四、Efficient inference algorithms for LLMs
Ⅰ、Quantization
1、background
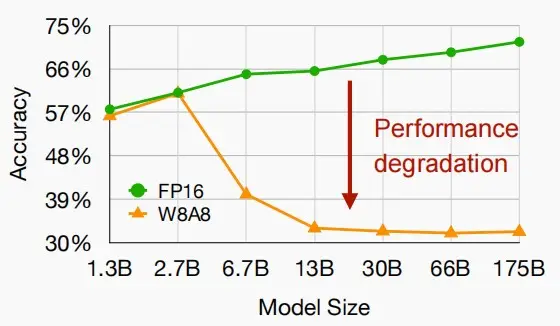
W8A8量化一直是CNNs的工业标准,但不是LLM。为什么?
当 LLMs 的模型参数量超过 6.7B 的时候,激活中会成片的出现大幅的离群点(outliers) ,朴素且高效的量化方法(W8A8、ZeroQuant等)会导致量化误差增大,精度下降 。如下图所示
什么是outliers?
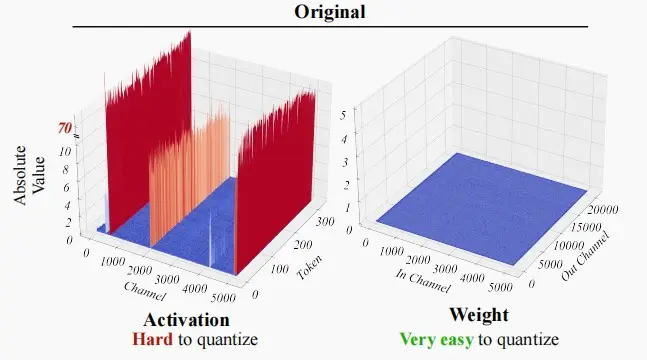
如下图LLM中激活值和权重的对比图,可以看出激活值的动态范围更大,最高值可高达70,这就是所谓i的outliers。朴素的量化方法会将绝大部分激活值变成0,导致量化误差增大,精度下降明显。相比之下,权重比较平坦,易于量化。
幸运的是,outliers存在于固定的通道中。
既然outliers仅存在固定的通道,为什么不采用逐通道量化(per-channel)?
逐通道量化虽然保留了精度,但是它与 INT8 GEMM 内核不兼容。即逐通道量化不能很好地映射到硬件加速的GEMM内核(硬件不能高效执行,从而增加了计算时间)。
2、SmoothQuant
SmoothQuant 提出了一种数学上等价的逐通道缩放变换(per-channel scaling transformation),可显著平滑通道间的幅度,从而使模型易于量化,保持精度的同时,还能够保证推理提升推理速度。
《SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models》 [Xiao et al., 2022]
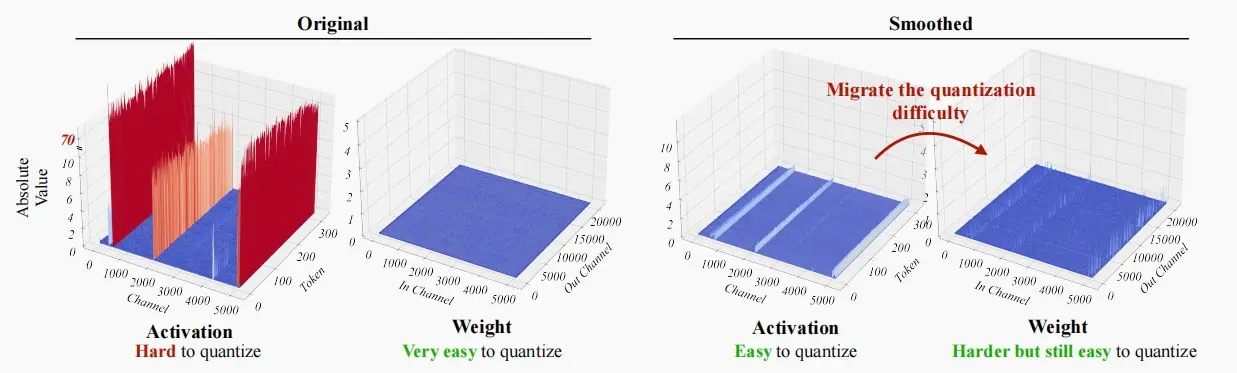
核心思想:对于等式Y=WX ,当我们把W等比例增大,X等比例减小,可以使Y保持不变,在数学上保持等价。因此同理可得,将权重扩大N倍,激活缩小N倍,数学上依旧等价,同时缩小了激活的方差。
效果:将量化难度从激活迁移到权重 ,因此两者都很容易量化。
如下图,左图为原分布,右图为Smooth处理后分布。
论文中提出了迁移强度\alpha ,来控制从激活值迁移多少难度到权重值。
一个合适的迁移强度值能够让权重和激活都易于量化。
\alpha 太大,权重难以量化,而 \alpha 太小激活难以量化。对于不同的模型,有不同的合适的迁移强度,一般0.5是一个很好的平衡点。
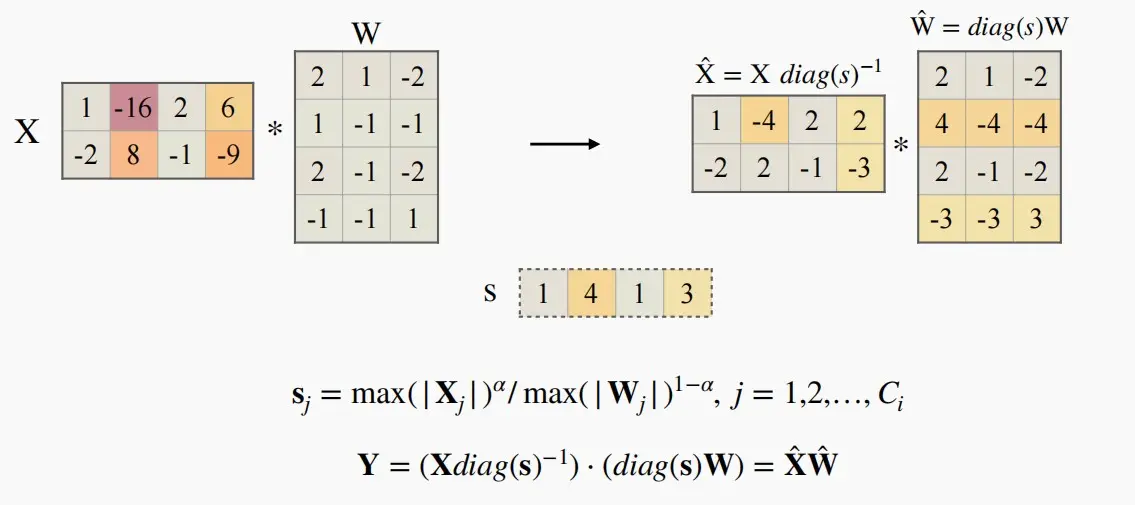
缩放因子s_j=max(|X_j|)^\alpha /max(|W_j|)^{1- \alpha },j=1,2,...,C_i
得到缩放因子后,直接对权重和激活矩阵进行缩放/增大即可。
如下图例子,采用\alpha=0.5 。
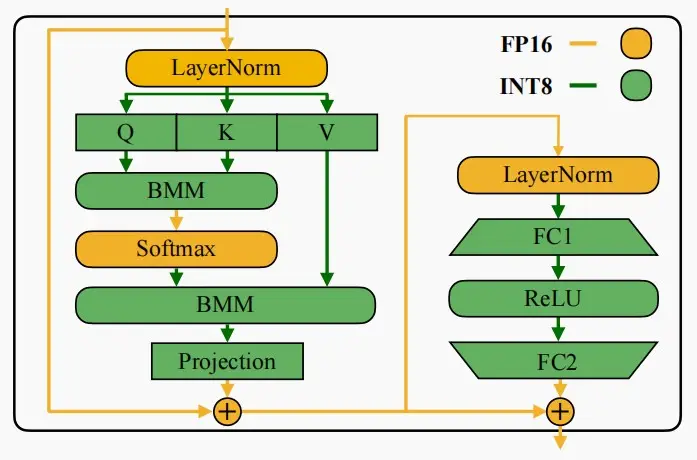
将SmoothQuant应用于Transformer
在Transformer 块中,将所有计算密集型算子(如:线性层、batched matmul (BMMs) )使用 INT8 运算,同时将其他轻量级算子(如:LayerNorm/Softmax)使用 FP16 运算 ,这样可以均衡精度和推理效率。
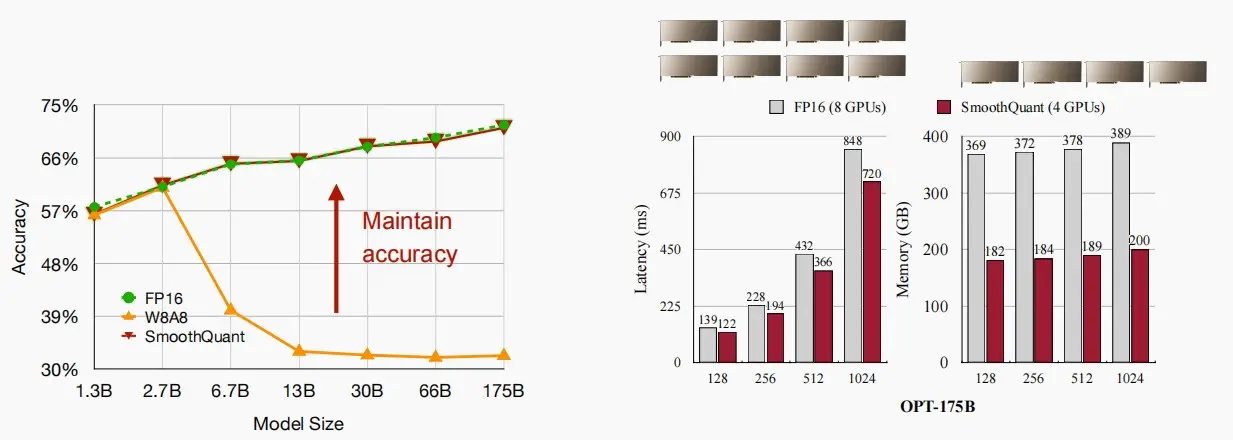
如下图,右图中使用SmoothQuant后精度仍得到很好的保持,左图中对OPT-175B进行SmoothQuant,可以看到延迟得到一定减小,且内存几乎降低1/2,效果显著。
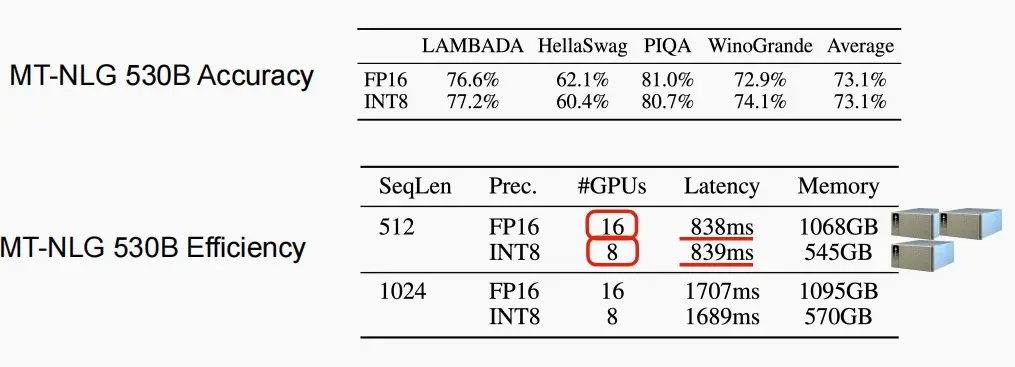
如下图对MT-NLG 530B进行SmoothQuant,精度和延迟几乎不变,而所需内存和GPU减少了一半。
作者还对LLaMA家族进行了实验,发现在Wikitext数据集上,SmoothQuant可以毫无损地量化LLaMA家族,进一步降低硬件障碍。
3、AWQ for Low-bit Weight-only Quantization
LLM解码具有高度的内存限制,W8A8是不够的。 W8A8量化适用于批量服务,例如,批量大小128。
但是对于单查询LLM推理,内存限制是十分严重的,我们需要更需要低位的权重,因为通常权重的数量远多于激活,因此可以采用W4A16对于single batch serving。
论文《AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration》 (Lin et al., 2023)提出了一种仅对权重进行量化的方法,"激活感知权重量化(Activation-aware Weight Quantization,AWQ)"方法。
仅权重量化减少了内存需求,并通过减轻内存瓶颈加速了token的生成。
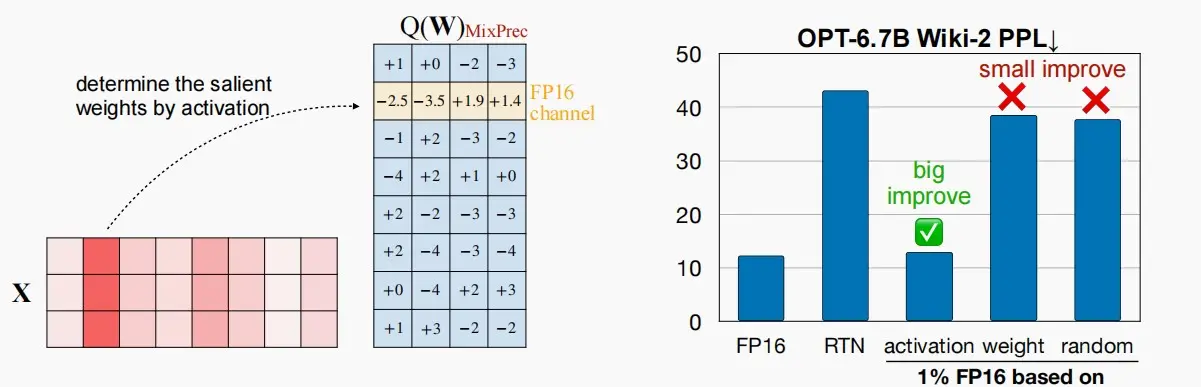
权重对于LLM的性能并不同等重要
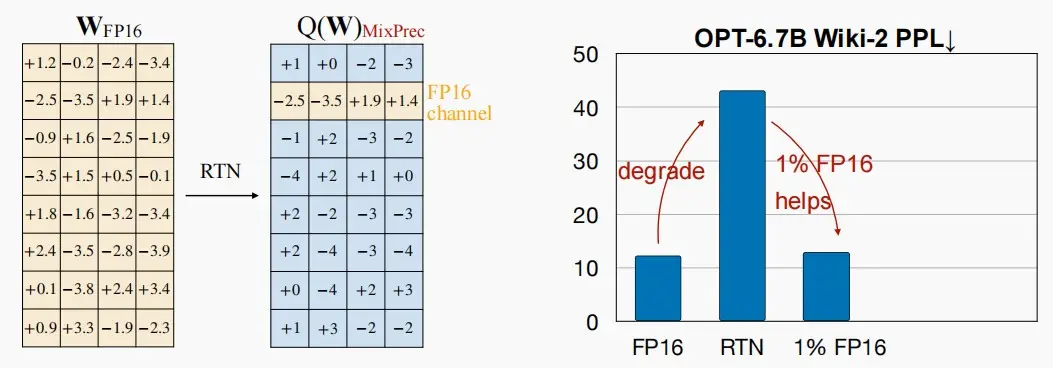
首先,作者发现对权重进行int3量化时,Wiki-2 PPL(Perplexity,困惑度指标)显著上升,这意味着直接量化权重对模型的负面影响较大。
接着,作者发现在FP16中只保留1%的显著权重通道可以大大改善困惑度。
因此,可以提出两个重要的问题:
我们如何选择显著通道呢?我们应该根据权重的大小来选择吗?
保留1%的FP16权重可能会使推理内核的实现变得困难,如何消除混合精度?提高硬件效率。
如何选择显著通道呢?
类似于剪枝,作者首先保留了较大的前1%权重,发现困惑度与随机选择接近,效果较差。
考虑到激活中的outliers,而激活与权重需要相乘,作者通过观察激活来确定哪个是显著权重,这也是为什么该方法为Activation-aware。
困惑度对比图如下,可以看出activation的困惑度较低,接近量化前。
如下消除混合精度?
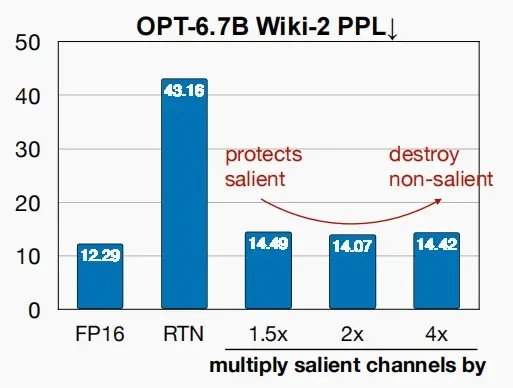
作者提出了缩放 的方法,即将权重显著通道乘s,对应激活通道除以s,数学上保持等价,s>1,以此来降低量化损失。
如下图可以看到,当s=1.5、2、4时困惑度先减后增,因此我们要考虑如何选择最佳的缩放因子s。
为什么缩放有效,且如何选择缩放因子s?
作者考虑在一个线性层通道中y=Wx ,进行量化后的损失为Q(w)x 。
原本的Q(w) = \Delta*Round(w/\Delta),\Delta=max(|w|)/2^{N-1}
缩放后,Q(ws) = \Delta'*Round(sw/\Delta) 。
首先Round() 的预期误差没有变化:由于舍入函数将浮点数映射为整数,误差大致均匀分布在 0-0.5 之间,平均误差为 0.25。
\Delta' \approx \Delta 因此可以认为Q(w) \approx Q(ws)
因此我们可以知道,缩放前后的Q() 几乎没变化,而 x->x/s ,因此量化误差减小了1/s倍。
最后,采用数据驱动的方法进行快速网络搜索,以寻找最佳的缩放因子。甚至有人提出了一种基于学习的方法,利用梯度下降来学习最佳的缩放因子。
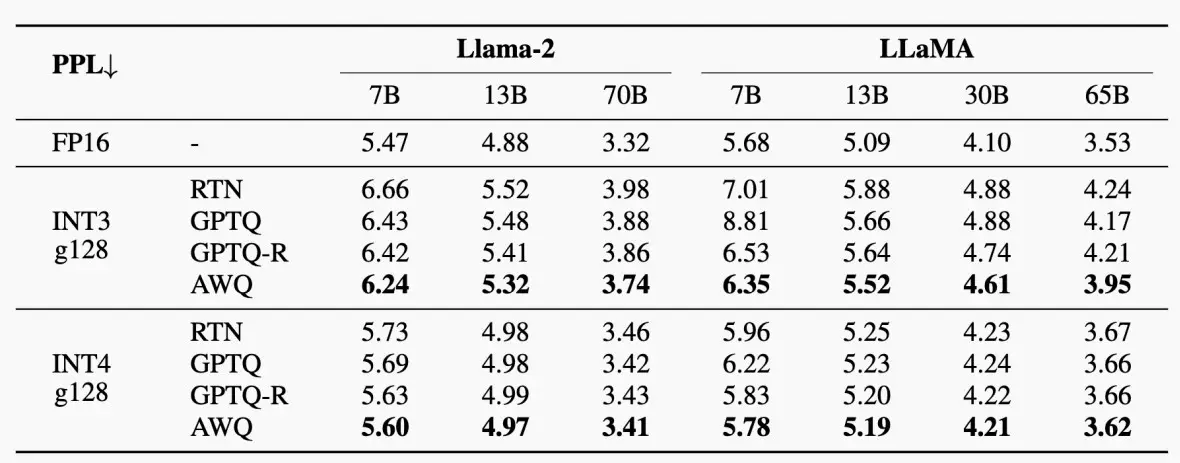
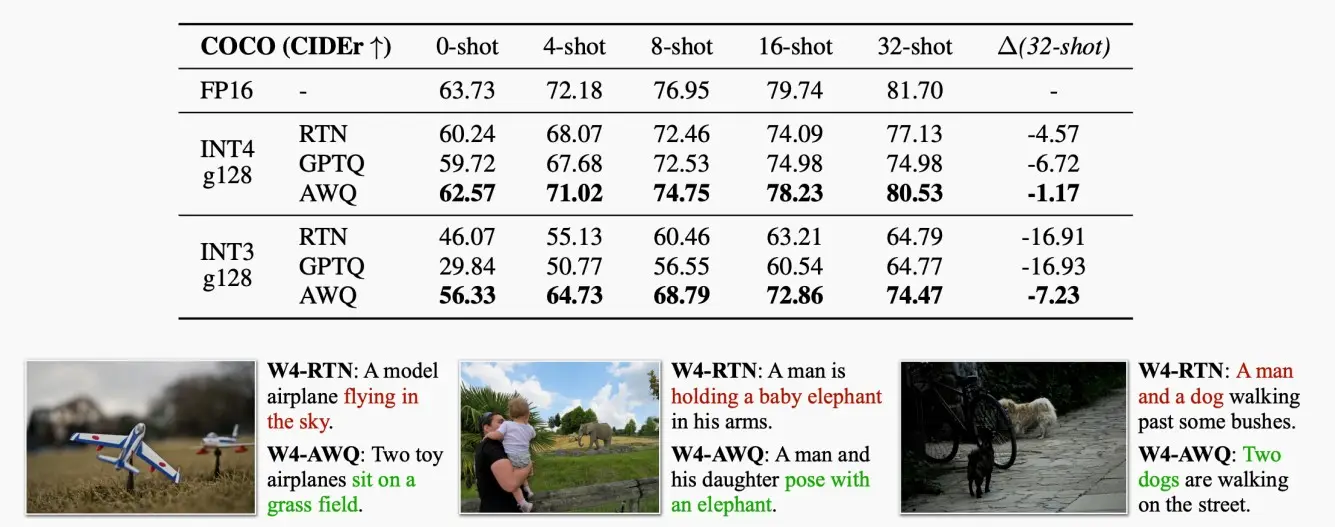
如下图为采用AWQ的效果图,图一为用于Llama,图二为用于OpenFlamingo-9B。
Ⅱ、Pruning
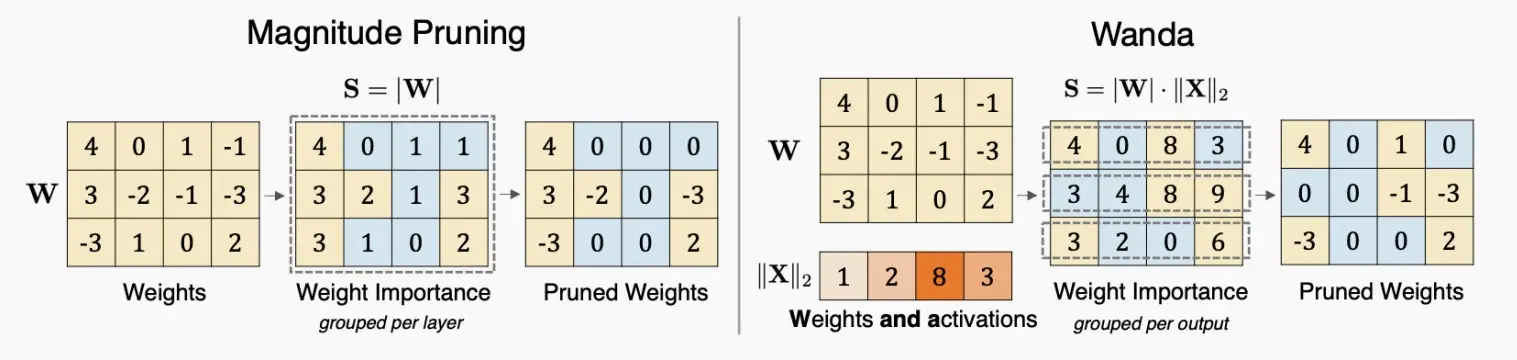
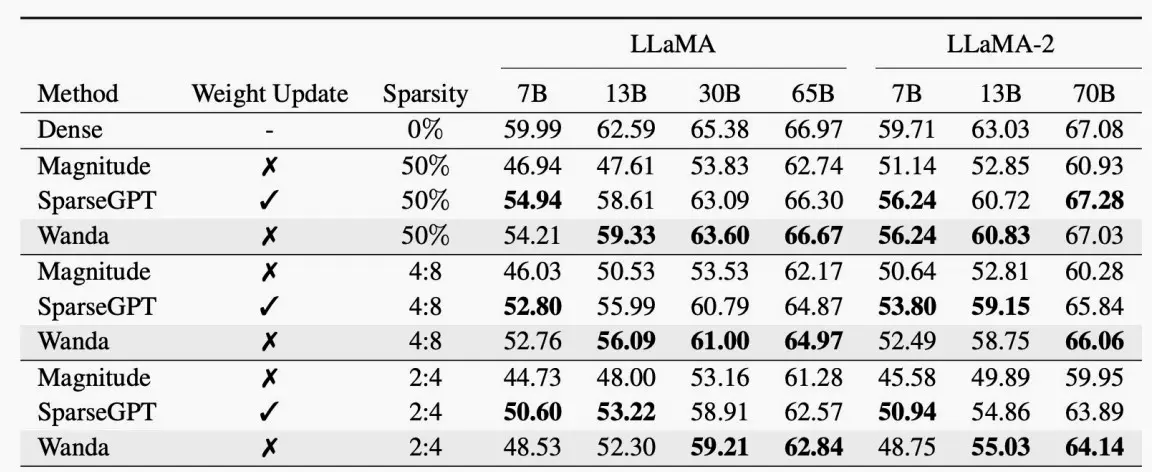
1、Wanda: pruning by considering weights and activations
与AWQ相比,剪枝也有类似的想法:在修剪权重时,我们也应该考虑激活分布,而不只是权重的幅度。
因此,剪枝标准就变成了权重×激活值。
例如下图中,左图为原剪枝,右图为Wanda,重要性=权重×激活,因此左右图的剪枝结果不同。
Ⅲ、Sparsity
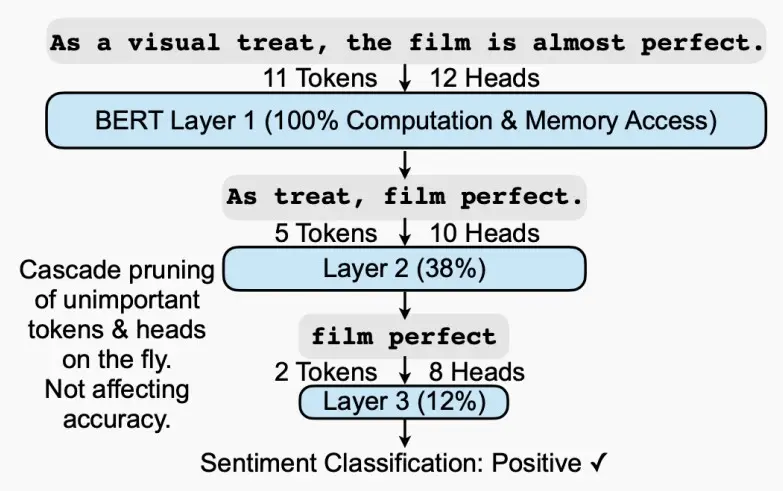
1、SpAtten:token pruning & head pruning
论文《SpAtten: Efficient Sparse Attention Architecture with Cascade Token and Head Pruning》 (Wang et al., 2020)
SpAtten中提出串联 (cascade) token和head pruning,对不重要的token和head进行剪枝 (注意区别: 传统的剪枝算法,减掉的是权重,这里减掉的是token和head)。cascade的含义是,一旦一个token或head被减掉了,在之后的层中,这个token或head也都不复存在。
如下图,逐层剪枝,并且在一层里剪去的token和head不在考虑。
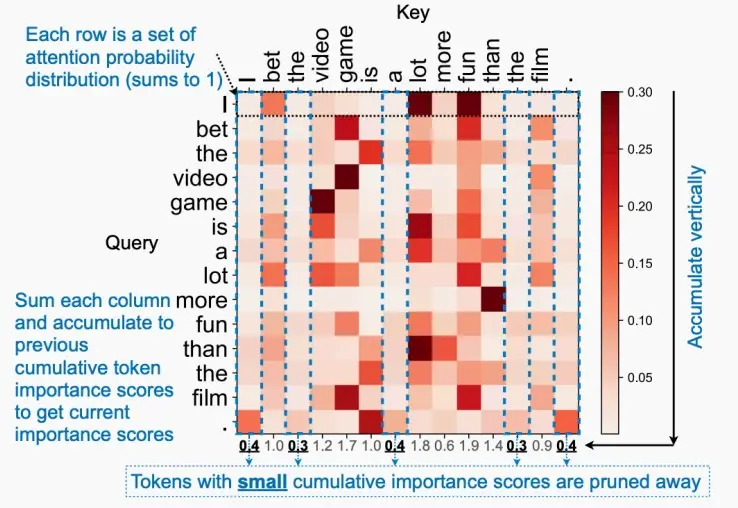
重要性衡量:SpAtten提出了累计重要性得分,如下图中11个token的注意力图,每个token的重要性为该列的注意力累计和,较低的累计重要性分数的token将被剪枝。
除此以外,SpAtten还提出了两点
V剪枝:如果QK矩阵较小,则不存取V矩阵。
渐进式量化:从低精度开始量化,如果模型不够自信(即softmax分布平缓柔和),则逐渐提高量化精度。
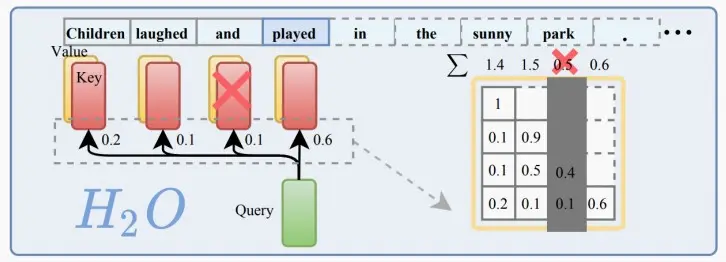
2、H_2 O:token pruning in KV cache
基于attention的观察,即在计算attention分数时,一小部分token贡献了大部分价值。我们将这些token称为heavy Hitter Tokens(H_2 )。通过全面的调查,我们发现H2的出现是自然的,并且与文本中标记的频繁共现密切相关,删除它们会导致性能显着下降。
基于这些见解,提出了 Heavy Hitter Oracle (H_2 O ),这是一种 KV 缓存驱逐策略(贪婪算法),可动态保持最近token和 H_2 token的平衡。
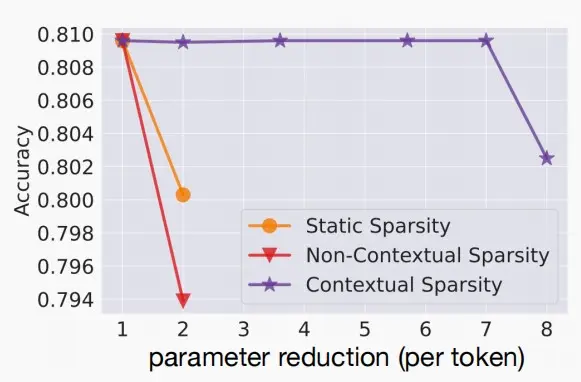
如下图静态和动态稀疏性关于参数与延迟的对比图
静态稀疏性:提供中高程度的稀疏性,但随着移除更多参数,准确度下降极为迅速。
上下文稀疏度:小的、依赖于输入的冗余头和特征集,即使进行大量压缩,也很好的保持准确度。
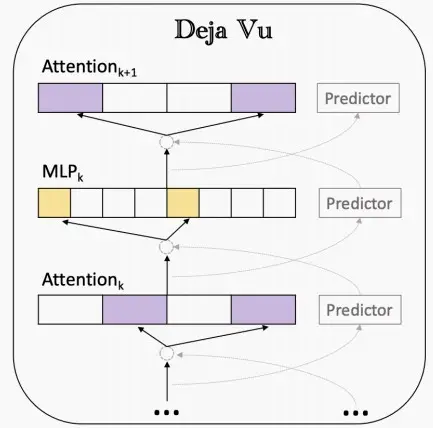
《Deja Vu: Contextual Sparsity for Efficient LLMs at Inference Time 》(Liu et al., 2023)
引入了一种利用当前特征图预测下一层所需注意力的预测器,它能够与注意力层或MLP层的计算并行运行,从而使预测器与通信过程得以重叠,最终带来显著的加速。
4、Mixture-of-Experts (MoE)
什么是MoE?
混合专家模型(MoE)是一种稀疏门控制的深度学习模型,它主要由一组专家模型和一个门控模型组成。MoE的基本理念是将输入数据根据任务类型分割成多个区域,并将每个区域的数据分配一个或多个专家模型 。每个专家模型可以专注于处理输入这部分数据,从而提高模型的整体性能。
论文《Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity》
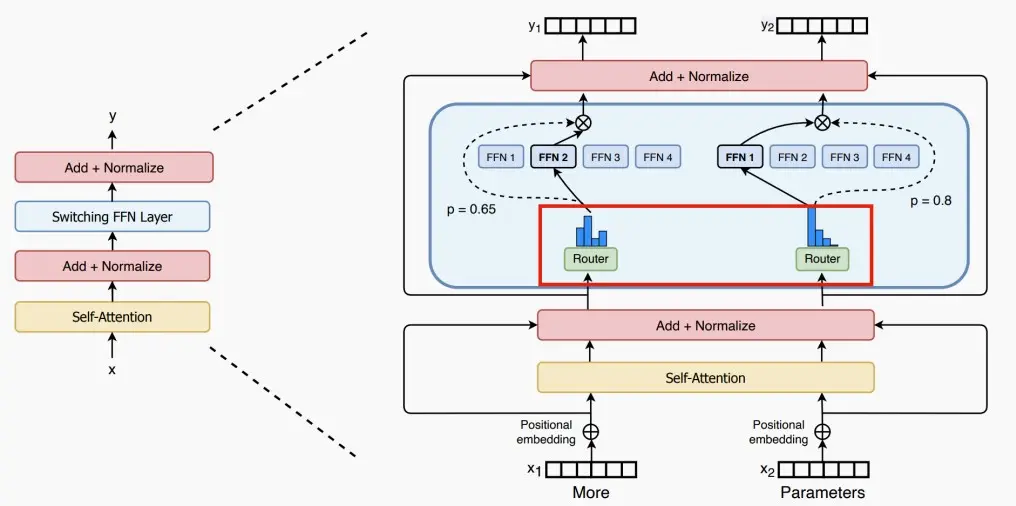
论文将MoE思想应用到Transformer中,提出了Switch Transformers架构如下图,使用一个稀疏的Switch前馈网络层(FFN)替换原本的密集FFN层,该层独立的对序列中的标记进行操作,然后路由到多个FFN专家中。
在MoE中,针对每个输入token,不需要激活整个网络。
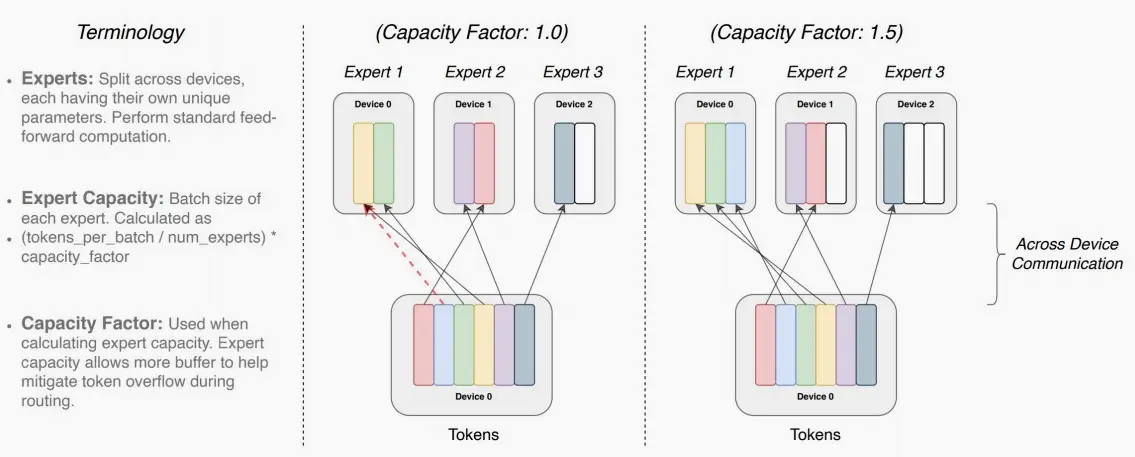
每个专家可处理的token大小=(总token数 / 专家数量)× 容量因子。如果令牌分配不均匀,那么某些专家会溢出(用虚线红线表示),导致这些令牌不会被该层处理。较大的扩容因子可以减轻这种溢出问题,但也会增加计算和通信成本(由填充的白色/空白插槽表示)。
如下图,容量因子Capacity Factor分别为1.0和1.5时路由图。
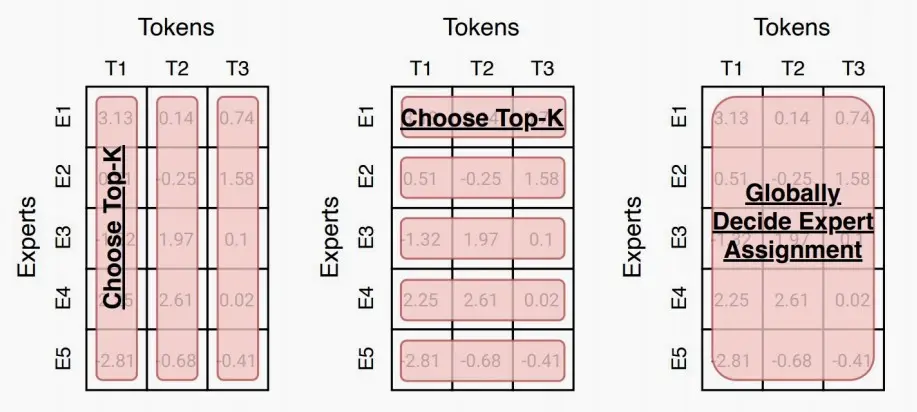
如图,Switch Transformers提出了不同的路由机制,第一种从专家维度上对每个token取前K个,第二种从token维度上对每个专家取前K个,第三种从全局决定分配。
五、Efficient inference systems for LLMs
Ⅰ、vLLM
分析KV高速缓存使用情况中的浪费:
内部碎片:由于未知的输出长度而过度分配。
保留:未在当前步骤中使用,但将在将来使用。
外部碎片:由于不同的序列长度。
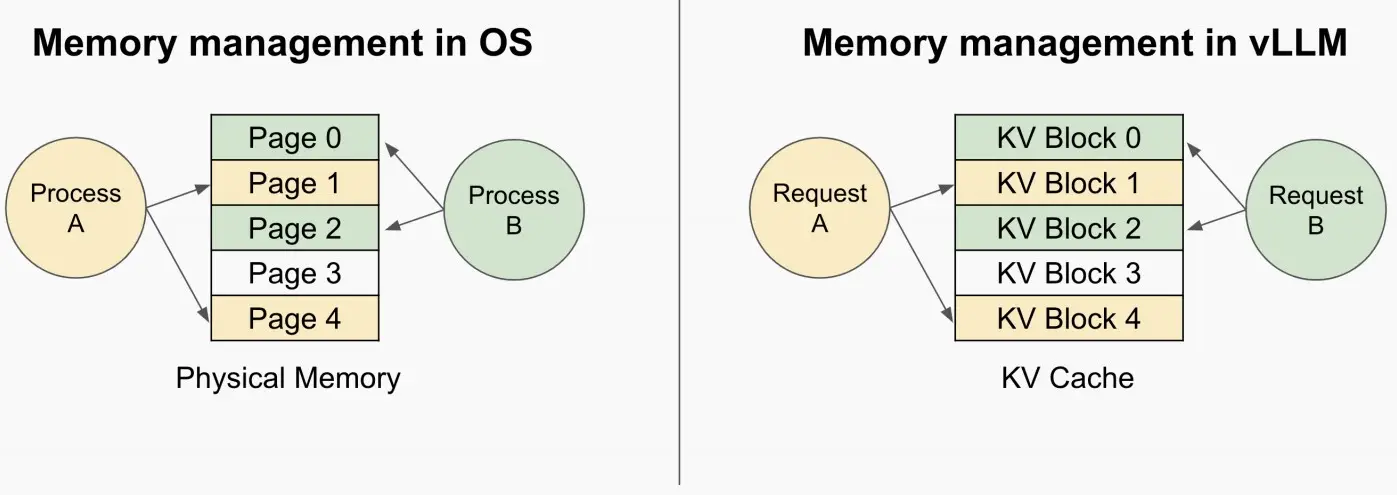
vLLM提出了Paged Attention,来自操作系统(OS)的灵感来源:虚拟内存和分页功能!
我们可以通过在此处设置一层间接寻址,类似于页表的机制,并利用这个KV block,实现动态分配。每次分配块时,产生的最大浪费即为块的大小,而非在KV缓存中大量浪费内存,尤其是在为请求长度各异的多个用户提供服务时。
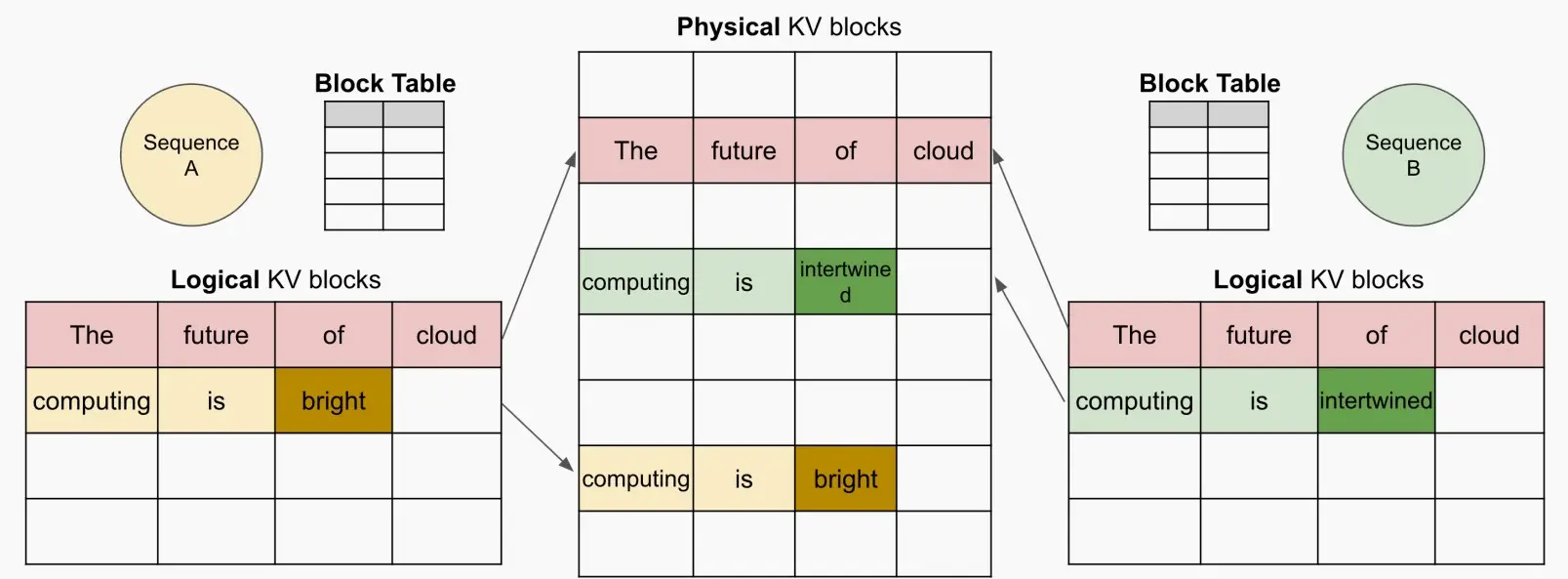
Paged Attention是如何工作的?
与OS类似,有一个逻辑KV缓存块,一个块表,一个物理KV缓存块,与OS的虚拟内存几乎一致,块表负责从逻辑到物理的映射,每个块可以存储4个token。
对一个Prompt,它在逻辑地址上是连续的,而在物理地址上是可以不连续的。
动态块映射支持在并行采样 中进行即时共享 ,如下图。
并行采样:指在给定提示的情况下预测未来,这些预测可以在不同的序列间共享。
Ⅱ、StreamingLLM
在流媒体应用程序中迫切需要llm,如多轮对话,其中需要长时间的交互。
挑战:首先,在解码阶段,缓存先前tokens的键和值状态(KV)会消耗大量内存。其次,流行的LLMs无法泛化到超出训练序列长度的更长文本。
三种现有方法的不足之处
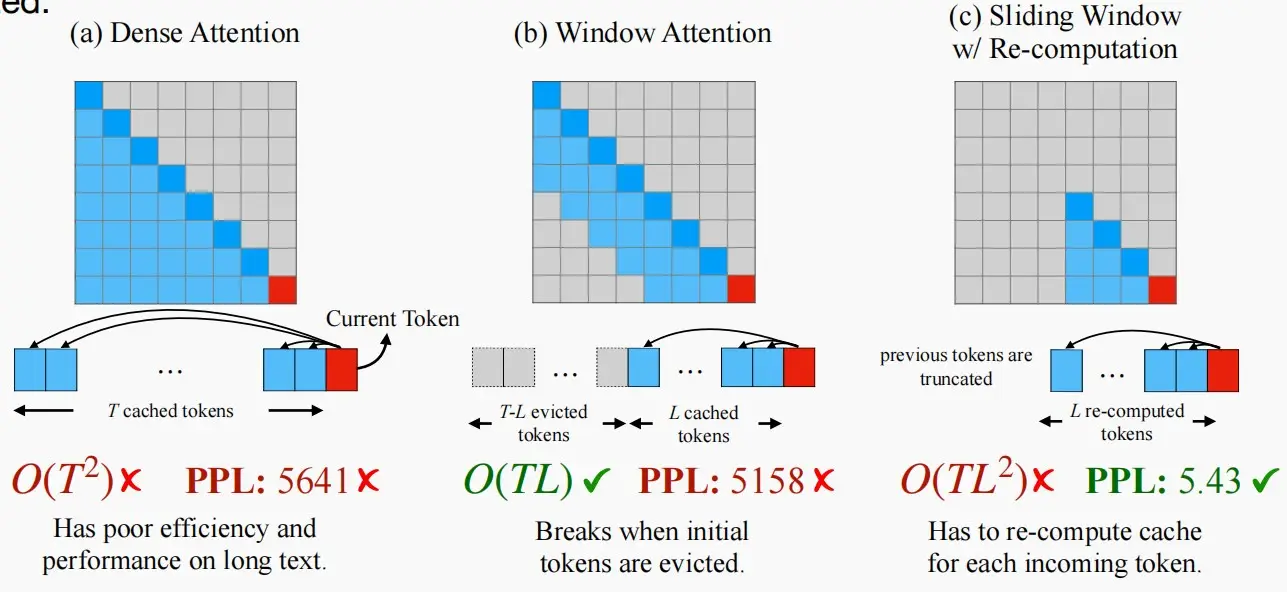
密集注意力 :具有O(T2)的时间复杂度和不断增加的缓存大小。当预测文本T远远大于预训练文本长度L(T>>L),困惑度上升性能下降。深蓝色方块是不停新增token计算注意力,重新计算softmax, 然后cache到内存中(浅蓝色方块)。直达达到L是新一个token就会开始效果变差。简单思想可以理解只需要计算深蓝色score所在行,cache浅蓝色后,softmax重新更新当前token向量(最后一行)窗口注意力 :只维护最新的token的KV状态的固定大小的滑动窗口。问题很明显虽然在缓存最初填满后确保了恒定的内存使用和解码速度,但一旦序列长度超过缓存大小,即使只是逐出第一个token的KV,模型也会崩溃。重新计算 滑动窗口:发放为每个生成的token重建最新token的KV状态(这样一直保持有初始token)。虽然它在长文本上表现良好,但它的O(T*L2)复杂性(源于上下文重新计算中的二次注意力)使得它相当慢(流应用时不行)。
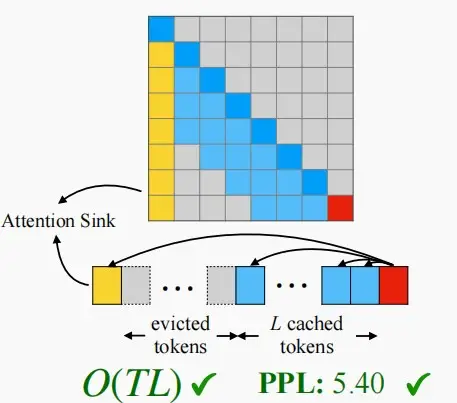
Attention Sink注意力汇聚现象
初始token有很大的注意力分数,即使它们在语义上并不显著,我们称其为注意力汇聚点。 背后的原理--Softmax
SoftMax操作在创建Attention Sink方面的作用——所有上下文令牌的注意力分数必须合计为1 。
初始token对于sink现象的推动,是由于它们对后续标记的可见性,根源于自回归语言建模,导致后续所有token都会关注第一个token。
由于softmax必须求和为1,如果某个部分不太相关,神经网络就会决定将所有注意力分数集中到第一个标记上。
初始token的重要性是来自于它们的位置还是它们的语义?
我们发现在前面添加初始四个“\n”,也会有很大的注意力分数。
因此,它们的位置更重要,语义无关。
StreamingLLM关键思想:始终如一地重新添加第一列,始终保持注意力同步,随后再对注意力进行窗口化处理。
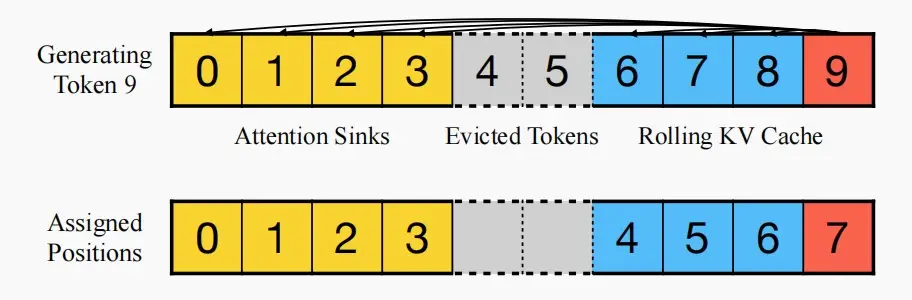
由于固定了初始token在高速缓存中,因此需要重新进行位置编码。
使用高速缓存中的位置,而不是原始文本中的位置(绝对位置)。
性能比较
比较dense attention, window attention, and sliding window w/ re-computation。
StreamingLLM显示出稳定的性能;困惑接近滑动窗口与重新计算基线。
从第一幅图可以看出sliding window w/ re-computation和StreamingLLM都有不错的困惑度,但是sliding window w/ re-computation计算复杂度很高,从第二幅图可以看出延迟提高了22.2×。
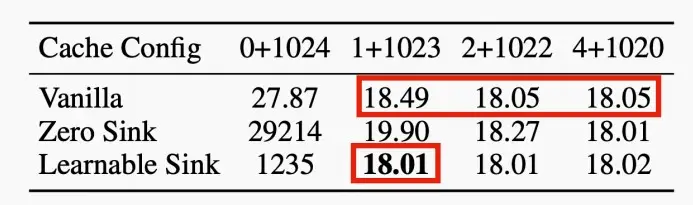
Why 4 attention sinks?
在所有训练样本开始时引入一个额外的可学习token,作为一个专门的attention sink。
这个预先训练过的模型在只使用这个单个sink token的流媒体情况下保持了性能,这与需要多个初始令牌的普通模型形成了对比。
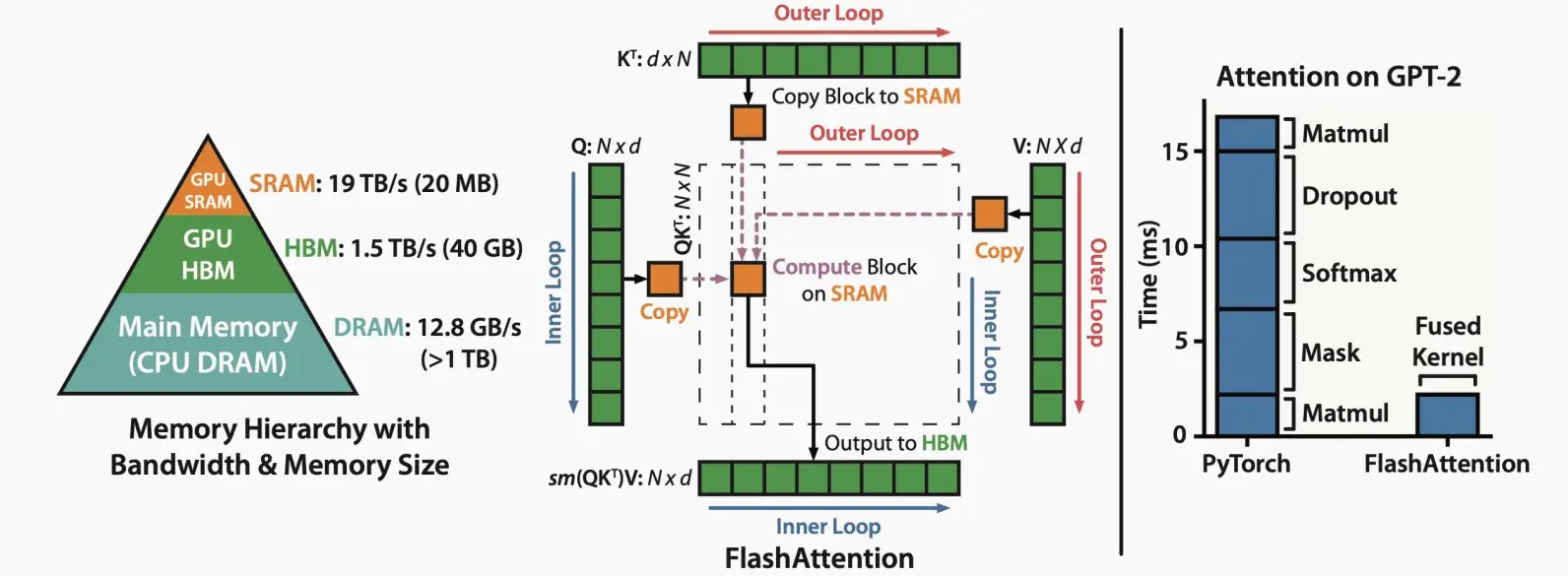
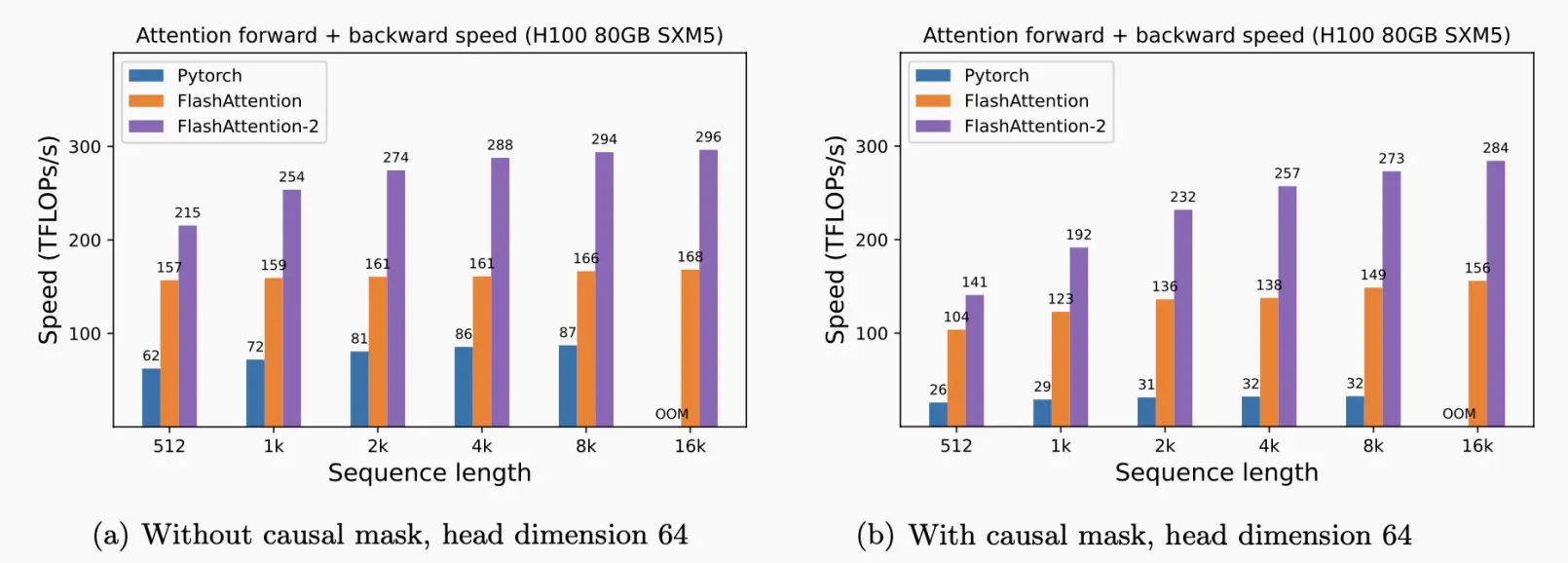
Ⅲ、FlashAttention
使用平铺来防止大型𝑁×𝑁注意矩阵的物化,从而避免使用缓慢的HBM;内核融合。
如下图中,将QKV实时计算部分在SRAM中执行,而绿色部分的数据存储在HBM中,且输出到HBM中。它可以显著的提高速度。
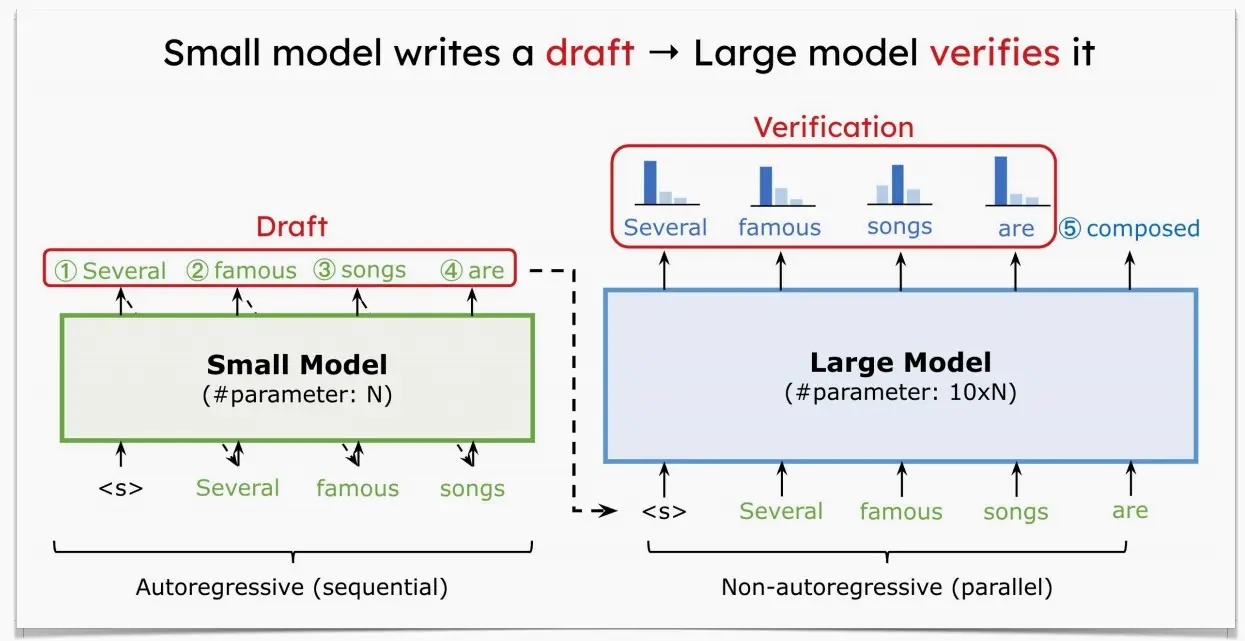
Ⅳ、Speculative decoding投机解码
LLM的解码阶段通过令牌生成输出令牌,这是高度内存限制的(特别是在小批处理大小时)。
在推测解码中有两种模型:
Draft模型:一个小型LLM(例如,7B,比原始目标模型小得多的近似模型 )
Target模型:一个大型LLM(例如,175B,我们正在试图加速的那个原始目标模型 )
过程:
草案模型将自动回归解码token。
将生成的token并行 输入目标模型,并得到每个位置的预测概率。
决定我们是想保留令牌还是拒绝它们。
下图展示随机采样的工作方式。下图中,每一行代表一次迭代。绿色的标记是由近似模型提出的token建议,而目标模型判断是否接受了这些token生成的建议。红色和蓝色的标记分别表示被拒绝和其修正。
例如第一行,小模型生成的'bond'被大模型拒绝,并给出建议'n'。
第二行中,小模型生成'nikkei 22',被大模型接受。
以此类推,由于用大模型对输入序列并行地执行,大模型只forward了9次,就生成了37个tokens。尽管总的大模型的计算量不变,但是大模型推理一个1个token和5个token延迟类似,这还是比大模型一个一个蹦词的速度要快很多。
六、Efficient fine-tuning for LLMs
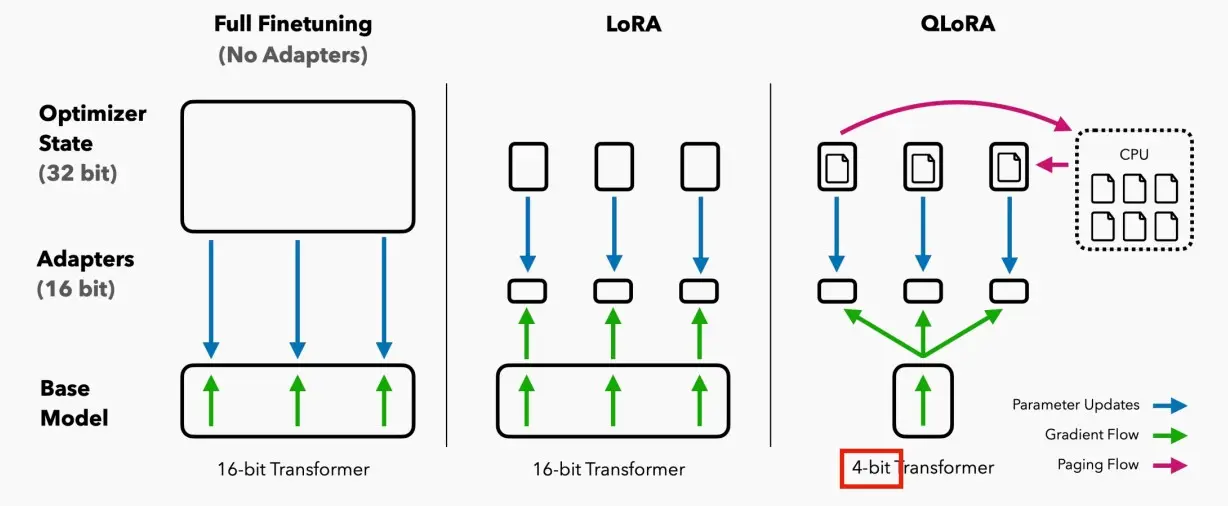
Ⅰ、LoRA/QLoRA
1、LoRA
《LoRA: Low-Rank Adaptation of Large Language Models》 (Hu et al., 2021)
大型语言模型/扩散模型的低秩自适应(Low-rank adaptation)
核心思想:与其更新完整的模型权重,不如更新一个小的低秩组件。
优势:
通过跳过梯度计算来加快微调速度。
通过减少optimizer的状态来节省微调内存。
防止灾难性遗忘。
低秩的权值可以被融合。
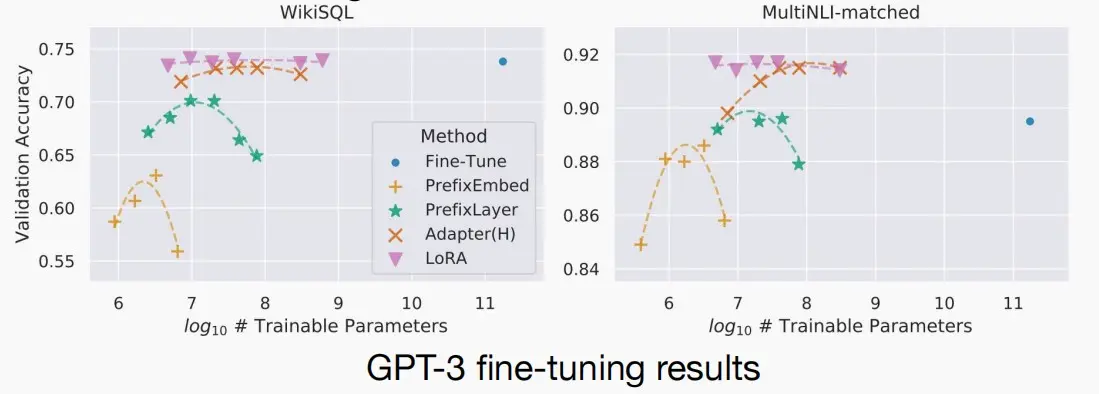
下图为对GPT-3使用几种微调方法后,参数大小和准确性的效果图:
2、QLoRA
《QLORA: Efficient Finetuning of Quantized LLMs》 (Dettmers et al., 2023)
QLoRA是一种新的微调大型语言模型(LLM)的方法,它能够在节省内存的同时保持速度。其工作原理是首先将LLM进行4位量化,从而显著减少模型的内存占用。接着,使用低阶适配器(LoRA)方法对量化的LLM进行微调。LoRA使得改进后的模型能够保留原始LLM的大部分准确性,同时具有更小的体积和更快的速度。
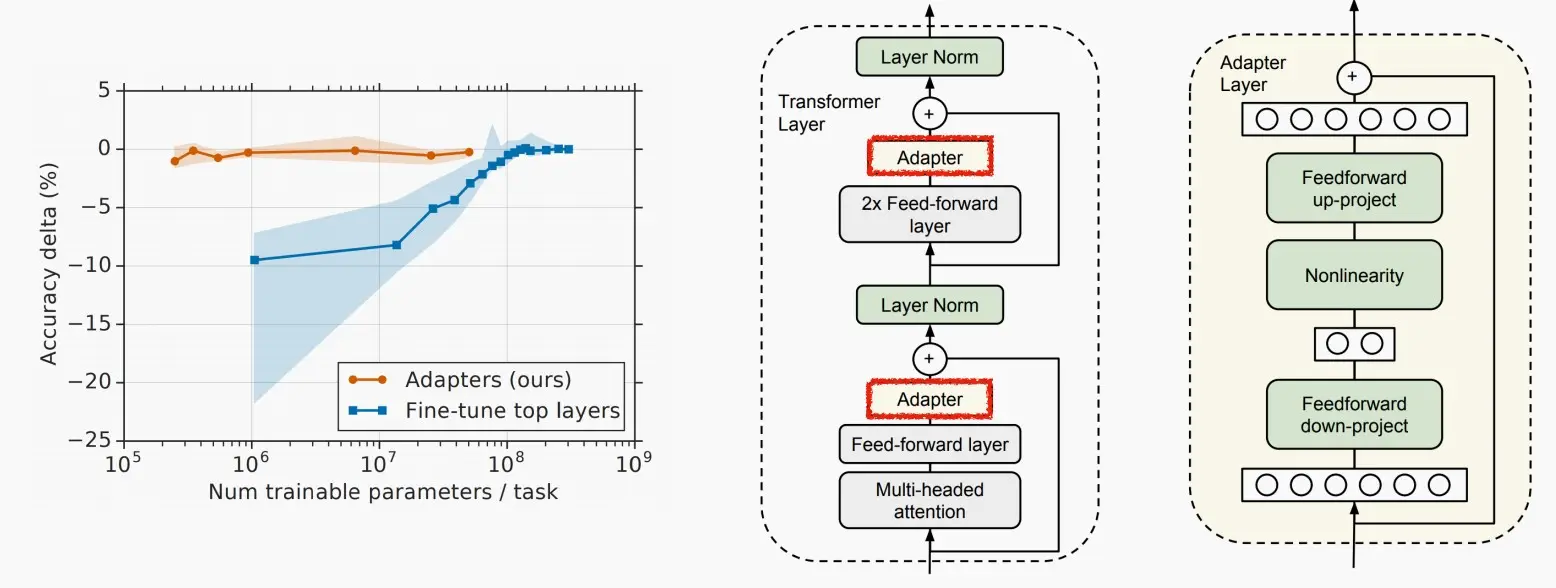
Ⅱ、Adapter
《Parameter-Efficient Transfer Learning for NLP》 (Houlsby et al., 2019)
Adapter Tuning 是一种参数高效的迁移学习方法,它允许在预训练语言模型(PLM)的基础上,通过仅调整模型的一小部分参数来实现与全量参数微调相近的效果 。其核心思想是在Transformer模型的每个层中增加额外的参数,这些参数被称为Adapter 。
Adapter模块的设计是紧凑且可扩展的,它通过在多头注意力和前馈网络之后增加两个前馈子层来实现,这两个子层分别是降维和升维的前馈网络,通过控制中间维度的大小来限制参数量。
AdapterTuning在训练时固定原始预训练模型的参数,只对新增的Adapter结构进行微调,从而提高了训练的效率 。AdapterTuning的优势在于,它只需要为每个任务添加少量的可训练参数,并且可以为新任务添加新的Adapter模块而无需重新访问以前的任务,原始网络的参数保持固定。在GLUE基准测试中,AdapterTuning证明了其有效性,获得了与全量微调性能相近的结果,同时每个任务只添加了少量参数 。
上述笔记摘自此处
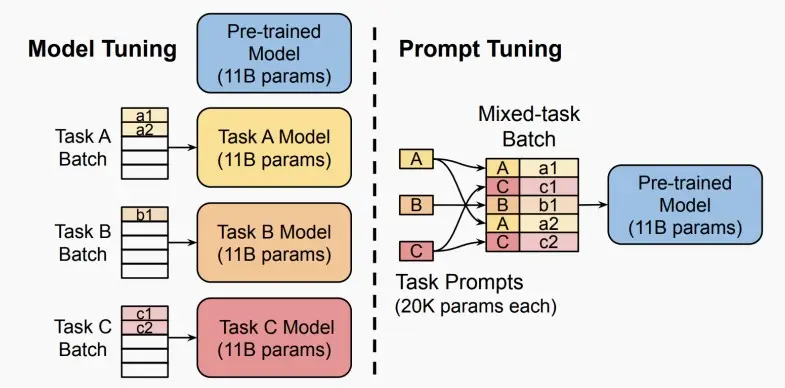
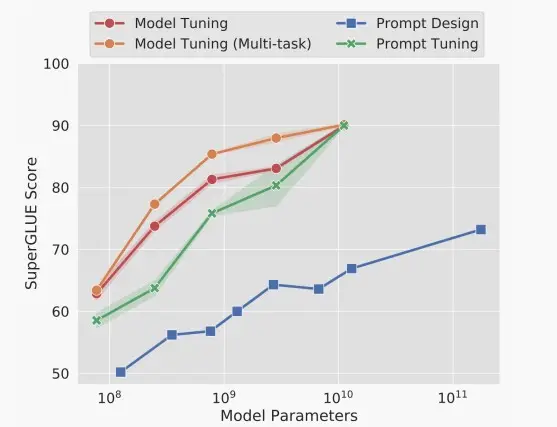
Ⅲ、Prompt Tuning
提示工程可以帮助LLM在不同的下游应用程序上工作,例如,“请总结以下文本:”。
我们可以训练一个连续的提示符,并预先准备好每个任务的输入。
我们可以在单个批中混合不同的学习提示。
上一篇
[MIT6.5940] Lect 14 Vision Transformer
下一篇
[MIT6.5940] Lect 12 Transformer and LLM (Ⅰ)
![[MIT6.5940] Lect 13 Transformer and LLM (Ⅱ)](/upload/宏村.webp)