![[MIT6.5940] Lect 12 Transformer and LLM (Ⅰ)](/upload/宏村.webp)
一、Transformer basics
Ⅰ、Pre-Transformer Era
- NLP Tasks
- 判别性任务:情感分析、文本分类、文本含义
- 生成性任务:语言建模、机器翻译、摘要
- Recurrent Neural Networks (RNNs)
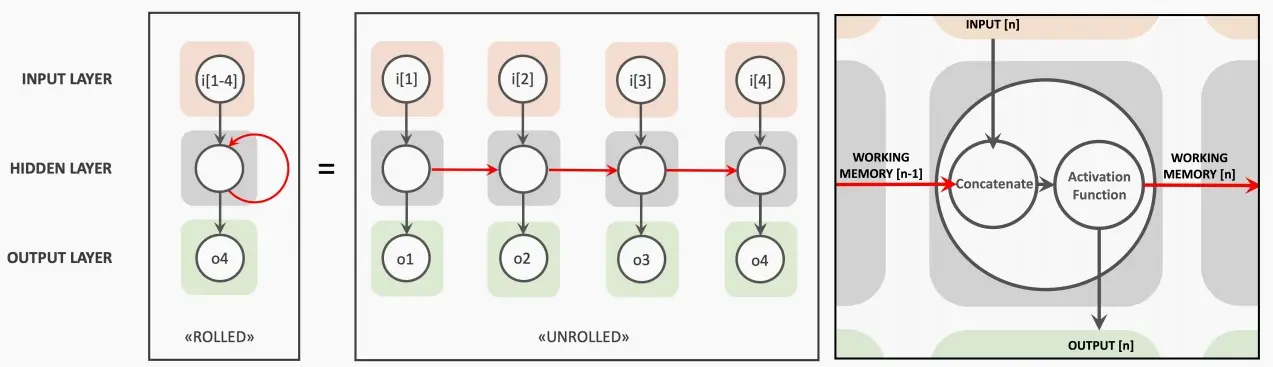
- 在Transformer时代之前,人们采用RNN及LSTM来构建语言模型。
- 每个RNNs都包含一个输入层、隐藏层和输出层,当按时间步进行计算时,隐藏状态不仅依赖于当前输入,还依赖于前一个隐藏状态,两者相结合后通过激活函数传递。
- “工作内存”难以保存长期的依赖关系(可以通过LSTM来解决),并且在tokens之间存在依赖性,这限制了可伸缩性。
- Convolutional Neural Networks (CNNs)
- 使用卷积,tokens之间没有依赖性,从而导致更好的可伸缩性。
- 但这里的局限在于,尽管可以拥有多层结构,你仍然受限于有限的上下文或感受野。这限制了上下文信息的获取,导致建模能力受限。而自然语言任务中,上下文具有重要作用,因此卷积不是最佳方案。
- NLP with RNN/LSTM
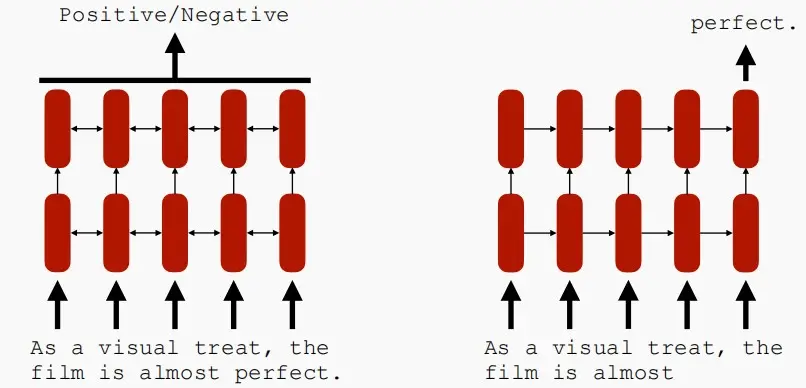
- 利用RNN和LSTM,我们可以得到双向RNNs(Bi-directional RNNs)和非双向RNNs(Uni-directional RNNs)。
- 双向RNNs:用于判别类任务,双向不仅能看到当前的词,还能看到未来的词。
- 非双向RNNs:用于生成类任务,因为在生成任务中,只能看到前一个词,但无法看见未来的词,颖仓状态的方向是单向的。
- 从下图中可以看出生成任务和判别任务中隐藏状态的区别,对于生成任务,隐藏状态依赖于前一个和后一个隐藏状态,而对于判别任务,隐藏状态仅依赖于前一个隐藏状态。
- Problem with RNNs/LSTMs
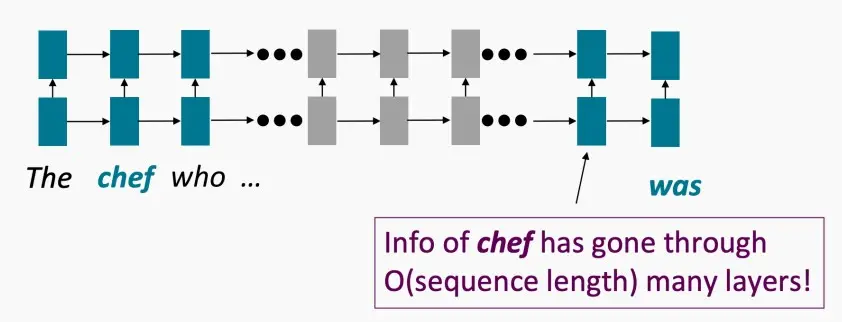
- 很难建模long-term的关系
- 它需要O(seq_len)步骤来建模两个标记之间的相互作用,例如下图一中,若要处理'chef'和'was'之间的关系,需要穿越O(seq_len)层。
- 图像具有局部性,但语言可能没有局部性,因此自然语言任务中存在较多long-term的关系需要处理。
- 有限的训练并行性
- 每一个状态都严格地依赖于早期的状态,因此具有较强的依赖性,导致并行的难度下降。
- 强依赖性意味着它需要n步才能得到状态n。
- 很难建模long-term的关系
Ⅱ、Transformer
1、Tokenize words (word -> tokens)
- Tokenization分词:将人理解的单词words转化为计算机能理解的tokens。
- 如下图中的分词结果,将一个单词映射到一个/多个tokens,例如图中generative、constrained被分词为多个tokens。因此,一个单词可以映射多个tokens,但是一个tokens只属于一个单词。

2、Map tokens into embeddings
- One-Hot Encoding
- 关键思想:将每个单词表示为一个向量,该向量中的值与词汇表中的单词一样多。一个向量中的每一列表示一个词汇表中的一个可能的单词。
- 缺点:对于大型词汇表,这些向量可以变长,并且它们包含除一个值之外的所有0。这是一个非常稀疏的表示。

- Word Embedding
- 关键思想:通过查找表,将单词索引映射到一个连续的词嵌入中。即设置一定的维度,每个词映射一个向量。
- 单词嵌入可以用模型端到端训练。
- 流行的预训练单词嵌入: Word2Vec,GloVe。

3、Embeddings go through transformer blocks
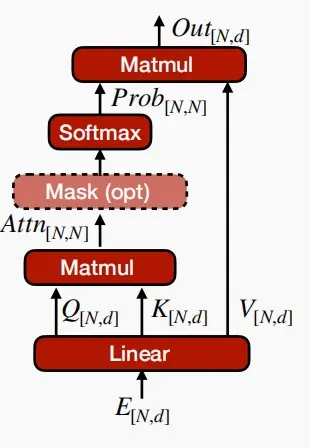
Multi-Head Attention (MHA)
- 多头注意力机制是transformer的重要组成部分
- Self-Attention
-
将词嵌入映射到query、key和value (Q,K,V) 三个独立的向量上。
- Q=XW^Q,K=XW^K,V=XW^V,其中W^Q,W^K,W^V是三个可训练的参数矩阵
-
查询键值的设计类似于一个检索系统(以YouTube搜索为例)
- query查询:搜索栏中的文本提示
- key键:视频的标题/描述
- value值:相应的视频
-
核心公式:Attention(Q,K,V) = softmax(QK^T/\sqrt{d_k})V
- Q和K_T经过MatMul,生成了相似度矩阵。
- 对相似度矩阵每个元素除以\sqrt{d_k},d_K为的维度大小。这个除法被称为Scale。当d_K很大时,QK_T的乘法结果方差变大,进行Scale可以使方差变小,训练时梯度更新更稳定。
- 然后经过SoftMax,最后与V做一个MatMul操作得到结果。
-
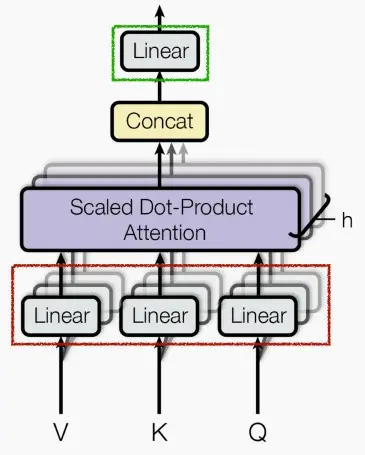
- Mutil-Head Self-Attention
- 核心公式:MultiHead(Q,K,V)=Concat(head_1,...,head_n)W^0,where head_i = Attention(QW_i^Q,KQW_i^K,VW_i^V)。
- 我们需要不同的注意力映射来捕捉不同的语义关系。
- 多头注意力通过多个head(平行的注意分支)来模拟不同的注意功能。每个head关注的子空间不一定是一样的,那么这个多头的机制能够联合来自不同head部分学习到的信息,这就使得模型具有更强的认识能力。
- 最终的输出被连接起来,并通过一个线性投影来合并特征。
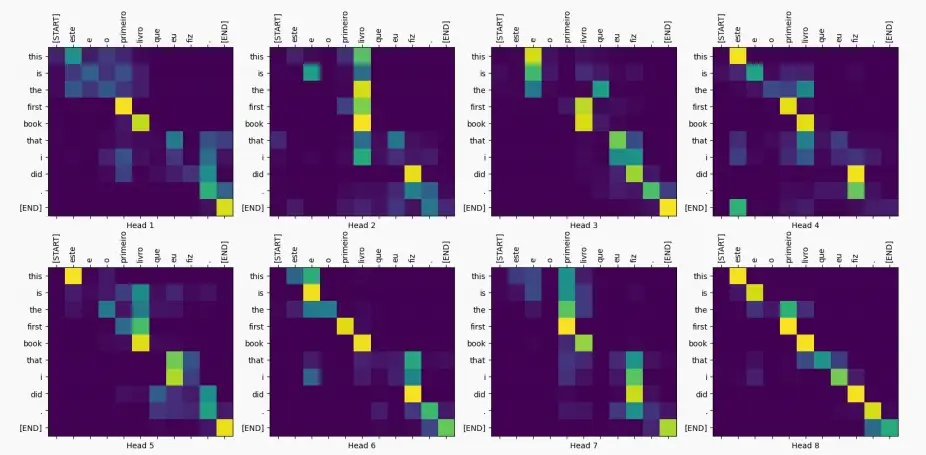
- 例如下图中,八个head关注到了八张注意力图,以便更细致地捕捉关系中的细节。
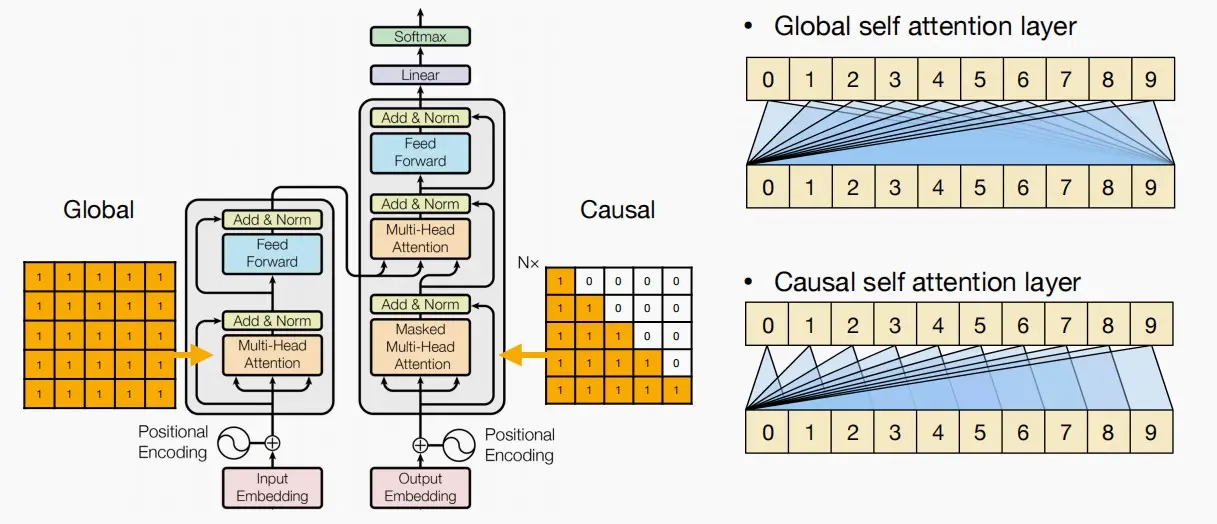
- Attention Masking
- 正如前面所述,判别任务和生成任务的token具有一定区别,判别任务token应该能看见其他所有token,而生成任务token应该只能看见前面的token。
- 如图所示,右上的为判别任务,右下的为生成任务。
Feed-Forward Network (FFN)
-
为什么我们需要一个前馈网络?
- 自我注意模型只是token之间的关系,但我们还需要学习元素级的非线性函数关系,并将这些特性应用于每个隐藏维度。
- 因此添加一个前馈网络(FFN),以辅助每个隐藏维度进行特征建模。
-
朴素实现是一个两层的MLP,具有更大的隐藏状态大小(反向瓶颈)和ReLU/GeLU激活。
FFN(x) = max(0,xW_1+b_1)W_2+b_2
LayerNorm & Residual connection
- LayerNorm
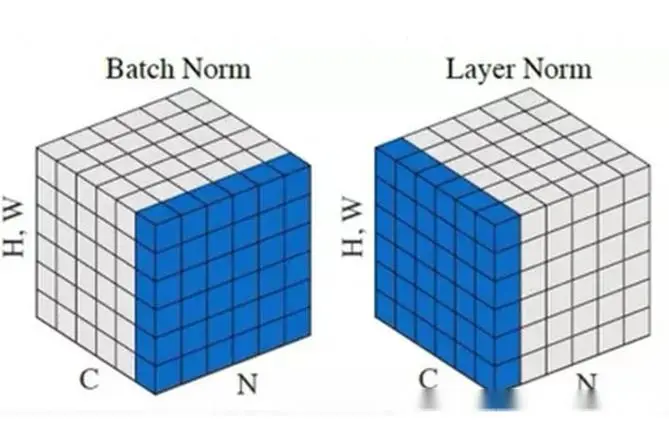
- 与CNNs中的BatchNorm(BN)不同,transformer使用LayerNorm(LN)。
- BatchNorm是对一个batch-size样本内的每个特征做归一化,而LayerNorm是对每个样本的所有特征做归一化。
- BN抹杀了不同特征之间的大小关系,但是保留了不同样本间的大小关系;LN抹杀了不同样本间的大小关系,但是保留了一个样本内不同特征之间的大小。
- LN对每个令牌的嵌入进行归一化,然后应用一个可学习的仿射变换。
- 与CNNs中的BatchNorm(BN)不同,transformer使用LayerNorm(LN)。
y = \frac{x-E[x]}{\sqrt{Var[x]+\epsilon}} * \gamma + \beta
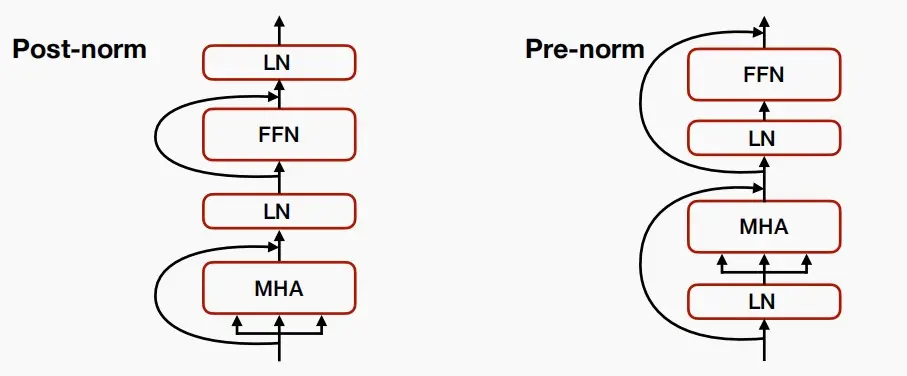
- 为了提高训练的稳定性,我们添加了LayerNorm和Residual Connections(残差连接)
- 在最初的transformer中,是Post-norm,即先计算多头注意力再LN归一化;而后来人们发现Pre-norm具有更好的训练的稳定性,即先LN归一化再计算多头注意力。
4、Positional encoding
- 讲到目前为止,我们仍将token当作集合,注意力和前馈网络没有办法区分输入token的位置顺序,而语言中每个词的位置和顺序是非常重要的,因此我们需要方法对序列进行编码->位置编码Positional encoding。
- Positional Encoding就是将位置信息添加(嵌入)到Embedding词向量中,让Transformer保留词向量的位置信息,可以提高模型对序列的理解能力。
- 原论文中,Transformer论文中,使用正余弦函数表示绝对位置PE_{(pos,i)},最后与词嵌入相加以融入位置信息。除此以外,可知两个绝对位置的乘积是独一无二的,使用乘积来表示两个token相对位置。
- 下图中为原论文中的位置编码公式,其中pos表示token在序列的位置,i表示该位置向量的第i个特征维度,d_{model}表示token的维度。
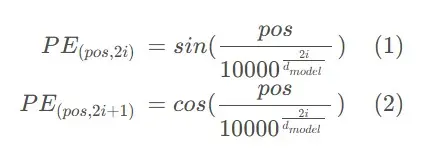
5、result
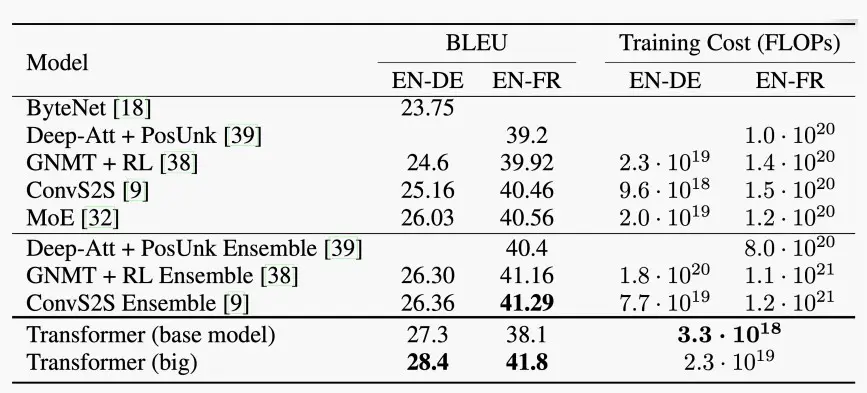
- 如下图是transformer与其他模型的对比
- BLEU测量了机器翻译的文本与一组参考翻译的相似性。
- transformer超过了所有以前发布的模型和集成,并且训练成本更低。
二、Transformer design variants
- 大多数transformer最初的设计已经被社区广泛使用,尽管如此,人们还是提出了各种替代设计。例如:
- Encoder-decoder (T5), encoder-only (BERT), decoder-only (GPT)
- Absolute positional encoding -> Relative positional encoding
- KV cache optimizations:
- Multi-Head Attention (MHA) -> Multi-Query Attention (MQA) -> Grouped-Query Attention
(GQA)
- Multi-Head Attention (MHA) -> Multi-Query Attention (MQA) -> Grouped-Query Attention
- FFN -> GLU (gated linear unit)
Ⅰ、Encoder and Decoder
1、Encoder-Decoder
- 用于机器翻译的原transformer就是一个Encoder-Decoder架构。
- 《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》这篇论文中提出了一个最新的预训练模型 T5(Text-To-Text Transfer Transformer),T5为各种NLP任务上的迁移学习提供了一个统一的文本到文本的模型。
- T5基于transformer模型,并且也是Encoder-Decoder架构,使用该模型使单个模型可以执行各种各样的有监督任务,例如翻译、分类、Q&A、摘要和回归。
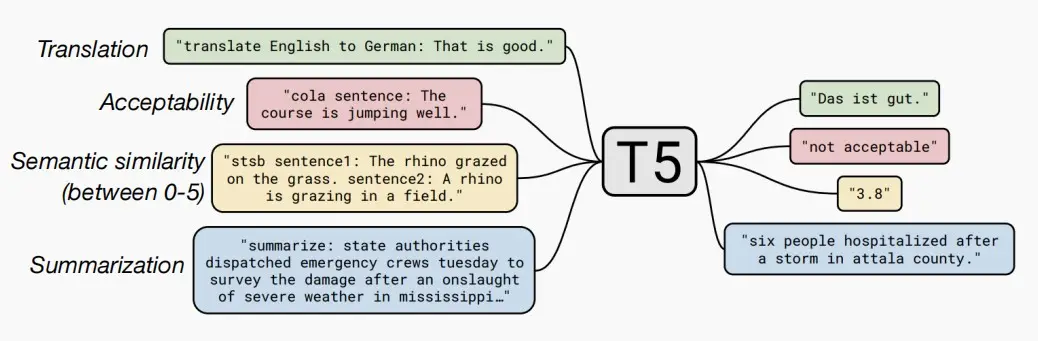
- 在Encoder-Decoder架构中,prompt会被输入给编码器,解码器会生成答案。
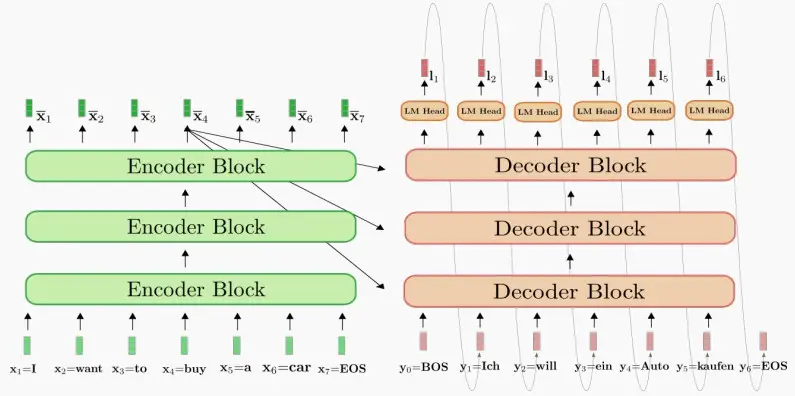
2、Encoder-only
- 最流行的Encoder-only架构模型Bidirectional Encoder Representations from Transformers (BERT),基于Transformer的双向编码器表示。
- BERT使用两种目标之一进行预训练
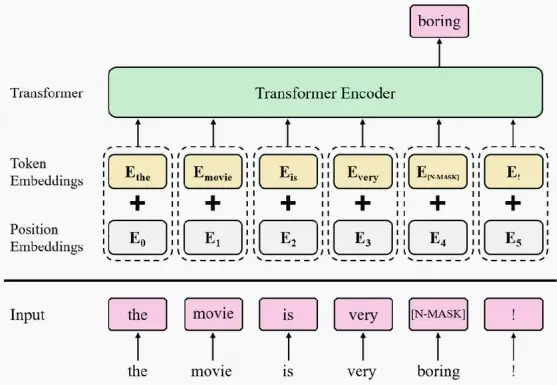
- task 1:掩码语言模型(Masked Language Model, MLM)
- 使用一个被称为掩码标记的特数标记,随机屏蔽大约15%或其他百分比的输入token,并训练模型预测这些被屏蔽的单词。
- 如下图,对'boring'进行掩码标记,生成特殊的掩码token嵌入,并与位置嵌入相加,然后将其通过Transformer编码器,获取预测结果,在此处注入分类损失来进行监督。
- task 2:下一句预测(Next Sentence Prediction, NSP)
- 句子B是否为句子A的下一个句子(较少使用)。
- task 1:掩码语言模型(Masked Language Model, MLM)
- 预先训练好的模型会根据下游任务进行微调。
3、Decoder-only
- 与Encoder-Decoder、Encoder-only的模型相比,Decoder-coder的注意力掩码特性是,每个单词仅能关注其之前的单词。
- 典型的模型之一是GPT模型,Generative Pre-trained Transformer。
- 预训练目标为下一个词预测,L_1(u)=\sum_ilogP(u_i|u_{i-k,...,u_{i-1};\theta})。
- 对于较小的模型(GPT-2),预先训练好的模型将根据下游任务进行微调。对于大模型,可以运行在零样本/少样本。
Ⅱ、Absolute / Relative Positional Encoding
- 原Transformer论文中采用的是绝对位置编码,但是现在人们发现相对位置编码更
- 绝对位置编码将位置信息融合到输入嵌入中(Q/K/V)。这些信息通过整个Transformer进行传播。
- 相对位置编码通过影响注意力分数(增加偏差或修改查询和键)来提供相对距离信息,而不是影响V。
- 优点:泛化到训练中未见的序列长度,即训练短序列,测试长序列(并不总是有效,需要借助技巧才能有效)。
1、Attention with Linear Biases
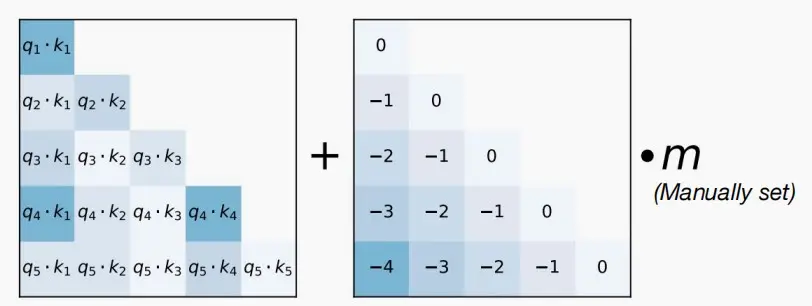
- Attention with Linear Biases (ALiBi,线性偏差注意力)
- 其想法是改变位置编码,只与相对距离相关,而不是绝对指数。
- ALiBi建议向注意矩阵添加一个偏移量(定义为相对距离),而不是将其添加到输入标记嵌入中。
- ALiBi 本质是,通过在注意力机制中加入基于查询和键之间相对距离的线性偏差,来提升Transformer模型对长序列的处理能力,无需增加位置嵌入或改变模型结构。
- 如下图,在计算注意力分数时,一个恒定的偏差(右侧矩阵)被添加到每个头的注意力分数计算中(左侧矩阵)。这个偏差是通过将一个头特定的固定标量m乘以一个下三角矩阵来实现的,其中下三角矩阵的值由查询q和键k之间的距离决定,这样更远的键将收到更大的惩罚。
2、Rotary Positional Embedding (RoPE)
- Rotary Positional Embedding (RoPE)
- RoPE出自论文《Self-Attention with Relative Position Representations》
- 论文中提出,为了能利用上token之间的相对位置信息,假定query向量q_m和key向量k_n之间的内积操作可以被一个函数g表示,该函数g的输入是词嵌入向量x_m,x_n和它们之间的相对位置m - n:
<f_q(x_m,m),f_k(x_n,n)> = g(x_m,x_n,m-n) - 为了满足上述等式,作者提出了RoPE方法,该编码方式中
f_q(x_m,m) = (W_qx_m)e^{im\theta}=q_me^{im\theta} 、
g(x_m,x_n,m-n)=Re[(W_qx_m)(W_kx_n)e^{i(m-n)\theta}]=q_mk_ne^{i(m-n)\theta},
此处的\theta=10000^{-2(i-1)/d}具体推导。 - 在二维空间中旋转嵌入件,将嵌入维度d分割成d/2对,每对被视为二维坐标。
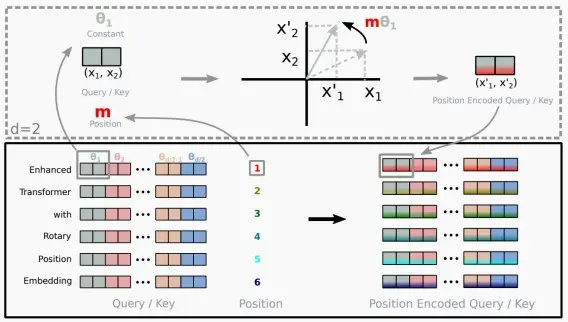
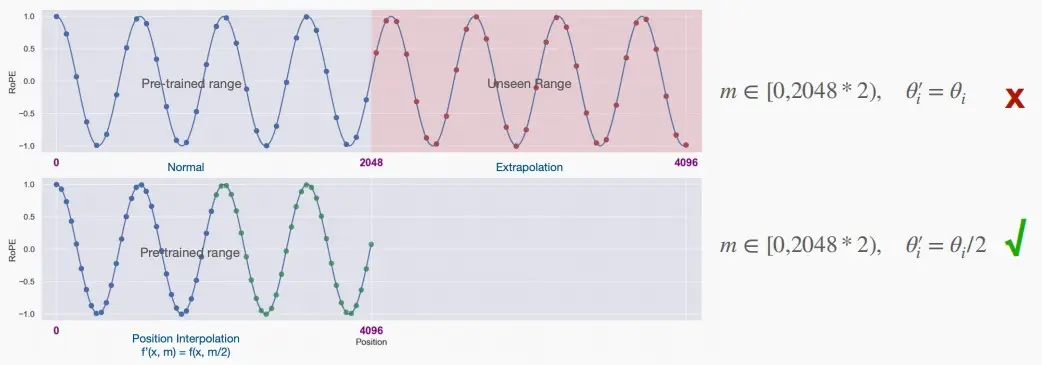
- RoPE的优点:扩展上下文窗口
- 我们可以通过插值RoPE PE(即使用一个较小的\theta_i)来扩展上下文长度支持。将LLaMA的上下文长度从2k扩展到32k。
Ⅲ、KV cache optimizations
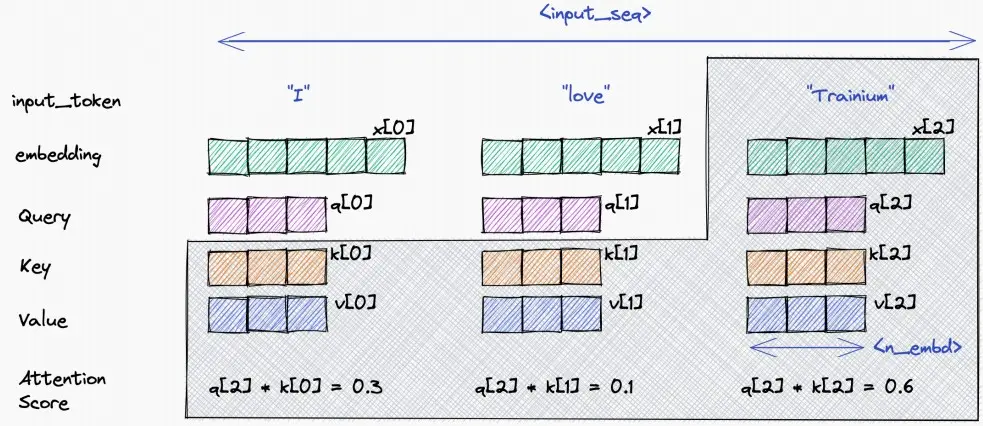
- 在Transformer decoding(GPT-style)过程中,我们需要存储所有之前token的Keys and Values,以便我们能够执行注意力计算,即KV缓存。
- 只需要当前的query token。
- 如下图中,当我们计算到token 2 'trainium'时,我们需要用到之前token的Keys and Values,即需要保存灰色区域到缓存中,以防止重复计算。
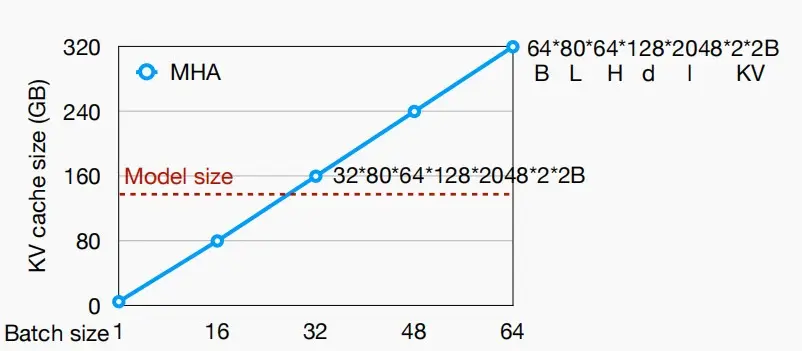
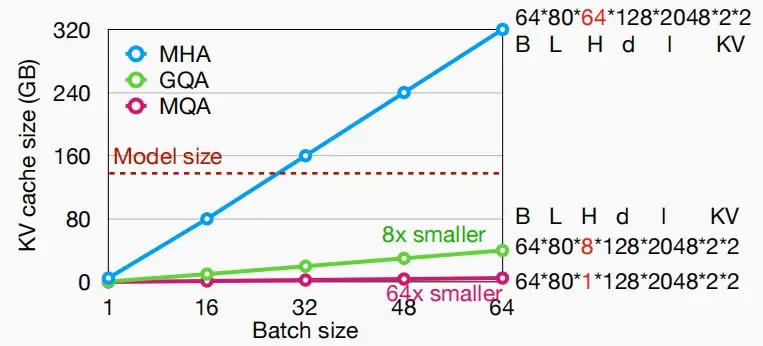
- 如下图,计算了Llama几个模型的KV缓存大小:
- 当BS=16,n_seq=4096时,即假设16个人同时向大模型输入了长度为4096的prompt,需要160GB的KV缓存,这还不包括激活函数和权重需要的的大小,因此迫切的需要减小KV缓存大小。


- 如下图,KV缓存大小随着Batch size线性增长,并且KV缓存大小很快大于模型权重。
- 因此人们提出了多种技术来减少KV缓存的大小,通过减少KV缓存的数目来实现。
- 通过减少#KV-heads来减少KV cache的大小
- Multi-head attention (MHA): N heads for query, N heads for key/value
- Multi-query attention (MQA): N heads for query, 1 heads for key/value
- 将key和value组合成一个数
- Grouped-query attention (GQA): N heads for query, G heads for key/value (typically G=N/8)
- 将key和value按组合并成一个数
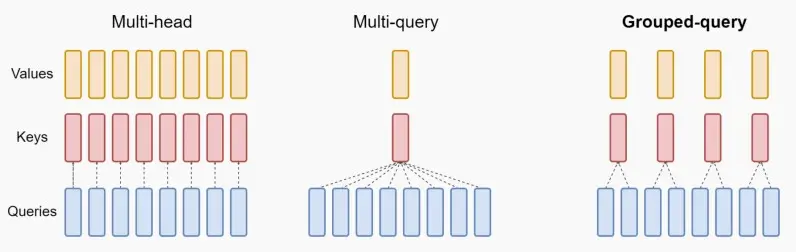
- 如下图是使用MQA和GQA后KV缓存大小随着Batch大小变化图,减少效果相当显著。
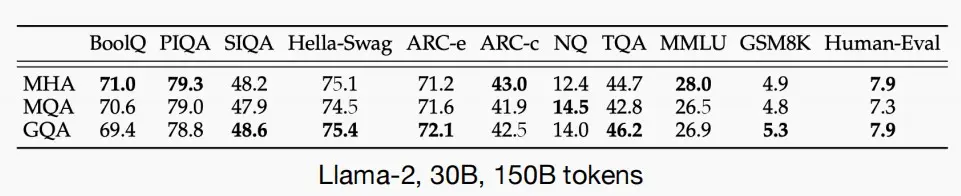
- 再考虑对精度的影响,如下图对Llama-2, 30B, 150B tokens进行MQA和GQA后精度的变化,可以看见精度略微下降,因为会丢失部分信息,但是可以接受。
Ⅳ、Gated Linear Units (GLU)
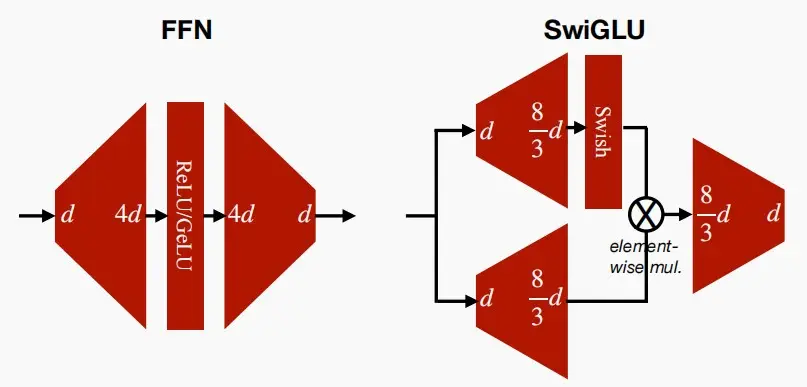
- 先前在讨论FFN时,我们假设它对于ReLU或GaLU激活函数而言,起到了逆瓶颈的作用但为了在此基础上进一步改进,人们提出了门控线性单元GLU,它实际上包含了三个矩阵变换。
FFN_{sWIglu}(x,W,V,W_2) = (Swish_1(xW)\otimes xV)W_2
- FFN和SwiGLU的结构对比图
- GeLU和Swish激活函数图
三、Large language models (LLMs)
Ⅰ、涌现能力(emergent)
- LLMs是在大型语言语料库(自然语言、代码等)上训练的scaled-up transformers模型。
- 涌现能力(emergent):在较小的模型中不出现,而在较大的模型中出现的能力。
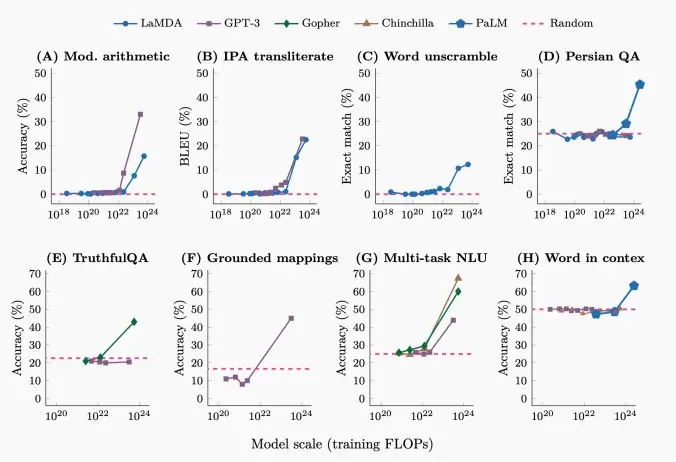
- 如下图,可以看出几个模型在八种常见任务中,随着模型规模增大到一定程度,准确度开始明显上升,这就是大模型的涌现能力。
Ⅱ、GPT-3
- GPT-3
- 将Transformer模型扩展为少样本学习者(few-shot learners),引入了上下文学习(In-context learning)。
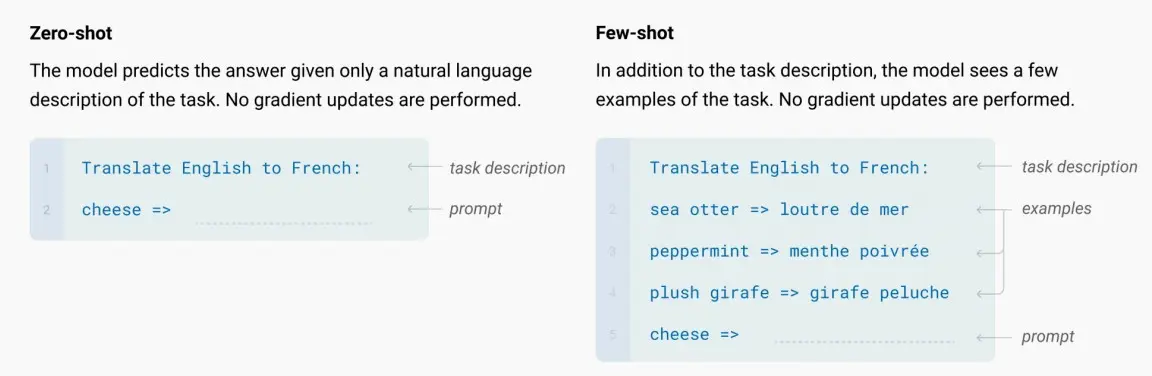
- 零/少样本学习
- 传统上,对于下游任务,人们必须针对不同的下游任务对预训练模型进行微调,十个下游任务就要十个微调。例如翻译,就需要给大量样本进行训练,梯度学习。
- 零/少样本学习本质上是指模型直接在自然语言提示中描述任务,少样本需要从提示中学习,而零样本不需要,因此两者不需要样本为不同的任务微调成单独的模型,没有梯度更新。
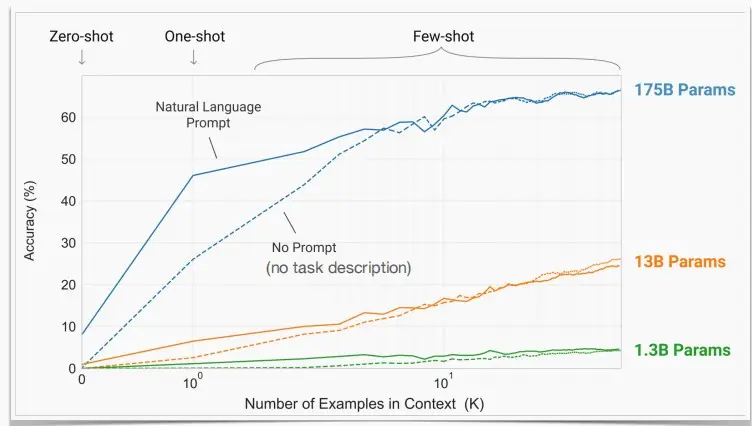
- 如图,可以看出更大的模型可以更有效地利用少样本的描述进行学习。
- 随着更多的演示,无prompt的准确性赶上了task-prompt的准确性。这意味着使用者不需要给出明确的任务指示,例如“翻译成法语”,模型也可以自动翻译成法语。
Ⅲ、OPT
- Open-source pre-trained LLM from Meta
- Size: 125M/350M/1.3B/2.7B/6.7B/13B/30B/66B/175B
- Design choices: Decoder-only, Pre-norm (post-norm for 350M), ReLU activation in FFN
- 175B model: hidden dimension 12288, #heads 96, vocab size 50k, context length 2048
- Close performance compared to GPT models
Ⅳ、BLOOM
- Open-source pre-trained LLM from BigScience (and opensource community)
- Size: 560M/1.1B/1.7B/3B/7.1B/176B
- Design choices: Decoder-only, Pre-norm, GeLU activation in FFN, ALiBI positional embedding
- 176B model: hidden dimension 14336, #heads 112, vocab size 250k, context length 2048
- Support multi-lingual (59 languages in the corpus)
Ⅴ、LLaMA
- Open-source pre-trained LLM from Meta
- Size: 7B/13B/33B/65B
- Design choices: Decoder-only, Pre-norm, SwiGLU (swish, gated linear units), rotary positional embedding (RoPE)
- 7B model: hidden dimension 4096, #heads 32, #layers 32, vocab size 32k, context length 2048
- 65B model: hidden dimension 8192, #heads 64, #layers 80, vocab size 32k, context length 2048
- Much better performance compared to previous opensource models
Ⅵ、LLama 2
- Larger context length (2k -> 4k)
- More training tokens (1T/1.4T -> 2T, no sign of saturation yet)
- GQA for larger models (70B, 64 heads, 8 kv heads)
- Also include Llama-2-chat, an instruction-tuned version
Ⅶ、How to scale up?
- The Chinchilla Law
- 我们需要扩大模型大小和数据大小来进行训练,以获得最佳的训练计算量与精度权衡。
- 注意:如果我们考虑推理计算的交易,那么权衡是不同的。
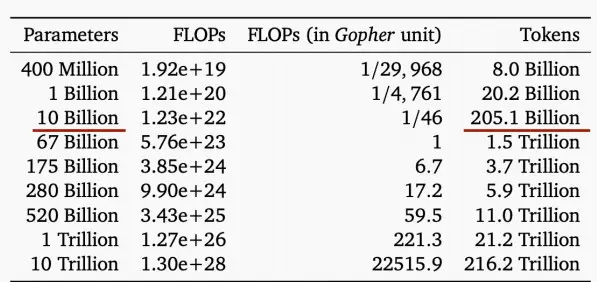
- 如图,根据Chinchilla法则,一个10B参数的模型,需要大约205B tokens才能达到非常出色的性能。