现输入中可混合多模态信息而输出文本信息。
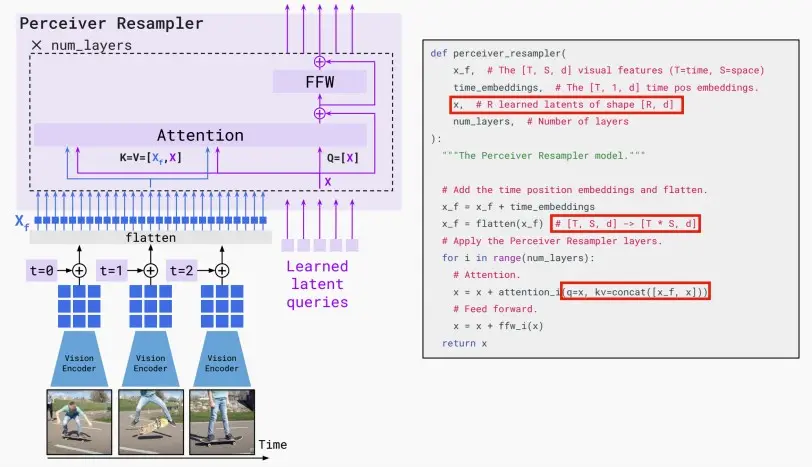
- Perceiver Resampler
- Perceiver Resampler 模块结构与伪代码如下图所示。
- 它可以接收任意多个的视频帧(如果是图像,可以视作是单帧视频),经过视觉编码器(文中是 NFNet)提取特征,加上时间embedding之后全部展平,得到一个视觉 token 序列X_f。
- 还会有一个可学习的latent query序列X,作为Q;X_f与X进行拼接作为K。
- 在经过多层 Attention + FFW 处理之后,输出固定长度的token,原文中是 64,作为视觉表征。
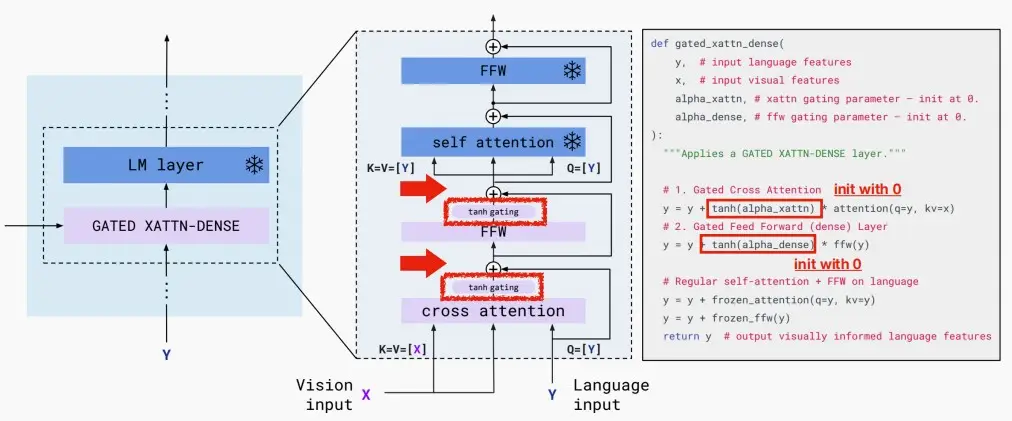
- Gated cross-attention layer
- Gated cross-attention layer模块结构与伪代码如下图所示。
- 在原先固定的LLM结构的每一层基础上叠加了门控单元,门控单元由交叉注意力机制和门控结构、FFW交替组成,其中交叉注意力的k和v都是感知重采样器的输出,而q则是文本输入。
- 为了保证在训练初始阶段模型和原先的LLM不至于偏差太远,作者采用了门控机制,具体来说就是将新层的输出乘上一个可学习的\tanh(\alpha),将LLM的原先输入与其加和,只需要在初始化时候将\alpha = 0即可确保初始化时候和原先LLM无太大偏差。
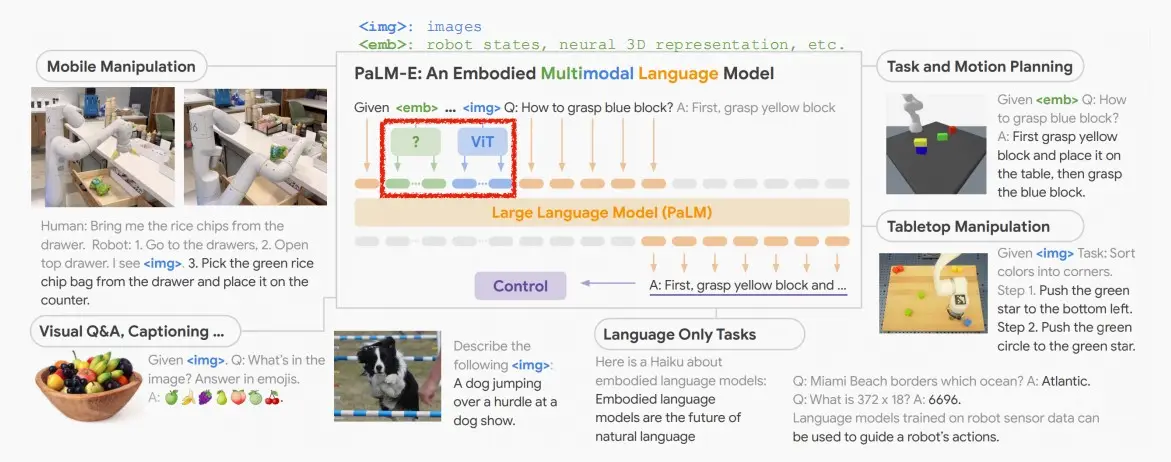
Ⅱ、Visual token (PaLM-E)
- 《PaLM-E: An Embodied Multimodal Language Model》 [Driess et al., 2022]
- 以视觉输入(或其他模式)作为token。