![[MIT6.5940] Lect 17 Distributed Training (Ⅰ)](/upload/宏村.webp)
一、Background and motivation
-
更好的模型总是具有更高的计算成本。(包括视觉和NLP)
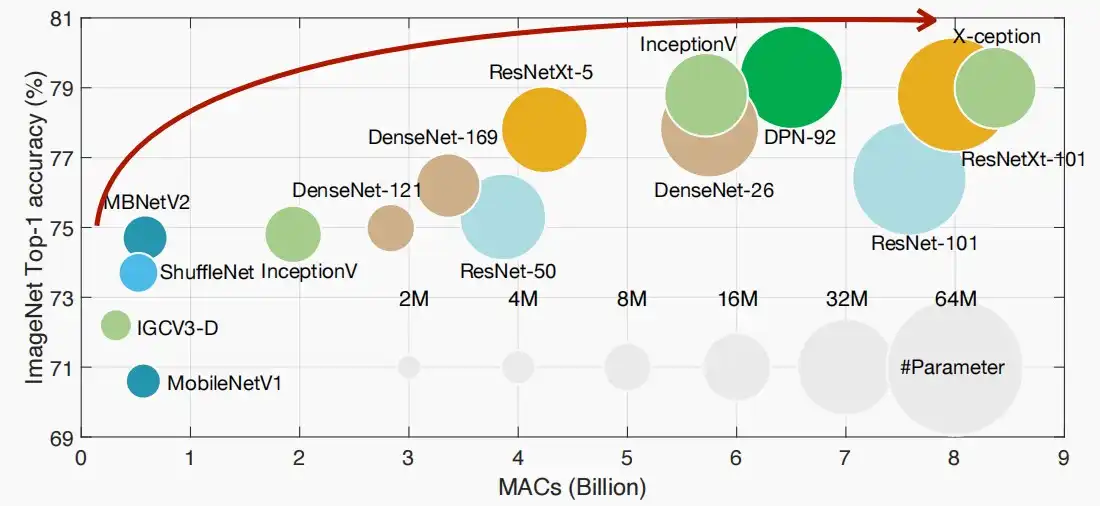
- 而越大的模型需要更久的时间训练。
- 如下图所示,如果没有分布式训练,一个单个GPU将需要355年才能完成GPT-3的训练!
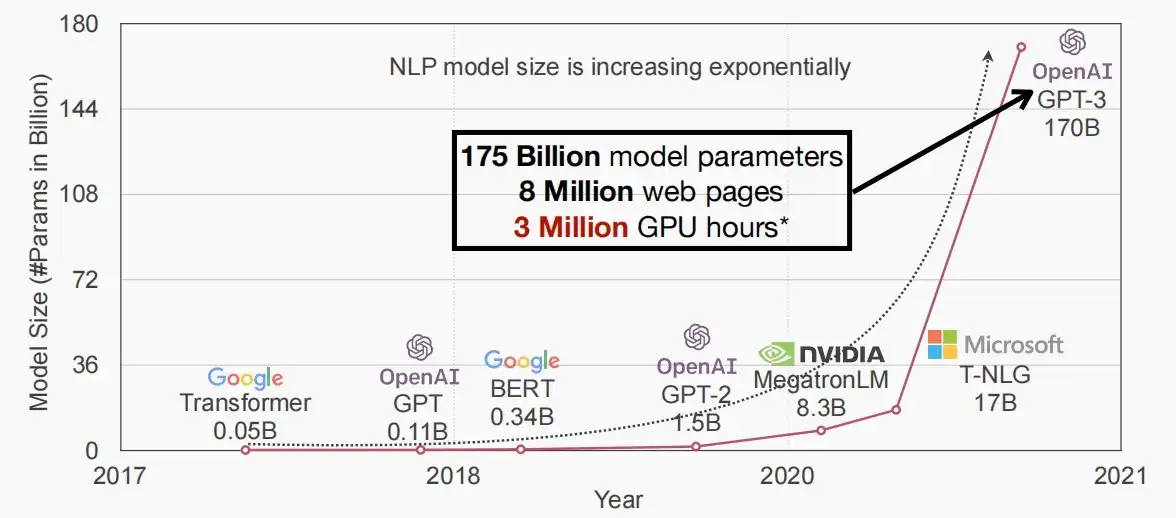
- 如果使用分布式训练,10个GPU日的训练任务,在1024个GPU上只需要训练14分钟。
二、Parallelization methods for distributed training
- 分布式训练的并行化方法主要是三种:数据并行、流水线并行和张量并行。
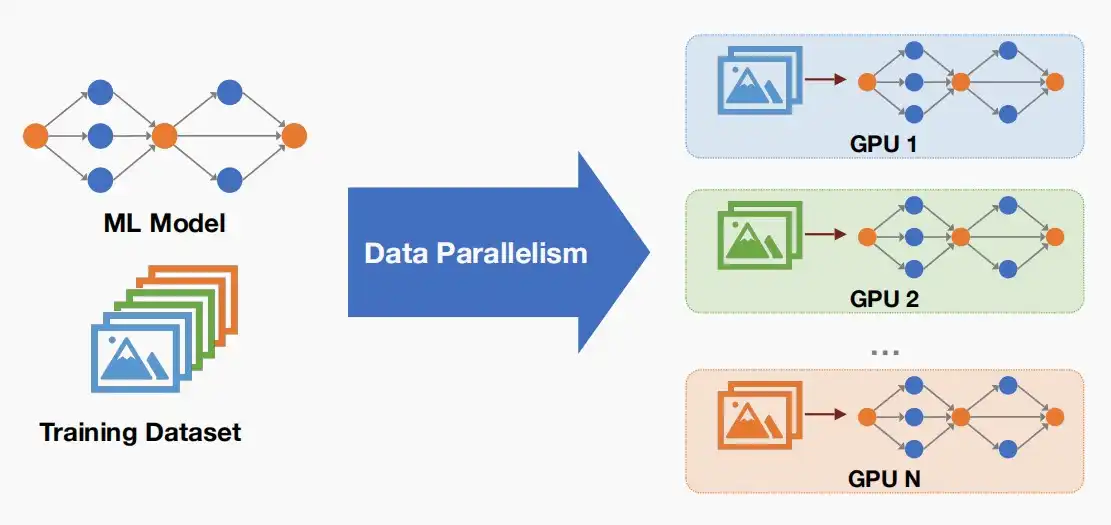
Ⅰ、Data Parallelism
- 数据并行比较简单,即同一个模型在N个GPU上部署,将数据集分割成N份,分别在N个GPU上处理。
【图】
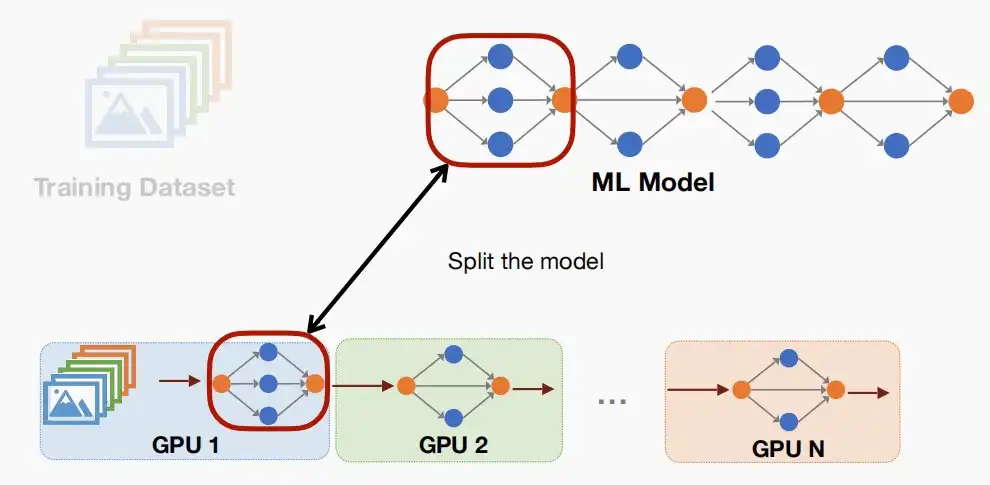
Ⅱ、Pipeline Parallelism
- 流水线并行化,即将模型分成N个部分,分别部署在N个GPU上。
Ⅲ、Tensor Parallelism
- 张量并行化,将通道划分为N个部分,分别部署在N个GPU上,当计算张量时可以在不同的GPU上进行,因此成为张量并行化。
三、Data parallelism
- 《Scaling Distributed Machine Learning with the Parameter Server》 [Mu Li et al. 2014]
- 框架中的两种不同角色:
- 参数服务器:接收来自工作节点的梯度并返回聚合的结果。
- 工作节点:使用分割的数据集计算梯度\Delta W,并发送到参数服务器。
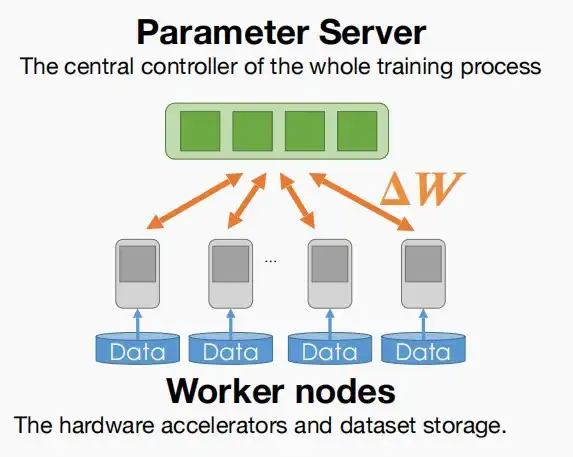
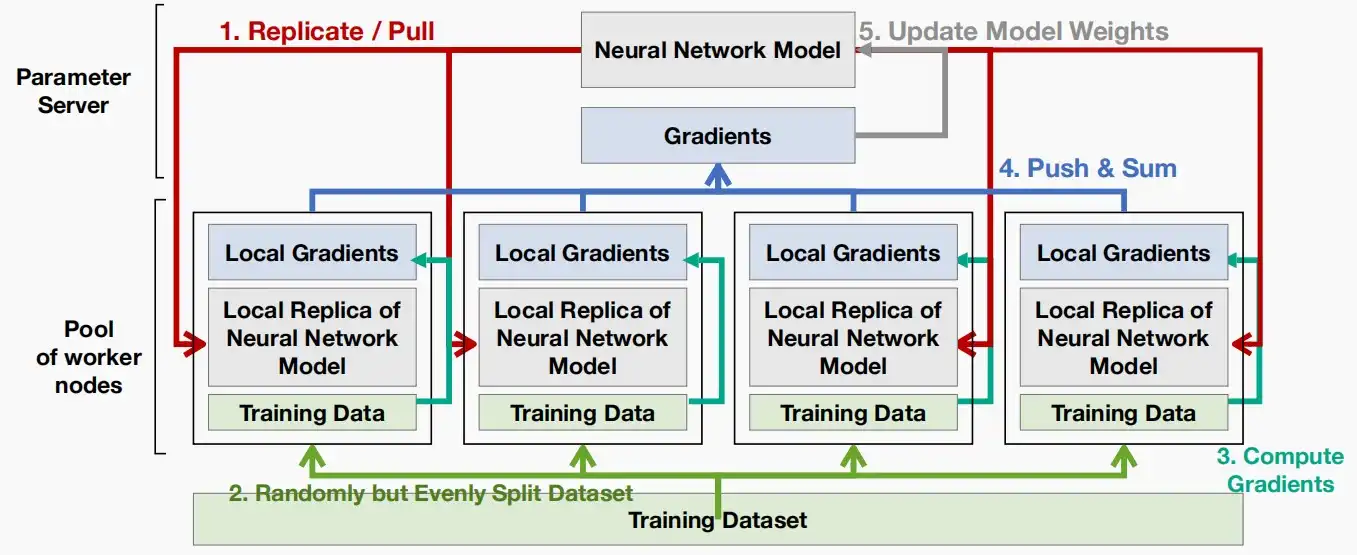
- 基础框架如下图
- 第一Replicate / Pull,参数服务器向每个工作节点复制模型。
- 第二Split Dataset,将训练数据分割,分别输入各个工作节点。
- 第三Compute Gradients,工作节点的本地神经网络模型副本处理输入数据,并输出局部梯度。
- 第四Push & Sum,参数模型对各个工作节点的局部梯度进行求和,并更新自身参数。
- 第五Update Model Weights,将更新后的模型参数出啊数值本地神经网络模型副本,保持同步。
四、Communication primitives
- Communication primitives通信原语,由于需要在不同节点间进行通信,因此需要用到通信原语。
Ⅰ、One-to-One: Send and Recv
- 一对一的通信:将数据从一个进程传输到另一个进程。
- Send & Recv是在Socket、MPI、Glue、NCCL等中最常见的分布式通信方案。

Ⅱ、One-to-Many
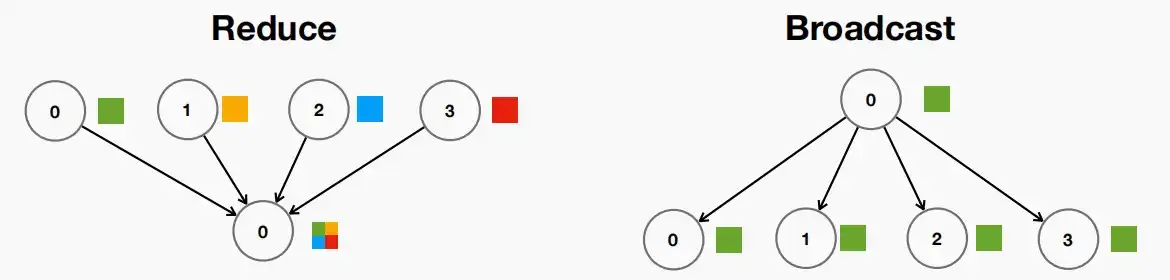
- 一对多通信:一种对所有工作节点进行的操作。常见的有以下两种操作。
- Scatter and Gather
- Scatter:向所有工作节点发送一个张量。
- Gather:从所有工作节点那里得到一个张量。

- Reduce and Broadcast
- Reduce:类似于聚合,但在聚合期间进行平均/求和。gather与reduce的区别如下:
- [1] [2] [3] [4] —(gather)—> [1,2,3,4]
- [1] [2] [3] [4] —(reduce)—> [1 + 2 + 3 + 4] = [10]
- Broadcast:发送相同的副本给所有其他工作节点。
- Reduce:类似于聚合,但在聚合期间进行平均/求和。gather与reduce的区别如下:
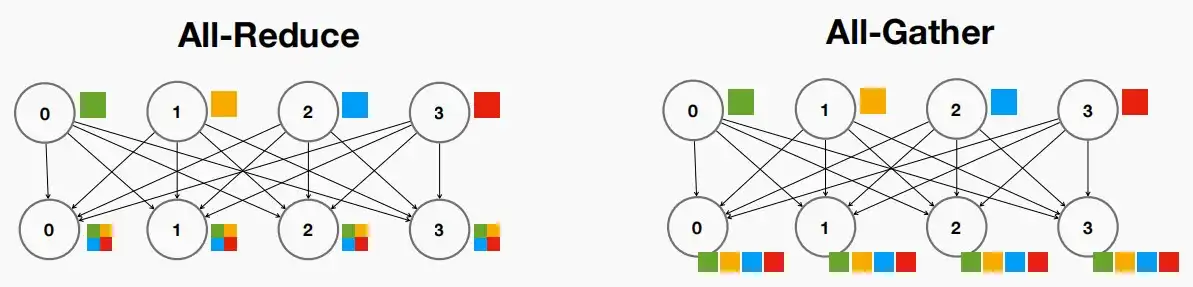
Ⅲ、Many-to-Many: All Reduce and All Gather
- All Reduce and All Gather
- All Reduce:对所有员工执行reduce。
- All Gather:对所有工作节点执行gather。
Ⅳ、communication schemes in Parameter Server
- 参数服务器中的通信原语
- Replication & Pull:使用Broadcast,将模型参数广播给所有工作节点。
- Push & Sum:使用Reduce,将工作节点的梯度参数输入给参数服务器,进行平均聚合。
- 复杂度 & 瓶颈
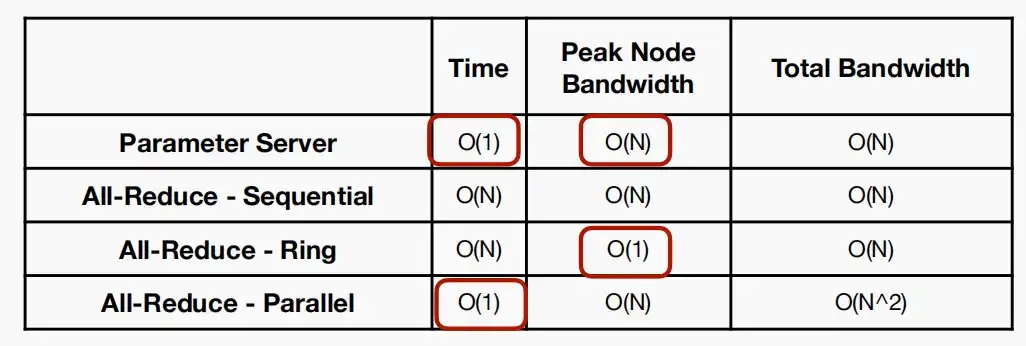
- 无论是Replication & Pull还是Push & Sum,对于工作节点的宽带需求都是O(1),对于参数服务器的宽带需求都是O(N)。
- 中心参数服务器的带宽以数量线性增长,当机器较多时,可能会成为瓶颈。
- 我们可以在没有中心参数服务器的条件下实现聚合吗?
- 使用All-Reduce!取消中心参数服务器,直接对工作节点进行Reduce操作。可以利用All-Reduce设计出如下三种实现方式
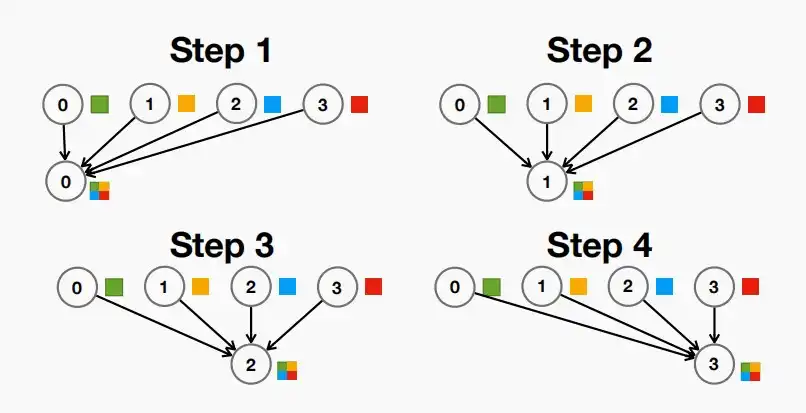
- Sequential:下方第一张图,循环每一个工作节点,依次进行All-Reduce操作。此时时间和宽带复杂度都是O(N)。
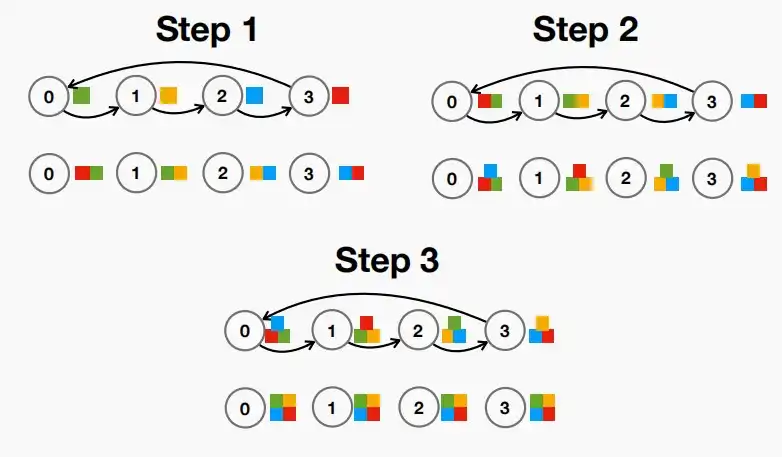
- Ring:下方第二张图,对于N个工作节点,依次进行N-1次交换信息,每一次仅与左边的节点进行信息交换。此时时间为O(N),峰值带宽复杂度为O(1),总带宽复杂度为O(N)。
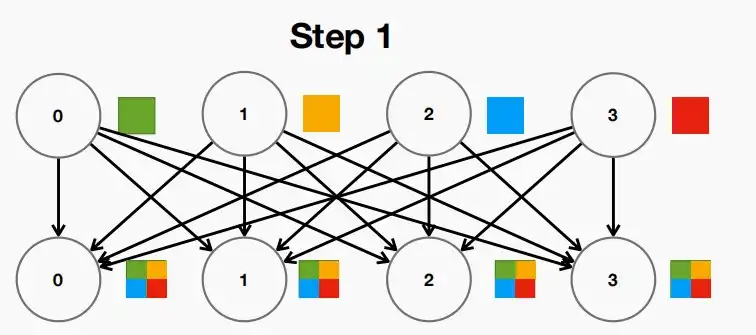
- Parallel:下方第三张图,同时并行处理N个节点的All-Reduce操作。此时时间复杂度为O(1),单节点带宽复杂度为O(N),总带宽复杂度为O(N^2)。
- Recursive Halving All Reduce
- 这是一种相比于上述Sequential等更高级的方法,同样用于在没有中心服务器的条件下聚合。
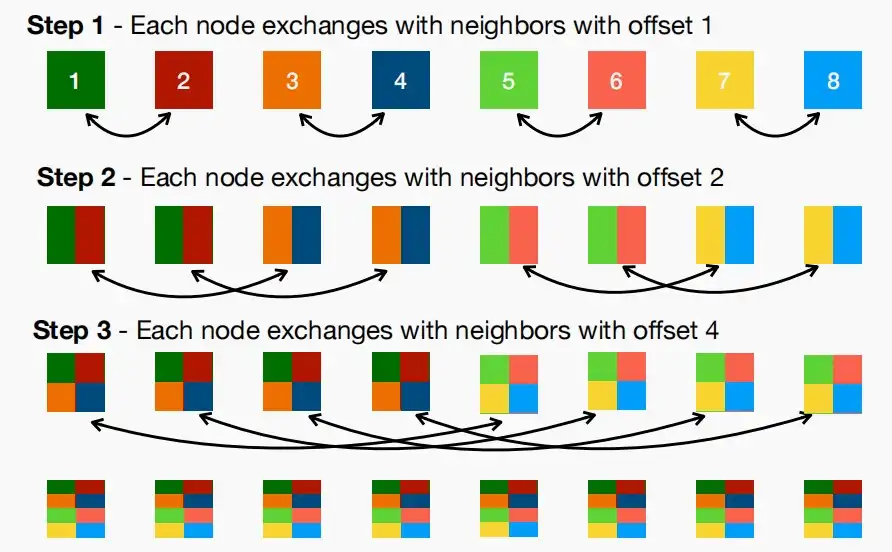
- 其具体流程如下图,对于N=8个工作节点,依次进行偏移量offset=2^{(i-1)}的半reduce,其中i为当前步数,只需要3步即可实现聚合操作。
- 对于任意的N个工作节点,只需要log(N)步即可完成All-Reduce操作。
五、Reducing memory in data parallelism
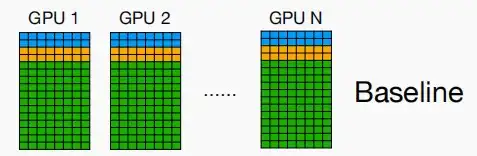
- 在数据并行中,数据被分割成N个部分,但每个GPU上都有模型副本,这会导致对内存的需求巨大。包括权重、优化器状态和梯度,因此数据并行难以训练大模型。即使是具有更好设备利用率的流水线并行,也难以训练一个超大模型(例如,GPT-3 175B)。
- 因此我们需要一种能缓解内存压力的方法,使得满足大模型分布式训练的需求。
- 本章将介绍《ZeRO: Memory Optimizations Toward Training Trillion Parameter Models》提出的DeepSpeed Zero,分为三个点。
- 参数需要的内存
- 一个参数需要多少存储空间
- 对于使用FP16精度的权重和梯度,分别需要2个字节。
- 对于优化器状态,包括FP32精度的参数副本、动量和方差,因此需要12个字节。
- 综上可以知道,对于一个模型参数,就需要2+2+12=16个字节。
- 对于目前最先进的A100/H100显卡,具有80GB的内存,最大可训练参数为80GB/16Byte=5B,即5B个参数,这远小于目前SOTA模型的175B。
- 一个参数需要多少存储空间
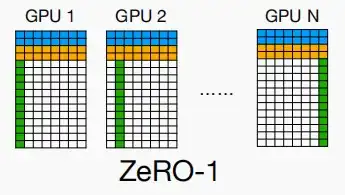
Ⅰ、ZeRO-1
- ZeRO-1提出了对优化器状态分片,将优化器状态分散到不同的工作节点上,工作节点仅拥有其自身副本的一部分优化器状态,因此它只能更新自身副本的梯度以及权重,因为它仅拥有优化器状态的自身副本。如果它需要访问其他优化器状态,需要通过通信交换信息。
- 假设有N=64个工作节点,那么分片后优化器状态只需要大约0.2字节,则一个参数只需要2+2+0.2=4.2个字节,使用A100/H100可以训练80GB/4.2Byte=19B个参数的模型。
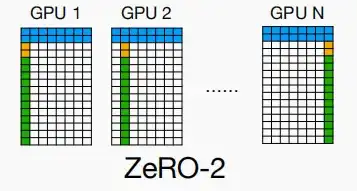
Ⅱ、ZeRO-2
- ZeRO-2在Zero-1的基础上,进一步提出了分片梯度。
- 每个节点不再拥有所有梯度,而只是拥有自己的梯度,负责更新自己的权重。
- 假设有N=64个工作节点,使用A100/H100可以训练80GB/2.2Byte=36B个参数的模型。
- ZeRO-2比ZeRO-1使用更加广泛,因为几乎没有什么代价即可得到提升。
Ⅲ、ZeRO-3
- ZeRO-3在ZeRO-2的基础上,提出分区权重。
- 但这使得情况变得略微复杂,因为在推理过程中,你无法获取所有的参数,而前向传播与后向传播时都需要能够访问所有的权重。
- 因此在每一次传播时,都需要进行工作节点间的通信,获取完整的权重参数。这也是通信与存储需求的权衡。
- 假设有N=64个工作节点,使用A100/H100可以训练80GB/0.25Byte=320B个参数的模型。
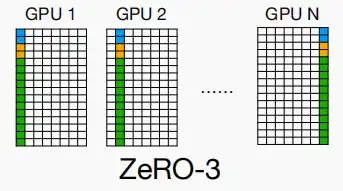
- ZeRO-3实现了全内容分片,在Pytorch中通过FullyShardedDataParallel实现,被称为FSDP。
六、Pipeline parallelism
- 流水线并行不分割数据,而是分割模型。
- 因此大模型可以被分片部署在不同的GPU上,对于一个权重大小为350GB的模型,每个GPU上平均只需要大约43.75GB的内存空间,这有利于大模型的部署和训练。
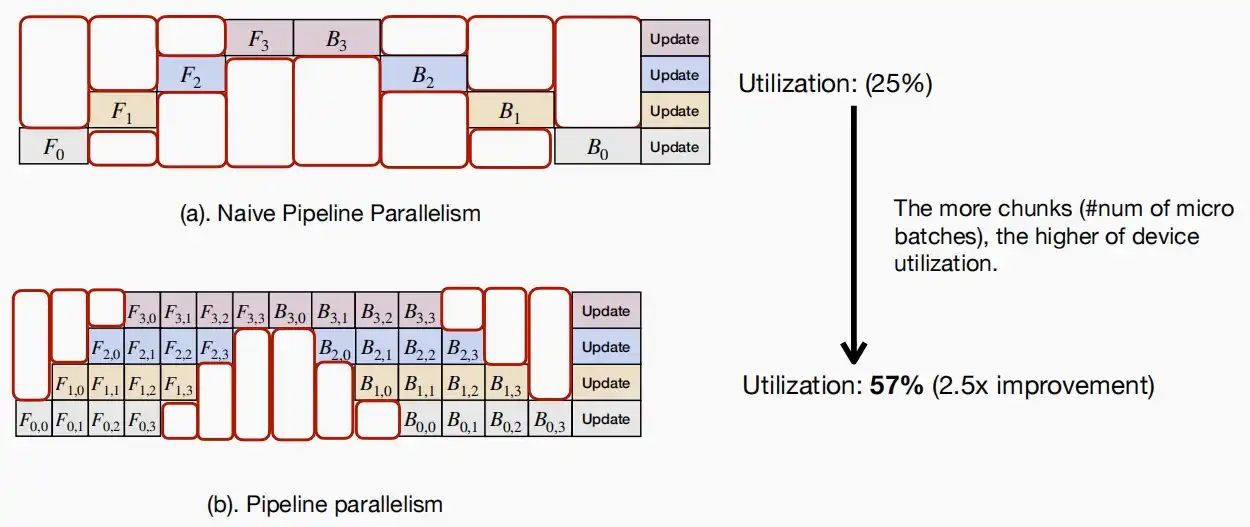
- 但是普通的流水线显然硬件效率十分低效,同时只有一个GPU在进行计算,模型串行计算,空闲时间多。
- 由于模型参数在一个batch内不会改变,只有完成一次前后向传播后才更新参数,因此可以将每一个batch进行分片,例如[16,10,512]分片成四个块[4,10,512],即原本的前向传播F_0 \rightarrow \{F_{0,0},F_{0,1},F_{0,2},F_{0,3}\},依次输入。
- 可以看到,batch分片后的利用率从25%提升到了57%。
- 当块越小,设备利用率越高。但是,此处的利用率仅考虑了GPU正在计算,而没有考虑GPU是否全负荷运转,因此当块太小时,该块的计算无法占用整个GPU,导致实际效率降低。
七、Tensor parallelism
问题:优化后的流水线并行仍然会导致GPU的空闲时间,我们能否进一步改进它(同时保持低内存使用需求)?
答案:使模型分区更细粒度!
- 张量并行:将一个权重张量分成N个块,并在多个GPU上同时并行计算。
- 接下来分别介绍如何利用张量并行来并行处理多层感知机MLP和自注意力层。
- 具体框架如下图,f和g表示用于同步的All-Reduce操作/恒等操作,蓝色部分的参数和激活值被分片在不同的GPU上。
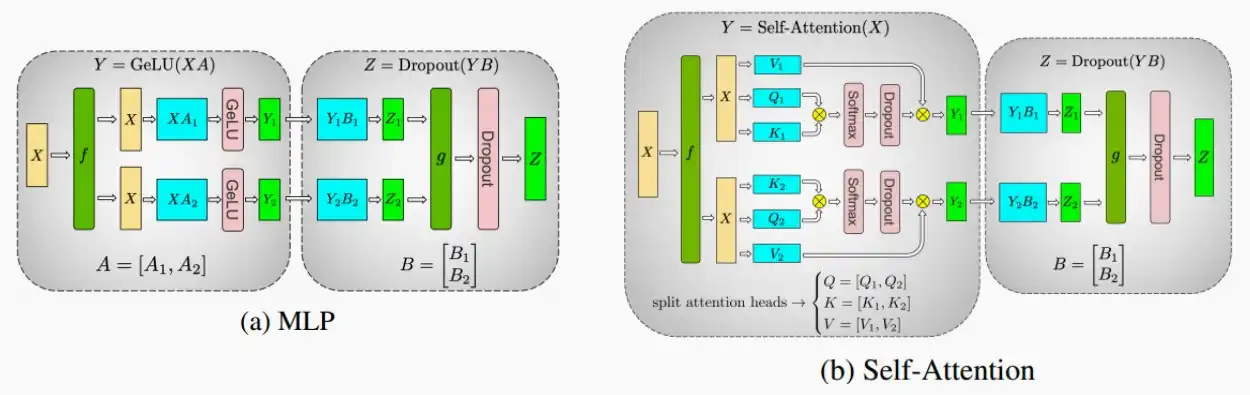
Ⅰ、Partition in FFN Layer
- 对于一个两层的FFN层,分别采用行和列的方式进行分割。
- 如下图,第一层采用按列分割的方式,两个不同的GPU有不同的权重矩阵A_1和A_2;将输入矩阵X进行广播Broadcast给两个GPU,分别进行XA计算后得到输出Y_1和Y_2。

- 第二层采用按行分割的方式,将前一层的输出分别与权重B_1和B_2计算,得到的结果进行All-Reduce进行归约。
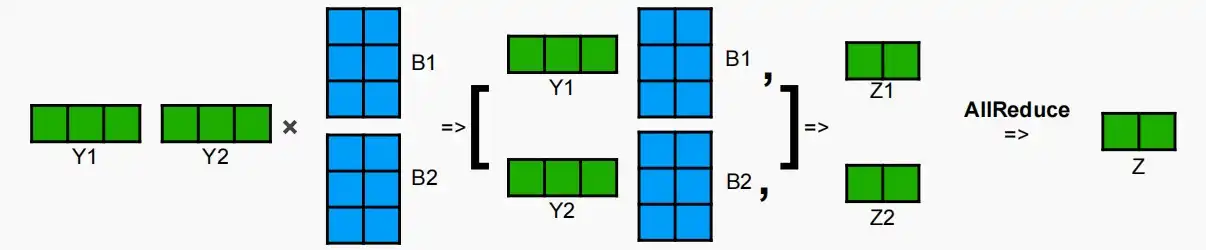
- 在此方法中,第一层切分后,无论是垂直还是水平方向,后续各层之间便不再进行通信。
Ⅱ、Partition in Attention Layers
- 首先,我们将Q,K,V矩阵按列(高)进行分割,分别部署在不同的GPU上,因此,可以认为每个GPU负责一个头部。接着将输入X广播Broadcast给每一个GPU进行计算。
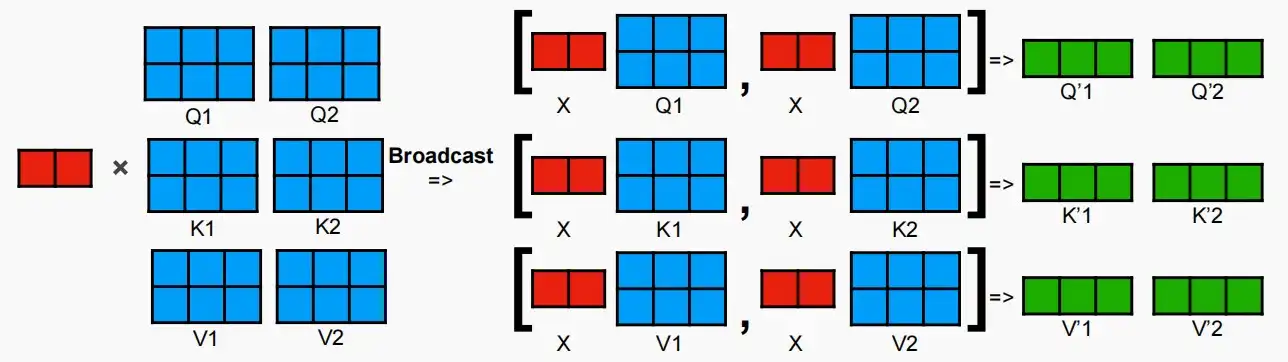
- 之后,将计算QK^T,进行softmax后与V相乘得到Y_1和Y_2,即注意力机制。每个头部的操作都是独立进行的。
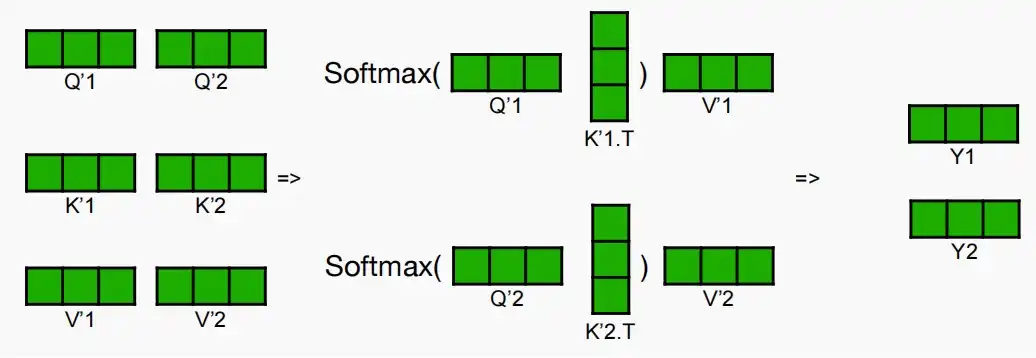
- 最后进入输出投影层,矩阵Y分别与输出投影矩阵B进行并行乘法,得到Z_1和Z_2,再进行All-Reduce操作得到最终结果Z。
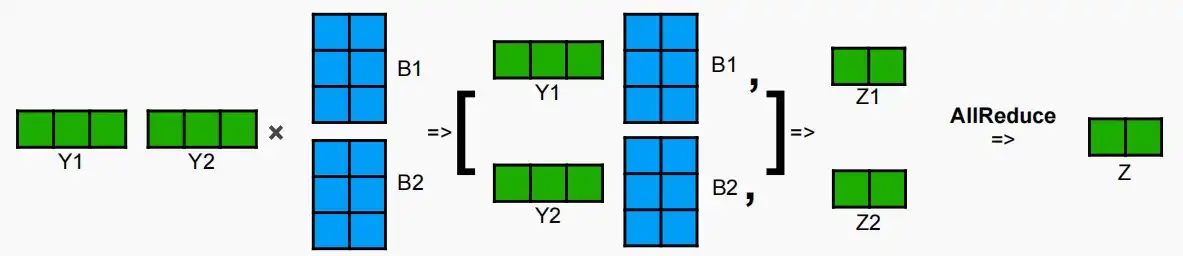
- 实际上,这种情况下不同工作节点间的通信很少,因为计算输入投影的不同头部是独立进行的,可以在不同GPU上独立计算自注意力机制。之哟在最后一步All-Reduce需要进行通信。